@zhangyy
2021-09-15T15:40:06.000000Z
字数 2785
阅读 642
ClickHouse数据库的基础
ClickHouse系列
一:ClickHouse 介绍
1.1 数据的应用分类
从数据库的业务应用类型来分,一般有三种:OLTP,OLAP, HTAPOLTP: 联机事务处理OLTP 是 传统关系型数据库的主要应用,其主要面向基本的,日常的事务处理,例如银行交易,消费等业务,我们平时接触最多的属于这种类型OLAP:联机分析处理,OLAP 是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策分析支持,并提供直观的易懂的查询结果,如:大数据分析,报表,可视化。HTAP:混合事务分析处理(OLTP+OLAP),可以同时支持完成处理事务与 分析事务
1.2 数据库的存储方式
从数据库的存储方式来分,一般分为:行存储,列式存储行级别存储(Row)数据是按照行数据为基础的逻辑存储单元进行存储,一行中的数据在存储介质中以连续存储 形式存在,如:Oracle,MySQL postgresql DB2, SQL SERVER 等 传统的关系型级别的数据库列存储(Column)数据是安装列为存储的逻辑存储单元进行存储,一列中的数据在存储介质中以连续存储形式存在。如:clickhouse,hbase,greenplum,HP vertica , HANA 等分布式数据库。
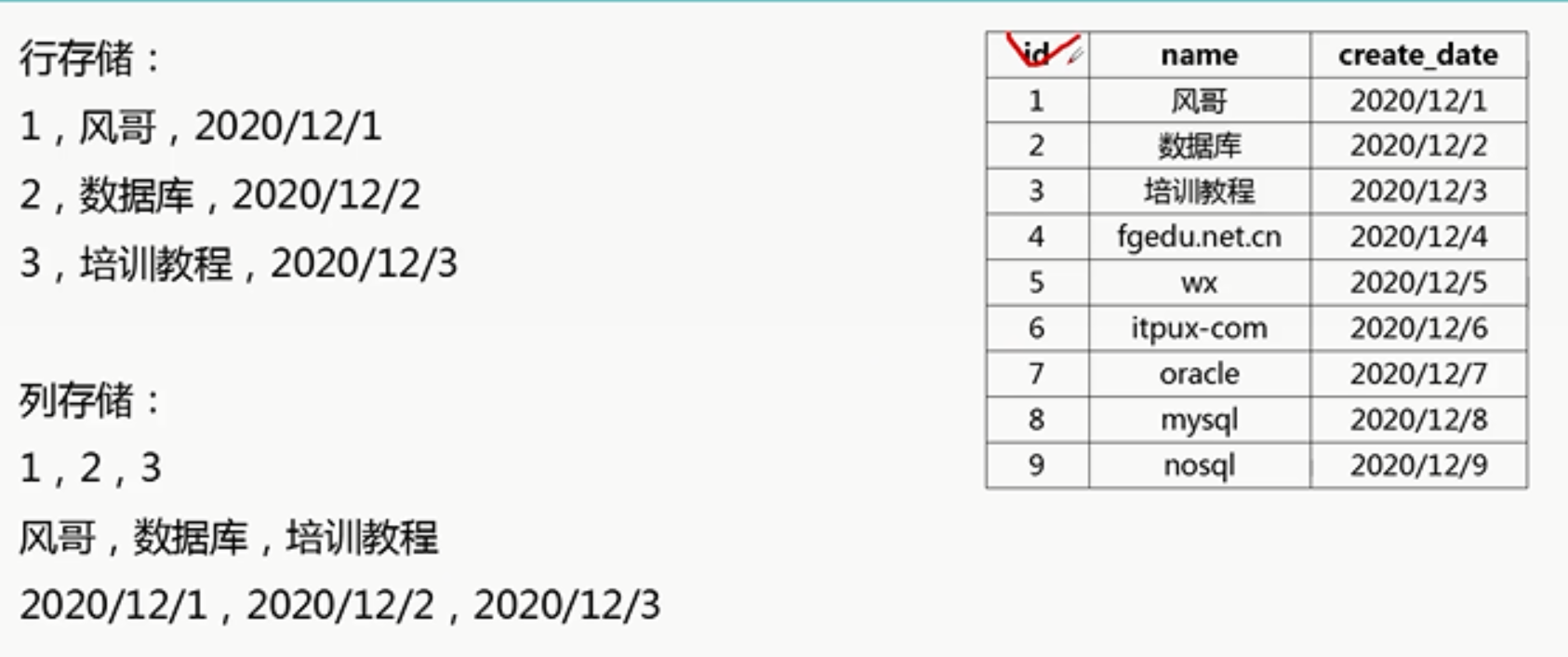
行式数据库:1. 数据是按行存储的,行存储的写入是一次性完成的,消耗的时间比列存储少,并且能够保证数据的完整性,缺点是数据读取过程中会产生冗余数据。2. 没有索引的查询使用大量I/O ,可通过索引加快查询效率,但是建立索引和物化视图需要花费成本高,面对大量的查询需求,数据库必须被大量的读取才能满足需求。列式数据库:1.数据按列存储,即每一列单独存放,数据即索引,在写入效率,保证数据完整性上都不如行级别的存储,他的优势是在每次读取只访问查询涉及的列,不会产生冗余数据,可以大量降低系统I/O2. 每一个列由一个线程来处理,即查询的并发处理性能高,有多少CPU 就用多少CPU3. 每一列数据类型一致,数据特征相似,可以高效压缩,提升查询速度。
1.3 clickhouse的数据库介绍
clickhouse 是 2016 年 俄罗斯yandex 公司开源出来的一款MPP架构(大规模并行处理)的列式数据库,主要用于大数据分析(OLAP)领域,具有快速查询,线性可扩展,功能 丰富,硬件利用效率高,容错,高度可靠等优点。ClickHouse的主要应用场景:电信行业用于存储数据和统计数据使用用户行为数据记录与分析信息安全日志分析商业智能与广告网络价值数据挖掘分析网络游戏以及物联网的数据处理与分析。clickhouse 与其它的数据查询对比https://clickhouse.tech/benchmark/dbms/

容错与高可靠1. 分布式集群2 支持多主机异步复制,并且可以跨多个数据中心进行部署3. clickhouse 所有节点都相等,这个可以避免出现单点故障4. clickhouse 单个节点或者整个数据中心的停机时间不会影响系统的 读写可用性。5. clickhouse 包括许多企业级别安全功能和针对人为错误的故障安全机制。不支持事务。只有alter, 没有 真正的update 与 delete 操作。
1.4 clickhouse 的核心特性与架构
clickhouse 的定位是分析型的数据库,而不是严格的关系心数据库,但具有完善的DBMS功能,比如: 实例, database,table,row,colume,DDL,DML,用户,权限控制,数据备份,数据恢复,分布式管理等功能,而且支持大规模并行计算,每个节点存在有对应的分区数据
clickhouse 服务实例与数据库1. 服务实例与MySQL 相似,启动clickhouse 程序就有一个服务进程,默认9000 端口的进程,启动的这个程序就是一个实例,一台主机上也可以启动多个实例,不同的端口即可。2. 数据库则是文件的集合,一个服务启动后,clickhouse 默认会有system 与default 的两个数据库,如果业务使用,可以通过create database 来创建业务数据库,用于数据的存放于管理。
clickhouse 数据访问流程1. server:clickhouse 服务器实现了多个不同的接口:1.用于认为外部客户端的HTTP 接口2.用于传输数据进行拷贝接口3.用于本机clickhouse 客户端以及在分布式查询中跨服务器通信的TCP 接口
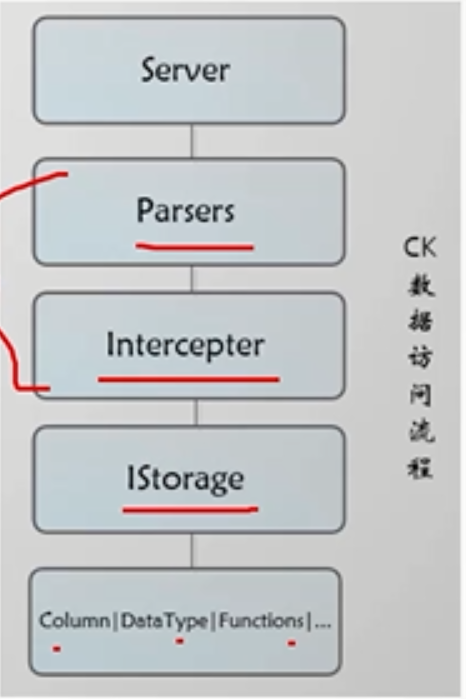
2. Parsers 分析器负责创建AST 对象(抽象语法树)parser 分析器可以将一条SQL 语句 解析成AST 语法树的形式不同的SQL 语句,会由不同的parser 实现类解析。3. Intercepter 解析器负责解释AST 对象(抽象语法树),然后创建查询的执行通道。4. Istorage 存储 接口IStorge 负责根据AST 查询语句的指示要求,返回指定列的原始数据IStorge 接口定了DDL(如alter,rename ,drop 等),read 和write 方法,分别负责数据的定义,查询写入。在这个过程中,通过对block 对象完成一系列数据操作block 对象的本质是由数据对象(cloumn),数据类型(DataType)和列名称组成的三元组,block在这些对象的基础上实现了进一步的抽象封装,从而简化了整个使用的过程,仅通过block就可以完成一些列数据操作。
clickhouse 数据访问流程:1. Column 与field2. column 提供数据的读取能力3. column 和Field 是clickhouse 数据的最基础的映射单元4. clickhouse 按列式存储数据,内存中的一列数据由一个column对象表示,而filed 对象代表Column的一个单值。
Datatype:数据类型是由DataType 负责,DataType 提供序列化和反序列化,数据从Column 或者Field 获取FunctionClickhouse 主要提供两类函数:普通函数和聚合函数普通函数 由 IFunction 接口定义,内部由很多的函数实现。聚合函数是有状态的 ,由IAggregateFunction接口定义。
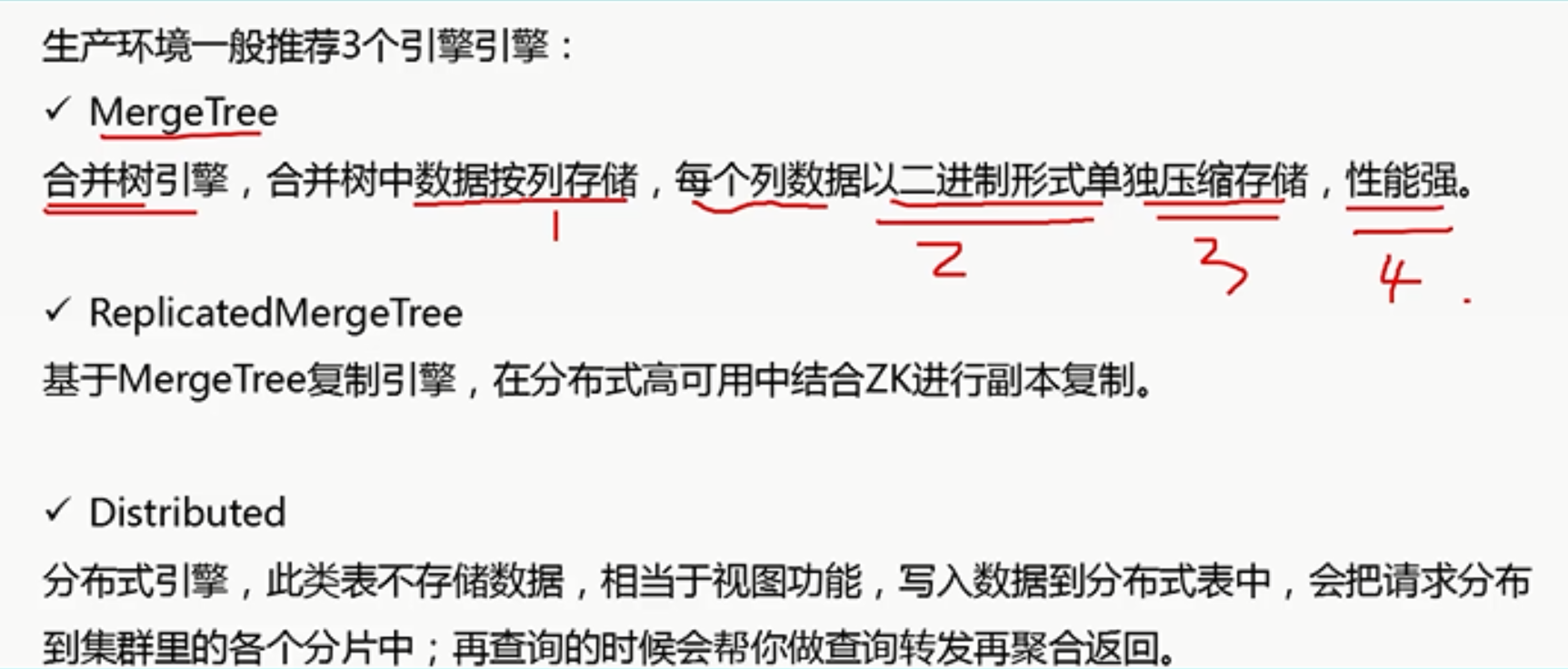
1.5 Clickhouse的存储引擎

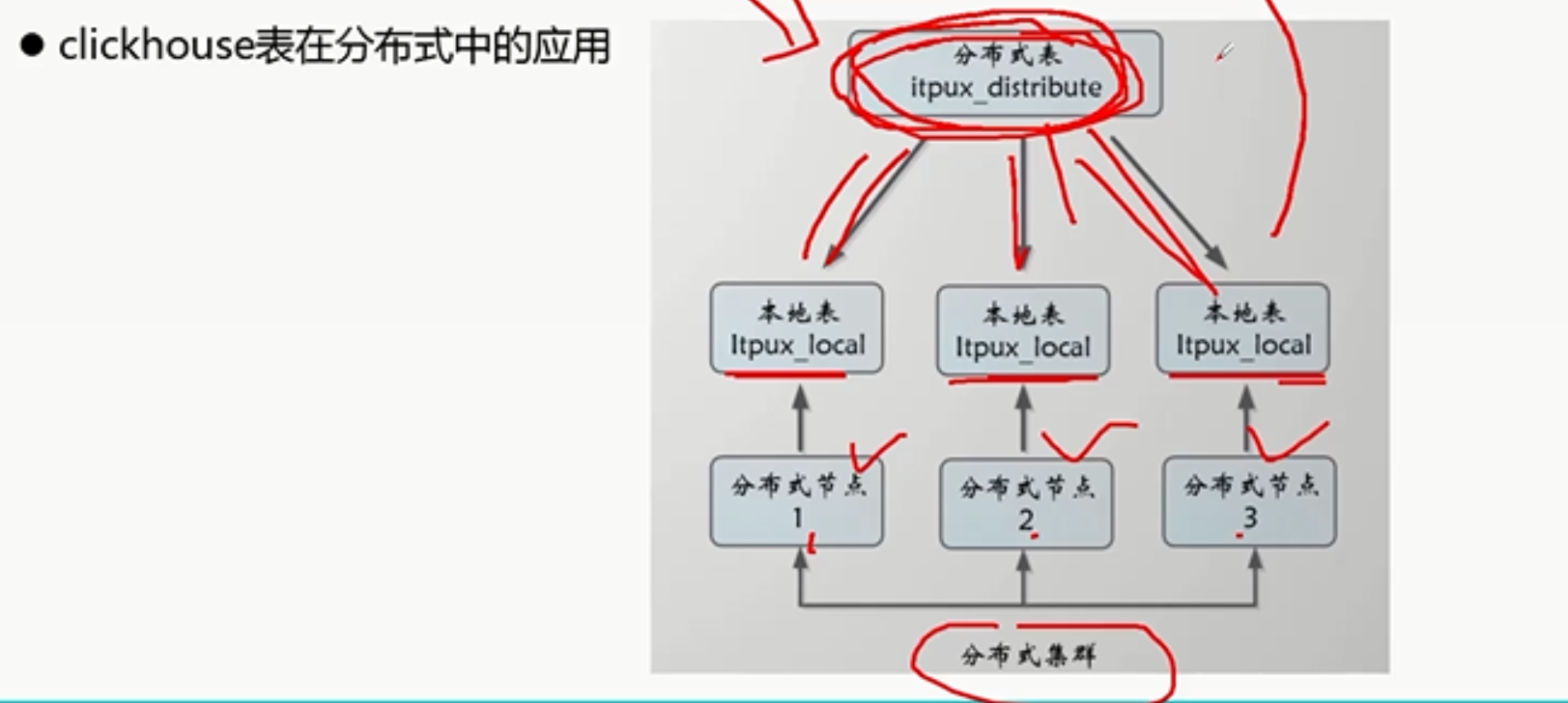
1.6 clickhouse表:

1.7 clickhouse 分区

1.8 clickhouse 的 索引


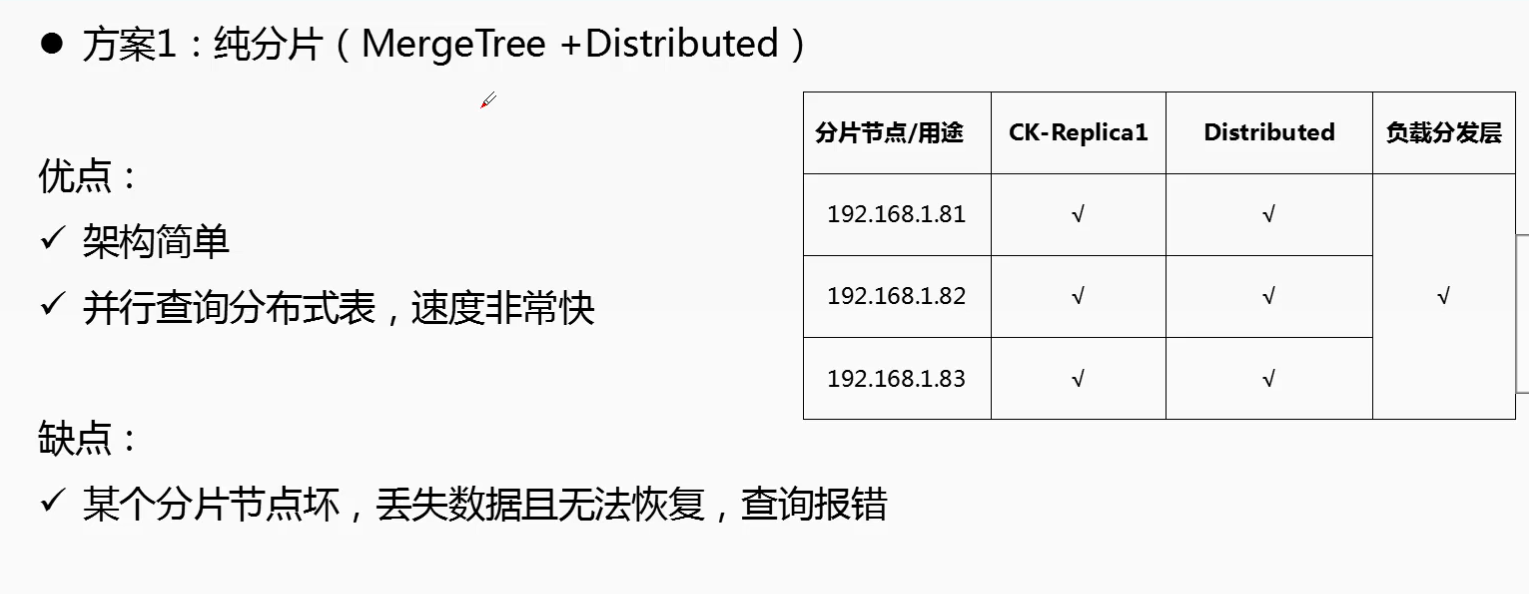
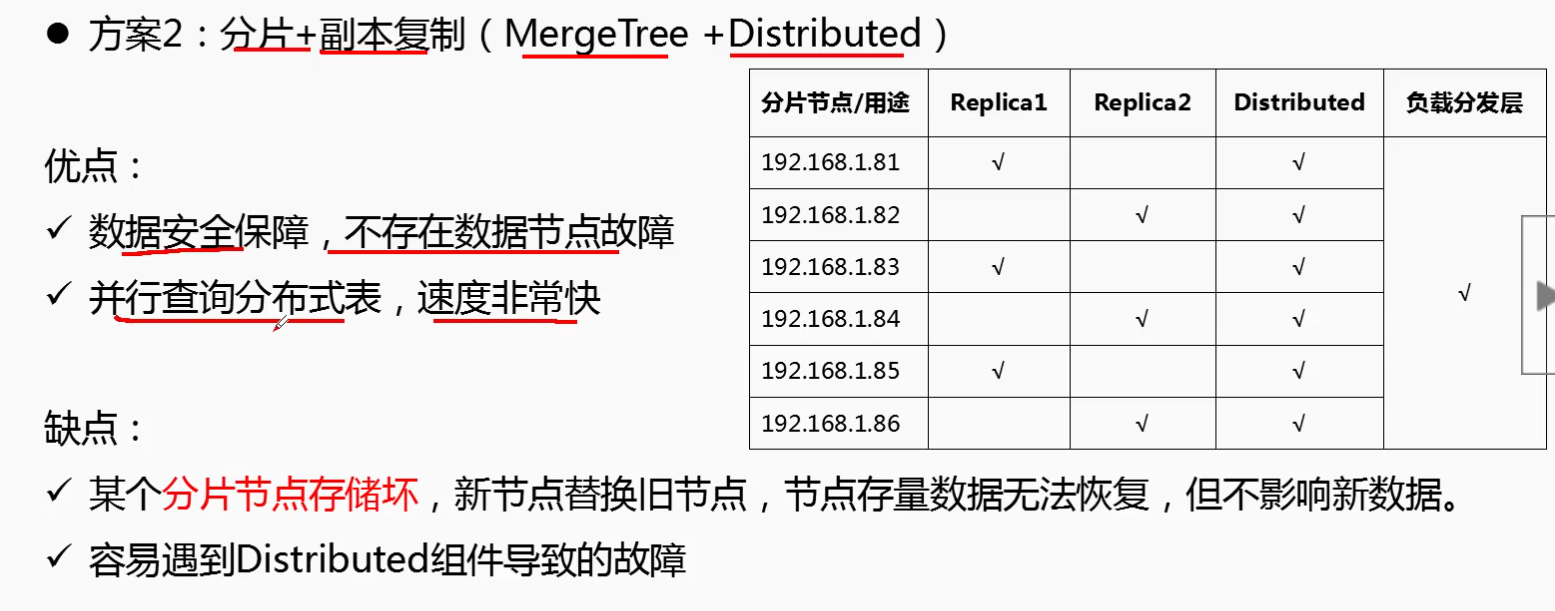
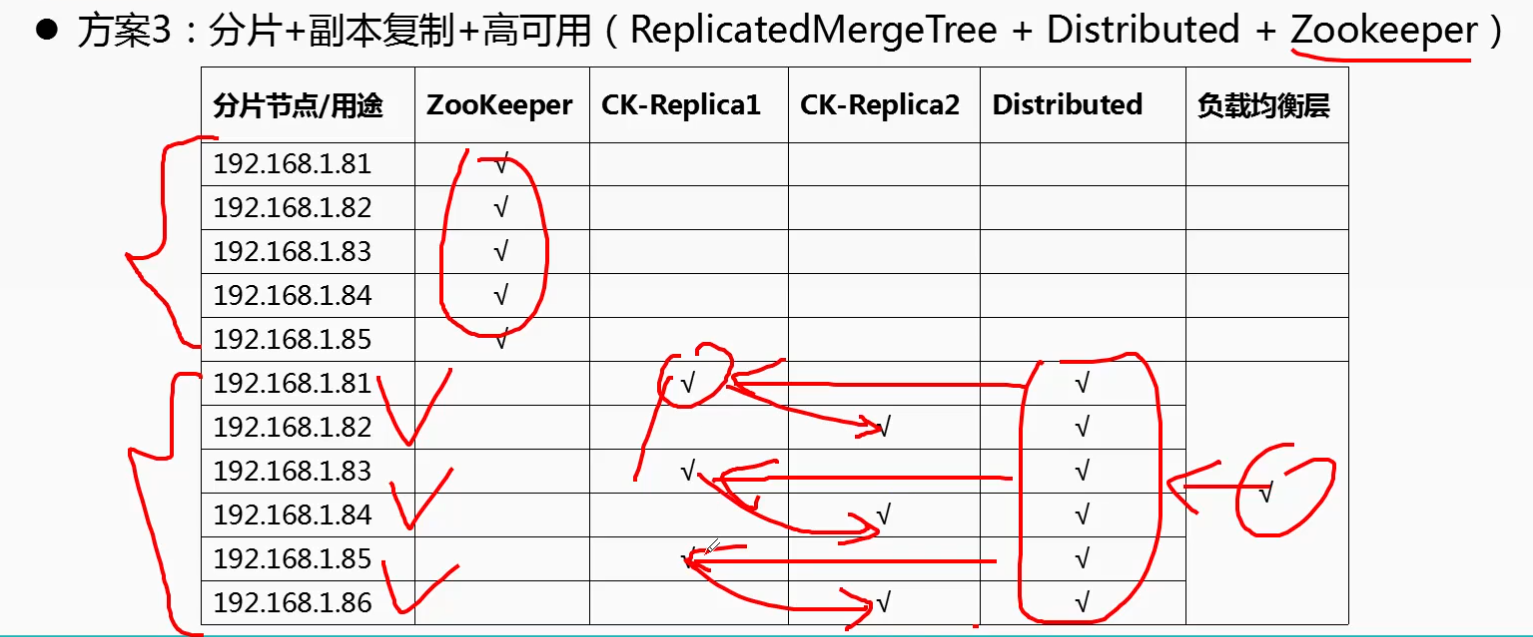
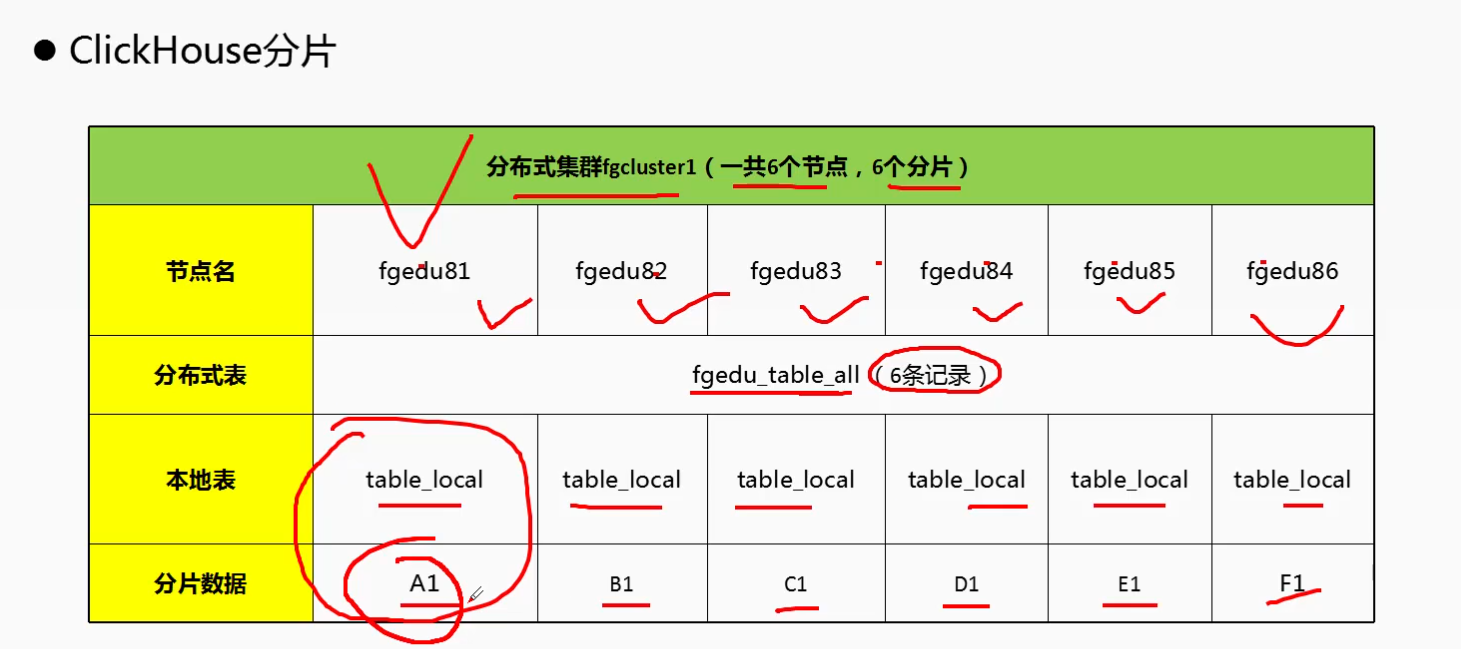
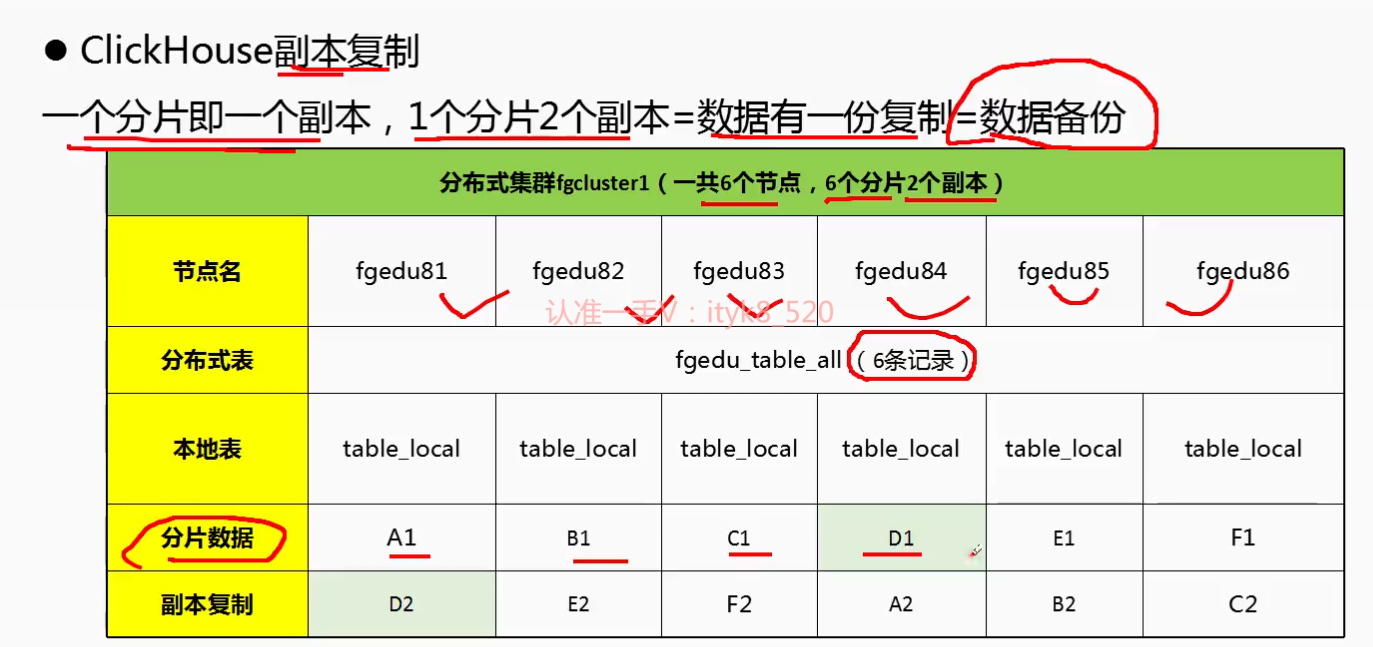
二: ClickHouse 集群分片与副本复制的特性


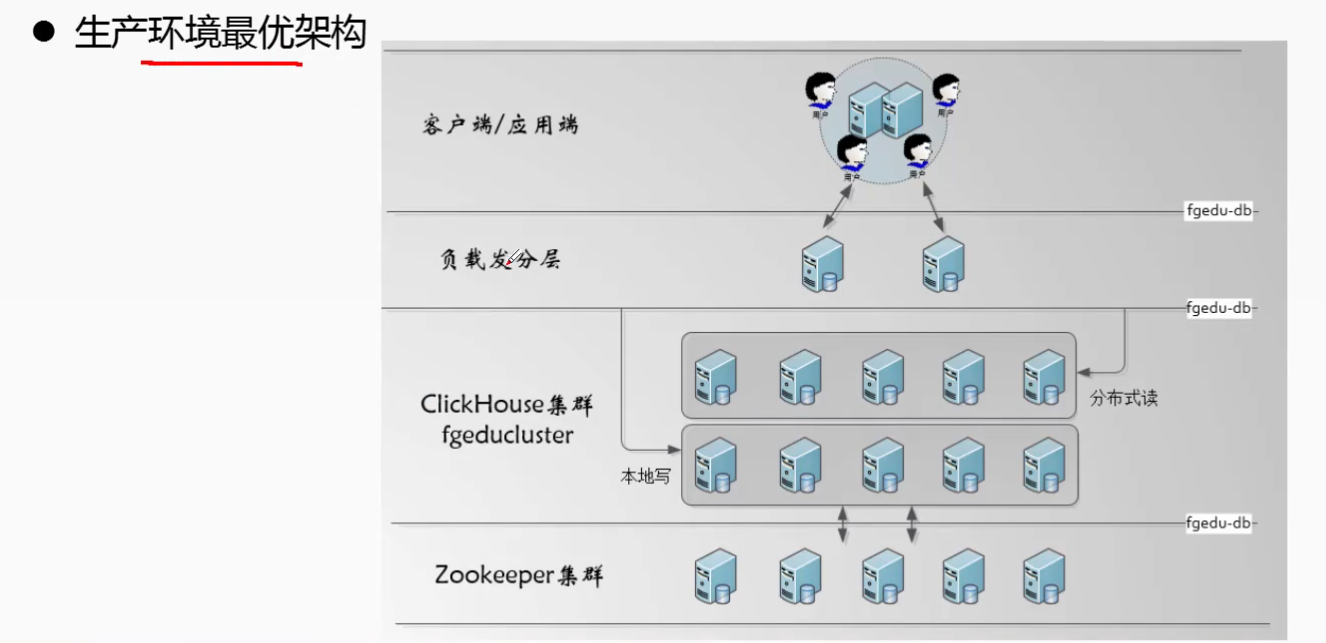
三:Clickhouse 的生产环境