@zhangyy
2020-09-30T10:01:12.000000Z
字数 1646
阅读 975
大数据hadoop海量运维
大数据运维系列
一:大数据集群运维
hadoop集群节点6000+数据容量100P+日处理数据量200T+----文件数2亿+日处理条数1.5万亿+日作业数30万+


二: 大数据运维与传统运维的区别
数据量:传统数据的数据量在GB或TB级大数据的数据量在PB级集群规模:传统运维的机器规模小大数据运维的机器数据庞大,成千上万可靠性:传统运维系统可靠性取决于关键节点,数据备份恢复困难大数据运维提供海量数据3副本冗余备份,关键组件提供HA功能传统运维:传统运维转大数据运维有优势,因为有运维思维有毅力、好学、积极上进想提升自己收入的人
三:大数据运维工程师职责
规划部署:根据业务规划和未来业务演进评估集群规模、存储规模、算力需求、技术选型等大数据生态组件高可用部署,安全合规保障开发人员使用集群方式规划、权限配置管理变更:根据监控的存储指标、资源指标、性能指标或业务调整进行集群的扩容上线、退役 下线、数据均衡、数据清理根据需求变化进行权限修改、参数修改、集群访问方式修改变更方案编写、评审,变更流程梳理建设、变更记录流痕监控告警:无运维不监控,建设监控体系、打通多样化告警方式了解大数据组件关键核心指标含义,监控服务可用性、存储状态、资源状态、性 能瓶颈、操作安全深度监控,作业状态、小文件、冷数据、影响评估故障排查:对产线环境产生的服务停止卡死、集群节点失败失联、主从切换、RPC性能问题进 行排查并进行复盘对作业失败、作业卡死、数据误删除、数据丢失等问题进行排障并进行复盘调优:主机测参数调优、JVM参数调优、RPC性能调优资源队列资源调整、线程分配调整针对不同组件的运维场景与实践进行优化调整体系建设:运维流程制度建设、运维文化建设运维人员成长晋升、成就感打造工具体系的建设,打造一站式运维平台
四: 大数据初级运维工程师必备技能
基础知识:熟练Linux常用操作命令、排障命令;比如查看系统负载、CPU负载、IO负载、磁盘负载等熟悉Linux基本变更,比如用户操作、磁盘挂载、权限设置、用户资源设置等熟悉网络命令,查看网络流量、查看网络连接----脚本编写:熟悉shell脚本编程熟悉python脚本编程数据SQL编写大数据组件:熟悉常用大数据组件的体系结构、运行原理以及应用场景熟悉组件的运维场景,比如启动、停止、扩缩容、监控核心指标熟练使用大数据组件的常用运维命令
五:大数据高级运维工程师必备技能
经验:工作起码要在3年以上,经历过2~3个中等以上规模大数据平台项目的运维运维过几个常用大数据组件,并采坑无数,经历过日夜奋战引起过产线故障,趟着公司的血,从战火里走出来原理深入:对组件体系结构、运行机制有更深入的了解具有丰富的排查、调优经验,能够解决技术和业务中的复杂问题熟悉JVM,比如参数调整、垃圾回收、内存结构等有一定的源码阅读能力(不是必备)体系建设(非必备):能够带人负责某一业务的运维工作运维体系化建设
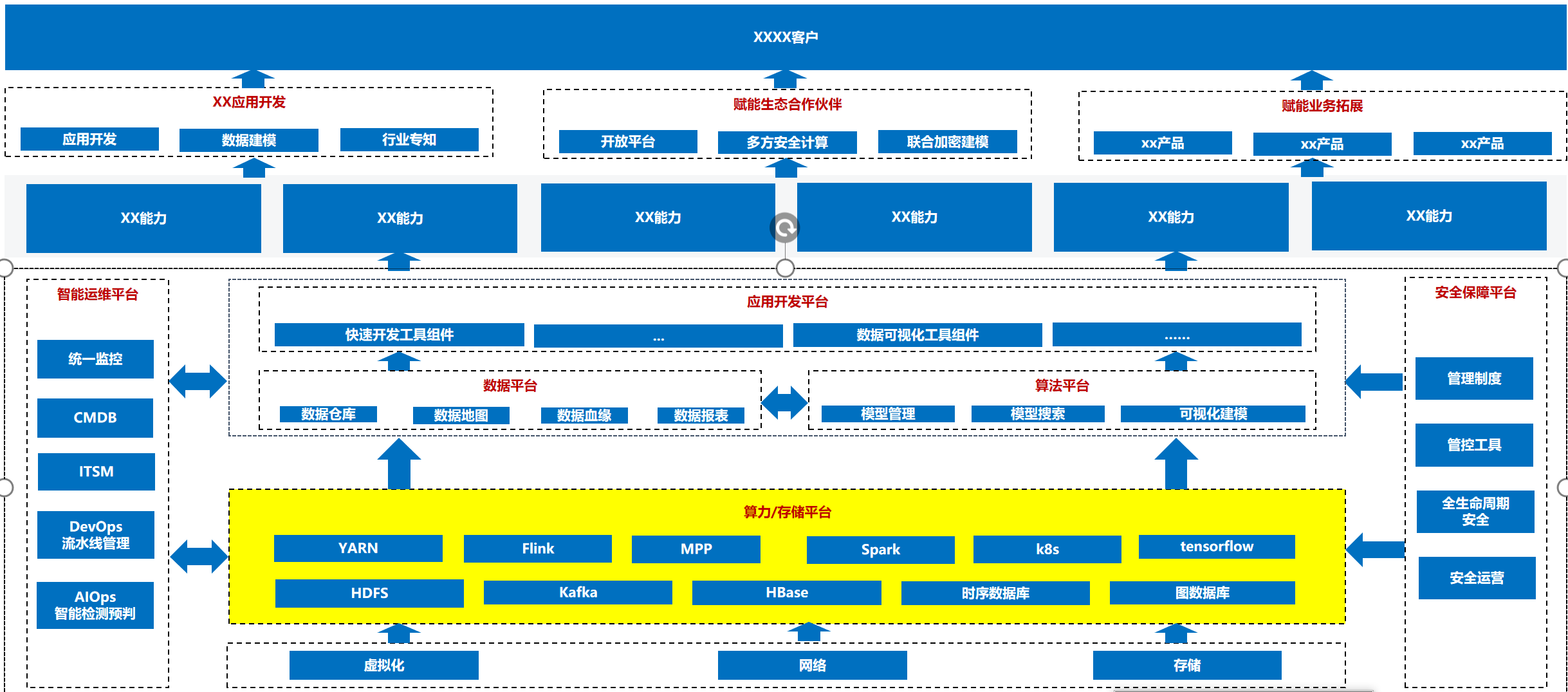
六:大数据运维的重要性-大数据平台能力底座
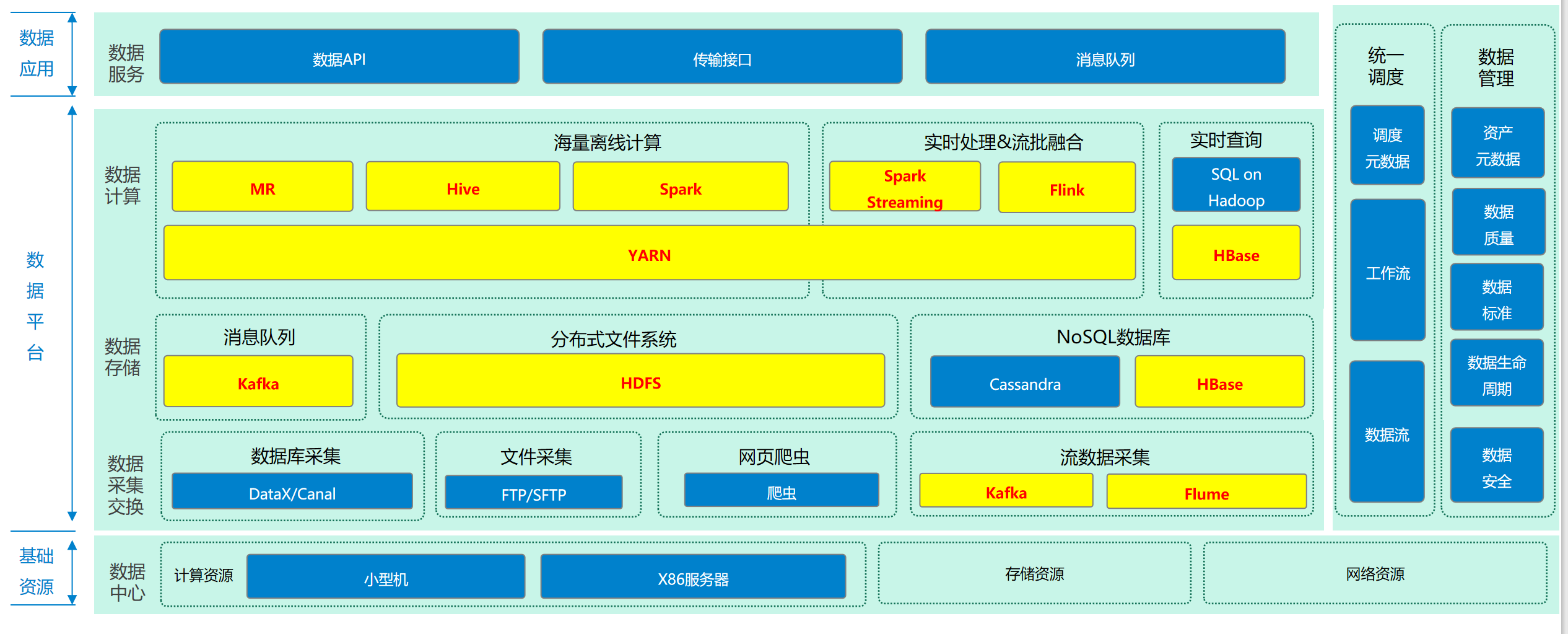
七:大数据常用组件在大数据项目中的位置
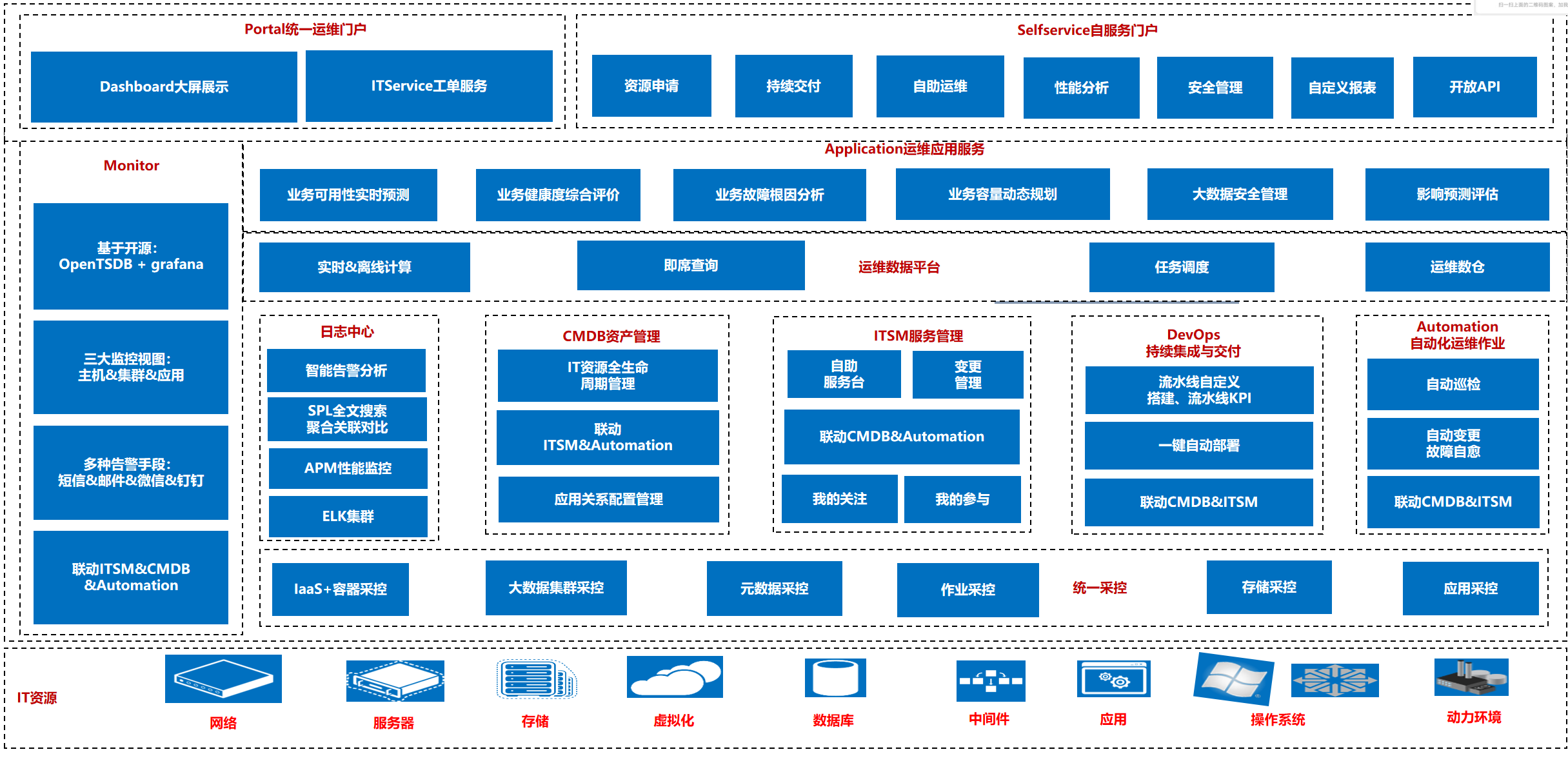
八:运维体系架构
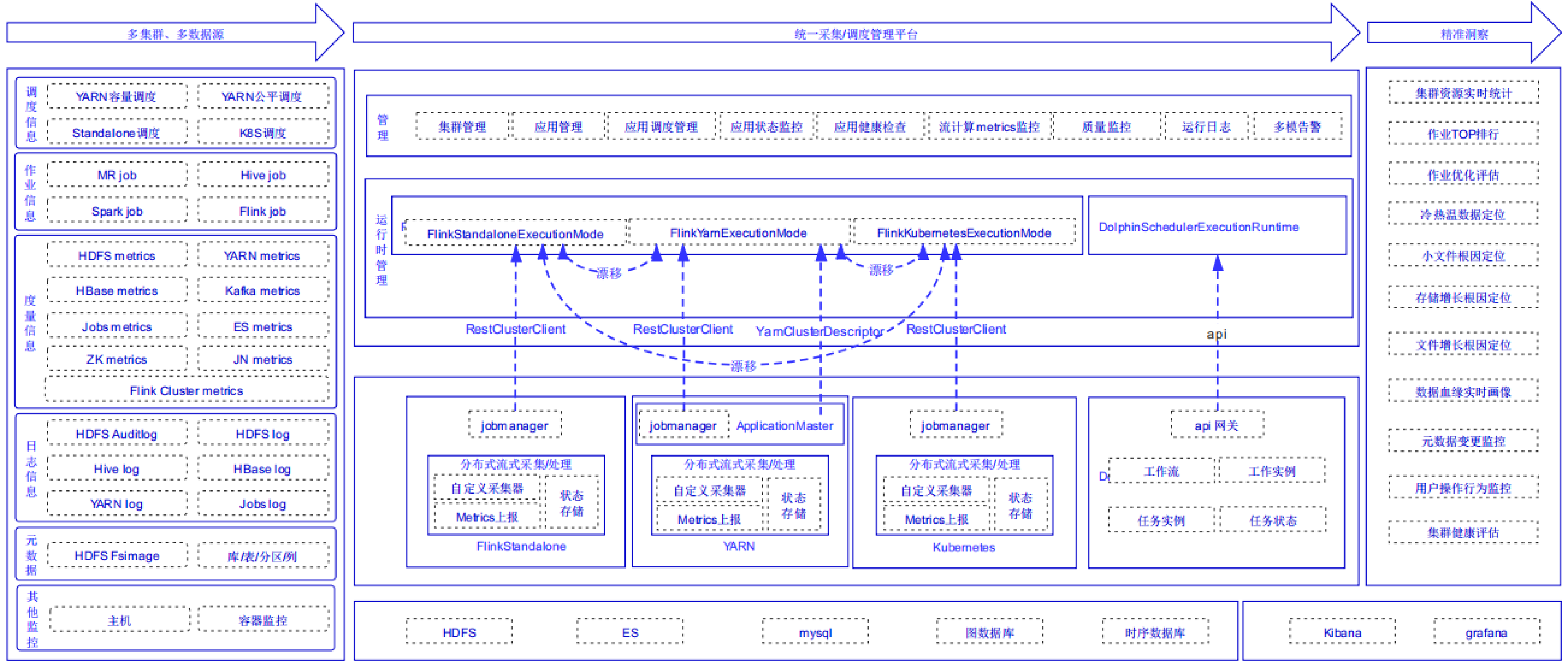
九:大数据集群深度治理
十:HDFS分布式存储系统-特性&场景&业界使用
高容错数据自动保存多个副本副本丢失后,自动恢复适合批处理移动计算而非数据数据位置暴露给计算框架适合大数据处理GB、TB、甚至PB级数据百万规模以上的文件数量10K+节点规模流式文件访问一次性写入,多次读取保证数据一致性可构建在廉价机器上通过多副本提高可靠性提供了容错和恢复机制数据访问延迟高不支持毫秒级的响应不擅长小文件存储占用NameNode大量内存寻道时间超过读取时间

