@zhangyy
2020-06-02T01:06:16.000000Z
字数 5679
阅读 600
hbase 数据库管理
hbase的部分
- 一:hbase 简介与架构功能
- 二:hbase 安装与配置
- 三:hbase 常见shell 命令操作
一:hbase 简介与架构功能
1.1 为什么要使用hbase 数据库
传统的RDBMS关系型数据库(例如SQL)存储一定量数据时进行数据检索没有问题,可当数据量上升到非常巨大规模的数据(TB或PB)级别时,传统的RDBMS已无法支撑,这时候就需要一种新型的数据库系统更好更快的处理这些数据。我们可以选择HBase。
1.2 hbase 简介:
1.2.1 HBase技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。1.2.2 HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。1.2.3 HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。1.2.4 HBase实际上是一个Hadoop的数据库系统,它的主要作用和传统数据库系统一样存储数据和检索数据。不同的是,HBase可以存储海量数据及海量数据的检索。
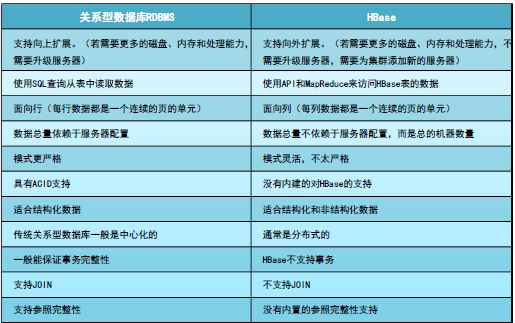
1.3 HBase与Hadoop的对比

1.4 HBase与关系型数据库的功能对比
1.5 HBase架构设计及表的存储设计
1.5.1 HBase是水平扩展的、分布式的、开源有序映射数据库。1.5.2 Hbase运行在Hadoop文件系统HDFS上。它不要求有预定义的模式,可以被看做弹性扩展的多维表格,通过动态添加列,在数据插入或查询之前修改列结构,以支持任意的数据结构。1.5.3 HBase是一个建立在HDFS上的列存储数据库,具有至此线性扩展(横向扩展)、自动故障转移、自动分区及模式自由等特性。
1.6 HBase架构设计
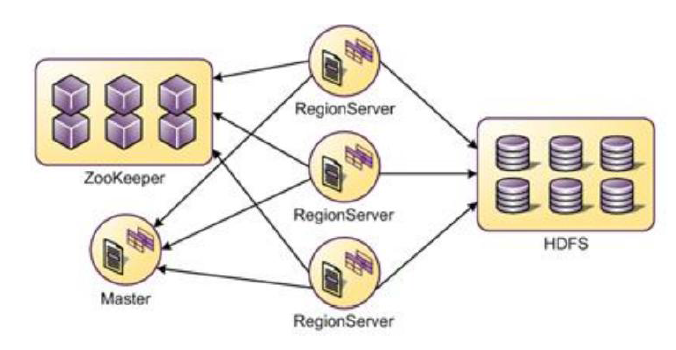
Master:为HBase的主节点,用来协调客户端应用程序和RegionServer的关系,同时用来监控和记录元数据的变化和管理。RegionServer:是从节点,用region的形式处理实际的表。region是HBase表的基础单元组件,它存储了分布式表。所以HBase表和HBase集群利用Master和RegionServer来协同工作。ZooKeeper:是一个高性能、集中化、分布式应用程序协调服务,它为HBase提供了分布式同步和组服务。在HBase中,它用来选举集群主节点Master,以便跟踪可用的在线服务器,同时维护集群的元数据。一般安装多个,用于提供Master的高可用性。通常,Master和Hadoop的NameNode进程运行在同一台主机上,与DataNode通信以读写HDFS的数据。RegionServer跟Hadoop的DataNode运行在同一台主机上。
1.7 HBase数据存储模型
HBase不是以关系设计为中心,它是根据用户需求更灵活的开放设计。它提供了在行键上的单一索引,这在关系世界里称为主键。我们可以通过把行划分为列族和列来避免大的读取和写入操作,并且这种方式支持水平切分和垂直切分。一个HBase表由以下几部分组成:
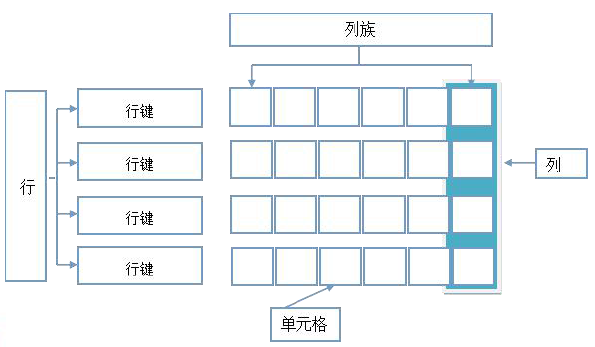
行键:这是HBase表中每个记录的唯一键,无论选择什么类型数据作为行健,它在 内部、磁盘或内存里,都将转换为字节数组进行存储。表中的每条数据有唯一的标识符,即rowkey,类似于关系型数据库的主键。列族:一张HBase表由表的不同列集合在一起。将相同功能或类型的列分类组合在 一起,这样做的好处是可以更快的分开存储在HBase磁盘上的列族中检索出所需的列。列:列属于某一个column family列族。版本:HBase能够为一个单元格元组(行、列族和列)保存多个值,每个单元格被 称为一个记录的版本。版本制定为基于时间戳的长整形。默认情况下,HBase保留3个版本 的记录。当然,我们也可以改变保留版本的数量,我们也可以通过指定来获取某个特定的版 本。时间戳:对于每个插入的数据,当前的时间戳与值是相关的,它表示了数值插入到表中的时间。单元格最小或基本的存储单元,在内部是一个列的实际值存储。故插单元格数 据时必须包含rowkey+ columnfamily(列族名)+columnname(列名)+timestamp:val ue。
1.8 hbase 的特点:
1.8.1 HBase中没有花哨的数据类型,它所有都是字节数组。它是一种字节进字节出的数据库,其特征在于,当插入一个值时,HBase隐式地通过序列号框架将数据转换成字节数组,然后存储进单元格,或者给出字节数组。1.8.2 当添加或者获取数值时,它隐式地转换成等价的数据展示出来。1.8.3 HBase的单元格只能容纳字节数组。任何可以转换成字节的数据都可以存储在HBase中。1.8.4 可以存储10-15MB的值到HBase的单元格中,但如果值太大,可以将文件存储到HDFS中,然后在HBase中存储文件的路径。1.8.5 不建议将一个巨大的文件或值转换成字节数组存储在HBase中;但是HDFS用到的主机文件和文件元数据可以存储到HBase中。
二:hbase 安装与配置
2.1 安装hbase
下载:hbase-0.98.6-cdh5.3.6.tar.gztar -zxvf hbase-0.98.6-cdh5.3.6.tar.gzmv hbase-0.98.6-cdh5.3.6 yangyang/hbase
2.2 更改hbase 的配置文件
cd /home/hadoop/yangyang/hbase/confvim hbase-env.shjdk 目录:export JAVA_HOME=/home/hadoop/yangyang/jdk关闭 hbase 自身的zookeeperexport HBASE_MANAGES_ZK=false
vim hbase-site.xml增加 如下内容<configuration><property><name>hbase.rootdir</name><value>hdfs://namenode01.hadoop.com:8020/hbase</value></property><property><name>hbase.cluster.distributed</name><value>true</value></property><property><name>hbase.zookeeper.property.dataDir</name><value>/home/hadoop/yangyang/hbase/zookeeper</value></property><property><name>hbase.zookeeper.quorum</name><value>namenode01.hadoop.com</value></property><!-- hbase 的权限 设定--><property><name>hbase.superuser</name><value>hadoop</value></property><property><name>hbase.coprocessor.region.classes</name><value>org.apache.hadoop.hbase.security.access.AccessController</value></property><property><name>hbase.coprocessor.master.classes</name><value>org.apache.hadoop.hbase.security.access.AccessController </value></property><property><name>hbase.rpc.engine</name><value>org.apache.hadoop.hbase.ipc.SecureRpcEngine</value></property><property><name>hbase.security.authorization</name><value>true</value></property></configuration>
2.3 更改 regionservers 的配置
单机hbase 配置echo "namenode01.hadoop.com " > regionservers
2.4 启动hbase
bin/start-hbase.sh

2.5 web ui 页面
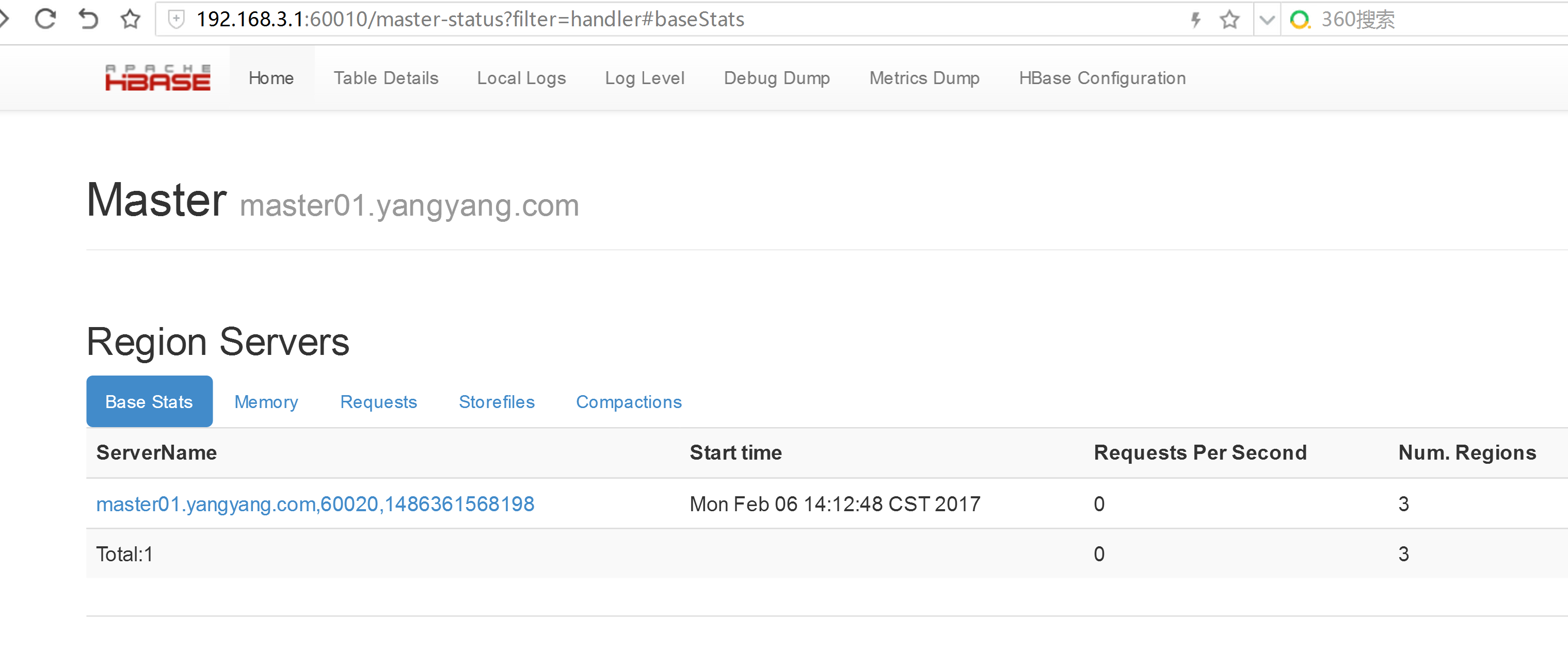
2.6 进入hbase 的 shell
bin/hbase shell

三:hbase 常见shell 命令操作
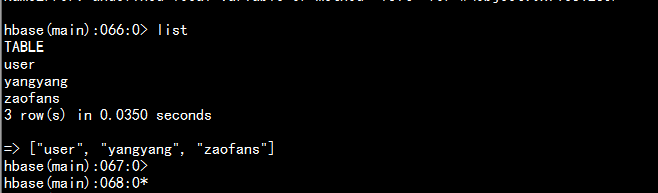
3.1 查看表:
hbase(main)> list
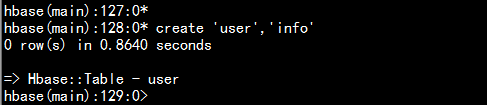
3.2 创建表:
# 语法:create <table>, {NAME => <family>, VERSIONS => <VERSIONS>}# 例如:创建表zaofans, 列簇为infohbase(main)> create 'user','info';
3.3 查看表结构:
# 语法:describe <table># 例如:查看表user的结构hbase(main)> describe 'user'

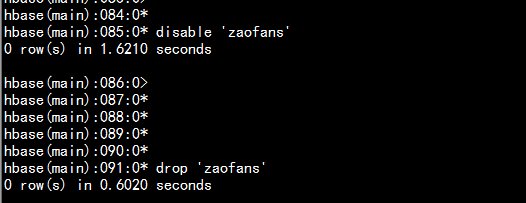
3.4 删除表:
分两步:首先disable,然后drop例如:删除表zaofanshbase(main)> disable 'zaofans'hbase(main)> drop 'zaofans'
3.5 表的权限:
3.5.1 表的附权限
# 语法 : grant <user> <permissions> <table> <column family> <column qualifier> 参数后面用逗号分隔# 权限用五个字母表示: "RWXCA".# READ('R'), WRITE('W'), EXEC('X'), CREATE('C'), ADMIN('A')# 例如,给用户‘test'分配对表user有读写的权限,grant 'test','RW','user'

3.5.2 表权限的查看:
# 语法:user_permission <table># 例如,查看表user的权限列表hbase(main)> user_permission 'user'

3.5.3 表权限的的收回
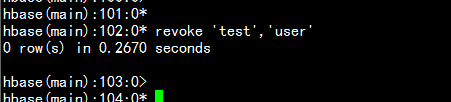
# 与分配权限类似,语法:revoke <user> <table> <column family> <column qualifier># 例如,收回test用户在表t1上的权限hbase(main)> revoke 'test','user'
3.6 表的增删改查
3.6.1 增加数据:
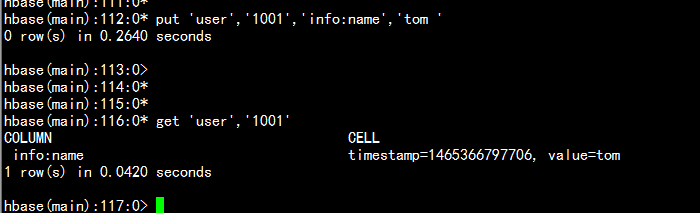
# 语法:put <table>,<rowkey>,<family:column>,<value>,<timestamp># 例如:给表user的添加一行记录:rowkey是1001,family name:info,column name:name,value:tom,timestamp:系统默认hbase(main)> put 'user','1001','info:name','tom'
3.6.2 查询数据:
hbase 查询数据分三种:1. 根据表的rowkey的 进行的查询 这种情况主要的是get 查询2. scan range 范围扫描3. scan 全表扫描---4. 统计行数
1. get 查询:hbase(main)> get 'user','1001'

2. scan range 范围查询:hbase(main)> scan 'user', { STARTROW => '1002' , ENDROW => '1003' }范围查询包头不包尾

3. scan 全表扫描hbase(main)> scan 'user'注: 因现实情况下数据量比较大 一般不用全表扫描

3.6.3 hbase 统计表的rowkey个数
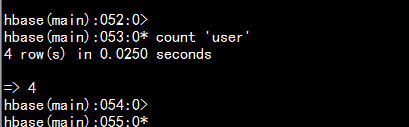
统计数据表的行数hbase(main)> count 'user'
3.6.4 hbase 删除数据记录
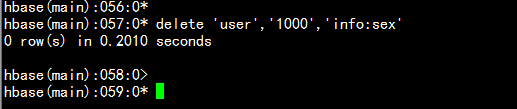
删除行中的某个列值# 语法:delete <table>, <rowkey>, <family:column> , <timestamp>,必须指定列名# 例如:删除表user,1000中的info:sex的数据hbase(main)> delete 'user','1000','info:sex'
# 语法:deleteall <table>, <rowkey>, <family:column> , <timestamp>,可以不指定列名,删除整行数据# 例如:删除表user,1003的数据hbase(main)> deleteall 'user','1003'

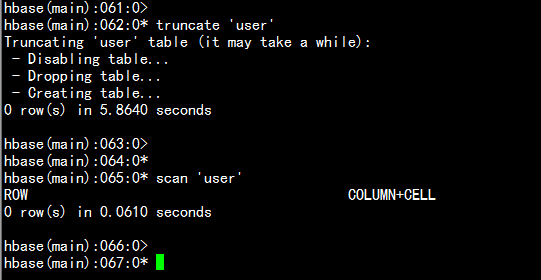
删除表中的所有数据# 语法: truncate <table># 其具体过程是:disable table -> drop table -> create table# 例如:删除表user的所有数据hbase(main)> truncate 'user'
3.7 创建命名空间:
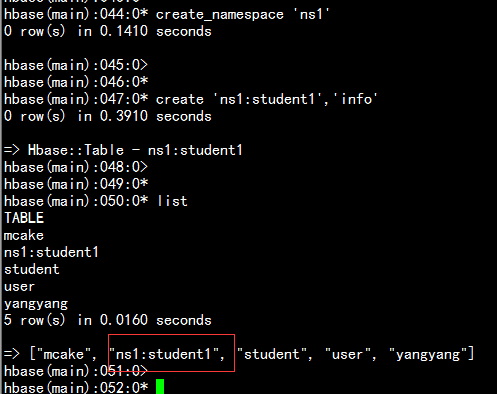
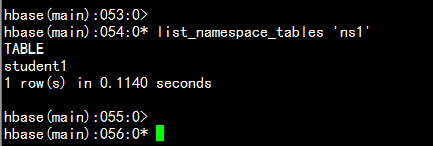
create namespace ns1:在命名空间上建立表:create 'ns1:student1','info'查找命名空间上的表list_namespace_tables 'ns1'
3.8 创建rowkey 的范围region 区域:
方式一:create 't1', 'f1', SPLITS => ['10', '20', '30', '40']ti(rowkey) Start Key End Keyregion1 10region2 10 20region3 20 30region4 30 40region5 40----方式二:cd /home/hadoop/vim region.txt20160601201606022016060320160604create 't2', 'f1', SPLITS_FILE => '/home/hadoop/region.txt', OWNER => 'johndoe'---方式三: 采用十六进制的这种方式创建create 't3', 'f1', {NUMREGIONS => 15, SPLITALGO => 'HexStringSplit'}