@zhangyy
2020-07-20T03:02:48.000000Z
字数 4160
阅读 488
hadoop 分布式环境搭建处理
hadoop的部分
- 一: 环境配置
- 二:系统环境的初始化
- 三:安装hadoop与配置处理
- 四:环境测试
一: 环境配置
- 1.1系统软件要求:
系统:CentOS 6.4 X64软件:Hadoop-2.5.2.tar.gznative-2.5.2.tar.gzjdk-7u67-linux-x64.tar.gz将所有软件安装上传到/home/hadoop/yangyang/ 下面- 主机名配置:192.168.3.1 master.hadoop.com192.168.3.2 slave1.hadoop.com192.168.3.3 slave2.hadoop.com
- 角色分配处理

二:系统环境的初始化
- 2.1 三台虚拟机配置NTP 时间同步处理
以 master.hadoop.com 配置 作为NTP SERVER,master.hadoop.com master.hadoop.com NTP 配置:master.hadoop.com去网上同步时间

#加入开机自启动
#echo “ntpdate –u 202.112.10.36 ” >> /etc/rc.d/rc.local#vim /etc/ntp.conf
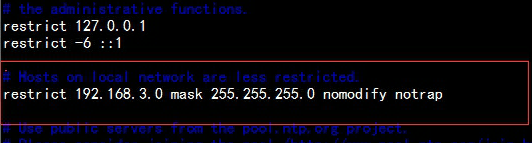
#取消下面两行的#
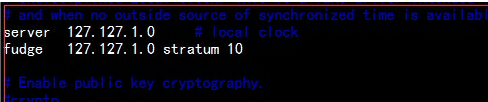
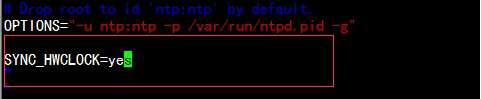
#vim /etc/sysconfig/ntpd增加:
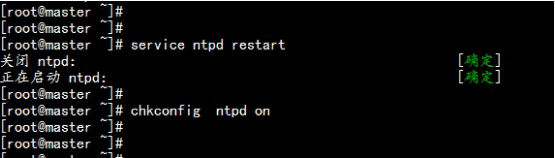
#service ntpd restart#chkconfig ntpd on
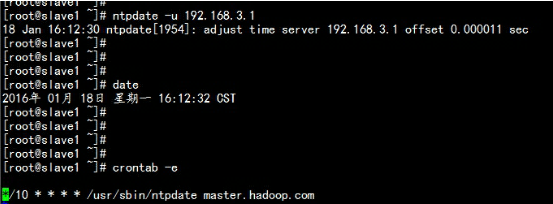
slave1.hadoop.com与slave2.hadoop.com 配置计划任务处理将从master.hadoop.com 同步时间crontab –e*/10 * * * * /usr/sbin/ntpdate master.hadoop.com
slave1.hadoop.com
slave2.hadoop.com
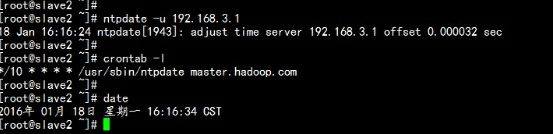
- 2.2 三台虚拟机配置jdk环境
安装jdktar -zxvf jdk-7u67-linux-x64.tar.gzmv jdk-7u67-linux-x64 jdk环境变量配置#vim .bash_profile到最后加上:export JAVA_HOME=/home/hadoop/yangyang/jdkexport CLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jarexport HADOOP_HOME=/home/hadoop/yangyang/hadoopPATH=$PATH:$HOME/bin:$JAVA_HOME/bin:${HADOOP_HOME}/bin
等所有软件安装部署完毕在进行source .bash_profilejava –version

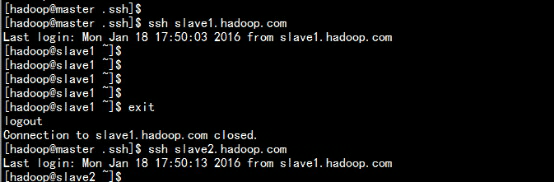
- 2.3:SSH 免密钥登陆:
ssh-keygen-------一种按回车键即可生成。(三台服务器一样)slave1和slave2的配置cd .sshscp id_rsa.pub hadoop@192.168.3.1:/home/hadoop/.ssh/slave1.pubscp id_rsa.pub hadoop@192.168.3.1:/home/hadoop/.ssh/slave2.pubmaste的配置cat id_rsa.pub >> authorized_keyscat slave1.pub >> authorized_keyscat slave2.pub >> authorized_keyschmod 600 authorized_keysscp authorized_keys hadoop@slave1.hadoop.com:/home/hadoop/.ssh/scp authorized_keys hadoopslave2.hadoop.com:/home/hadoop/.ssh/
测试:
三:安装hadoop与配置处理
3.1 安装hadoop 与配置文件处理tar -zxvf hadoop-2.5.2.tar.gzmv hadoop-2.5.2 hadoopcd /home/hadoop/yangyang/hadoop/etc/hadoop3.2更换native 文件rm -rf lib/native/*tar –zxvf hadoop-native-2.5.2.tar.gz –C hadoop/lib/nativecd hadoop/lib/native/
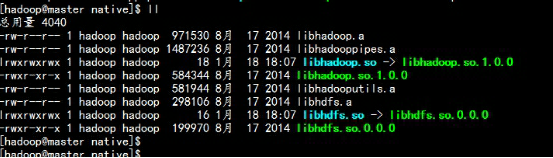
编辑core-site.xml 文件:
<configuration><property><name>fs.defaultFS</name><value>hdfs://master.hadoop.com:8020</value></property><name>hadoop.tmp.dir</name><value>/home/hadoop/yangyang/hadoop/data</value><description>hadoop_temp</description></property></configuration>
编辑hdfs-site.xml 文件:
<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.http-address</name><value>master.hadoop.com:50070</value></property><property><name>dfs.namenode.secondary.http-address</name><value>slave2.hadoop.com:50090</value></property></configuration>
编辑mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>slave2.hadoop.com:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>slave2.hadoop.com:19888</value></property></configuration>
编辑yarn-site.xml
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>slave1.hadoop.com</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>
编辑hadoop-env.sh 文件:
export JAVA_HOME=/home/hadoop/yangyang/jdkexport HADOOP_PID_DIR=/home/hadoop/yangyang/hadoop/data/tmpexport HADOOP_SECURE_DN_PID_DIR=/home/hadoop/yangyang/hadoop/data/tmp
编辑mapred-env.sh 文件:
export JAVA_HOME=/home/hadoop/yangyang/jdkexport HADOOP_MAPRED_PID_DIR=/home/hadoop/yangyang/hadoop/data/tmp
编辑yarn-env.sh 文件:
vim yarn-env.sh
export JAVA_HOME=/home/hadoop/yangyang/jdk
编辑slaves 文件
vim slaves
master.hadoop.comslave1.hadoop.comslave2.hadoop.com
3.3 同步到所有节点slave1和slave2
cd /home/hadoop/yangyang/tar –zcvf hadoop.tar.gz hadoopscp hadoop.tar.gz hadoop@192.168.3.2:/home/hadoop/yangyang/scp hadoop.tar.gz hadoop@192.168.3.3:/home/hadoop/yangyang/
3.4 格式化文件系统HDFS
master.hadoop.com 主机上执行:cd hadoop/bin/./hdfs namenode –format3.5 启动hdfsmaster.hadoop.com 主机上执行:cd hadoop/sbin/./start-dfs.sh

3.6启动start-yarn.sh
slave1.hadoop.comcd hadoop/sbin/./start-yarn.sh
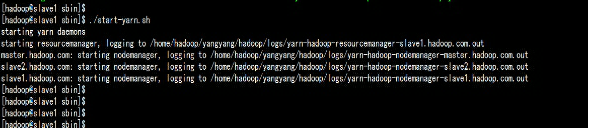
3.7 启动日志功能:
slave1.hadoop.comcd hadoop/sbin/./mr-jobhistory-daemon.sh start historyserver

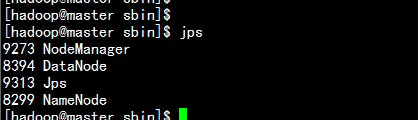
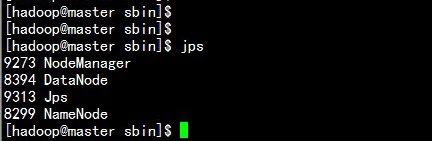
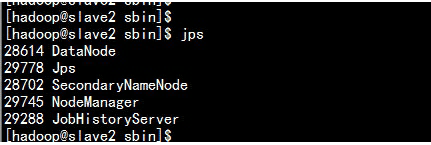
3.8 参照分配表处理

master.hadoop.com 主机:
slave1.haodop.com 主机:
Slave2.hadoop.com 主机
四:环境测试
master.hadoop.com
上面的HDFS
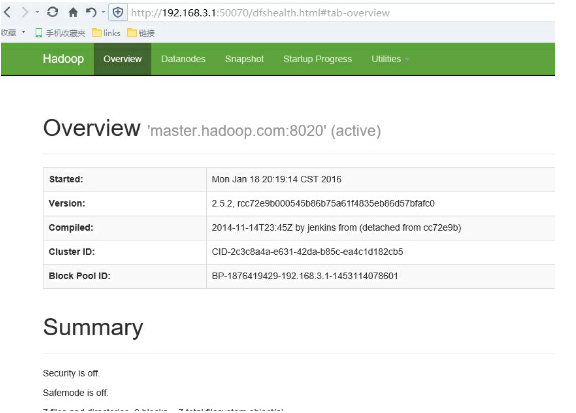
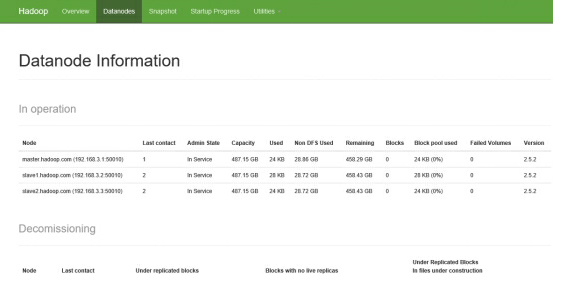
slave1.hadoop.com
上的yarn
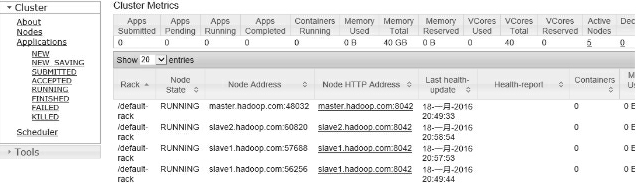
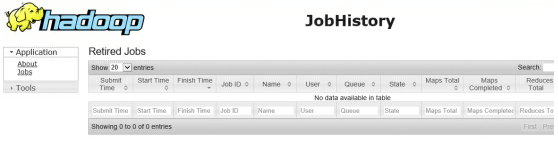
slave2.hadoop.com上面的jobhistory
hadoop 环境的测试与检查:
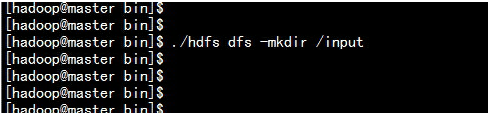
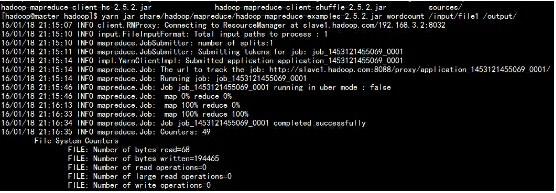
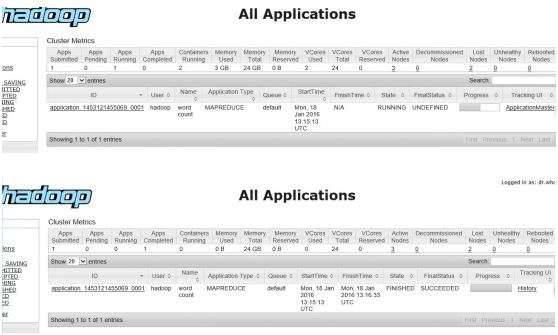
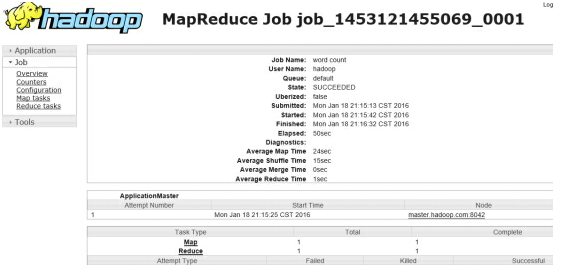
创建,上传,运行wordcount 检测