@zhangyy
2021-03-22T09:45:17.000000Z
字数 2157
阅读 1271
Spark SQL 的应用
Spark的部分
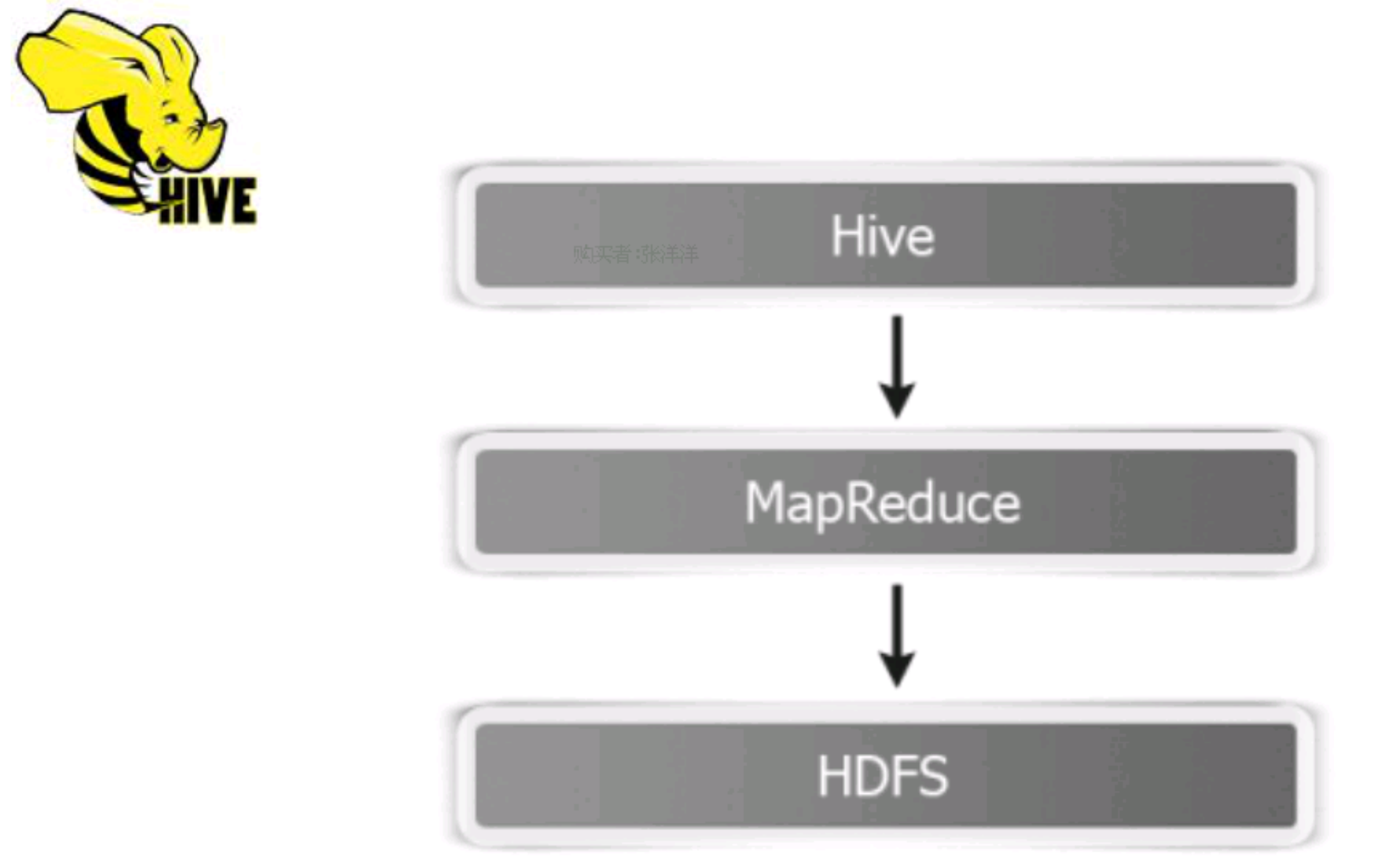
一: Spark Sql 的前世今生
1.1 SparkSql 基础
- 1. 基础1.1:hive基本上Hiveql 95% 都可以在spark sql 运行1.2:SparkCoreRDD- 2. DataFrame企业中SparkSql-1,分析数据hive 表中-2,DSLDataFrame性能非常好内存考虑sqlContext.read.parquet("/user/beifeng/spark/sql/order.parquet") // DataFrame.select("col1").groupBy("co12").orderBy("col3").filter().write.jdbc(url,tableName,props)归结于:DataFrame + External Data Source
1.2 围绕在大数据旁边的sql框架
Dremel-1,Presto-2,Impala游戏公司-2.1 yum rpm 安装-2.2 CMflume + kafka + hbase + impala + java + python-3,drill (1PB/3s)-4,kylin (麒麟框架 olap)http://kylin.apache.org/
二:SparkSQL 相关查询
2.1 hive 的查询
2.2 shark


Spark sql 前世今生-1,1.0 版本shark = hive on spark-2, 1.0.x 版本spark sqlappha 版本-3, 1.3.X 版本dataframerelease 版本-4, 1.5.x 版本钨丝计划-5, 1.6.新版本DataSet-6, 2.0 版本。。。。。总结一点:spark sql 开始的话,替换HIVE 底层,sparkSQL与hive完全兼容,尤其是HQL 语句shark-1. Spark SQLalpha 版本-2,hive on sparkhive-1,mapreduce-2,spark-3,tez
2.3 hive 与 Spark SQL 的集成
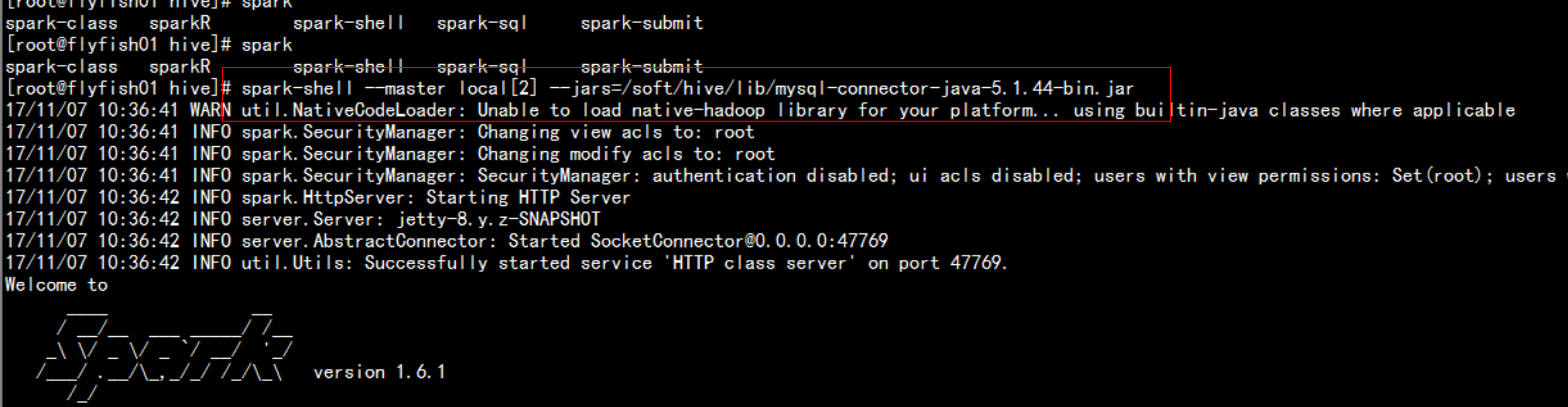
cd /soft/hive/confcp -p hive-site.xml /soft/spark/conf第一种方法:spark-shell --master local[2] --jars=/soft/hive/lib/mysql-connector-java-5.1.44-bin.jar
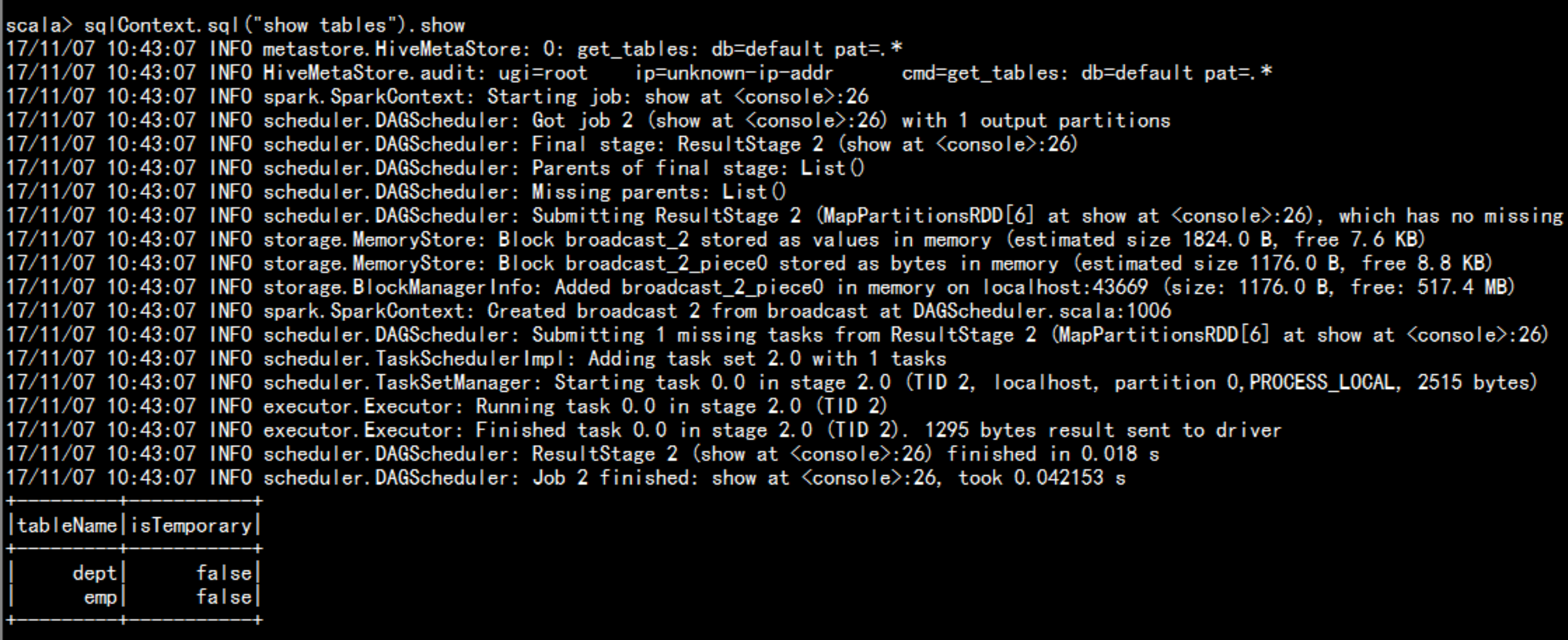
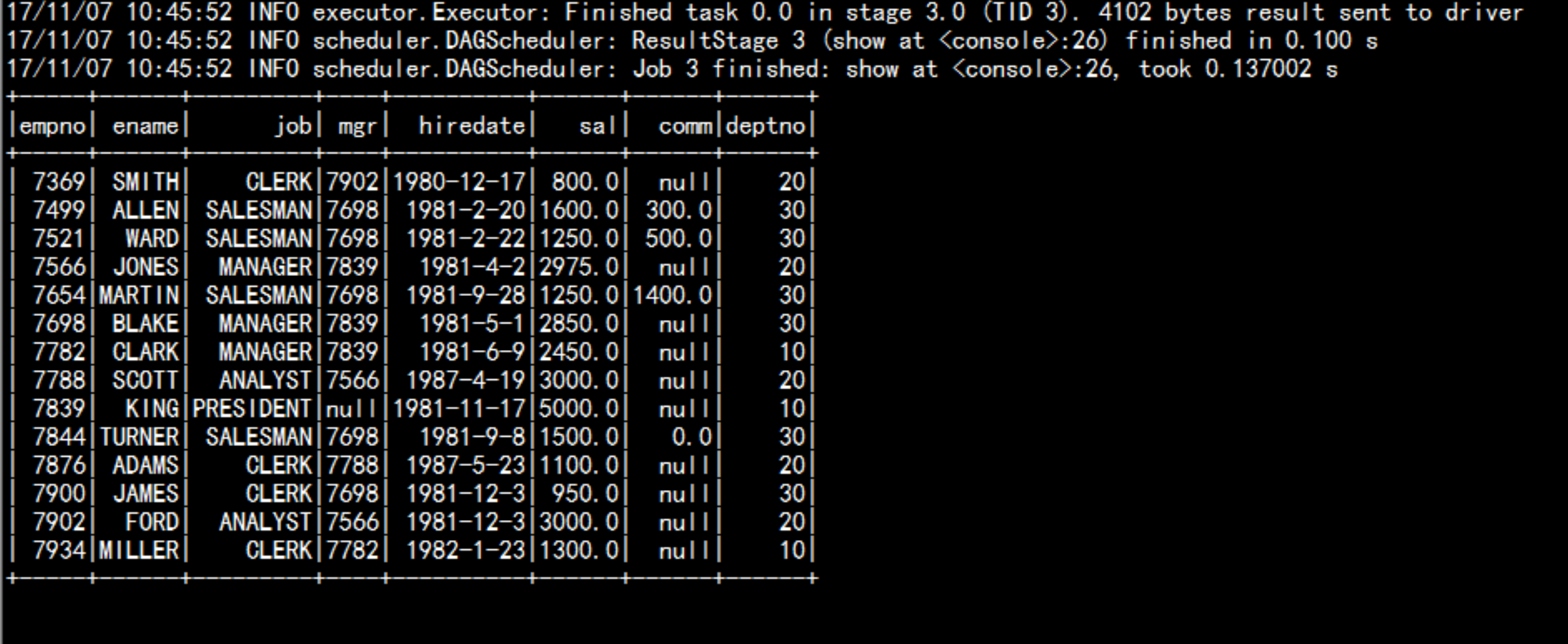
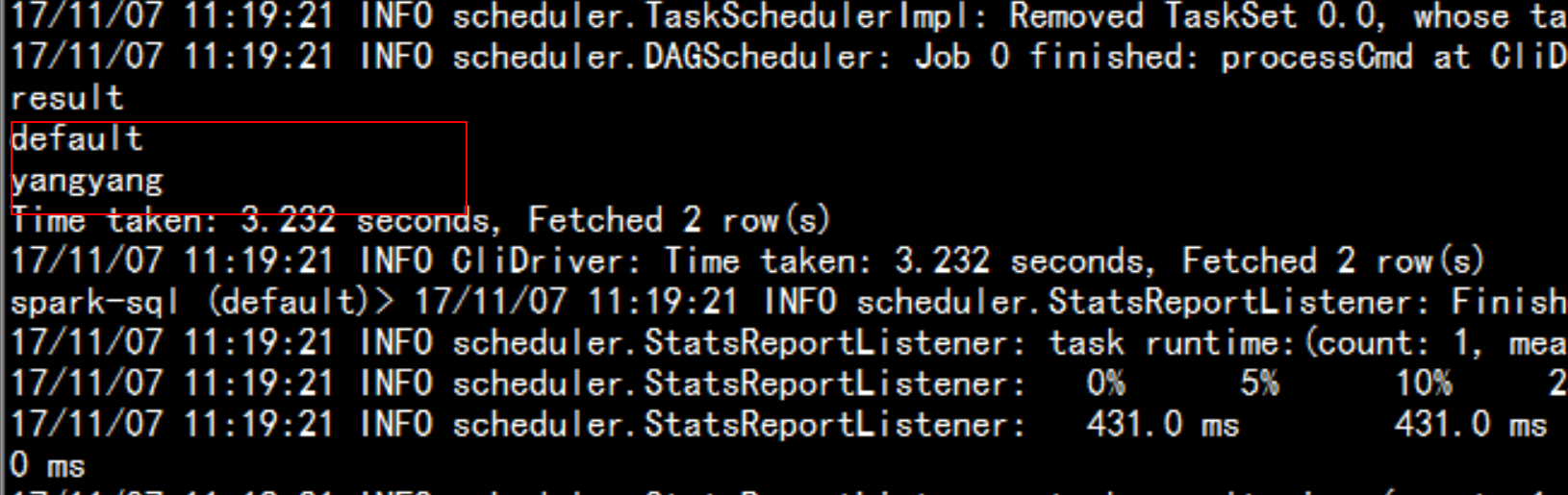
sqlContext.sql("show databases")sqlContext.sql("show databases").showsqlContext.sql("use default").showsqlContext.sql("show tables").showsqlContext.sql("select * from emp").show
2.4 hive 与 spark sql 查询对比
select deptno,count(1) from emp group by deptno;sqlContext.sql("select deptno,count(1) from emp group by deptno").show
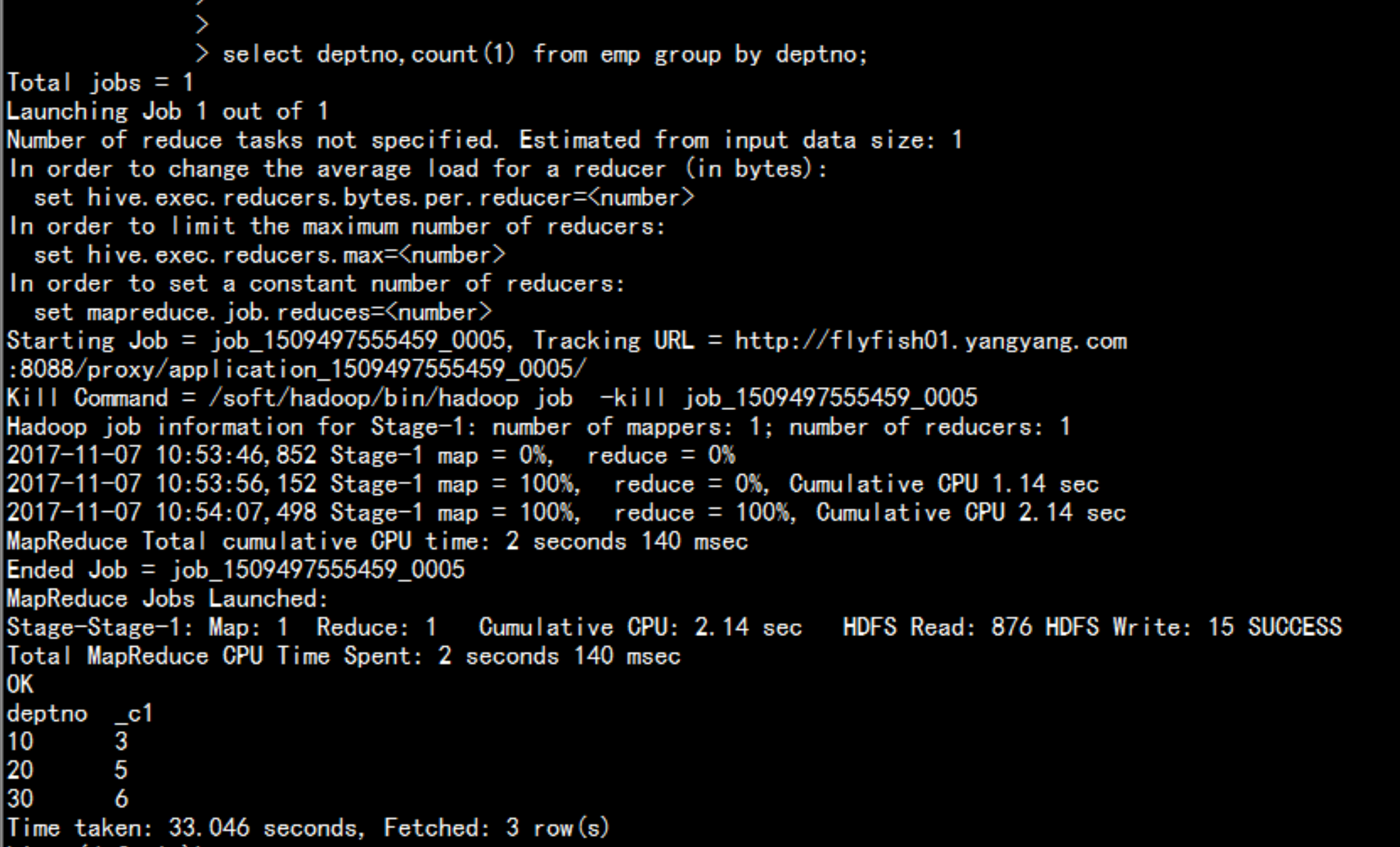

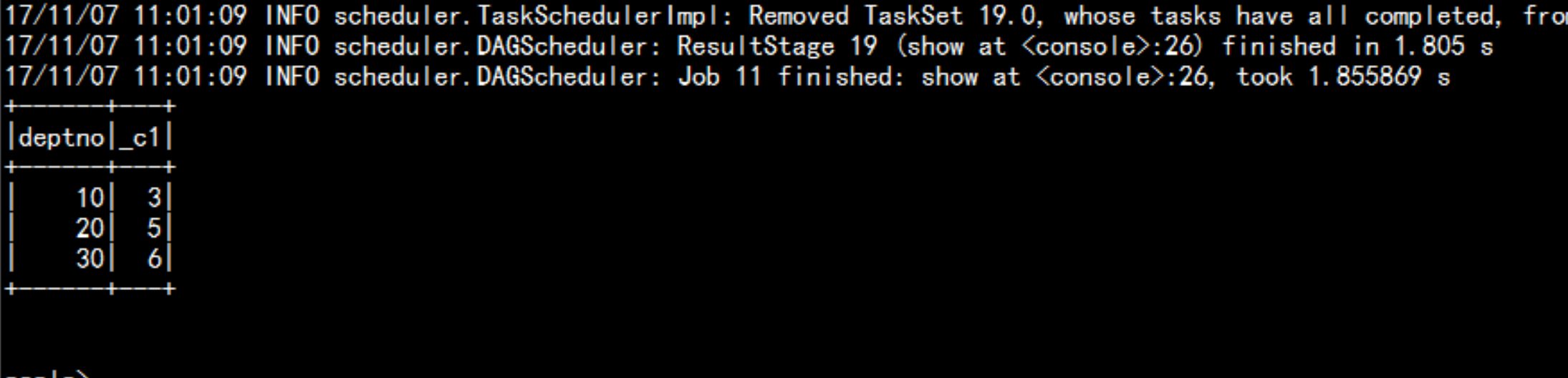
直接调用spark-sql 命令行:spark-sql --master local[2] --jars=/soft/hive/lib/mysql-connector-java-5.1.44-bin.jarshow databases;

2.5 SparkSQL 与 hive 的比较

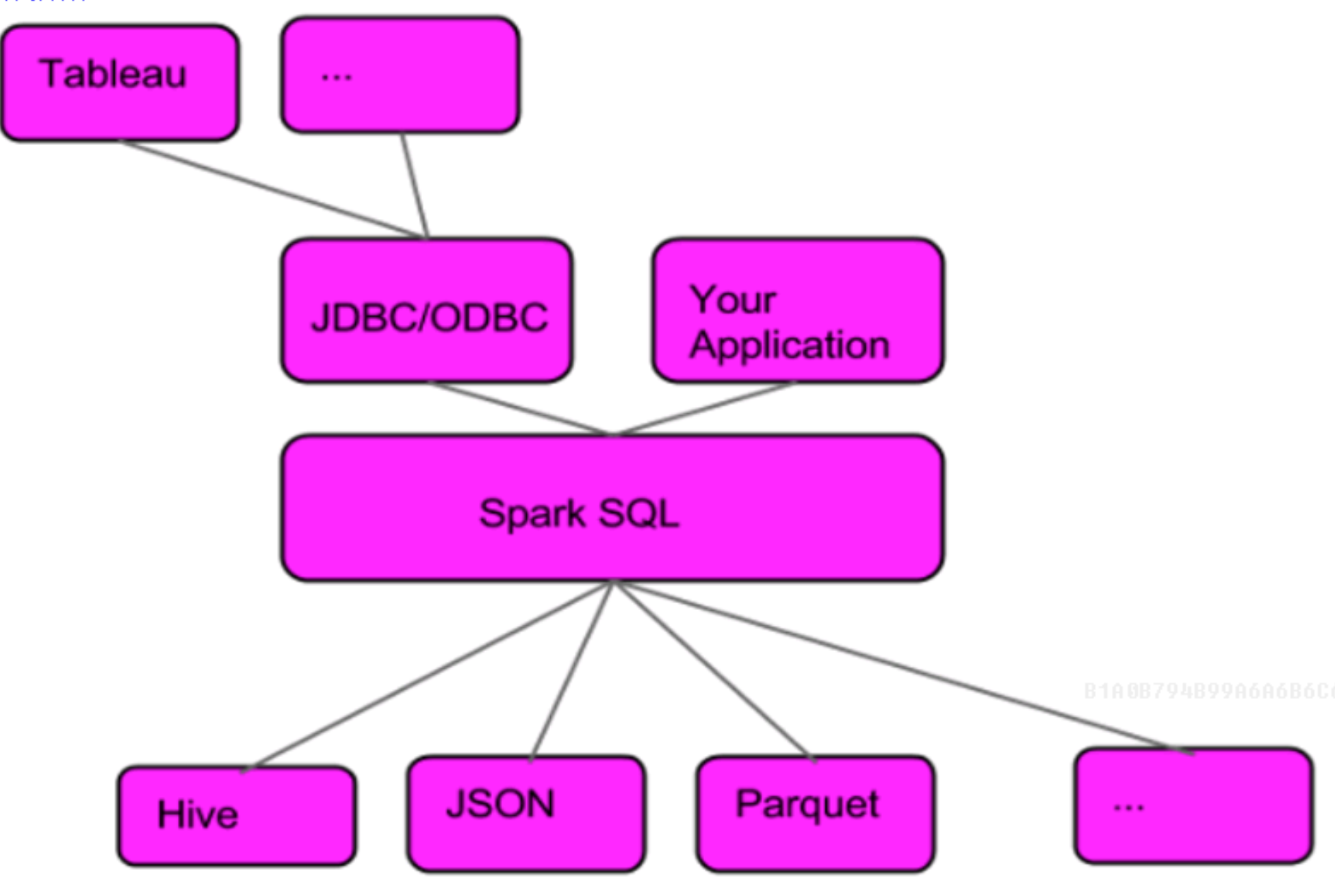
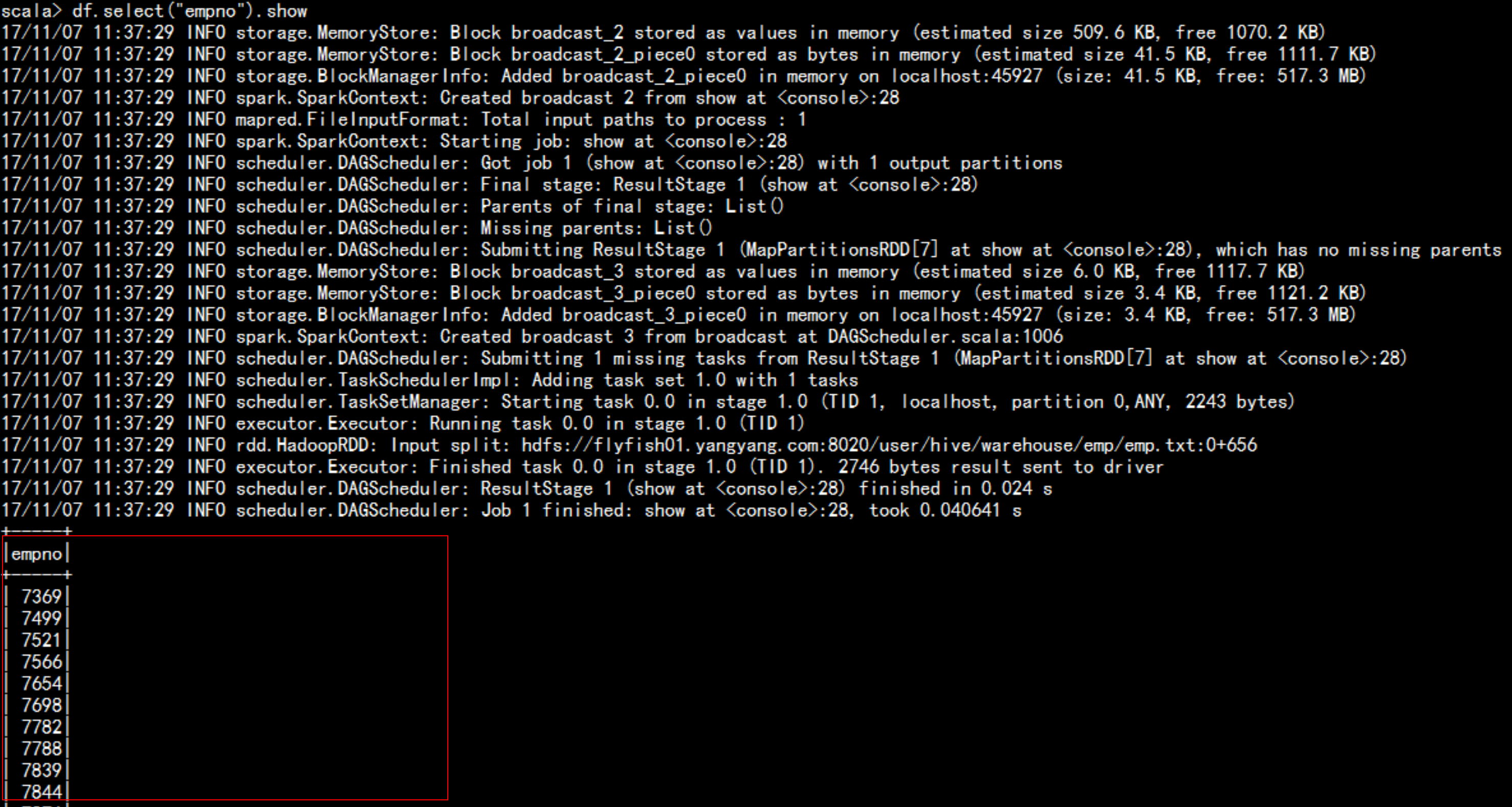
spark sql 的 DSL 语句:spark-shell --master local[2] --jars=/soft/hive/lib/mysql-connector-java-5.1.44-bin.jarval df = sqlContext.sql("select * from emp")df.select("empno").showdf.select($"empno").show

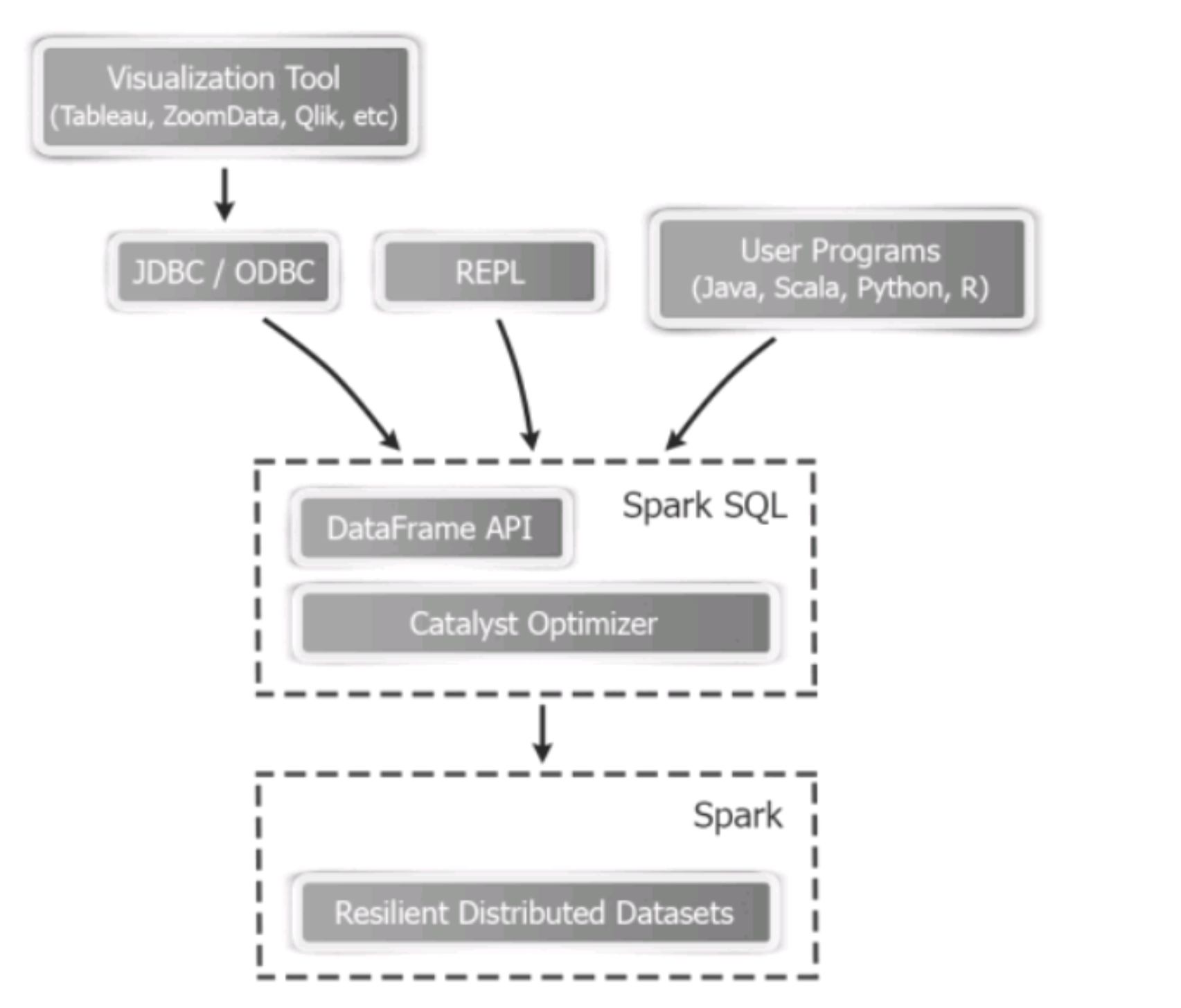
2.6 SparkSQL的架构
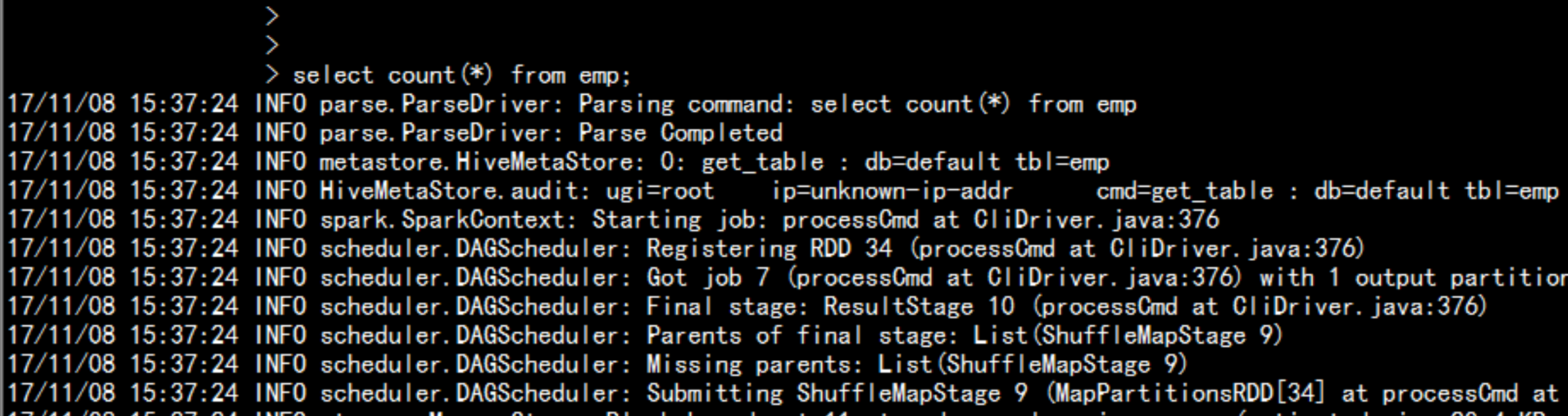
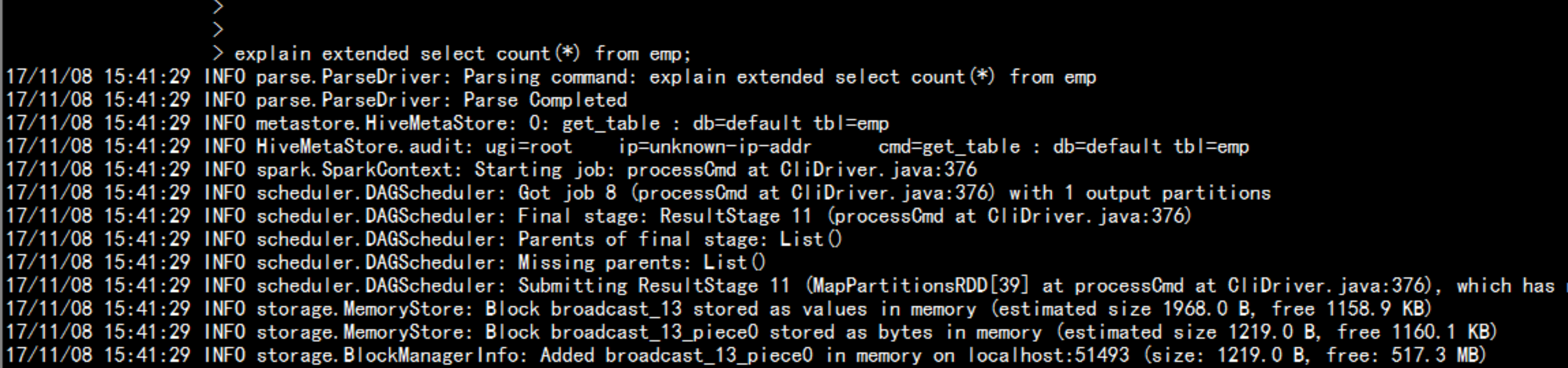
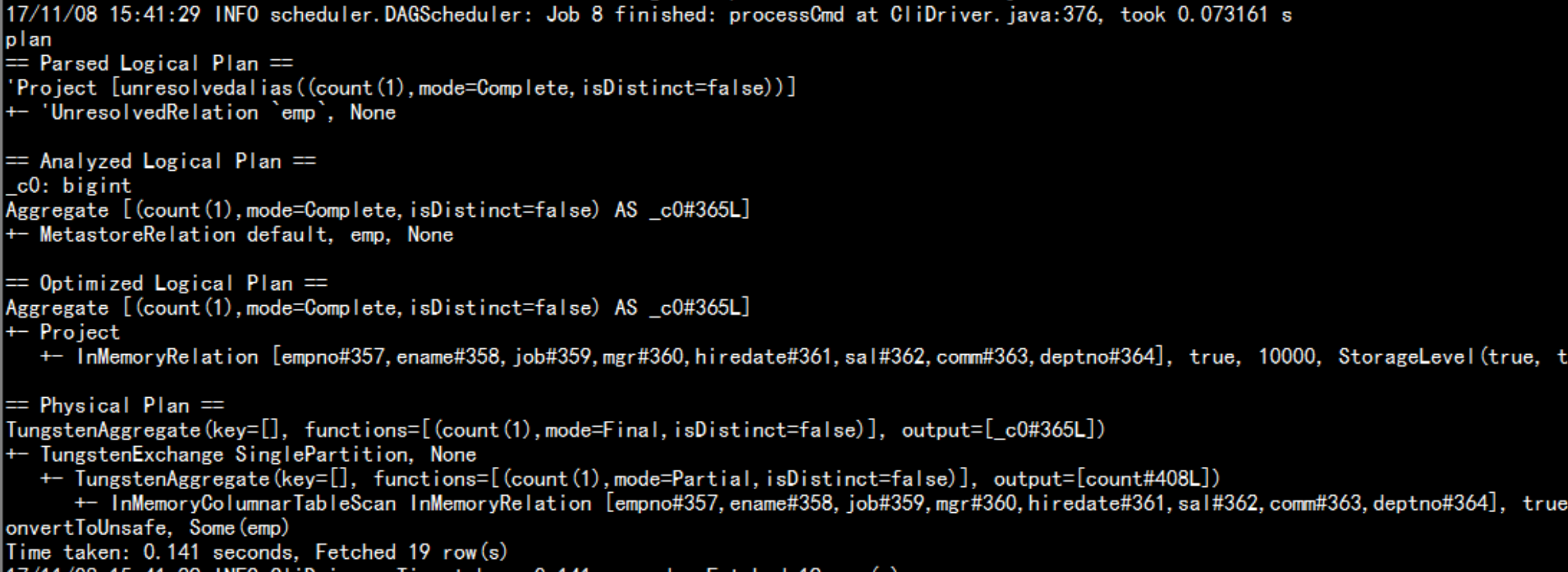
spark 的 cache 缓存spark-sql --master local[2] --jars=/soft/hive/lib/mysql-connector-java-5.1.44-bin.jarcache table empselect * from emp;执行计划:explain extended select count(*) from emp显示出执行这个SQL 语句的执行计划


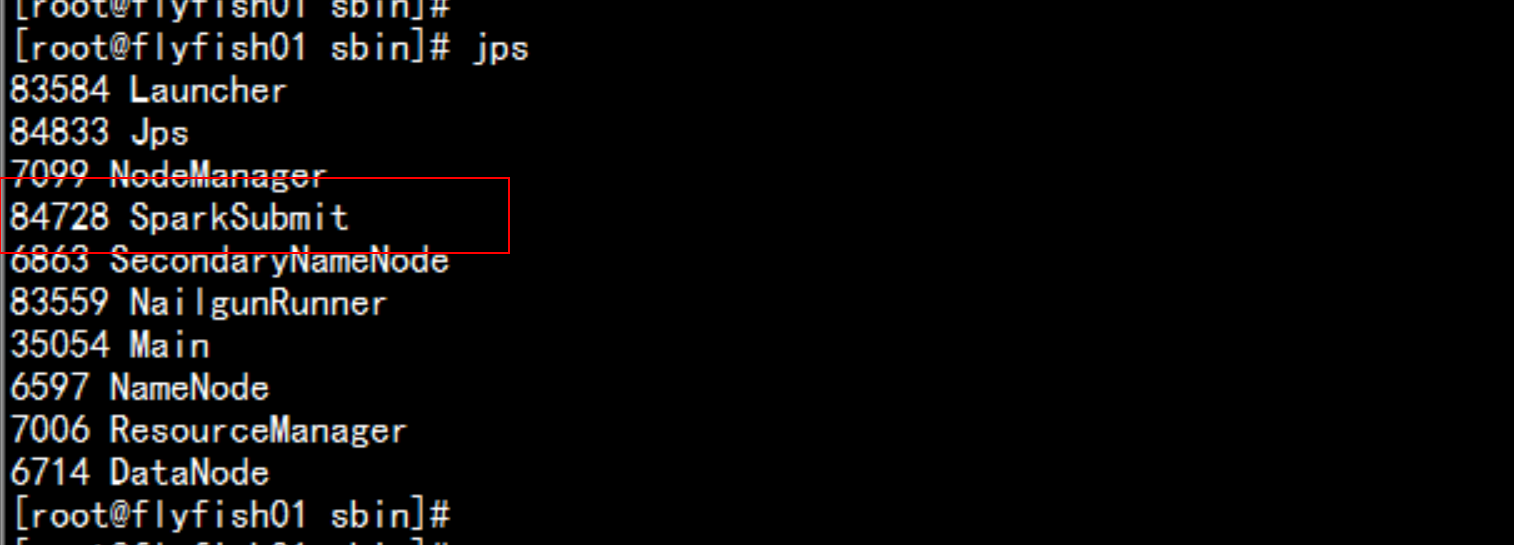
2.7 SparkSQL的ThriftServer2 配置
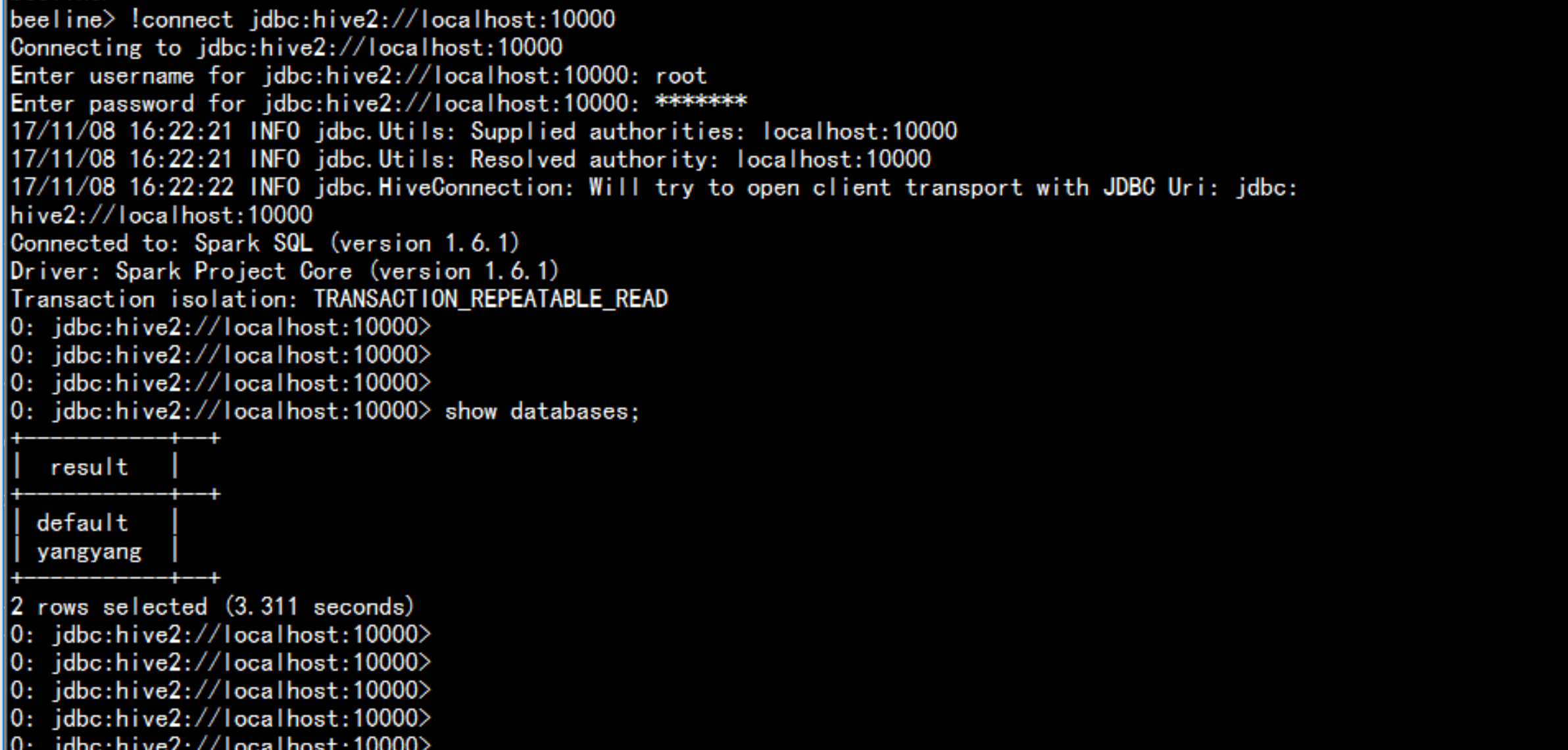
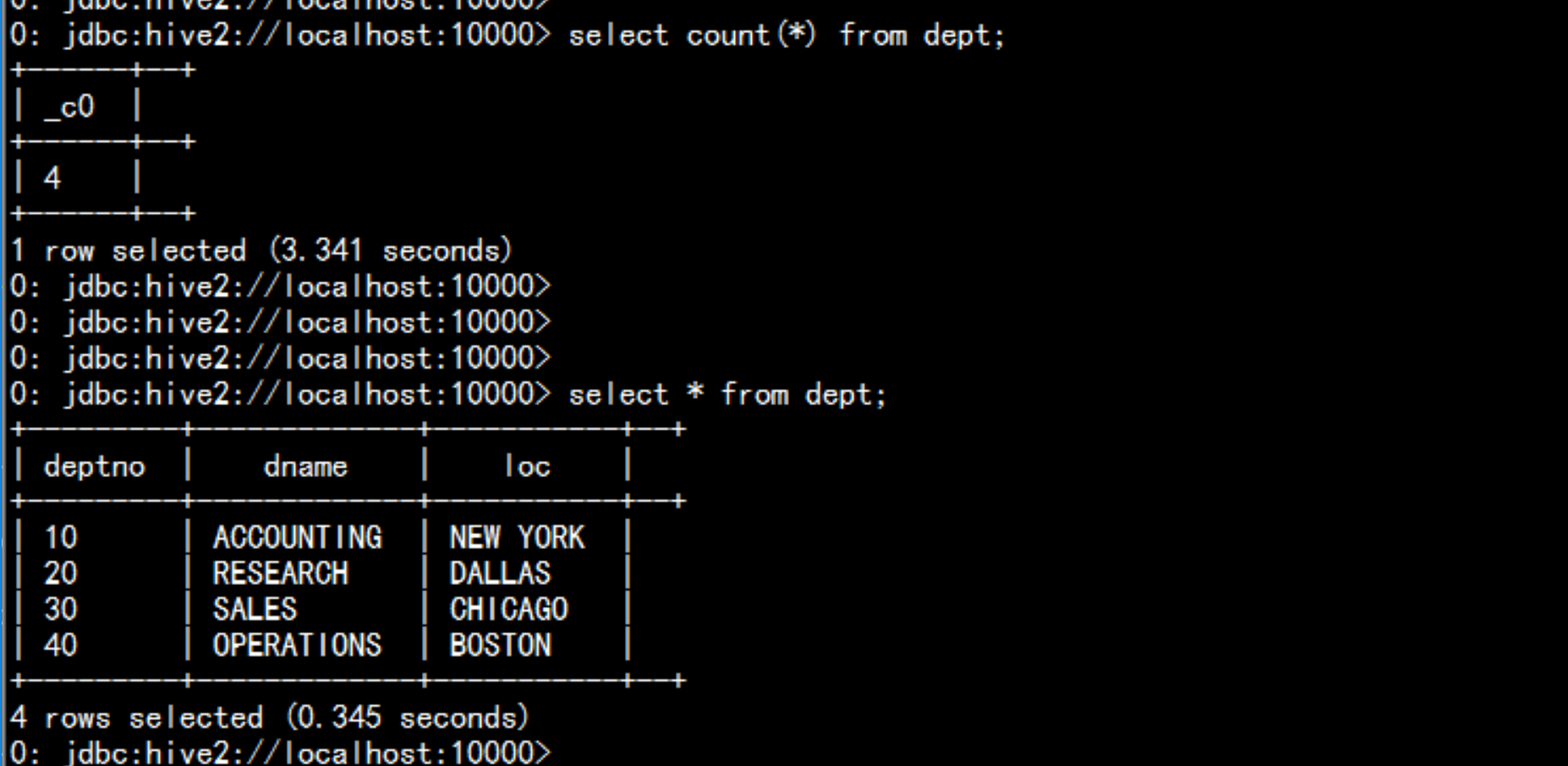
cd /soft/spark/sbin/./start-thriftserver.sh --master local[2] --jars=/soft/hive/lib/mysql-connector-java-5.1.44-bin.jarcd /soft/spark/bin./beeline!connect jdbc:hive2://localhost:10000