@zhangyy
2019-01-03T06:37:26.000000Z
字数 4479
阅读 547
hive 的日志处理与python的数据清洗
hive的部分
- 一:hive 清理日志处理 统计PV、UV 访问量
- 二: hive 数据python 的数据清洗
一: 日志处理
统计每个时段网站的访问量:
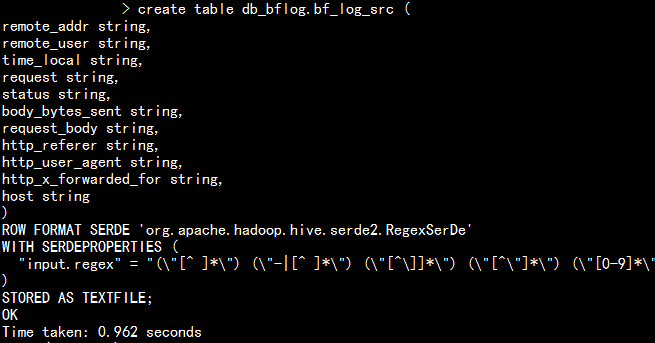
1.1 在hive 上面创建表结构:
在创建表时不能直接导入问题create table db_bflog.bf_log_src (remote_addr string,remote_user string,time_local string,request string,status string,body_bytes_sent string,request_body string,http_referer string,http_user_agent string,http_x_forwarded_for string,host string)ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'WITH SERDEPROPERTIES ("input.regex" = "(\"[^ ]*\") (\"-|[^ ]*\") (\"[^\]]*\") (\"[^\"]*\") (\"[0-9]*\") (\"[0-9]*\") (-|[^ ]*) (\"[^ ]*\") (\"[^\"]*\") (-|[^ ]*) (\"[^ ]*\")")STORED AS TEXTFILE;
1.2 加载数据到 hive 表当中:
load data local inpath '/home/hadoop/moodle.ibeifeng.access.log' into table db_bflog.bf_log_src ;

1.3 自定义UDF函数
1.3.1:udf函数去除相关引号
package org.apache.hadoop.udf;import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;/*** * New UDF classes need to inherit from this UDF class.** @author zhangyy**/public class RemoveQuotesUDF extends UDF {/*1. Implement one or more methods named "evaluate" which will be called by Hive.2."evaluate" should never be a void method. However it can return "null" if needed.*/public Text evaluate(Text str){if(null == str){return null;}// validateif(StringUtils.isBlank(str.toString())){return null ;}// lowerreturn new Text(str.toString().replaceAll("\"", ""));}public static void main(String[] args) {System.out.println(new RemoveQuotesUDF().evaluate(new Text("\"GET /course/view.php?id=27 HTTP/1.1\"")));}}
1.3.2:udf函数时间格式进行转换
package org.apache.hadoop.udf;import java.text.SimpleDateFormat;import java.util.Date;import java.util.Locale;import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;/*** * New UDF classes need to inherit from this UDF class.** @author zhangyy**/public class DateTransformUDF extends UDF {private final SimpleDateFormat inputFormat = new SimpleDateFormat("dd/MMM/yy:HH:mm:ss", Locale.ENGLISH) ;private final SimpleDateFormat outputFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss") ;/*1. Implement one or more methods named "evaluate" which will be called by Hive.2."evaluate" should never be a void method. However it can return "null" if needed.*//*** input:* 31/Aug/2015:00:04:37 +0800* output:* 2015-08-31 00:04:37*/public Text evaluate(Text str){Text output = new Text() ;if(null == str){return null;}// validateif(StringUtils.isBlank(str.toString())){return null ;}try{// 1) parseDate parseDate = inputFormat.parse(str.toString().trim());// 2) transformString outputDate = outputFormat.format(parseDate) ;// 3) setoutput.set(outputDate);}catch(Exception e){e.printStackTrace();}// lowerreturn output;}public static void main(String[] args) {System.out.println(new DateTransformUDF().evaluate(new Text("31/Aug/2015:00:04:37 +0800")));}}
将RemoveQuotesUDF 与 DateTransformUDF 到出成jar 包 放到/home/hadoop/jars 目录下面:

1.4 去hive 上面 生成 udf 函数
RemoveQuotesUDF 加载成udf函数 :add jar /home/hadoop/jars/RemoveQuotesUDF.jar ;create temporary function My_RemoveQuotes as "org.apache.hadoop.udf.RemoveQuotesUDF" ;DateTransformUDF 加载成udf 函数:add jar /home/hadoop/jars/DateTransformUDF.jar ;create temporary function My_DateTransform as "org.apache.hadoop.udf.DateTransformUDF" ;




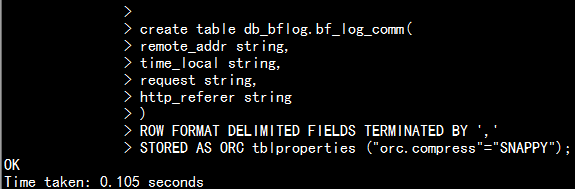
1.5 创建生成所要要求表:
create table db_bflog.bf_log_comm(remote_addr string,time_local string,request string,http_referer string)ROW FORMAT DELIMITED FIELDS TERMINATED BY ','STORED AS ORC tblproperties ("orc.compress"="SNAPPY");
从原有表中提取 相关的数据处理:
insert into table db_bflog.bf_log_comm select remote_addr, time_local, request, http_referer from db_bflog.bf_log_src ;
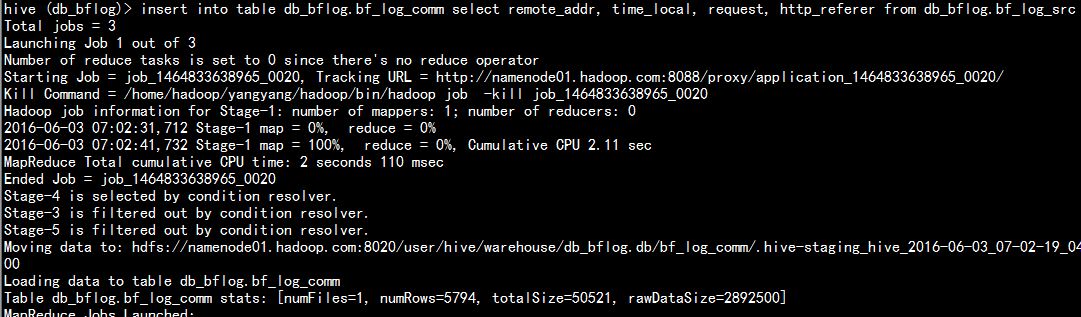
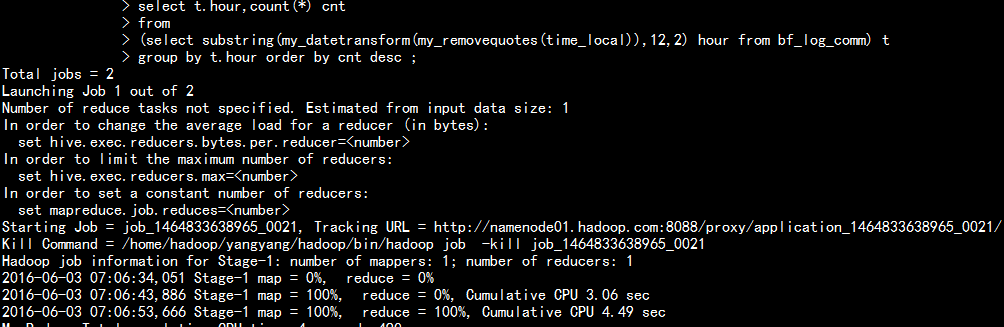
执行sql 统计每小时的pv 访问量:
select t.hour,count(*) cntfrom(select substring(my_datetransform(my_removequotes(time_local)),12,2) hour from bf_log_comm) tgroup by t.hour order by cnt desc ;
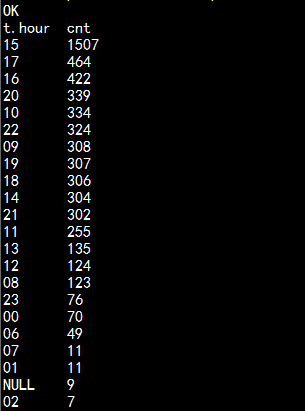
二: hive 数据python 的数据清洗
统计国外一家影院的每周看电影的人数测试数据下载地址:wget http://files.grouplens.org/datasets/movielens/ml-100k.zipunzip ml-100k.zip
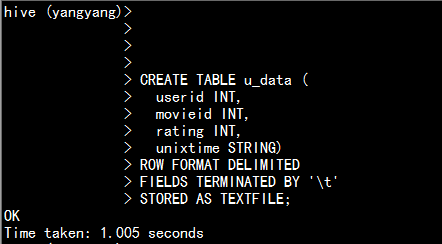
2.1 创建hive 的数据表
CREATE TABLE u_data (userid INT,movieid INT,rating INT,unixtime STRING)ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\t'STORED AS TEXTFILE;
2.2 加载数据:
LOAD DATA LOCAL INPATH '/home/hadoop/ml-100k/u.data'OVERWRITE INTO TABLE u_data;

2.3 创建weekday_mapper.py 脚本
import sysimport datetimefor line in sys.stdin:line = line.strip()userid, movieid, rating, unixtime = line.split('\t')weekday = datetime.datetime.fromtimestamp(float(unixtime)).isoweekday()print '\t'.join([userid, movieid, rating, str(weekday)])
2.4 创建临时hive 表 用于提取数据:
CREATE TABLE u_data_new (userid INT,movieid INT,rating INT,weekday INT)ROW FORMAT DELIMITEDFIELDS TERMINATED BY '\t';增加python 脚本到hiveadd FILE /home/hadoop/weekday_mapper.py;
2.5 从旧表中数据提取
INSERT OVERWRITE TABLE u_data_newSELECTTRANSFORM (userid, movieid, rating, unixtime)USING 'python weekday_mapper.py'AS (userid, movieid, rating, weekday)FROM u_data;
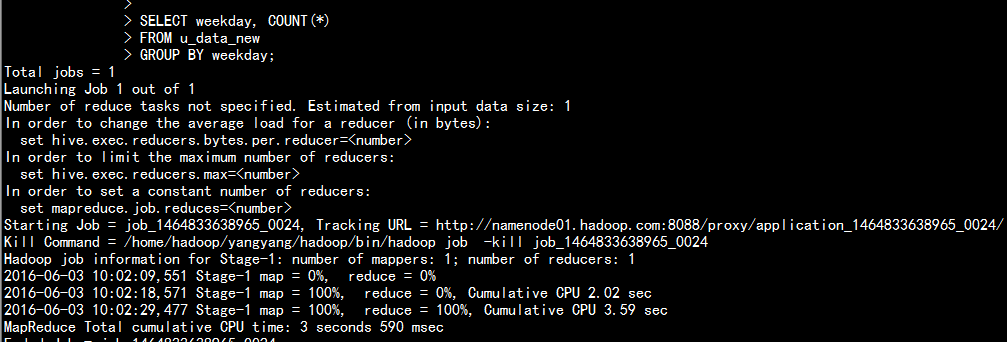
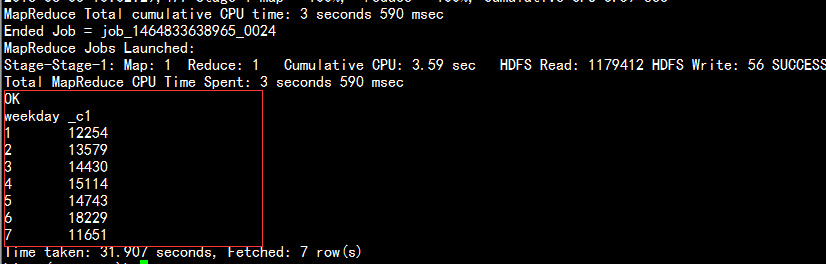
2.6 查找所需要的数据:
SELECT weekday, COUNT(*)FROM u_data_newGROUP BY weekday;