@zhangyy
2018-03-29T06:49:44.000000Z
字数 1817
阅读 680
hive 的日志案例分析
hive的部分
依据日志文件,参考字段,统计分析每日各时段的pv和uv
- 建立Hive表,表列分隔符需要与原文件保持一致
- Load加载数据到Hive表
- 写Hive sql统计,结果落地到Hive表2
- 从Hive表2导出结果到mysql表
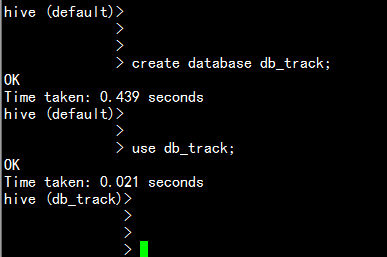
一: 在hive上面进行规划数据库:
- 在hive 上面建立一个库:
create database db_track;use db_track;
- 2 . 建立一张空表带表结构:
create table track_log(id string,url string,referer string,keyword string,type string,guid string,pageId string,moduleId string,linkId string,attachedInfo string,sessionId string,trackerU string,trackerType string,ip string,trackerSrc string,cookie string,orderCode string,trackTime string,endUserId string,firstLink string,sessionViewNo string,productId string,curMerchantId string,provinceId string,cityId string,fee string,edmActivity string,edmEmail string,edmJobId string,ieVersion string,platform string,internalKeyword string,resultSum string,currentPage string,linkPosition string,buttonPosition string)partitioned by (date string,hour string)row format delimited fields terminated by '\t' ;
- 3.加载数据到hive 表中。
load data local inpath '/home/hadoop/2015082818' into table track_log partition(date='20150828',hour='18') ;load data local inpath '/home/hadoop/2015082819' into table track_log partition(date='20150828',hour='19') ;
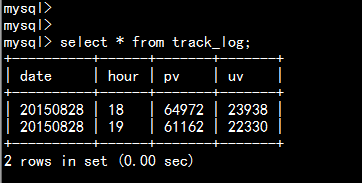
- 4.查找数据相关的pv,uv 数据:
select date,hour,count(url),count(distinct guid) from track_log where date='20150828' group by date,hour ;

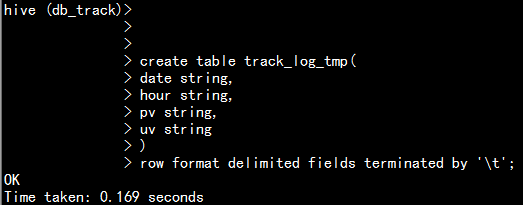
- 5.创建hive 的临时表
create table track_log_tmp(date string,hour string,pv string,uv string)row format delimited fields terminated by '\t';
- 6 . 将查找出的数据添加到新建的临时表当中:
insert into table track_log_tmp select date,hour,count(url),count(distinct guid) from track_log where date='20150828' group by date,hour ;

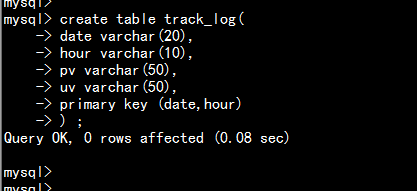
- 7 . 在mysql 数据库当创建临时表的的表结构
create table track_log(date varchar(20),hour varchar(10),pv varchar(50),uv varchar(50),primary key (date,hour)) ;
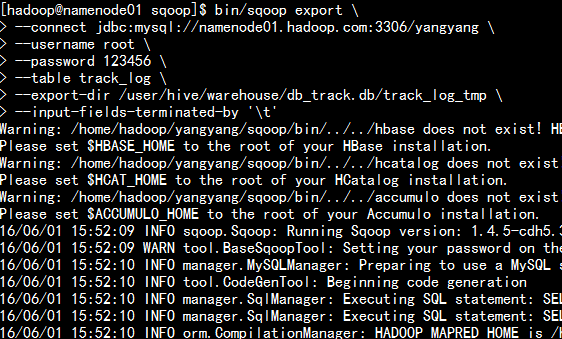
- 8 . 使用sqoop 将新生成的表导入到mysql当中:
bin/sqoop export \--connect jdbc:mysql://namenode01.hadoop.com:3306/yangyang \--username root \--password 123456 \--table track_log \--export-dir /user/hive/warehouse/db_track.db/track_log_tmp \--input-fields-terminated-by '\t'
- 9.查看数据库的最后结果。