@zhangyy
2017-05-04T10:00:05.000000Z
字数 1940
阅读 447
flume 监控hive日志文件
协作框架
- flume 监控hive 日志文件
一: flume 监控hive的日志
- 案例需求:
1. 实时监控某个日志文件,将数据收集到存储hdfs 上面, 此案例使用exec source ,实时监控文件数据,使用Memory Channel 缓存数据,使用HDFS Sink 写入数据2. 此案例实时监控hive 日志文件,放到hdfs 目录当中。hive 的日志目录是hive.log.dir = /home/hadoop/yangyang/hive/logs
- 1.2 在hdfs 上面创建收集目录:
bin/hdfs dfs -mkdir /flume
- 1.3 拷贝flume 所需要的jar 包
cd /home/hadoop/yangyang/hadoop/cp -p share/hadoop/hdfs/hadoop-hdfs-2.5.0-cdh5.3.6.jar /home/hadoop/yangyang/flume/lib/cp -p share/hadoop/common/hadoop-common-2.5.0-cdh5.3.6.jar/home/hadoop/yangyang/flume/lib/cp -p share/hadoop/tools/lib/commons-configuration-1.6.jar/home/hadoop/yangyang/flume/lib/cp -p share/hadoop/tools/lib/hadoop-auth-2.5.0-cdh5.3.6.jar /home/hadoop/yangyang/flume/lib/
- 1.4 配置一个新文件的hive-test.properties 文件:
cp -p test-conf.properties hive-conf.properties
vim hive-conf.properties
# example.conf: A single-node Flume configuration# Name the components on this agenta2.sources = r2a2.sinks = k2a2.channels = c2# Describe/configure the sourcea2.sources.r2.type = execa2.sources.r2.command = tail -f /home/hadoop/yangyang/hive/logs/hive.loga2.sources.r2.bind = namenode01.hadoop.coma2.sources.r2.shell = /bin/bash -c# Describe the sinka2.sinks.k2.type = hdfsa2.sinks.k2.hdfs.path = hdfs://namenode01.hadoop.com:8020/flume/%Y%m/%da2.sinks.k2.hdfs.fileType = DataStreama2.sinks.k2.hdfs.writeFormat = Texta2.sinks.k2.hdfs.batchSize = 10# 设置二级目录按小时切割a2.sinks.k2.hdfs.round = truea2.sinks.k2.hdfs.roundValue = 1a2.sinks.k2.hdfs.roundUnit = hour# 设置文件回滚条件a2.sinks.k2.hdfs.rollInterval = 60a2.sinks.k2.hdfs.rollsize = 128000000a2.sinks.k2.hdfs.rollCount = 0a2.sinks.k2.hdfs.useLocalTimeStamp = truea2.sinks.k2.hdfs.minBlockReplicas = 1# Use a channel which buffers events in memorya2.channels.c2.type = memorya2.channels.c2.capacity = 1000a2.channels.c2.transactionCapacity = 100# Bind the source and sink to the channela2.sources.r2.channels = c2a2.sinks.k2.channel = c2
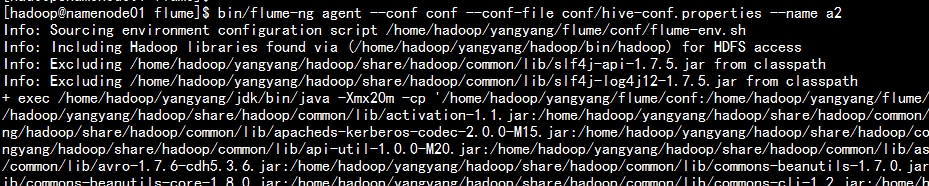
- 1.5 运行agent 处理
bin/flume-ng agent --conf conf --conf-file conf/hive-conf.properties --name a2
- 1.6 写入hive 的log日志文件测试:
cd /home/hadoop/yangyang/hive/logsecho "111" >> hive.log每隔一段时间执行上面的命令测试
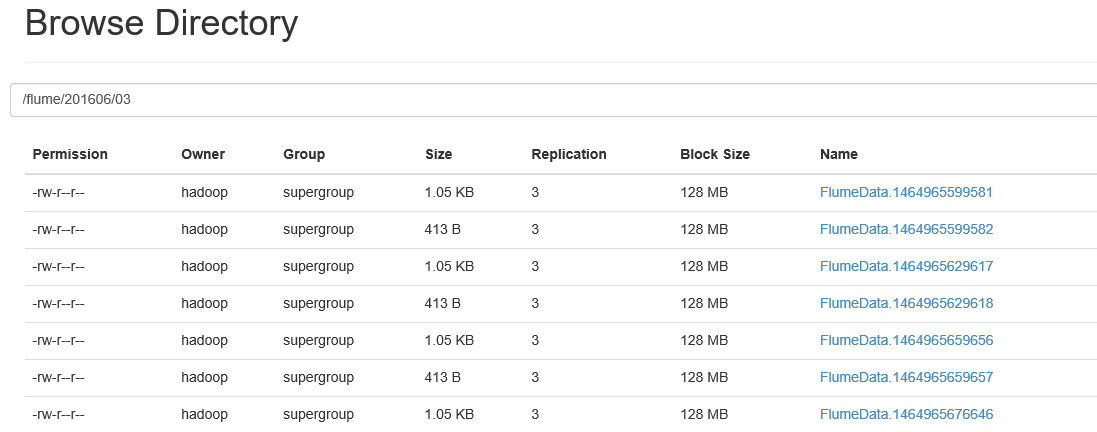
- 1.7 去hdfs 上面去查看: