@zhangyy
2020-09-17T11:14:39.000000Z
字数 1179
阅读 583
CDH6.3.2 集成flink的部署配置
大数据运维专栏
- 一:flink的简介
- 二:cdh6.3.2 集成flink
一:flink的简介
Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。此外,Flink的运行时本身也支持迭代算法的执行在 2019 年 10 月于柏林举行的 Flink Forward 活动上,Cloudera 的工程主管 Marton Balassi 和 Field CTO Andrew Psaltis 在大会上宣布,Cloudera 承诺将通过 CSA 产品不断给 Apache Flink 社区做出贡献。相信 Cloudera 对 Apache Flink 的集成将会为社区带来更多创新、为企业及开发者提供更便捷的操作与更友好的使用体验
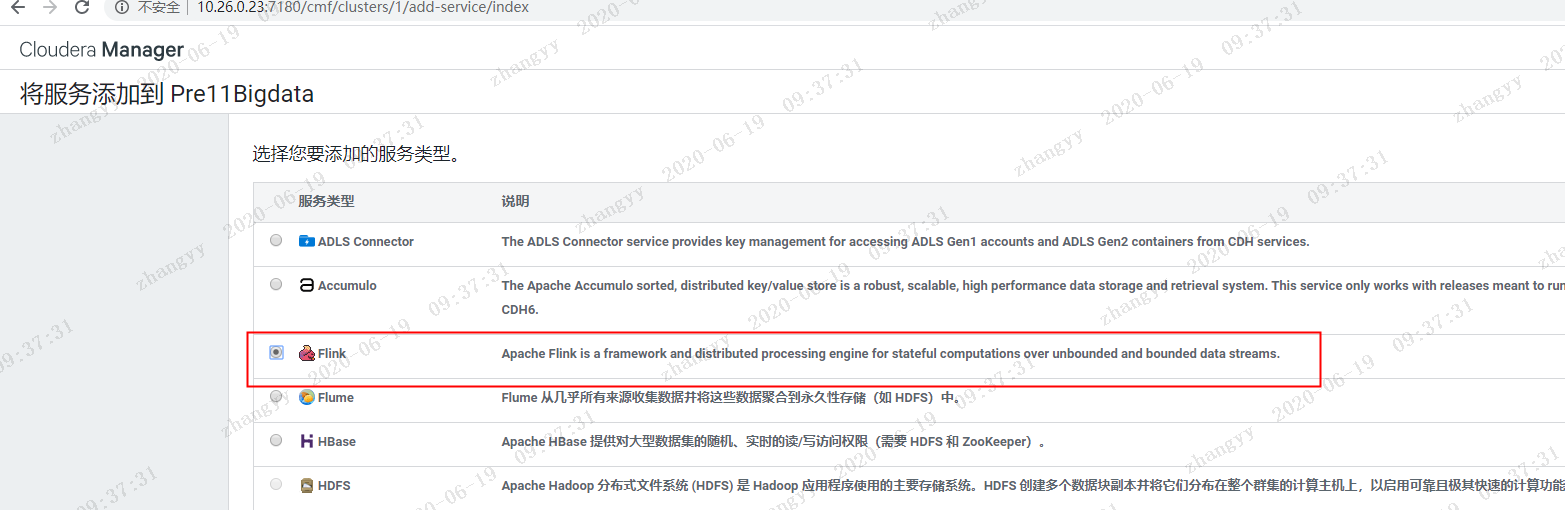
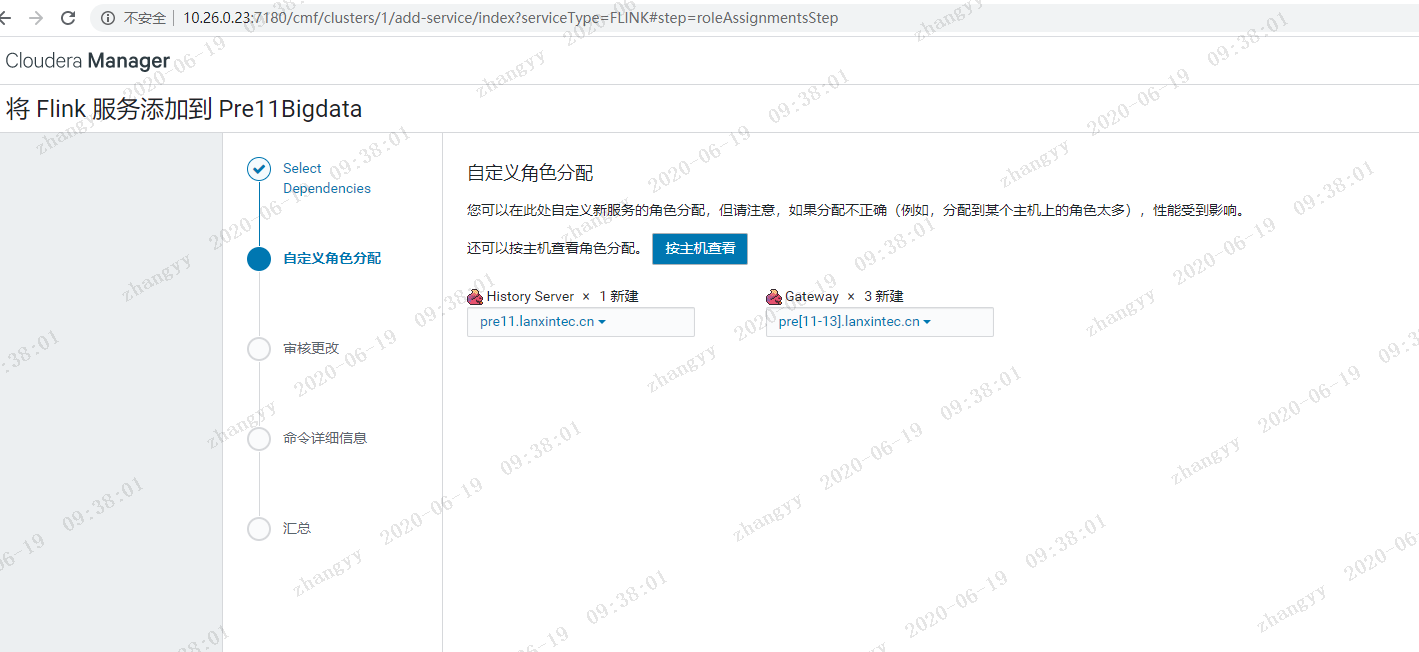
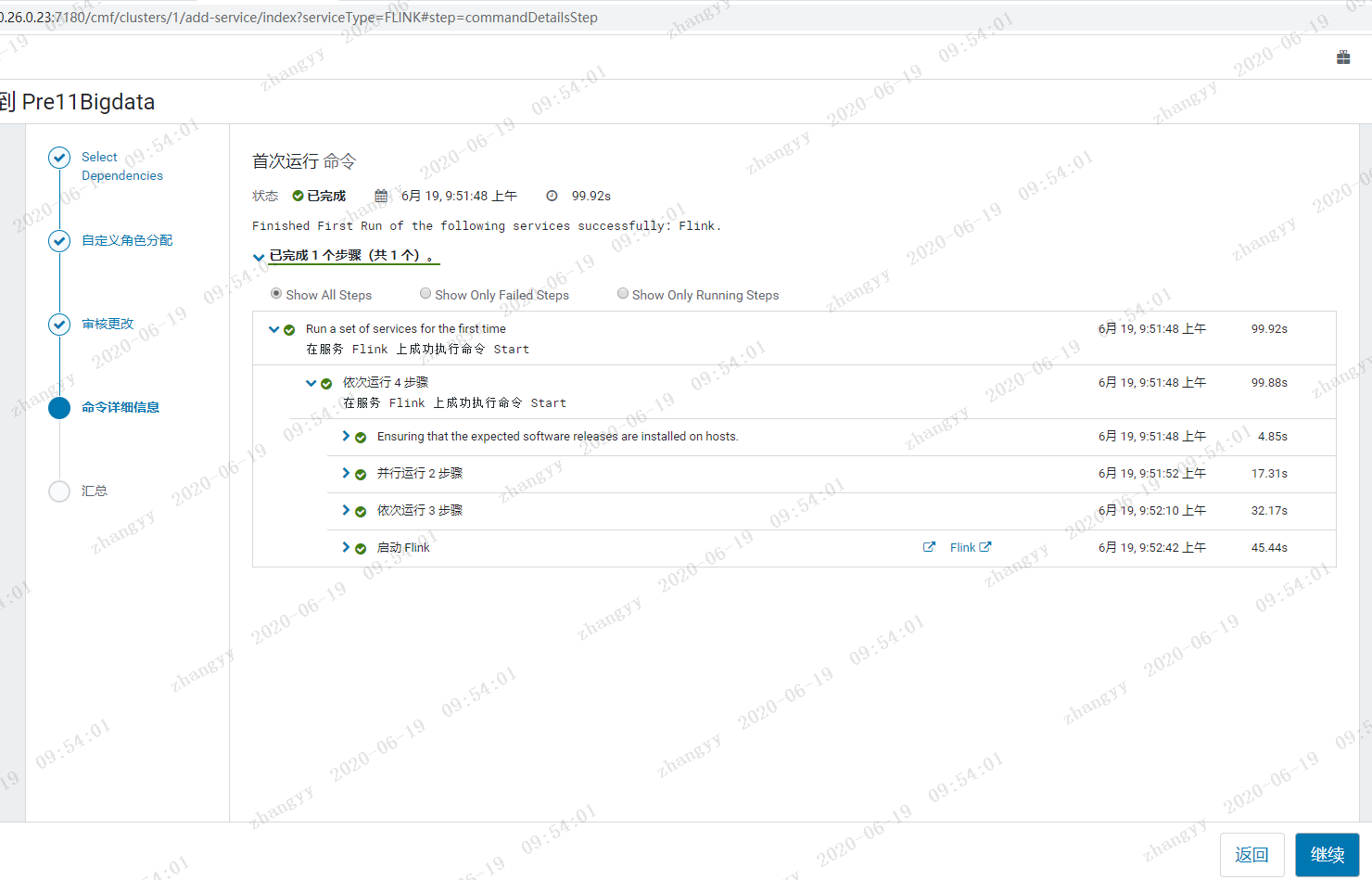
二:CDH6.3.2 集成flink
介绍如何在CDH6.3中安装Flink1.9以及运行你的第一个Flink例子,以下是测试环境信息:1.CM和CDH版本为6.3.22.CentOS7.5x643.JDK1.8.0_1814.集群启用Kerberos5.root用户安装flink 的parcels 包下载地址:https://archive.cloudera.com/csa/1.0.0.0FLINK-1.9.0-csa1.0.0.0-cdh6.3.0-el7.parcelFLINK-1.9.0-csa1.0.0.0-cdh6.3.0-el7.parcel.shaFLINK-1.9.0-csa1.0.0.0-cdh6.3.0.jarmanifest.json

mv FLINK-1.9.0-csa1.0.0.0-cdh6.3.0.jar /opt/cloudera/csd/chown cloudera-scm:cloudera-scm -R csd/ -Rcd ..mv flink /var/wwww/html/service cloudera-scm-server restartservice httpd start
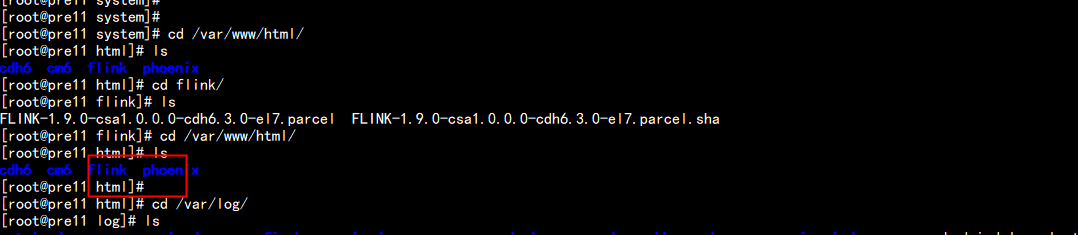
CM 增加 parcels 文件 然后从新启动CM
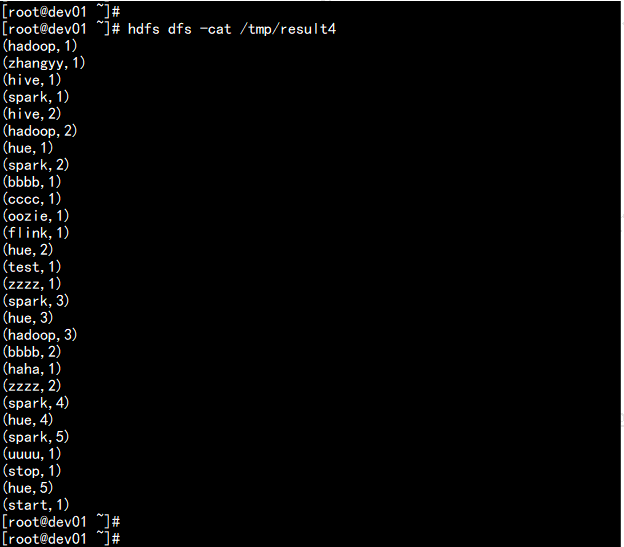
第一个Flink例子1.执行Flink自带的example的wordcount例子。hdfs dfs -put word.txt /tmpflink run -m yarn-cluster -yn 4 -yjm 1024 -ytm 1024 /opt/cloudera/parcels/FLINK/lib/flink/examples/streaming/WordCount.jar --input hdfs://192.168.11.160:8020/tmp/word.txt --output hdfs://192.168.11.160:8020/tmp/result4