@zhangyy
2020-09-15T23:15:48.000000Z
字数 7255
阅读 1137
Prometheus监控实战(二)
Prometheus系列
一、Prometheus的度量类型(metric types)
在学习Prometheus的常用函数前,我们得先知道Prometheus的几度量类型,然后才能使用相应的函数来进行计算。不知道大家有没有注意到,Prometheus从exporter抓取的每一个指标均是有注释度量类型的,例如,我们来查看node_exporter的度量指标,curlhttp://xxx.xxx.xxx.xxx:9100/metrics。
1.1 Counter(计数器类型)
Counter类型的指标代表的是一种计数器,是随时间只增不减永远不会减少(除非系统或者服务发生了重置)的。Counter一般用于累计值,例如记录请求次数,任务完成数、错误发生次数;还可以计算其在一段时间范围内的增量和变化速率,如果是counter类型的数据,首先应该想到是否要使用rate()或者increase()函数来计算其变化速率。不是Counter类型的度量却当做Counter类型来计算,会得到一个错误的结果。例如,使用计数器来计算当前正在运行的进程的数量;应该使用Gauge。
1.2 Gauge(仪表测量类型)
Gauge类型的指标值是可增可减的,可以用于反应当前应用的状态。比如在监控主机时,主机当前的内存大小(node_meomory_MemFree),可用内存大小(node_memory_MemAvailable)。或者主机CPU使用率,内存使用率,温度等。
1.3 Histogram(直方图类型)
Histogram是对数据进行采样的指标类型,用来展示数据集的频率分布。Histogram是表示数值分布的图形,它将数值分组到一个一个的bucket当中,然后计算每个bucket中值出现次数。在Histogram上,X轴表示表示数值的范围(例如人的身高/网站请求响应时间),Y轴表示对应数值出现的频次(对应身高/响应时间出现的次数)。在直方图上,对于各数值出现的次数,分布是否对称都显示的很清楚(对于这类数据如果只是简单的对数值取最小、最大或平均是没有多大意义的)。统计学上有一个段子是说:一个统计学家非常自信地去趟一条平均深度只有1米的河,后来他淹死了(类似把互联网大佬的身家和自己来平均一下)。这是取平均值的一个严重缺陷。
1.4 Summary(摘要类型)
Summary类型和Histogram类型相似,主要也用于表示一段时间内数据采样(通常是请求持续时间或响应时间)结果,它直接存储了quantile(分位数)数据,而不是根据统计区间计算出来的。什么是分位数?大家可度娘一下。总之,分位数能更好地表示数值的分布,也可以找出异常数值,便于优化。Summary与Histogram相比,区别如下:都包含 < basename>_sum和< basename>_count;Histogram需要通过< basename>_bucket计算quantile,而Summary直接存储了 quantile的值。用例:# 事件发生总的次数# 事件产生的值的总和# 事件产生的值的分布情况
二、Prometheus查询语法
常用表达式:fun(metric_name{Instant vector selectors}[Range Vector Selectors])Prometheus提供了一种名为PromQL (Prometheus查询语言)的功能查询语言,该语言允许用户实时选择和聚合时间序列数据。查询的结果可以显示为图表,如在Prometheus本身内置的Web控制台展示,又或者使用诸如Grafana数据展示工具。
1、瞬时向量选择器(Instant vector selectors)可以即时为每个度量选择一个样本值(最近的一个值),最简单的形式就是只给定度量名称,这样将返回所有包含此度量名称的时间序列元素的瞬时向量。可以通过在度量名称后的大括号{}中附加以逗号分隔的标签匹配器列表来进一步筛选这些时间序列。在PromQL中,使用以下符号对标签值进行正则匹配:= (等于),标签的值必须相等,并且区分大小写。!=(不等于),标签的值必须不相等,并且区分大小写。=~(模糊匹配),标签的值正则(模糊)匹配。!~(模糊匹配取反),标签的值正则(模糊)匹配后取反。
2、范围向量选择器(Range Vector Selectors)与瞬时向量类似,只是它从当前瞬间选择一个样本范围。从语法上讲,范围向量所持续的时间是放在瞬时向量选择器末尾的中括号[]中,用来获取指定的时间间隔内瞬时向量的所有值。
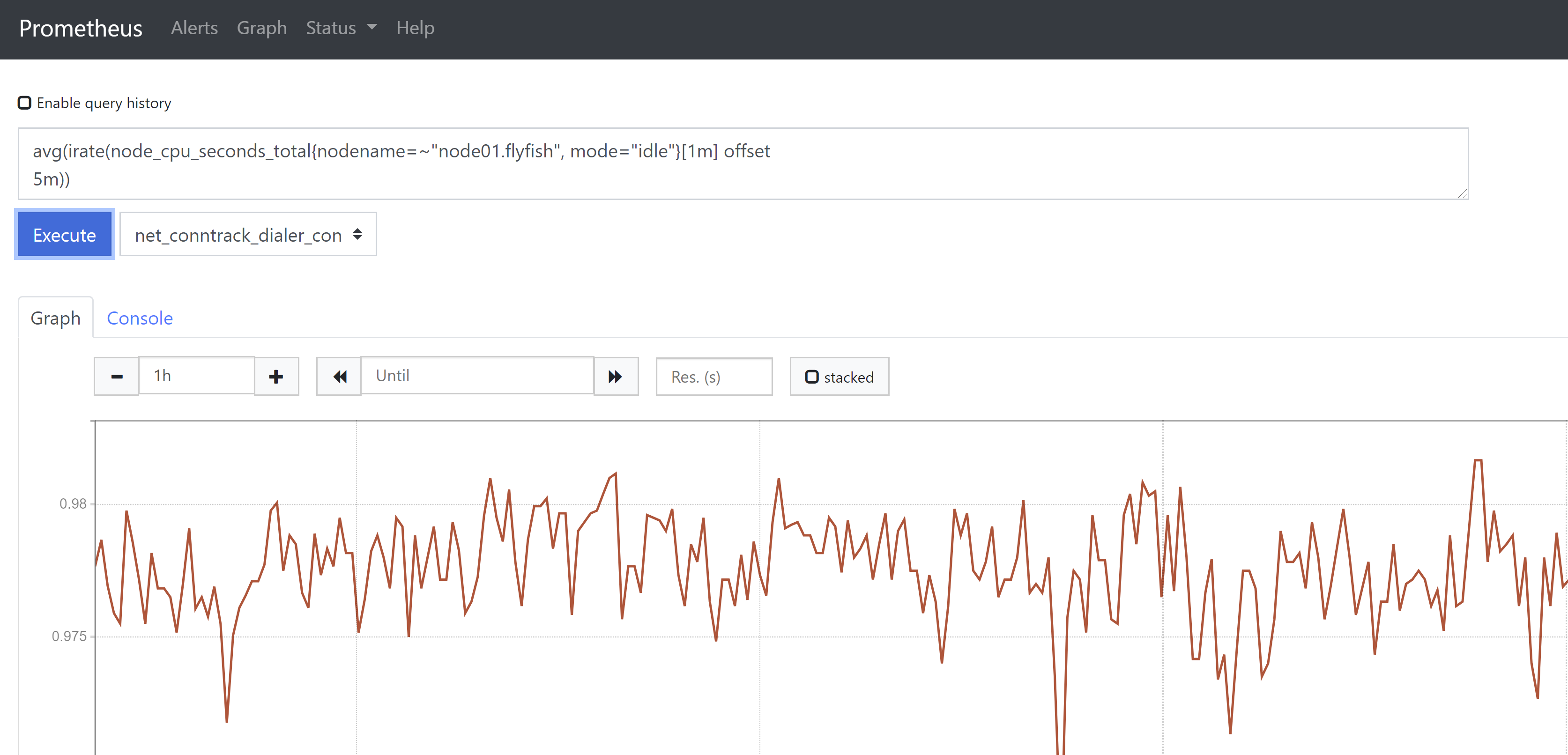
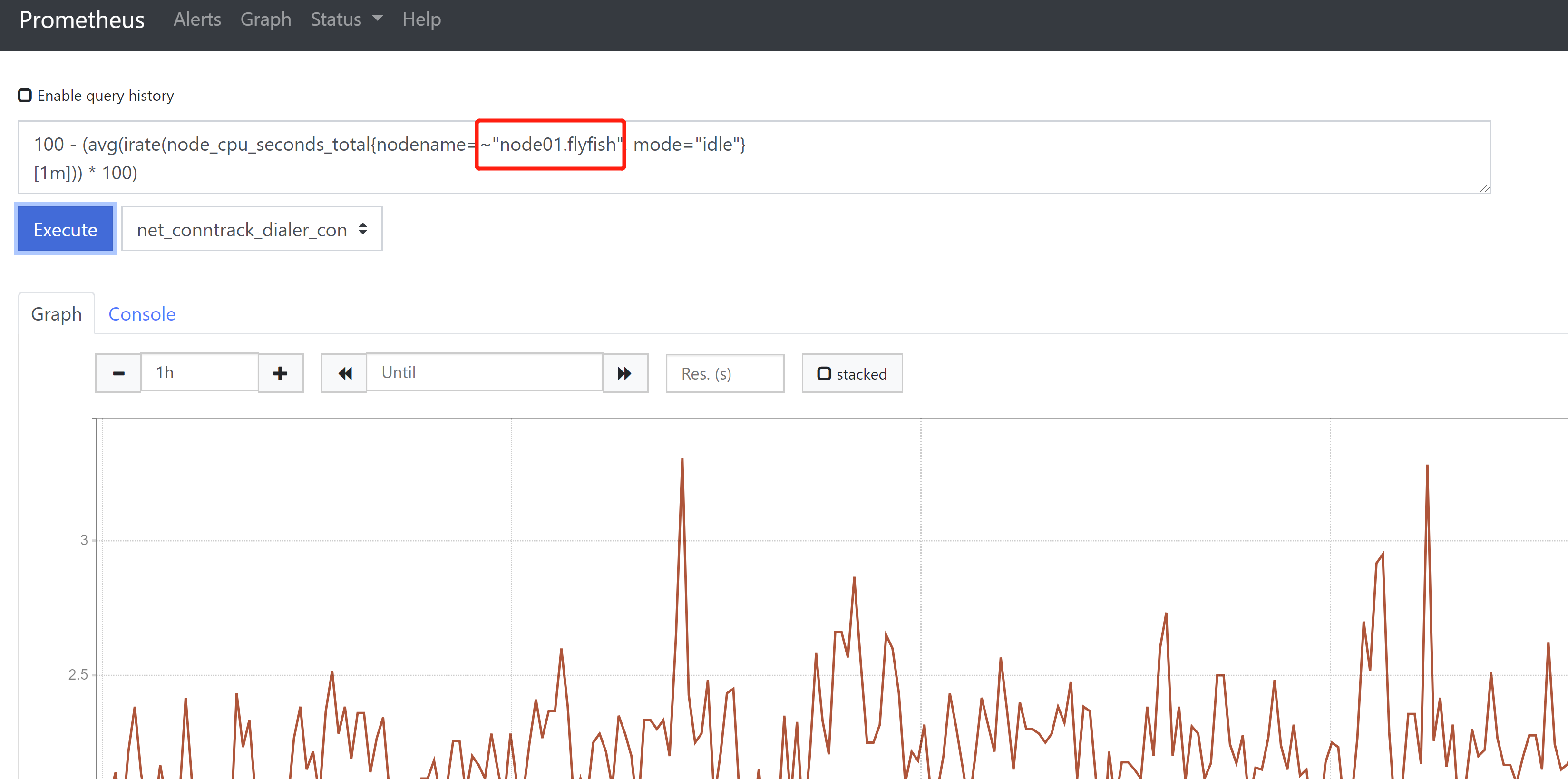
3、偏移修饰器(Offset modifier)Offset 在瞬时/范围向量选择器中用于对过去一段时间的偏移计算,例如,计算5分钟前CPU的空闲率avg(irate(node_cpu_seconds_total{nodename=~"node01.flyfish", mode="idle"}[1m] offset5m))注意:offset 的使用范围是在:瞬时/范围向量选择器中
三、Prometheus常用函数
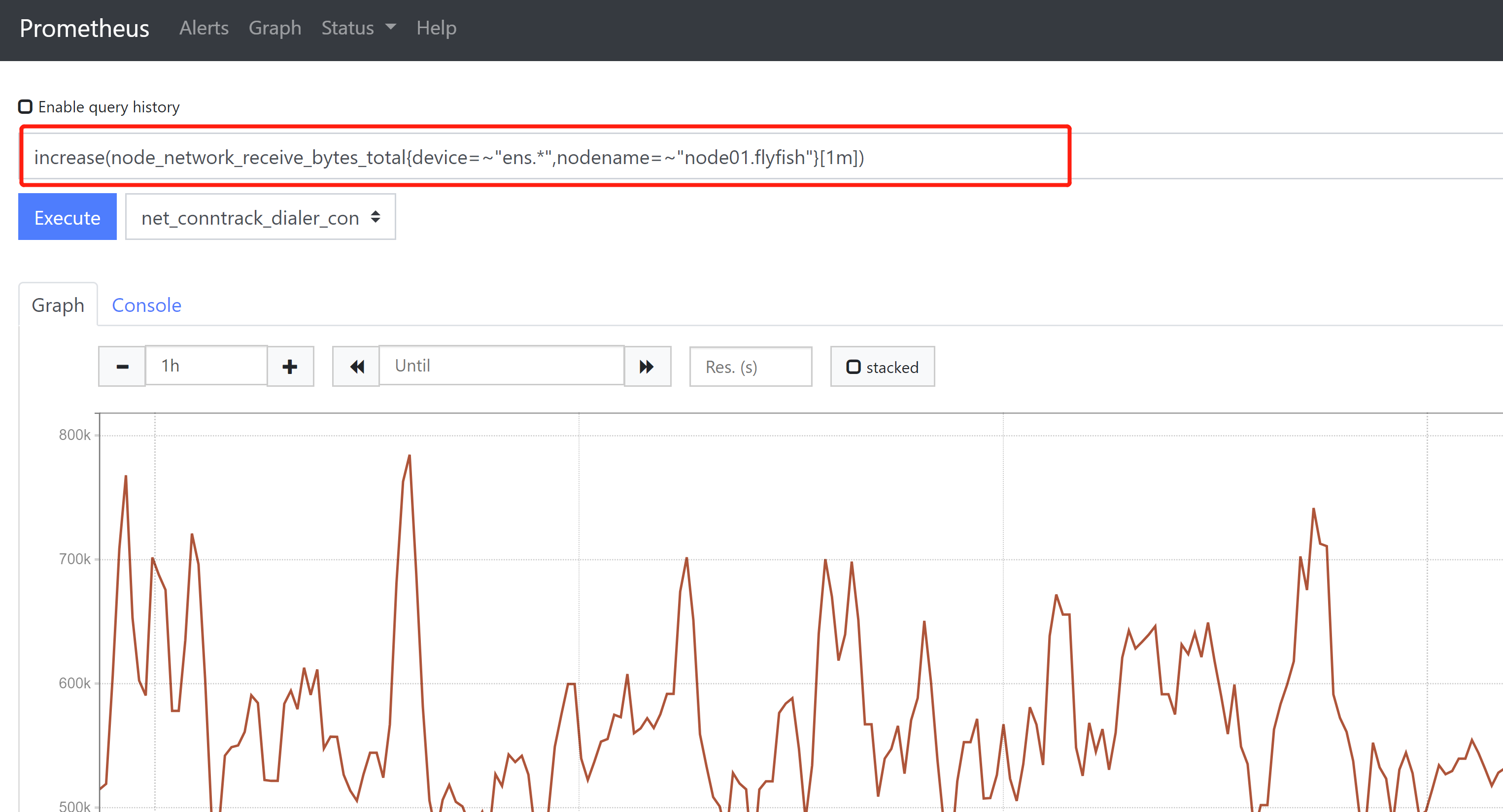
https://prometheus.io/docs/prometheus/latest/querying/functions/1、increase()函数,该函数结合counter数据类型使用,获取区间向量中的第一个和最后一个样本并返回其增长量。如果除以[区间]时间(秒)就可以获取该时间内的平均增长率。# 获取近1分钟内网卡接收的字节数,如果不除以时间,则为区间内累计增量。increase(node_network_receive_bytes_total{device=~"ens.*",nodename=~"node01.flyfish"}[1m])
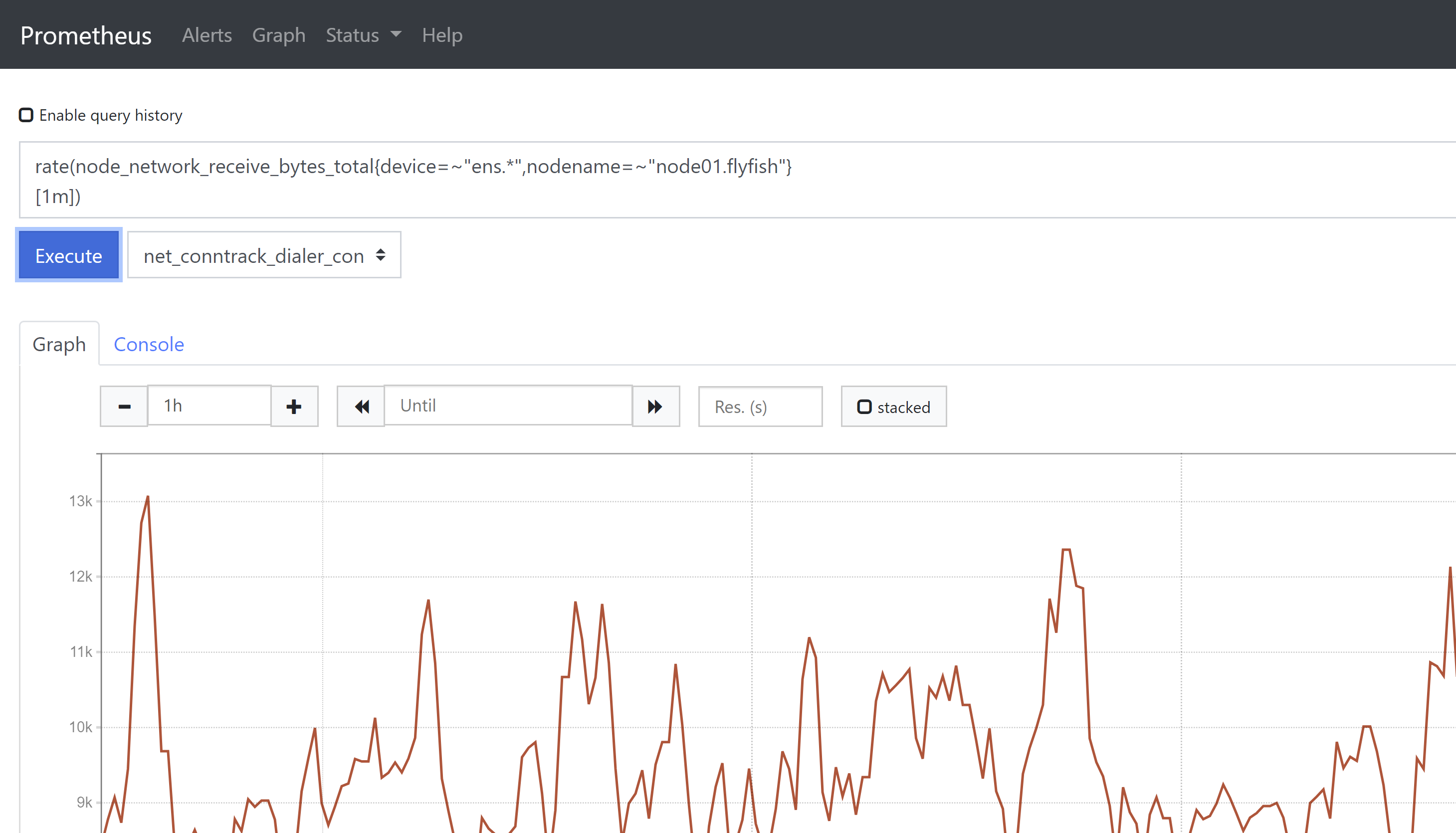
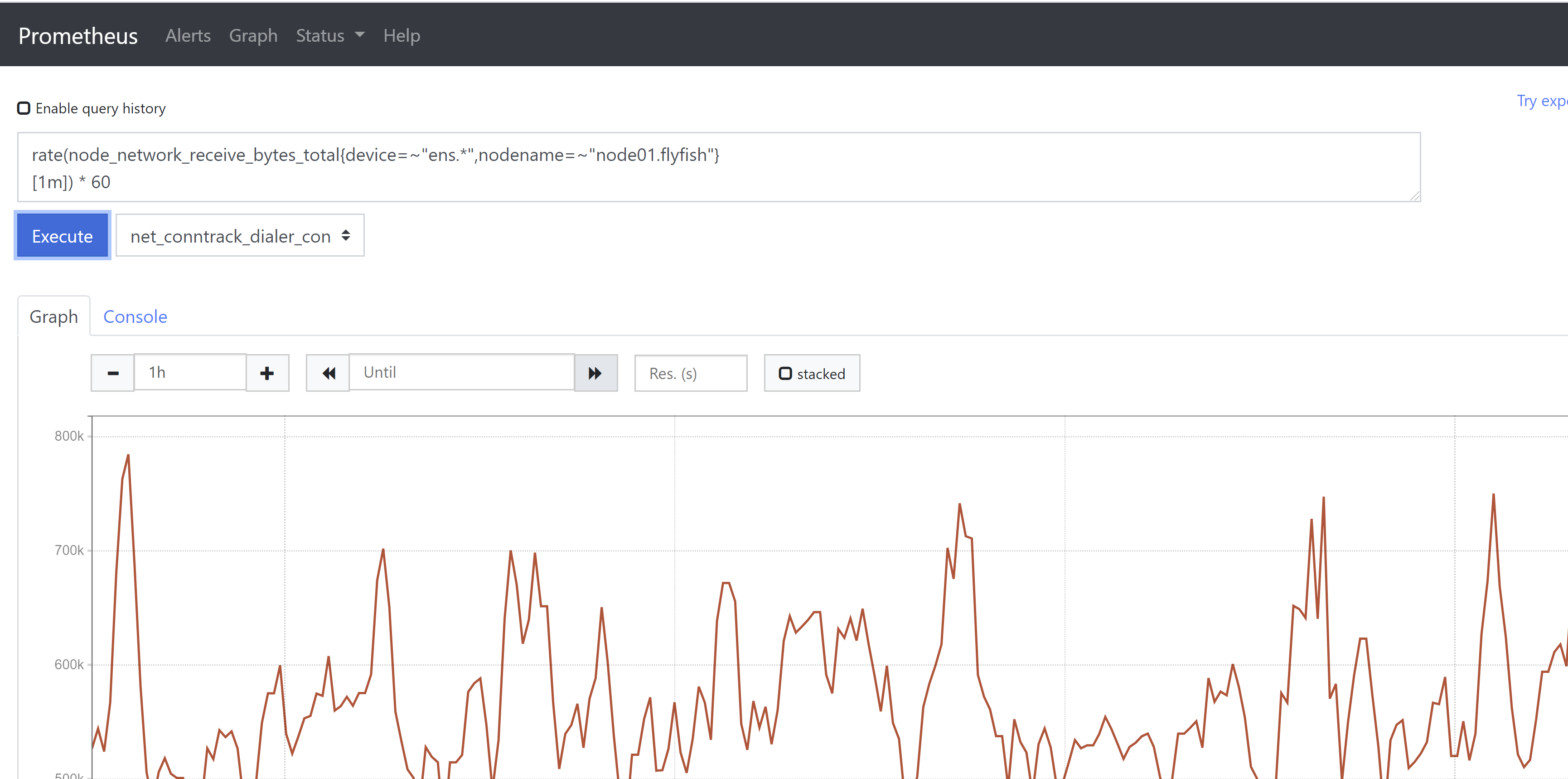
2-1、rate()函数,该函数配置counter数据类型使用,用于获取在这个时间段内的平均每秒增量。# 通过rate()函数获取在1分钟时间内网卡每秒接收字节数,如果再乘以区间时间,则同increase()函数。rate(node_network_receive_bytes_total{device=~"ens.*",nodename=~"node01.flyfish"}[1m])以下查询结果同increase()函数。rate(node_network_receive_bytes_total{device=~"ens.*",nodename=~"node01.flyfish"}[1m]) * 60
2-2、irate()函数,用于计算指定时间范围内每秒瞬时增长率,是基于该时间范围内最后两个数据点来计算。rate和irate函数都用于计算某个指标在一定时间间隔内的变化速率。但是它们的计算方法有所不同:irate取的是在指定时间范围内的最后两个数据点来算速率,而rate会取指定时间范围内所有数据点,算出一组速率,然后取平均值作为结果。所以官网文档说:irate适合快速变化(fast-moving)的计数器(counter),而rate适合缓慢变化(slow-moving)的计数器(counter)。
3、sum()函数,在实际工作中CPU大多是多核心,而node_cpu_seconds_total会将每个核的数据都单独显示出来,但我们关心的是CPU总的使用情况,因此可以使用sum()函数求和后得出一条总的数据,使用sum()函数获取实例在1分钟时间内,user在所有vCPU上的使用百分比之和# sum(increase(node_cpu_seconds_total{nodename=~"node01.flyfish",mode="user"}[1m])/60)
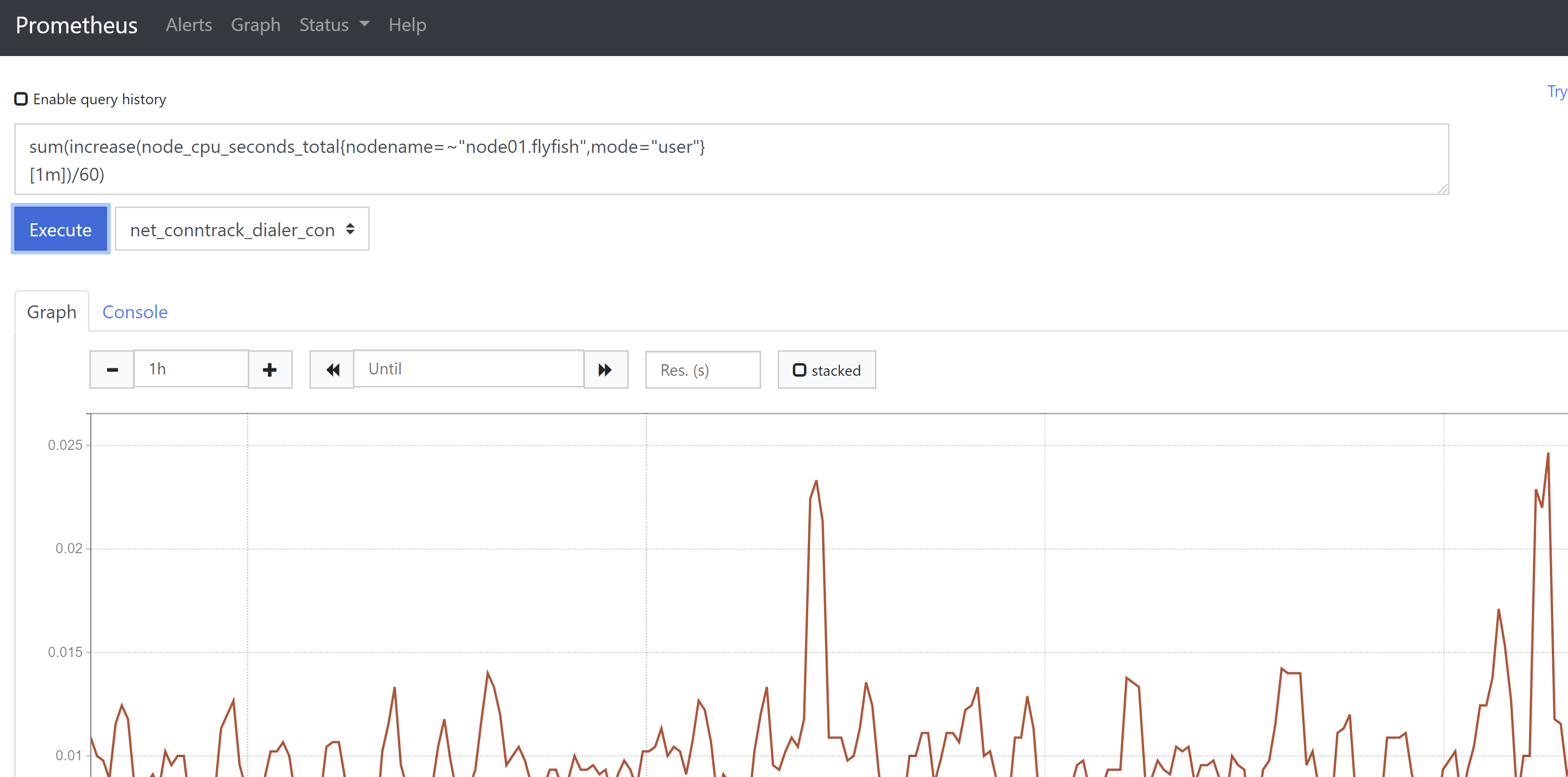
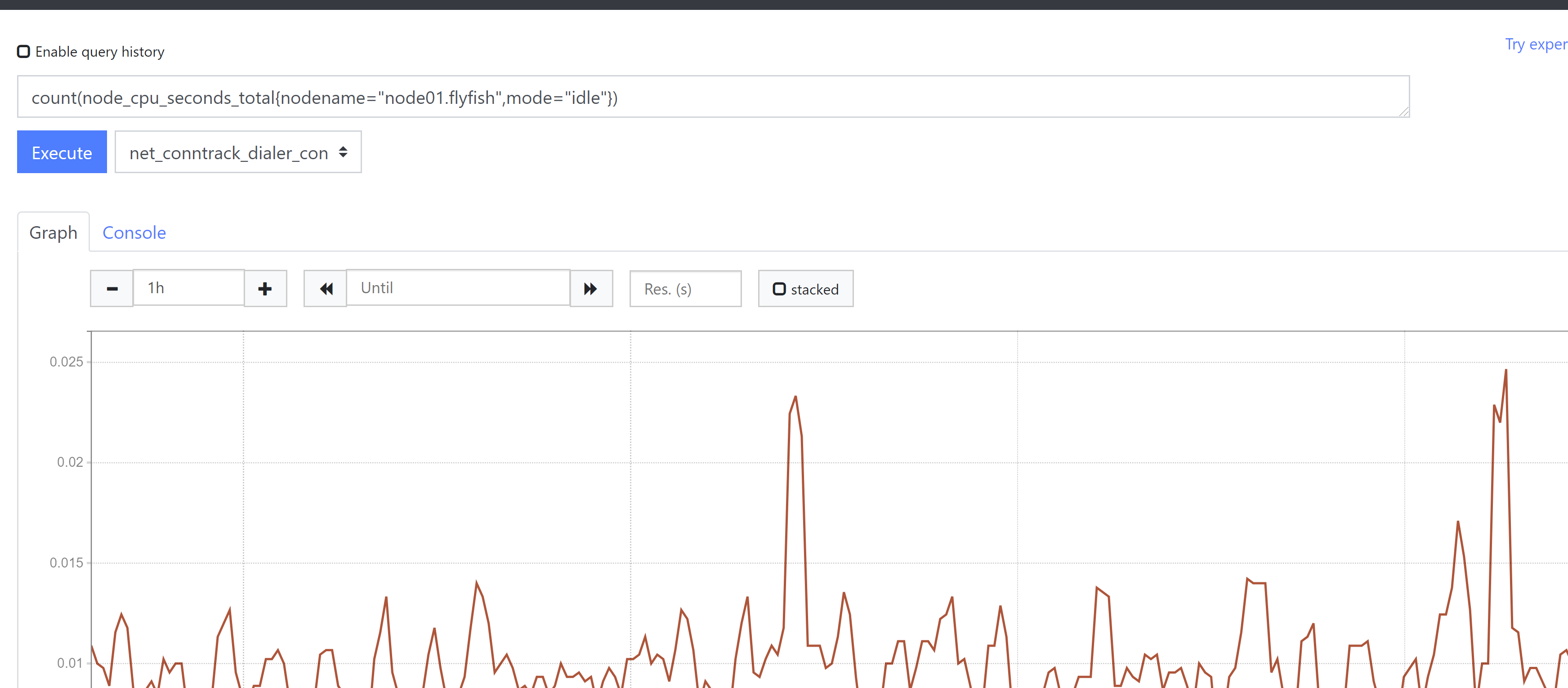
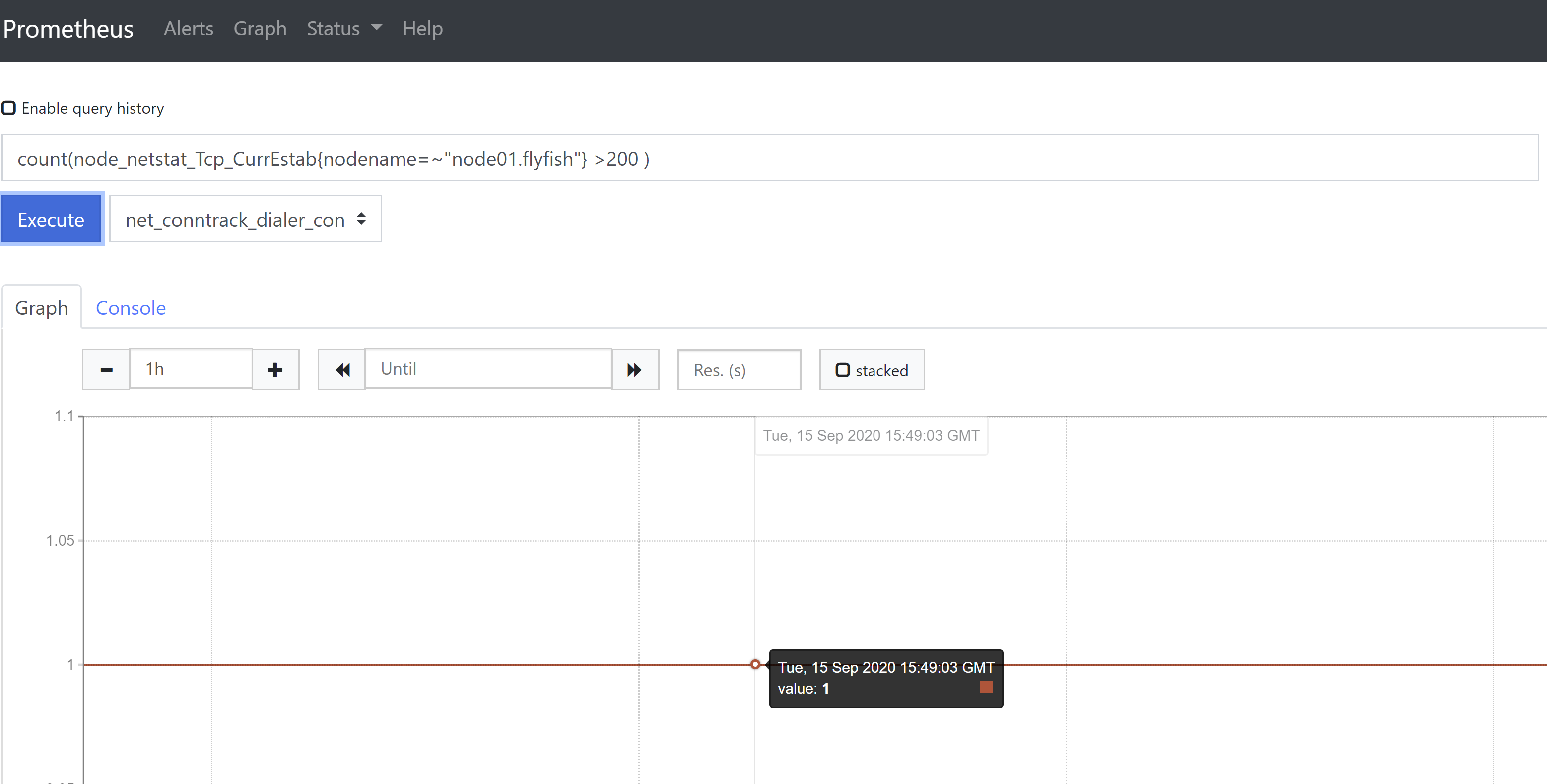
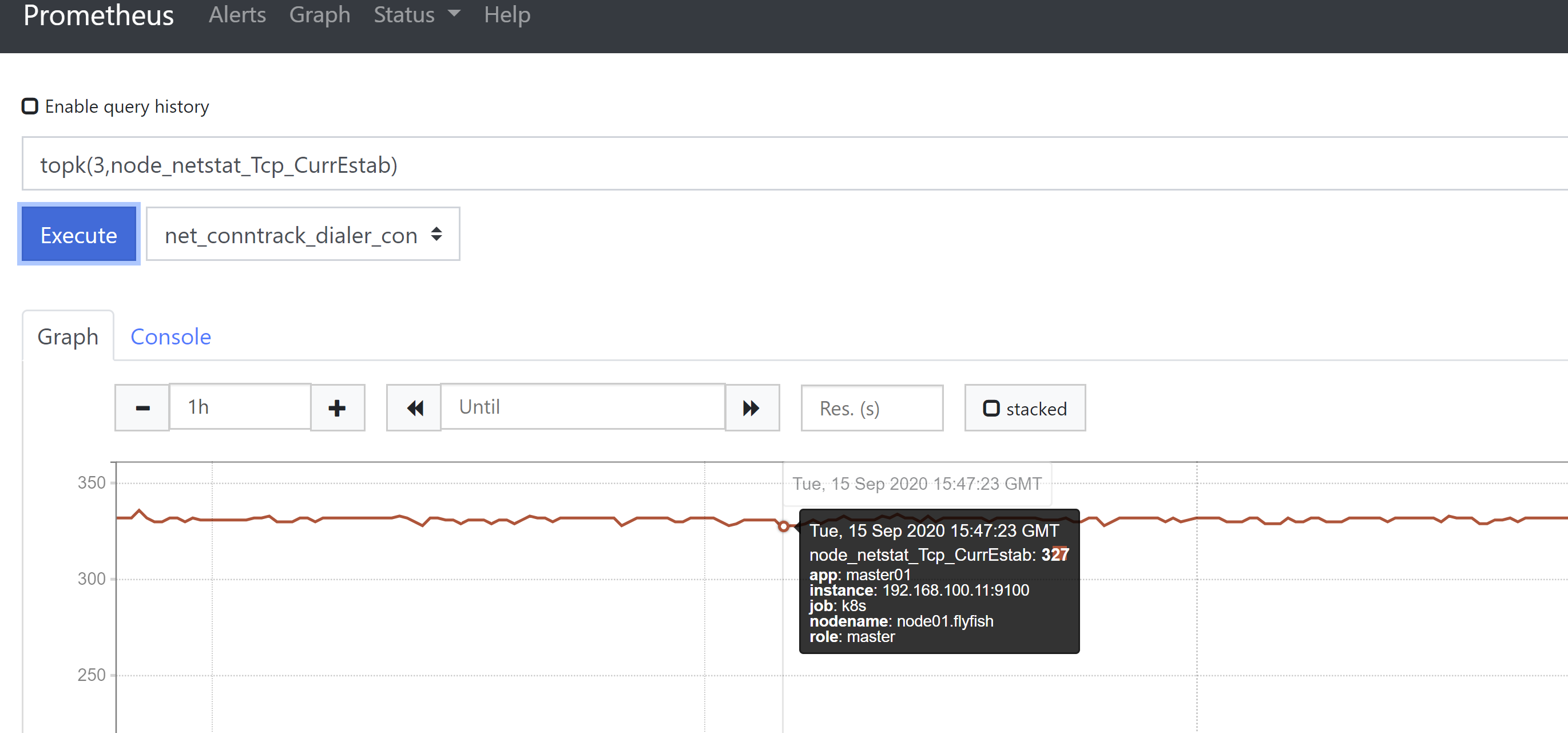
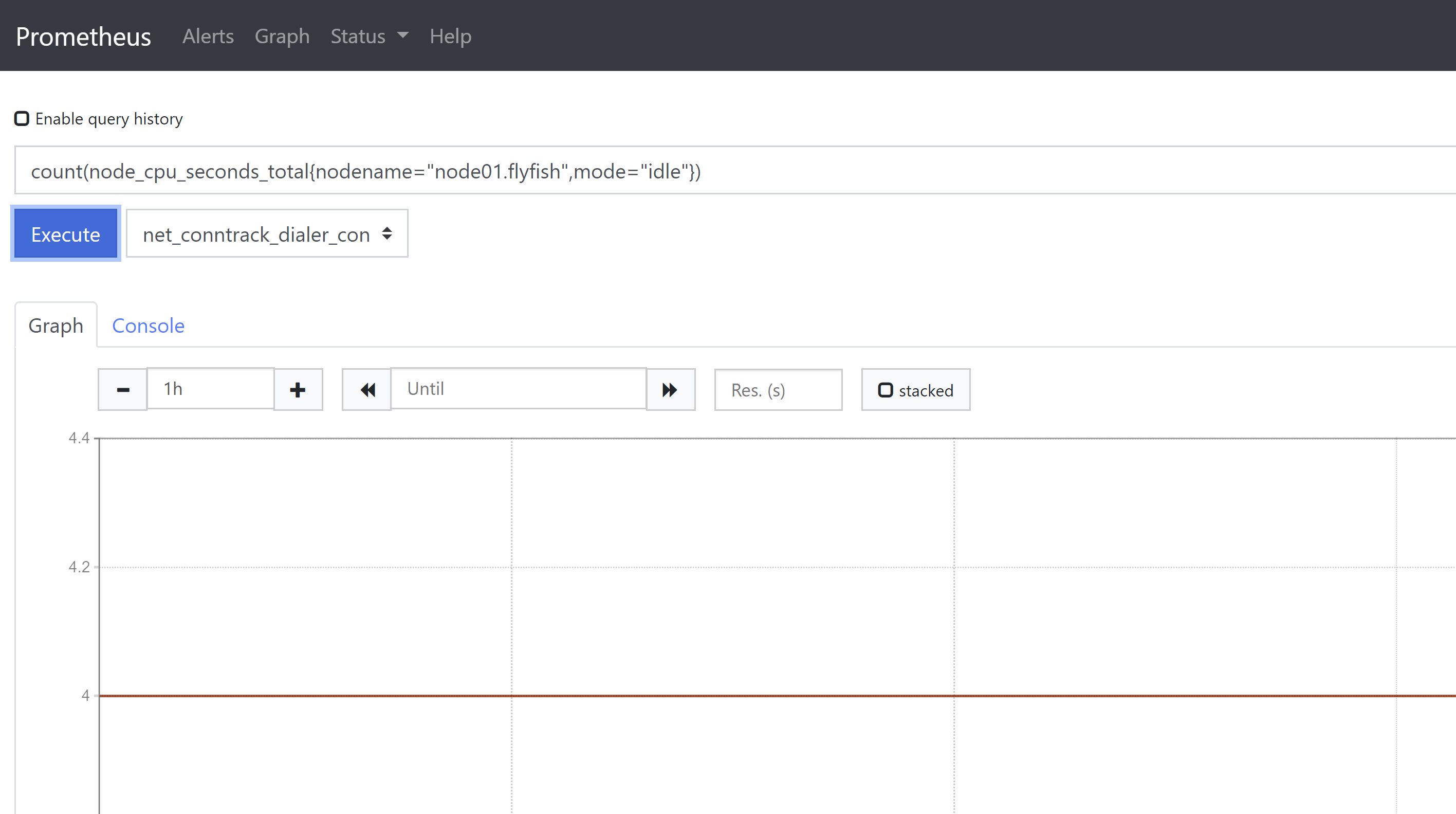
4、count()函数,该函数用于进行统计,或用来做一些模糊判断,比如判断服务器连接数大于某个值,为真则返回1,否则返回null。例如统计vCPU数count(node_cpu_seconds_total{nodename="node01.flyfish",mode="idle"})或者统计当前TCP建立连接数是否大于200count(node_netstat_Tcp_CurrEstab{nodename=~"node01.flyfish"} >200 )
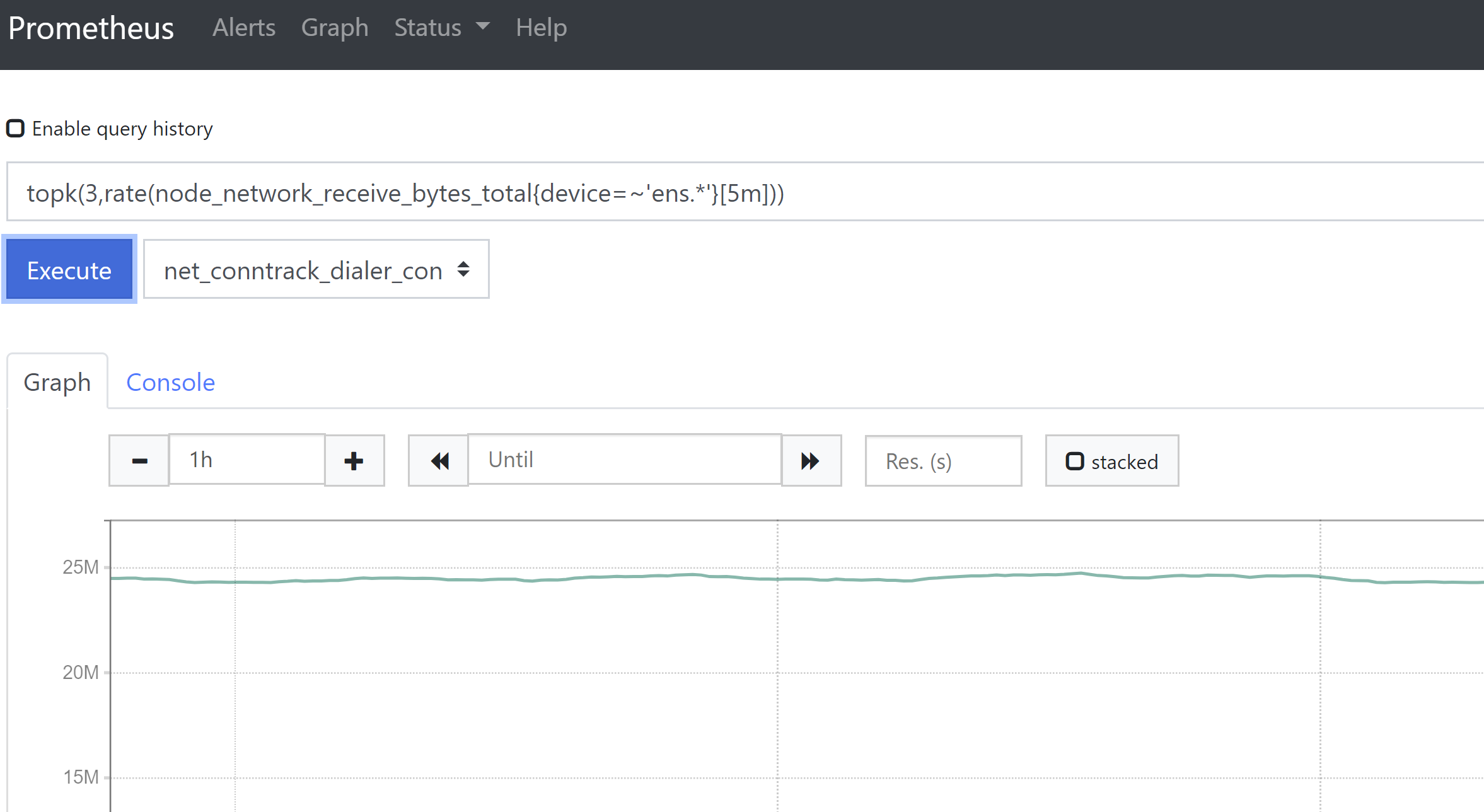
5、topk()函数,该函数可以从大量数据中取出排行前N的数值,N可以自定义。# 例如从所有主机中找出近5分钟网卡流量排名前3的主机(Counter类型数据)。topk(3,rate(node_network_receive_bytes_total{device=~'ens.*'}[5m]))或者用increasetopk(3,increase(node_network_receive_bytes_total{device=~'ens.*'}[5m])/300)# 例如从所有主机中找出连接数前3的主机(Gauge类型数据)。topk(3,node_netstat_Tcp_CurrEstab)
6、predict_linear()函数,根据前一个时间段的值来预测未来某个时间点数据的走势。例如,我们可以用predict_linear()函数,根据近1天的磁盘使用来预测磁盘在未来2天增长情况,大概在未来多长时间可以将磁盘占满。predict_linear(node_filesystem_free_bytes{device="rootfs",nodename=~"node01.fyfish",mountpoint="/"}[1d],2*86400)
四:常用系统资源监控指标
user time(us) 表示CPU执行用户进程所消耗的时间。system time(sy) 表示CPU在内核运行的时间,该值较大时表明系统存在瓶颈。wait time(wa) 表示CPU在等待I/O操作完成所花费的时间,该值较大时表明系统I/O存在瓶颈。idle time(id) CPU处于空闲状态,等待进程运行。nice time(ni) 表示在调整进程优先级时所花费CPU时间。irq time(hi) 表示在处理硬中断时所花费CPU时间。softirq time(si) 表示在处理软中断时所花费CPU时间。steal time(st) 表示Hypervisor在为另一个虚拟处理器提供服务时,虚拟CPU等待实际CPU的时间百分比。该种情况通常是在虚拟化或公有云环境存在CPU资源严重超卖的情况,多个虚拟机抢占CPU激烈。
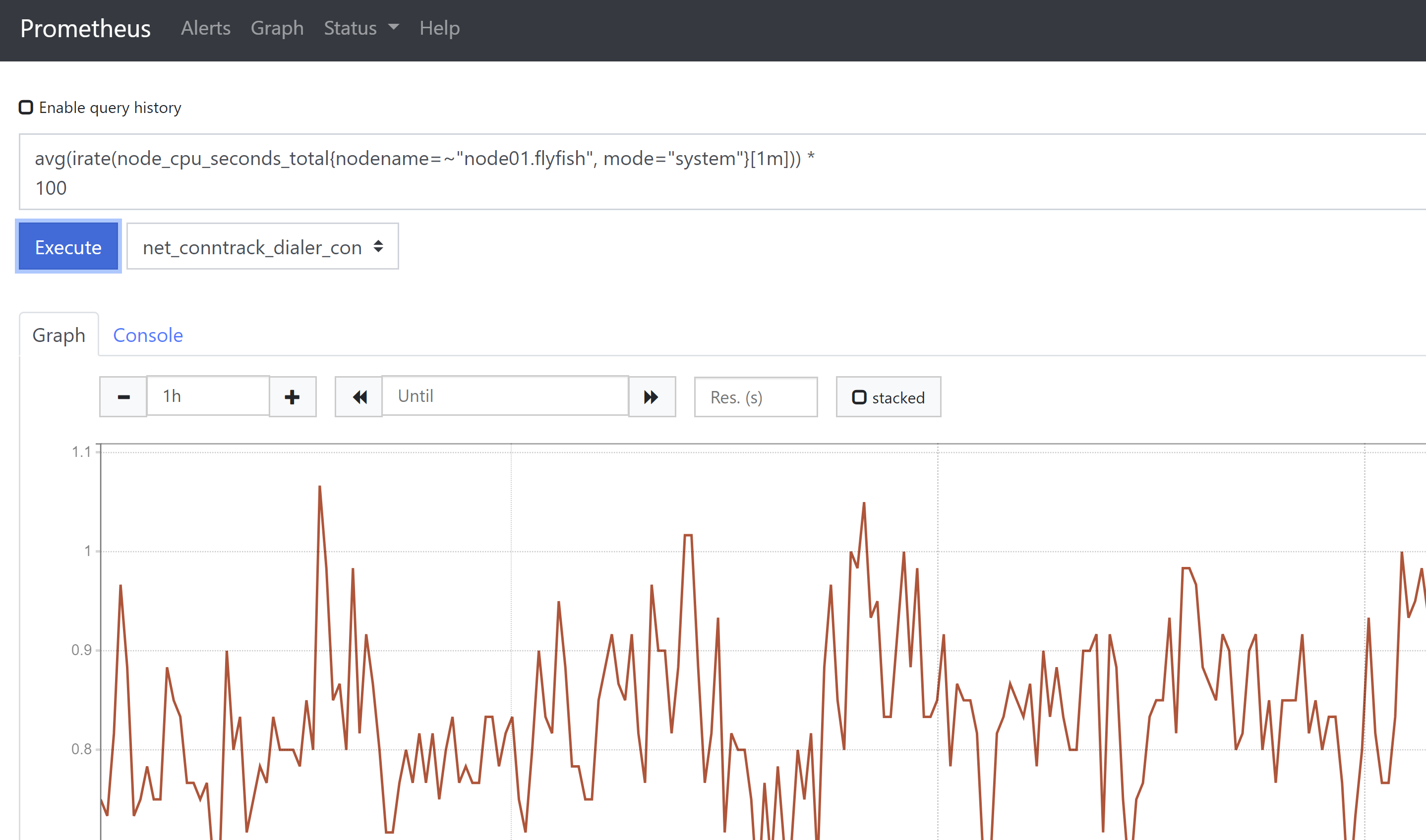
1、cpu使用率监控(Unit: percent 0-100)100 - (avg(irate(node_cpu_seconds_total{nodename=~"$hostname", mode="idle"}[1m])) * 100)同时还可以列出CPU其他使用指标,便于定位问题avg(irate(node_cpu_seconds_total{nodename=~"node01.flyfish", mode="system"}[1m])) *100说明:在计算CPU使用率时,范围向量选择器时间间隔不能太大,例如取5分钟,就很有可能会漏掉严重的抖动。cpu个数count(node_cpu_seconds_total{nodename="$hostname",mode="idle"})
-------------------------内存资源监控--------------------------------------------------1、总内存(Unit: bytes)node_memory_MemTotal_bytes{nodename=~"$hostname"}2、可用内存(Unit: bytes)node_memory_MemAvailable_bytes{nodename=~"$hostname"}3、空闲内存(Unit: bytes)node_memory_MemFree_bytes{nodename=~"$hostname"}4、活动内存(Unit: bytes)node_memory_Active_bytes{nodename=~"$hostname"}5、使用内存(Unit: bytes)node_memory_MemTotal_bytes{nodename=~"$hostname"} -node_memory_MemAvailable_bytes{nodename=~"$hostname"}
-------------------------系统负载监控--------------------------------------------------1、系统1分钟负载监控avg(node_load1{nodename=~"$hostname"})2、系统5分钟负载监控avg(node_load5{nodename=~"$hostname"})3、系统5分钟负载监控avg(node_load5{nodename=~"$hostname"})
-------------------------磁盘监控--------------------------------------------------1、分区总容量(Unit: bytes)node_filesystem_size_bytes{device=~"/dev/mapper/vg00-lvroot",nodename=~"$hostname"}2、磁盘空闲容量(Unit: bytes)node_filesystem_free_bytes{device=~"/dev/mapper/vg00-lvroot",nodename=~"$hostname"}3、磁盘使用容量(Unit: bytes)node_filesystem_size_bytes{device=~"/dev/mapper/vg00-lvroot",nodename=~"$hostname"} -node_filesystem_free_bytes{device=~"/dev/mapper/vg00-lvroot",nodename=~"$hostname"}3、磁盘每秒读(Unit: bytes/s)irate(node_disk_read_bytes_total{nodename=~"$hostname"}[5m])4、磁盘每秒读(Unit: bytes/s)irate(node_disk_written_bytes_total{nodename=~"$hostname"}[5m])5、磁盘读IO(Unit: IOPS)irate(node_disk_reads_completed_total{nodename=~"$hostname"}[5m])6、磁盘写(Unit: IOPS)irate(node_disk_writes_completed_total{nodename=~"$hostname"}[5m])
-------------------------网卡流量监控--------------------------------------------------1、网卡每秒接收字节(Unit: bytes/sec)rate(node_network_receive_bytes_total{device=~"ens.*",nodename=~"$hostname"}[5m])2、网卡每秒发送字节(Unit: bytes/sec)rate(node_network_transmit_bytes_total{device=~"ens.*",nodename=~"$hostname"}[5m])3、网卡每秒接收错误字节(Unit: bytes/sec)rate(node_network_receive_errs_total{device=~"ens.*",nodename=~"$hostname"}[5m])4、网卡每秒发送错误字节(Unit: bytes/sec)rate(node_network_transmit_errs_total{device=~"ens.*",nodename=~"$hostname"}[5m])5、网卡每秒接收包个数(Unit: packets/sec)rate(node_network_receive_packets_total{device=~"ens.*",nodename=~"$hostname"}[5m])6、网卡每秒发送包个数(Unit: packets/sec)rate(node_network_transmit_packets_total{nodename=~"$hostname"}[5m])
-------------------------socket连接监控--------------------------------------------------1、状态为ESTABLISHED的个数node_netstat_Tcp_CurrEstab{nodename=~'$hostname'}2、状态为TIMEWAIT的个数node_sockstat_TCP_tw{nodename=~'$hostname'}
总结:在使用Prometheus来计算各种指标时,使用的函数不同,得到的结果就会有偏差,正所谓越灵活也就越复杂。
