@zhangyy
2019-12-11T02:17:14.000000Z
字数 5636
阅读 816
python 的文件操作与函数(三)
Python学习
一: Python的 文件操作
二: Python的 函数
三: Python函数的局部变量
1. Python的 文件操作
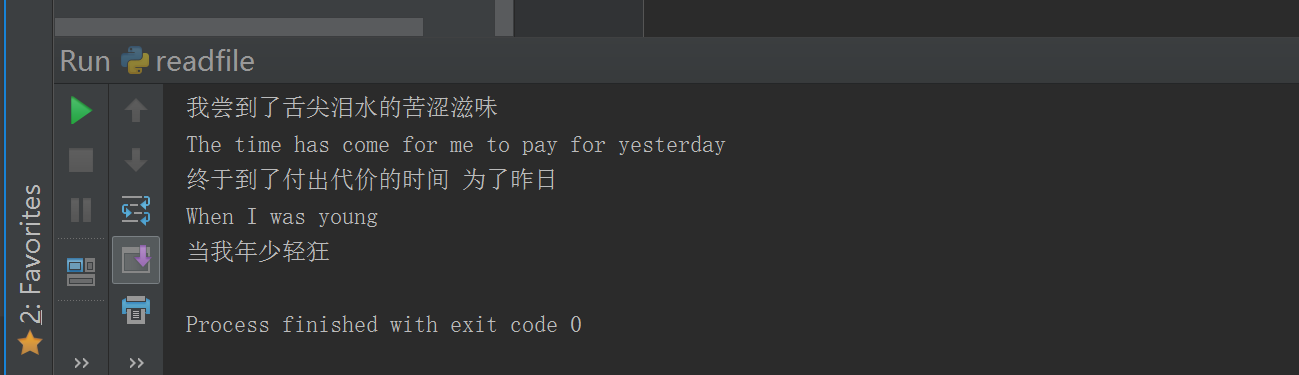
- 1.1 读文件
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyf = open("yesterday","r",encoding="utf-8") # 打开文件data = f.read()print(data)
- 1.2 文件的写
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyf = open("yesterday1","w",encoding="utf-8") # 打开文件f.write("zhangyy")f.write("anebi")
- 1.3 文件的追加
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyf = open("yesterday1","a",encoding="utf-8") # 打开文件f.write("homeupdate,")f.write("yangyang")print(f)
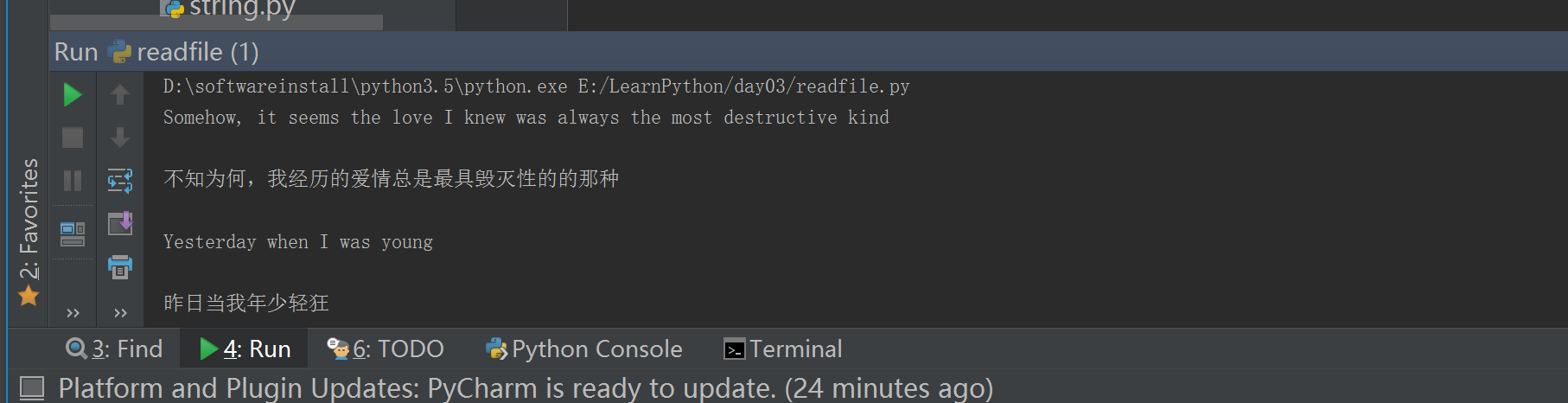
- 1.4 读取文件的前几行
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyy# f = open("yesterday","r",encoding="utf-8").read()f = open("yesterday","r",encoding="utf-8")for i in range(6):print(f.readline())
- 1.5 分割线取值一
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyf = open("yesterday","r",encoding="utf-8")for index,line in enumerate(f.readlines()):if index == 9:print('----分割线-----')continueprint(line.strip())
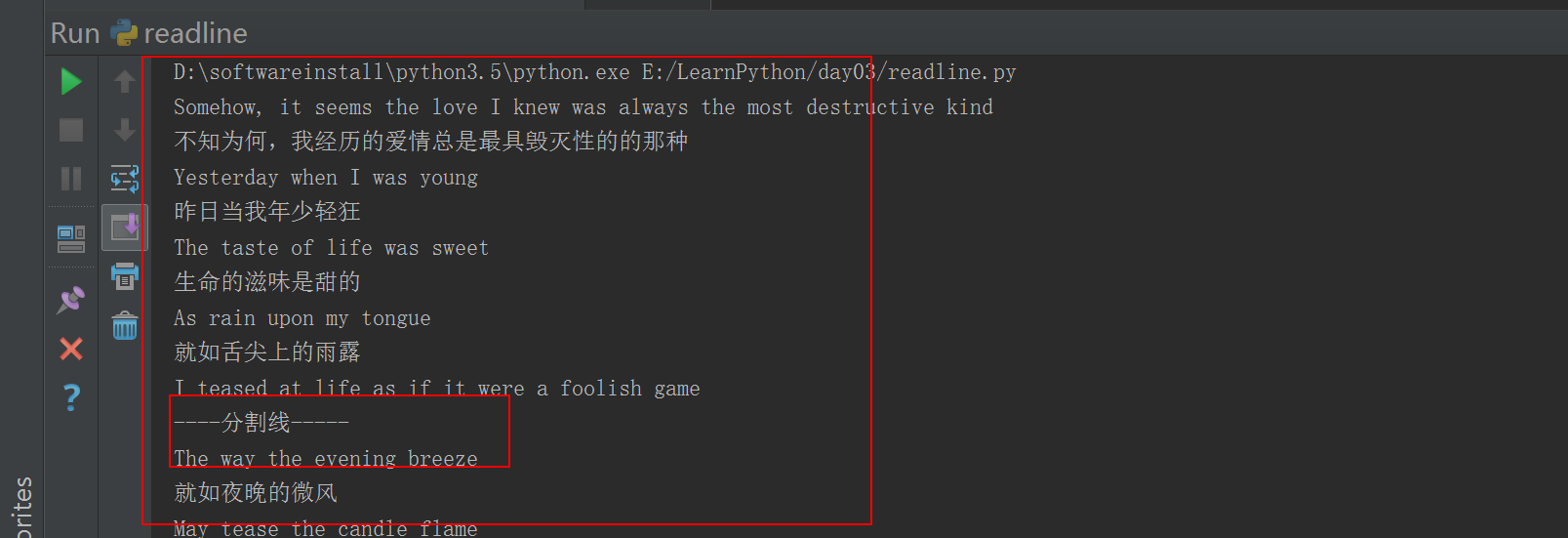
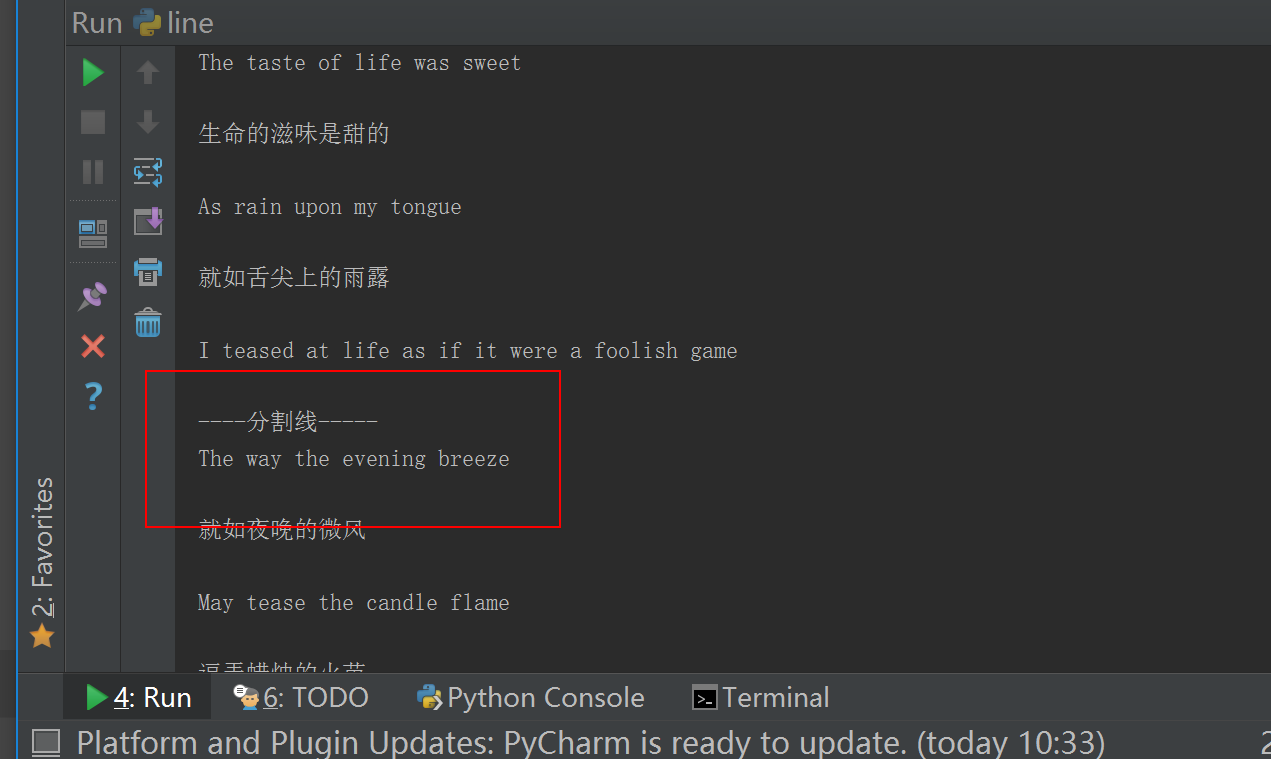
- 1.6 分割线取值二
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyf = open("yesterday","r",encoding="utf-8")count = 0for line in f:if count == 9:print("----分割线-----")count +=1continueprint(line)count +=1
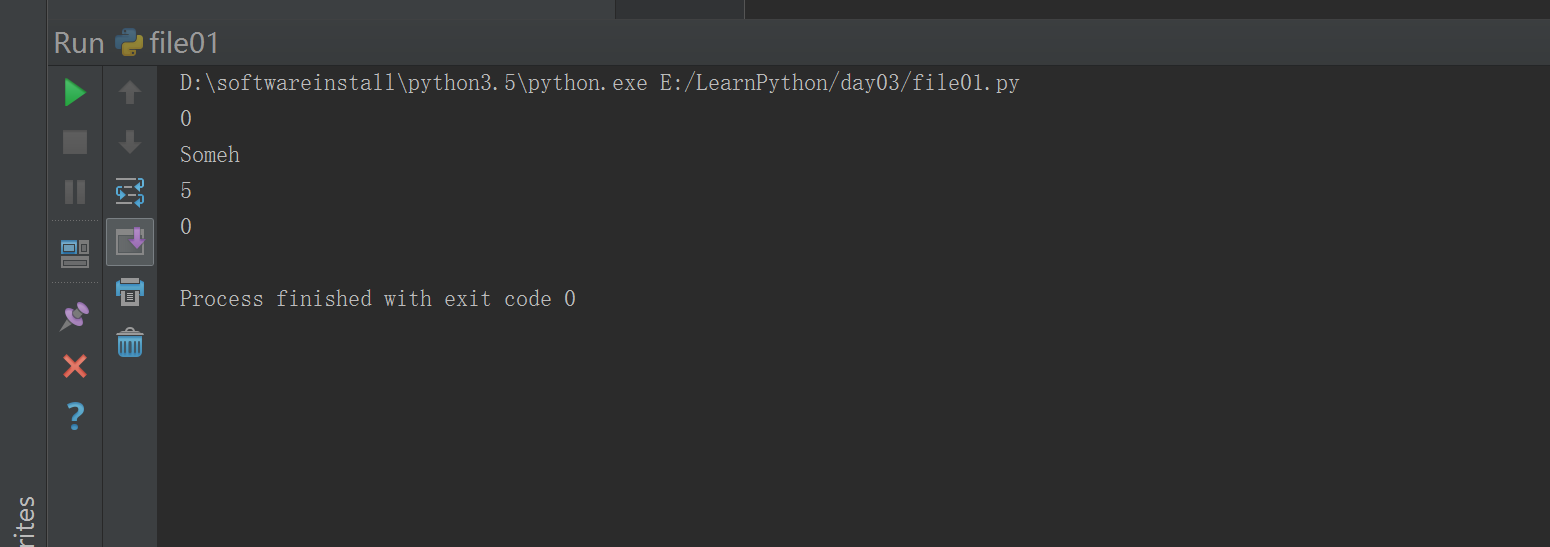
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyf = open('yesterday','r',encoding='utf-8')print(f.tell()) ### 定位标示符print(f.read(5))print(f.tell())print(f.seek(0)) ### 光标返回
- 1.7 进度条的书写
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyimport sysimport time'''f = open("yesterday2","w",encoding="utf-8") # 打开文件f.write("hello1,\n")f.write("hello2,\n")'''for i in range(20):sys.stdout.write("#")sys.stdout.flush()time.sleep(0.1)
- 1.8 截断文件
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyf = open("yesterday3","a",encoding="utf-8")f.seek(10)f.truncate(20)
- 1.9 读写文件
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyf = open("yesterday2","r+",encoding="utf-8") # 读写文件g = open("yesterday4",'w+',encoding="utf-8") # 写读文件t = open("yesterday4",'a+',encoding="utf-8") # 追加读写y = open("yesterday4",'rb') ## 以二进制的读写r = open("yesterday4",'wb') ### 以二进制的方式写读z = open("yesterday4",'wb') ### 以二进制的方式追加读写r.write("hello binary\n".encode())r.close()'''g.write("spark,\n")g.write("spark,\n")print(g.readline())print(g.readline())g.seek(5)g.write("------hadoop-------")print(g.readline())g.seek(5)'''
- 1.9 with 读写打开 文件
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyywith open("yesterday","r",encoding="utf-8") as f:for line in f:print(line)# print(f.readline())
二: Python的函数
- 2.1 Python的函数
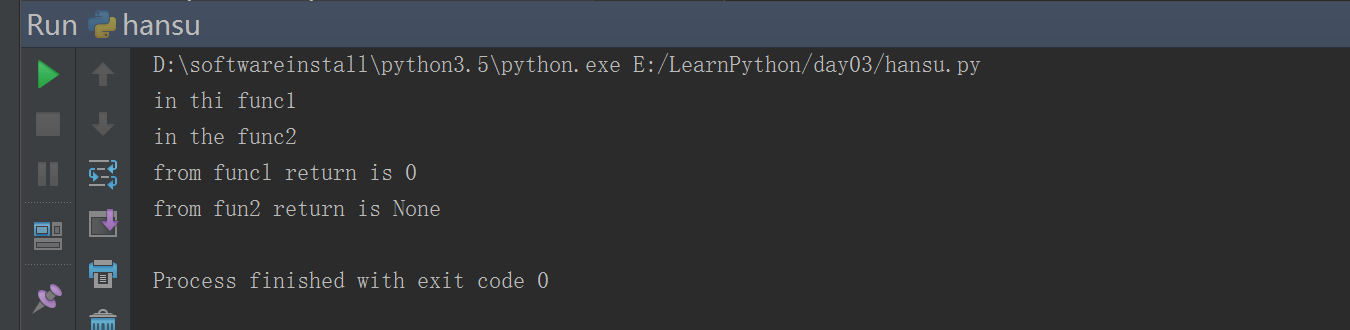
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyy### 函数def func1():print('in thi func1')return 0# 过程 ---- 过程就是没用返回值的函数def func2():print("in the func2")x = func1()y = func2()print("from funcl return is %s" %x)print('from fun2 return is %s' %y)
- 1.2 Python的返回值
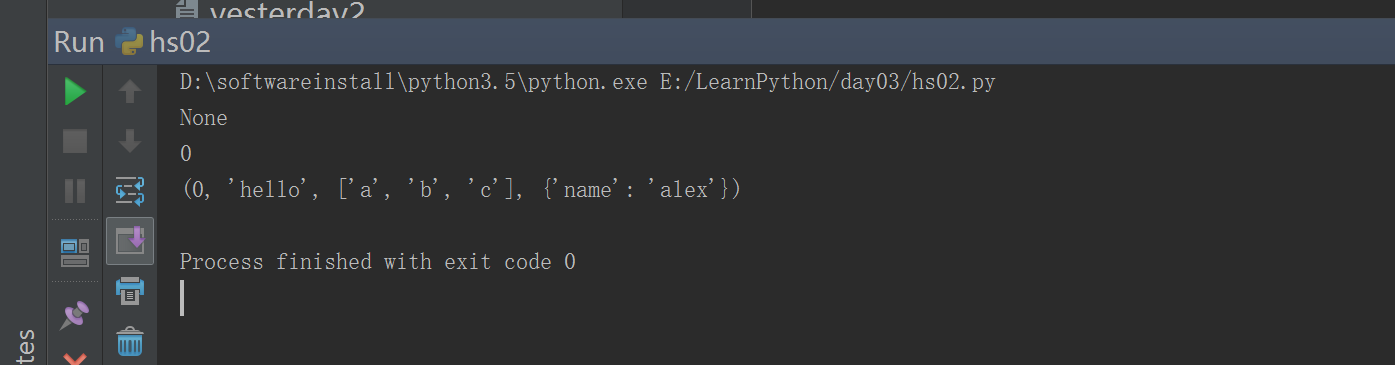
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyydef test1():passdef test2():return 0def test3():return 0,'hello',['a','b','c'],{'name':'alex'}x=test1()y=test2()z=test3()print(x)print(y)print(z)### python 的返回值最后 把所有的返回值 放到一个元组里面#### 函数的返回值:#### 默认没有返回值就是 none#### 返回值 = 1 默认的返回值 就是 一个object (对象)#### 返回值 > 1 默认返回值就是就是一个元组 (tuple)
- 1.3 python 的形式调用
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyydef test(x,y,z):print(x)print(y)print(z)# test(y=2,x=1) #与形参顺序无关# test(1,2) #与形参一一对应#test(x=2,3)test(3,z=2,y=6)
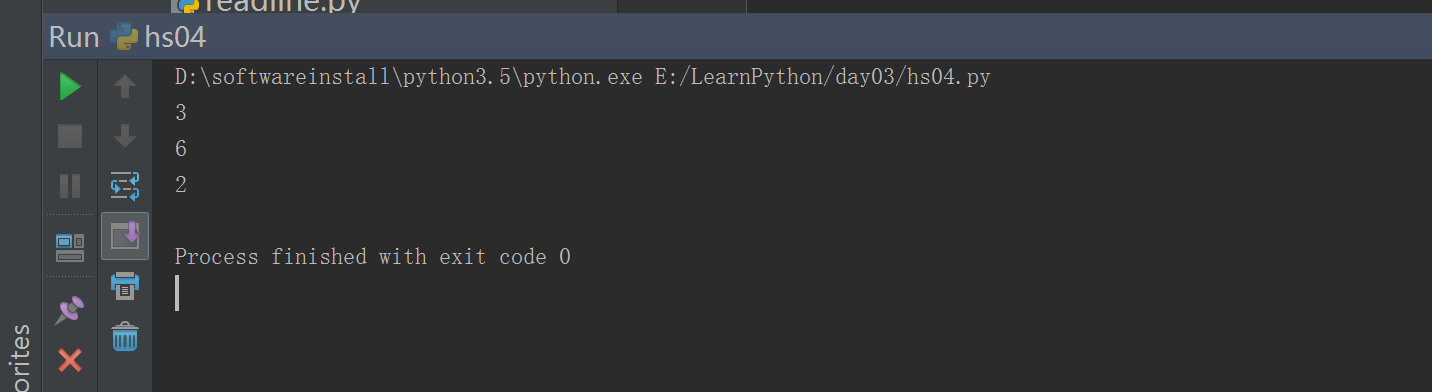
- 1.4 python的默认参数用途
def conn(host,port=3306):pass### #默认参数特点:调用函数的时候,默认参数非必须传递
- 1.4 取元组列表
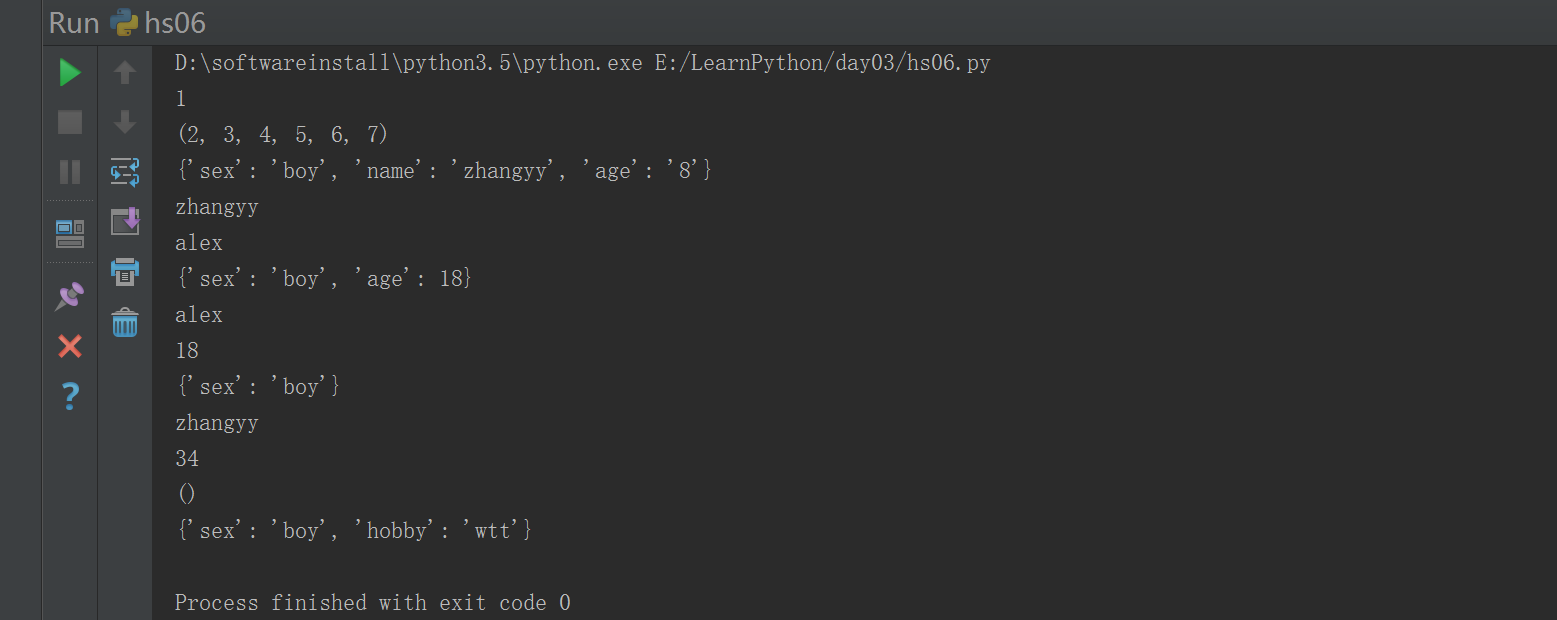
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyydef test1(x,*args):print(x)print(args)test1(1,2,3,4,5,6,7)#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyy#*args: 接收N 个 位置参数,转换成元组的方式#*kwargs:接收N 关键字参数,转换成字典的方式def test1(x,*args):print(x)print(args)test1(1,2,3,4,5,6,7)def test2(**kwargs):print(kwargs)print(kwargs['name']) ### 取值test2(name="zhangyy",age="8",sex = "boy")#test2(**{'name':'alex','age':8})def test3(name,**kwargs):print(name)print(kwargs)test3("alex",age =18,sex="boy")def test4(name,age =18,**kwargs):print(name)print(age)print(kwargs)test4("alex",sex="boy")def test5(name,age=18,*args,**kwargs):print(name)print(age)print(args)print(kwargs)test5('zhangyy',age=34,sex='boy',hobby='wtt')
三:Python函数的局部变量
- 3.1 局部变量
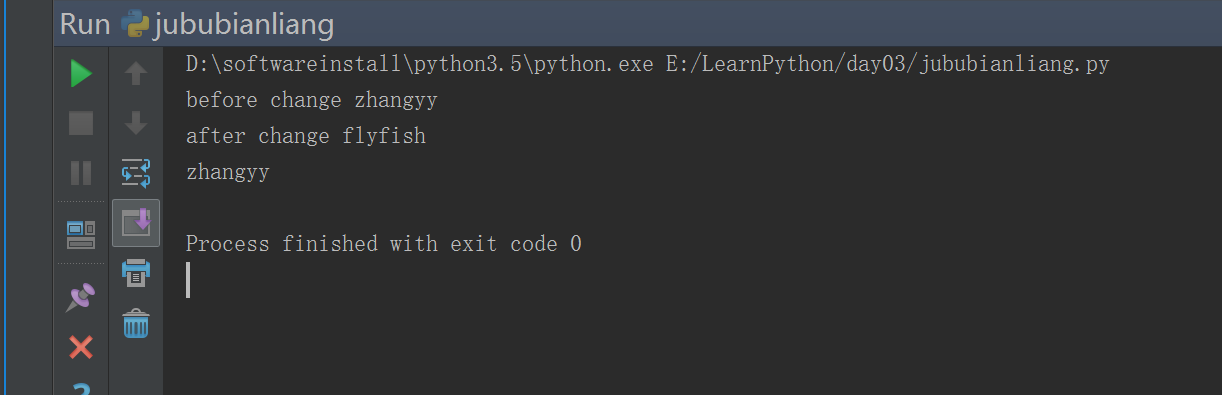
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyydef change_name(name):print("before change",name)name = "flyfish" #### 局部变量问题 ,只在函数内生效。print("after change",name)name = "zhangyy"change_name(name)print(name)
- 3.2 局部变量提权
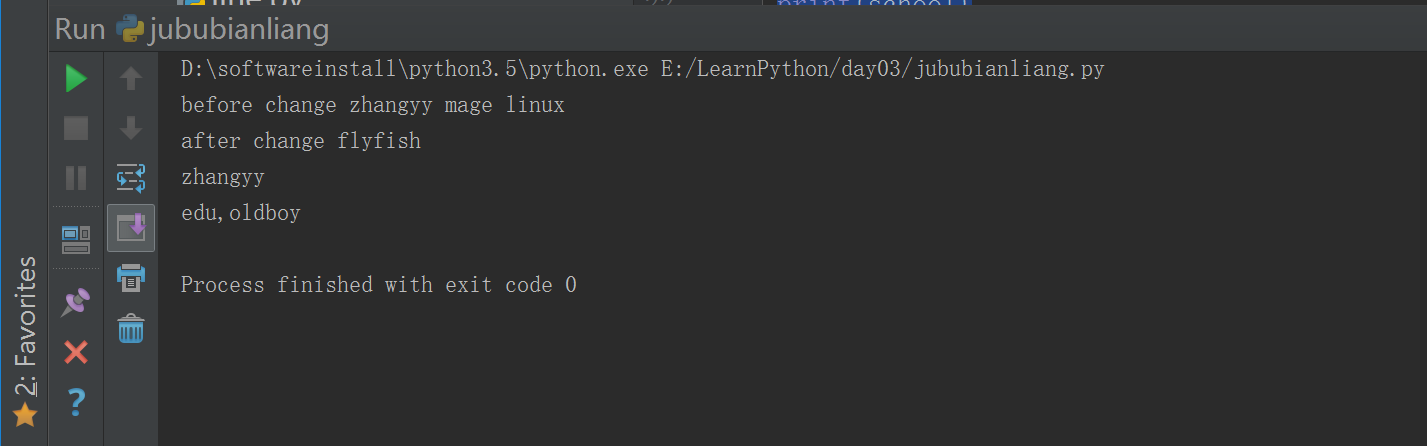
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyyschool = "edu,oldboy"def change_name(name):global school #### 更改 局部变量的 提权问题school = "mage linux"print("before change",name,school)name = "flyfish"age = 23print("after change",name)name = "zhangyy"change_name(name)print(name)print(school)#### 不应该在函数里面改全局变量,特殊情况下才使用,一般不用
- 3.3 列表调用
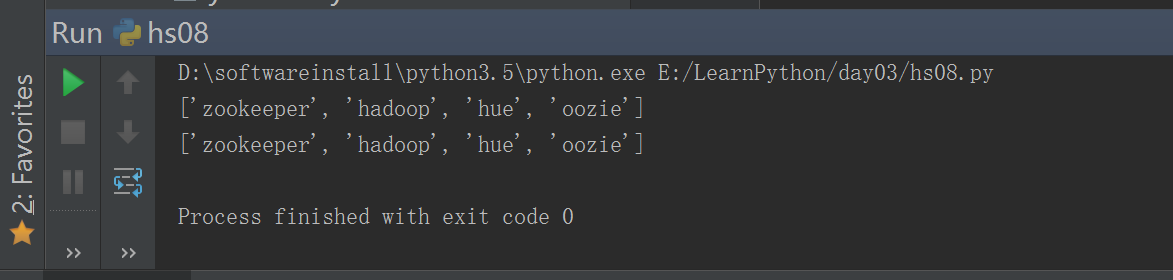
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyybigdata = ["spark","hadoop","hue","oozie"]def change_name():bigdata[0] = "zookeeper"print(bigdata)change_name()print(bigdata)#### 列表,集合, 字典 ,包括 类都可以修改
- 3.4 函数的递归
递归的特性1. 必须有一个明确的结束条件2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
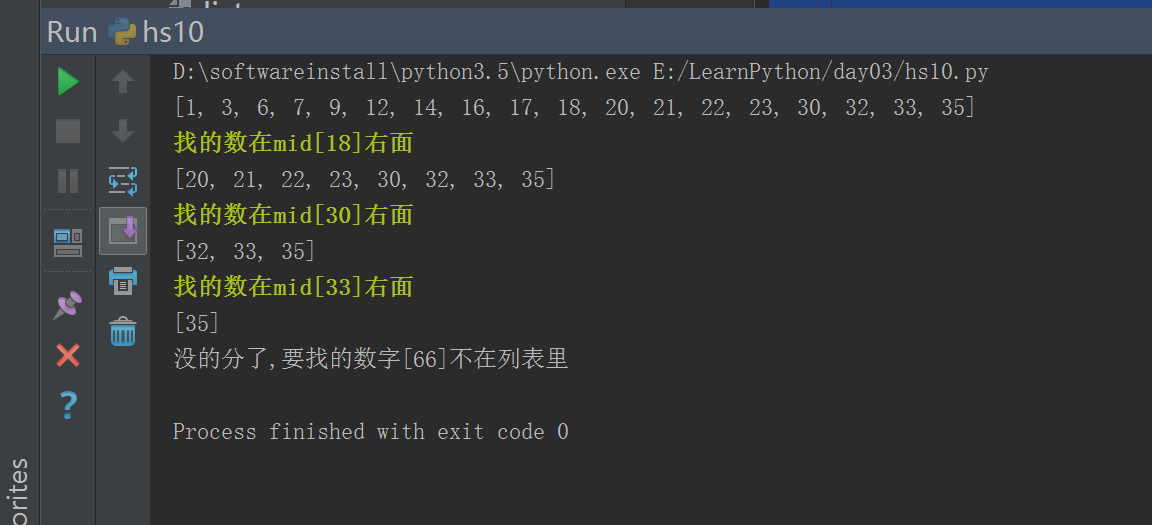
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyydata = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]def binary_search(dataset, find_num):print(dataset)if len(dataset) > 1:mid = int(len(dataset) / 2)if dataset[mid] == find_num: # find itprint("找到数字", dataset[mid])elif dataset[mid] > find_num: # 找的数在mid左面print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid])return binary_search(dataset[0:mid], find_num)else: # 找的数在mid右面print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid])return binary_search(dataset[mid + 1:], find_num)else:if dataset[0] == find_num: # find itprint("找到数字啦", dataset[0])else:print("没的分了,要找的数字[%s]不在列表里" % find_num)binary_search(data, 66)
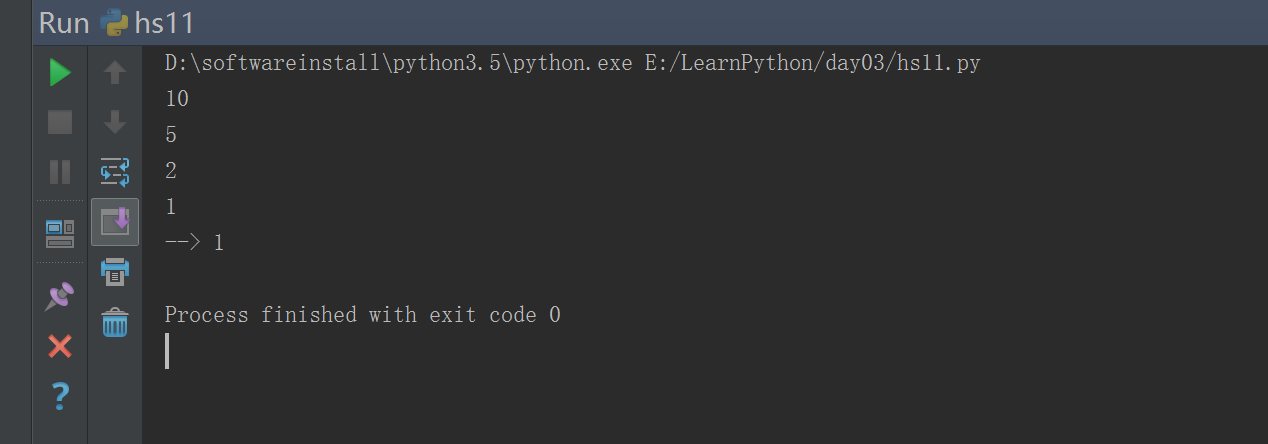
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyydef calc (n):print(n)if int (n/2) >0:return calc(int(n/2))print("-->",n)calc(10)
- 3.5 函数的高阶
变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyydef add(x, y, f):return f(x) + f(y)res = add(3, -6, abs)print(res)