@zhangyy
2017-02-03T23:03:23.000000Z
字数 4374
阅读 508
mapreduce 高级案例倒排索引
hadoop的部分
- 理解【倒排索引】的功能
- 熟悉mapreduce 中的combine 功能
- 根据需求编码实现【倒排索引】的功能,旨在理解mapreduce 的功能。
一:理解【倒排索引】的功能
倒排索引:
由于不是根据文档来确定文档所包含的内容,而是进行相反的操作,因而称为倒排索引
简单来说根据单词,返回它在哪个文件中出现过,而且频率是多少的结果。例如:就像百度里的搜索,你输入一个关键字,那么百度引擎就迅速的在它的服务器里找到有该关键字的文件,并根据频率和其他一些策略(如页面点击投票率)等来给你返回结果。
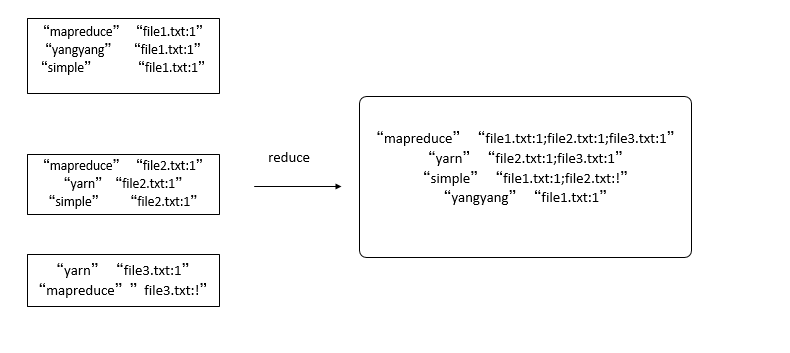
二:熟悉mapreduce 中的combine 功能
1 Map过程:Map过程首先分析输入的对,得到索引中需要的信息:单词,文档URI 和词频。key:单词和URI.value:出现同样单词的次数。
2 Combine过程:经过map方法处理后,Combine过程将key值相同的value值累加,得到一个单词在文档中的词频。
3 Reduce过程:经过上述的俩个过程后,Reduce过程只需要将相同的key值的value值组合成倒排引索文件的格式即可,其余的事情直接交给MapReduce框架进行处理
三:根据需求编码实现【倒排索引】的功能,旨在理解mapreduce 的功能。
InvertedIndexMapReduce.java
package org.apache.hadoop.studyhadoop.index;import java.io.IOException;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.conf.Configured;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Mapper.Context;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.util.Tool;import org.apache.hadoop.util.ToolRunner;/**** @author zhangyy**/public class InvertedIndexMapReduce extends Configured implements Tool {// step 1 : mapper/*** public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>*/public static class WordCountMapper extends //Mapper<LongWritable, Text, Text, Text> {private Text mapOutputKey = new Text();private Text mapOutputValue = new Text("1");@Overridepublic void map(LongWritable key, Text value, Context context)throws IOException, InterruptedException {// split1String[] lines = value.toString().split("##");// get urlString url = lines[0];// split2String[] strs = lines[1].split(" ");for (String str : strs) {mapOutputKey.set(str + "," + url);context.write(mapOutputKey, mapOutputValue);}}}// set combiner classpublic static class InvertedIndexCombiner extends //Reducer<Text, Text, Text, Text> {private Text CombinerOutputKey = new Text();private Text CombinerOutputValue = new Text();@Overridepublic void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {// splitString[] strs = key.toString().split(",");// set keyCombinerOutputKey.set(strs[0] + "\n");// set valueint sum = 0;for (Text value : values) {sum += Integer.valueOf(value.toString());}CombinerOutputValue.set(strs[1] + ":" + sum);context.write(CombinerOutputKey, CombinerOutputValue);}}// step 2 : reducerpublic static class WordCountReducer extends //Reducer<Text, Text, Text, Text> {private Text outputValue = new Text();@Overridepublic void reduce(Text key, Iterable<Text> values, Context context)throws IOException, InterruptedException {// TODOString result = new String();for (Text value : values) {result += value.toString() + "\t";}outputValue.set(result);context.write(key, outputValue);}}// step 3 : jobpublic int run(String[] args) throws Exception {// 1 : get configurationConfiguration configuration = super.getConf();// 2 : create jobJob job = Job.getInstance(//configuration,//this.getClass().getSimpleName());job.setJarByClass(InvertedIndexMapReduce.class);// job.setNumReduceTasks(tasks);// 3 : set job// input --> map --> reduce --> output// 3.1 : inputPath inPath = new Path(args[0]);FileInputFormat.addInputPath(job, inPath);// 3.2 : mapperjob.setMapperClass(WordCountMapper.class);// TODOjob.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Text.class);// ====================shuffle==========================// 1: partition// job.setPartitionerClass(cls);// 2: sort// job.setSortComparatorClass(cls);// 3: combinejob.setCombinerClass(InvertedIndexCombiner.class);// 4: compress// set by configuration// 5 : group// job.setGroupingComparatorClass(cls);// ====================shuffle==========================// 3.3 : reducerjob.setReducerClass(WordCountReducer.class);// TODOjob.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);// 3.4 : outputPath outPath = new Path(args[1]);FileOutputFormat.setOutputPath(job, outPath);// 4 : submit jobboolean isSuccess = job.waitForCompletion(true);return isSuccess ? 0 : 1;}public static void main(String[] args) throws Exception {args = new String[] {"hdfs://namenode01.hadoop.com:8020/input/index.txt","hdfs://namenode01.hadoop.com:8020/outputindex/"};// get configurationConfiguration configuration = new Configuration();// configuration.set(name, value);// run jobint status = ToolRunner.run(//configuration,//new InvertedIndexMapReduce(),//args);// exit programSystem.exit(status);}}
上传文件:
hdfs dfs -put index.txt /input
代码运行结果:
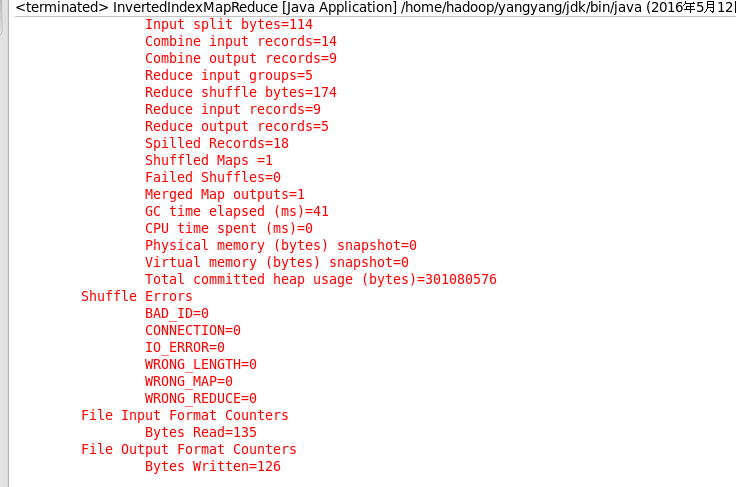
输出结果: