@zhangyy
2020-12-09T10:20:14.000000Z
字数 5514
阅读 1767
如何自定义编译zeppelin 的parcels 与CDH 集成
大数据运维专栏
- 一:关于zeppelin介绍
- 二:如何自定义CDH 的 parcels 与 csd 的jar 包
- 三:zeppelin 与CDH的集成
- 四:关于zeppelin 的测试
一:关于zepplin的介绍
Apache Zeppelin 是一个让交互式数据分析变得可行的基于网页的开源框架。Zeppelin提供了数据分析、数据可视化等功能。Zeppelin 是一个提供交互数据分析且基于Web的笔记本。方便你做出可数据驱动的、可交互且可协作的精美文档,并且支持多种语言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。Zeppelin 功能:数据提取数据发掘数据分析数据可视化展示以及合作
二:如何自定义CDH 的 parcels 与 csd 的jar 包
2.1 编译环境准备
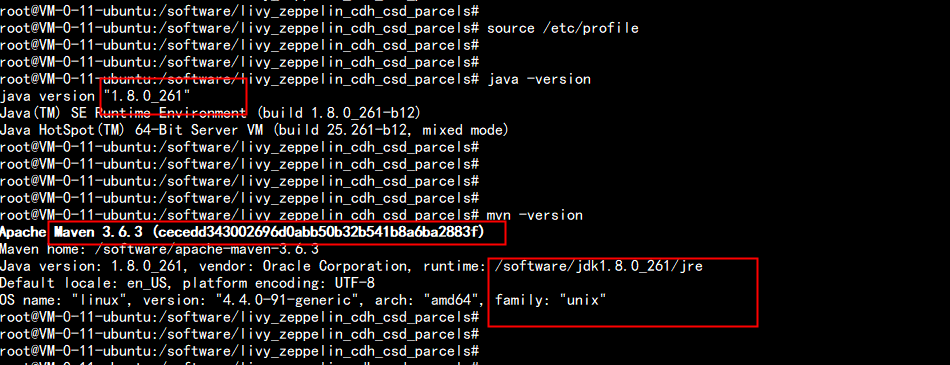
建议使用国外云主机 ,flyfish 这边用的是香港的云主机系统: ubuntu 16.0.4x64jdk: jdk1.8.0_261maven: apache-maven-3.6.3jdk 与maven 安装目录:/software环境变量配置:vim /etc/profile----# jdkexport JAVA_HOME=/software/jdk1.8.0_261export CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jarPATH=$PATH:$HOME/bin:$JAVA_HOME/bin# mavenexport MAVEN_HOME=/software/apache-maven-3.6.3PATH=$PATH:$HOME/bin:$MAVEN_HOME/bin----java -versionmaven -version
2.2 下载 打包 livy 与 zeppelin 的parcels 打包软件
编译步骤如下:1. 下载Livy和Zeppelin源码并编译2. 生成Livy和Zeppelin的Parcel包3. 下载编译Cloudera提供的cm_ext工具,用于校验parcel及生成manifest.json文件4. 生成Livy和Zeppelin的csd文件,用于CM对Livy和Zeppelin服务的识别
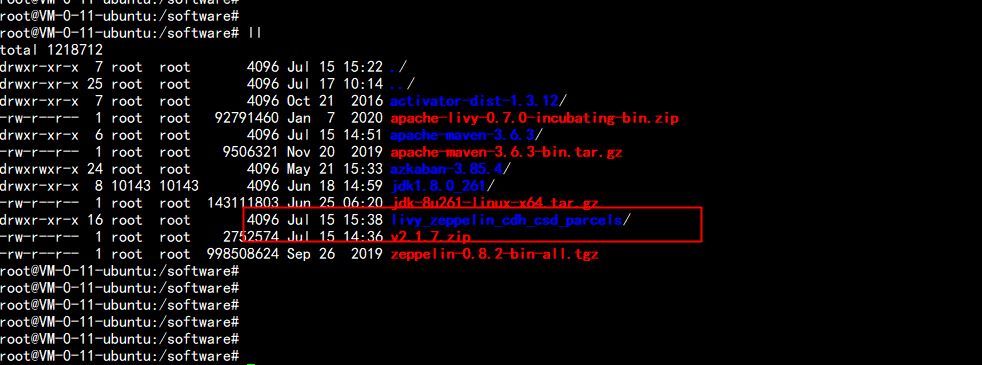
下载 打包 源cd /softwaregit clone https://github.com/alexjbush/livy_zeppelin_cdh_csd_parcels.gitflyfish 这里已经下载好了

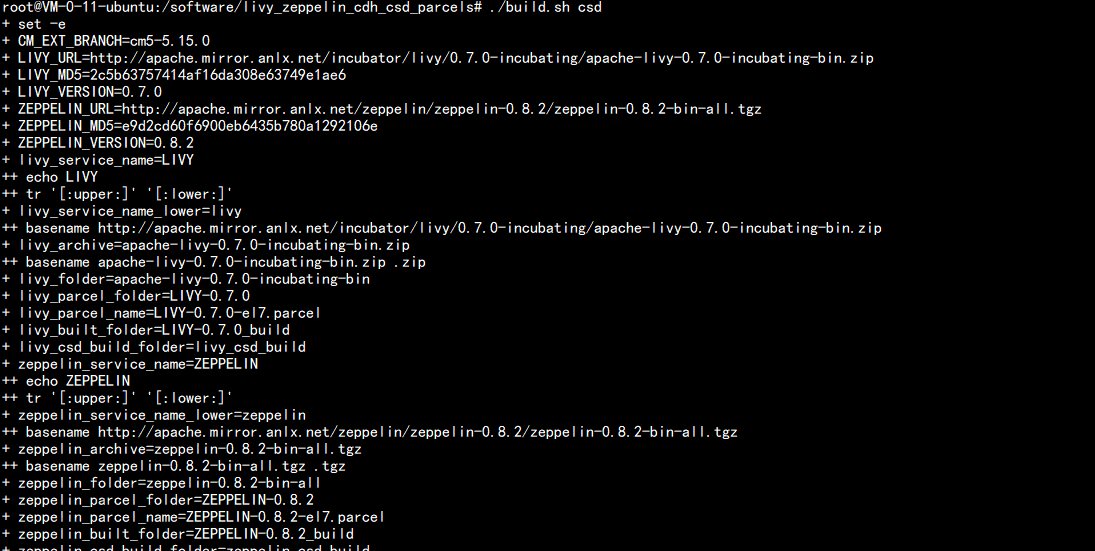
然后修改打包源的build.shcd /software/livy_zeppelin_cdh_csd_parcelsvim build.sh---主要修改的是上面 包的路径:CM_EXT_BRANCH=cm5-5.15.0LIVY_URL=http://apache.mirror.anlx.net/incubator/livy/0.7.0-incubating/apache-livy-0.7.0-incubating-bin.zipLIVY_MD5="2c5b63757414af16da308e63749e1ae6"LIVY_VERSION=0.7.0ZEPPELIN_URL=http://apache.mirror.anlx.net/zeppelin/zeppelin-0.8.2/zeppelin-0.8.2-bin-all.tgzZEPPELIN_MD5="e9d2cd60f6900eb6435b780a1292106e"ZEPPELIN_VERSION=0.8.2---切记 因为包 的 版本 不同 md5 码 也不同
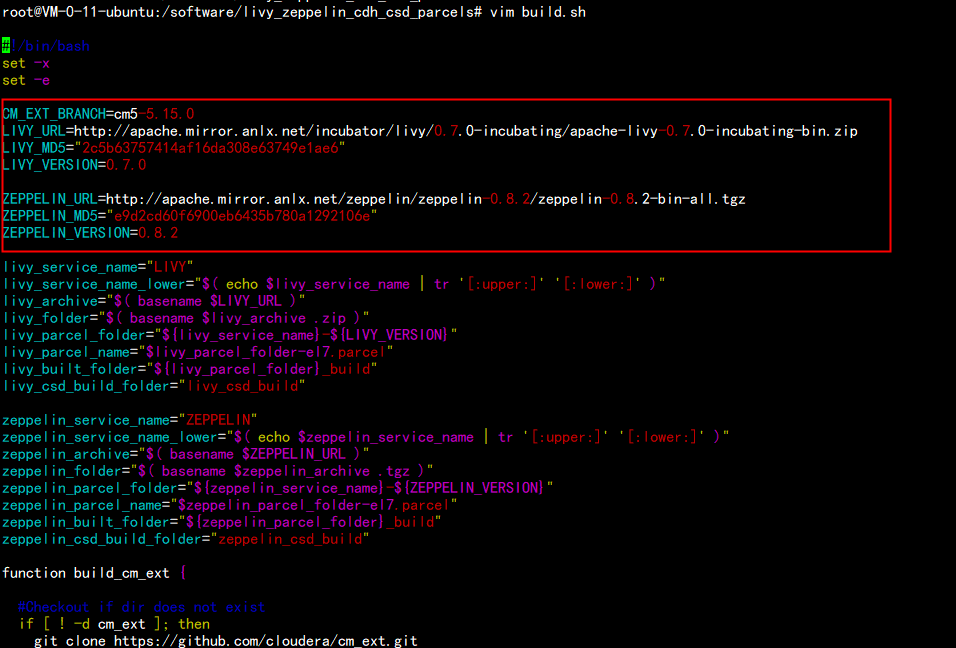
执行编译 生成parcels 包chmod +x build.sh./build.sh parcel
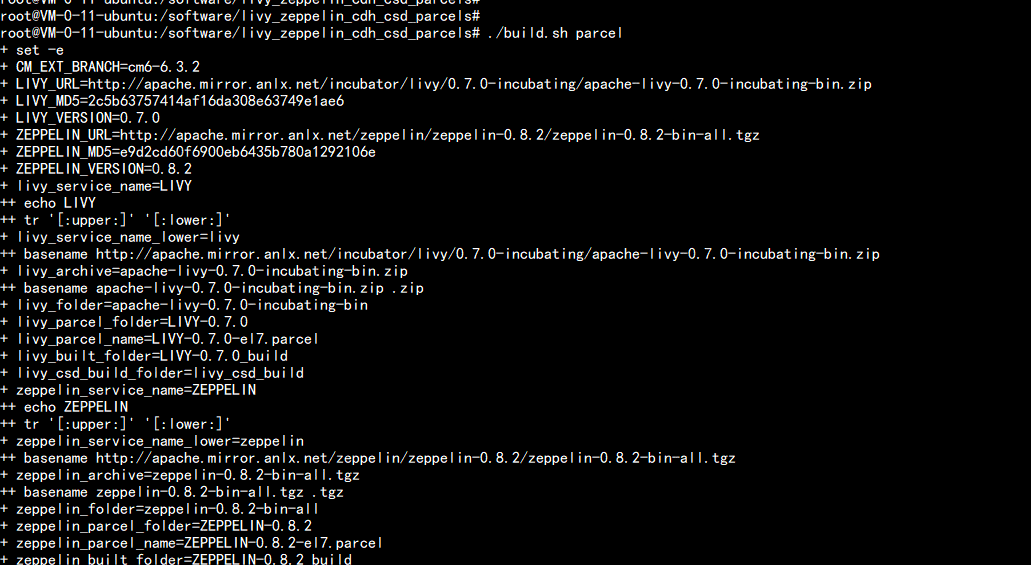
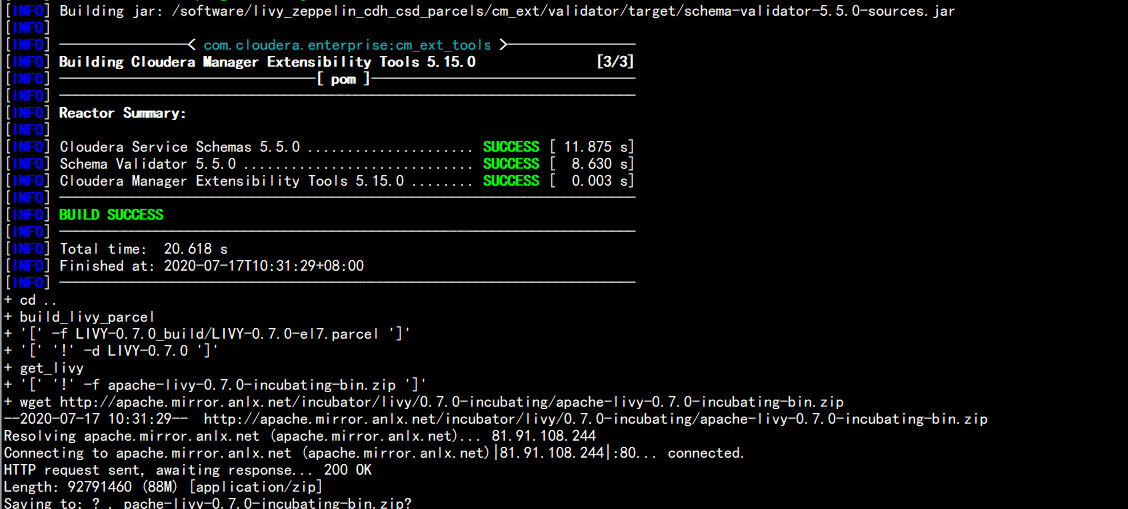
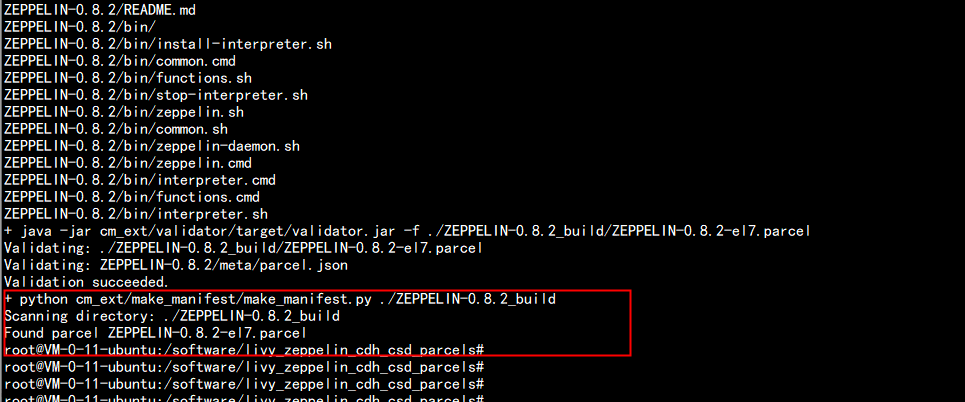
打出parcels 放在:ZEPPELIN-0.8.2_build 下面cd ZEPPELIN-0.8.2_buildmanifest.json ZEPPELIN-0.8.2-el7.parcel 文件LIVY 放在:cd LIVY-0.7.0_buildLIVY-0.7.0-el7.parcel manifest.json

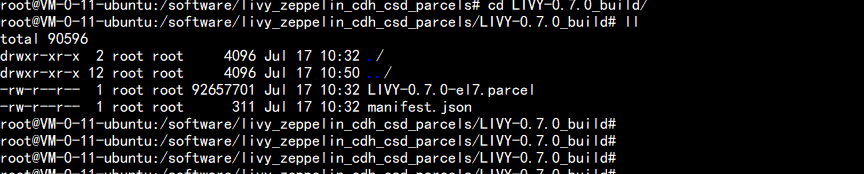
生成 csd 的jar 包cd /software/livy_zeppelin_cdh_csd_parcels./build.sh csd
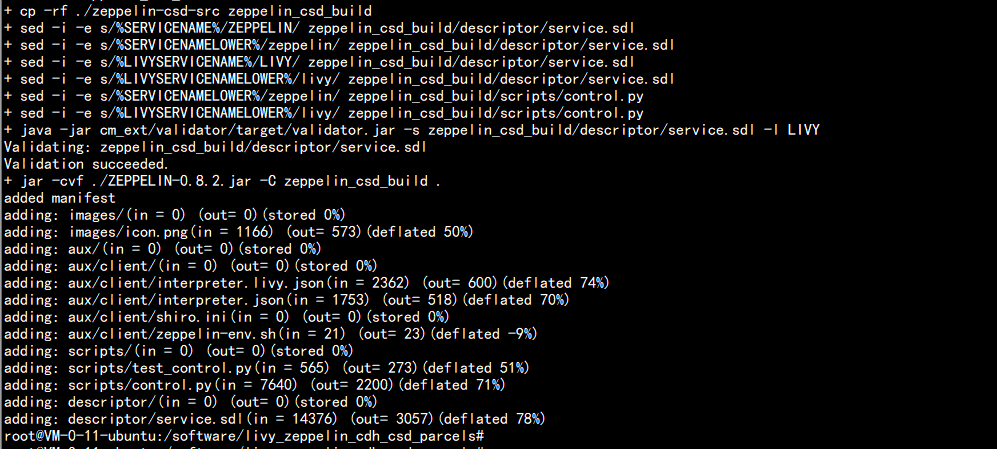
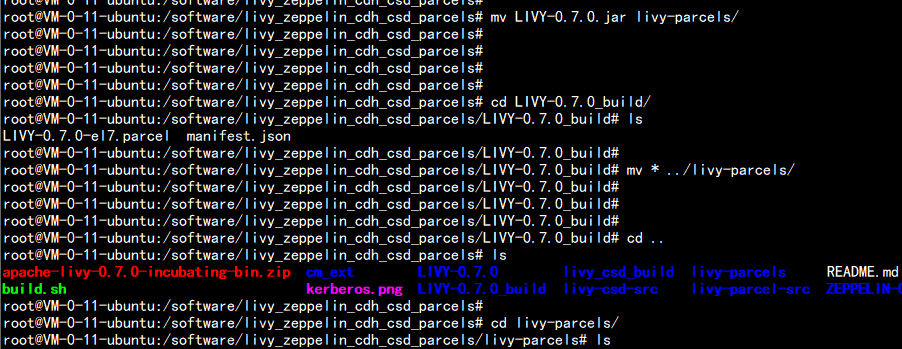
生成 jar 包ls -ld *.jar

mkdir zepplin-parcelsmv ZEPPELIN.jar zeppelin-parcelsmv ZEPPELIN-0.8.2_build/* zeppelin-parcelsmv LIVY-0.7.0.jar livy-parcels/cd LIVY-0.7.0_build/mv * ../livy-parcels/tar -zcvf zeppelin-parcels.tar.gz zeppelin-parcelstar -zcvf livy-parcels.tar.gz livy-parcels然后把 zeppelin-parcels.tar.gz livy-parcels.tar.gz 这两个包 下载下来 拿去 和 CDH 集成
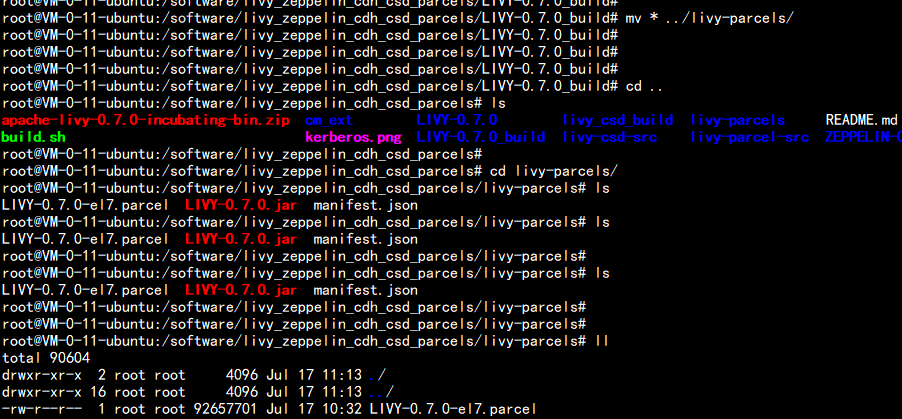
三:zeppelin 与CDH的集成
cd /var/www/html/mkdir livy zeppelin上传zeppelin-parcels.tar.gz 这个包 到 /var/www/html/zeppelin 下面上传livy-parcels.tar.gz 这个包到 /var/www/html/livy 下面解压 zeppelin-parcels.tar.gz 然后 将 manifest.json ZEPPELIN-0.8.2-el7.parcel ZEPPELIN-0.8.2.jar这三个文件 移动 到 /var/www/html/zeppelin 下面同样将 livy-parcels.tar.gz 这个包 解压 将 LIVY-0.7.0-el7.parcel LIVY-0.7.0.jar manifest.json 这三个文件 移动到 /var/www/html/livy 下面
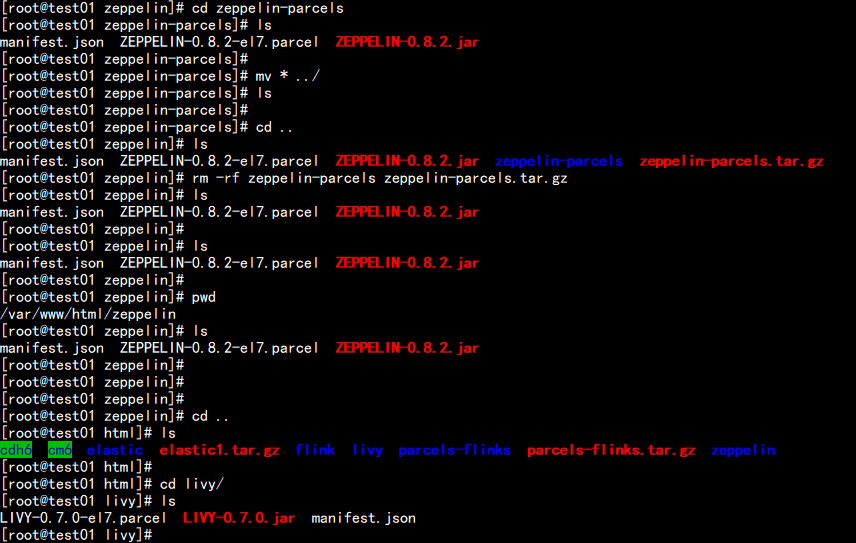
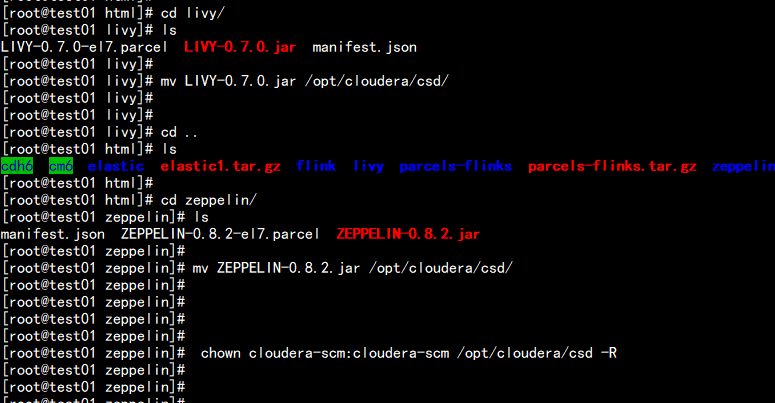
cd /var/www/html/livymv LIVY-0.7.0.jar /opt/cloudera/csd/cd /var/www/html/zeppelinmv mv ZEPPELIN-0.8.2.jar /opt/cloudera/csd/chown cloudera-scm:cloudera-scm /opt/cloudera/csd -Rservice cloudera-scm-server restart
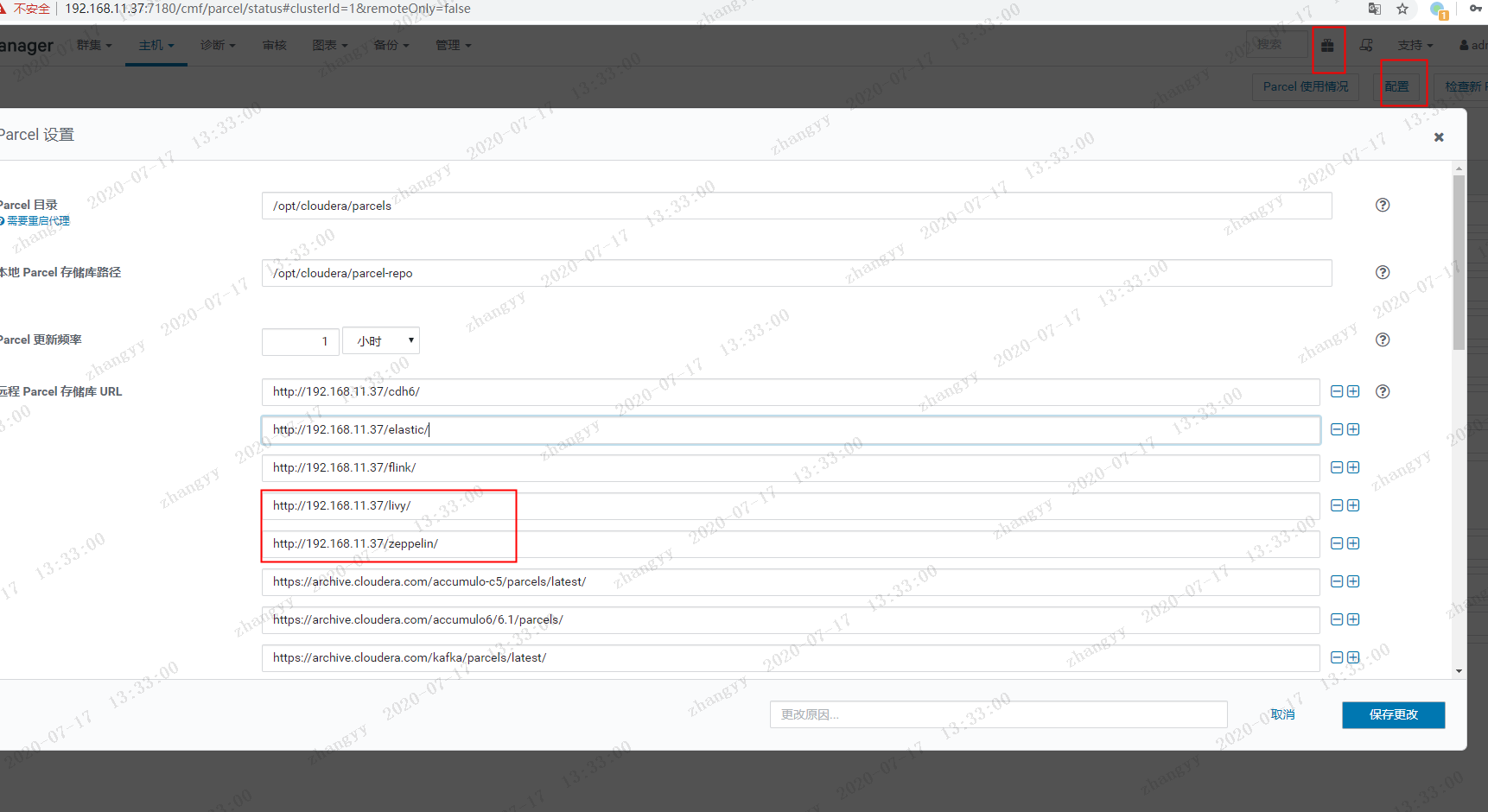
去CDH 上面 配置 parcels 目录http://192.168.11.37/livyhttp://192.168.11.37/zeppelin
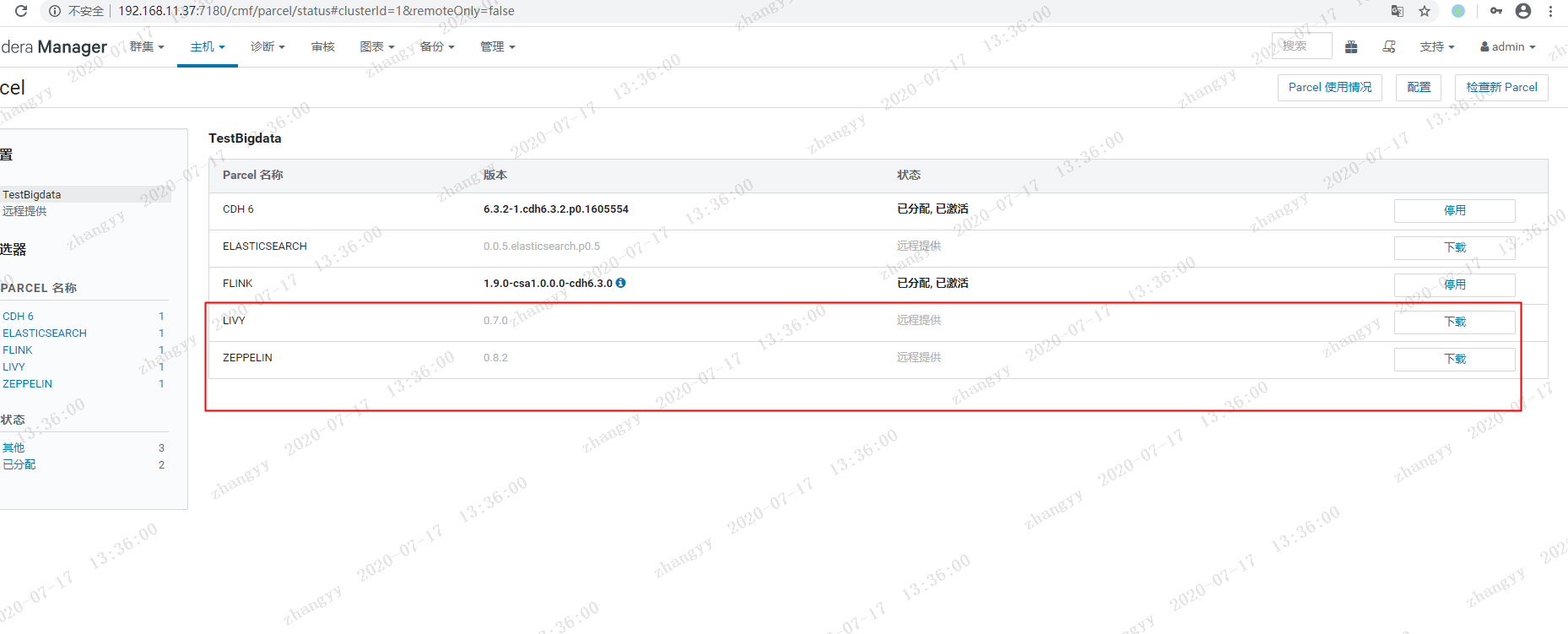
下载 ---》 分配---》 激活

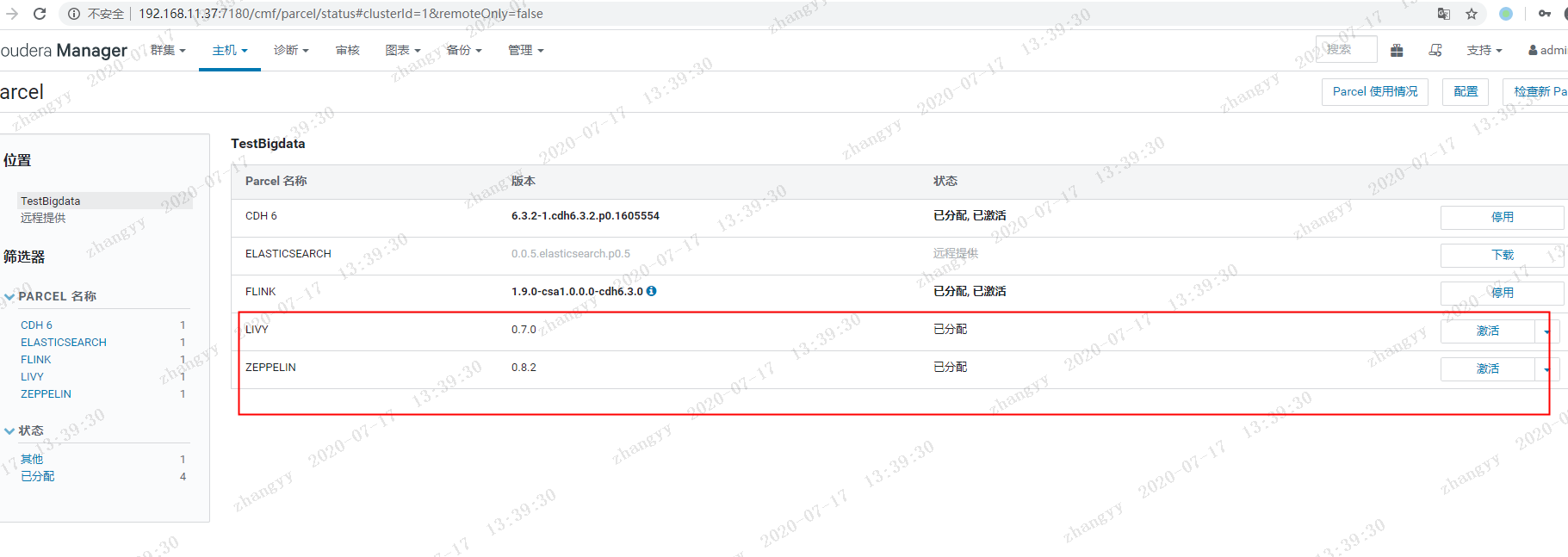
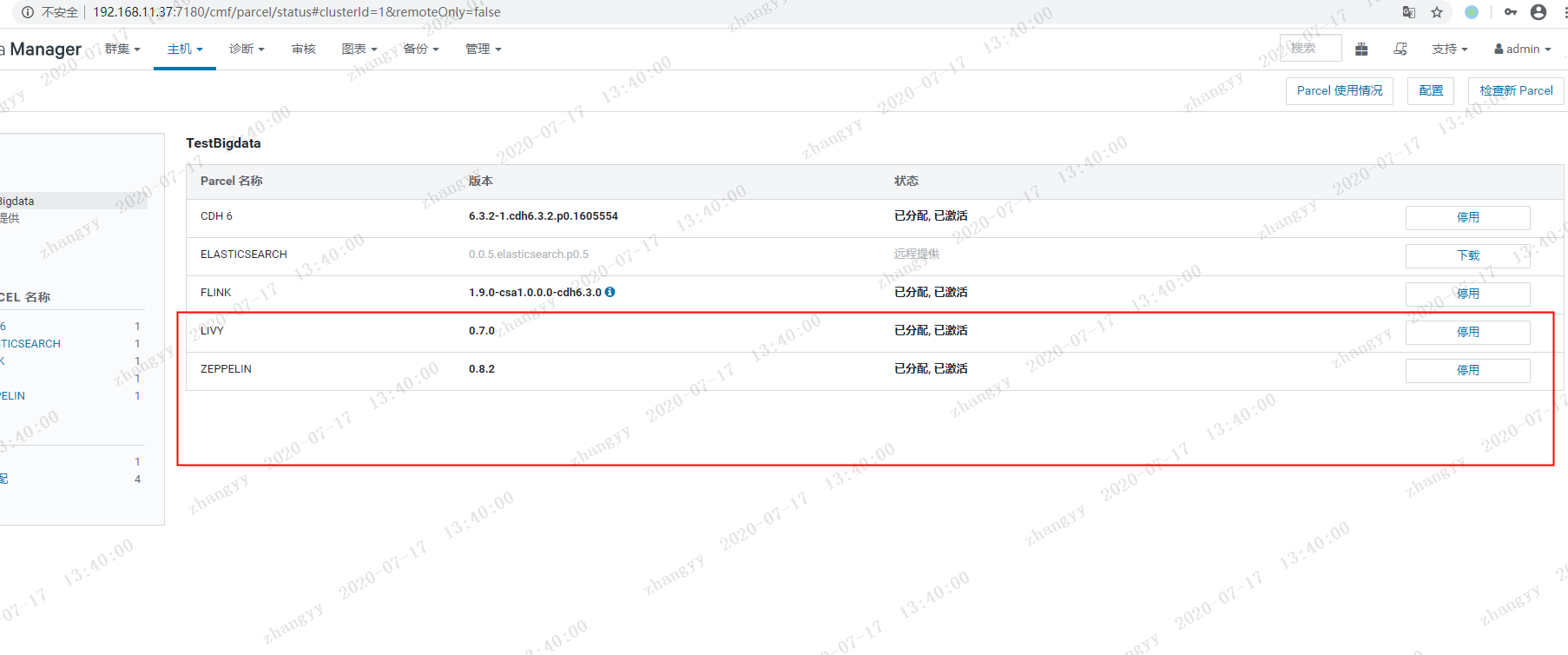
从新启动CM 加载扩展 jar 包
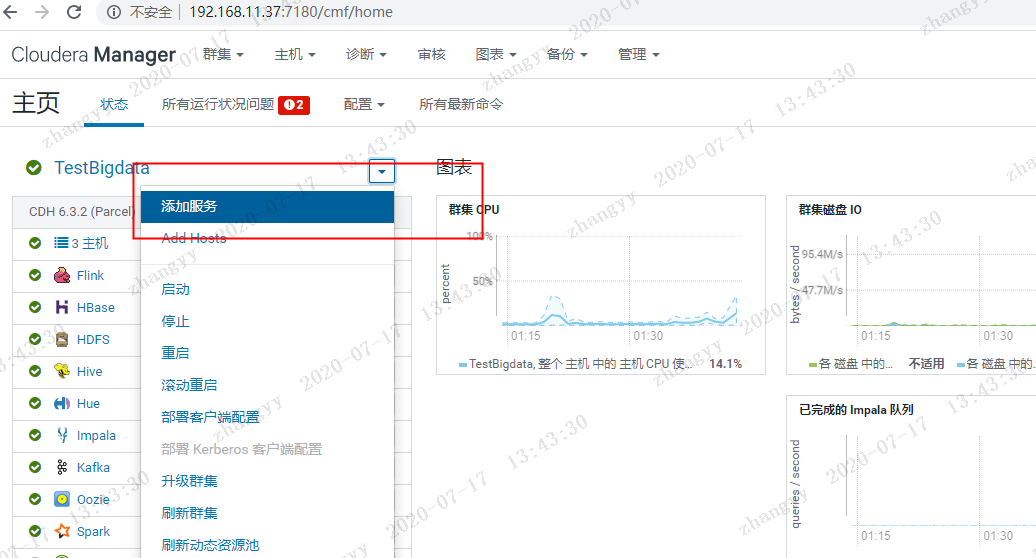
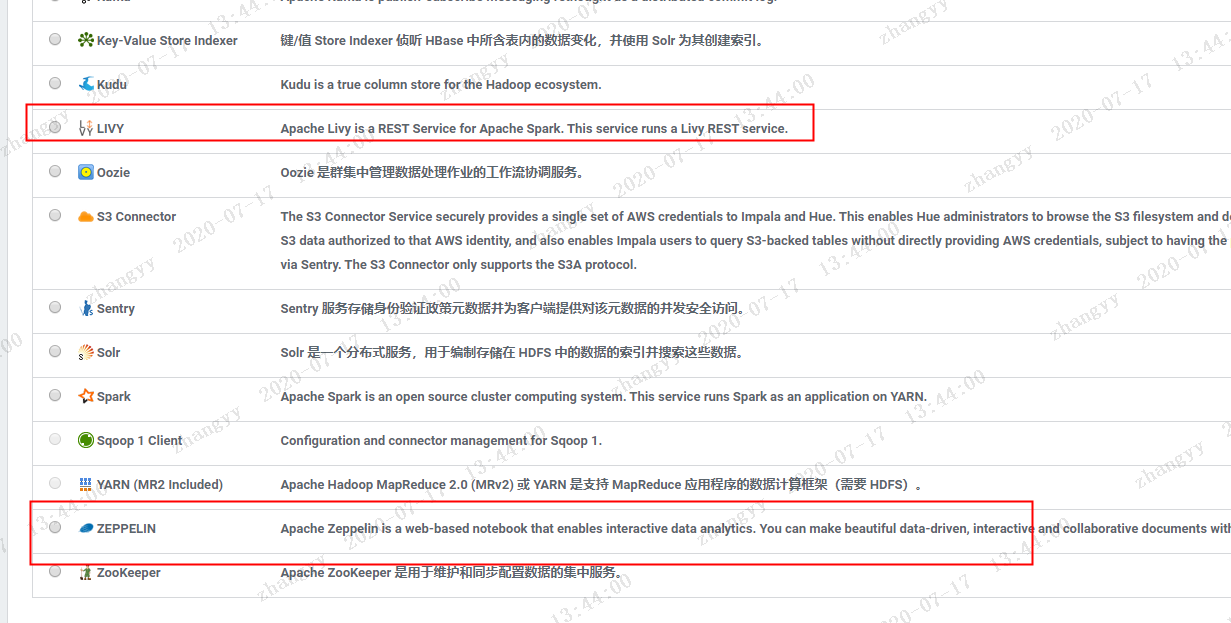
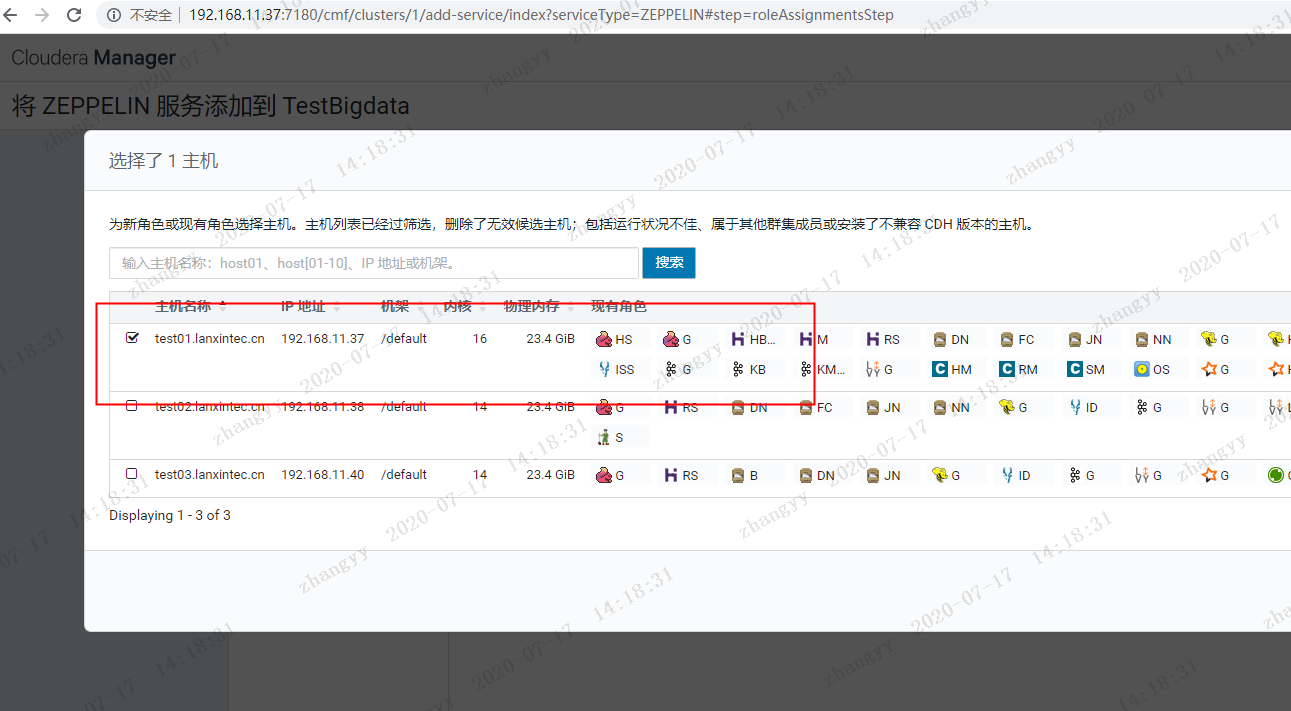
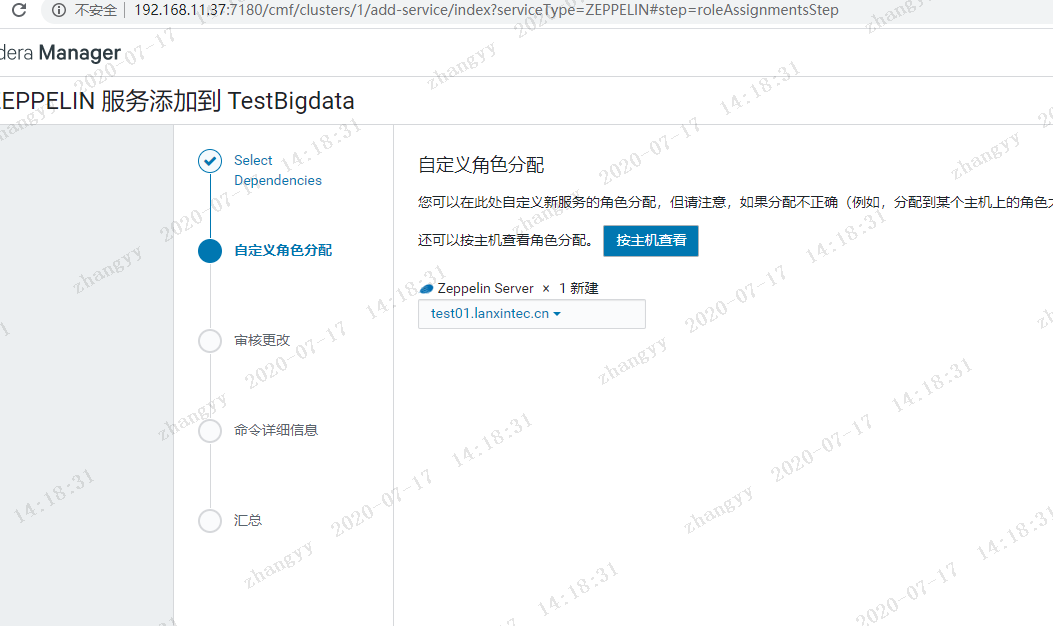
添加livy 与zeppelin 服务
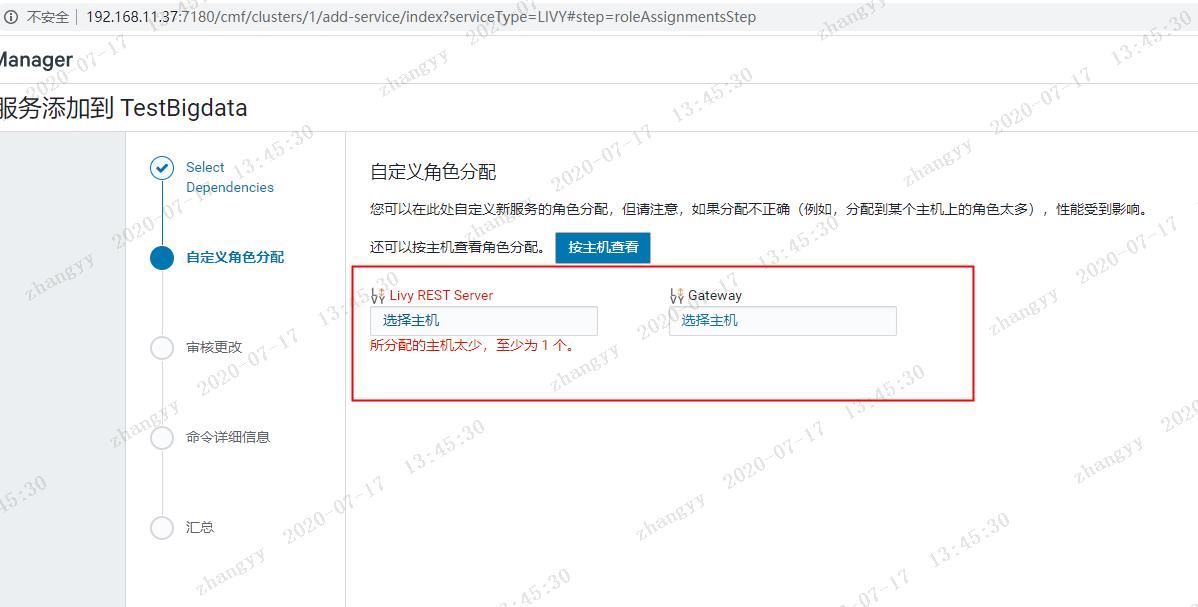
添加livy 服务依赖

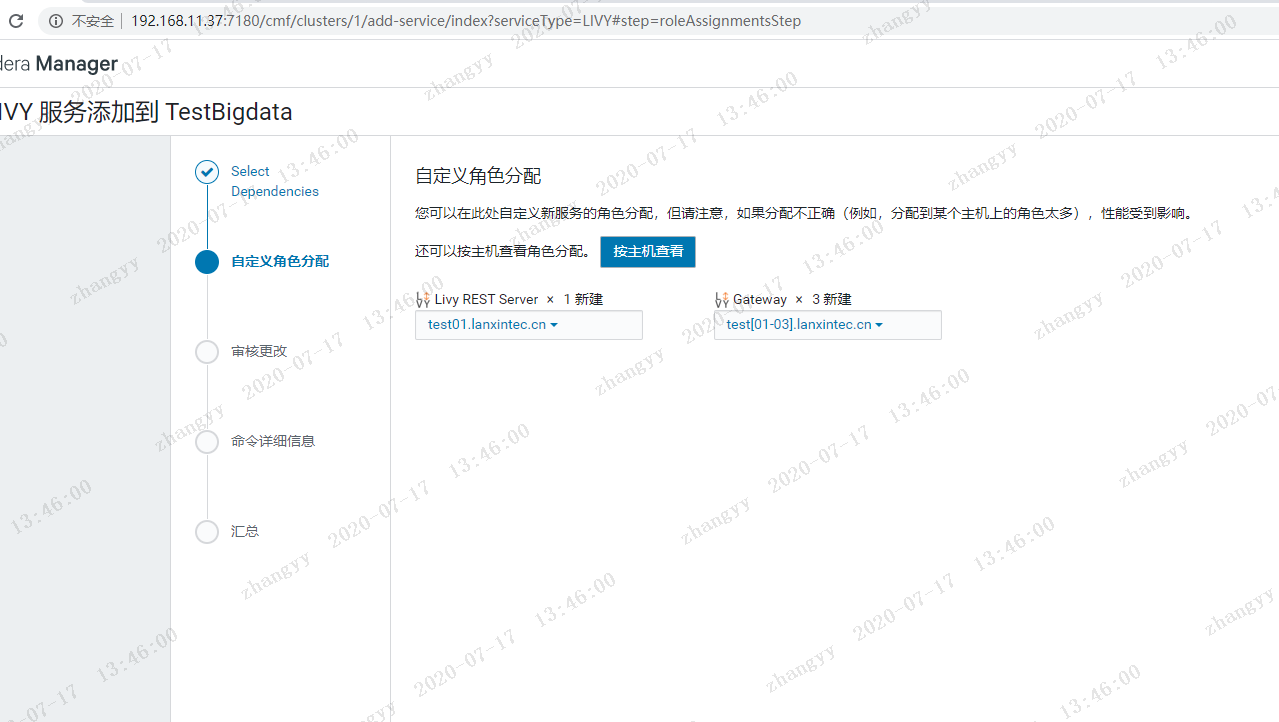

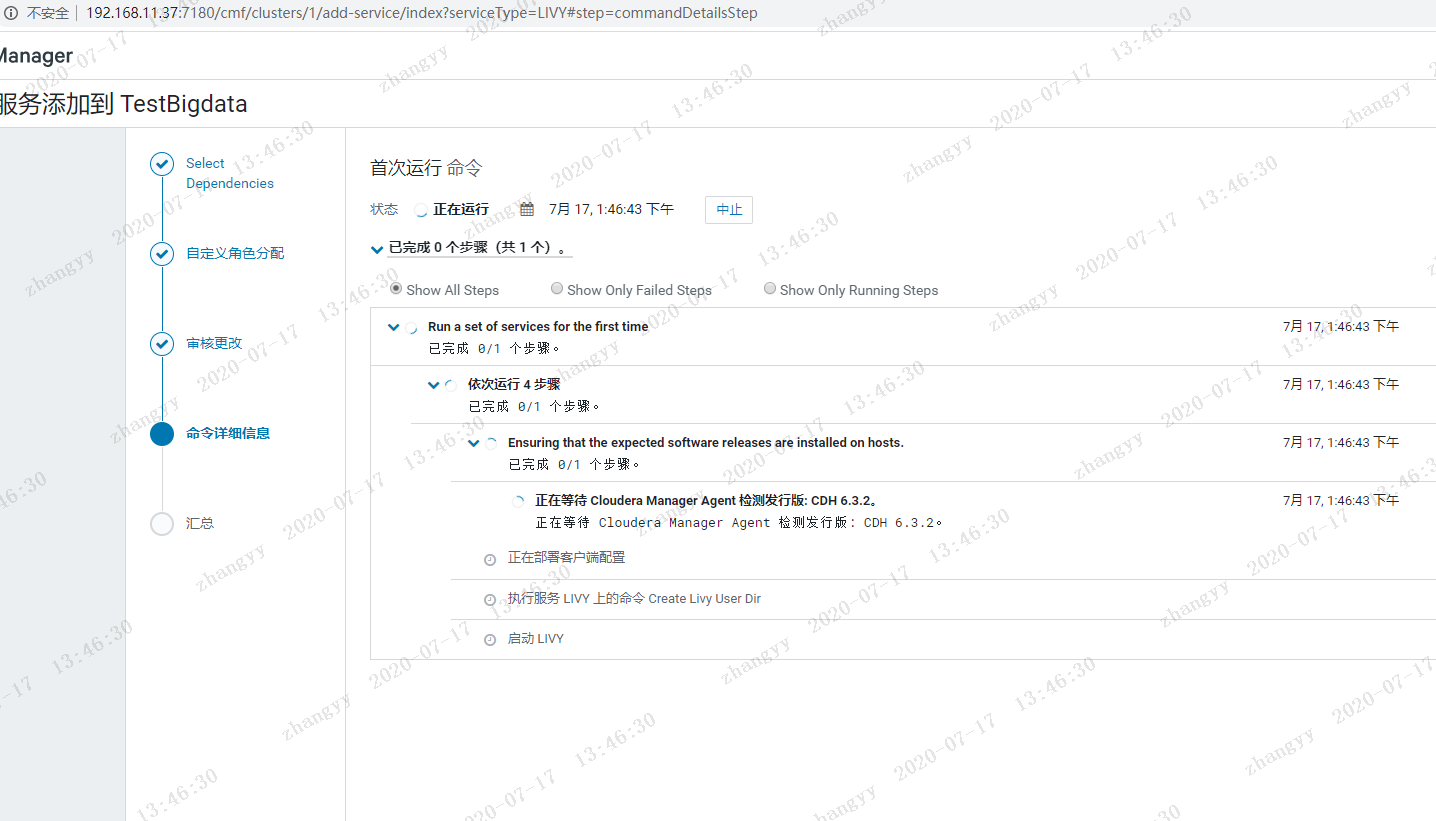
遇到问题:Error found before invoking supervisord: 'getpwnam(): name not found: livy'

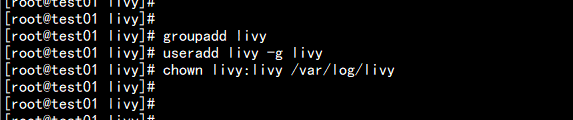
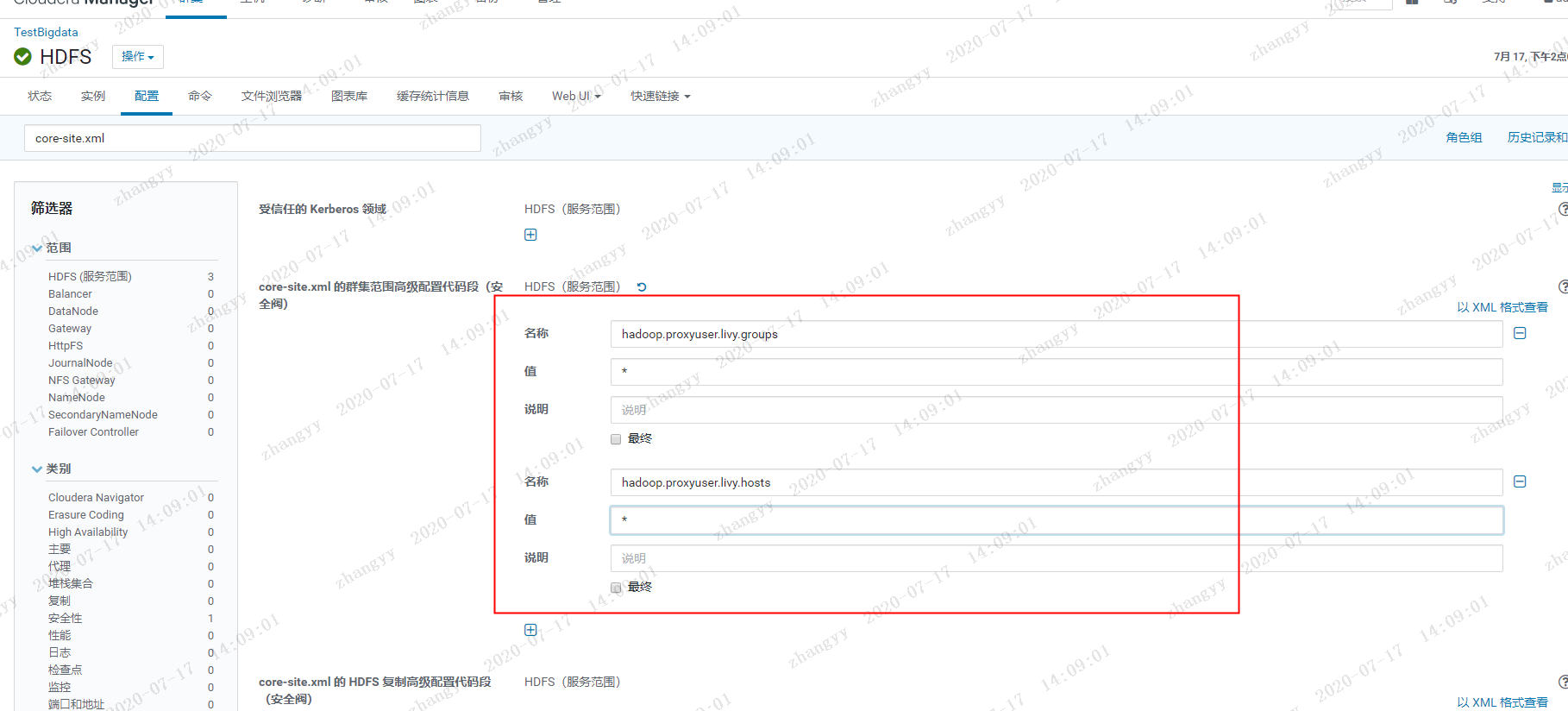
解决办法:解决办法:在Livy REST Server所在服务器上增加livy用户及用户组groupadd livyuseradd livy -g livychown livy:livy /var/log/livy在HDFS的core-site.xml 中添加一下配置:<property><name>hadoop.proxyuser.livy.groups</name><value>*</value></property><property><name>hadoop.proxyuser.livy.hosts</name><value>*</value></property>
添加完之后从新启动HDFS

添加zeppelin 服务在主机 节点 上创建 zepplin 的用户和组在 Zeppelin Server 服务所在的节点添加 zeppelin 用户和角色:groupadd zeppelinuseradd zeppelin -g zeppelinmkdir -p /var/log/zeppelinchown zeppelin:zeppelin /var/log/zeppelin

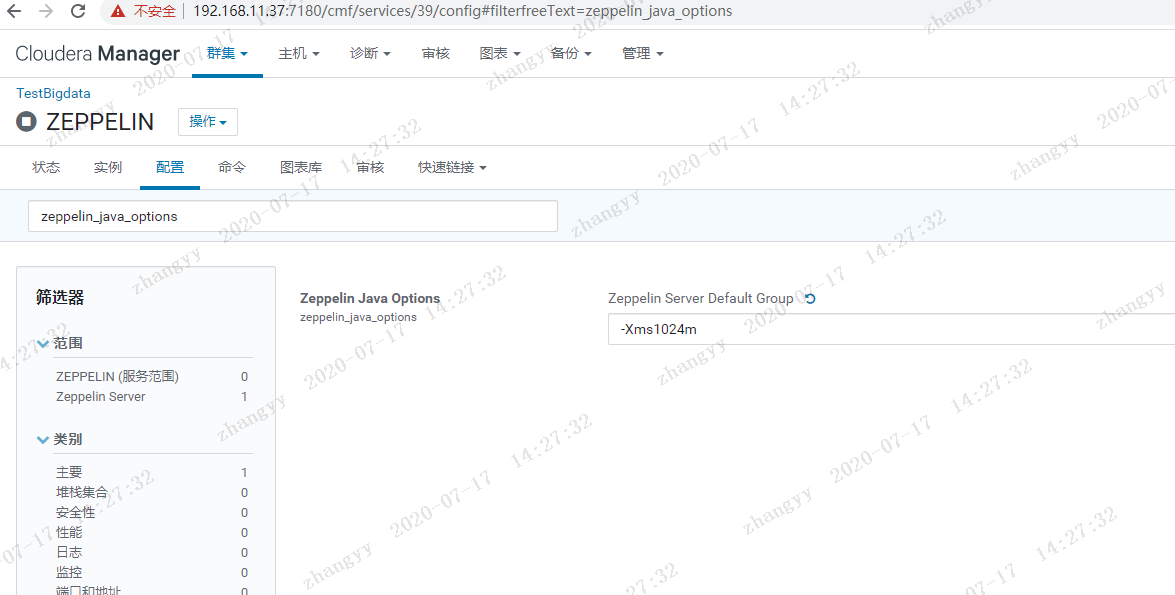
报错:由于错误 java.lang.IllegalArgumentException: The variable [${zeppelin_java_options}] does not have a corresponding value.,角色启动失败。解决:ZEPPELIN --> 配置 --> 搜索 zeppelin_java_options --> 添加参数 -Xms1024m --> 重启ZEPPELIN 服务
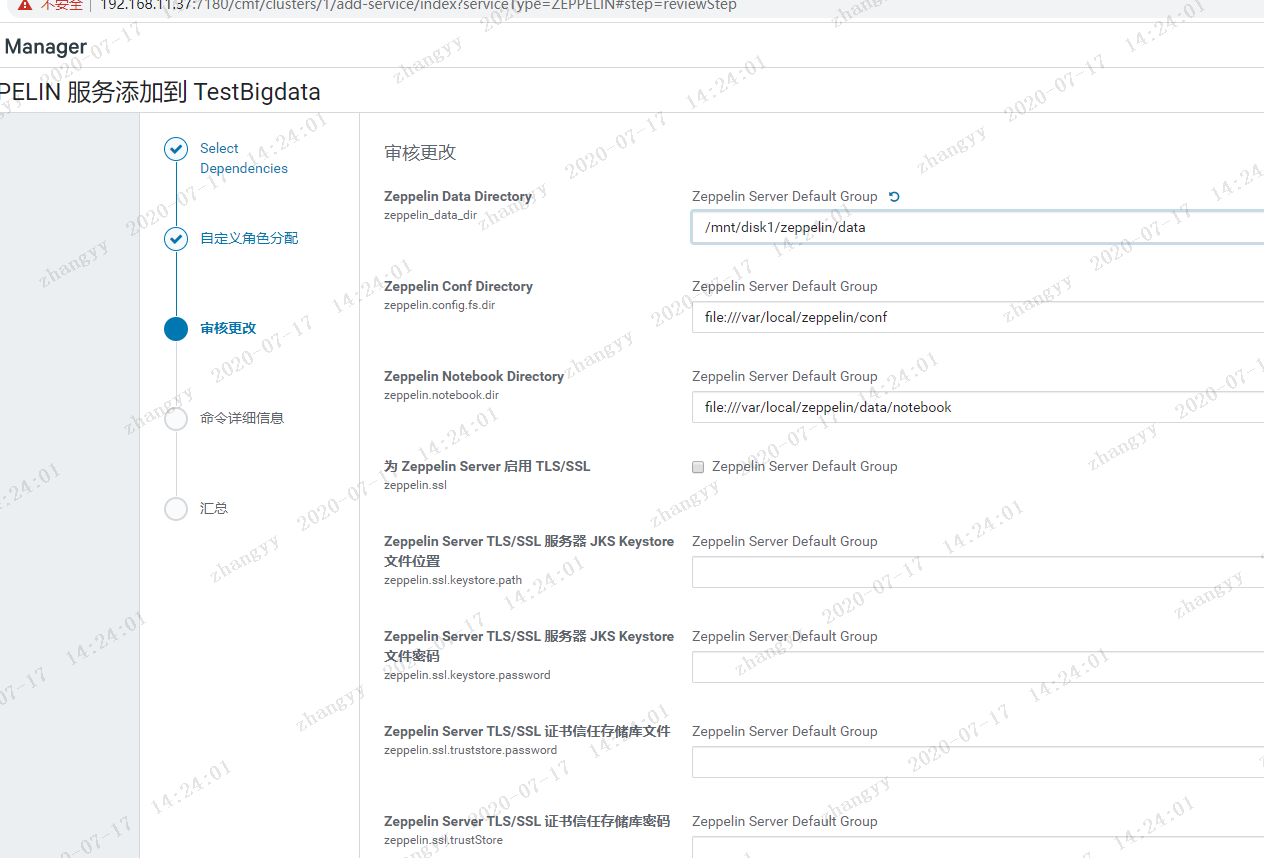
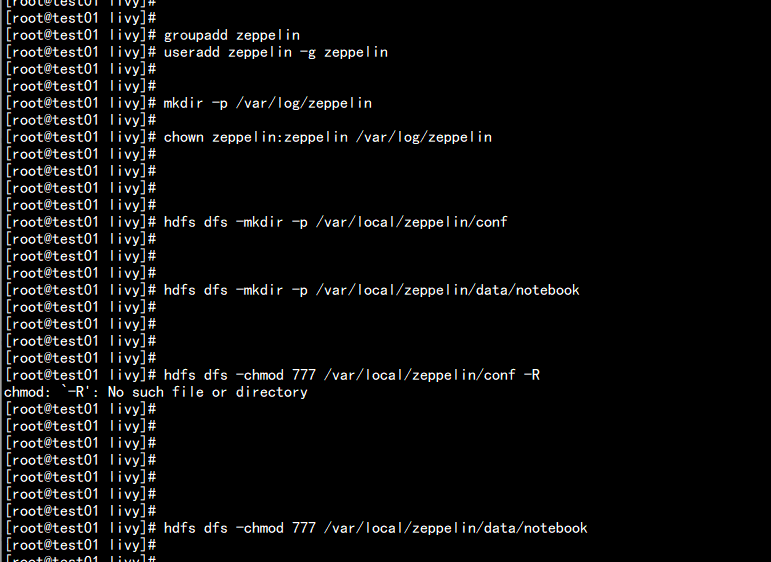
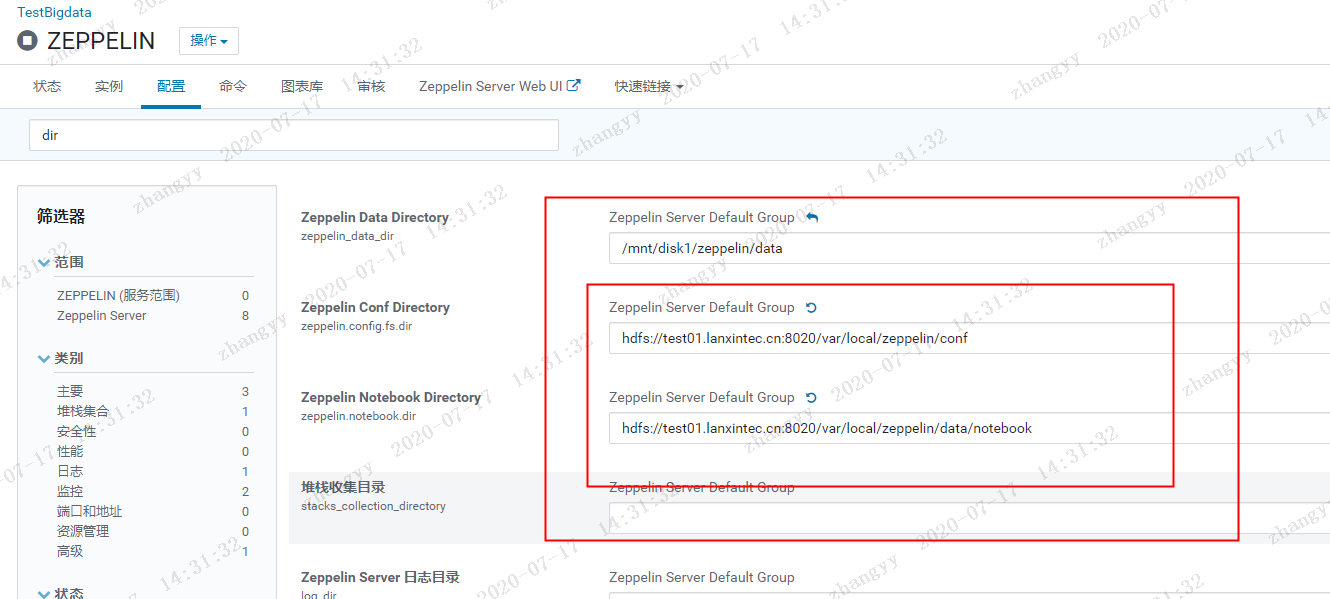
报错:mkdir: `file:///var/local/zeppelin/conf': Input/output error解决办法:ZEPPELIN --> 配置 --> 搜索 dir --> 修改配置 --> 重启ZEPPELIN 服务hdfs dfs -mkdir -p /var/local/zeppelin/confhdfs dfs -mkdir -p /var/local/zeppelin/data/notebookhdfs dfs -chmod 777 /var/local/zeppelin/confhdfs dfs -chmod 777 /var/local/zeppelin/data/notebook

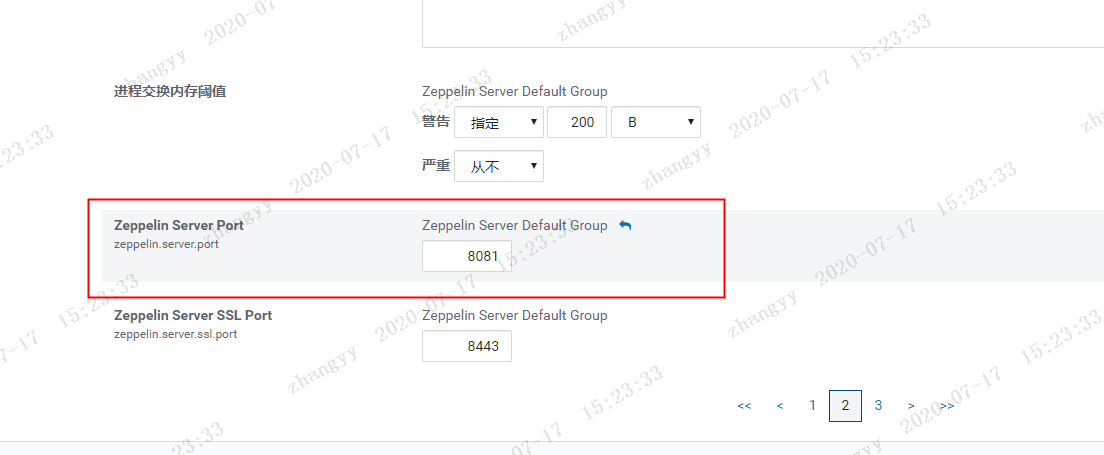
因为flyfish这边的 8080 端口 被占用了,改一下 zeppelin的端口 为 8081然后 改一下 zeppelin的 服务端 地址,然后从新启动zeppelin 服务
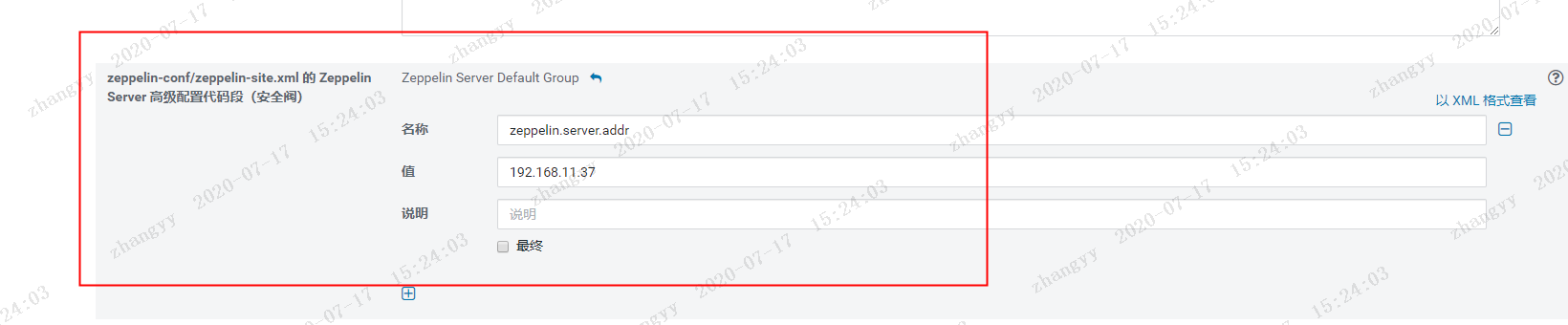
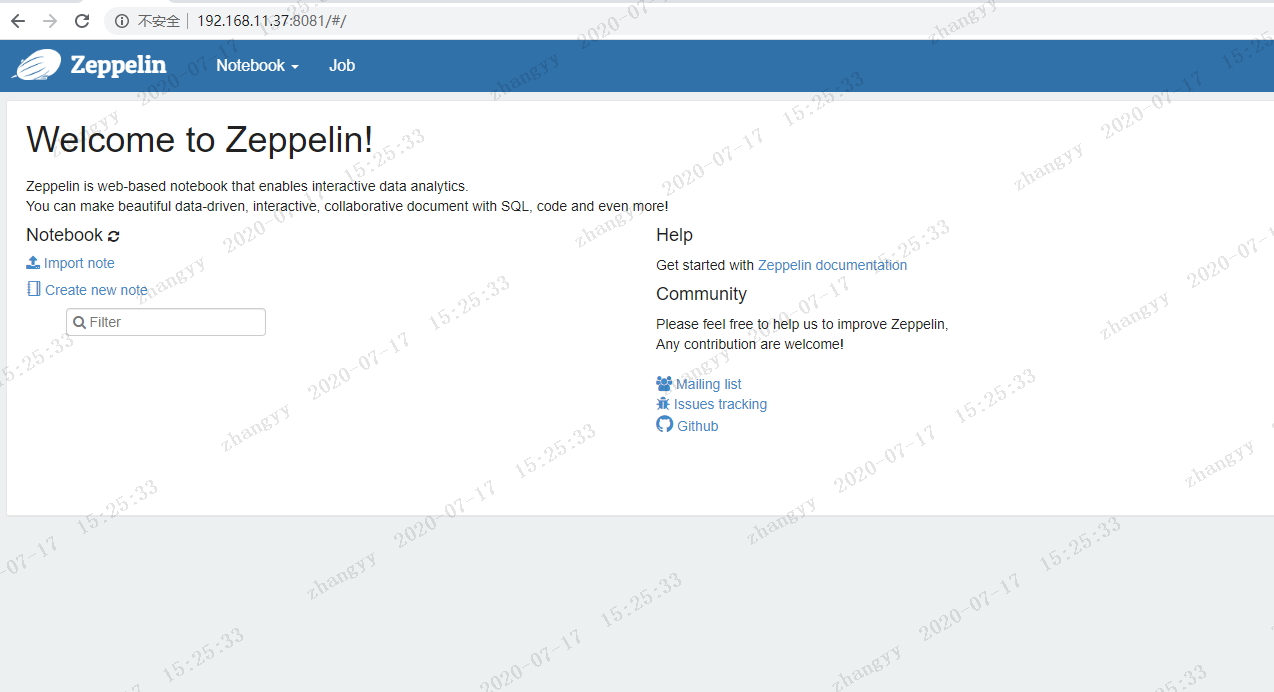
打开web:http://192.168.11.37:8081
四: 关于zeppelin 的测试
测试实例一:上传测试数据vim test.txt---hadoop hivespark zeppelinhadoop spark---hdfs dfs -put test.txt /tmp
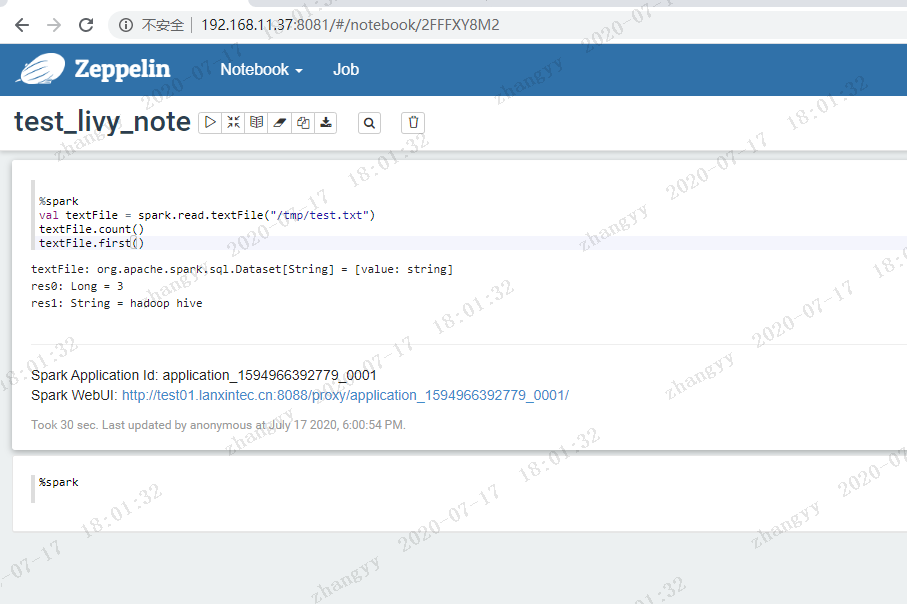
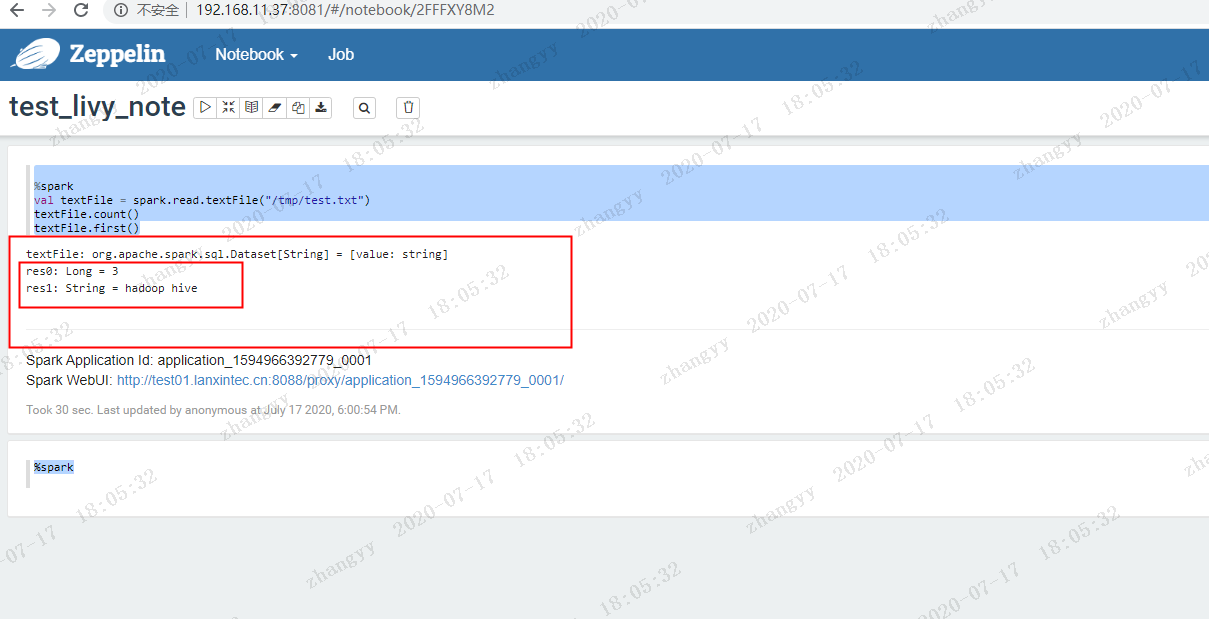
运行spark 测试程序%sparkval textFile = spark.read.textFile("/tmp/test.txt")textFile.count()textFile.first()
输出结果
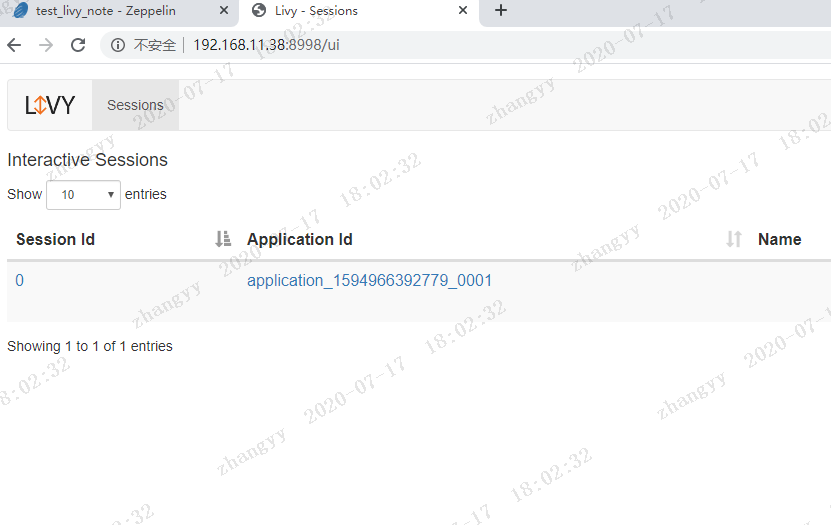
livy 的查询spark REST接口
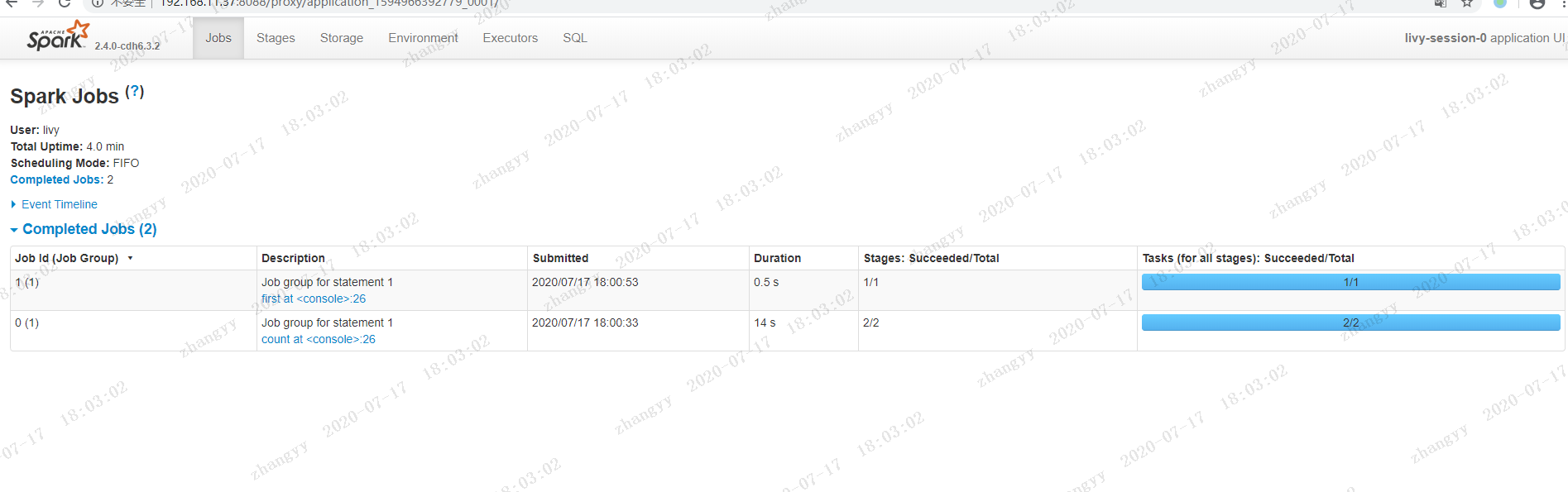
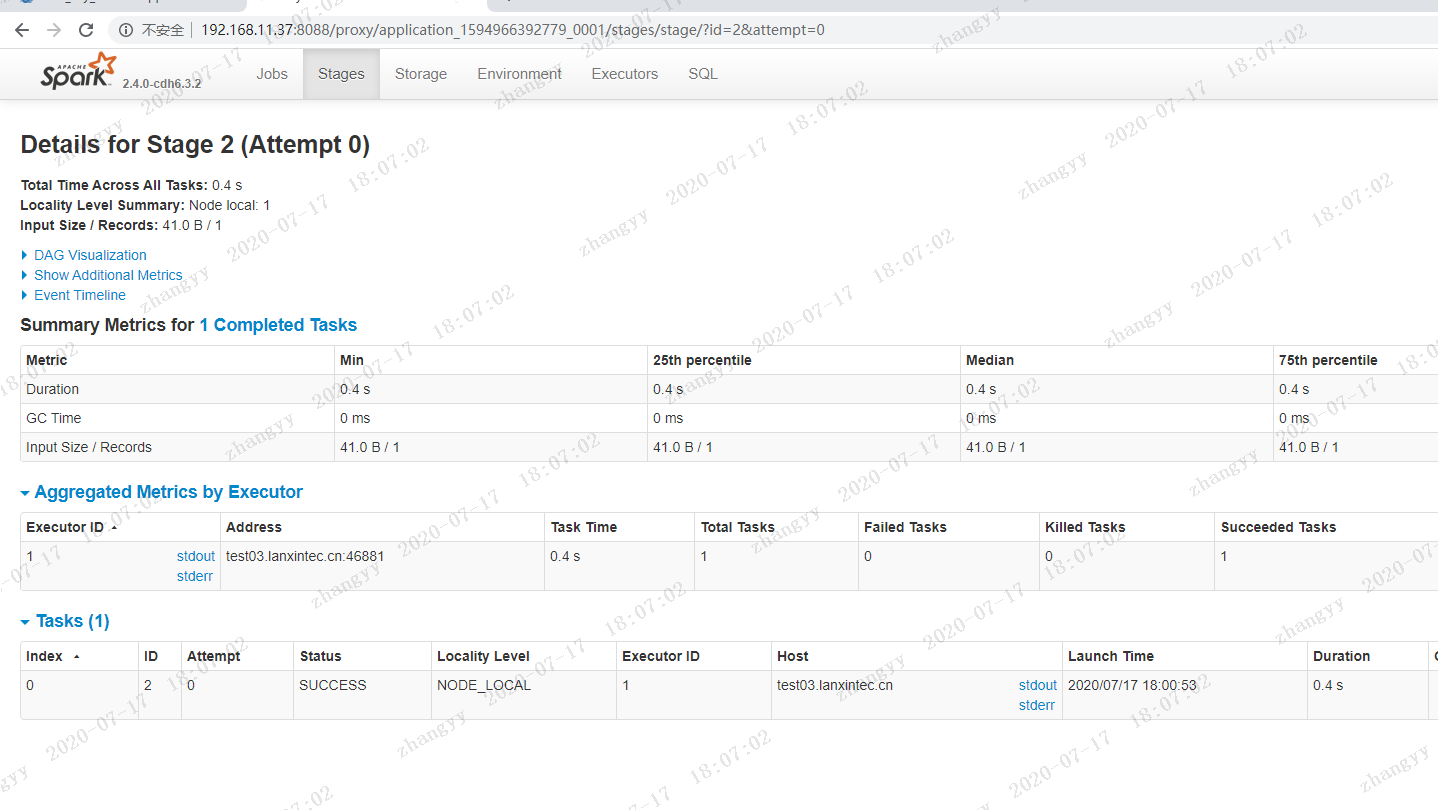
测试实例二:Data Refine下载需要bank数据,http://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank.zip首先,将csv格式数据转成Bank对象RDD,并过滤表头列上传到主节点:unzip bank.zip
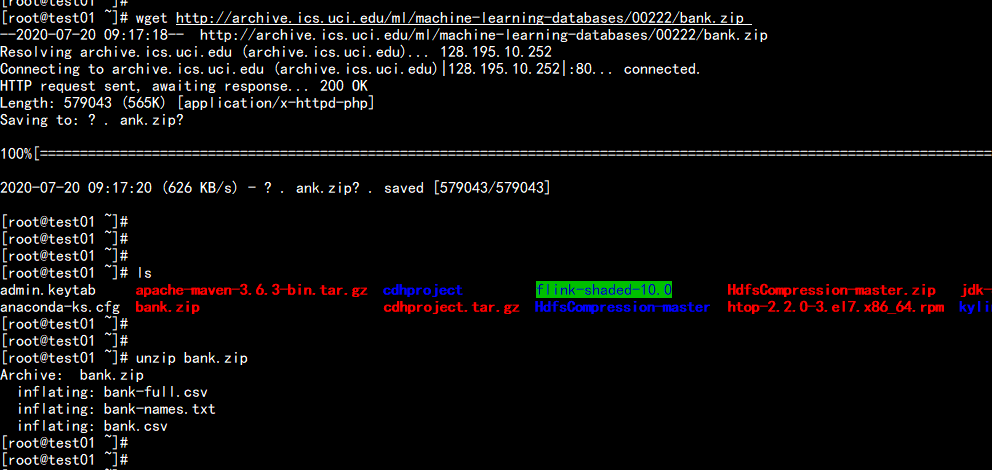
hdfs dfs -mkdir /tmp/testhdfs dfs -put bank-full.csv bank.csv bank-names.txt /tmp/test
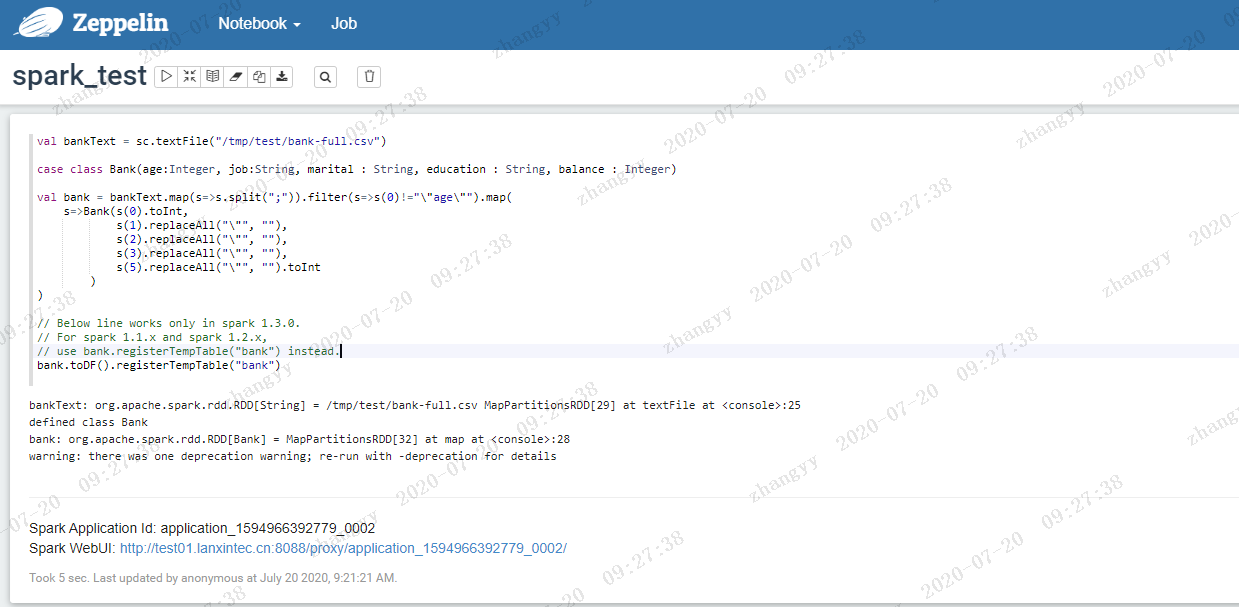
创建一个spark的notebookval bankText = sc.textFile("/tmp/test/bank-full.csv")case class Bank(age:Integer, job:String, marital : String, education : String, balance : Integer)val bank = bankText.map(s=>s.split(";")).filter(s=>s(0)!="\"age\"").map(s=>Bank(s(0).toInt,s(1).replaceAll("\"", ""),s(2).replaceAll("\"", ""),s(3).replaceAll("\"", ""),s(5).replaceAll("\"", "").toInt))// Below line works only in spark 1.3.0.// For spark 1.1.x and spark 1.2.x,// use bank.registerTempTable("bank") instead.bank.toDF().registerTempTable("bank")
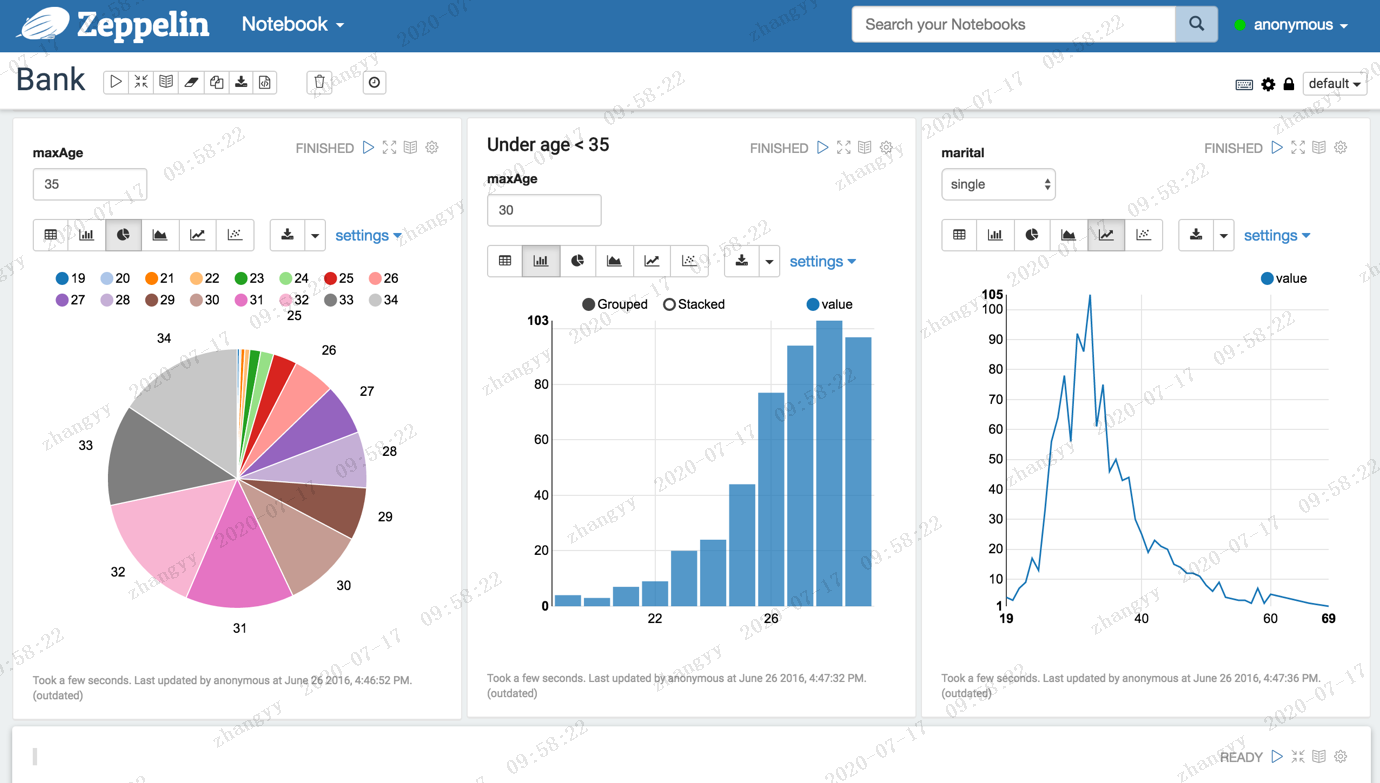
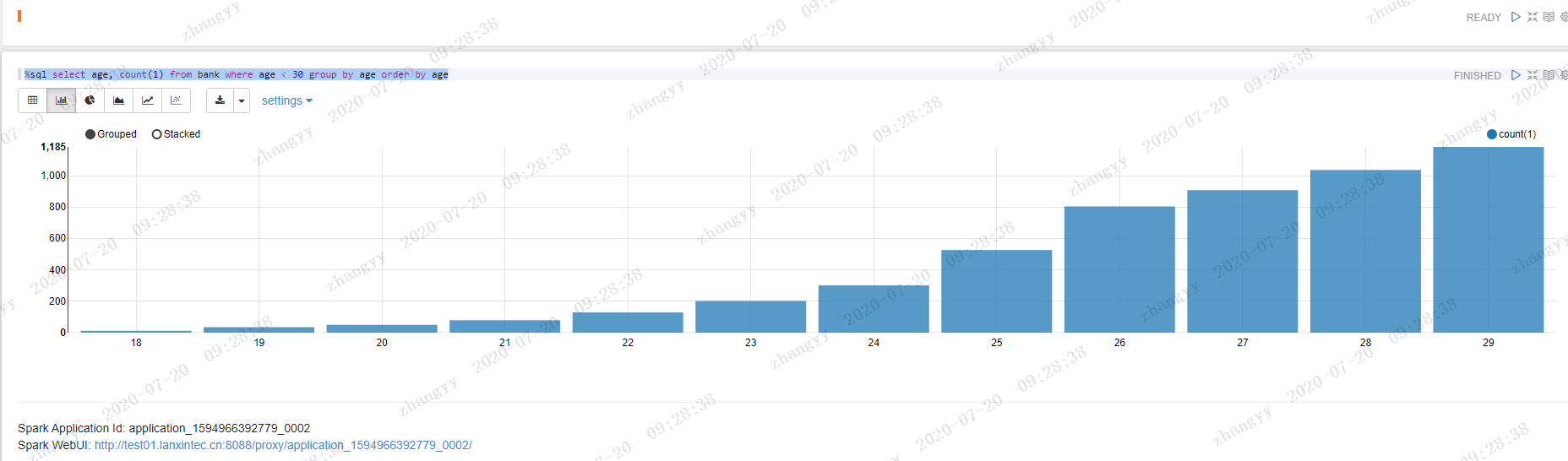
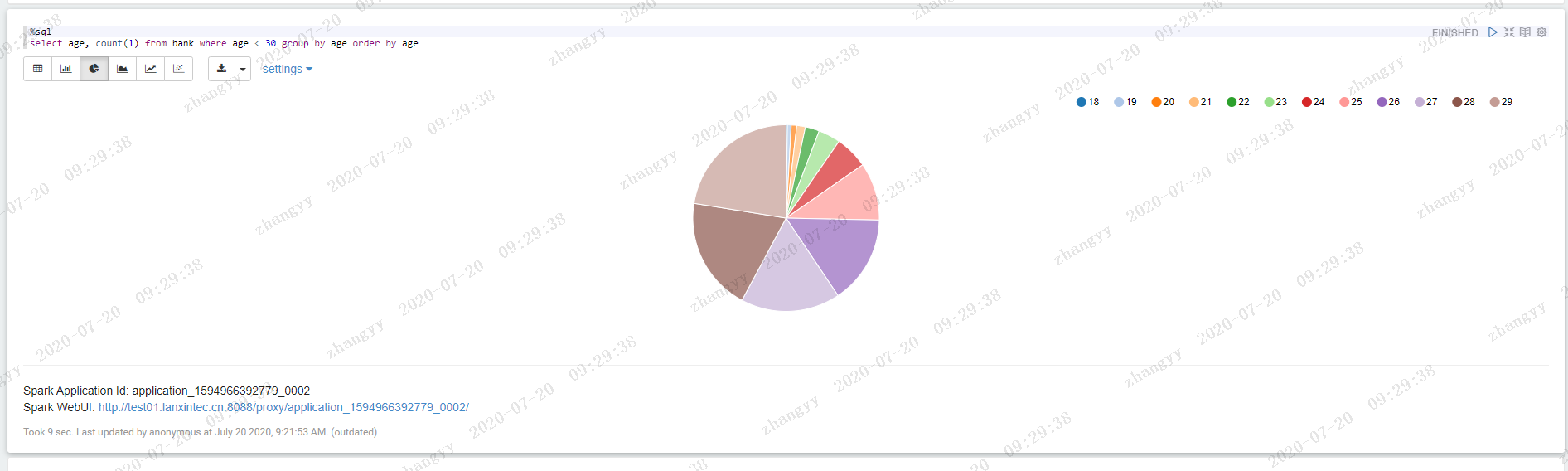
执行以下语句,可看到年龄的分布:%sql select age, count(1) from bank where age < 30 group by age order by age
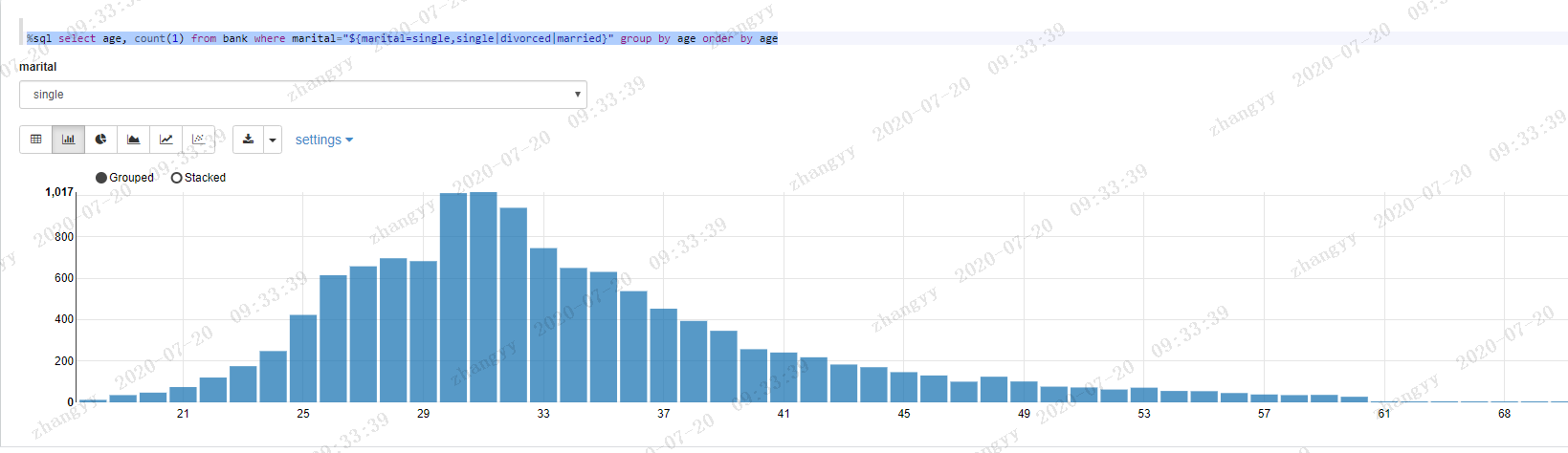
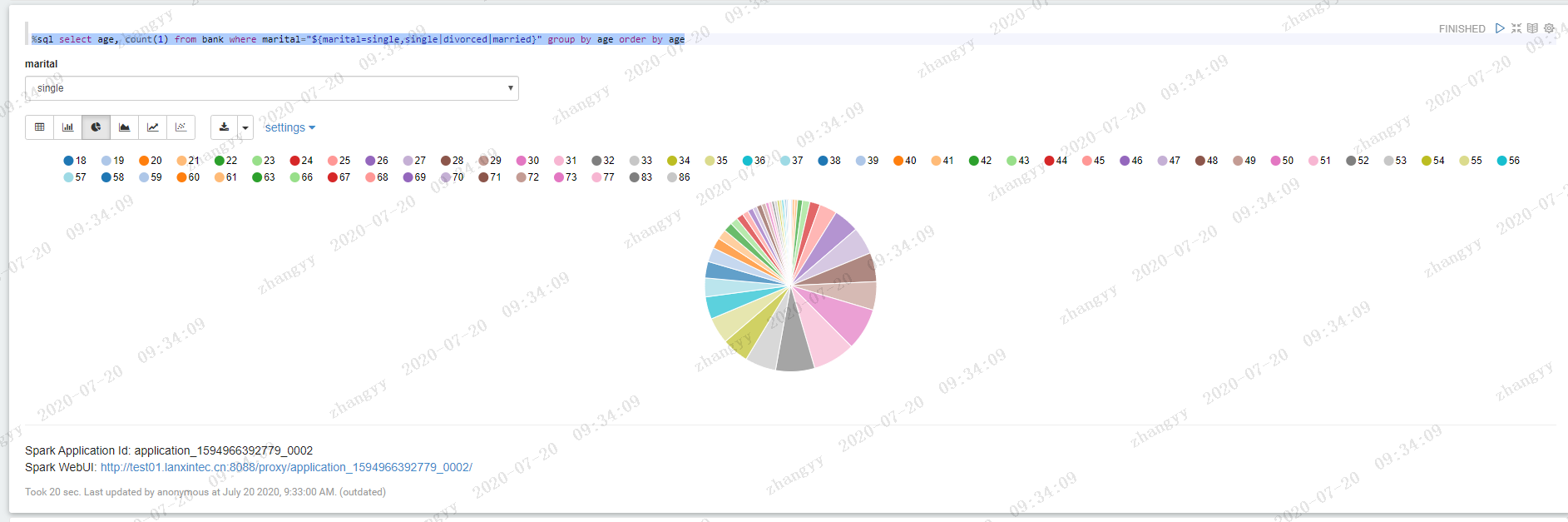
根据婚姻状况选项,查看年龄分布状况:%sql select age, count(1) from bank where marital="${marital=single,single|divorced|married}" group by age order by age
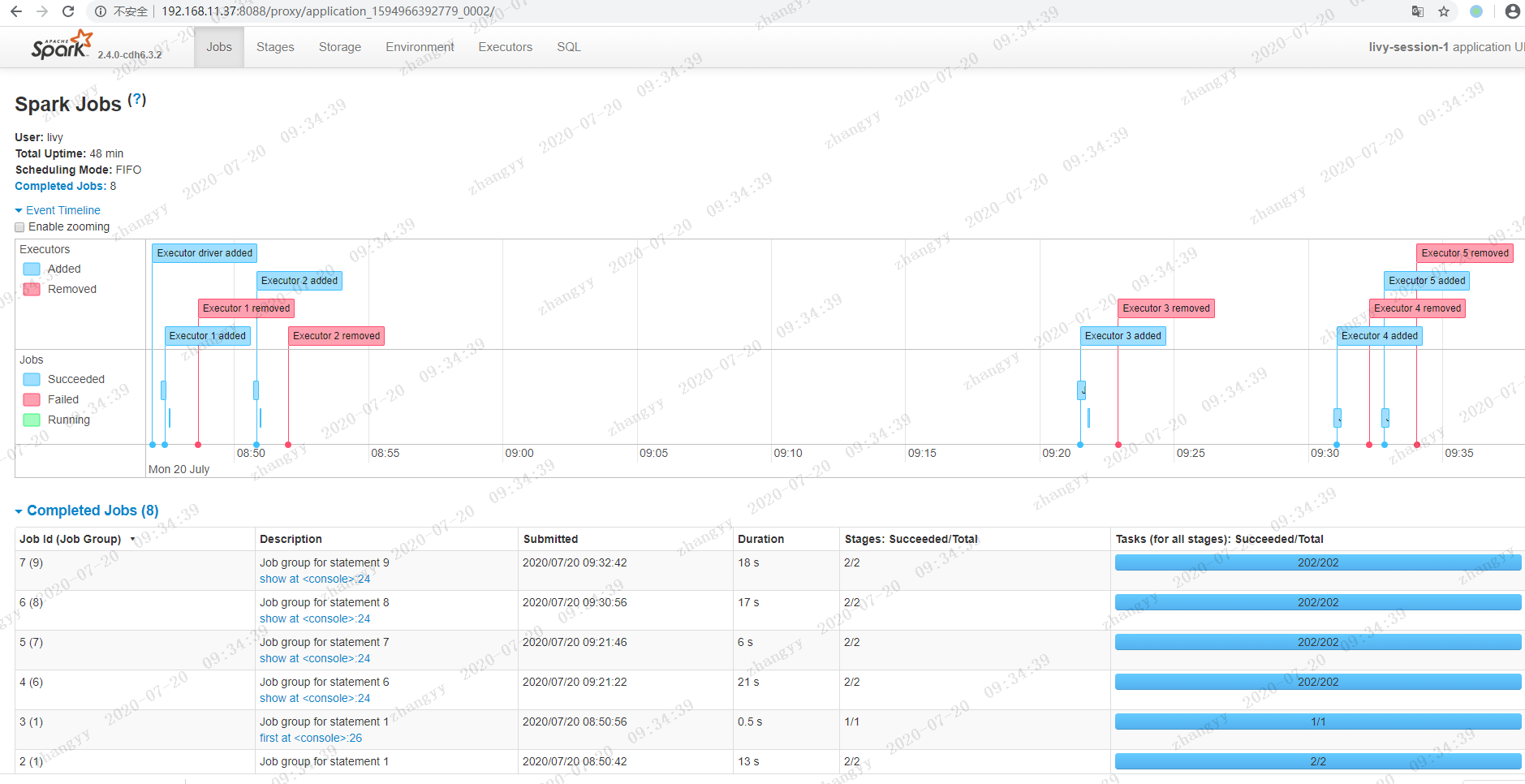
spark job 的分布
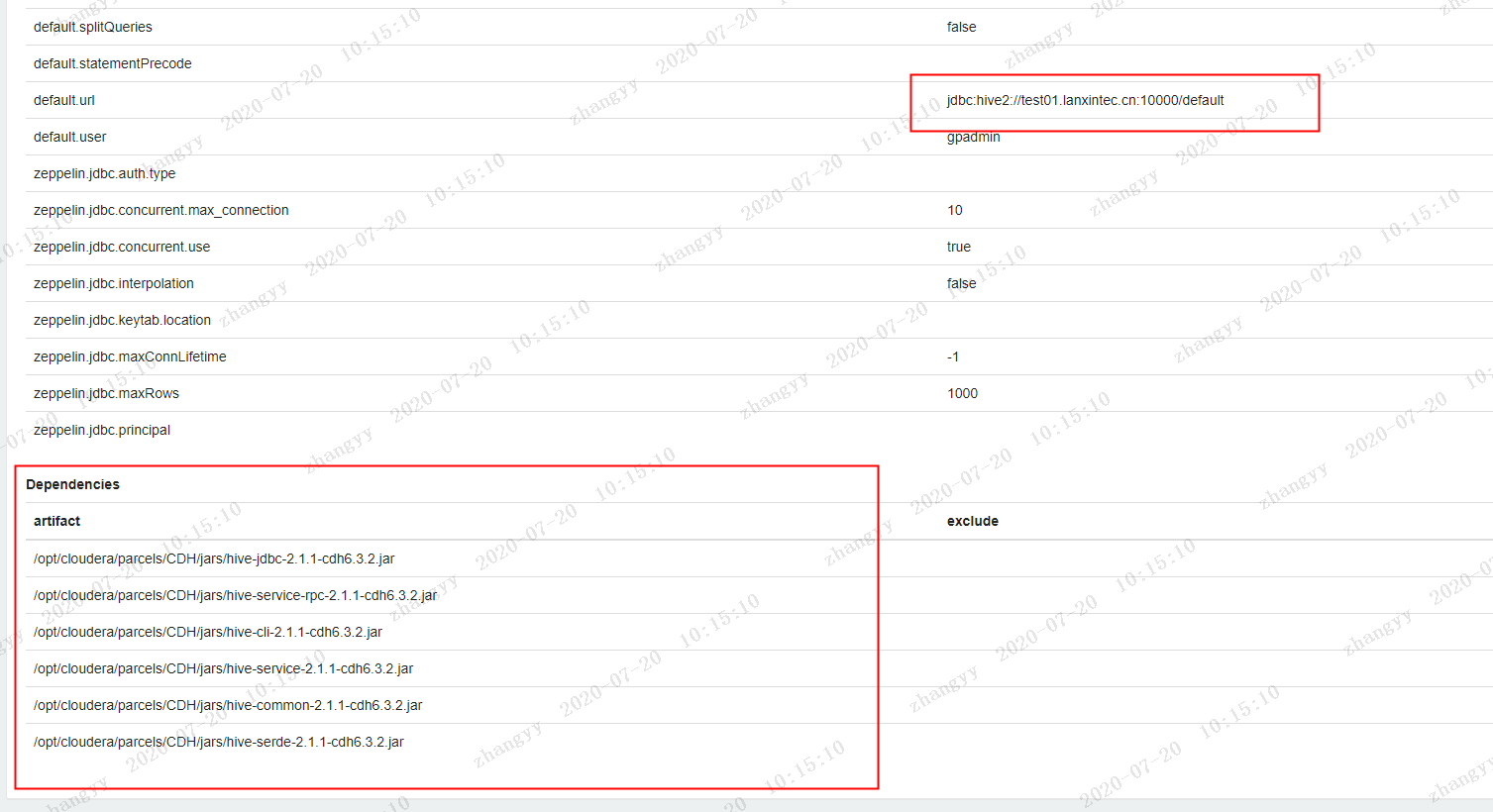
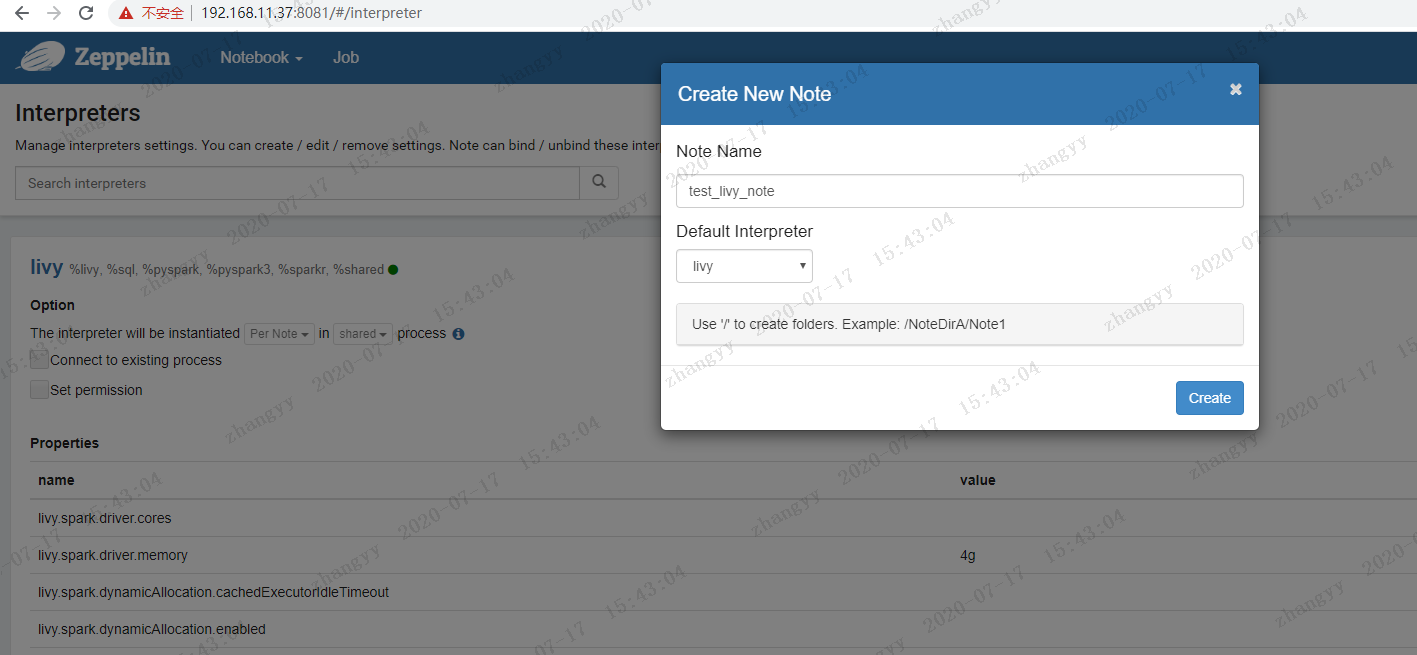
使用zeppelin 的配置 hive 连接create Interpreters
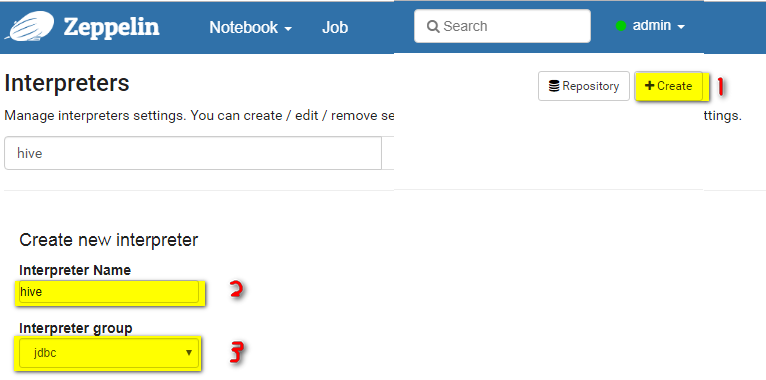
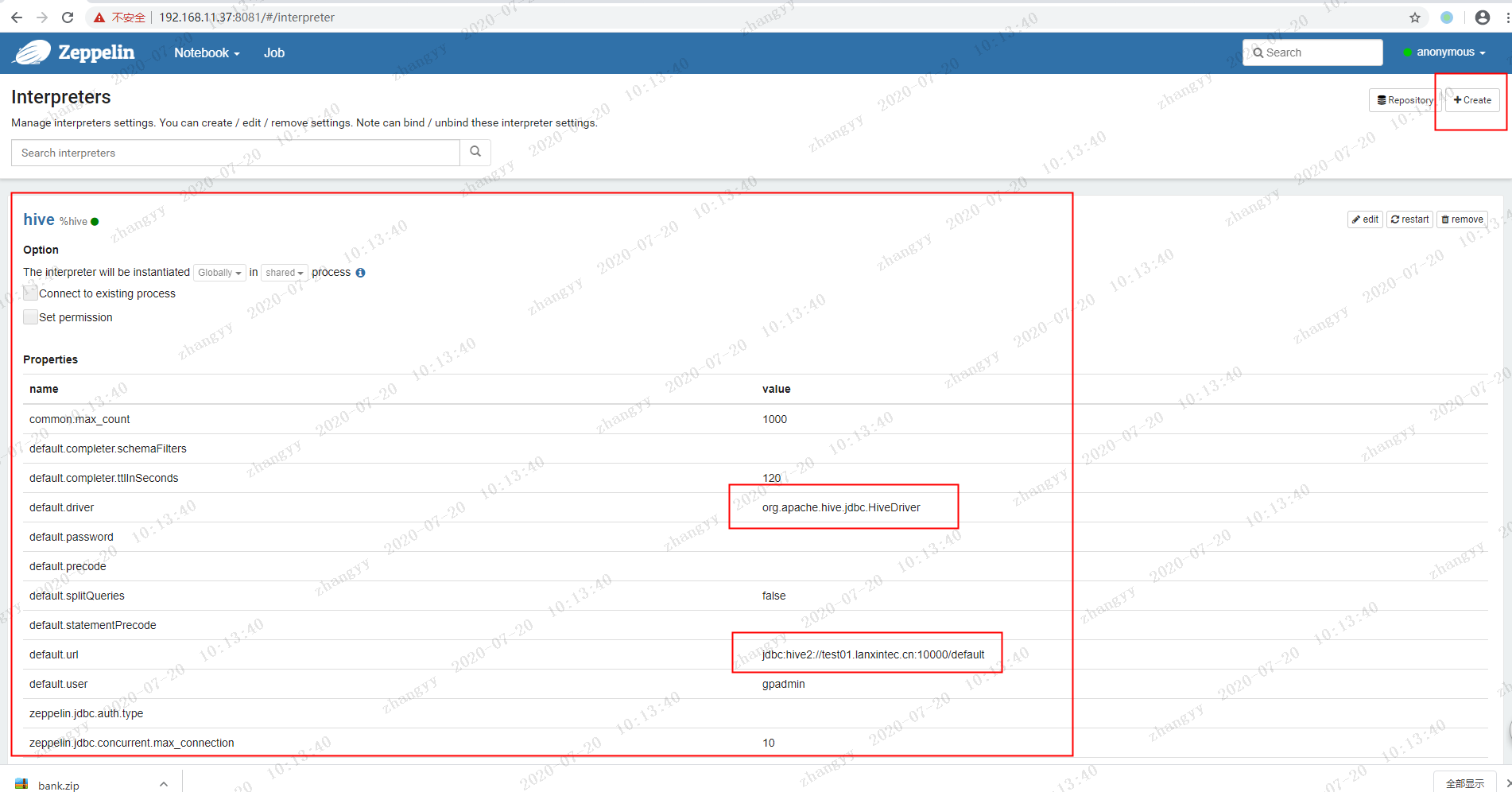
artifact的骨架配置/opt/cloudera/parcels/CDH/jars/hive-jdbc-2.1.1-cdh6.3.2.jar/opt/cloudera/parcels/CDH/jars/hive-service-rpc-2.1.1-cdh6.3.2.jar/opt/cloudera/parcels/CDH/jars/hive-cli-2.1.1-cdh6.3.2.jar/opt/cloudera/parcels/CDH/jars/hive-service-2.1.1-cdh6.3.2.jar/opt/cloudera/parcels/CDH/jars/hive-common-2.1.1-cdh6.3.2.jar/opt/cloudera/parcels/CDH/jars/hive-serde-2.1.1-cdh6.3.2.jar保存退出: