@zhangyy
2021-08-01T02:16:23.000000Z
字数 11705
阅读 544
Python 的模块与数据类型 (二)
Python学习
- 一.模块学习
- 二.python的pyc
- 三.python的数据类型
一:模块学习
- 1.1 python 的 lib 库
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport sysprint(sys.path)

D:\softwareinstall\Python3.5\python.exe E:/LearnPython/day02/sys_mod.py['E:\\LearnPython\\day02', 'E:\\LearnPython', 'D:\\softwareinstall\\Python3.5\\python35.zip', 'D:\\softwareinstall\\Python3.5\\DLLs', 'D:\\softwareinstall\\Python3.5\\lib', 'D:\\softwareinstall\\Python3.5', 'D:\\softwareinstall\\Python3.5\\lib\\site-packages']
python 的标准库 一般放在python 的安装目录下的lib 下面。。。。自己装的第三方的库放在 site-packages 下面
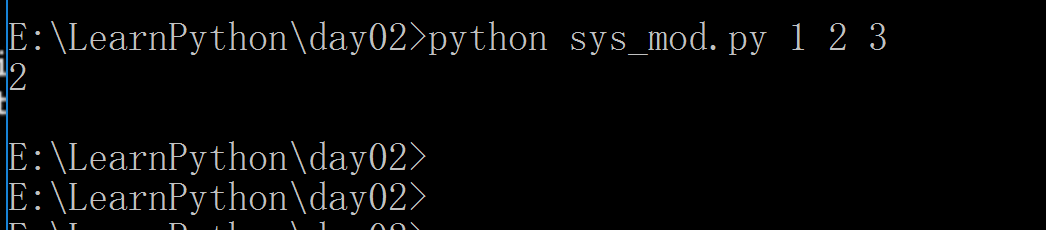
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport sys#print(sys.path)print(sys.argv)

python 取值输入的值:#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport sys#print(sys.path)print(sys.argv[2]) # 取输入的第二值
- 1.2 python 调用命令
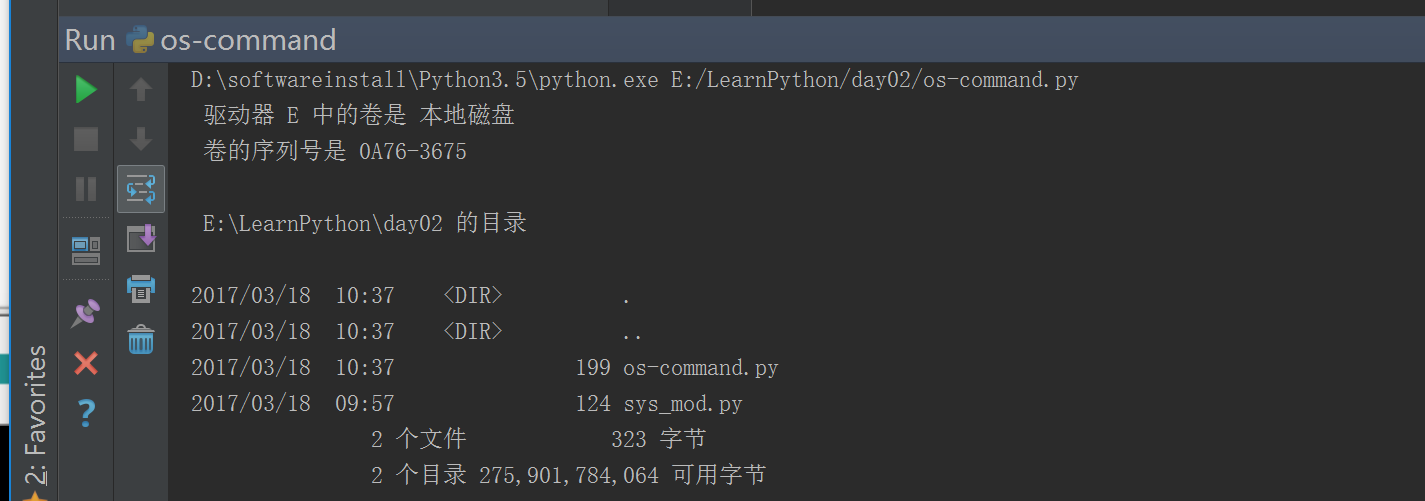
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport os#cmd_res = os.system("dir") ## 执行命令不保存结果cmd_res = os.popen("dir").read()print(cmd_res)
- 1.3 新建文件夹
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport os#cmd_res = os.system("dir") ## 执行命令不保存结果cmd_res = os.popen("dir").read()os.mkdir("yangyang")print(cmd_res)
python 的模板全部调用,自己的写的模块可以将其copy到site-packages 下面 这样在导入包的 时候, 就可以 调用了
二:python 的pyc
1. Python是一门解释型语言?我初学Python时,听到的关于Python的第一句话就是,Python是一门解释性语言,我就这样一直相信下去,直到发现了*.pyc文件的存在。如果是解释型语言,那么生成的*.pyc文件是什么呢?c应该是compiled的缩写才对啊!为了防止其他学习Python的人也被这句话误解,那么我们就在文中来澄清下这个问题,并且把一些基础概念给理清。2. 解释型语言和编译型语言计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,第一种是编译,第二种是解释。编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。3. Python到底是什么其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:javac hello.javajava hello只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。4. 简述Python的运行过程在说这个问题之前,我们先来说两个概念,PyCodeObject和pyc文件。我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
三.python的数据类型
1、数字2 是一个整数的例子。长整数 不过是大一些的整数。3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。int(整型)在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647在64位系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807long(长整型)跟C语言不同,Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。注意,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。float(浮点型)浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。complex(复数)复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。注:Python中存在小数字池:-5 ~ 2572、布尔值真或假1 或 03、字符串"hello world"万恶的字符串拼接:python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。字符串格式化输出1234name = "alex"print "i am %s " % name#输出: i am alexPS: 字符串是 %s;整数 %d;浮点数%f字符串常用功能:移除空白分割长度索引切片4、列表创建列表:123name_list = ['alex', 'seven', 'eric']或name_list = list(['alex', 'seven', 'eric'])基本操作:索引切片追加删除长度切片循环包含5、元组(不可变列表)创建元组:123ages = (11, 22, 33, 44, 55)或ages = tuple((11, 22, 33, 44, 55))6、字典(无序)创建字典:123person = {"name": "mr.wu", 'age': 18}或person = dict({"name": "mr.wu", 'age': 18})常用操作:索引新增删除键、值、键值对循环长度
- 3.2 布尔值:
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFisha = 0if a:print("a")

#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFisha = 1if a:print("a")

- 3.3 :三元运算:
result = 值1 if 条件 else 值2
- 3.4: byte-string 转换
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishname = "飞鱼"print(name.encode())
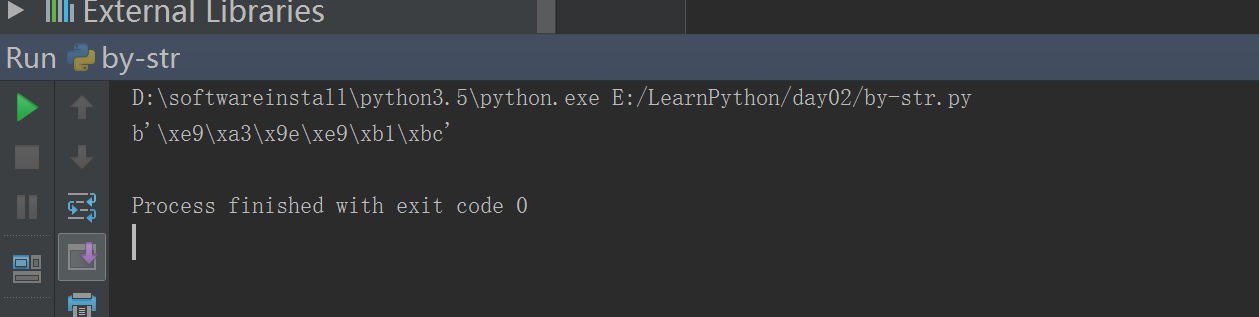
- 3.5 string --byte 转换
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishname = "飞鱼"print(name.encode(encoding= "utf-8").decode(encoding= "utf-8"))

- 3.6 列表的使用:
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishlist1 = ['physics', 'chemistry', 1997, 2000];#list2 = [1, 2, 3, 4, 5 ];#list3 = ["a", "b", "c", "d"];print(list1[0])print(list1[0],list1[3])print(list1[1:3]) ##切片# 包头不包尾
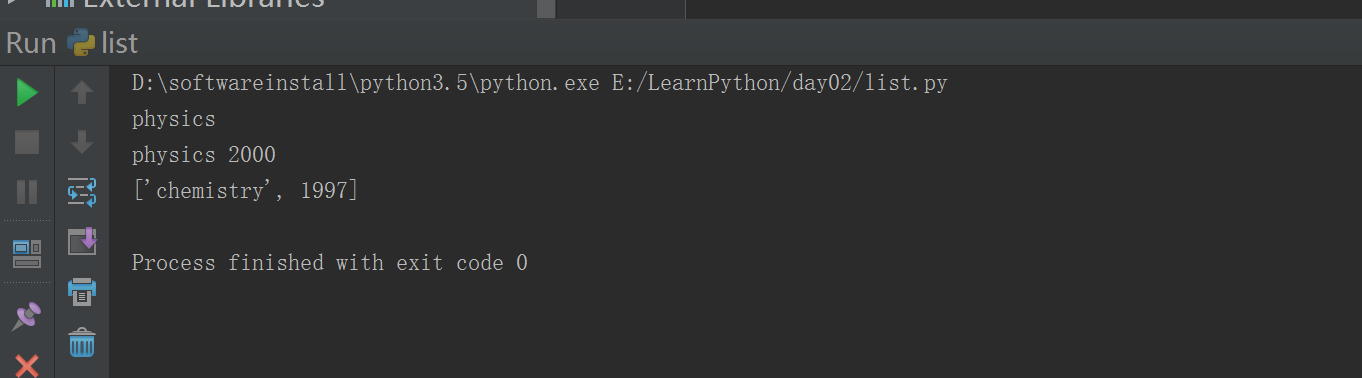
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishlist1 = ['physics', 'chemistry', 1997, 2000];print(list1[-1])print(list1[-3:-1])print(list1[-3:])
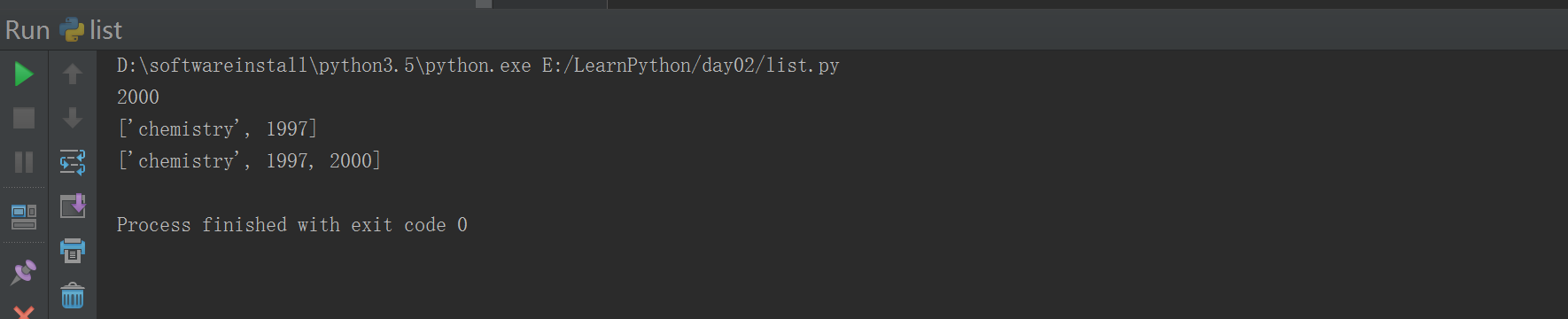
删除一个元素
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishlist1 = ['physics', 'chemistry', 1997, 2000,4000];#list1.append(3000)#list1.insert(1,"hadoop") ###插入 一个 列表元素list1[0] = "spark" ###改动列表元素list1.remove(2000) ###删除一个元素del list1[2] ####删除一个元素list1.pop() ####默认不输入下标就是删除最后一个元素print(list1)#print(list1[-3:-1])#print(list1[-3:])

找出元素的下标并打印
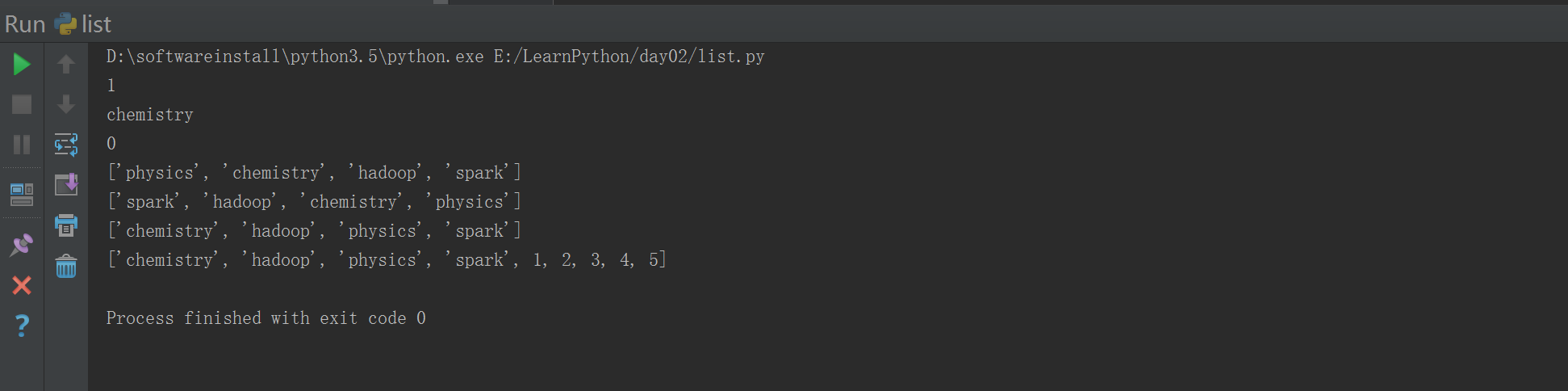
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishlist1 = ['physics', 'chemistry', 1997, 2000,4000];#list1.append(3000)#list1.insert(1,"hadoop") ###插入 一个 列表元素#list1[0] = "spark" ###改动列表元素#list1.remove(2000) ###删除一个元素#del list1[2] ####删除一个元素#list1.pop() ####默认不输入下标就是删除最后一个元素print (list1.index("chemistry")) ####找出 所在元素的下标print (list1[list1.index("chemistry")]) ####找出 所在元素的下标并打印出来print(list1)#print(list1[-3:-1])

#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishlist1 = ['physics', 'chemistry', 'hadoop','spark']list2 = [1,2,3,4,5]#list1.append(3000)#list1.insert(1,"hadoop") ###插入 一个 列表元素#list1[0] = "spark" ###改动列表元素#list1.remove(2000) ###删除一个元素#del list1[2] ####删除一个元素#list1.pop() ####默认不输入下标就是删除最后一个元素print (list1.index("chemistry")) ####找出 所在元素的下标print (list1[list1.index("chemistry")]) ####找出 所在元素的下标并打印出来print(list1.count(1997)) ####统计这个列表中的1997有几个print(list1)list1.reverse() ###反转print(list1)list1.sort() ##### 排序按照ASCII排序print(list1)list1.extend(list2) ####增加合并print(list1)
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishlist1 = ['physics', 'chemistry', 'hadoop','spark',["hbase","sqoop"]]#list2 = [1,2,3,4,5]list3 = list1.copy() ####copy一份列表 只拷贝 第一层 (浅拷贝)print(list1)print(list3)list1[2] = "天下第一"list1[4][0] = "hive"print(list1)print(list3)

#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport copy #### 深拷贝完全的复制list1 = ['physics', 'chemistry', 'hadoop','spark',["hbase","sqoop"]]#list2 = [1,2,3,4,5]list3 = copy.deepcopy(list1) ####copy一份列表 (深copy)print(list1)print(list3)list1[2] = "天下第一"list1[4][0] = "hive"print(list1)print(list3)
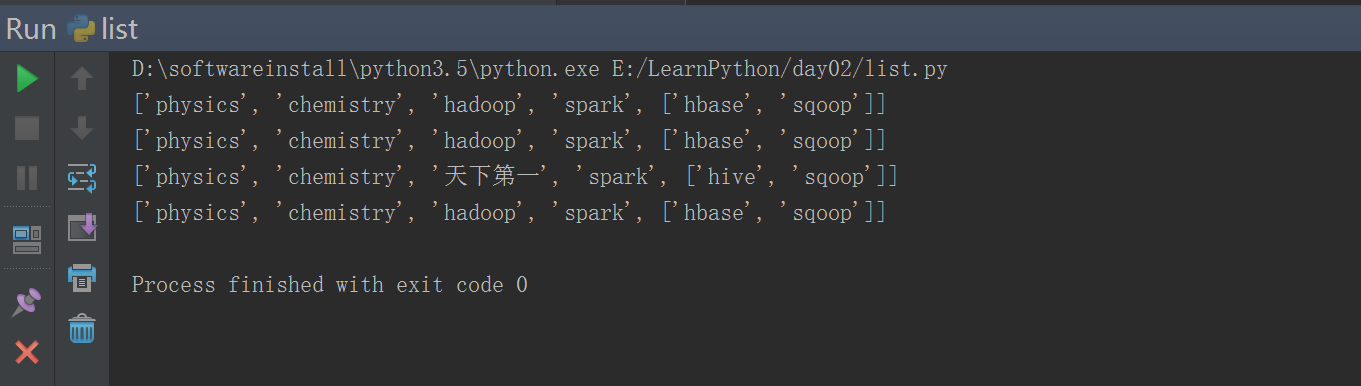
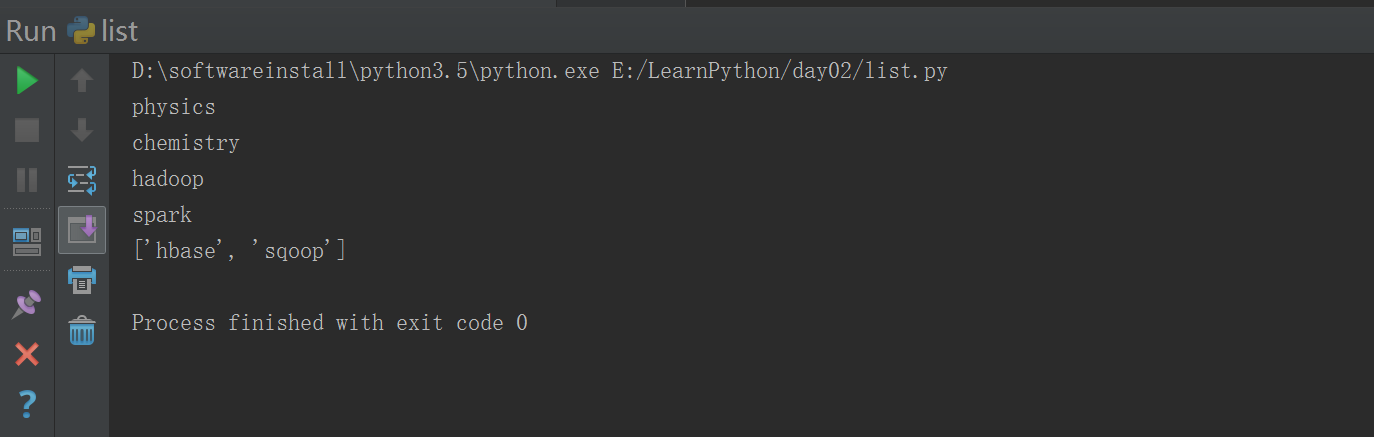
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport copylist1 = ['physics', 'chemistry', 'hadoop','spark',["hbase","sqoop"]]for i in list1: ####列表的循环打印print(i)
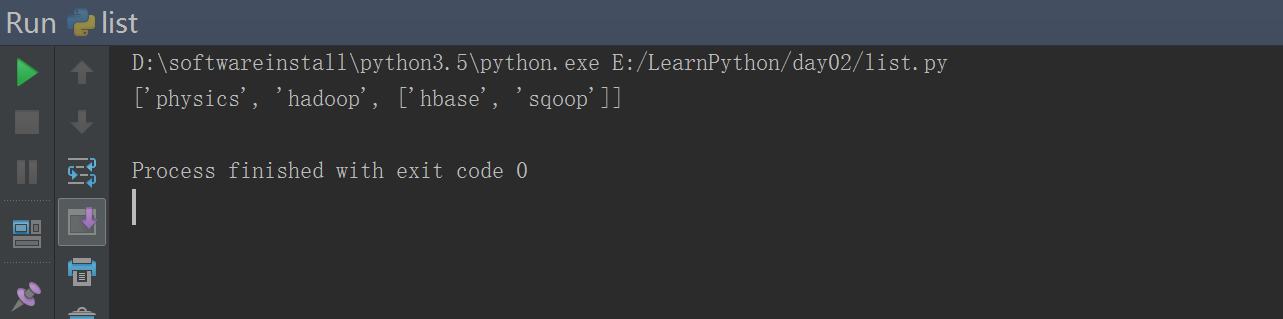
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport copylist = ['physics', 'chemistry', 'hadoop','spark',["hbase","sqoop"]]print(list[::2]) ### 跳着切片
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishimport copypersion = ["spark",["saving",100]]'''p1 = copy.copy(persion)p2 = persion[:]p3 = list(persion)'''p1 = persion[:]p2 = persion[:]p1[0] = "zhangy"p2[0] = "flyfish"p1[1][19] = 50print(p1)print(p2)

- 3.7 元组
元组元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表语法1names = ("alex","jack","eric")它只有2个方法,一个是count,一个是index,完毕。
- 3.8 购物车程序:
程序:购物车程序需求:启动程序后,让用户输入工资,然后打印商品列表允许用户根据商品编号购买商品用户选择商品后,检测余额是否够,够就直接扣款,不够就提醒可随时退出,退出时,打印已购买商品和余额
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishproduct_list = [['Apple',10],['Banner',6],['Peach',12],['Orage',14],['Grape',11]]shopping_list = []salary = input("请输入你的余额:")if salary.isdigit():salary = int(salary)while True:for index, item in enumerate(product_list):print(index,item)user_choice = input("请输入商品的编号:")if user_choice.isdigit():user_choice = int(user_choice)if user_choice < len(product_list) and user_choice >= 0:p_item = product_list[user_choice]if p_item[1] < salary:shopping_list.append(p_item)salary -= p_item[1]print("您购买的%s已加入购物车,余额剩余:\033[31;1m%s\033[0m" %(p_item,salary))else:print("\033[41;1m你的余额不足!\033[0m")else:print("找不到相应的商品编号!")elif user_choice == 'q':print("购物车内的商品如下:%s\n您的余额剩余:%s" %(shopping_list,salary))for i in shopping_list:print(i)exit()else:print("您输入的选项错误!")else:print("Error!")
- 3.9 字符串操作
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishname = "my \tname is flyfish"name1 = "my name is {name1} and i am {year} old"print(name.capitalize()) # 首字母大写print(name.count("f")) # 统计f 的 个数print(name.center(50,"-")) # 打印50 个字符,不够- 补上 中间显示print(name.endswith("sh")) # 判断一句话以什么结尾print(name.expandtabs(tabsize=30)) # 转换有多少个空格print(name.find("name")) # 查找 name 是第几个字符print(name[name.find("name"):]) # 字符串切片print(name1.format(name1= "flyfish",year=23)) # 字符串格式化print (name1.format_map( {"name1":"flyfish","year":12}))print(name.index("is"))print(name.isalnum()) ## 阿拉伯数字加阿拉伯字符print("abc123".isalnum()) ## 纯英文与 数字print("abc123\t".isalnum())print("abcd".isalpha()) # 纯英文字符(包含大写与小写)print("1".isdecimal()) # 十进制的意思print("1A".isdecimal())print("1A".isdigit()) # 整数print("1A".isidentifier()) ## 判断是不是一个合法的标识符变量名print('1A'.islower()) ### 判断是不是一个小写print('1A'.isnumeric())print('My Name Is '.istitle()) ## 大写字母开头print("My Name is".isprintable())print("AA".isupper()) ### 判端是不是大写print("+".join(["1","2","3"])) ## 加减法print(name.ljust(50,"*")) ### 长50 不够 *右补充print(name.rjust(50,"*")) ### 长50 不够#左边补充print("alex".upper())print("Alex".lower())print("\nALEX".lstrip()) ### 从左边去除空格print("ALEX\n".rstrip()) ### 去除右边的空格print("\n ALEX\n".strip()) ### 去除左右边的空格p = str.maketrans("abcdefli","12$%3456")print("alex li".translate(p))print("alex li".replace("l","L",1)) # 替换 第一个I变成大写print("alex li".rfind("l")) # 找最后I的下标print("1+2+3+4".split("+")) ## 切分数据块print("alex li".swapcase()) ## 大写print("alex li" .zfill(50)) ## 长度50 不够 0 补充
- 4.1 字典使用
字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划、字母来查对应页的详细内容。字典的特性:dict是无序的key必须是唯一的,so 天生去重
- 4.1.1 字典的 基本操作
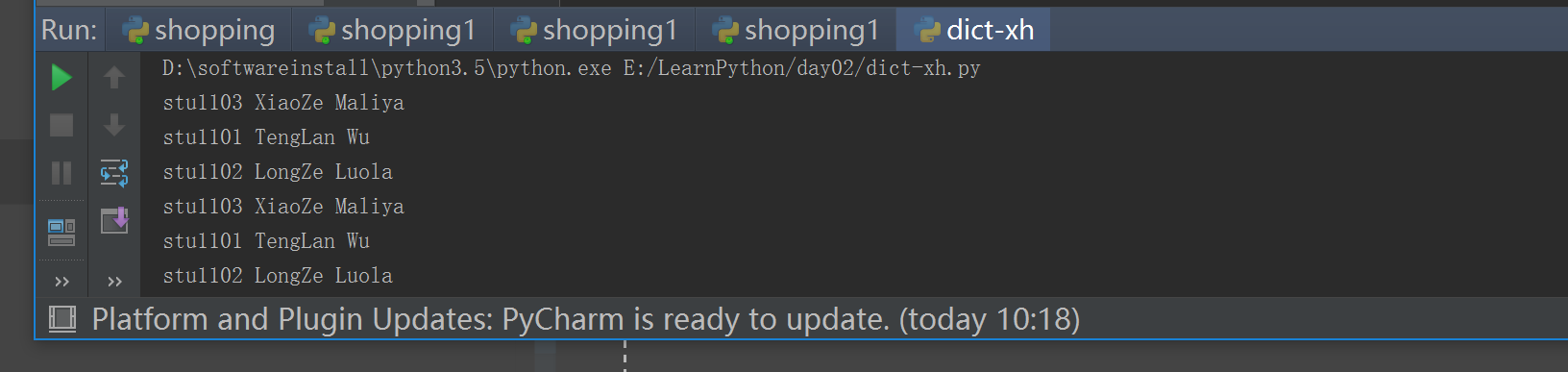
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishinfo = {'stu1101': "TengLan Wu",'stu1102': "LongZe Luola",'stu1103': "XiaoZe Maliya",}print(info)print(info["stu1101"]) ### 字典以键 取值info["stu1101"] = "武藤兰" # 修改info["stu1104"] = "changjingkong"# 增加#del info ["stu1101"]# 删除#info.pop("stu1101")# 删除info.popitem() ## 随便删除一个print(info)print("stu1103" in info) # python2 这样写print(info.get("stu1105"))# 查看一个key 是否存在
- 4.1.2 字典的多级嵌套
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishav_catalog = {"欧美":{"www.youporn.com": ["很多免费的,世界最大的","质量一般"],"www.pornhub.com": ["很多免费的,也很大","质量比yourporn高点"],"letmedothistoyou.com": ["多是自拍,高质量图片很多","资源不多,更新慢"],"x-art.com":["质量很高,真的很高","全部收费,屌比请绕过"]},"日韩":{"tokyo-hot":["质量怎样不清楚,个人已经不喜欢日韩范了","听说是收费的"]},"大陆":{"1024":["全部免费,真好,好人一生平安","服务器在国外,慢"]}}av_catalog["大陆"]["1024"][21] += ",可以用爬虫爬下来"print(av_catalog["大陆"]["1024"])av_catalog.setdefault("大陆",{"www.baidu.com"})print(av_catalog)#ouput['全部免费,真好,好人一生平安', '服务器在国外,慢,可以用爬虫爬下来']
- 4.1.3 字典的 增加 与合并 有交叉的key 就覆盖了
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishinfo = {'stu1101': "TengLan Wu",'stu1102': "LongZe Luola",'stu1103': "XiaoZe Maliya",}b = {"stu1101" : "alex",1:2,3:4}info.update(b)print(info)
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishinfo = {'stu1101': "TengLan Wu",'stu1102': "LongZe Luola",'stu1103': "XiaoZe Maliya",}b = {"stu1101" : "alex",1:2,3:4}info.update(b)c = dict.fromkeys([6,7,8],"test") ## 初始化一个字典给一个keysd = dict.fromkeys([6,7,8],[1,{"name":"alex"},444])print(d)d[7][22]["name"] = "jack chen" # 少用这个就是一个坑print(d)print(c )print(info.items()) # 把一个字典变成一个列表
- 字典的循环
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:FlyFishinfo = {'stu1101': "TengLan Wu",'stu1102': "LongZe Luola",'stu1103': "XiaoZe Maliya",}for i in info:print(i,info[i])for k,v in info.items():print(k,v)
- 5 集合:
集合是一个无序的,不重复的数据组合,它的主要作用如下:去重,把一个列表变成集合,就自动去重了关系测试,测试两组数据之前的交集、差集、并集等关系
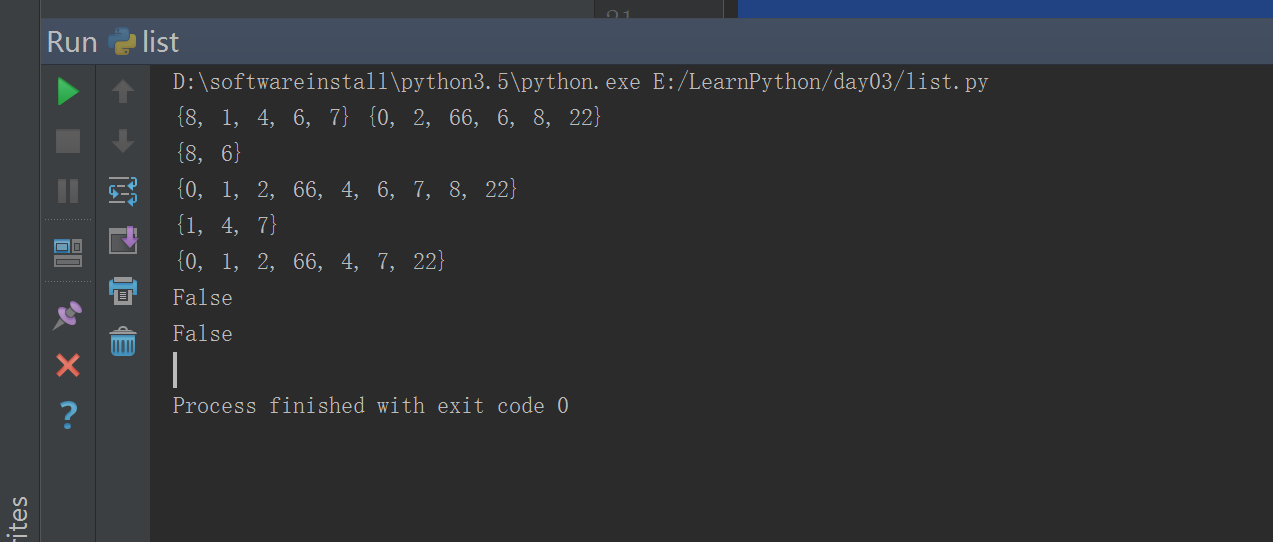
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyylist01 = [1,4,5,7,5,4,3]list01= set(list01)list02 = set([2,6,5,7,9])b = list01 | list02 # 求并集t = list01 & list02 # 求交集c = list01 - list02 # 求差集d = list01 ^ list02 # 求对称差集e = list01 in list02print(b)print(t)print(c)print(d)print(e)
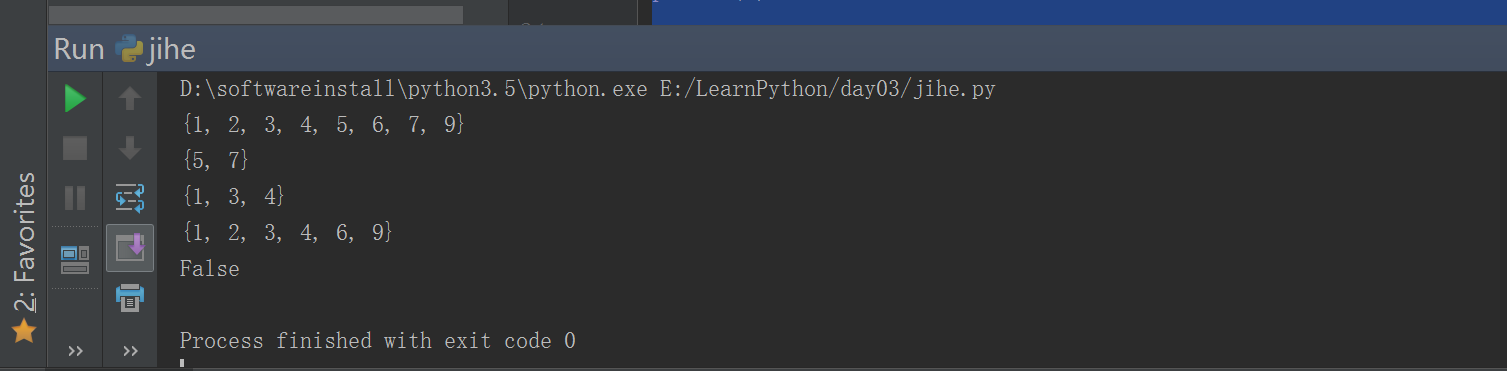
#!/usr/bin/env python# -*- coding: utf-8 -*-# Author:zhangyylist1 = [1,4,6,7,8,4]list02 = [2,3,4,5,6]list1 = set(list1) ###变成集合,去除重复的list2 = set([2,6,0,66,22,8])print(list1,list2)print(list1.intersection(list2)) ### 取交集print(list1.union(list2)) #### 取并集print(list1.difference(list2)) ### 取差集print(list1.symmetric_difference(list2)) ## 对称差集print(list1.issubset(list2)) ### 取子集print(list1.issuperset(list2)) ### 取父集