@zhangyy
2019-12-11T03:24:35.000000Z
字数 3743
阅读 493
hadoop 的组建概述
hadoop的部分
- 一:hdfs 的相关概念
- 二:yarn 的相关概念
一:hdfs 的相关概念:
1.1 hdfs 的来源:
HDFS 的来源源自于Google的GFS论文发表于2003年10月HDFS是GFS克隆版Hadoop Distributed File System易于扩展的分布式文件系统运行在大量普通廉价机器上,提供容错机制为大量用户提供性能不错的文件存取服务
1.2 hdfs 的架构:
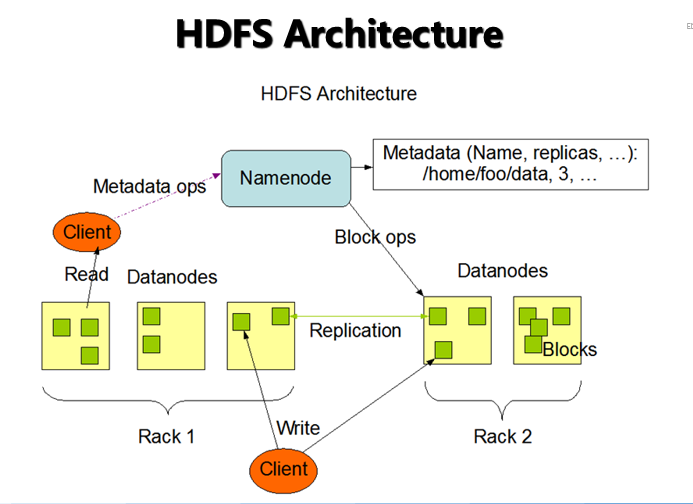
1. menode 是一个中心服务器,单一节点(简化系统的设计和实现),负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。2.操作,NameNode 负责文件元数据的操作,DataNode负责处理文件内容的读写请求,跟文件内容相关的数据流不经过NameNode,只会询问它跟那个DataNode联系,否则NameNode会成为系统的瓶颈。3.本存放在哪些DataNode上由 NameNode来控制,根据全局情况做出块放置决定,读取文件时NameNode尽量让用户先读取最近的副本,降低带块消耗和读取时延4.Namenode 全权管理数据块的复制,它周期性地从集群中的每个Datanode接收心跳信号和块状态报告(Blockreport)。接收到心跳信号意味着该Datanode节点工作正常。块状态报告包含了一个该Datanode上所有数据块的列表。
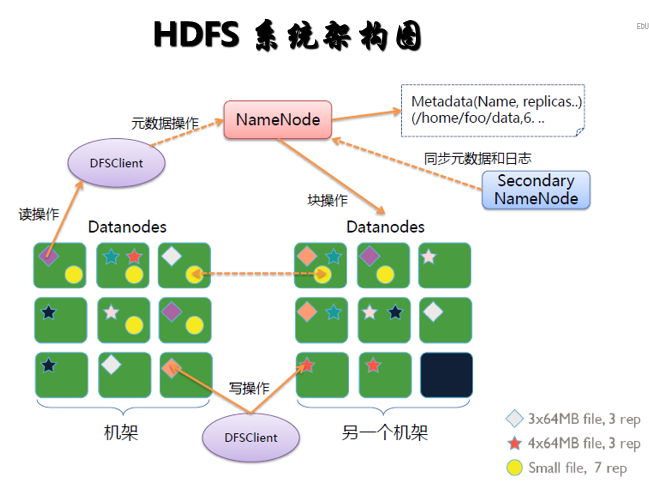
NameNode主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表和块所在DataNode等。DataNode在本地文件系统存储文件块数据,以及块数据的校验和。Secondary NameNode用来监控HDFS状态的辅助后台程序,每隔一段时间获取HDFS元数据的快照
1.3 namenode 的启动过程
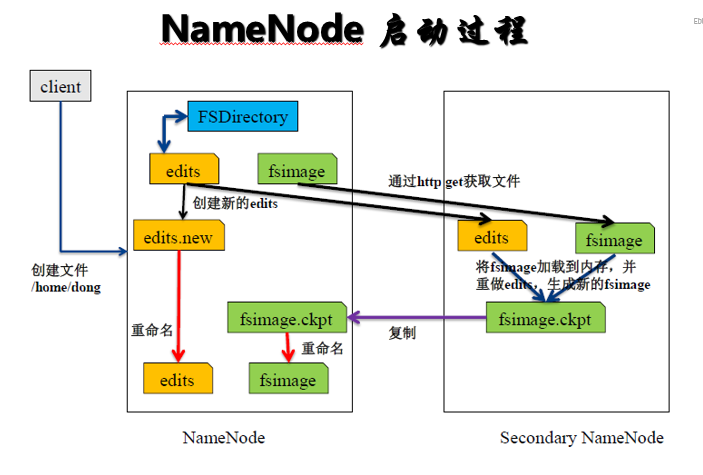
1、Name启动的时候首先将fsimage(镜像)载入内存,并执行(replay)编辑日志editlog的的各项操作;2、一旦在内存中建立文件系统元数据映射,则创建一个新的fsimage文件(这个过程不需SecondaryNameNode)和一个空的editlog;3、在安全模式下,各个datanode会向namenode发送块列表的最新情况;4、此刻namenode运行在安全模式。即NameNode的文件系统对于客服端来说是只读的。(显示目录,显示文件内容等。写、删除、重命名都会失败);5、NameNode开始监听RPC和HTTP请求解释RPC:RPC(Remote Procedure Call Protocol)——远程过程通过协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议;6、系统中数据块的位置并不是由namenode维护的,而是以块列表形式存储在datanode中;7、在系统的正常操作期间,namenode会在内存中保留所有块信息的映射信息。
1.4 DataNode 的作用
1.个数据块在DataNode以文件存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳2.DataNode启动后向NameNode注册,通过后,周期性(1小时)的向NameNode上报所有的块信息。3.心跳是每3秒一次,心跳返回结果带有NameNode给该DataNode的命令如复制块数据到另一台机器,或删除某个数据块。如果超过10分钟没有收到某个DataNode 的心跳,则认为该节点不可用。4.集群运行中可以安全加入和退出一些机器
1.5 hdfs 的存储活机制
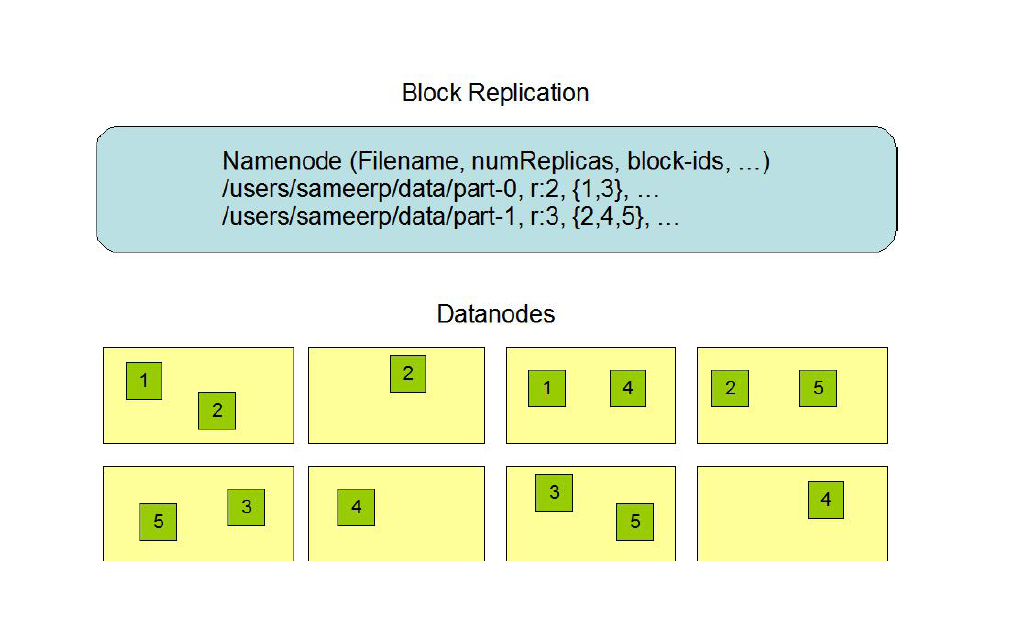
文件1.文件切分成块(默认大小128M),以块为单位,每个块有多个副本存储在不同的机器上,副本数可在文件生成时指定(默认3)2.NameNode 是主节点,存储文件的元数据如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个文件的块列表以及块所在的DataNode等等3.DataNode 在本地文件系统存储文件块数据,以及块数据的校验和。4.可以创建、删除、移动或重命名文件,当文件创建、写入和关闭之后不能修改文件内容。
数据损坏(corruption)处理1.当DataNode读取block的时候,它会计算checksum2.如果计算后的checksum,与block创建时值不一样,说明该block已经损坏。3.Client读取其它DN上的block。4.NameNode标记该块已经损坏,然后复制block达到预期设置的文件备份数5.DataNode 在其文件创建后三周验证其checksum
SafeMode 相关说明1.安全模式下,集群属于只读状态。但是严格来说,只是保证HDFS元数据信息的访问,而不保证文件的访问,因为文件的组成Block信息此时NameNode还不一定已经知道了。所以只有NameNode已了解了Block信息的文件才能独到。而安全模式下任何对HDFS有更新的操作都会失败.2.对于全新创建的HDFS集群,NameNode启动后不会进入安全模式,因为没有Block信息。
二:yarn 的相关概念
2.1 hadoop 1.x 与 hadoop 2.x 的 比较
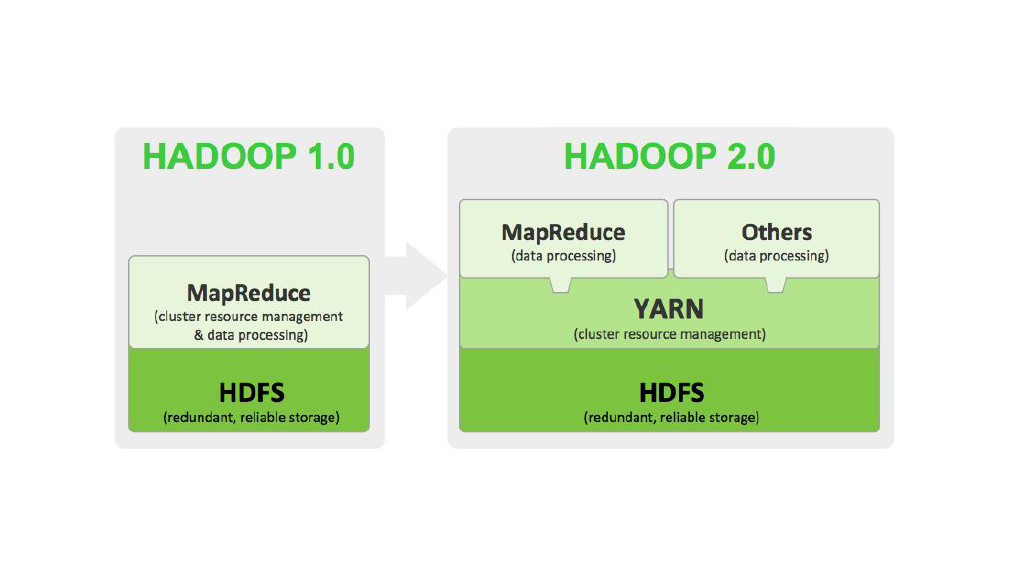
2.2 yarn 的架构图
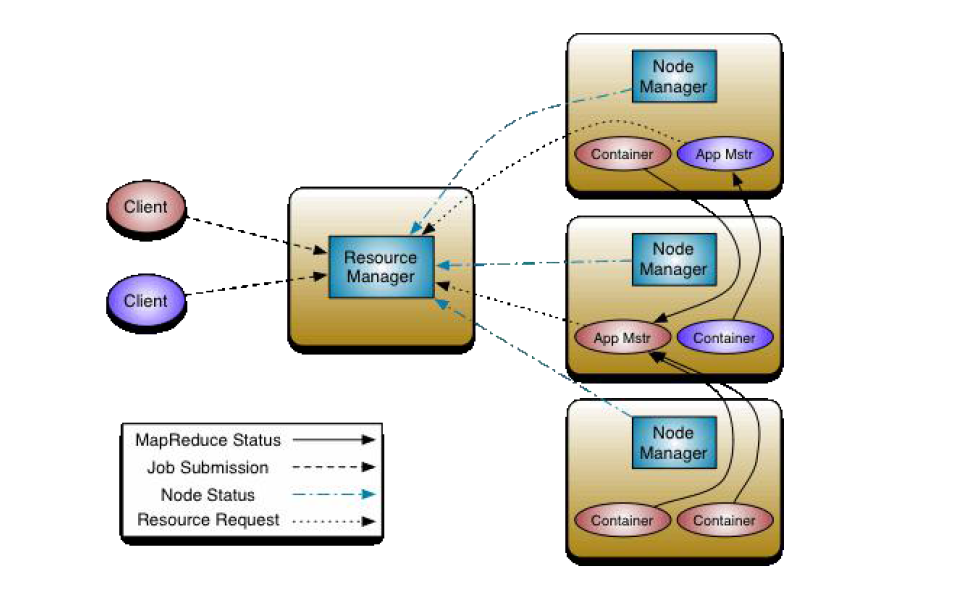
YARN服务组件1.YARN 总体上仍然是Master/Slave 结构,在整个资源管理框架中,ResourceManager 为Master,NodeManager 为Slave。2.ResourceManager 负责对各个NodeManager 上的资源进行统一管理和调度3.当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的。ApplicationMaster,它负责向ResourceManager 申请资源,并要求NodeManger 启动可以占用一定资源的任务。4.由于不同的ApplicationMaster 被分布到不同的节点上,因此它们之间不会相互影响
ResourceManager 的作用1.全局的资源管理器,整个集群只有一个,负责集群资源的统一管理和调度分配。功能1.1 处理客户端请求1.2 启动/监控ApplicationMaster1.3 监控NodeManager1.4 资源分配与调度
NodeManager 的作用1. 整个集群有多个,负责单节点资源管理和使用功能:1.1 单个节点上的资源管理和任务管理1.2 处理来自ResourceManager的命令1.3 处理来自ApplicationMaster的命令1.4 NodeManager管理抽象容器,这些容器代表着可供一个特定应用程序使用的针对每个节点的资源。1.5 定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态
Application Master 的作用:1.1 管理一个在YARN 内运行的应用程序的每个实例功能:1.2 数据切分1.3 为应用程序申请资源,并进一步分配给内部任务1.4 任务监控与容错1.5 负责协调来自ResourceManager的资源,幵通过NodeManager监视容器的执行和资源使用(CPU、内存等的资源分配)。
Container 的作用1. YARN中的资源抽象,封装某个节点上多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM向AM返回的资源便是用Container表示的。2. YARN 会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。功能2.1 对任务运行环境的抽象2.2 描述一系列信息2.3 任务运行资源(节点、内存、CPU)2.4 任务启动命令2.5 任务运行环境
YARN 资源管理1. 资源调度和资源隔离是YARN作为一个资源管理系统,最重要和最基础的两个功能。资源调度由ResourceManager完成,而资源隔离由各个NM实现。2. ResourceManager将某个NodeManager上资源分配给任务(这就是所谓的“资源调度”)后,NodeManager需按照要求为任务提供相应的资源,甚至保证这些资源应具有独占性,为任务运行提供基础的保证,这就是所谓的资源隔离。3. 当谈及到资源时,我们通常指内存,CPU和IO三种资源。Hadoop YARN同时支持内存和CPU两种资源的调度。4.内存资源的多少会会决定任务的生死,如果内存不够,任务可能会运行失败;相比之下,CPU资源则不同,它只会决定任务运行的快慢,不会对生死产生影响。5. YARN允许用户配置每个节点上可用的物理内存资源,注意,这里是“可用的”,因为一个节点上的内存会被若干个服务共享,比如一部分给YARN,一部分给HDFS,一部分给HBase等,YARN配置的只是自己可以使用的,配置参数如下:

6. 目前的CPU被划分成虚拟CPU(CPU virtual Core),这里的虚拟CPU是YARN自己引入的概念,初衷是,考虑到不同节点的CPU性能可能不同,每个CPU具有的计算能力也是不一样的,比如某个物理CPU的计算能力可能是另外一个物理CPU的2倍,这时候,你可以通过为第一个物理CPU多配置几个虚拟CPU弥补这种差异。用户提交作业时,可以指定每个任务需要的虚拟CPU个数。在YARN中,CPU相关配置参数如下:

