@zhangyy
2016-05-20T03:13:10.000000Z
字数 2175
阅读 583
hive 的udf 函数处理
大数据系列
- 1)依据课程讲解UDF编程案例,完成练习,总结开发UDF步骤,代码贴图,给予注释,重点
- 2)更改emp 表中名字的大写给为小写。
一:hive 的udf 函数:
- hive UDF 函数概述:
- hive自带了一些函数比如:max/min 等,但是由于自带的函数数量有限,自己可以定义udf来方便扩展。
- udf 函数可以直接应用于select 语句,对查询结构做格式化处理之后,然后再输出内容。
- hive 编写udf函数的时候需要注意的地方:
- 自定义udf函数需要继承org.apache.hadoop.hive.ql.UDF
- 需要实现evaluate 函数,evaluate 函数支持重载。
- udf 必须要有返回类型,可以返回null,但是返回类型不能为void;
- udf 常用Text/LongWrite 等类型,不推荐使用java类型。
hive 的udf 函数编写:
- 环境配置处理:
更改repository源
cd .m2/mv repository repository.bak上传新的repository.tar.gz 包。tar -zxvf repository.tar.gz备份原有setting.xml 文件cp -p setting.xml setting.xml.bakcd /home/hadoop/yangyang/maven/confcp -p setting.xml setting.xml
更改maven源的配置:
在setting.xml 中<mirrors> ....</mirrors> 之间增加新的源仓库:<mirror><id>nexus-osc</id><mirrorOf>central</mirrorOf><name>Nexus osc</name><url>http://maven.oschina.net/content/groups/public/</url></mirror>拷贝新的setting文件到maven 的配置文件中cp -p .m2/setting.xml /home/hadoop/yangyang/maven/conf
更改eclipse的pom.xml 文件增加:
在原有的<dependencies>....</dependencies> 之间加上hive 的参数:<dependency><groupId>org.apache.hive</groupId><artifactId>hive-jdbc</artifactId><version>0.13.1</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>0.13.1</version></dependency></dependencies>
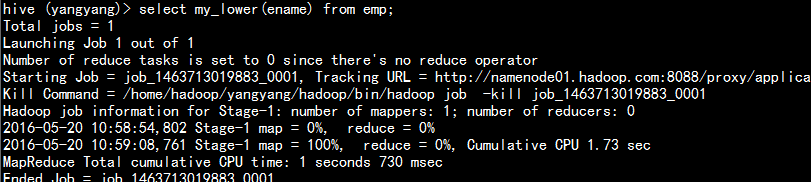
二: 更改emp 表中名字的大写给为小写。
新建UDF包:
编写lowerudf.java
package org.apache.hadoop.udf;import org.apache.commons.lang.StringUtils;import org.apache.hadoop.hive.ql.exec.UDF;import org.apache.hadoop.io.Text;/*** New UDF classes need to inherit from this UDF class.*/public class LowerUDF extends UDF{/*** 1. Implement one or more methods named "evaluate" which will be called by Hive.** 2. "evaluate" should never be a void method. However it can return "null" if needed.*/public Text evaluate(Text str){// input parameter validateif(null == str){return null ;}// validateif(StringUtils.isBlank(str.toString())){return null ;}// lowerreturn new Text(str.toString().toLowerCase()) ;}public static void main(String[] args) {System.out.println(new LowerUDF().evaluate(new Text()));}}
导出jar包 到/home/hadoop/yangyang/hive/jars 下面:
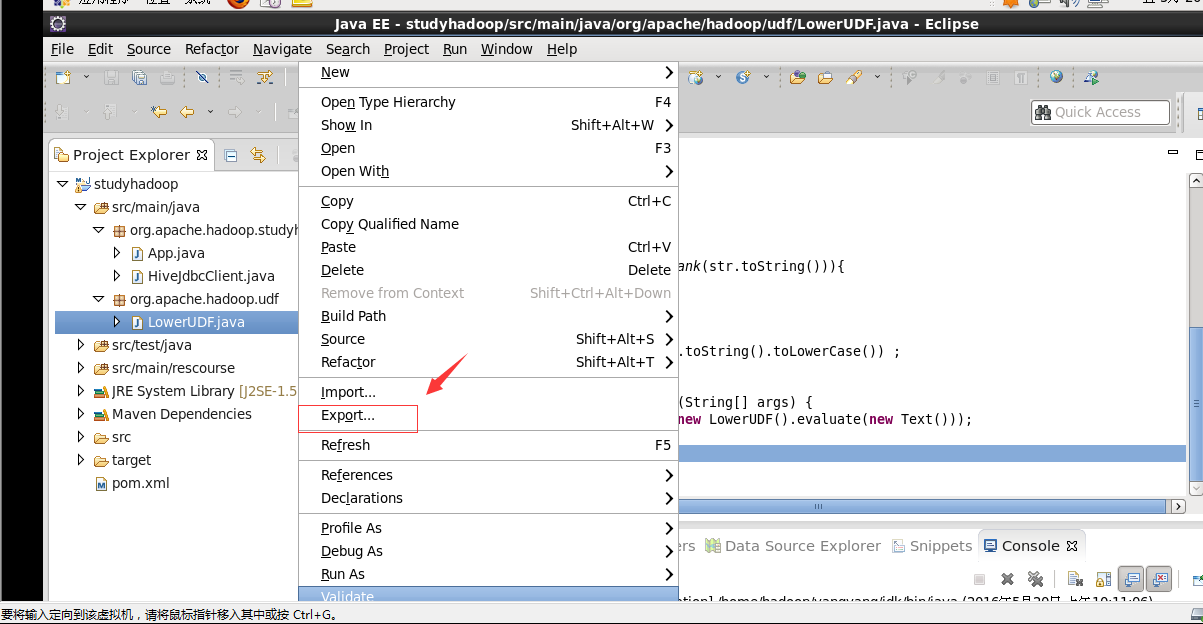
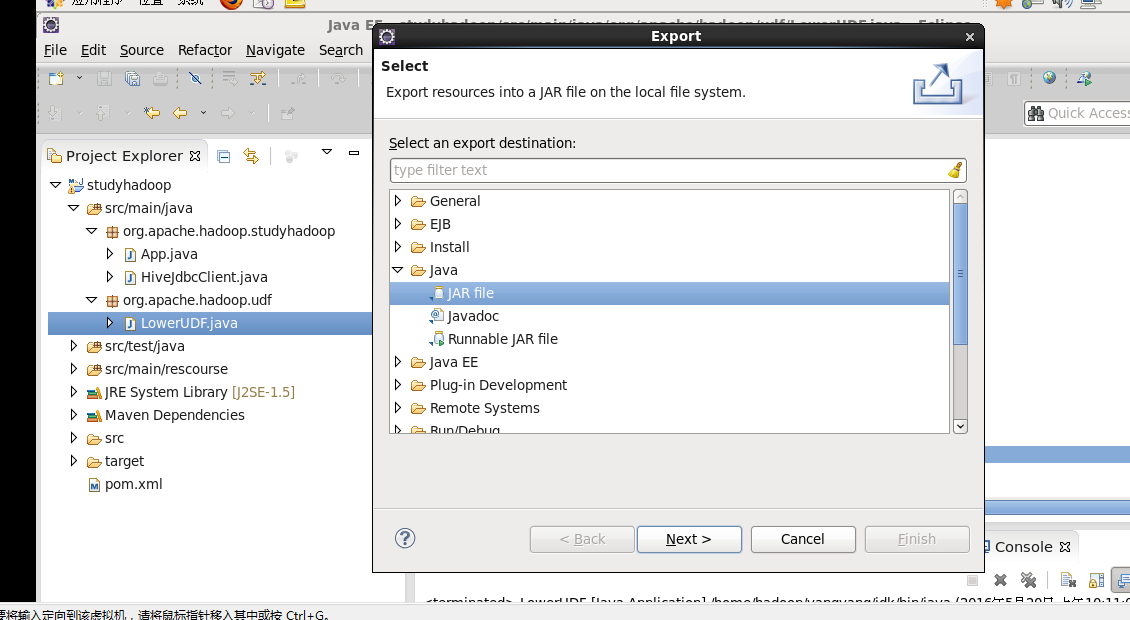
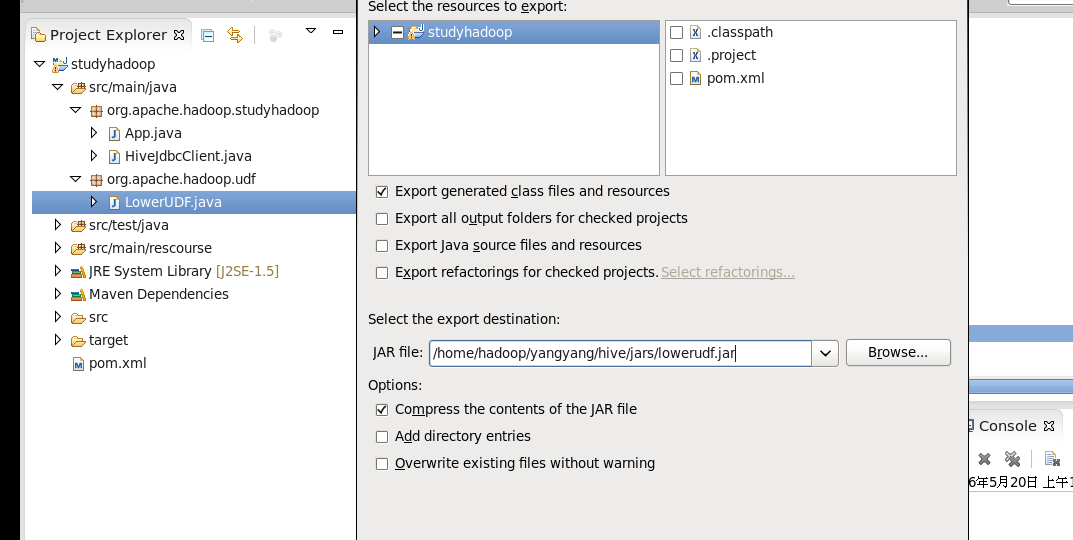


执行lowerudf 包:
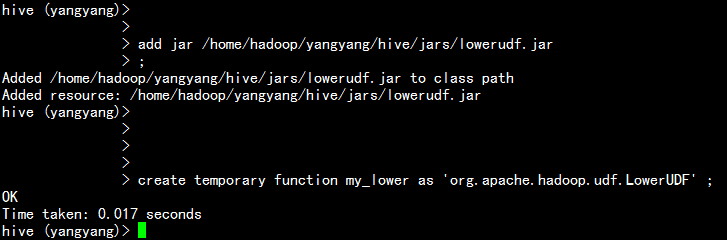
增加jar包与hive的关联:
add jar /home/hadoop/yangyang/hive/jars/lowerudf.jarcreate temporary function my_lower as 'org.apache.hadoop.udf.LowerUDF' ;show functions;

销毁临时的udf 函数:
drop temporary function add_example;<!--这里指my_lower 函数-->
执行my_lower 函数:
select my_lower(ename) from emp;