@zhangyy
2018-05-08T03:08:20.000000Z
字数 11306
阅读 601
Spark 的 Core 深入(二)
Spark的部分
一、日志清洗的优化:
1.1 日志清洗有脏数据问题
hdfs dfs -mkdir /apachelog/hdfs dfs -put access_log /apachelogshdfs dfs -ls /apachelogs

执行结果报错。
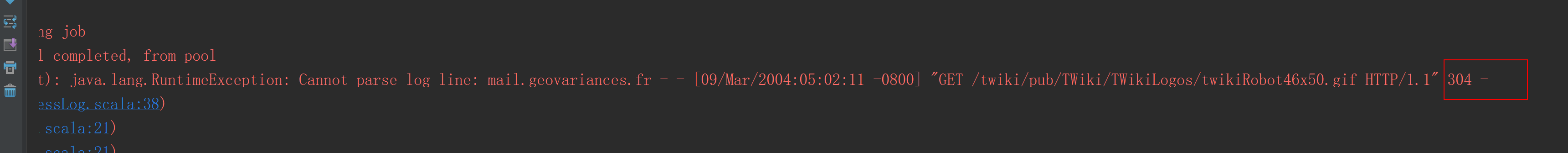
LogAnalyzer.scala
package com.ibeifeng.bigdata.spark.app.coreimport org.apache.spark.{SparkContext, SparkConf}/*** Created by zhangyy on 2016/7/16.*/object LogAnalyzer {def main(args: Array[String]) {// step 0: SparkContextval sparkConf = new SparkConf().setAppName("LogAnalyzer Applicaiton") // name.setMaster("local[2]") // --master local[2] | spark://xx:7077 | yarn// Create SparkContextval sc = new SparkContext(sparkConf)/** ================================================================== */val logFile = "/apachelogs/access_log"// step 1: input dataval accessLogs = sc.textFile(logFile)// filer logs data.filter(ApacheAccessLog.isValidateLogLine) // closures/*** parse log*/.map(line => ApacheAccessLog.parseLogLine(line))/*** The average, min, and max content size of responses returned from the server.*/val contentSizes = accessLogs.map(log => log.contentSize)// computeval avgContentSize = contentSizes.reduce(_ + _) / contentSizes.count()val minContentSize = contentSizes.min()val maxContentSize = contentSizes.max()// printlnprintf("Content Size Avg: %s , Min : %s , Max: %s".format(avgContentSize, minContentSize, maxContentSize))/*** A count of response code's returned*/val responseCodeToCount = accessLogs.map(log => (log.responseCode, 1)).reduceByKey(_ + _).take(3)println(s"""Response Code Count: ${responseCodeToCount.mkString(", ")}""")/*** All IPAddresses that have accessed this server more than N times*/val ipAddresses = accessLogs.map(log => (log.ipAddress, 1)).reduceByKey( _ + _)// .filter( x => (x._2 > 10)).take(5)println(s"""IP Address : ${ipAddresses.mkString("< ", ", " ," >")}""")/*** The top endpoints requested by count*/val topEndpoints = accessLogs.map(log => (log.endPoint, 1)).reduceByKey(_ + _).top(3)(OrderingUtils.SecondValueOrdering)// .map(tuple => (tuple._2, tuple._1))// .sortByKey(false)//.take(3)//.map(tuple => (tuple._2, tuple._1))println(s"""Top Endpoints : ${topEndpoints.mkString("[", ", ", " ]")}""")/** ================================================================== */// Stop SparkContextsc.stop()}}
ApacheAccessLog.scala
package com.ibeifeng.bigdata.spark.app.core/*** Created by zhangyy on 2016/7/16.** 1.1.1.1 - - [21/Jul/2014:10:00:00 -0800]* "GET /chapter1/java/src/main/java/com/databricks/apps/logs/LogAnalyzer.java HTTP/1.1"* 200 1234*/case class ApacheAccessLog (ipAddress: String,clientIndentd: String,userId: String,dateTime:String,method: String,endPoint: String,protocol: String,responseCode: Int,contentSize: Long)object ApacheAccessLog{// regex// 1.1.1.1 - - [21/Jul/2014:10:00:00 -0800] "GET /chapter1/java/src/main/java/com/databricks/apps/logs/LogAnalyzer.java HTTP/1.1" 200 1234val PARTTERN ="""^(\S+) (\S+) (\S+) \[([\w:/]+\s[+\-]\d{4})\] "(\S+) (\S+) (\S+)" (\d{3}) (\d+)""".r/**** @param log* @return*/def isValidateLogLine(log: String): Boolean = {// parse logval res = PARTTERN.findFirstMatchIn(log)// invalidateif (res.isEmpty) {false}else{true}}/**** @param log* @return*/def parseLogLine(log: String): ApacheAccessLog ={// parse logval res = PARTTERN.findFirstMatchIn(log)// invalidateif(res.isEmpty){throw new RuntimeException("Cannot parse log line: " + log)}// get valueval m = res.get// returnApacheAccessLog( //m.group(1), //m.group(2),m.group(3),m.group(4),m.group(5),m.group(6),m.group(7),m.group(8).toInt,m.group(9).toLong)}}
OrderingUtils.scala
package com.ibeifeng.bigdata.spark.app.coreimport scala.math.Ordering/*** Created by zhangyy on 2016/7/16.*/object OrderingUtils {object SecondValueOrdering extends Ordering[(String, Int)]{/**** @param x* @param y* @return*/override def compare(x: (String, Int), y: (String, Int)): Int = {x._2.compare(y._2)// x._2 compare y._2 // 1 to 10 | 1.to(10)}}}

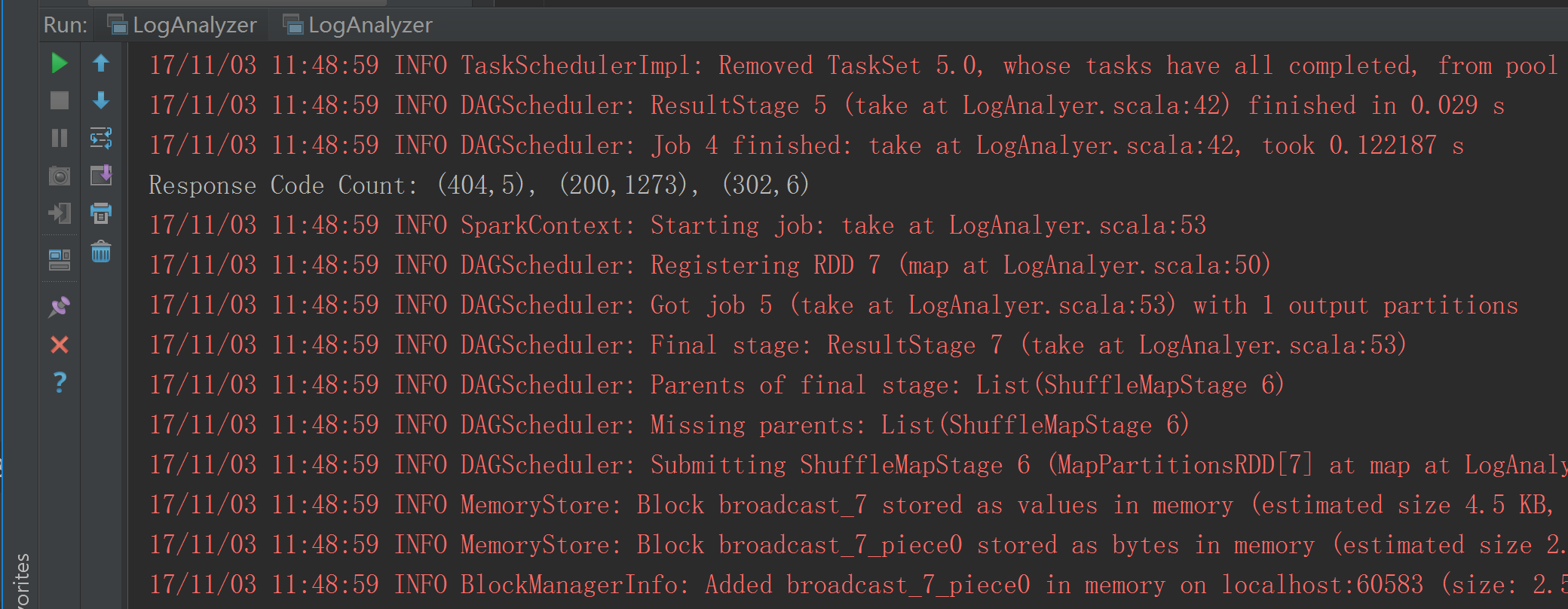
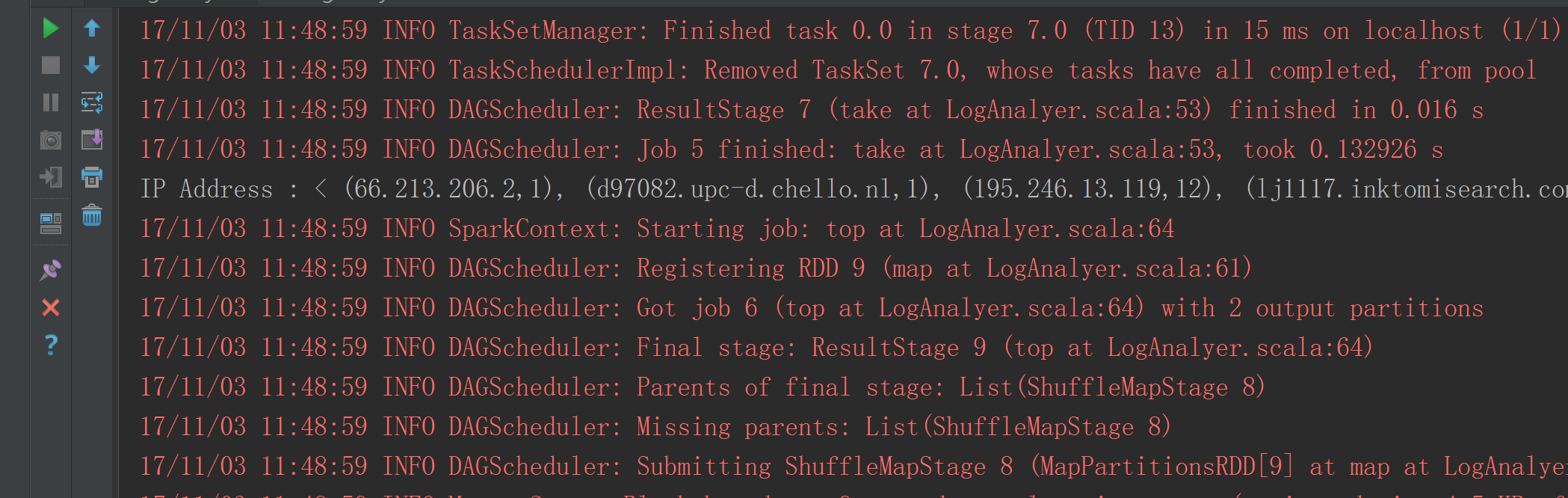
二、Spark RDD
2.1:RDD的含义:
RDD,全称为Resilient Distributed Datasets,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。在这些操作中,诸如map、flatMap、filter等转换操作实现了monad模式,很好地契合了Scala的集合操作。除此之外,RDD还提供了诸如join、groupBy、reduceByKey等更为方便的操作(注意,reduceByKey是action,而非transformation),以支持常见的数据运算
2.2、RDD 在 hdfs的结构
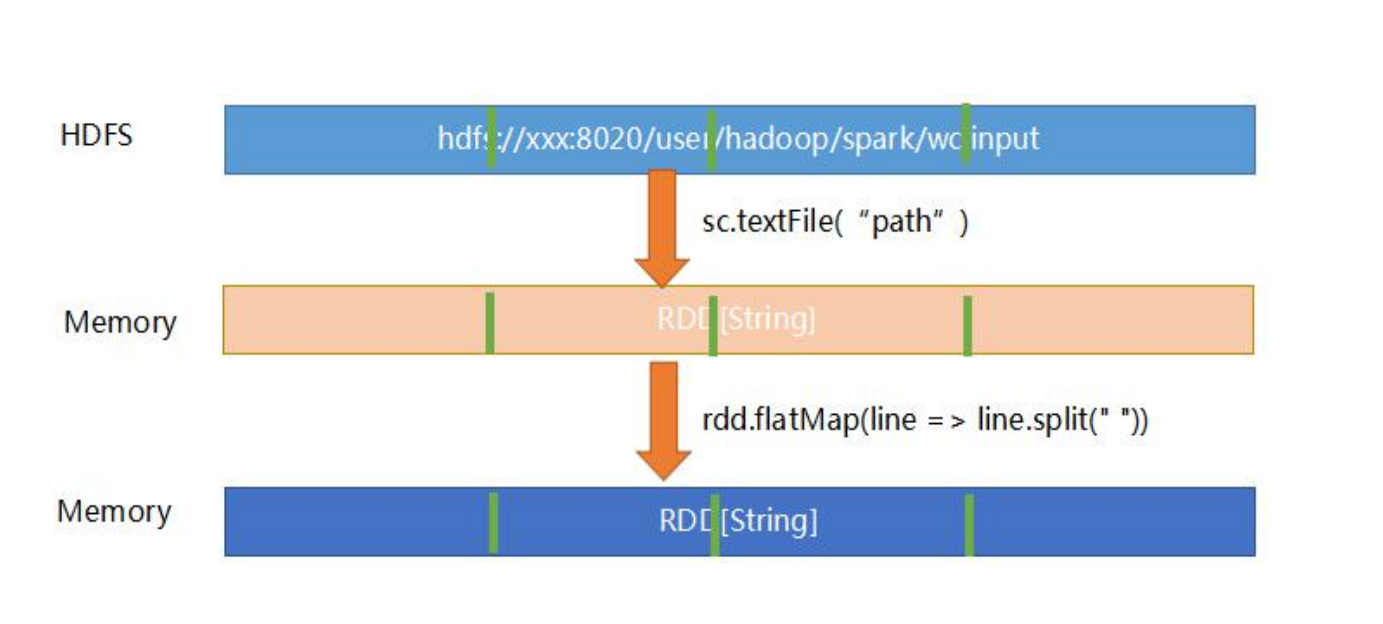
val rdd = sc.textFile("/spark/rdd")rdd.partitions.lengthrdd.cacherdd.count一个分区默认一个task 分区去处理默认是两个分区去处理

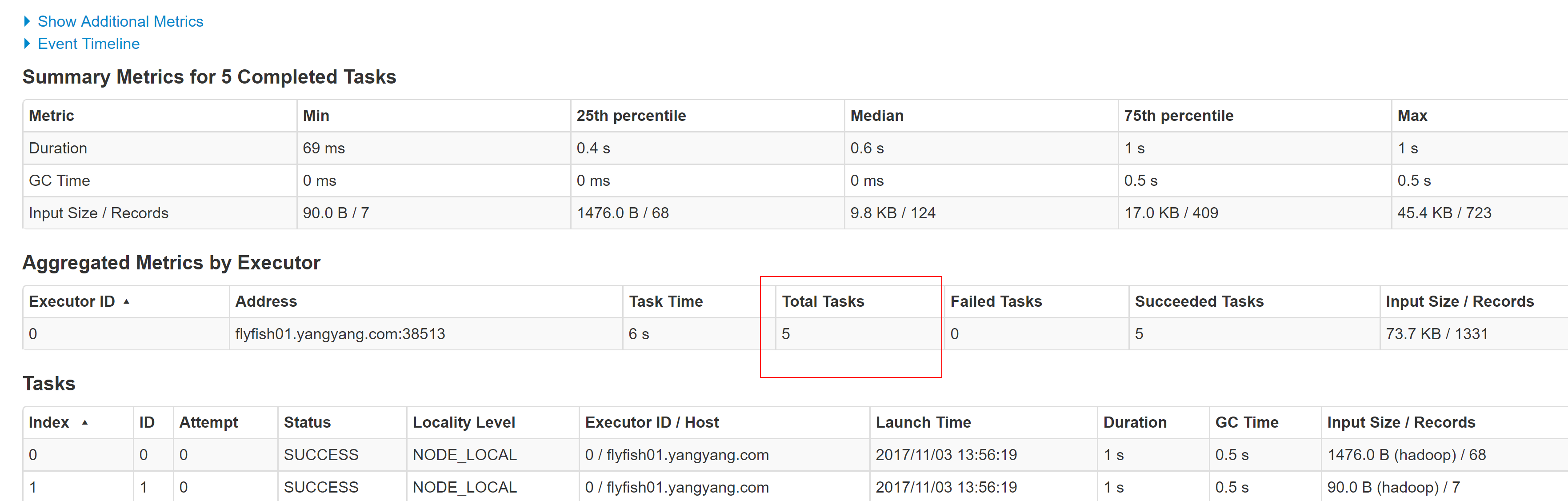
2.3、RDD的五个特点对应方法
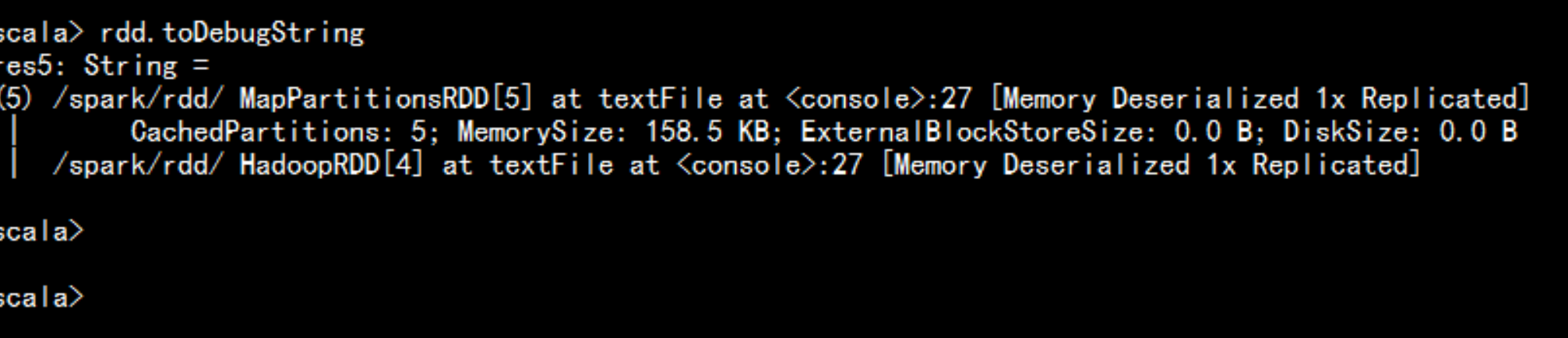
1. A list of partitions : (protected def getPartitions: Array[Partition])一系列的的分片,比如说64M一片,类似于hadoop中的split2. A function ofr computing each split :( @DeveloperApidef compute(split: Partition, context: TaskContext): Iterator[T])在每个分片上都有一个方式去迭代/执行/计算3. A list of dependencies on other RDD :(protected def getDependencies: Seq[Dependency[_]] = deps)一系列的依赖:RDDa 转换为RDDb,转换为 RDDc, 那么RDDc 就依赖于RDDb , RDDb 又依赖于RDDa---wordcount 程序:## val rdd = sc.textFile("xxxx")val wordRdd = rdd.flatMap(_.split(""))val kvRdd = wordRdd.map((_,1))val WordCountRdd = kvRdd.reduceByKey(_ + _)# wrodcountRdd.saveAsTextFile("yy")kvRdd <- wordRdd <- rddrdd.toDebugString---4. Optionlly,a Partitioner for kev-values RDDs (e,g,to say that the RDDis hash-partitioned) :(/** Optionally overridden by subclasses to specify how they are partitioned. */@transient val partitioner: Option[Partitioner] = None)5. optionlly,a list of preferred location(s) to compute each split on (e,g,block location for an HDFS file):(protected def getPreferredLocations(split: Partition): Seq[String] = Nil)要运行的计算/执行最好在哪(几)个机器上运行,数据本地型为什么会有那几个呢?比如: hadoop 默认有三个位置,或者spark cache 到内存是可能同过StroageLevel 设置了多个副本,所以一个partition 可能返回多个最佳位置。
2.4、 如何创建RDD的两种方式
方式一:并行化集合:并行化集合List\Seq\ArraySparkContext:----def parallelize[T: ClassTag](seq: Seq[T],numSlices: Int = defaultParallelism): RDD[T]---
list 创建:
val list = List("11","22","33")val listRdd = sc.parallelize(list)listRdd.countlistRdd.fristlistRdd.take(10)
seq 创建:
val seq = Sep("aa","bb","cc")val seqRdd = sc.parallelize(seq)seqRdd.countseqRdd.fristseqRdd.take(10)
Array创建:
val array = Array(1,2,3,4,5)val arryRdd = sc.parallelize(array)arryRdd.firstarryRdd.countarryRdd.take(10)
方式二:从外部存储创建:val disFile = sc.textFile("/input")
2.5、RDD的转换过程
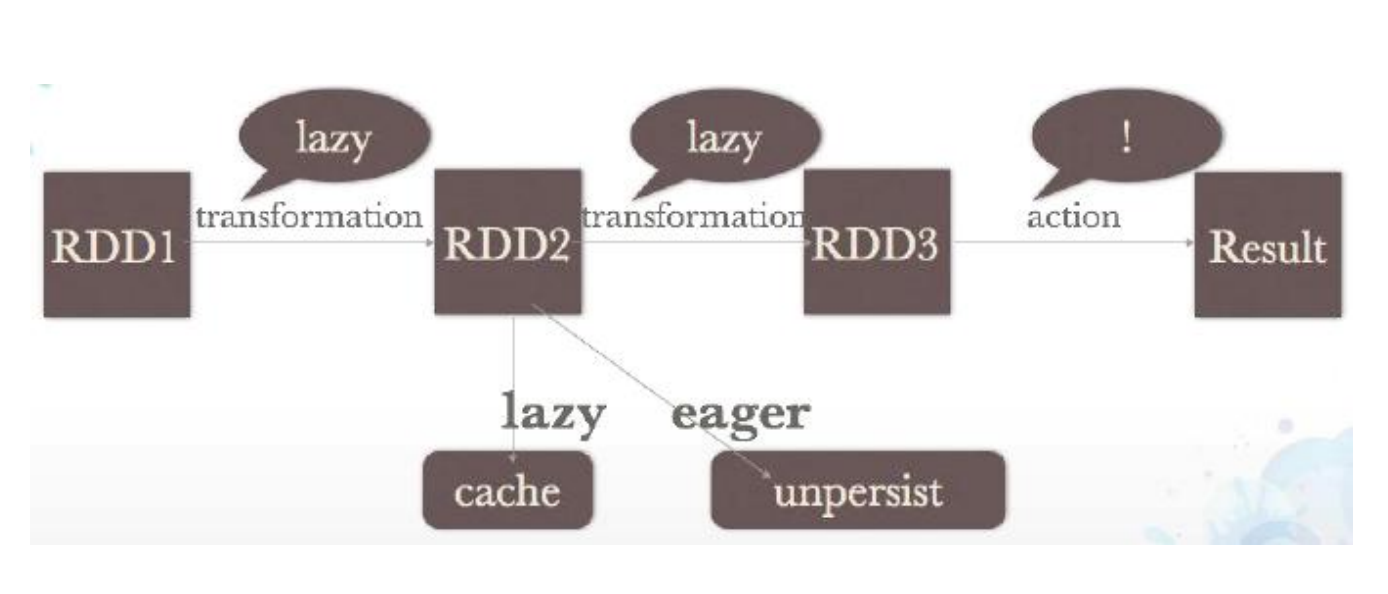
transformation 转换actions 执行出结果persistence 基本都是cache过程
2.5.1: rdd transformation 应用

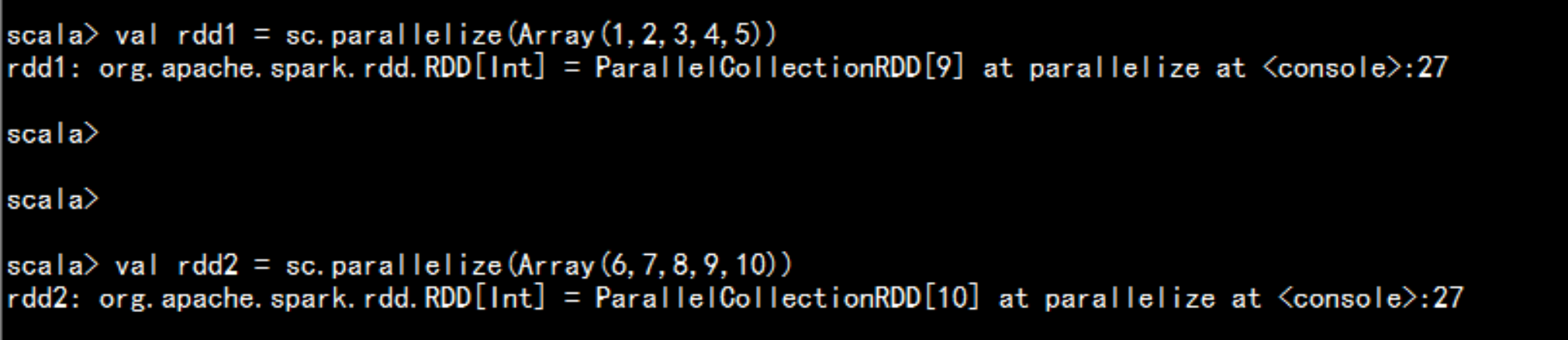
union()合并应用val rdd1 = sc.parallelize(Array(1,2,3,4,5))val rdd2 = sc.parallelize(Array(6,7,8,9,10))val rdd = rdd1.union(rdd2)rdd.collect
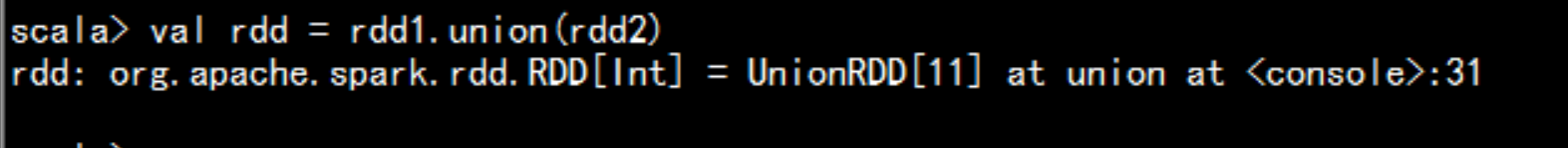

对于分布式计算框架来说,性能瓶颈IO-1,磁盘IO-2,网络IOrdd1 -> rdd2Shuffle============================================groupByKey() & reduceByKey()在实际开发中,如果可以使用reduceByKey实现的功能,就不要使用groupBykey使用reduceByKey有聚合功能,类似MapReduce中启用了Combiner===============join()-1,等值链接-2,左连接数据去重结果数据res-pre.txt - rdd1新数据进行处理web.tsv - 10GB - rdd2解析里面的url,如果res-pre.txt中包含,就不放入,不包含就加入或者不包含url进行特殊处理rdd2.leftJoin(rdd1)
join()应用
val list =List("aa","bb","cc","dd")val rdd1 = sc.parallelize(list).map((_, 1))rdd1.collectval list2 = List("bb","cc","ee","hh")val rdd2 = sc.parallelize(list2).map((_, 1))rdd2.collectval rdd = rdd2.leftOuterJoin(rdd1)rdd.collectrdd.filter(tuple => tuple._2._2.isEmpty).collect
repartition()应用:
val rdd = sc.textFile("/spark/rdd")rdd.repartition(2)rdd.count

2.5.2: RDD Actions 操作
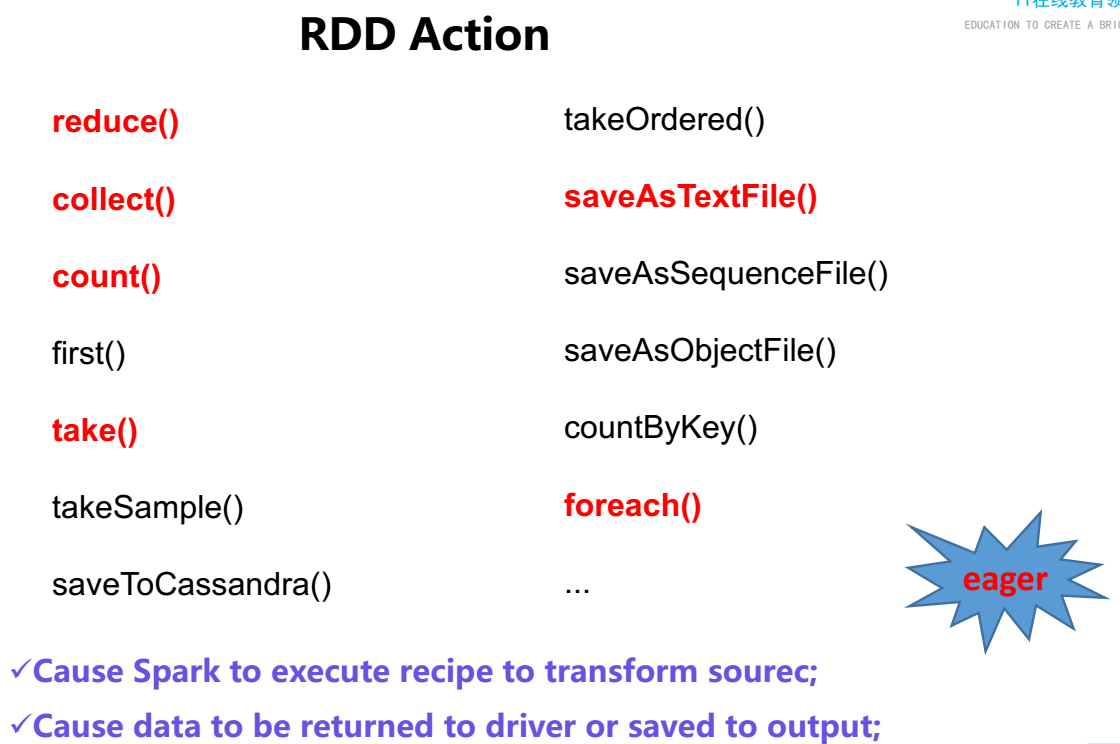
val list = List(("aa",1),("bb",4),("aa",56),("cc",0),("aa",89),("cc",34))val rdd = sc.parallelize(list)rdd.countByKey
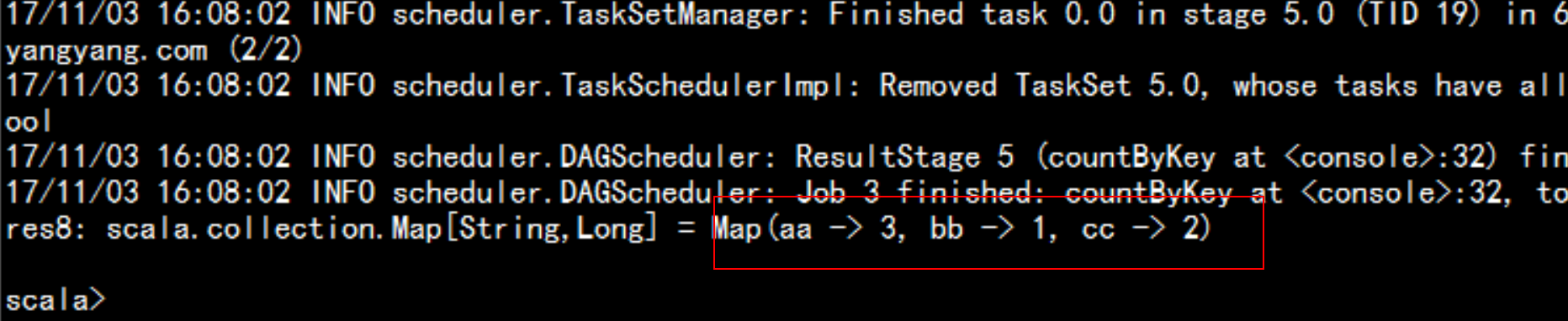
wordcount 转变val rdd = sc.textFile("\input")rdd.flatMap(_.split(" ")).map((_, 1)).countByKey

foreach() 应用
val list = List(1,2,3,4,5)val rdd = sc.parallelize(list)rdd.foreach(line => println(line))
分组topkey
aa 78bb 98aa 80cc 98aa 69cc 87bb 97cc 86aa 97bb 78bb 34cc 85bb 92cc 72bb 32bb 23
val rdd = sc.textFile("/topkeytest")val topRdd = rdd.map(line => line.split(" ")).map(arr => (arr(0), arr(1).toInt)).groupByKey().map(tuple => (tuple._1, tuple._2.toList.sorted.takeRight(3).reverse))topRdd.collect

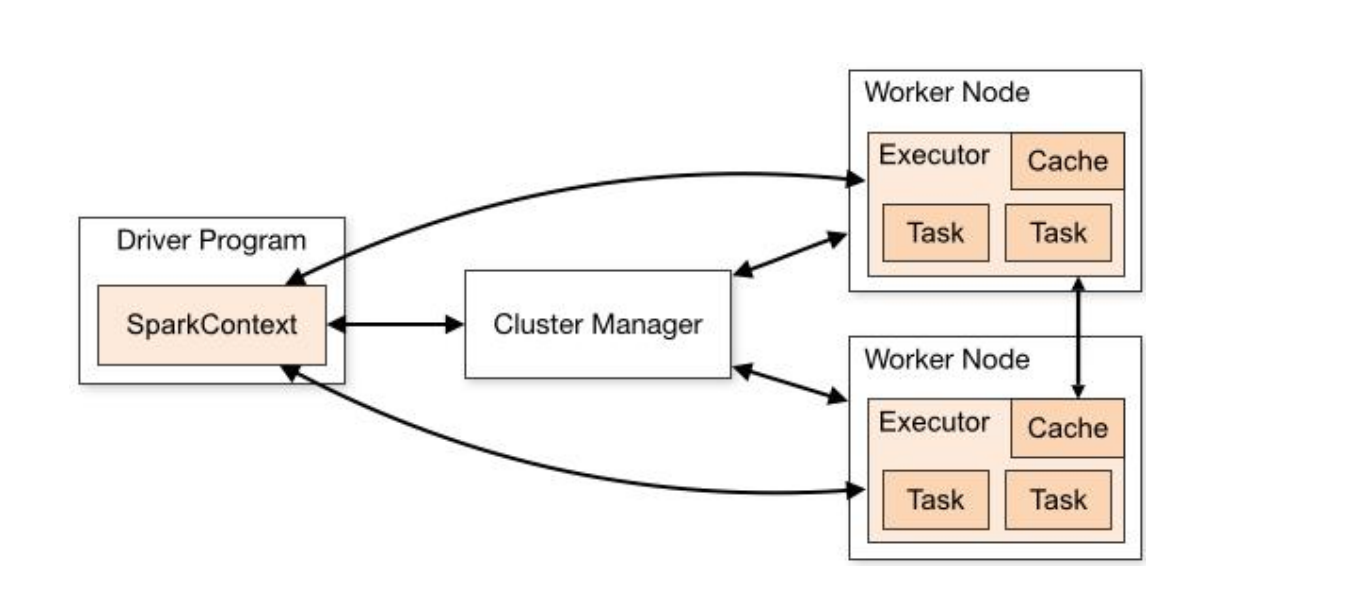
三:SparkContext三大功能
3.1、没有使用广播变量
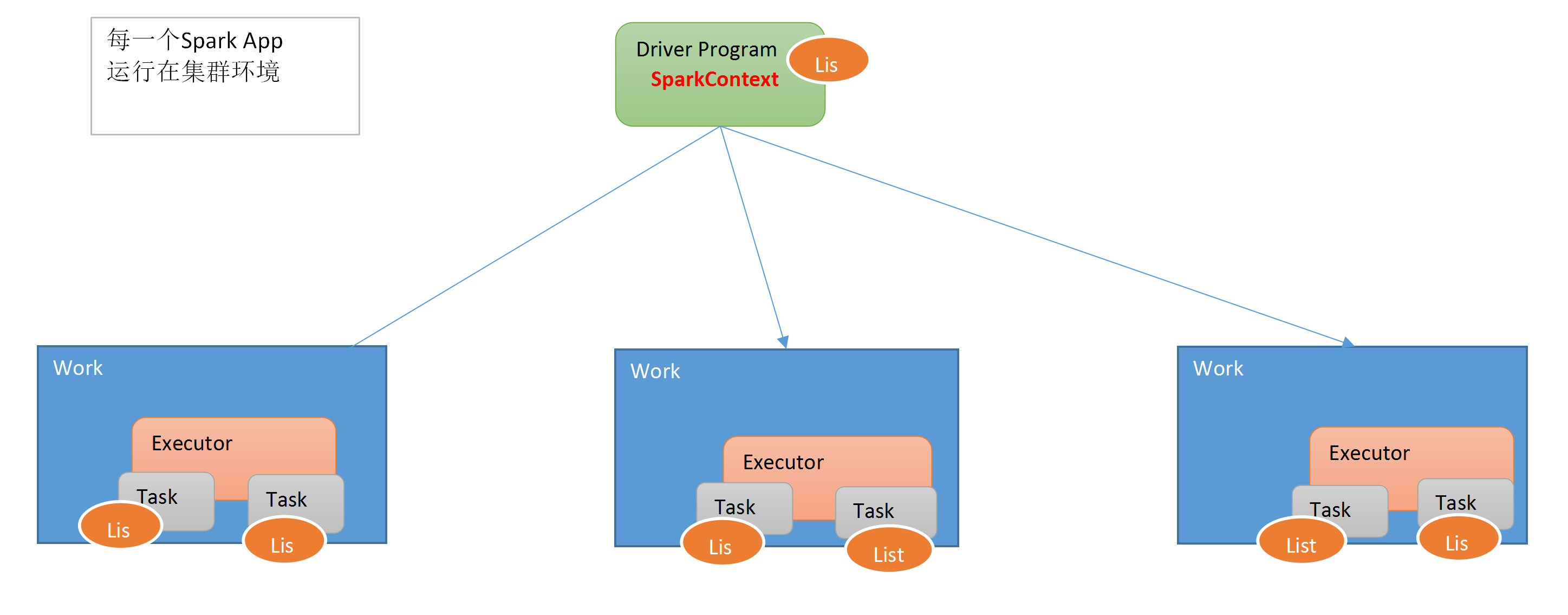
SparkContext 的作用:-1,向Master(主节点,集群管理的主节点)申请资源,运行所有Executor-2,创建RDD的入口sc.textFile("") // 从外部存储系统创建sc.parxx() // 并行化,从Driver 中的集合创建-3,调度管理JOB运行DAGScheduler 、 TaskScheduler--3.1为每个Job构建DAG图--3.2DAG图划分为Stage按照RDD之间是否存在Shuffle倒推(Stack)--3.3每个Stage中TaskSet每个阶段中Task代码相同,仅仅处理数据不同
3.2 使用广播变量
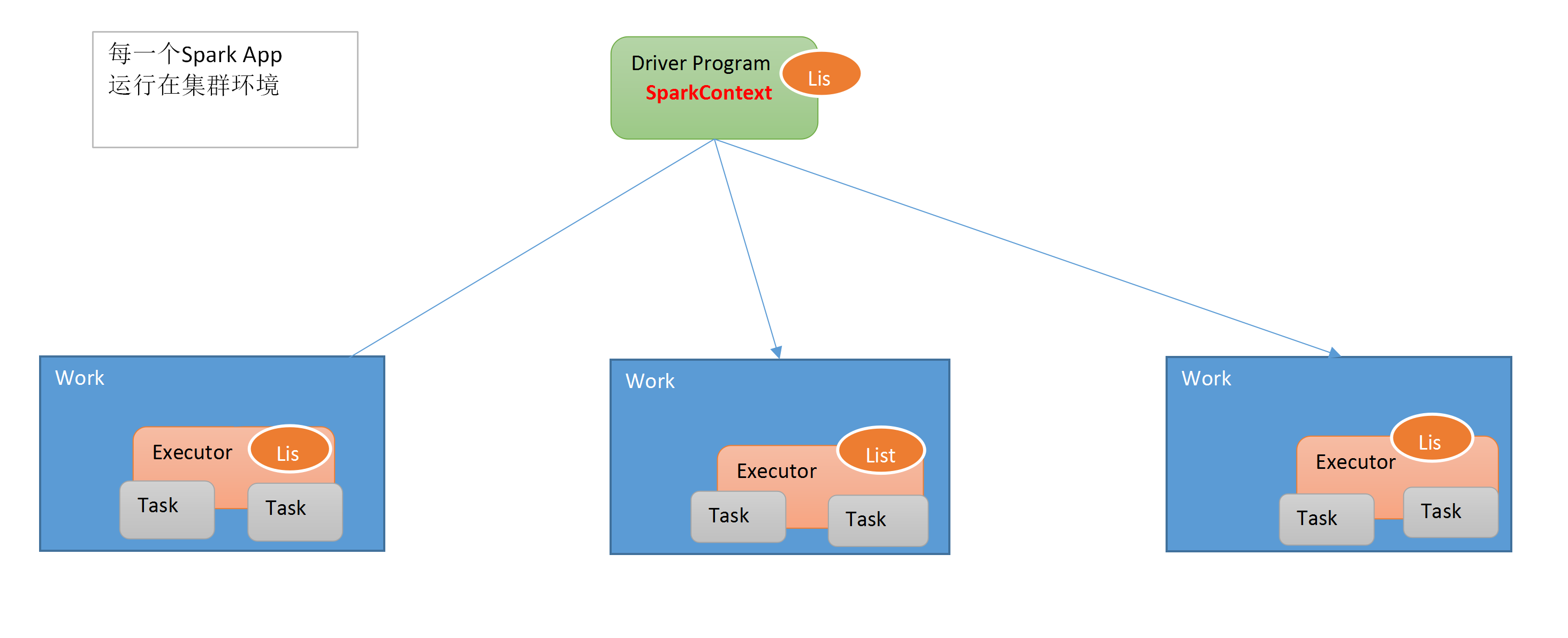
val list = List(".", "?", "!", "#", "$")val braodCastList = sc.broadcast(list)val wordRdd = sc.textFile("")wordRdd.filter(word => {braodCastList.value.contains(word)})
3.4 spark 的 cluster mode
3.4.1 spark的部署模式:
1.spark的默认模式是local模式spark-submint Scala_Project.jar
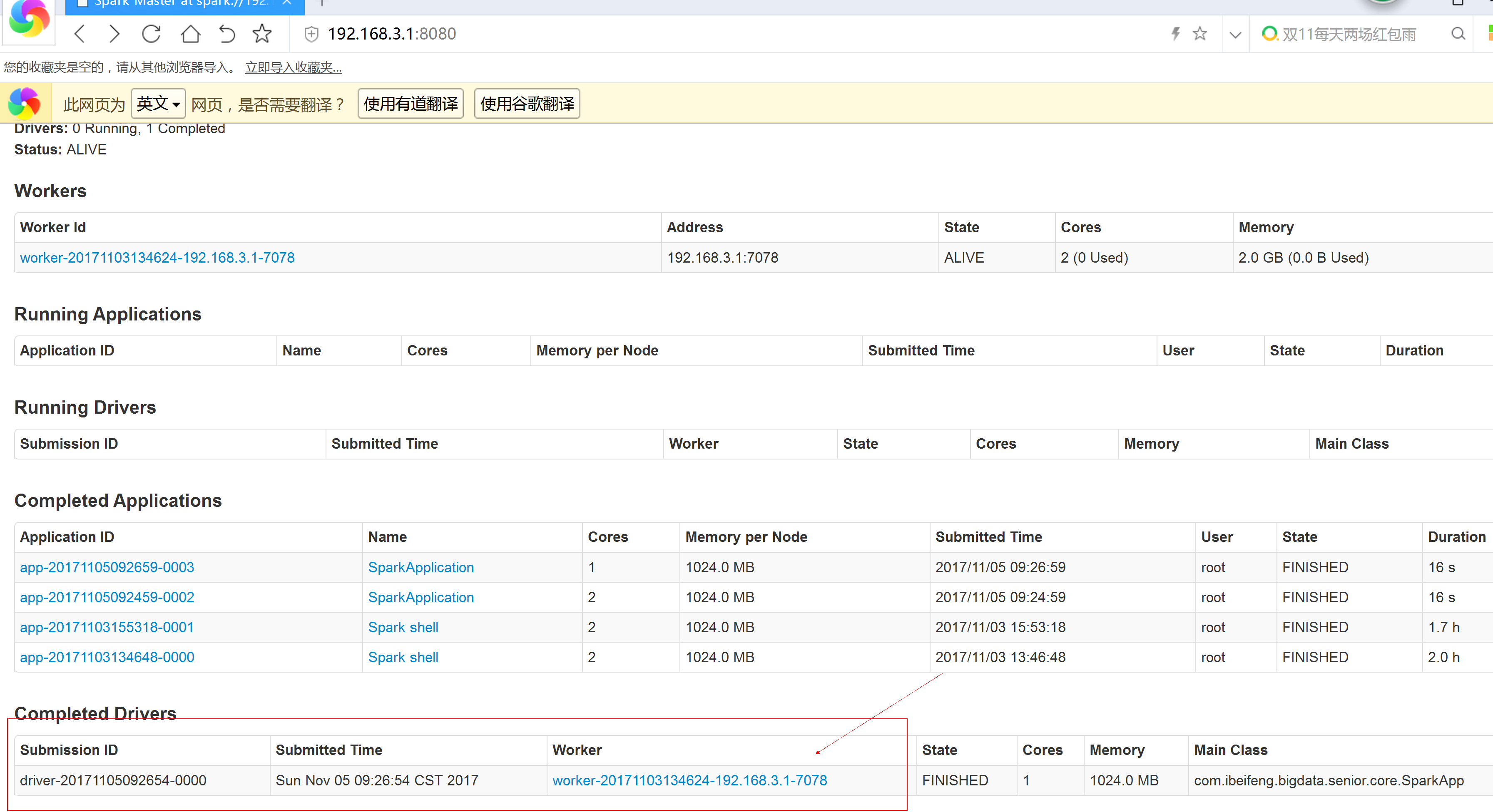
2. spark job 运行在客户端集群模式:spark-submit --master spark://192.168.3.1:7077 --deploy-mode cluster Scala_Project.jar

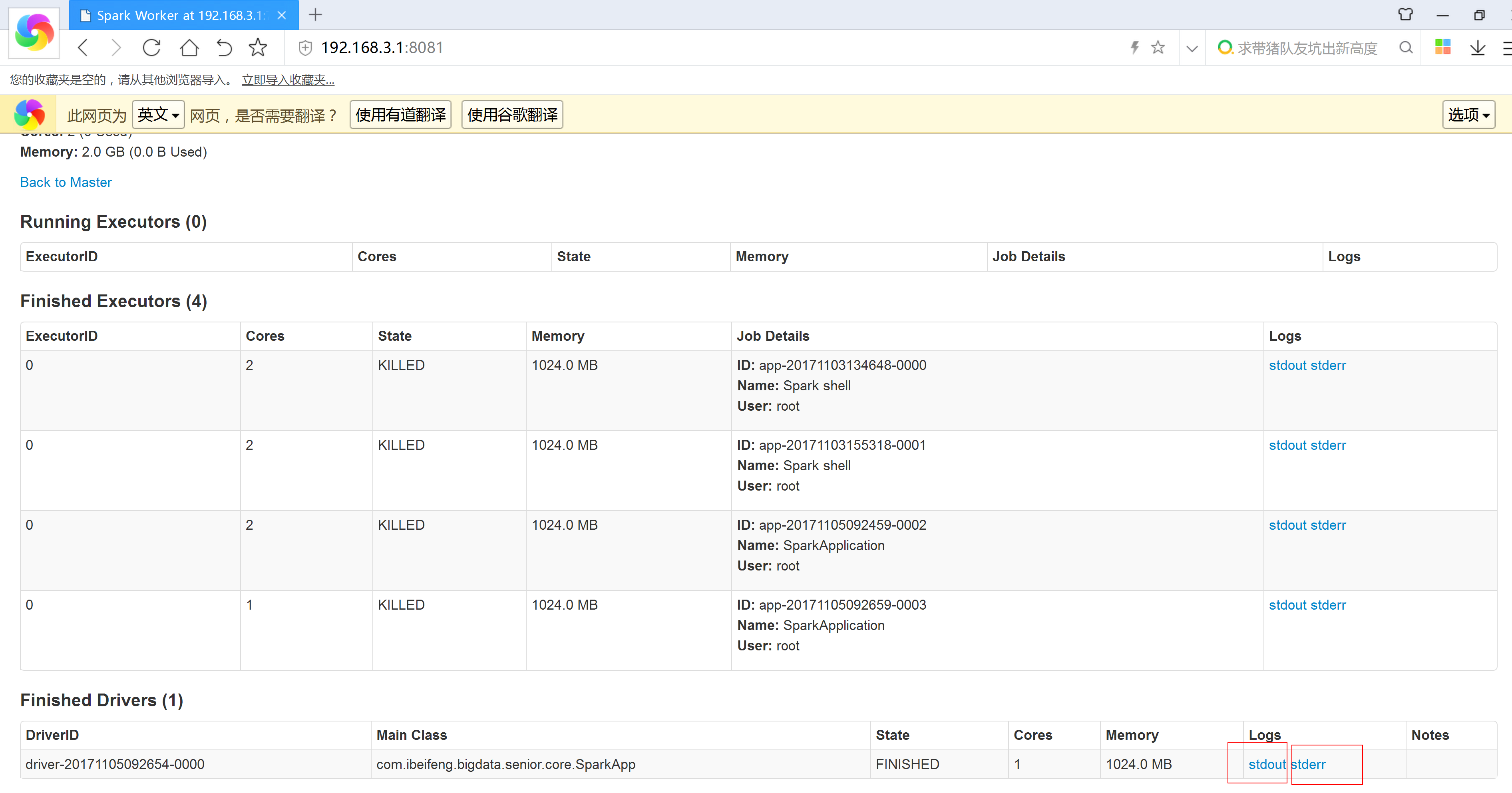
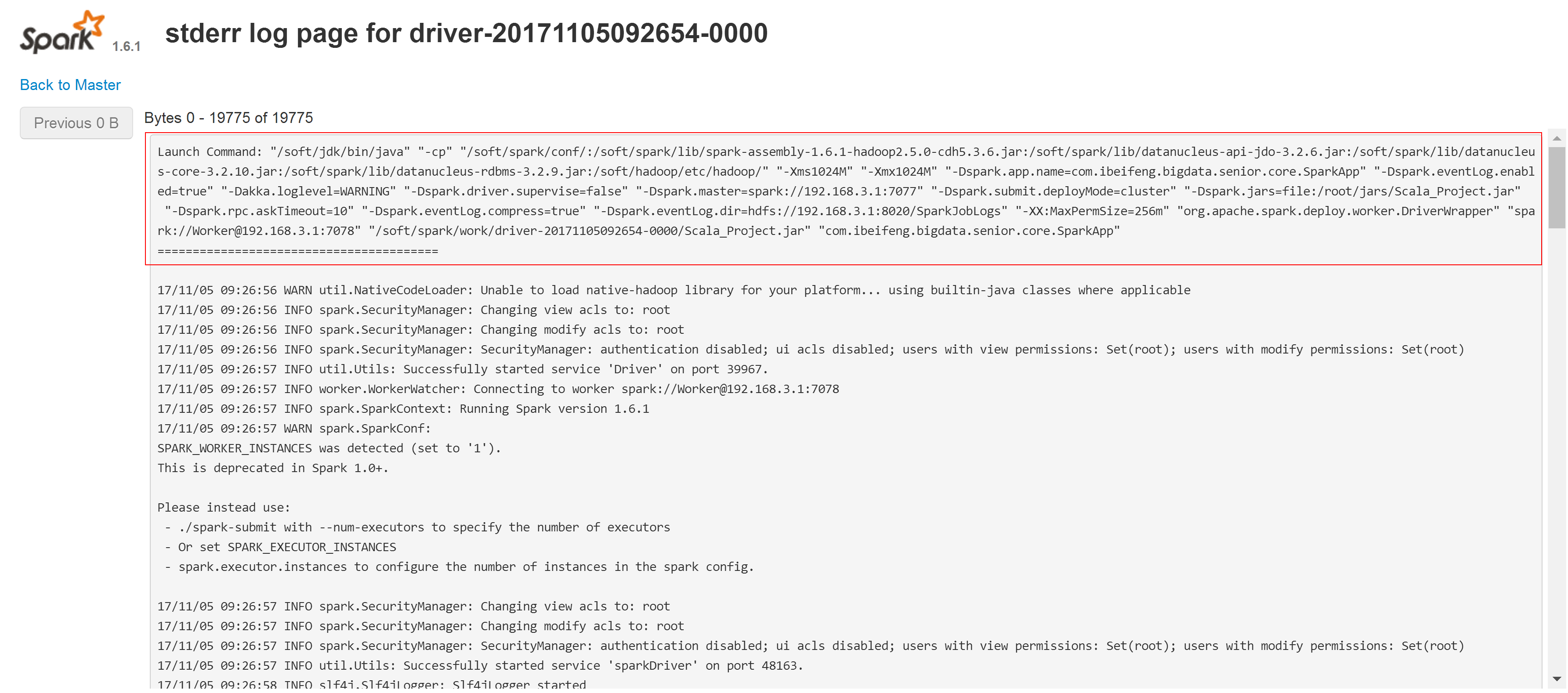
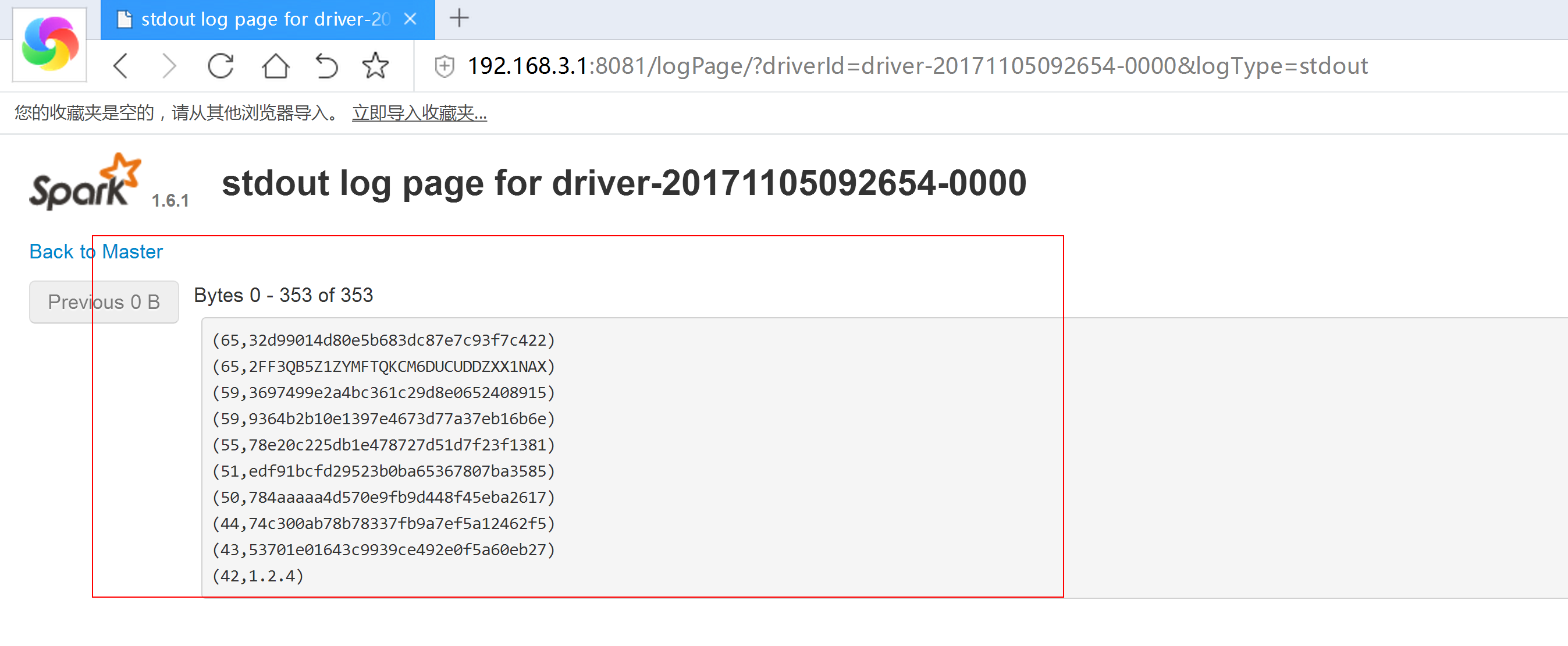
3.5 spark 增加外部依赖jar包的方法
方式一:--jars JARSComma-separated list of local jars to include on the driver and executor classpaths.jar包的位置一定要写决定路径。方式二:--driver-class-pathExtra class path entries to pass to the driver. Note that jars added with --jars are automatically included in the classpath.方式三:SPARK_CLASSPATH配置此环境变量
3.5.1 企业中Spark Application提交,shell 脚本
spark-app-submit.sh:#!/bin/sh## SPARK_HOMESPARK_HOME=/opt/cdh5.3.6/spark-1.6.1-bin-2.5.0-cdh5.3.6## SPARK CLASSPATHSPARK_CLASSPATH=$SPARK_CLASSPATH:/opt/jars/sparkexternale/xx.jar:/opt/jars/sparkexternale/yy.jar${SPARK_HOME}/bin/spark-submit --master spark://hadoop-senior01.ibeifeng.com:7077 --deploy-mode cluster /opt/tools/scalaProject.jar
四:Spark on YARN
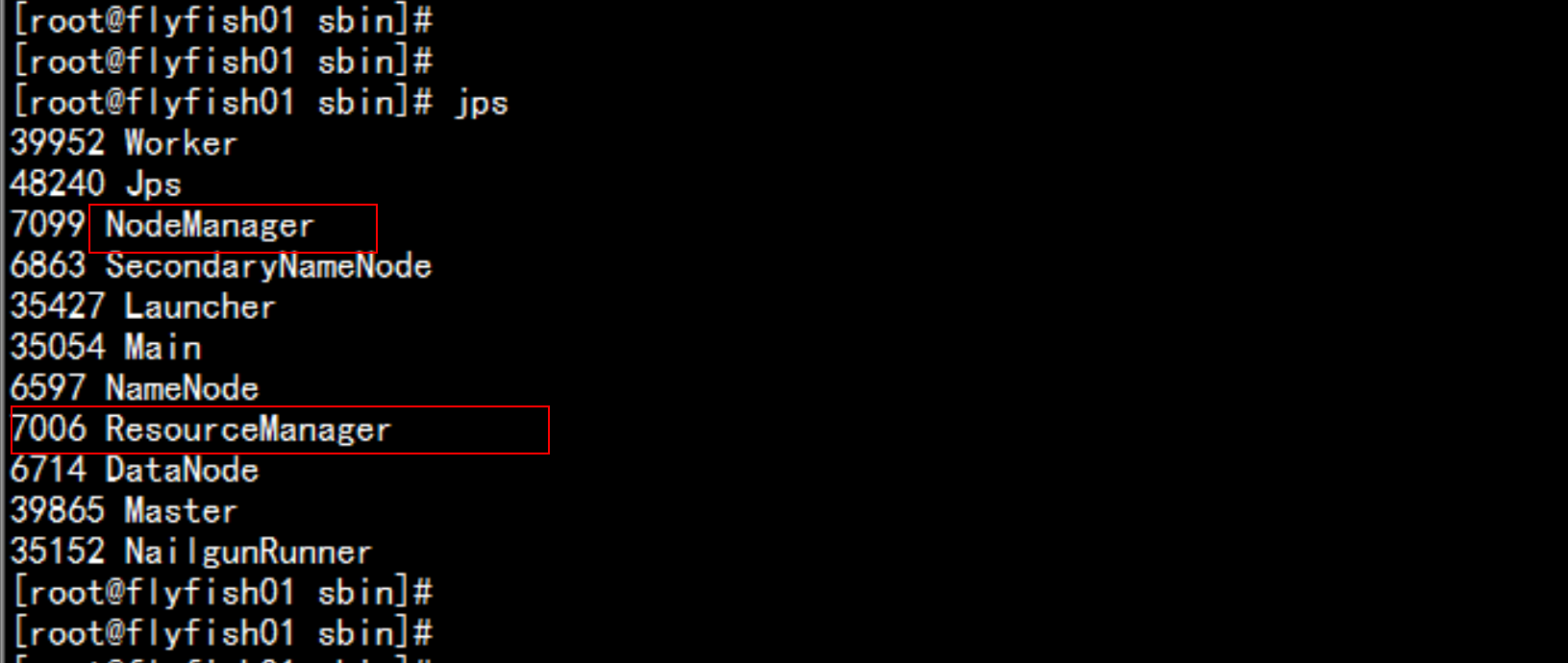
4.1 启动hadoop的YARN上面的服务
cd /soft/hadoop/sbin启动rescouremanager:./yarn-daemon.sh start resourcemanager启动nodemanger:./yarn-daemon.sh start nodemanager
4.2 yarn 的架构
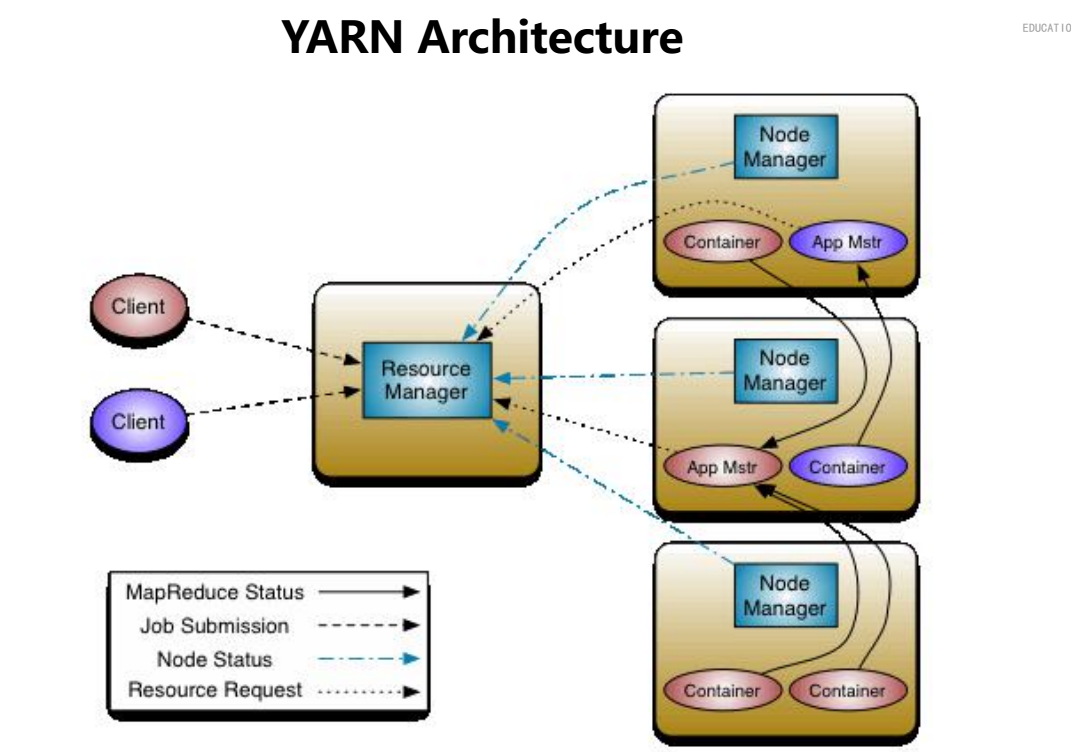
YARN-1,分布式资源管理主节点:ResouceManager从节点:NodeManager -> 负责管理每台机器上的资源(内存和CPU Core)-2,资源调度--1,容器ContainerAM/Task--2,对于运行在YARN上的每个应用,一个应用的管理者ApplicaitonMaster 资源申请和任务调度
4.2 Spark Application
Spark Application-1,Driver Program资源申请和任务调度-2,Executors每一个Executor其实就是一个JVM,就是一个进程以spark deploy mode : clientAM-- 全部都允许在Container中Executor s运行在Container中,类似于MapReduce任务中Map Task和Reduce Task一样Driver -> AM -> RM
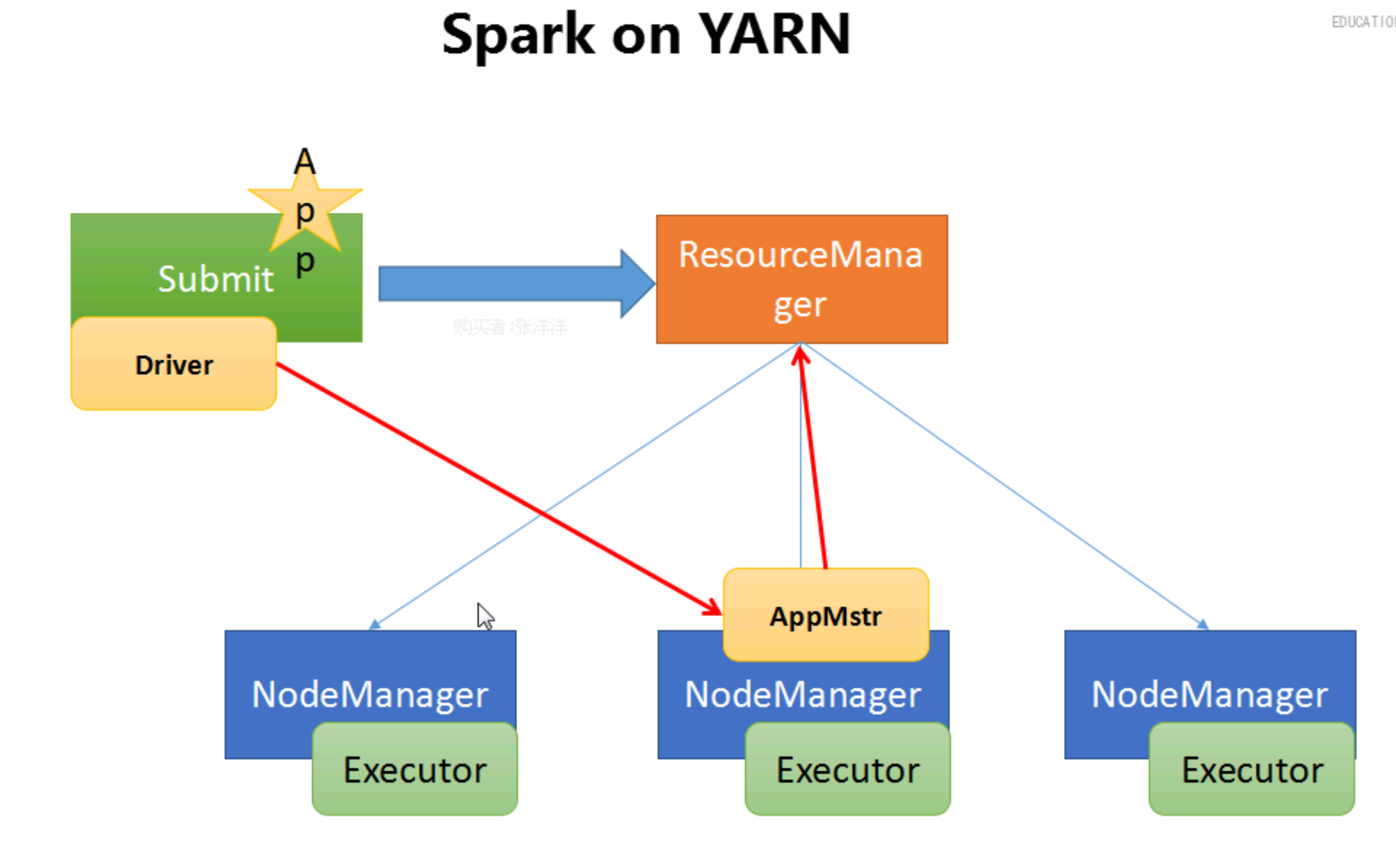
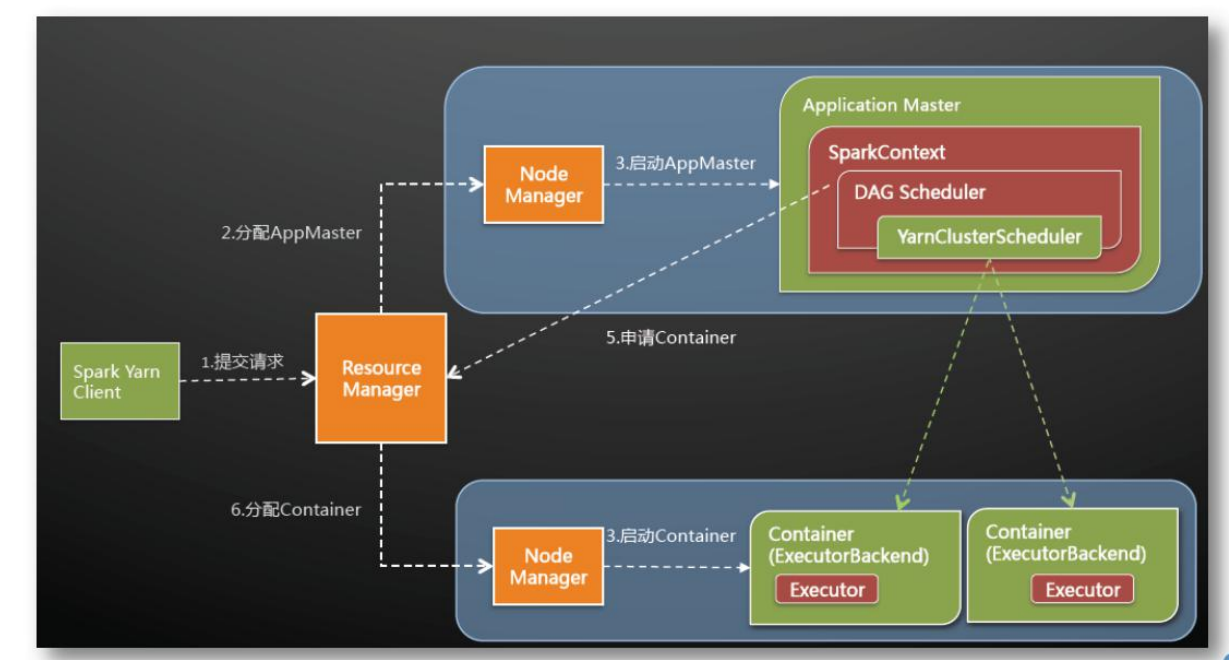
4.3 spark on yarn 的运行
spark-shell --master yarn

4.4 spark job on yarn
cd jars/spark-submit --master yarn --deploy-mode cluster Scala_Project.jar
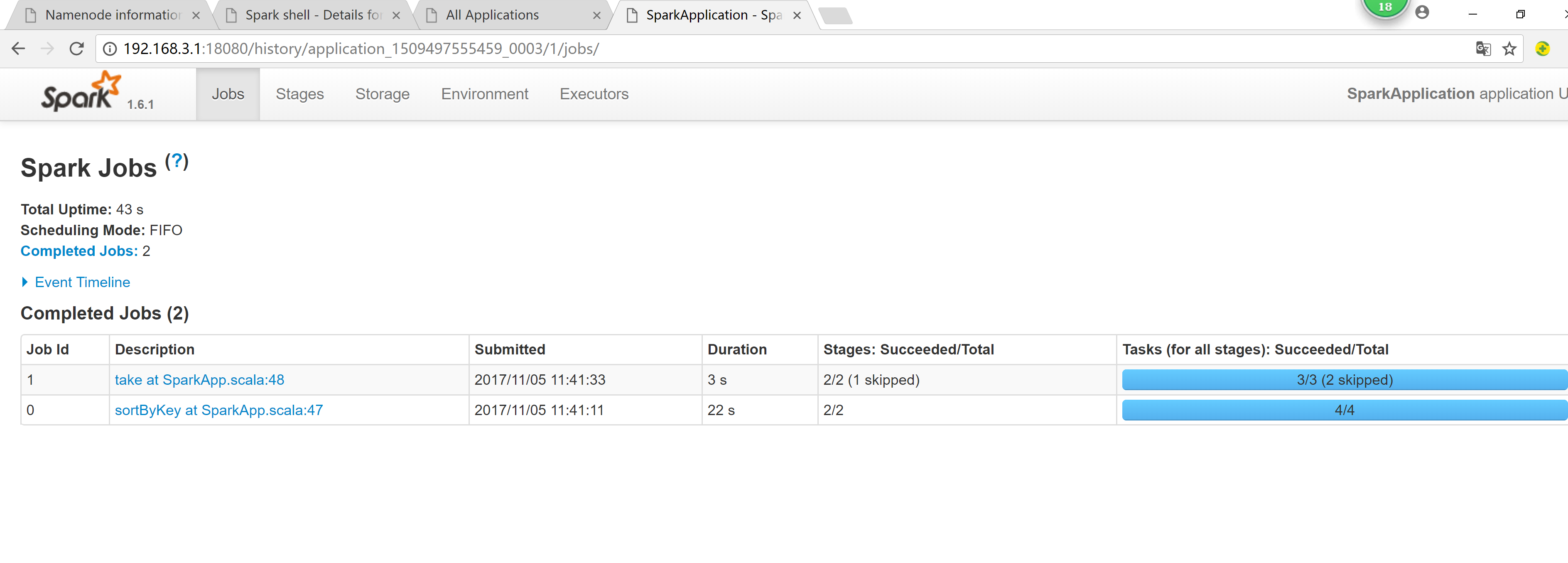
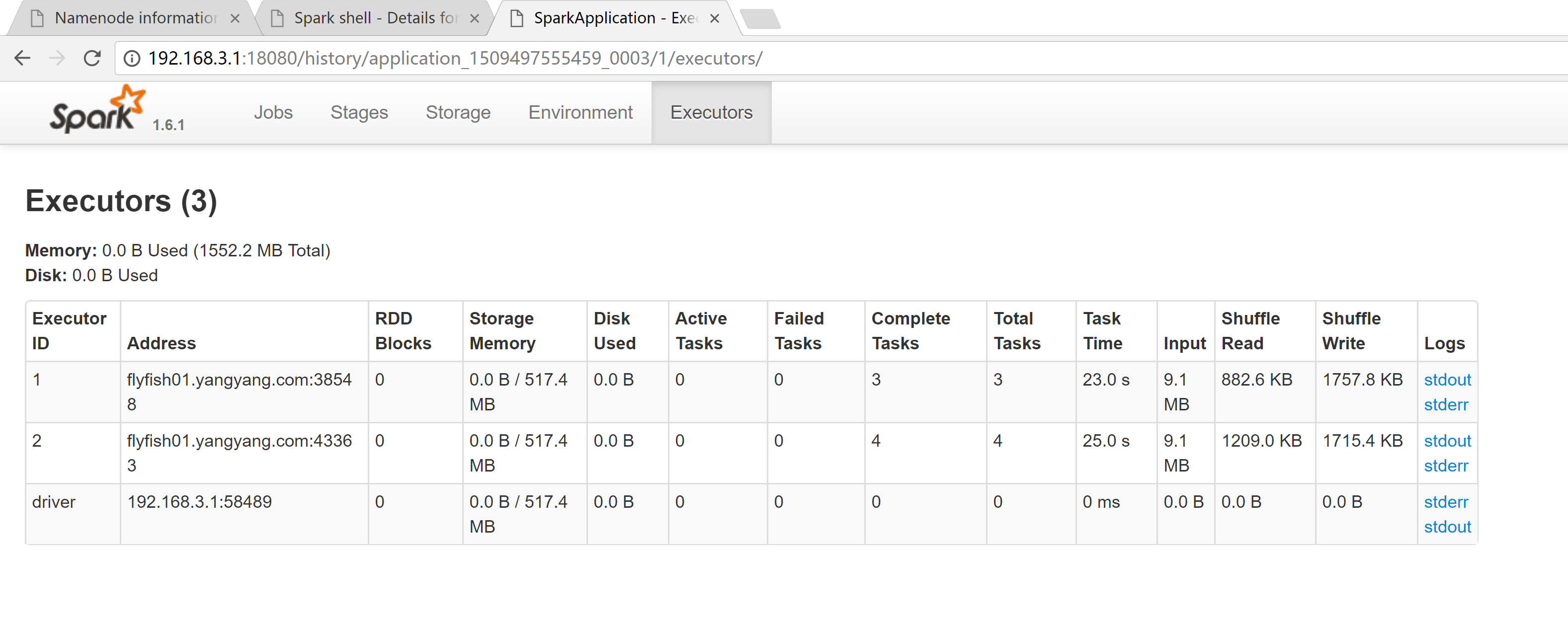
五: spark RDD 的 依赖
5.1 RDD Rependencies
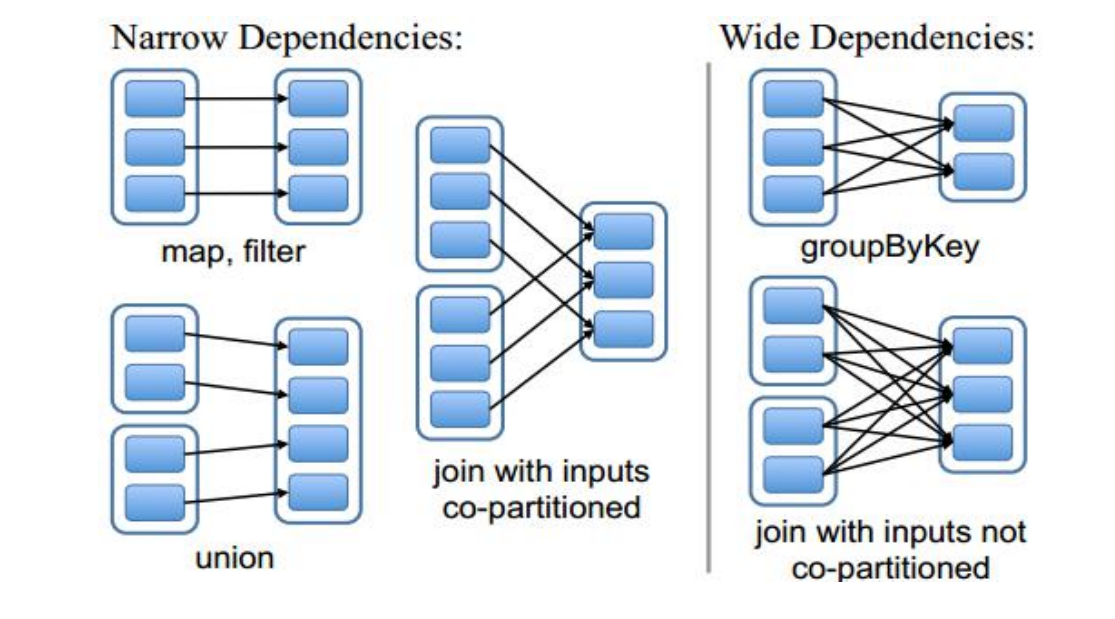
spark的wordcount##val rdd = sc.textFile("/input")##val wordRdd = rdd.flatMap(_.split(" "))val kvRdd = wordRdd.map((_, 1))val wordcountRdd = kvRdd.reduceByKey(_ + _)##wordcountRdd.collect-----------------input -> rdd -> wordRdd -> kvRdd : Stage-01 -> ShuffleMapStage -> SMT->wordcountRdd -> output :Stage-02 -> ResultStage -> ResultTask
1. 窄依赖(narrow dependencies)1.1:子RDD的每个分区依赖于常数个父分区(即与数据规模无关)1.2: 输入输出一对一的算子,且结过RDD 的分区结构不变,主要是map,flatMap1.3:输出一对一,单结果RDD 的分区结构发生变化,如:union,coalesce1.4: 从输入中选择部分元素的算子,如filer,distinct,subtract,sample2. 宽依赖(wide dependencies)2.1: 子RDD的每个分区依赖于所有父RDD 分区2.2:对单个RDD 基于key进行重组和reduce,如groupByKey,reduceByKey2.3:对两个RDD 基于key 进行join和重组,如:join
如何判断RDD之间是窄依赖还是宽依赖:父RDD的每个分区数据 给 子RDD的每个分区数据1 -> 11 -> N : MapReduce 中 Shuffle
5.2 spark 的shuffle
5.2.1 spark shuffle 的内在原理
在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性能高低直接影响了整个程序的性能和吞吐量。Spark作为MapReduce框架的一种实现,自然也实现了shuffle的逻辑。
5.2.2 shuffle
Shuffle是MapReduce框架中的一个特定的phase,介于Map phase和Reduce phase之间,当Map的输出结果要被Reduce使用时,输出结果需要按key哈希,并且分发到每一个Reducer上去,这个过程就是shuffle。由于shuffle涉及到了磁盘的读写和网络的传输,因此shuffle性能的高低直接影响到了整个程序的运行效率。下面这幅图清晰地描述了MapReduce算法的整个流程,其中shuffle phase是介于Map phase和Reduce phase之间。
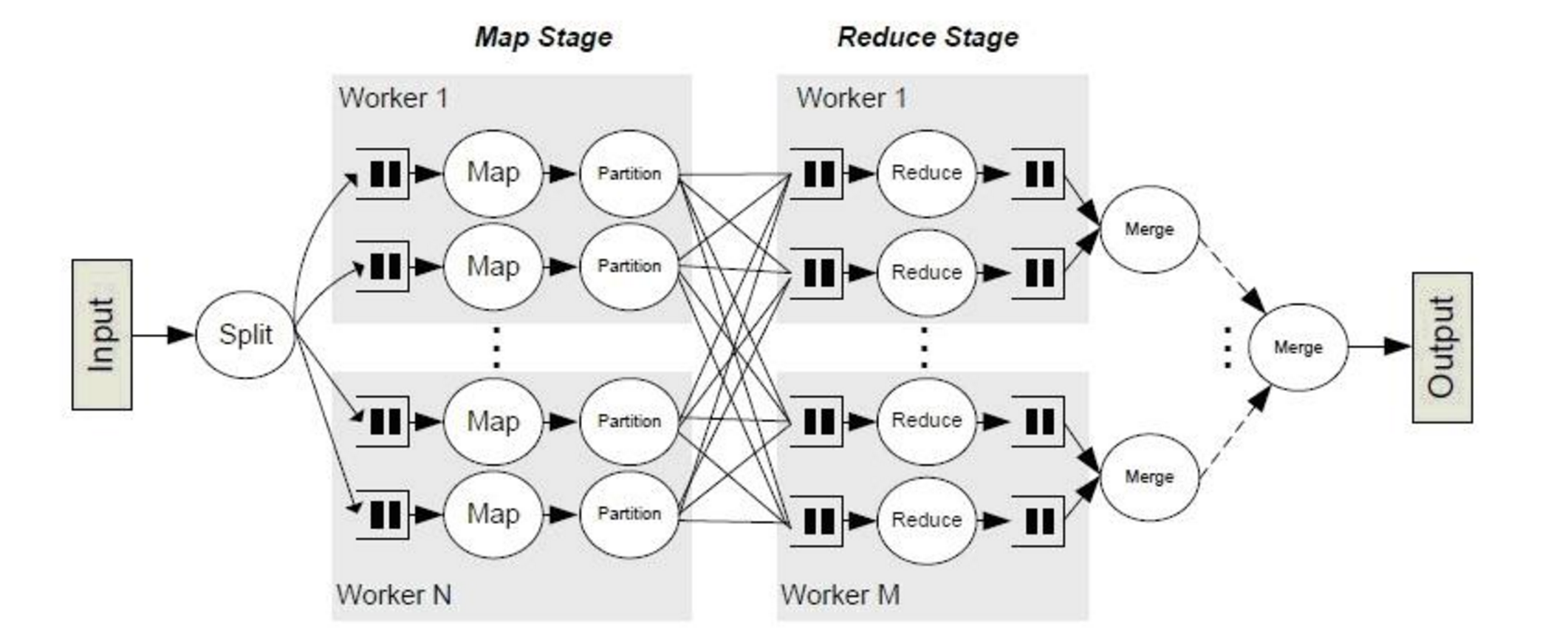
概念上shuffle就是一个沟通数据连接的桥梁,那么实际上shuffle(partition)这一部分是如何实现的的呢,下面我们就以Spark为例讲一下shuffle在Spark中的实现。
5.2.3 spark的shuffle
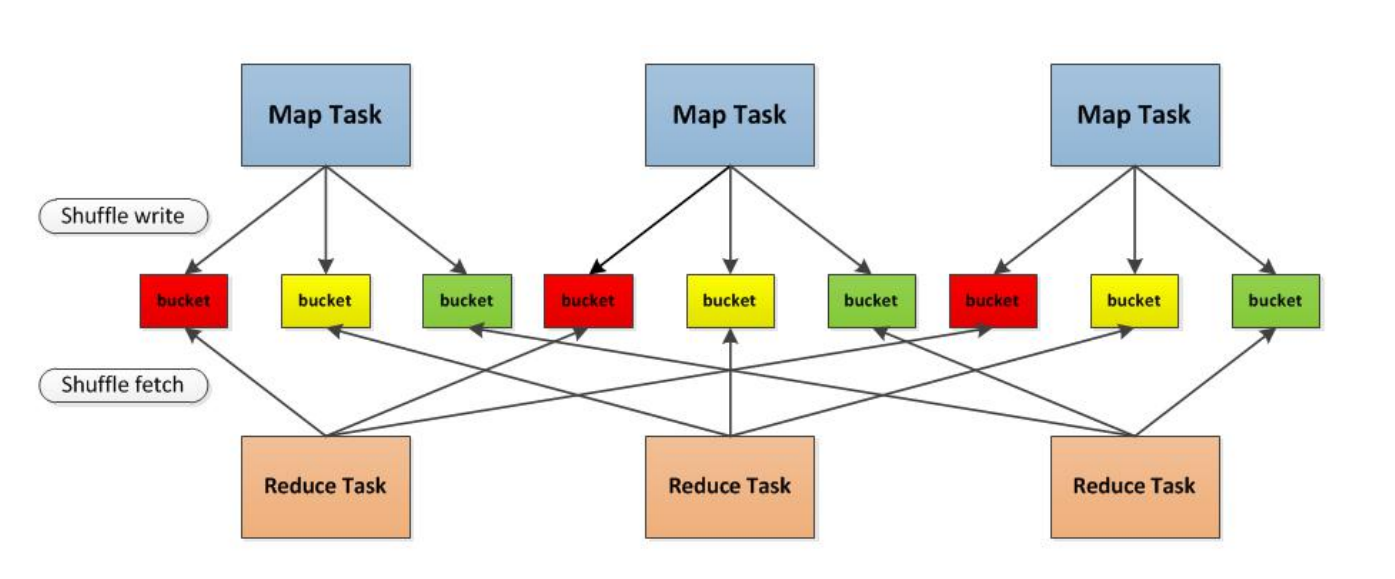
1.首先每一个Mapper会根据Reducer的数量创建出相应的bucket,bucket的数量是M×RM×R,其中MM是Map的个数,RR是Reduce的个数。2.其次Mapper产生的结果会根据设置的partition算法填充到每个bucket中去。这里的partition算法是可以自定义的,当然默认的算法是根据key哈希到不同的bucket中去。当Reducer启动时,它会根据自己task的id和所依赖的Mapper的id从远端或是本地的block manager中取得相应的bucket作为Reducer的输入进行处理。这里的bucket是一个抽象概念,在实现中每个bucket可以对应一个文件,可以对应文件的一部分或是其他等。3. Apache Spark 的 Shuffle 过程与 Apache Hadoop 的 Shuffle 过程有着诸多类似,一些概念可直接套用,例如,Shuffle 过程中,提供数据的一端,被称作 Map 端,Map 端每个生成数据的任务称为 Mapper,对应的,接收数据的一端,被称作 Reduce 端,Reduce 端每个拉取数据的任务称为 Reducer,Shuffle 过程本质上都是将 Map 端获得的数据使用分区器进行划分,并将数据发送给对应的 Reducer 的过程。
那些操作会引起shuffle1. 具有重新调整分区操作,eg: repartition,coalese2. *ByKey eg: groupByKey,reduceByKey3. 关联操作 eg:join,cogroup
