@zhangyy
2020-07-20T07:06:54.000000Z
字数 3106
阅读 690
部署Hadoop 的HDFS 的联盟 federation ( hdfs双 active)
大数据运维专栏
- 一: 关于 hadoop 的hdfs 的联盟的 概述
- 二: Hadoop 的 federation的部署
- 三: 关于fedration 联盟的数据写入测试
一: 关于 hadoop 的hdfs 的联盟的 概述
1.1 hdfs federation 背景概述
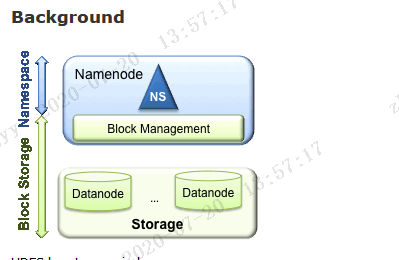
单 NameNode 的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程使用的内存可能会达到上百 G,NameNode 成为了性能的瓶颈。因而提出了 namenode 水平扩展方案-- Federation。Federation 中文意思为联邦,联盟,是 NameNode 的 Federation,也就是会有多个NameNode。多个 NameNode 的情况意味着有多个 namespace(命名空间),区别于 HA 模式下的多 NameNode,它们是拥有着同一个 namespace。既然说到了 NameNode 的命名空间的概念,这里就看一下现有的 HDFS 数据管理架构,如下图所示:
1.2 Federation 架构设计
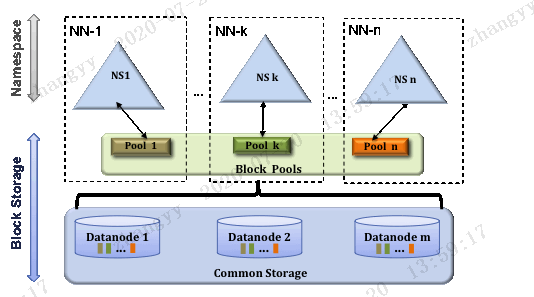
HDFS Federation 是解决 namenode 内存瓶颈问题的水平横向扩展方案。Federation 意味着在集群中将会有多个 namenode/namespace。这些 namenode 之间是联合的,也就是说,他们之间相互独立且不需要互相协调,各自分工,管理自己的区域。分布式的 datanode 被用作通用的数据块存储存储设备。每个 datanode 要向集群中所有的namenode 注册,且周期性地向所有 namenode 发送心跳和块报告,并执行来自所有 namenode的命令。
二: Hadoop 的 federation的部署
2.1 环境部署
承接在上文中的分布式部署环境
2.2编辑改变hadoop 的配置文件
编辑core-site.xml 文件:fat01.flyfish.com 的core-site.com 文件配置vim core-site.xml----<configuration><property><name>fs.defaultFS</name><value>hdfs://fat01.flyfish.com:8020</value></property><property><name>hadoop.tmp.dir</name><value>/opt/bigdata/hadoop/data</value></property></configuration>----fat02.flyfish.com 的core-site.xml 文件配置<configuration><property><name>fs.defaultFS</name><value>hdfs://fat02.hadoop.com:8020</value></property><property><name>hadoop.tmp.dir</name><value>/opt/bigdata/hadoop/data</value></property></configuration>---fat03.flyfish.com 的core-site.xml 文件配置:<configuration><property><name>hadoop.tmp.dir</name><value>/opt/bigdata/hadoop/data</value></property></configuration>----
2.3 编辑hdfs-site.xml 文件:
vim hdfs-site.xml (所有节点)<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.nameservices</name><value>ns1,ns2</value></property><property><name>dfs.namenode.rpc-address.ns1</name><value>fat01.flyfish.com:8020</value></property><property><name>dfs.namenode.http-address.ns1</name><value>fat01.flyfish.com:50070</value></property><property><name>dfs.namenode.rpc-address.ns2</name><value>fat02.flyfish.com:8020</value></property><property><name>dfs.namenode.http-address.ns2</name><value>fat02.flyfish.com:50070</value></property></configuration>
2.4 启动服务节点:
删掉原有分布式 节点上面的数据cd /opt/bigdata/hadoop/datarm -rf *----格式化HDFS 节点处理fat01.flyfish.comcd /opt/bigdata/hadoop/bin/hdfs namenode –format –clusterID hdfs-cluster
fat02.flyfish.comcd /opt/bigdata/hadoop/bin/hdfs namenode –format –clusterID hdfs-cluster
启动fat01.flyfish.com与fat02.flyfish.com节点上的namenodefat01.flyfish.combin/hdfs --daemon start namenode
fat02.flyfish.combin/hdfs --daemon start namenode

启动各个节点上面datanodebin/hdfs --daemon start datanode


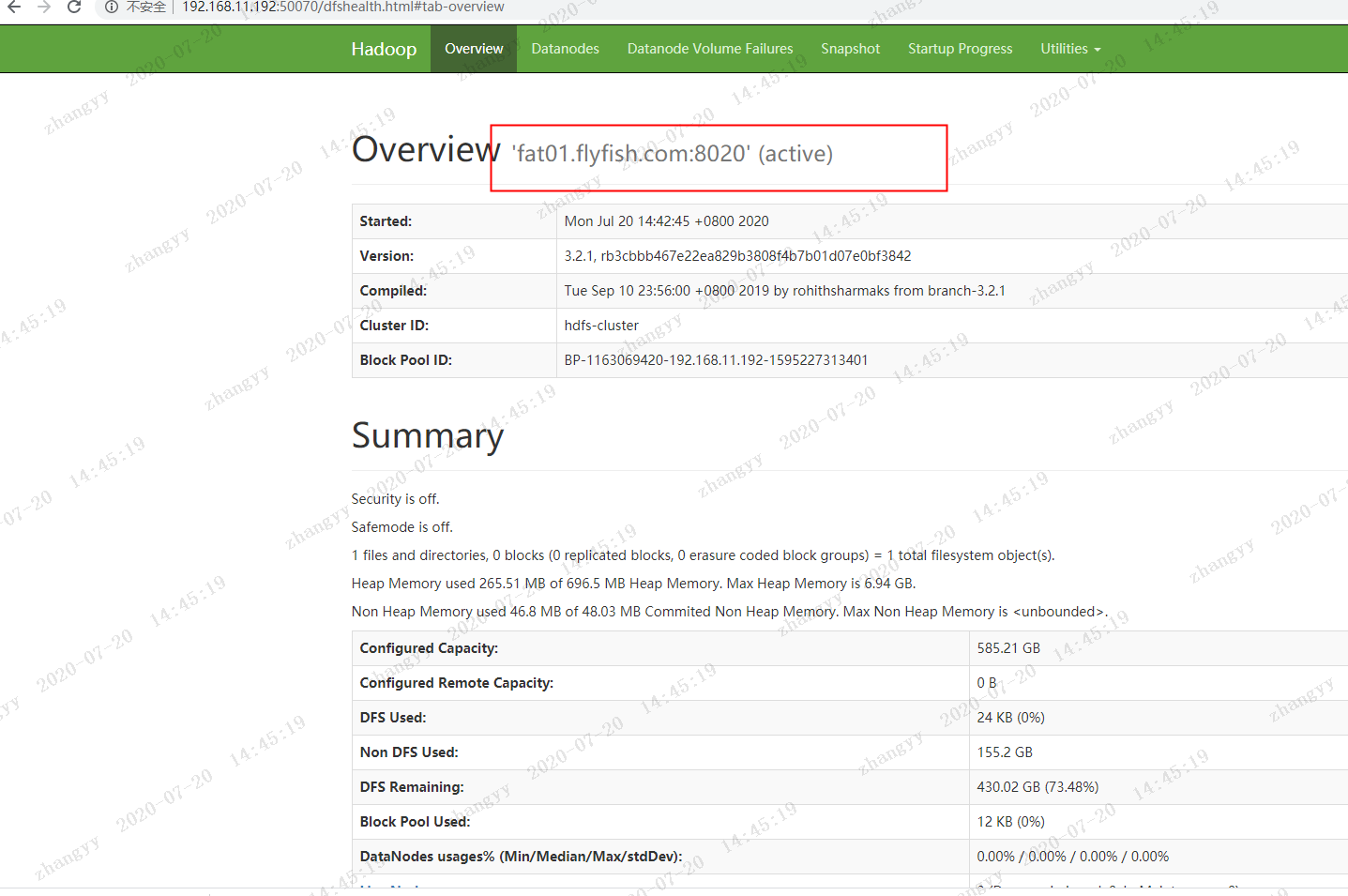
打开fat01.flyfish.com 的hdfs 页面http://192.168.11.192:50070
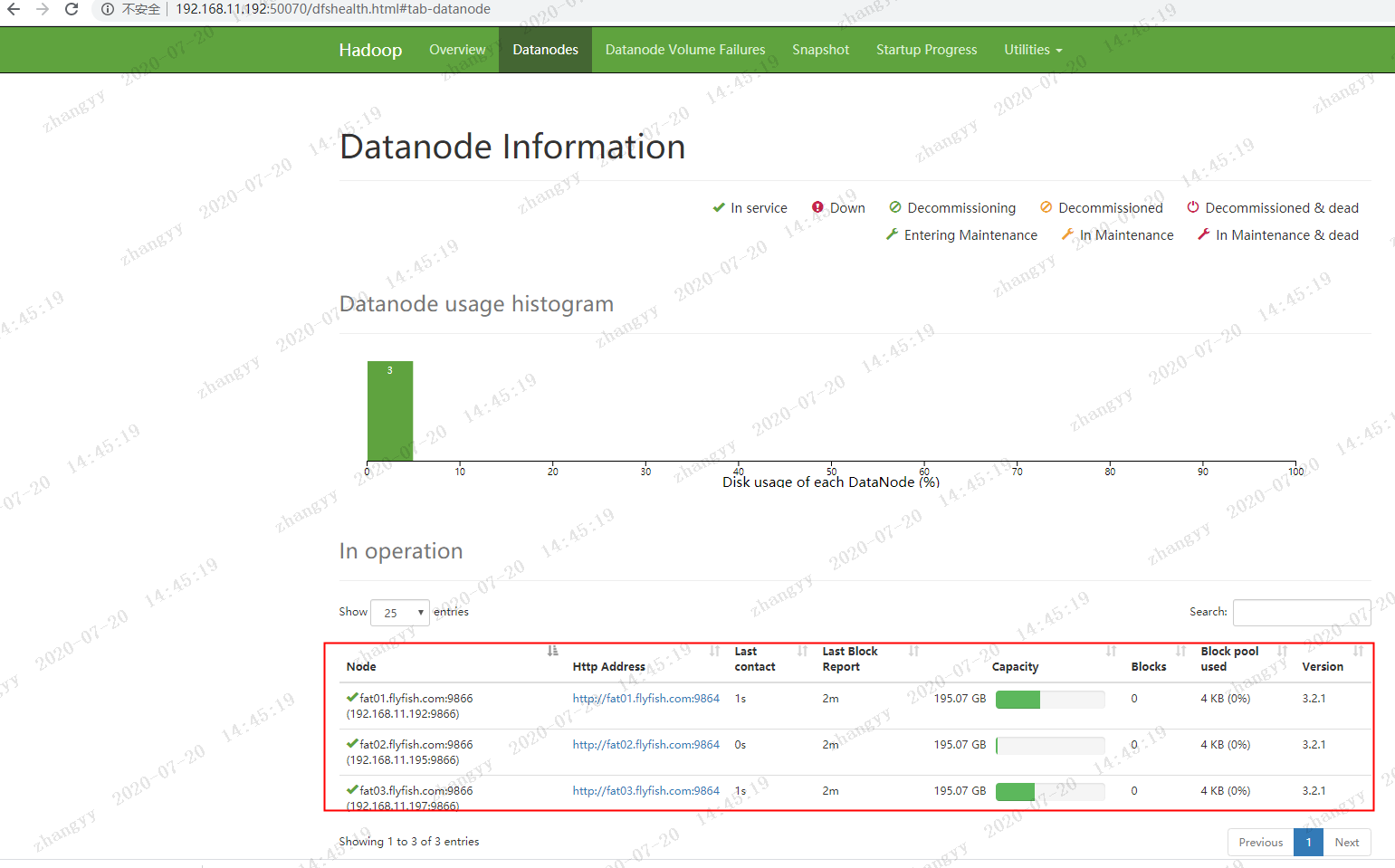
打开fat02.flyfish.com 的hdfs 页面http://192.168.11.195:50070
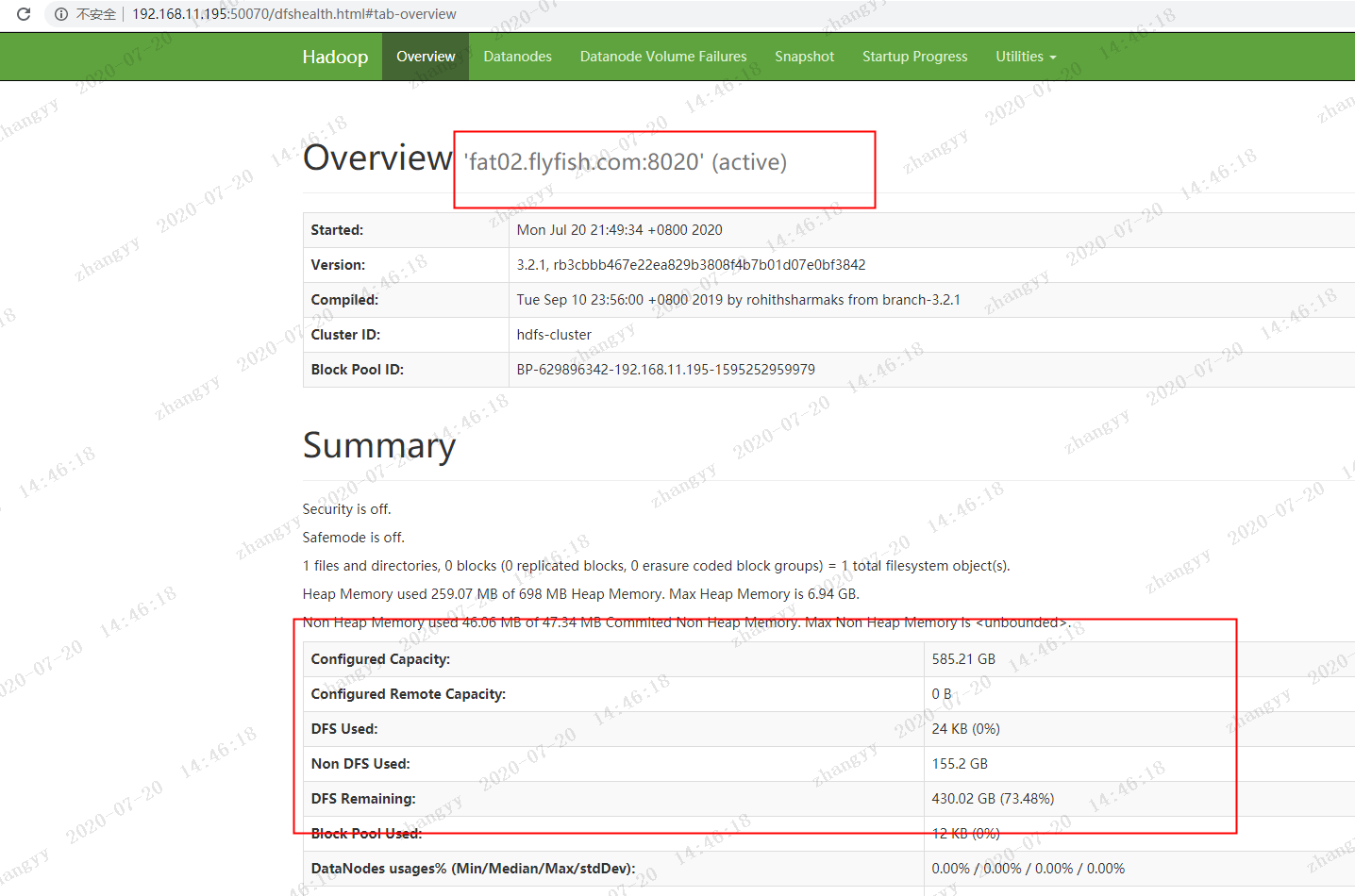
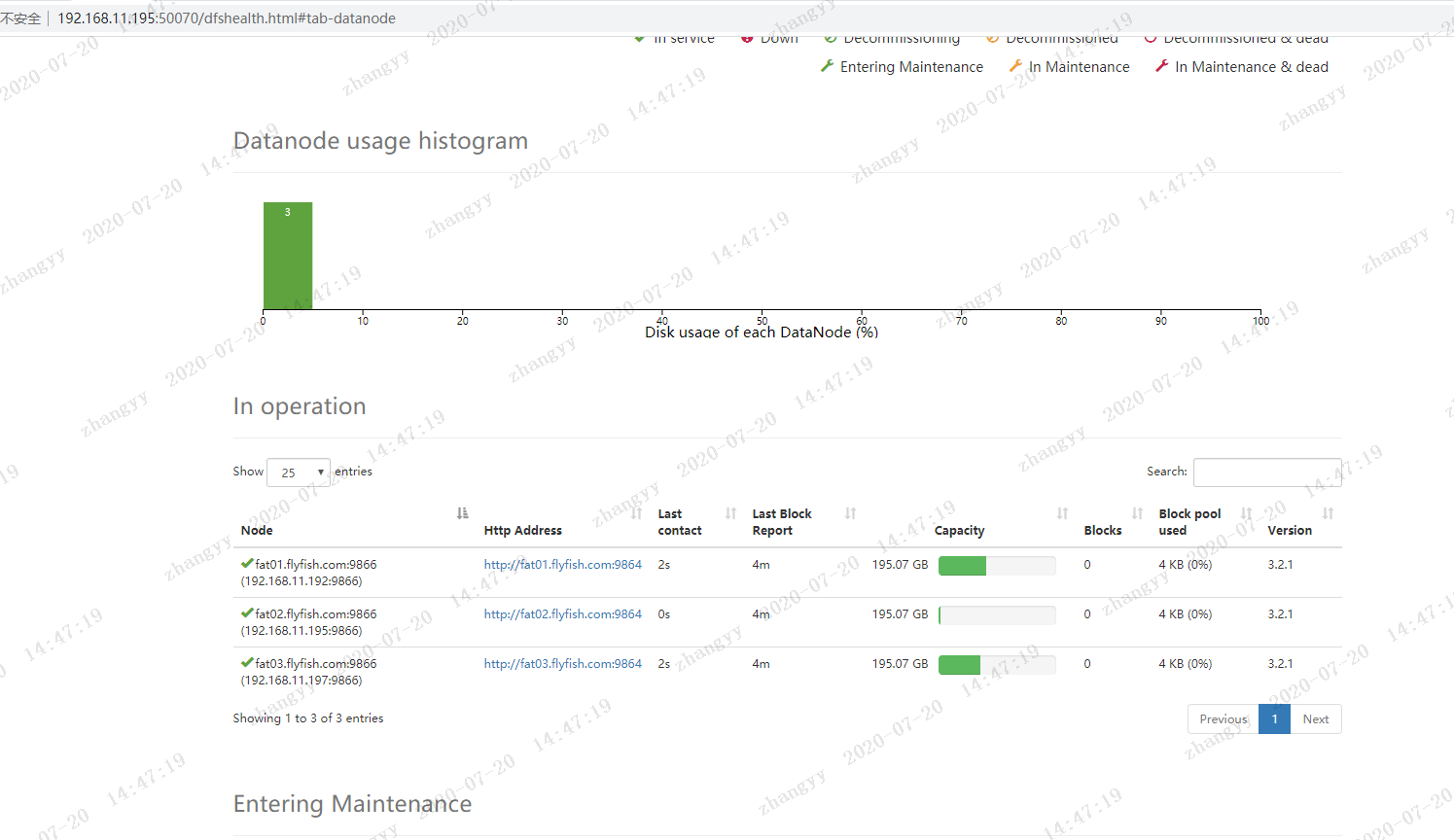
三: hdfs federation 的测试
fat01.flyfish.comhdfs dfs -mkdir /inputhdfs dfs -put word.txt /input
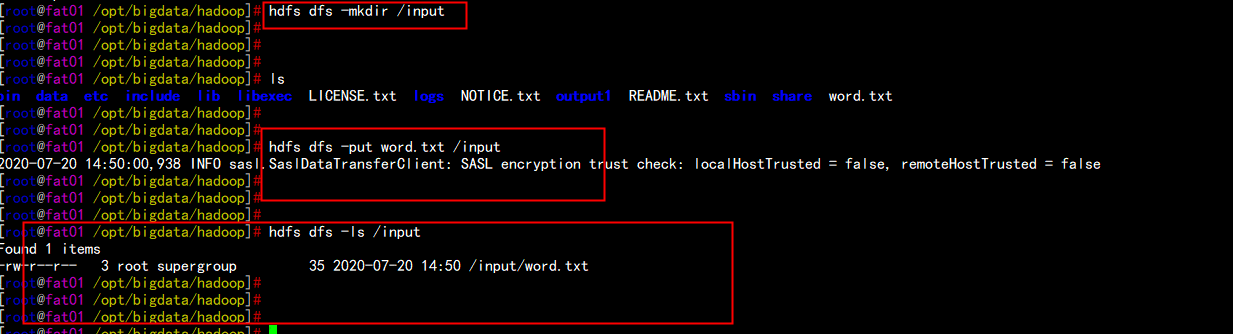
去fat02.flyfish.com 上面去查看hdfs dfs -ls /input在 fat02.flyfish.com 节点上面 是看不到 在fat01.flyfish.com 上面 数据的

fat02.flyfish.com 创建目录与文件hdfs dfs -mkdir /flyfishhdfs dfs -put word.txt /flyfish
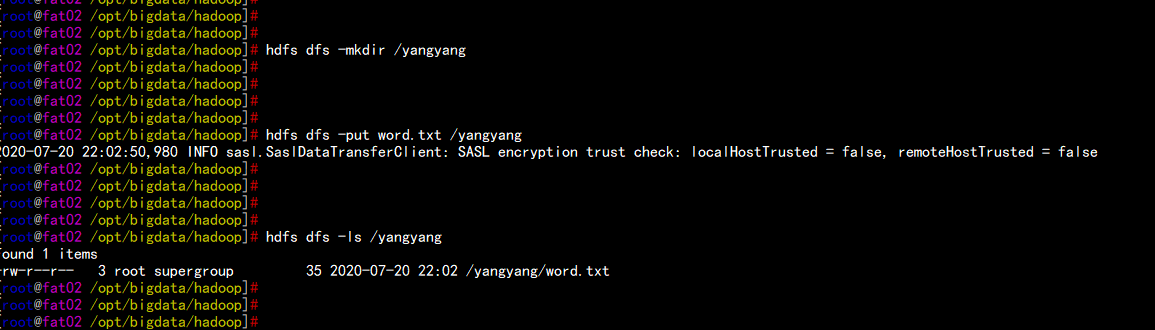
去fat01.flyfish.com 节点上面去查看hdfs dfs -ls /flyfish可以看出 fat01.flyfish.com 节点也 查看不了 fat02.flyfish.com 创建目录与文件

fat03.flyfish.com 节点访问hdfs dfs -ls /fat03.flyfish.com 因为没有NN 入口 访问的是 系统 目录
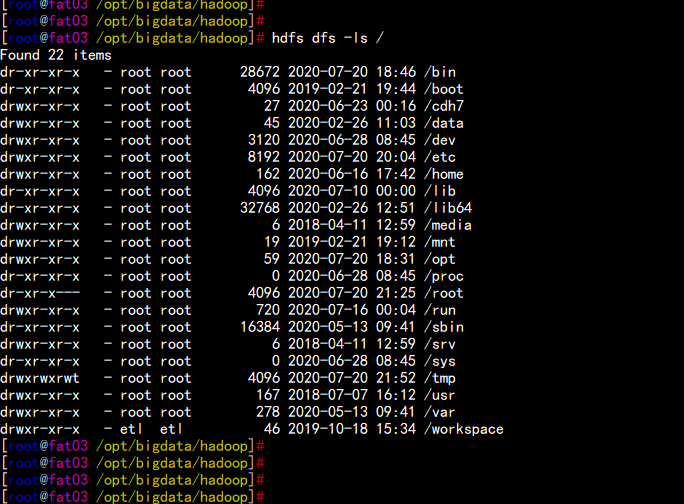
综上所述: hdfs 的 federation 公用的是底层数据主机的DN 节点,上层 走的NN 节点是不同的,另外访问数据也是 从哪个NN节点 写入,也只能走这个节点去查看,其它节点访问不了。如果该节点只做DN 节点默认 访问的是系统 所在 目录
