@zhangyy
2018-06-11T05:32:49.000000Z
字数 1798
阅读 745
在CDH5.14.2 中启用kudu的配置
大数据平台构建
- 一: 系统平台介绍
- 二: 安装kudu的集成
一: 系统平台介绍
1.1. 关于kudu的介绍
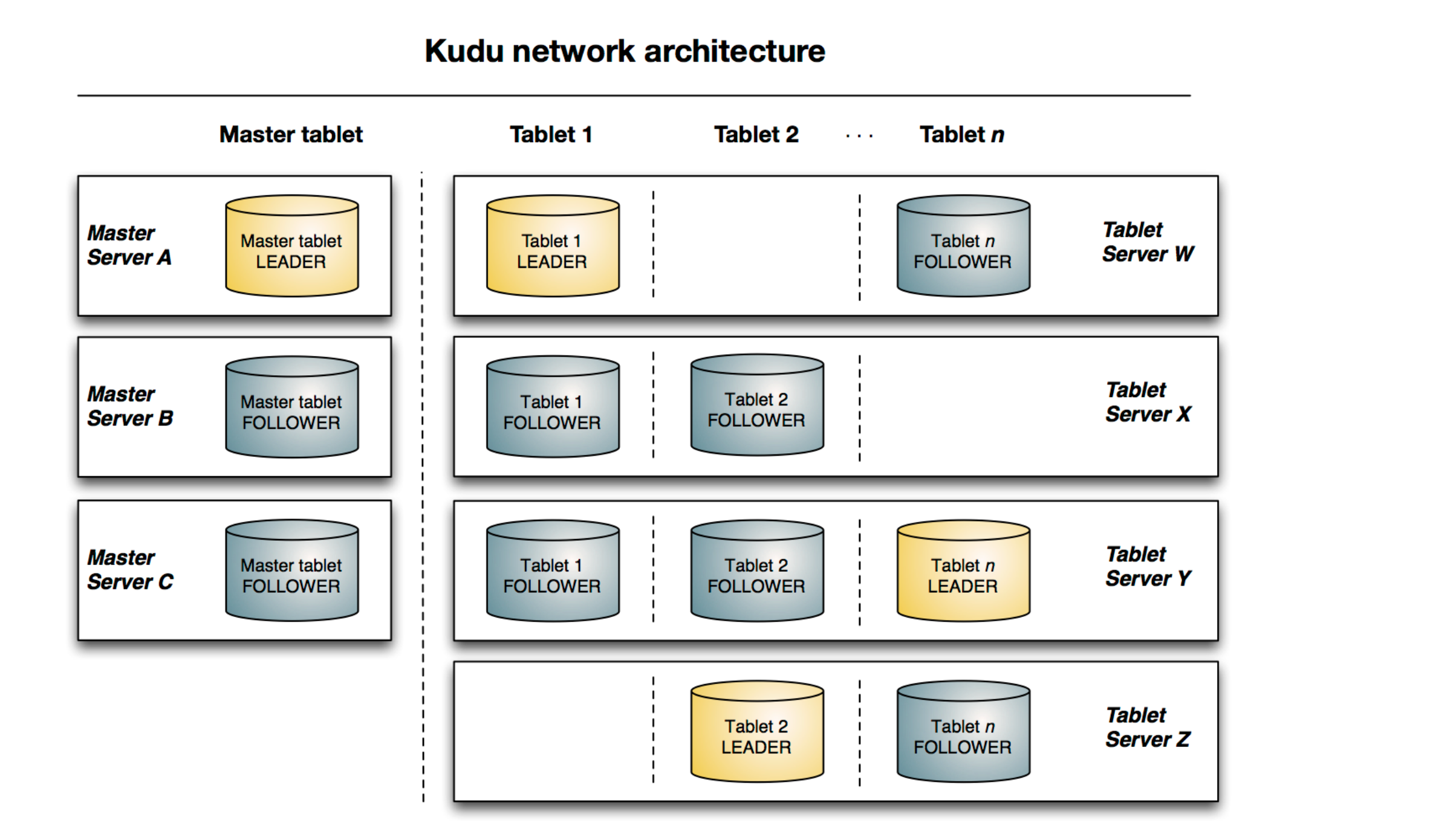
Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的新成员之一(incubating),专门为了对快速变化的数据进行快速的分析,填补了以往Hadoop存储层的空缺。Hadoop生态系统有很多组件,每一个组件有不同的功能。在现实场景中,用户往往需要同时部署很多Hadoop工具来解决同一个问题,这种架构称为混合架构 (hybrid architecture)。比如,用户需要利用Hbase的快速插入、快读random access的特性来导入数据,HBase也允许用户对数据进行修改,HBase对于大量小规模查询也非常迅速。同时,用户使用HDFS/Parquet + Impala/Hive来对超大的数据集进行查询分析,对于这类场景, Parquet这种列式存储文件格式具有极大的优势。很多公司都成功地部署了HDFS/Parquet + HBase混合架构,然而这种架构较为复杂,而且在维护上也十分困难。首先,用户用Flume或Kafka等数据Ingest工具将数据导入HBase,用户可能在HBase上对数据做一些修改。然后每隔一段时间(每天或每周)将数据从Hbase中导入到Parquet文件,作为一个新的partition放在HDFS上,最后使用Impala等计算引擎进行查询,生成最终报表。
二: 安装kudu的集成
2.1 kudu 准备与下载
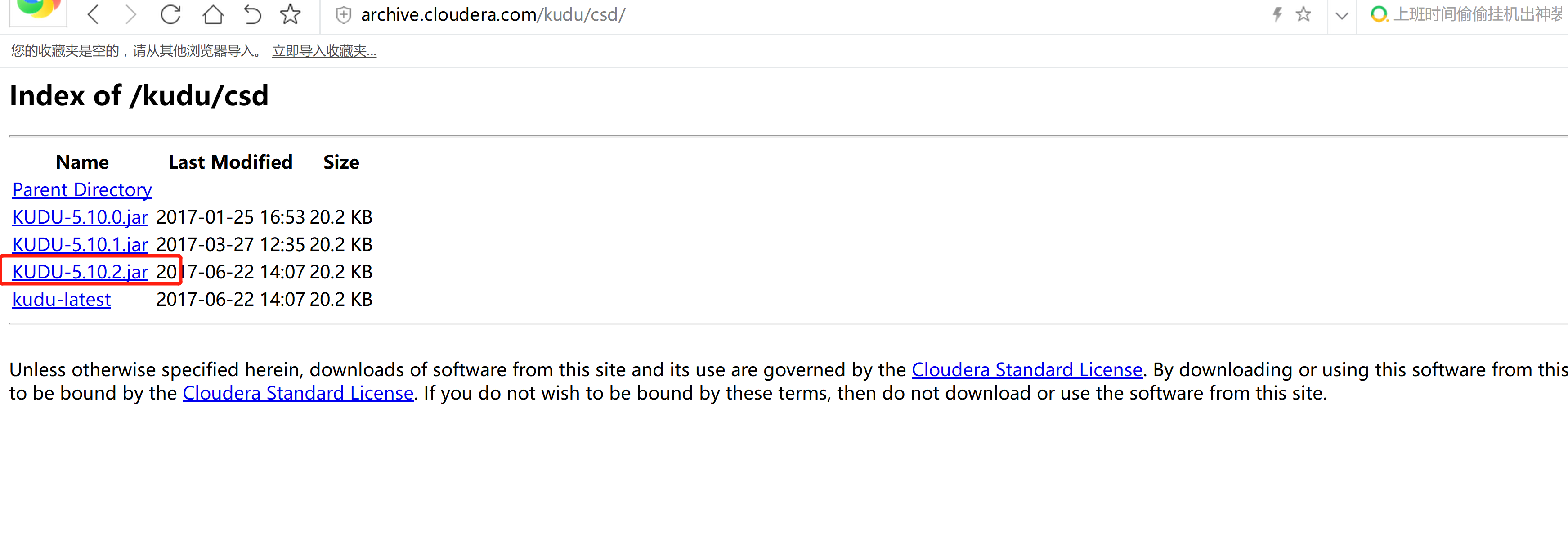
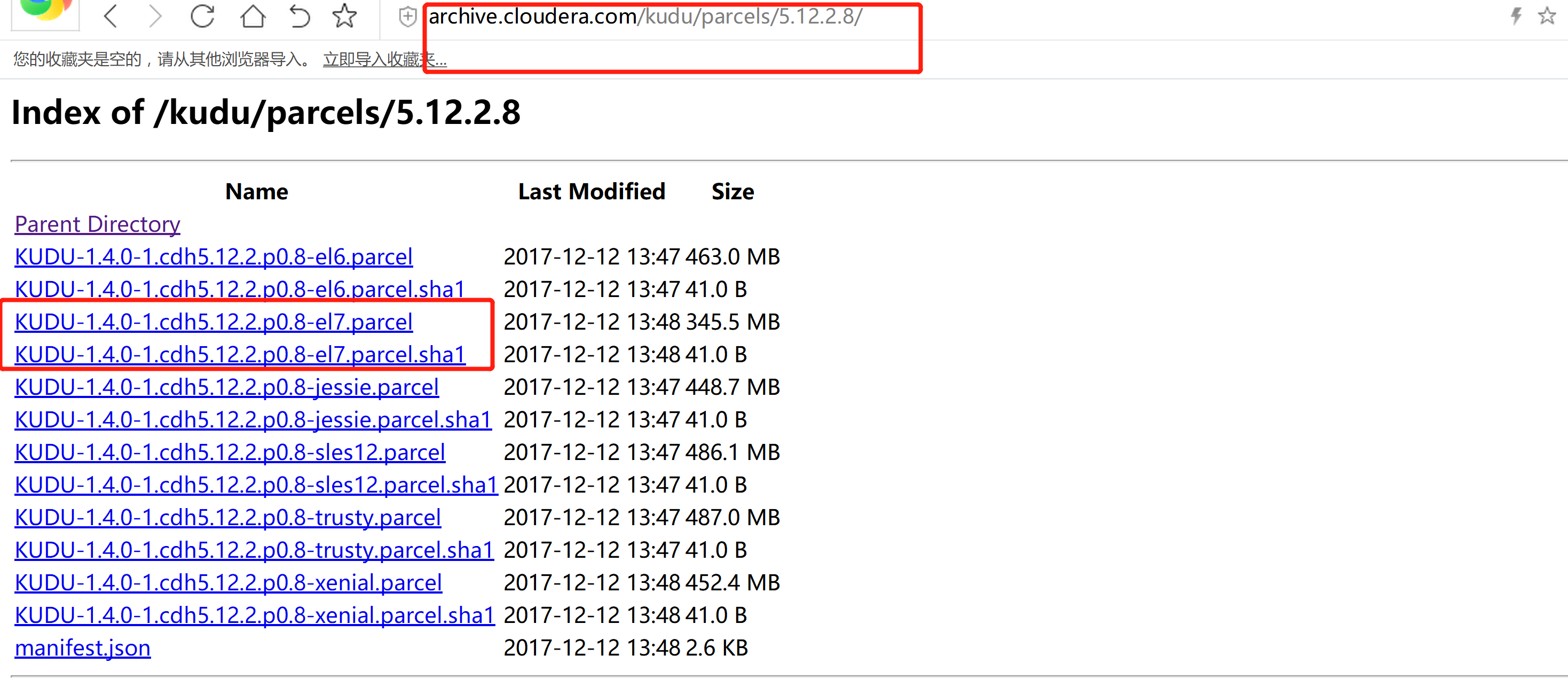
CDH从5.10开始,打包集成Kudu1.2,并且Cloudera正式提供支持。这个版本开始Kudu的安装较之前要简单很多,省去了Impala_Kudu,安装完Kudu,Impala即可直接操作Kudu。CSD 包下载软件下载:http://archive.cloudera.com/kudu/csd/KUDU-5.10.2.jarparcel 包:http://archive.cloudera.com/kudu/parcels/5.12.2.8/KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcelKUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel.sha1manifest.json
2.2 开始安装kudu
mv KUDU-5.10.2.jar /opt/cloudera/csd/chown cloudera-scm:cloudera-scm /opt/cloudera/csd/KUDU-5.10.2.jarcd /opt/cloudera/csd/chmod 644 KUDU-5.10.2.jar
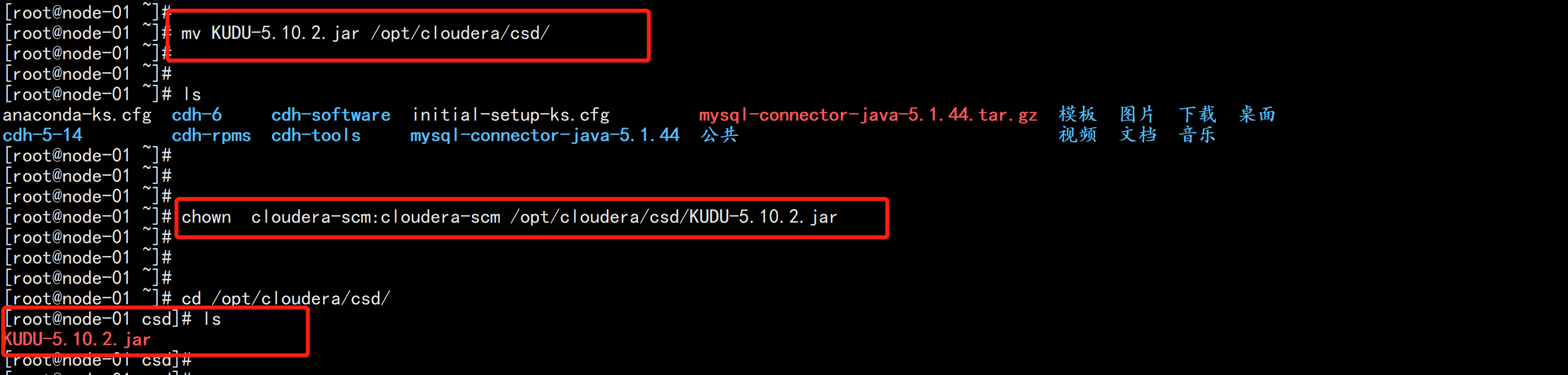

配置httpd-serveryum install -y httpd*service httpd startchkconfig httpd onmv KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel* /var/www/html/kudumv manifest.json /var/www/html/kudu/cd /var/www/html/kudu/mv KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel.sha1 KUDU-1.4.0-1.cdh5.12.2.p0.8-el7.parcel.sha
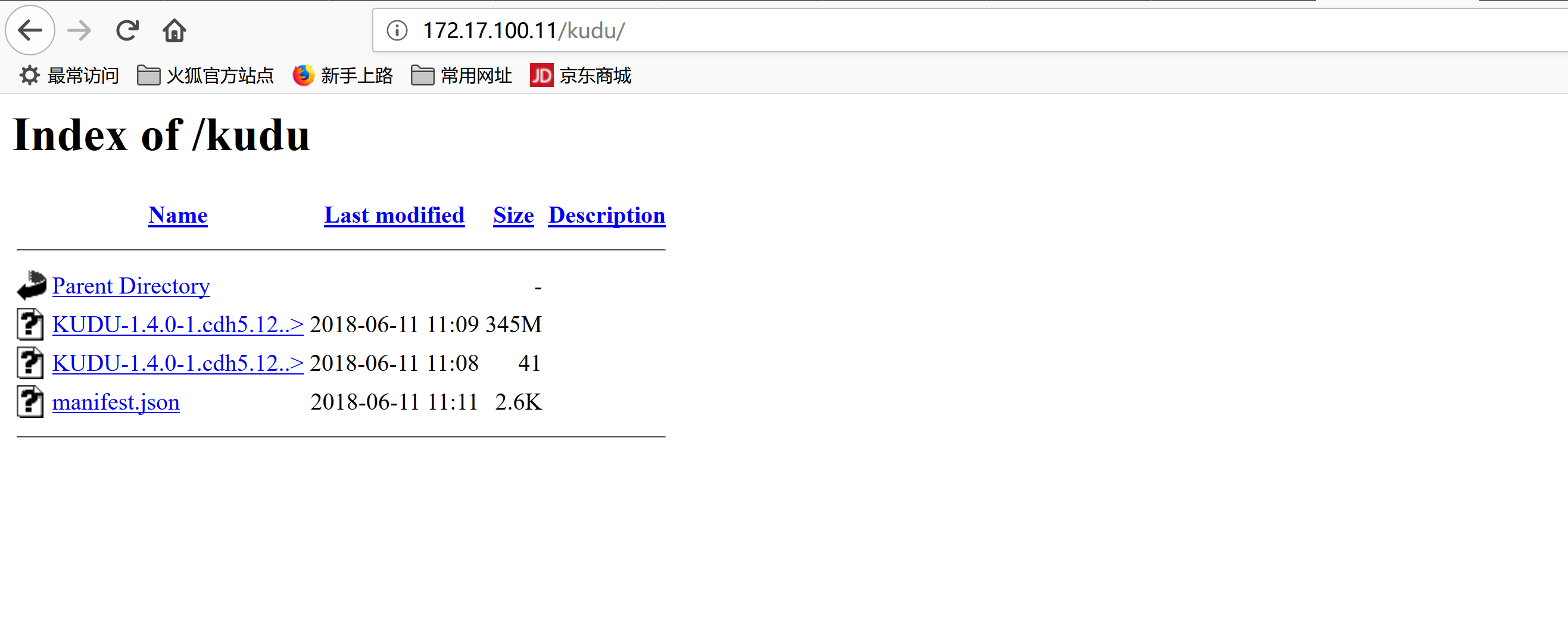
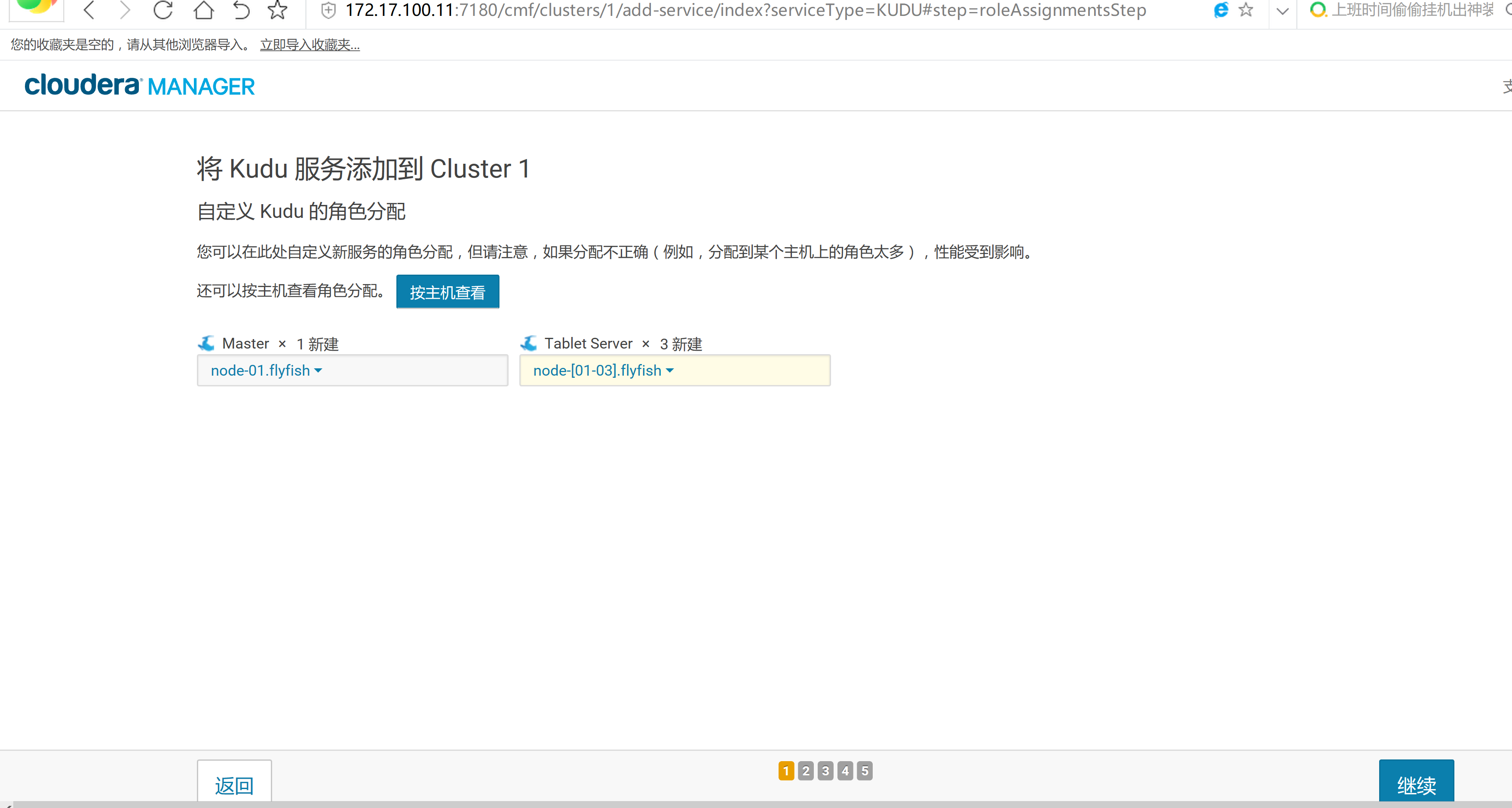
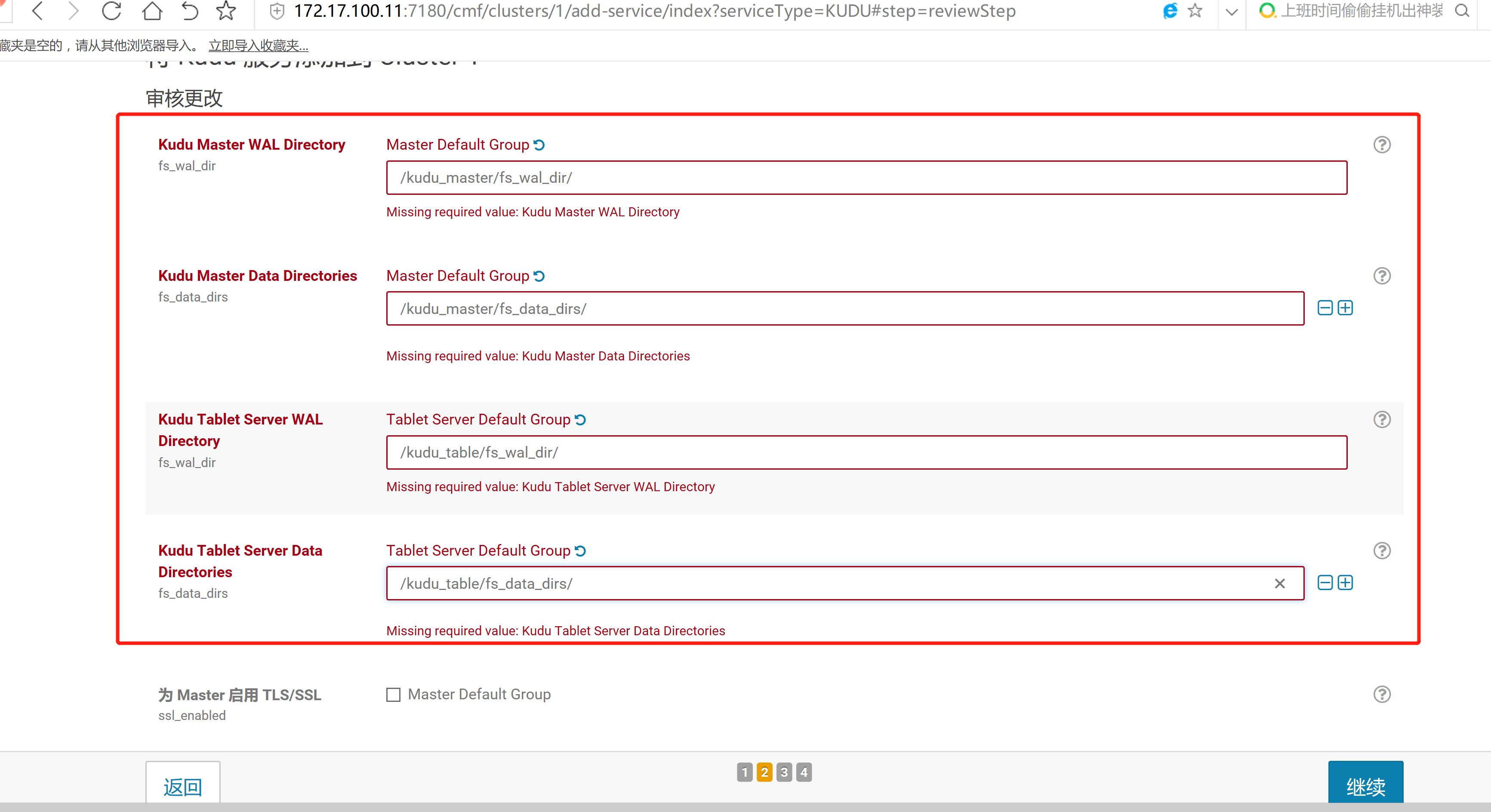
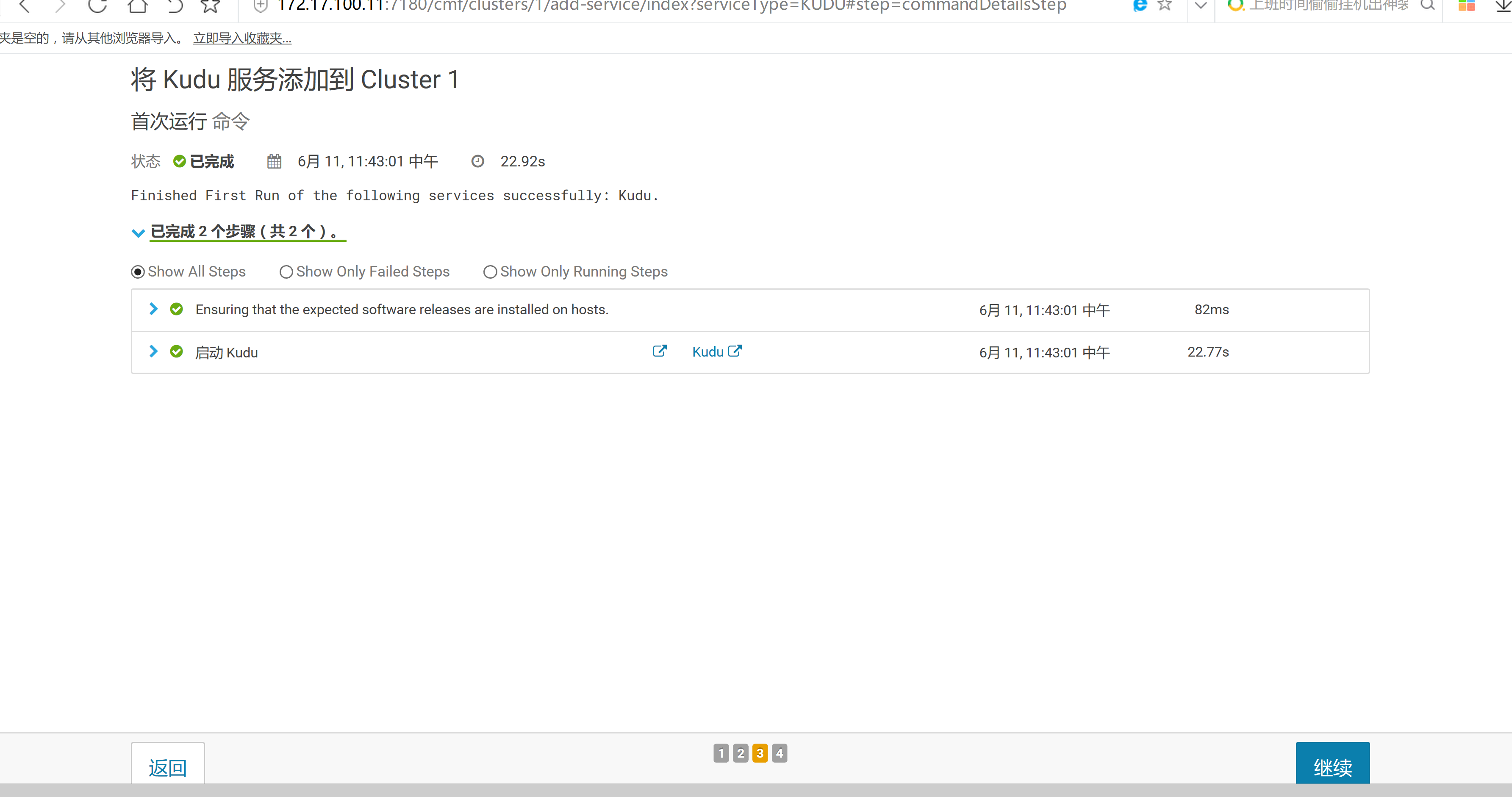
2.3 通过CM界面配置Kudu的Parcel地址,并下载,分发,激活Kudu
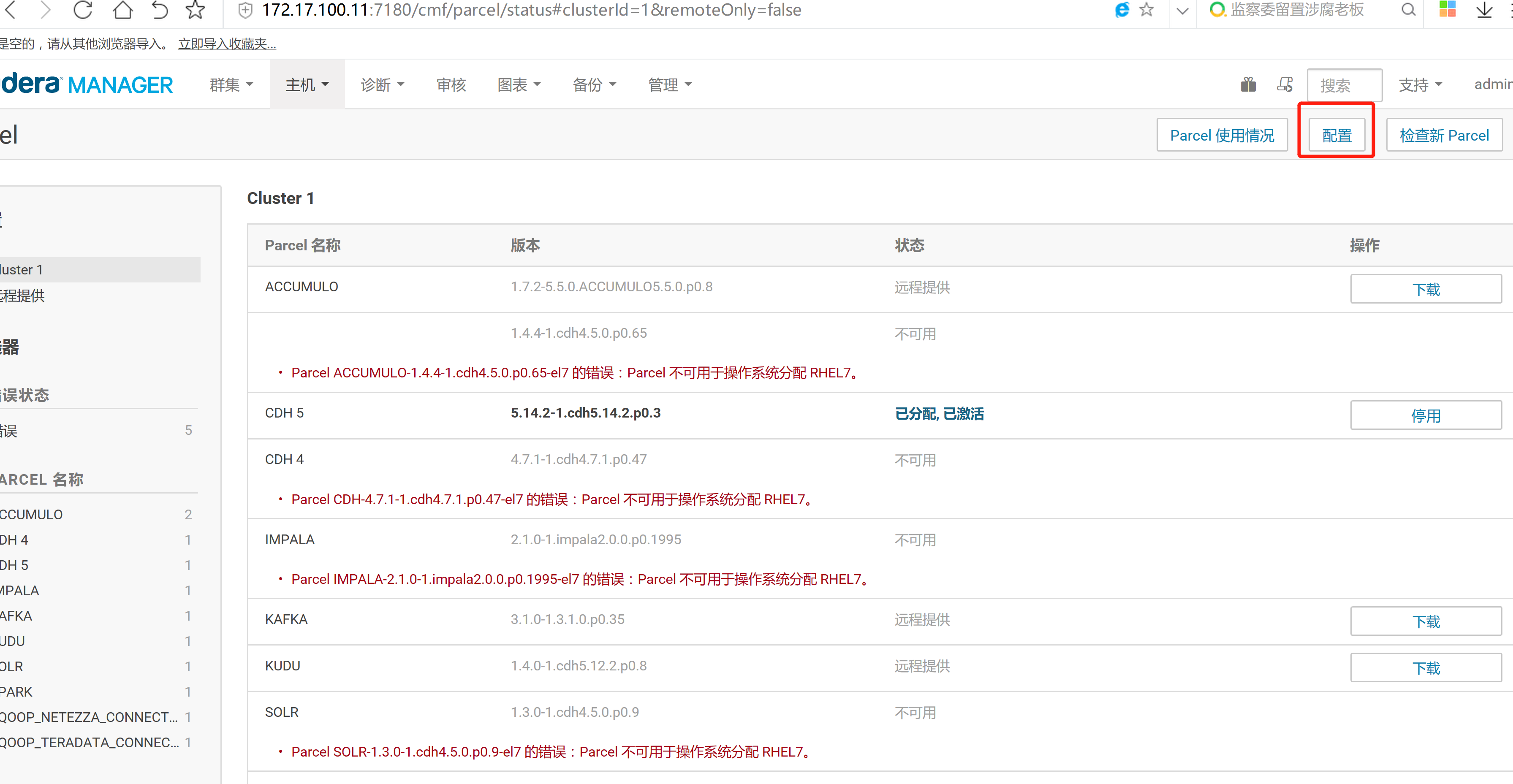
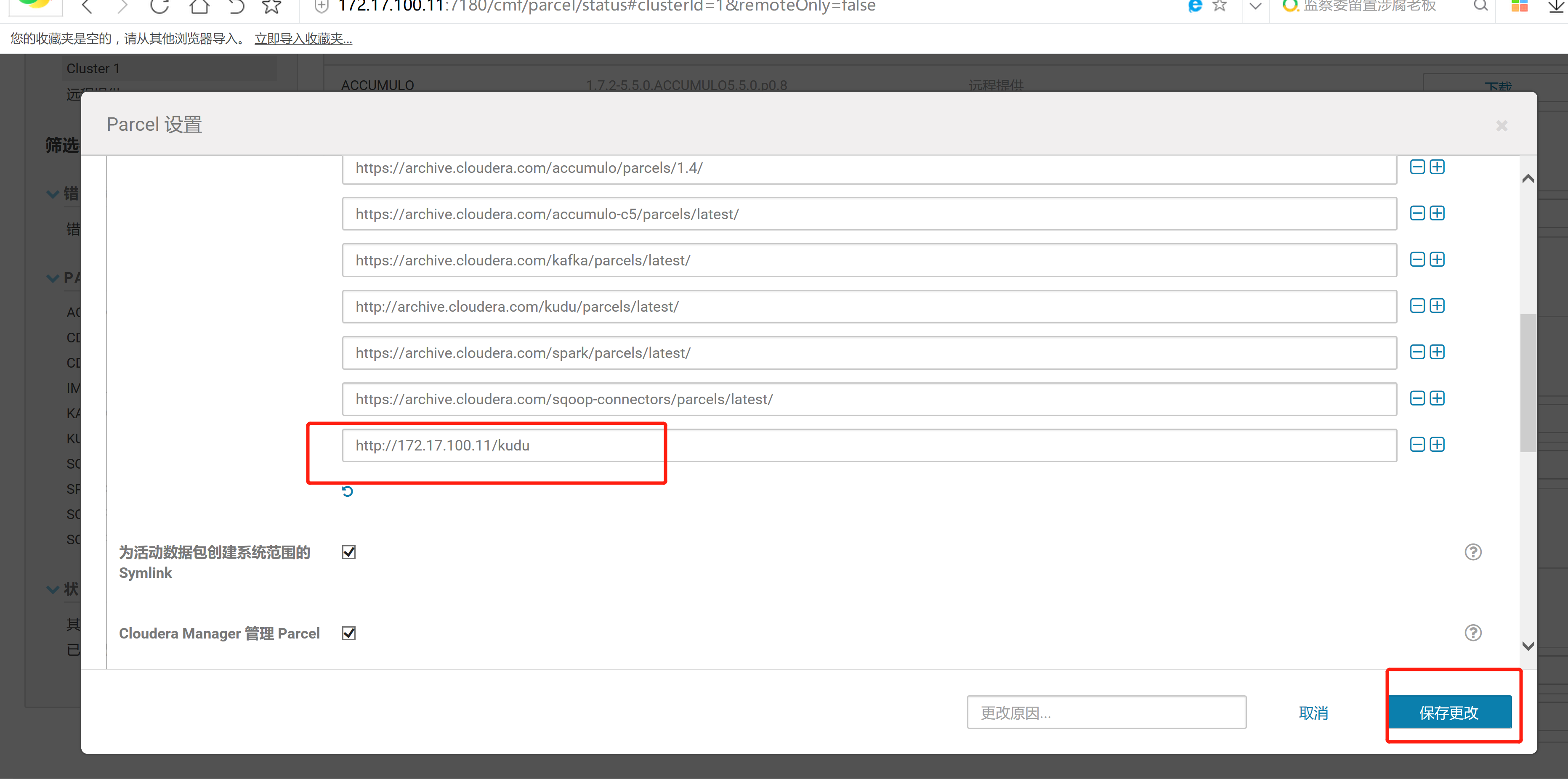
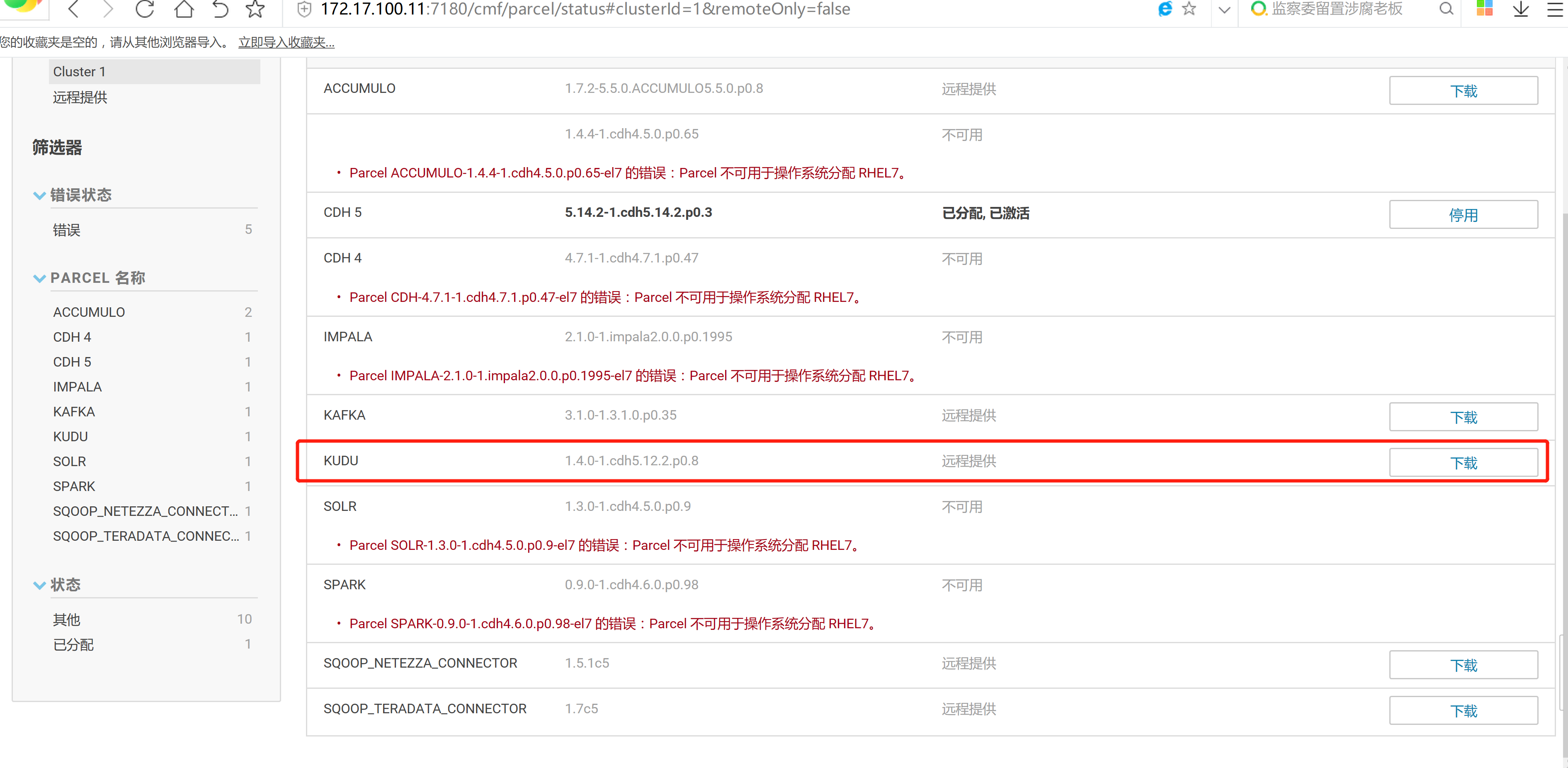
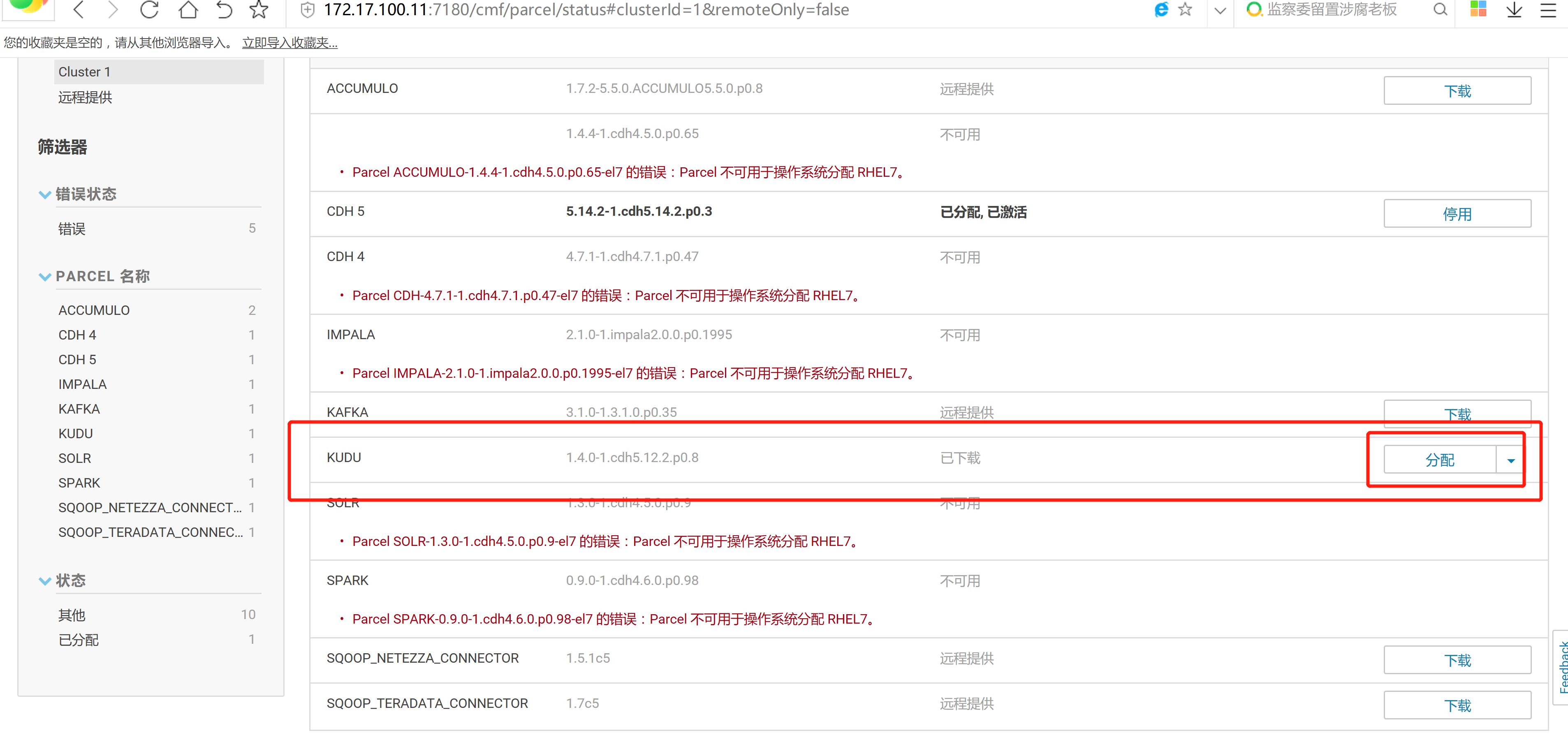

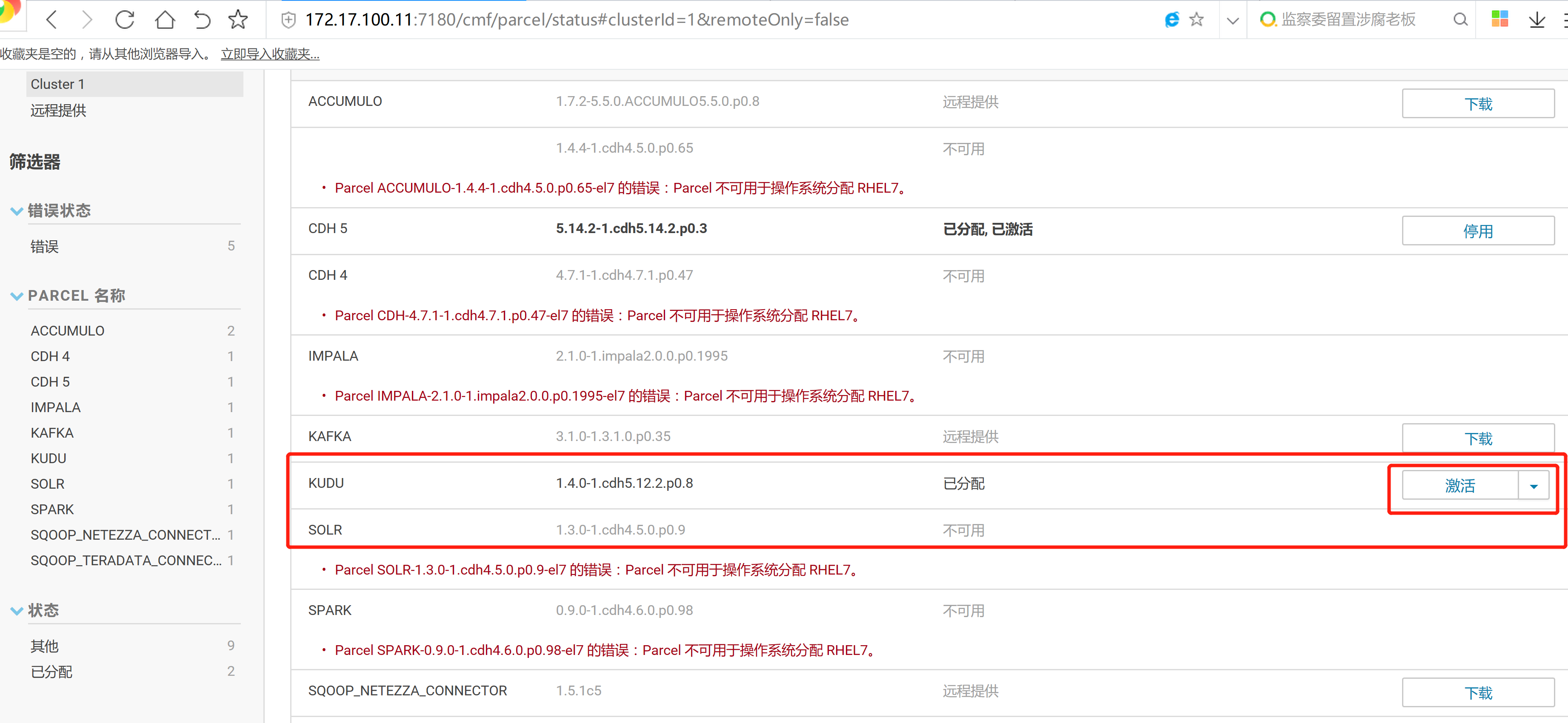
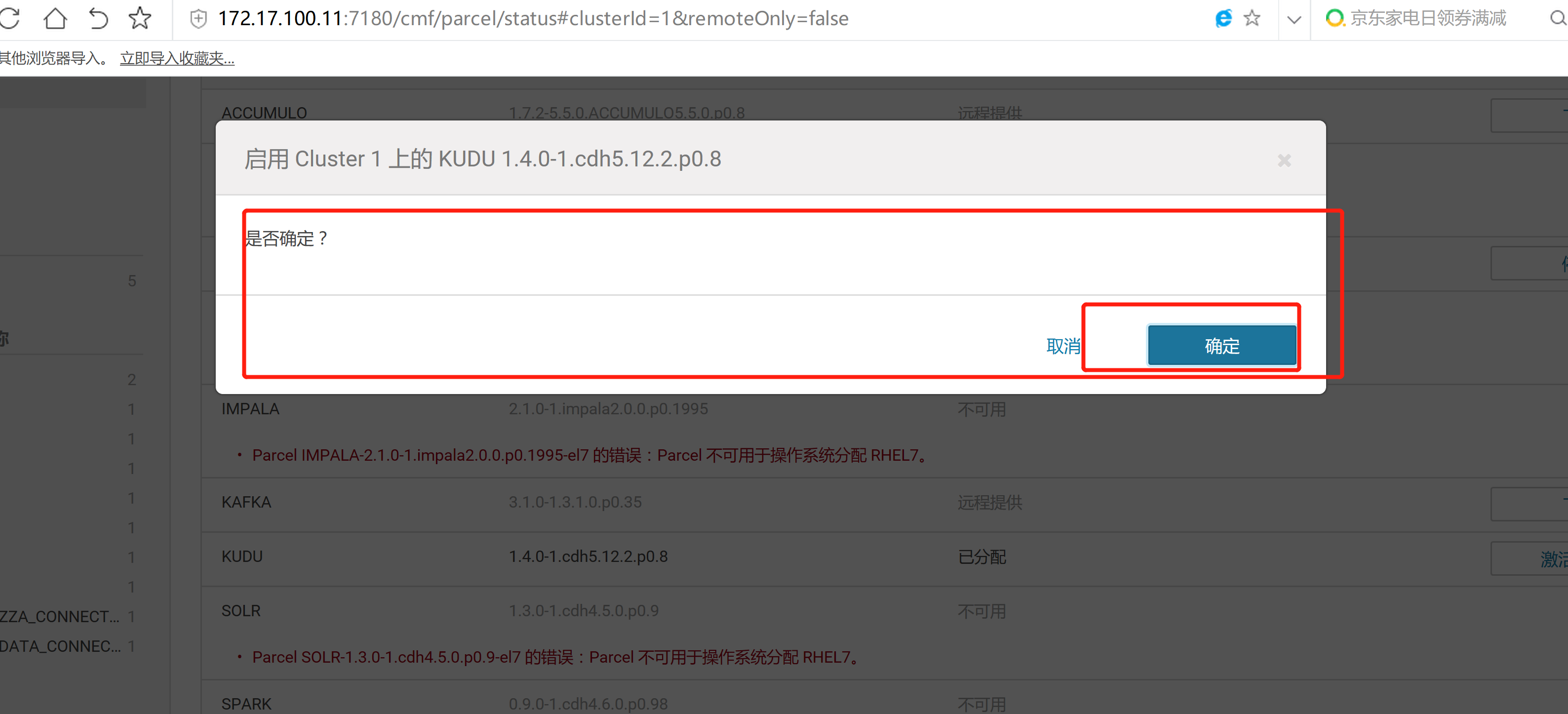
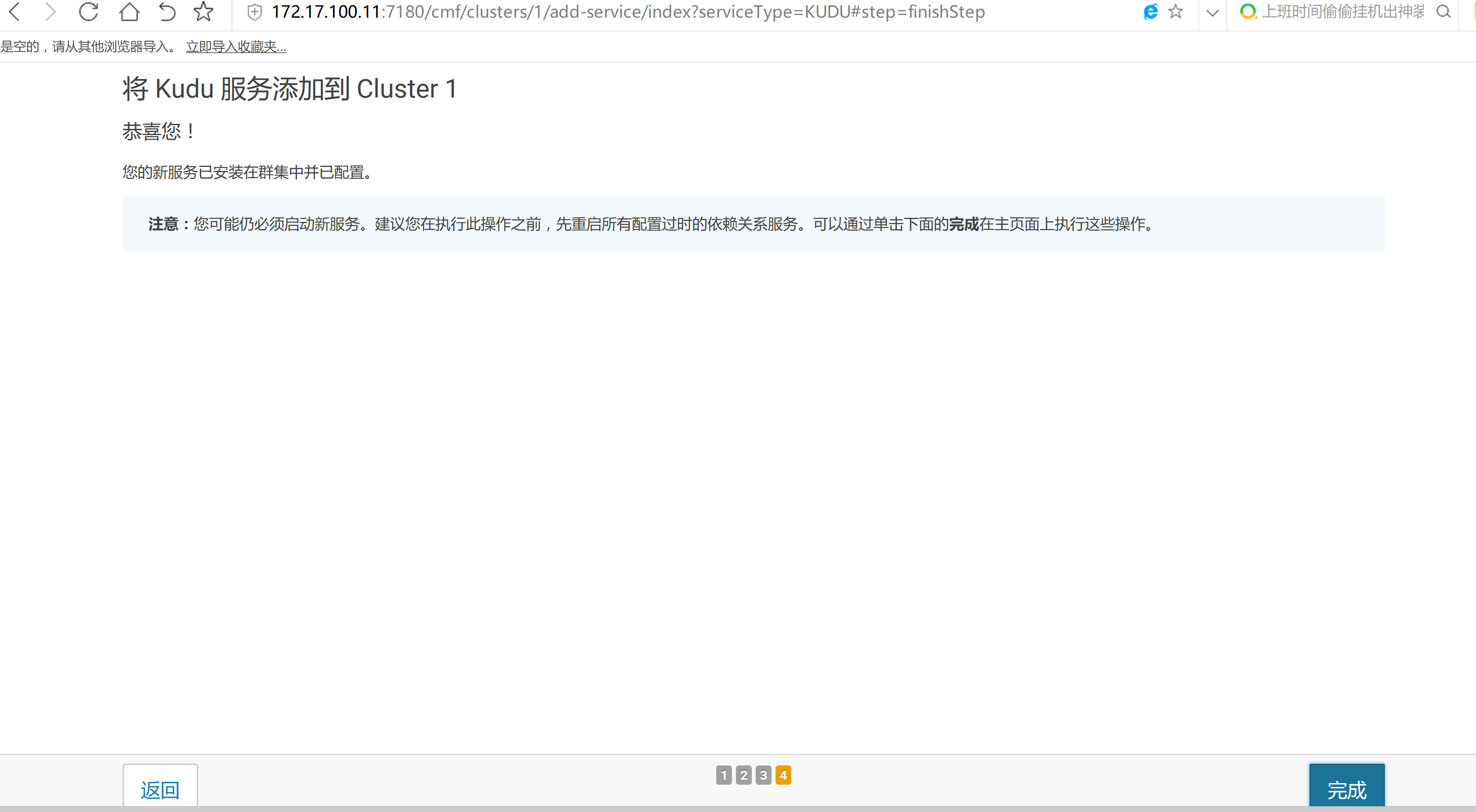
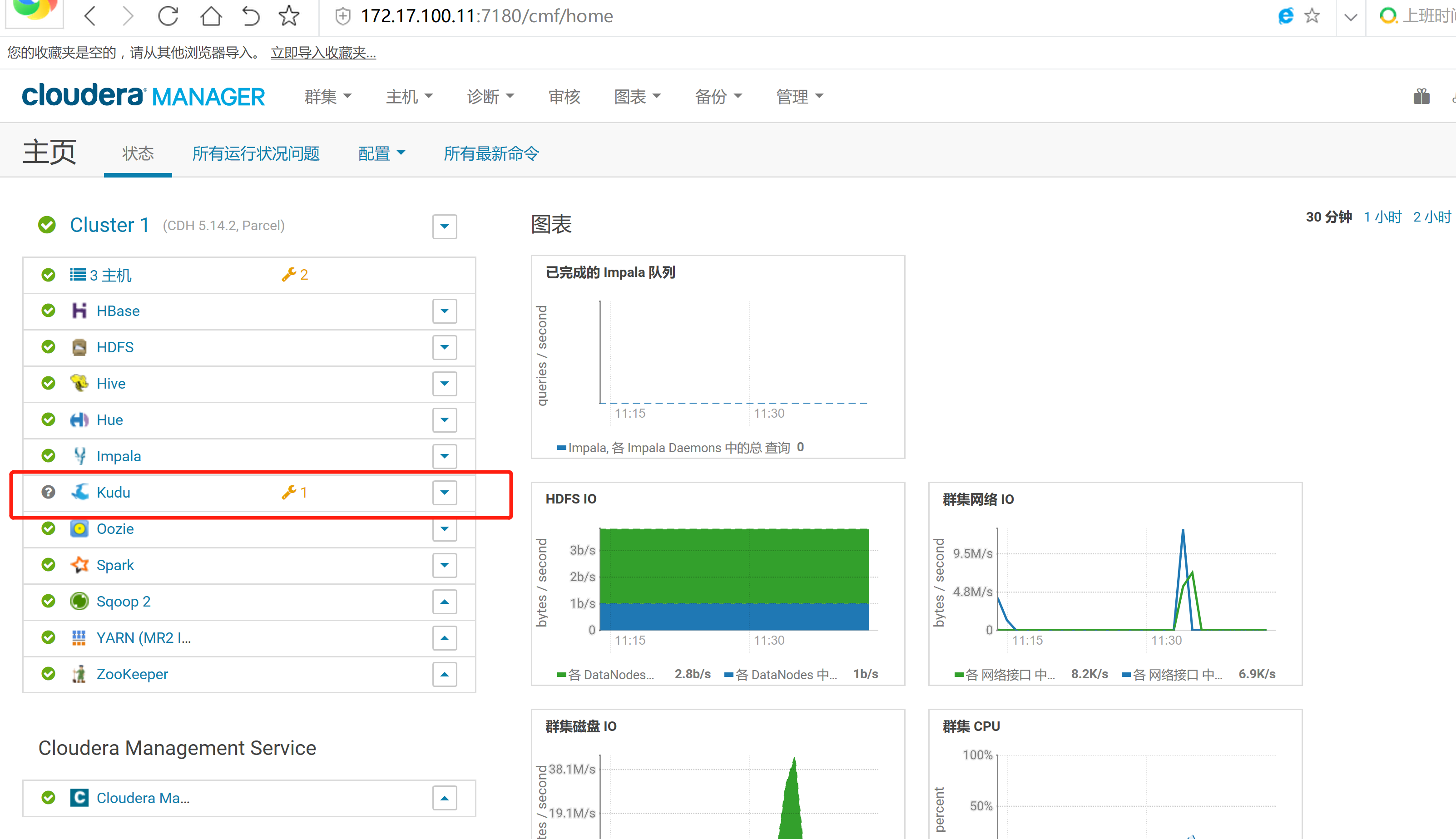
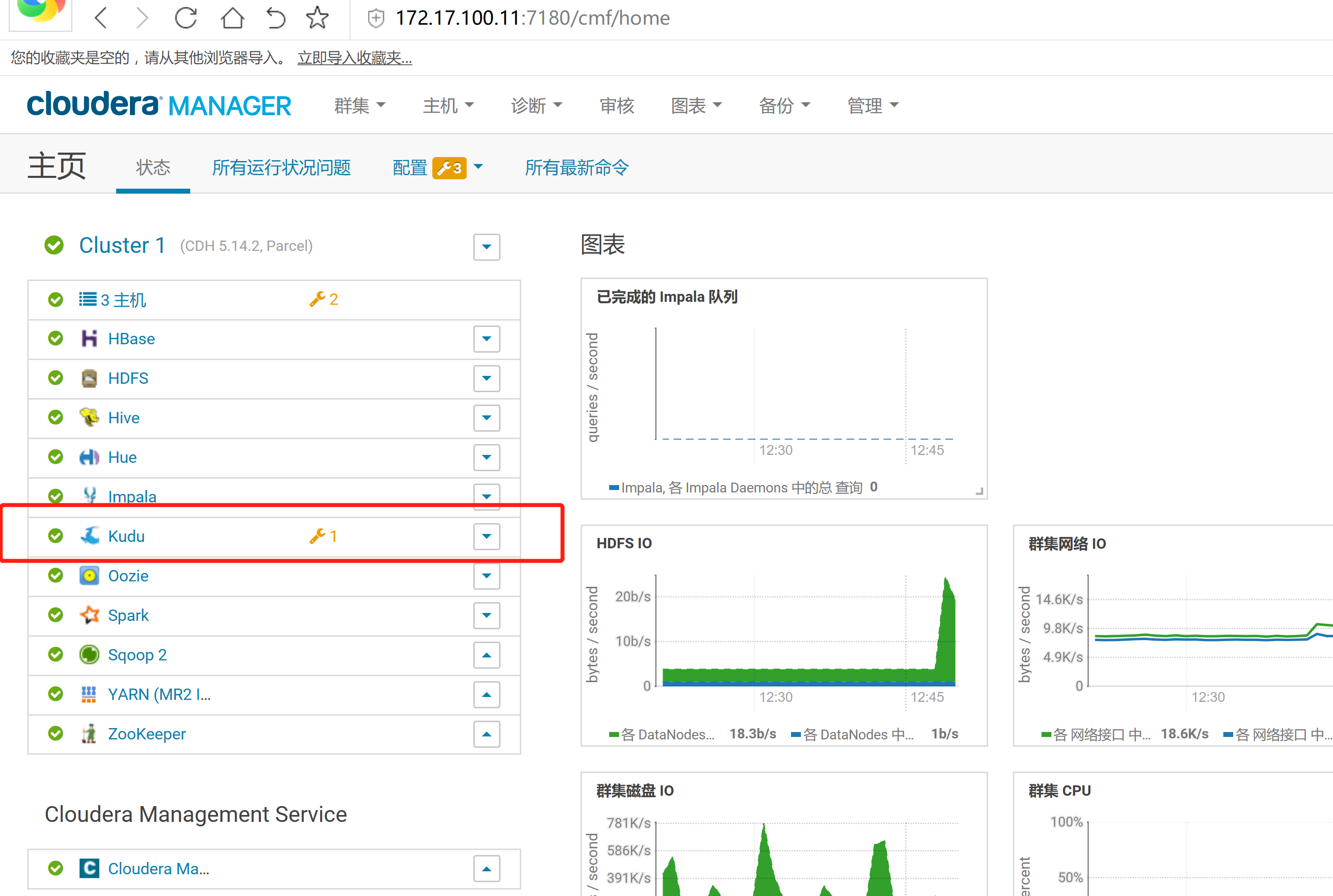
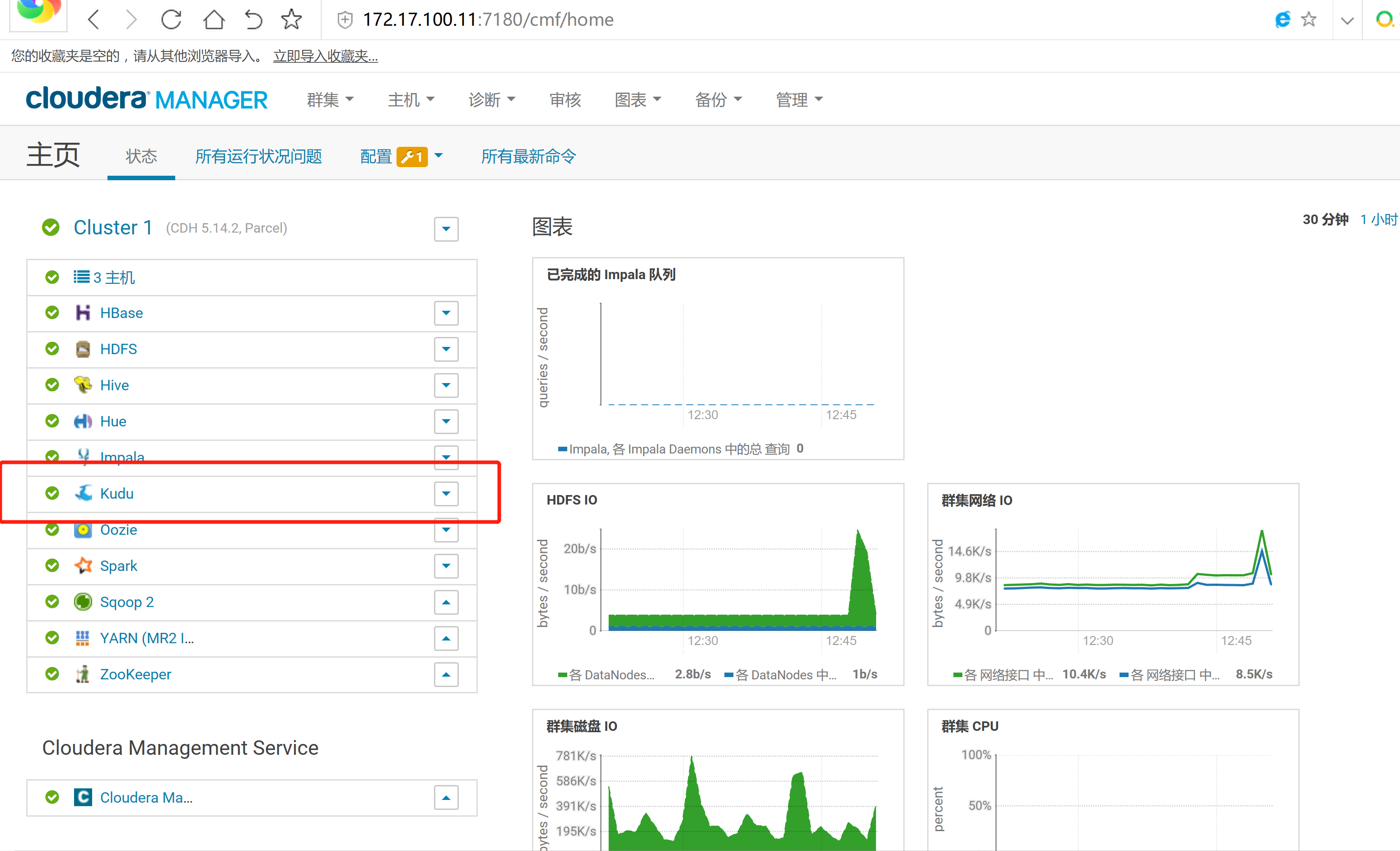
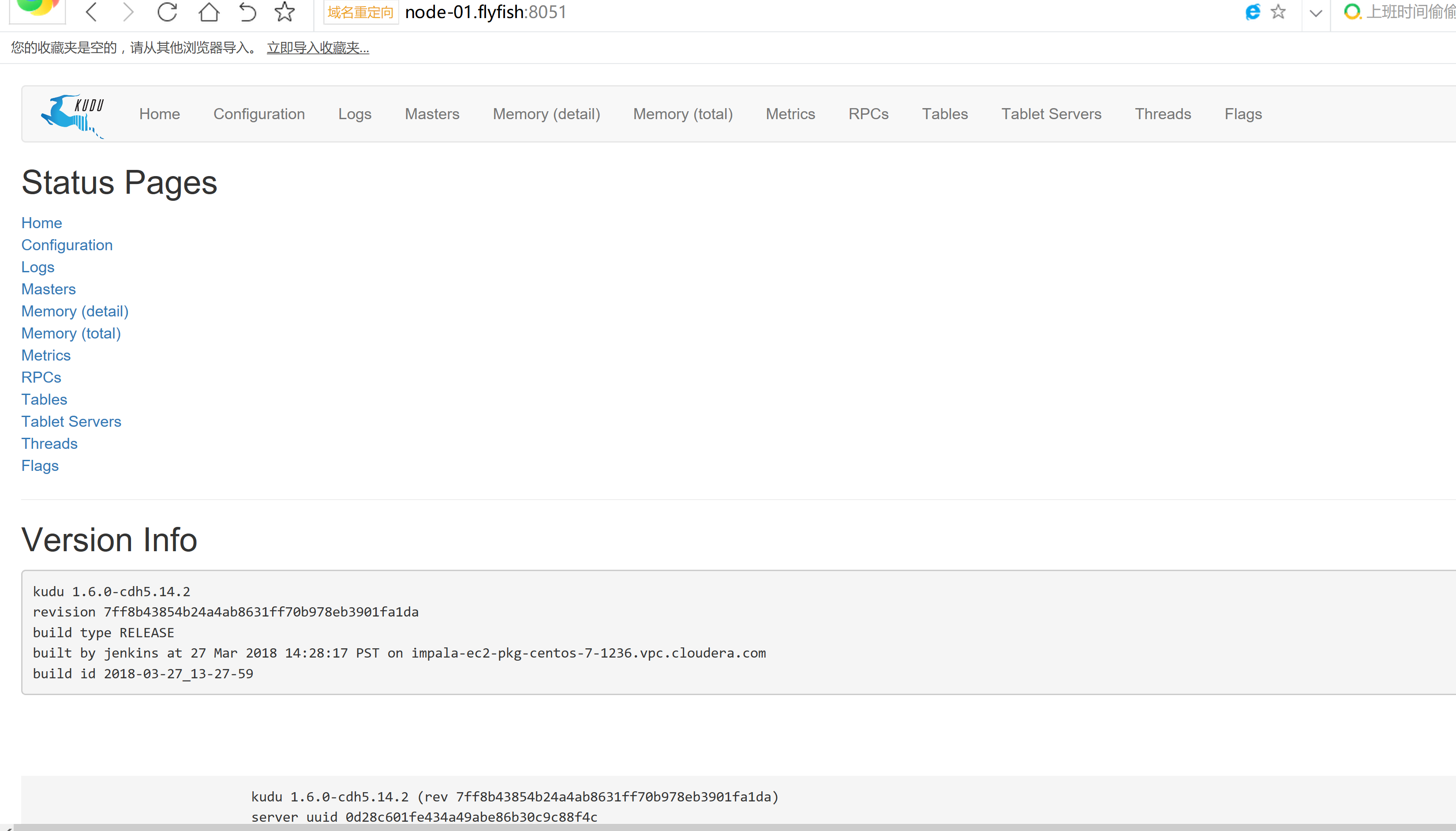
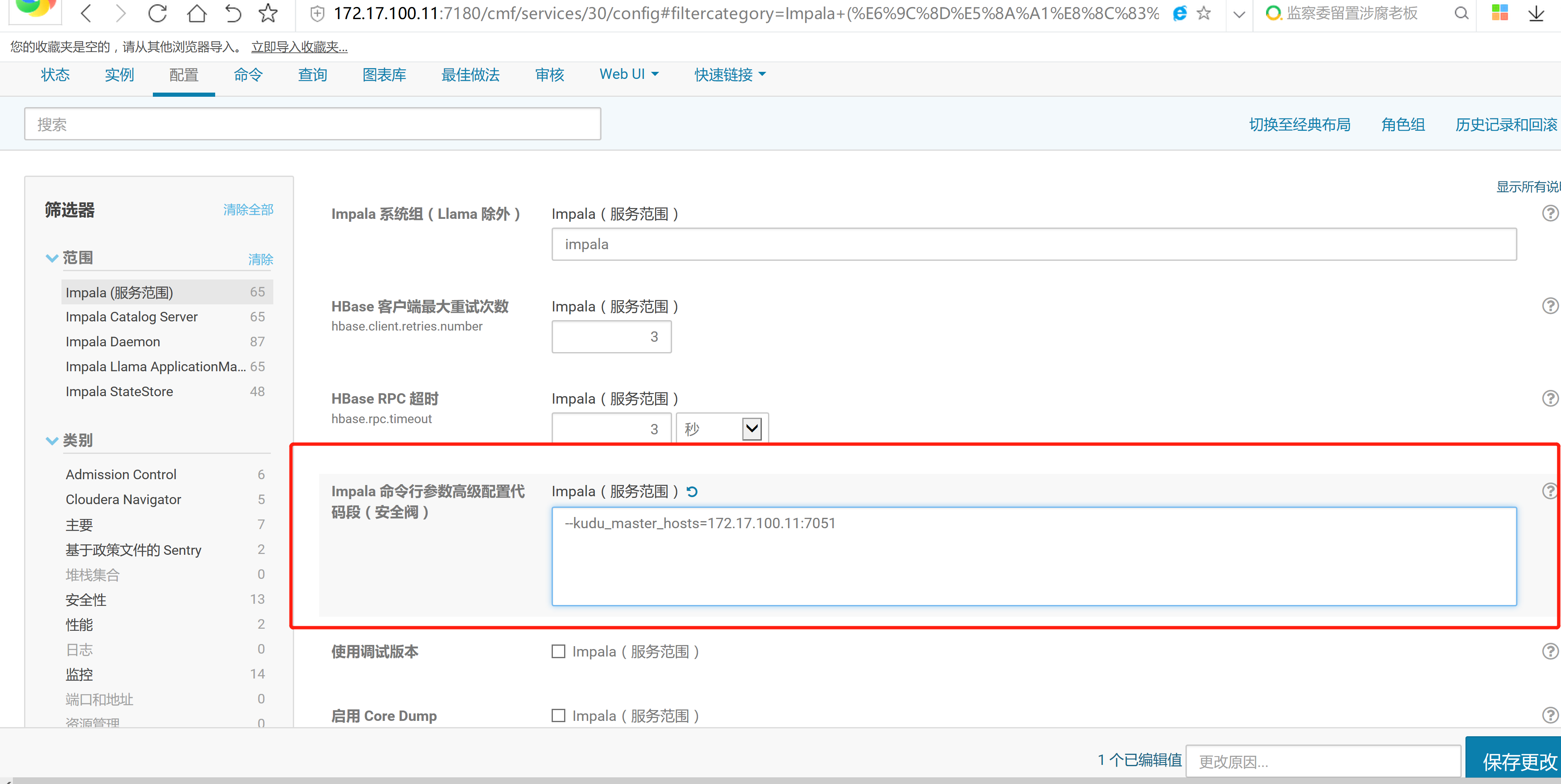
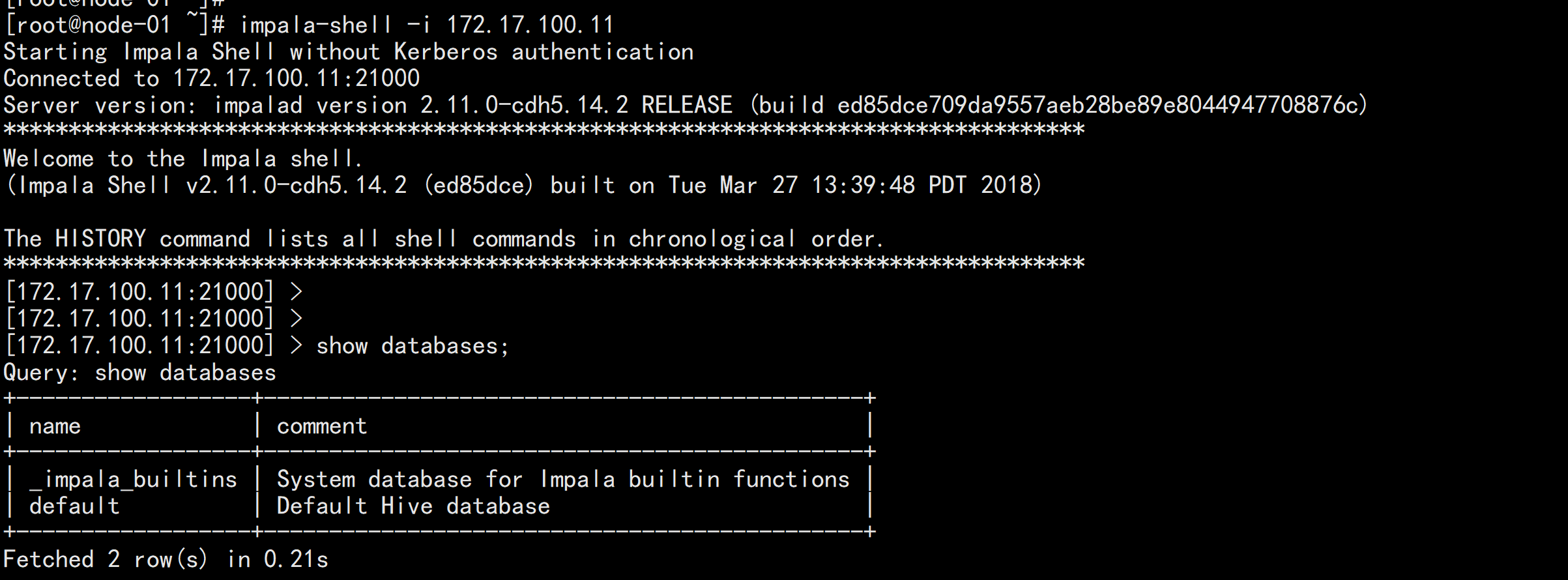
2.4 kudu的验证: 使用impala 直接创建读取kudu上面的数据
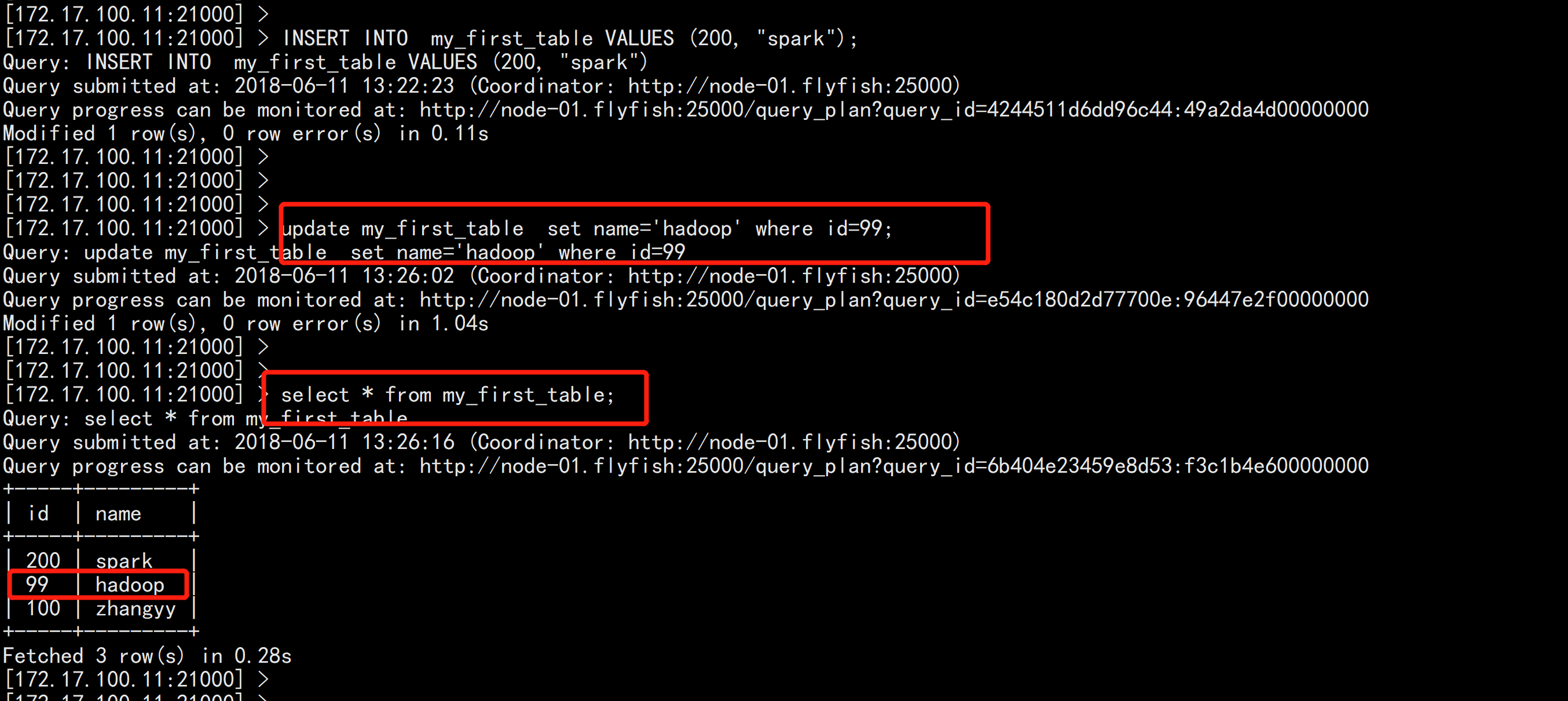
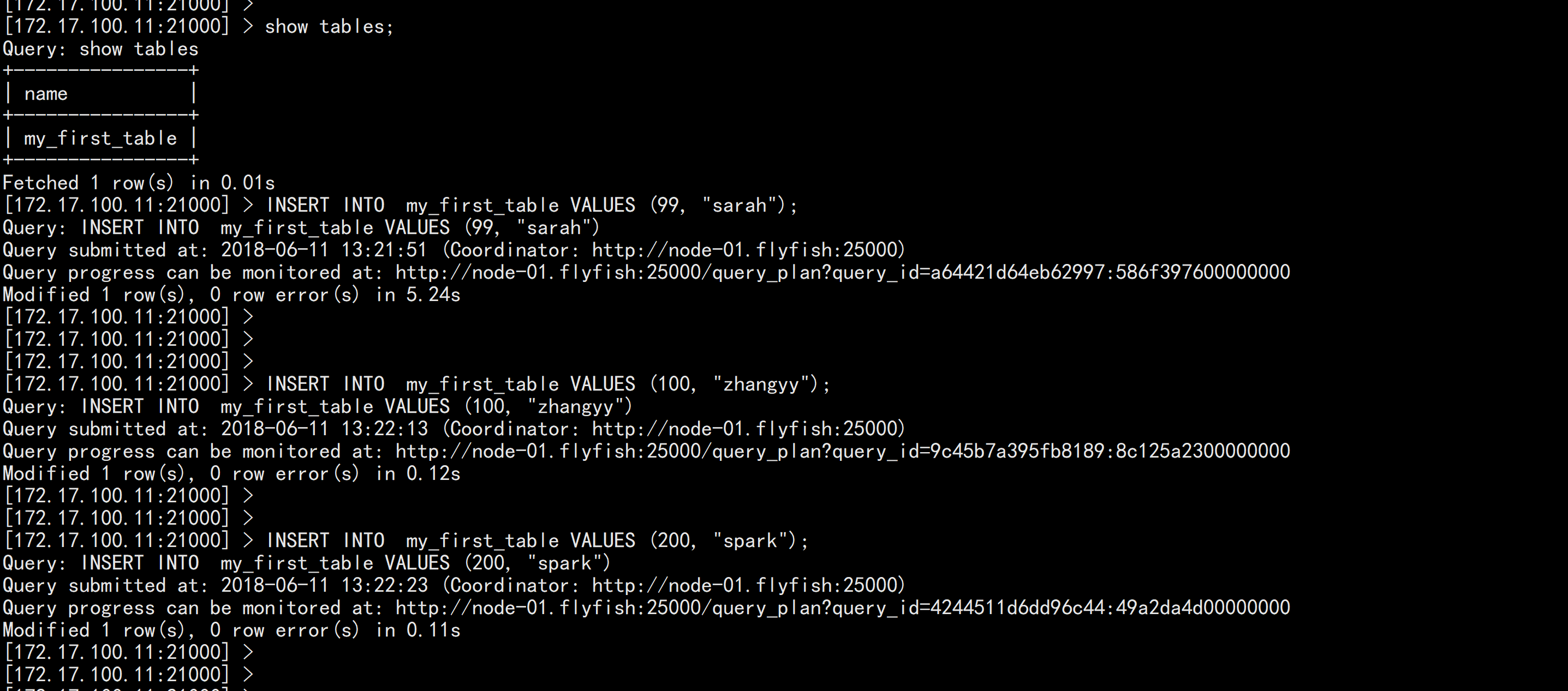
impala-shell -i 172.17.100.11create database kudu_test;

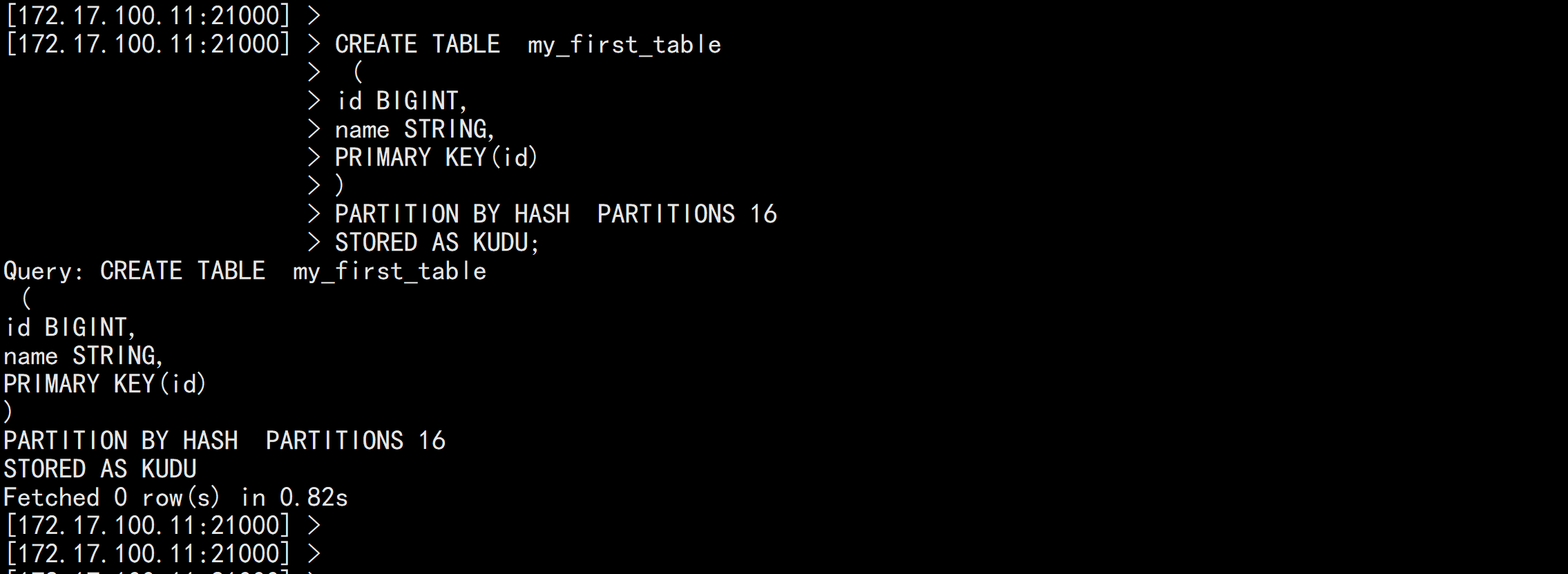
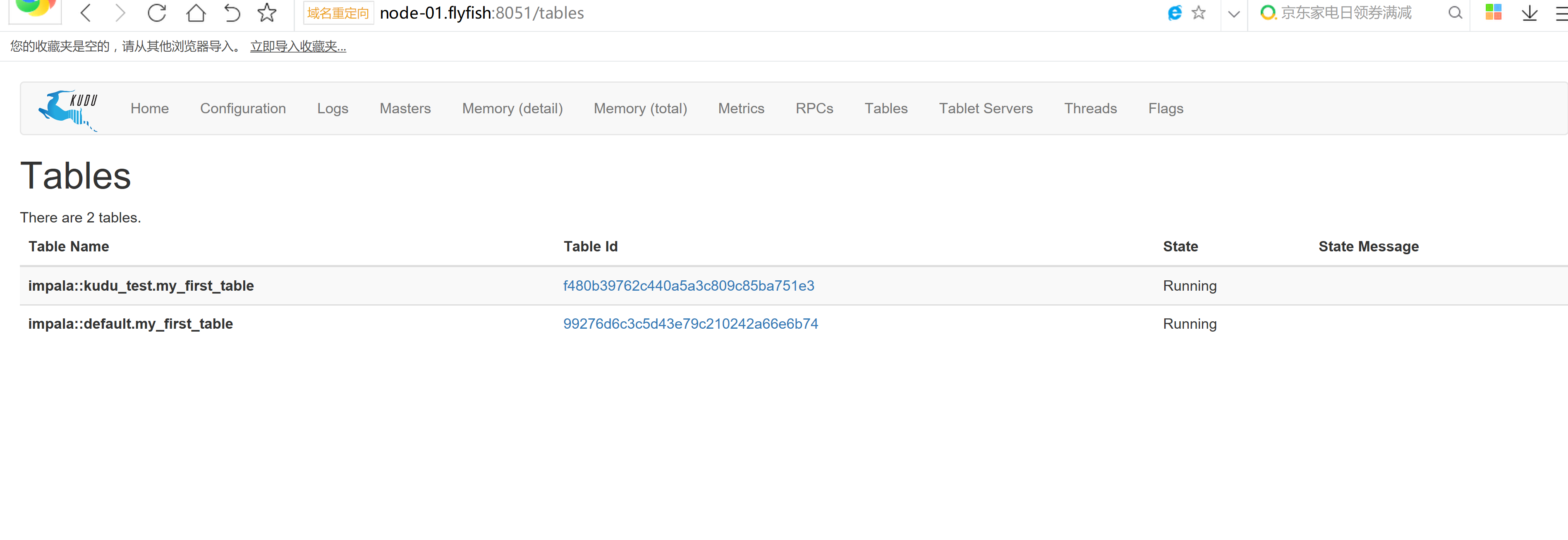
use kudu_test;CREATE TABLE my_first_table(id BIGINT,name STRING,PRIMARY KEY(id))PARTITION BY HASH PARTITIONS 16STORED AS KUDU;
INSERT INTO my_first_table VALUES (99, "sarah");INSERT INTO my_first_table VALUES (100, "zhangyy");INSERT INTO my_first_table VALUES (200, "spark");
update my_first_table set name='hadoop' where id=99;