@zhangyy
2016-04-28T02:39:14.000000Z
字数 2966
阅读 548
画图加文件讲解MapReduce的shuffle 过程
大数据系列
- Map shuffle 主要做了哪些事? 哪些可以设置及如何设置
- Reduce shuffle 主要做了哪些事? 那些可以设置及如何设置
- 在shuffle阶段中的Combiner 如何理解作用?
- MapReduce 执行过程中中间数据的压缩配置
1. Map shuffle 主要做了哪些事? 哪些可以设置及如何设置
1.1 map 端的shuffle ,map task 任务
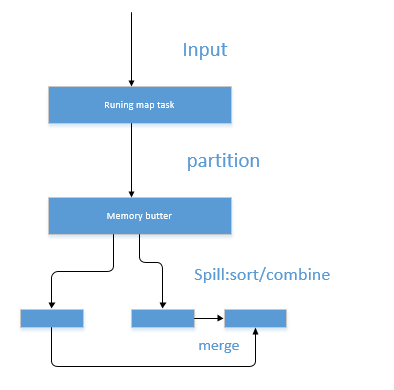
- 1.1.1 在map task执行时,它的输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取split。Split与block的对应关系可能是多对一,默认是一对一。如:在WordCount例子里,假设map的输入数据是 “yangyang”这样的字符串。
- 1.1.2 在经过mapper的运行后,我们得知mapper的输出是这样一个key/value对: key是可以是一个字符串,value是数值1。因为当前map端只做加1的操作,在reduce task里才去合并结果集。
MapReduce提供Partitioner接口,它的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个 reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
例如: 输入wordcount 输入的字符串为"yangyang"
“yangyang”经过Partitioner后返回0,也就是这对值应当交由第一个reducer来处理。接下来,需要将数据写入内存缓冲区 中,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之 前,key与value值都会被序列化成字节数组。
注: 整个内存缓冲区就是一个字节数组
内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过 程被称为Spill,中文可译为溢写,字面意思很直观。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map 的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。
2. Reduce shuffle 主要做了哪些事? 哪些可以设置及如何设置 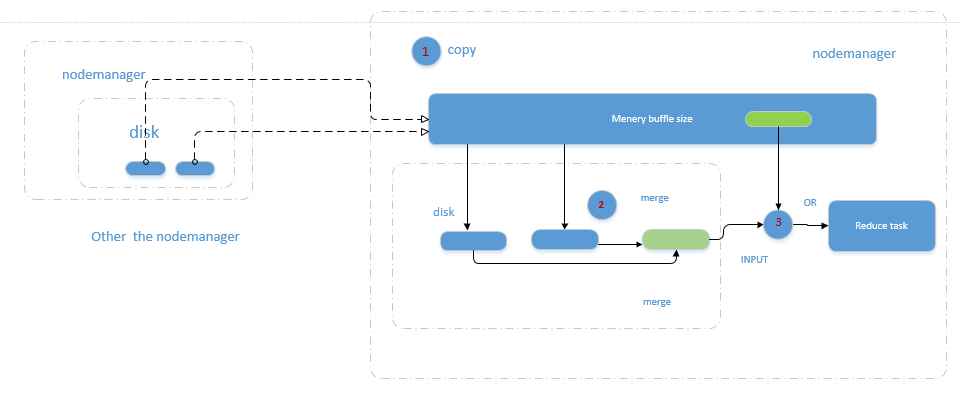
2.1 整个Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的nodemanager获取map task的输出文件。因为map task早已结束,这些文件就归nodemanager管理在本地磁盘中。
2.2 Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区 中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形 式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,让人比较困惑,当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运 行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
2.3 Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。这个文件可能存在于磁盘上,也可能存在于内存中。对我们 来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。至于怎样才能让这个文件出现在内存中,之后的性能优化篇我再说。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
注: Shuffle在reduce端的过程。当前reduce copy数据的前提是它要从resourcemanager获得有哪些map task已执行结束,Reducer真正运行之前,所有的时间都是在拉取数据,做merge,且不断重复地在做。
3.在shuffle阶段中的Combiner 如何理解作用?
- 3.1 将有相同key的key/value对的value加起来,减少溢 写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。所以从我的想法来看,Combiner只应该用于那种 Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定 得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
4. MapReduce 执行过程中中间数据的压缩配置
- 4.1.输入的文件的压缩
如果输入的文件是压缩过的,那么在被mapreduce读取时,它们会被自动解压 - 4.2.mapreduce作业的输出的压缩
如果要压缩mapreduce作业的输出,请在作业配置文件中将mapred.output.compress属性设置为true。将mapred.output.compression.codec属性设置为自己打算使用的压缩编码/解码器的类名。
如果为输出使用了一系列文件,可以设置mapred.output.compression.type属性来控制压缩类型,默认为record,它压缩单独的记录。将它改为block,则可以压缩一组记录。由于它有更好的压缩比。 - 4.3.map作业输出结果的压缩
即使mapreduce应用使用非压缩的数据来读取和写入,我们也可以受益于压缩map阶段的中间输出。因为map作业的输出会被写入磁盘并通过网络传输到reducer节点,所以如果使用lzo之类的快速压缩,能得到更好的性能,因为传输的数据量大大减少了。以下代码显示了启用rnap输出压缩和设置压缩格式的配置属性。
conf.setcompressmapoutput(true);
conf.setmapoutputcompressorclass(gzipcodec.class);
