@zhangyy
2020-09-21T02:14:58.000000Z
字数 2847
阅读 662
CDH 6.3.2 开启kerberos 遇到 的坑
大数据运维专栏
- 一: 关于安装系统的一些坑
- 二: 关于 开启Kerberos Java 的 一些坑
- 三: 关于hive
一: 关于 安装系统的一些坑
1) 安装之前一定 确认 jdk 的安装 目录 因为 通过 centos 7 这个系统 默认会 在装之前 会自带 一些 jdk 版本 要彻底卸载 这个 jdk , 最好是保证安装系统之前 自装 最简 的centos 7.5 x64 mini2 ) 系统最好 分区为三个/swap/boot千万不要用 LVM 分区 与启用raid产线存储数据(DN)盘 另外加
二:关于 开启Kerberos Java 的 一些坑
1) 安装cloudera-manger 有安装依赖包yum -y install chkconfig python bind-utils psmisc libxslt zlib sqlite cyrus-sasl-plain cyrus-sasl-gssapi fuse fuse-libs redhat-lsb postgresql* portmap mod_ssl openssl-devel python-psycopg2 MySQL-python执行 完这个步骤 之后 有 jdk 安装要卸载这个 jdk 保证 系统的jdk 为自己安装的jdk 在安装 CDH 6.3.2保证CDH 的 环境 有一个JDK 存在,并且是 自己安装的2) 20/05/29 09:13:18 WARN security.UserGroupInformation: Not attempting to re-login since the last re-login was attempted less than 60 seconds before. Last Login=1590714794874这个报错是开启的Kerberos 的jdk 缺少 应用因为系统采用的是Centos7.6,对于使用Centos5.6及以上系统,默认采用 AES-256 来加密;这就需要CDH集群所有的节点都安装 Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy File需要下载 jdk 8 的JCE 来覆盖下载链接:https://www.oracle.com/technetwork/java/javase/downloads/index.htmlJAVA_HOME=/usr/java/jdk1.8.0_161-clouderacp UnlimitedJCEPolicyJDK8/*.jar /usr/java/jdk1.8.0_161-cloudera/jre/lib/security/然后 从新启动CDH6.3.2的集群
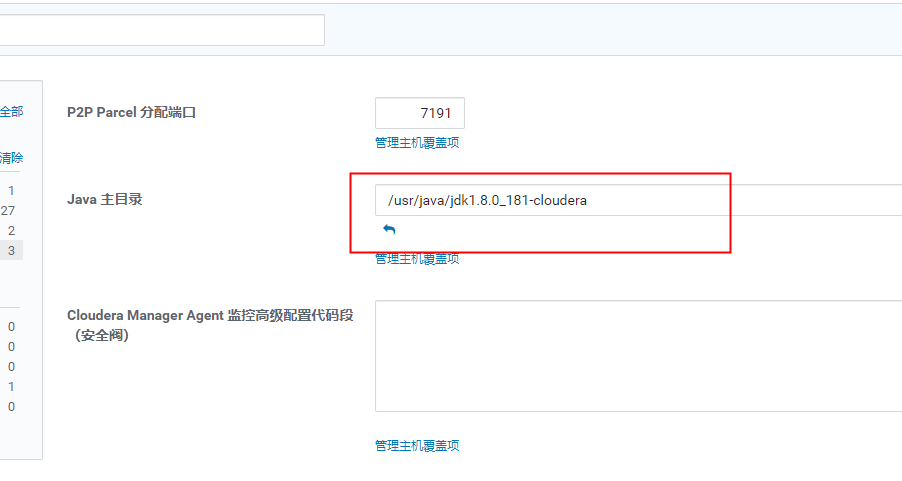
3) 确认CDH6.3.2 集群 是 当前 安装的jdk 这个 不然开启Kerberos 会报错所有主机 --》 配置--高级--》 设置Java 的环境目录然后从新 启动 整个 CDH 集群
三: 关于 那个 新建用户的提交任务的坑
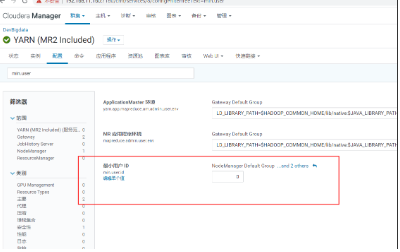
1. 新建用户提交job----1)保证所有节点 都有这个用户 没有就用useradd 去建立useradd flyfish2) 保证Kerberos 的 krb5admin 库有 principal 库有 这个 账号kadmin.localaddprinc flyfish@LANXIN.COM输入密码 然后使用kinit 登录 没有问题才可以之后导出这个keytabkadmin.localxst -kt /root/flyfish.keytab -norandkey flyfish@LANXIN.COM这里面会有涉及那个Kerberos 导出keytab 过期问题要 一定要加一个 -norandkey 参数kinit -kt /root/flyfish.keyab flyfishklist3)在yarn上面提交任务必须 userid 小与 1000----

是由于Yarn限制了用户id小于1000的用户提交作业;解决方法:修改Yarn的min.user.id来解决
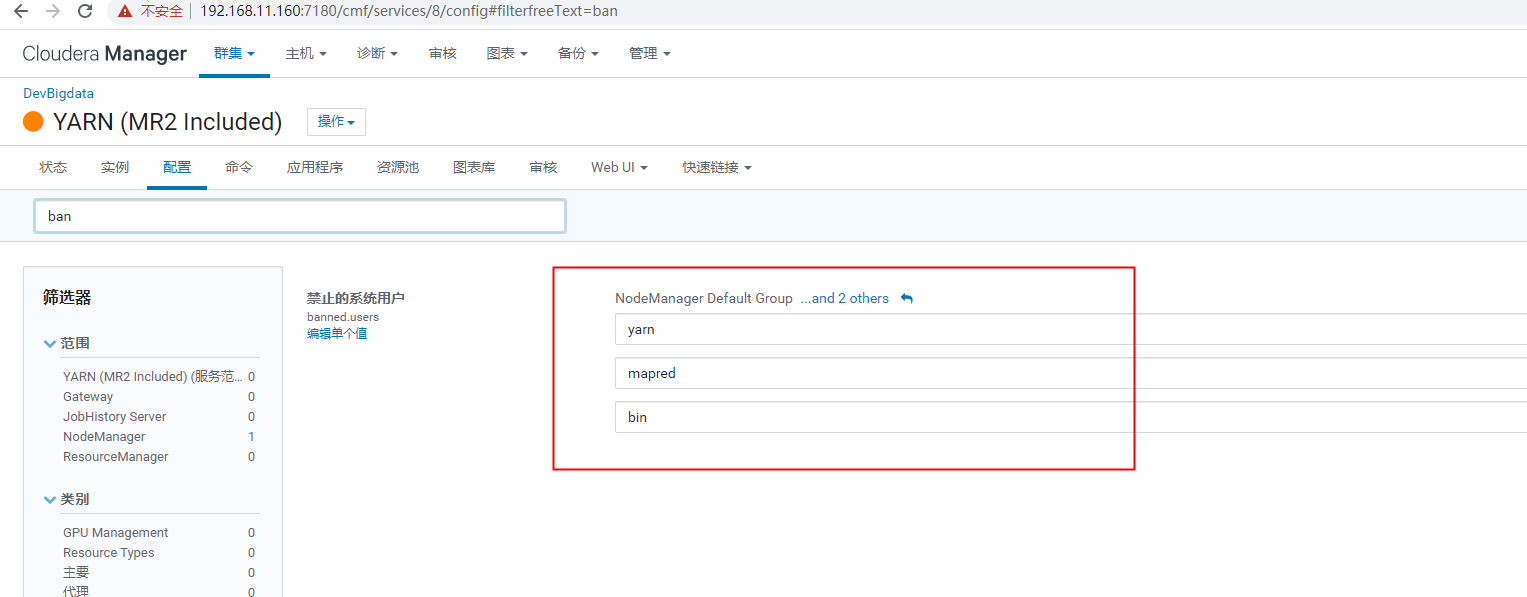
2.异常信息:Diagnostics: Application application_1504017397148_0002 initialization failed (exitCode=255) with output: main : command provided 0main : run as user is hdfsmain : requested yarn user is hdfsRequested user hdfs is not whitelisted and has id 986,which is below the minimum allowed 1000-------以上报错是因为 CDH 不给以 hdfs 这个用户 提交 任务 所以要给予 hdfs 的这个用户 提交 任务 的权限取消掉 hdfs 的 禁用 拿掉
错误:FATAL org.apache.hadoop.hdfs.server.namenode.NameNode Exception in namenode join java.io.IOException There appears to be a gap in the edit log这个一般是Hadoop HDFS HA 出现问题fsimage 损坏出现 问题 会报这个错误如果在CDH中的 HDFS HA 散架崩溃 出现问题1) 下架 问题 namenode节点2) 第二步 会出现 以上 fsimage 问题先把元数据fsimage 的问题节点 进行 备份 就是 安装 大数据CDH 平台时候 namenode的NN 目录生成文件一般是 /dfs/nn 这个目录3) namenode元数据被破坏,需要修复hdfs namenode –recover一路选择c,一般就OK了
hive 中的 坑:AnalysisException: Failed to load metadata for table: 'dw_pay_report_results.t_pay_report_credit_paopi_pay' CAUSED BY: TableLoadingException: Failed to load metadata for table: dw_pay_report_results.t_pay_report_credit_paopi_pay CAUSED BY: IllegalArgumentException: java.net.UnknownHostException: ns1 CAUSED BY: UnknownHostException: ns1这个是 因为 HDFS HA 出现 散架 配置 这个时候 一般要 从新 CDH 上面 配置 HA 在启动 配置 并命名 为 ns1 的HA 然后跟新 hive 的 metastore可以查看 metastore 中的 mysql 中 DBS 与 SDS 两表中设置了 Hive的元数据信息 需要修改此表。
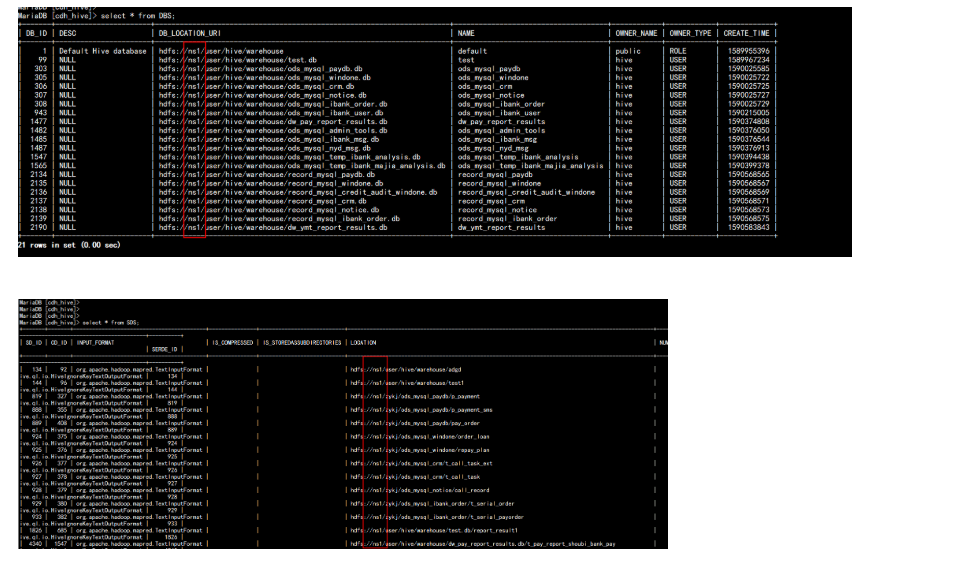
第一种方法是将 这些 ns1 全部 改掉 这种 方法 一般 用在 apache 的版本 部署的Hadoop 因为 启用 HA 配置比较麻烦第二种方法就是在CDH 中 再次启动 HA 然后 跟新 hive 的metastore更新hive metastore 一般是在 启用 hdfs HA 之后1) 启用 hdfs HA 之后2) 启用 hive 的metastore 更新先停掉 hive
然后更新然后从新启动 hive