@zhangyy
2020-07-20T05:50:44.000000Z
字数 6372
阅读 424
hadoop 3.2.1 伪分布与分布式环境构建
大数据运维专栏
- 一:环境准备
- 二:安装Hadoop3.2.1
- 三:运行一个wordcount 测试
- 四:Hadoop 分布式构建与测试
一:环境准备:
1.1 系统环境介绍
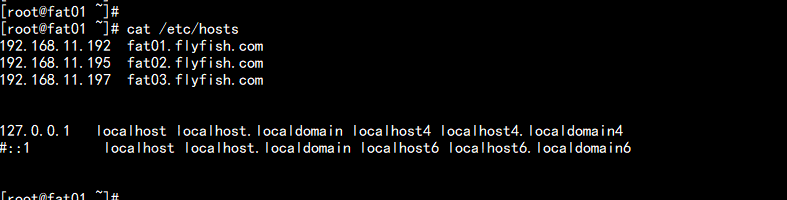
系统:CentOS7.5x64主机名:cat /etc/hosts------192.168.11.192 fat01.flyfish.com192.168.11.195 fat02.flyfish.com192.168.11.197 fat03.flyfish.com-------jdk版本: jdk1.8.181hadoop版本 : hadoop3.2.1
1.2 部署jdk1.8.181
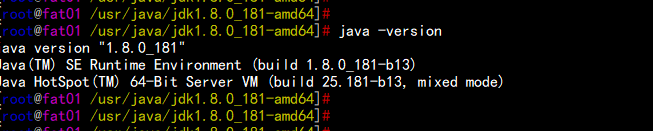
rpm -ivh jdk-8u181-linux-x64.rpmvim /etc/profile---## JAVA_HOMEexport JAVA_HOME=/usr/java/jdk1.8.0_181-amd64export CLASSPATH=$JAVA_HOME/jre/lib:$JAVA_HOME/libexport PATH=$PATH:$JAVA_HOME/bin---source /etc/profilejava -version
二: 安装Hadoop3.2.1 配置伪分布
2.1 准备下载Hadoop3.2.1 版本
下载:wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz解压:tar -zxvf hadoop-3.2.1.tar.gz

2.2 设定Hadoop 安装目录
mkdir -p /opt/bigdata ## 将Hadoop 安装到 /opt/bigdata 目录下面mv hadoop-3.2.1 /opt/bigdata/hadoop

2.3 配置Hadoop 的配置文件
2.3.1 编译core-site.xml
编译 core-site.xmlcd /opt/bigdata/hadoop/etc/hadoop/vim core-site.xml-----<configuration><property><name>hadoop.tmp.dir</name><value>/opt/bigdata/hadoop/data</value><description>hadoop_temp</description></property><property><name>fs.default.name</name><value>hdfs://fat01.flyfish.com:8020</value><description>hdfs_derect</description></property></configuration>----
2.3.2 编辑hdfs-site.xml
vim hdfs-site.xml---<configuration><property><name>dfs.replication</name><value>1</value><description>num</description><name>dfs.namenode.http-address</name><value>fat01.flyfish.com:50070</value></property></configuration>---
2.3.3 编辑mapred-site.xml
vim mapred-site.xml----<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>fat01.flyfish.com:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/opt/bigdata/hadoop</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/opt/bigdata/hadoop</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/opt/bigdata/hadoop</value></property></configuration>-----
2.3.4 编辑yarn-site.xml
vim yarn-site.xml----<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>-----
2.4 关于jdk 的环境变量配置
echo "export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64" >> hadoop-env.shecho "export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64" >> mapred-env.shecho "export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64" >> yarn-env.sh
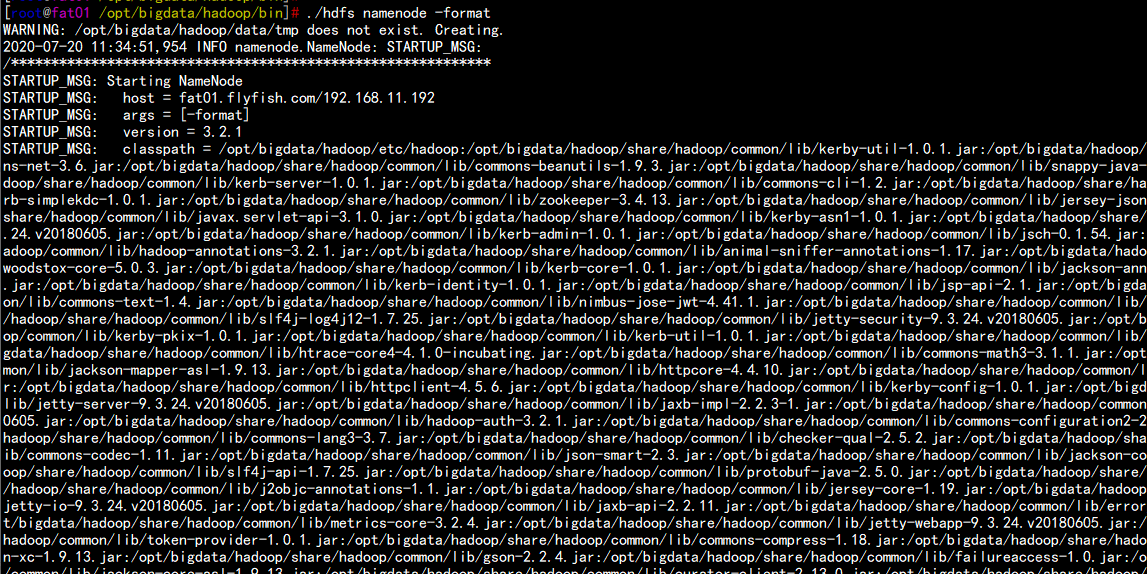
2.5 格式化 namenode文件系统:
cd /opt/bigdata/hadoopbin/hdfs namenode -format


2.6 启动Hadoop 的 hdfs
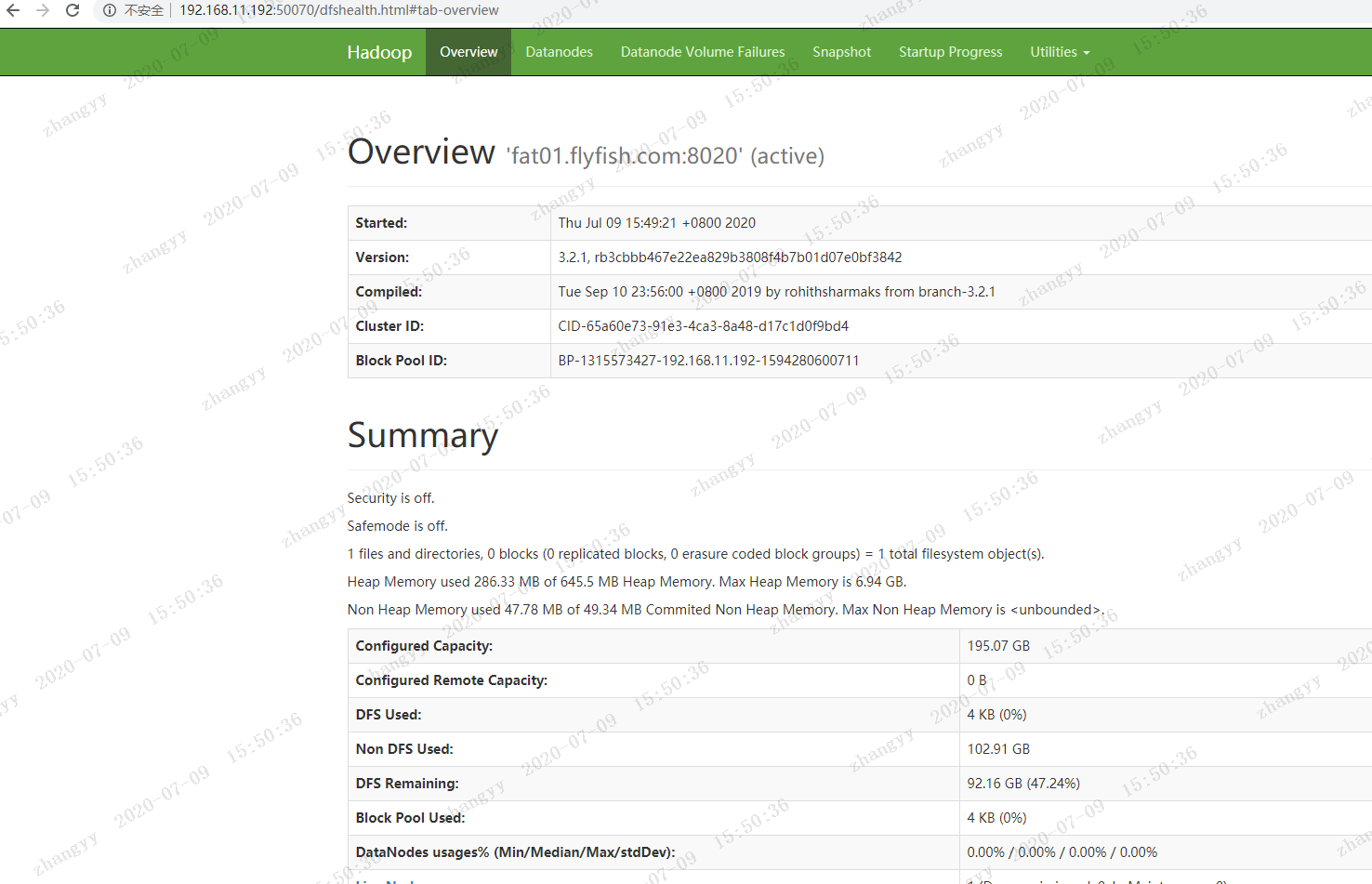
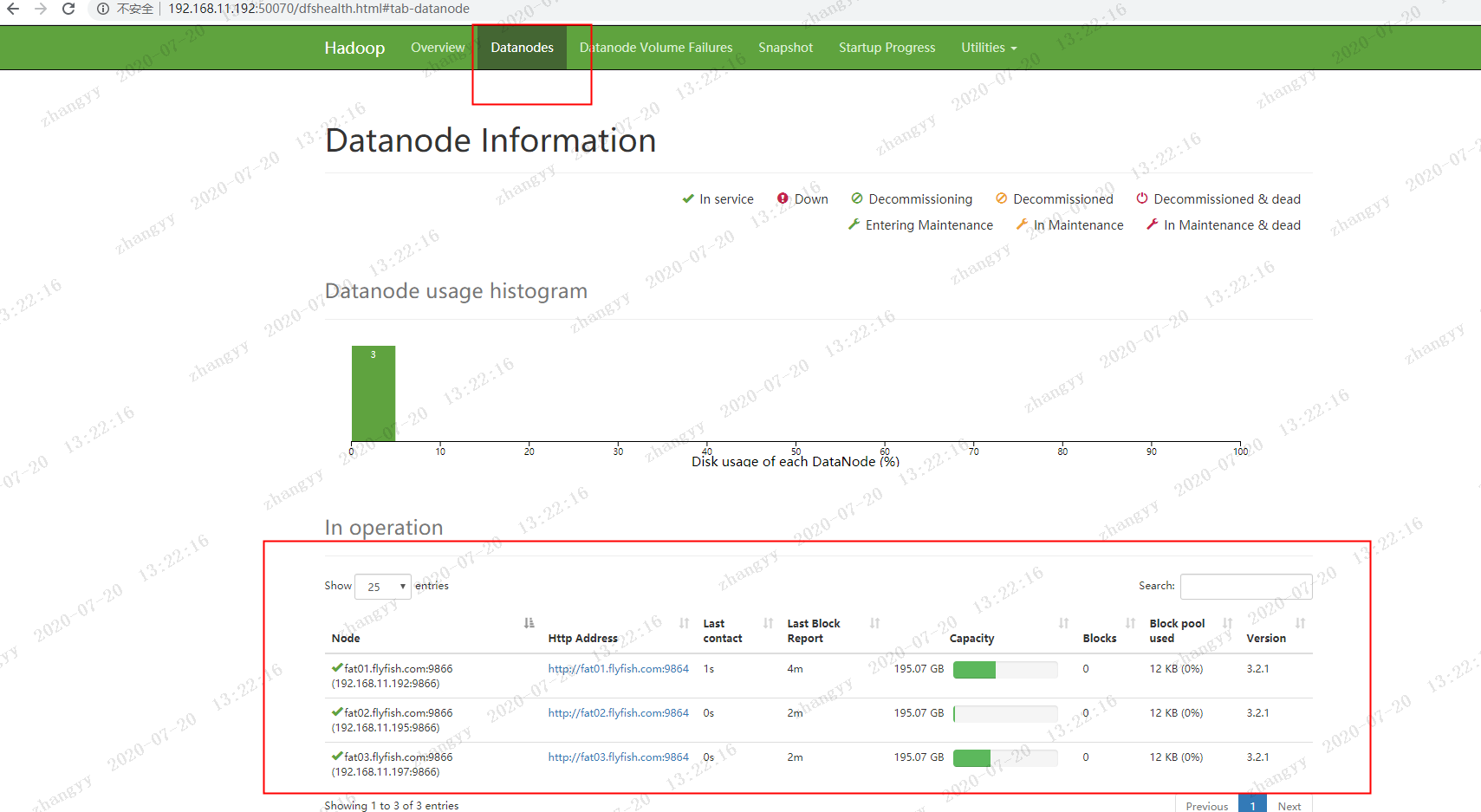
bin/hdfs --daemon start namenodebin/hdfs --daemon start datanode浏览器访问:http://192.168.11.192:50070

2.7 启动Hadoop的yarn
bin/yarn --daemon start resourcemanagerbin/yarn --daemon start nodemanager

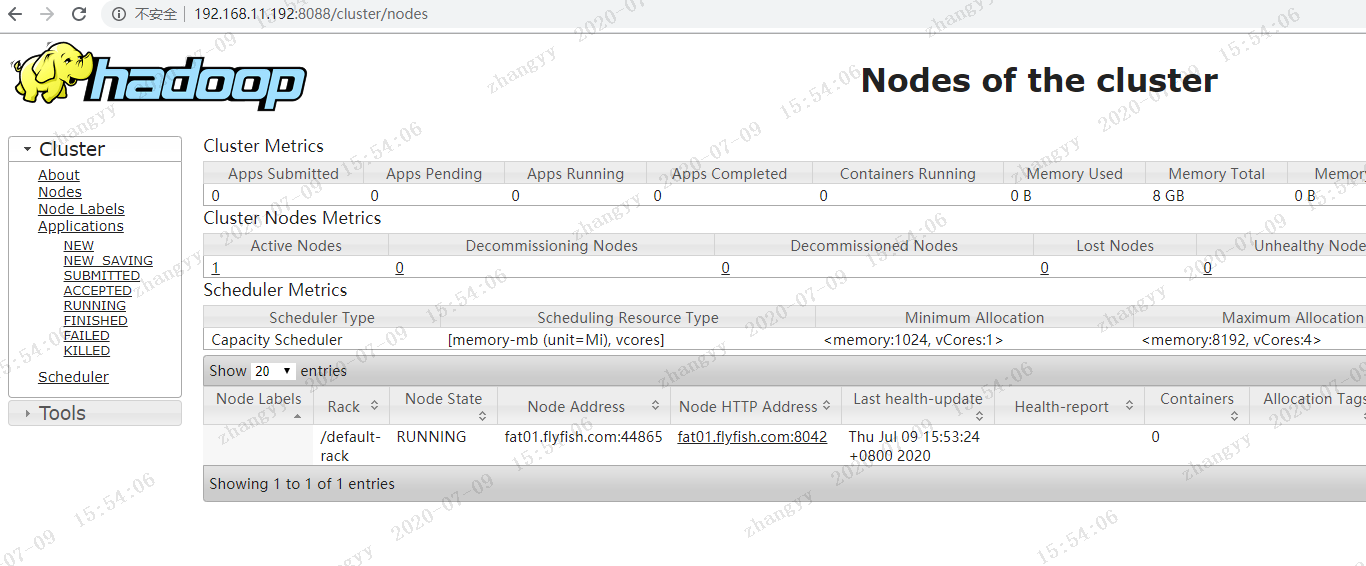
2.8 启动historyserver
bin/mapred --daemon start historyserver
三:运行一个wordcount 测试
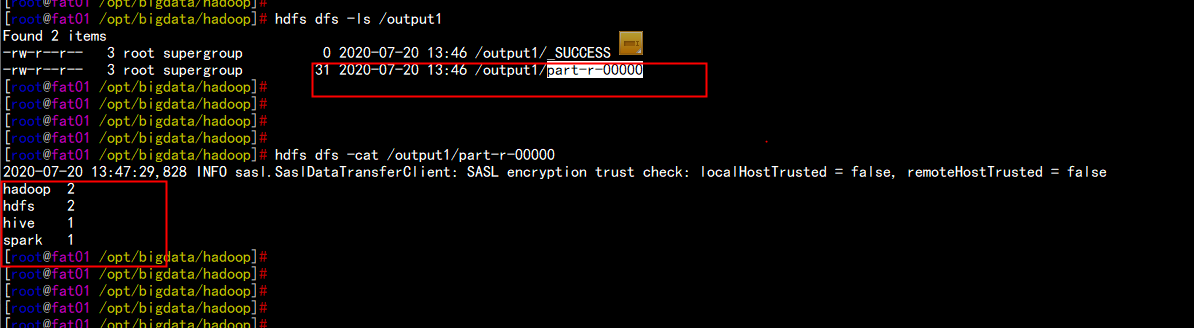
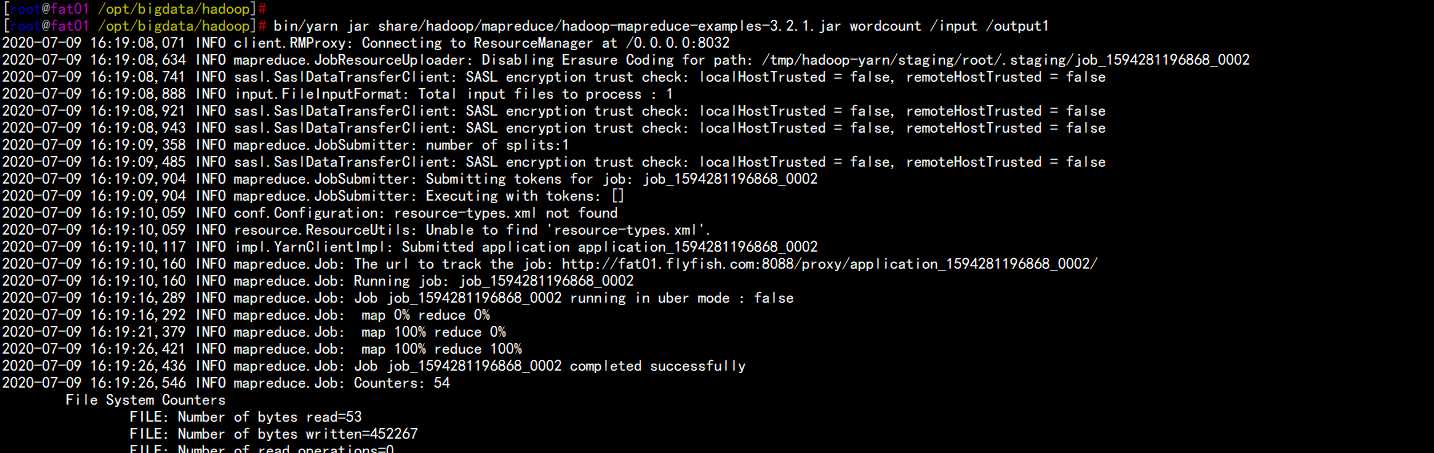
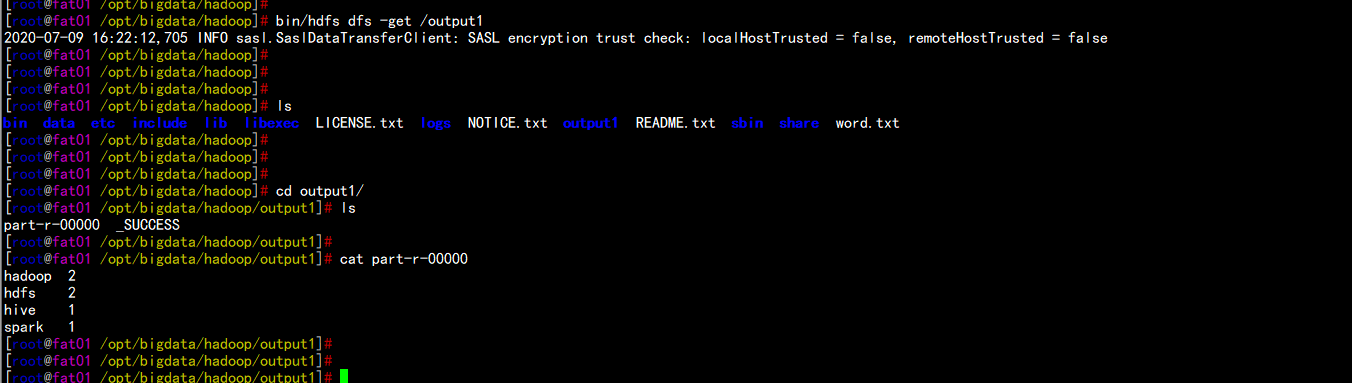
cd /opt/bigdata/hadoopbin/hdfs dfs -mkdir /inputbin/hdfs dfs -put word.txt /inputbin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output1
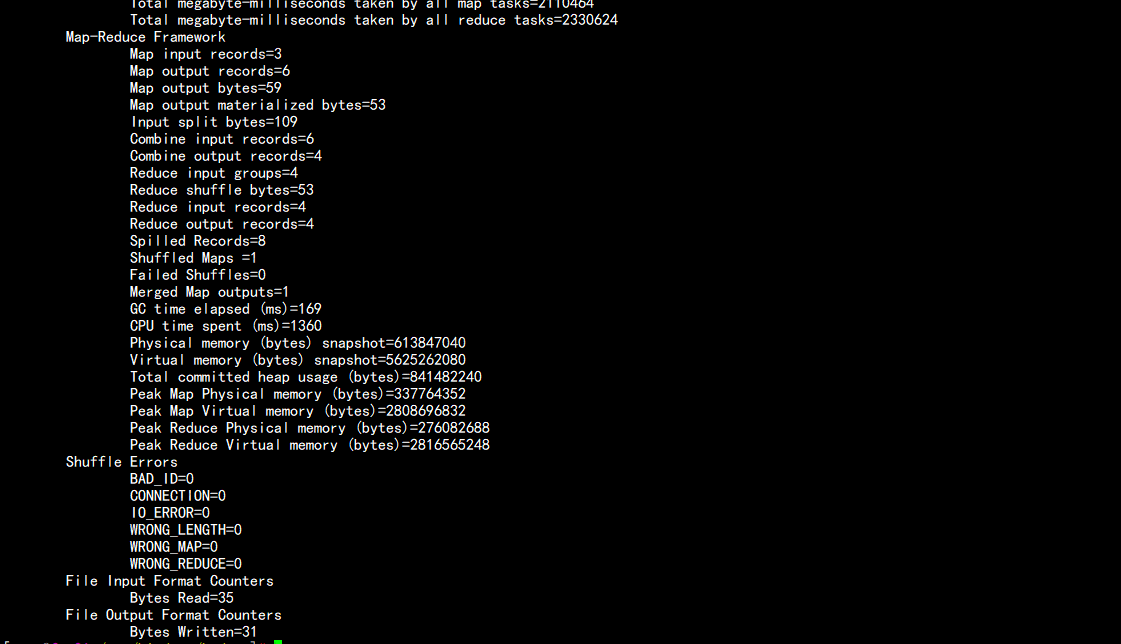
bin/hdfs dfs -put /output1
四:Hadoop 分布构建
4.1 分布构建
承接上文伪分布基础上部署:角色分配图:

cd /opt/bigdata/hadoop/etc/vim core-site.xml----<configuration><property><name>hadoop.tmp.dir</name><value>/opt/bigdata/hadoop/data</value><description>hadoop_temp</description></property><property><name>fs.default.name</name><value>hdfs://fat01.flyfish.com:8020</value><description>hdfs_derect</description></property></configuration>----
编辑hdfs-site.xml 文件:<configuration><property><name>dfs.replication</name><value>3</value></property><property><name>dfs.namenode.http-address</name><value>fat01.flyfish.com:50070</value></property><property><name>dfs.namenode.secondary.http-address</name><value>fat02.flyfish.com:50090</value></property></configuration>
编辑mared-site.xmlvim mared-site.xml-----<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>fat02.flyfish.com:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>fat02.flyfish.com:19888</value></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=/opt/bigdata/hadoop</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=/opt/bigdata/hadoop</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=/opt/bigdata/hadoop</value></property></configuration>-----
编辑yarn-site.xmlvim yarn-site.xml----<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.hostname</name><value>fat02.flyfish.com</value></property><property><name>yarn.log-aggregation-enable</name><value>true</value></property><property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value></property></configuration>----
编辑hadoop-env.sh 文件:vim hadoop-env.sh---export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64export HADOOP_PID_DIR=/opt/bigdata/hadoop/data/tmpexport HADOOP_SECURE_DN_PID_DIR=/opt/bigdata/hadoop/data/tmp----
编辑mapred-env.sh 文件:vim mapred-env.sh----export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64export HADOOP_MAPRED_PID_DIR=/opt/bigdata/hadoop/data/tmp----
编辑yarn-env.sh 文件:vim yarn-env.sh----export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64-----
编辑works 文件vim works---fat01.flyfish.comfat02.flyfish.comfat03.flyfish.com---
同步所有节点cd /opt/tar –zcvf bigdata.tar.gz bigdatascp bigdata.tar.gz root@192.168.11.195:/opt/scp bigdata.tar.gz root@192.168.11.197:/opt/然后到每个节点上面去 解压这个 bigdata.tar.gz删掉原有节点上面格式数据cd /opt/bigdata/hadoop/datarm -rf *
4.2 格式化数据节点
fat01.flyfish.com 主机上执行:cd /opt/bigdata/hadoop/bin./hdfs namenode –format
启动之前先决定 启动用户是是是什么这边默认是rootcd /opt/bigdata/hadoop/sbin对于start-dfs.sh和stop-dfs.sh文件,添加下列参数:----#!/usr/bin/env bashHDFS_DATANODE_USER=rootHADOOP_SECURE_DN_USER=hdfsHDFS_NAMENODE_USER=rootHDFS_SECONDARYNAMENODE_USER=root----
vim start-yarn.sh---YARN_RESOURCEMANAGER_USER=rootHADOOP_SECURE_DN_USER=yarnYARN_NODEMANAGER_USER=root----
4.3 启动角色
启动hdfsfat01.flyfish.com 主机上执行:cd hadoop/sbin/./start-dfs.sh
打开 hdfs webhttp://192.168.11.192:50070
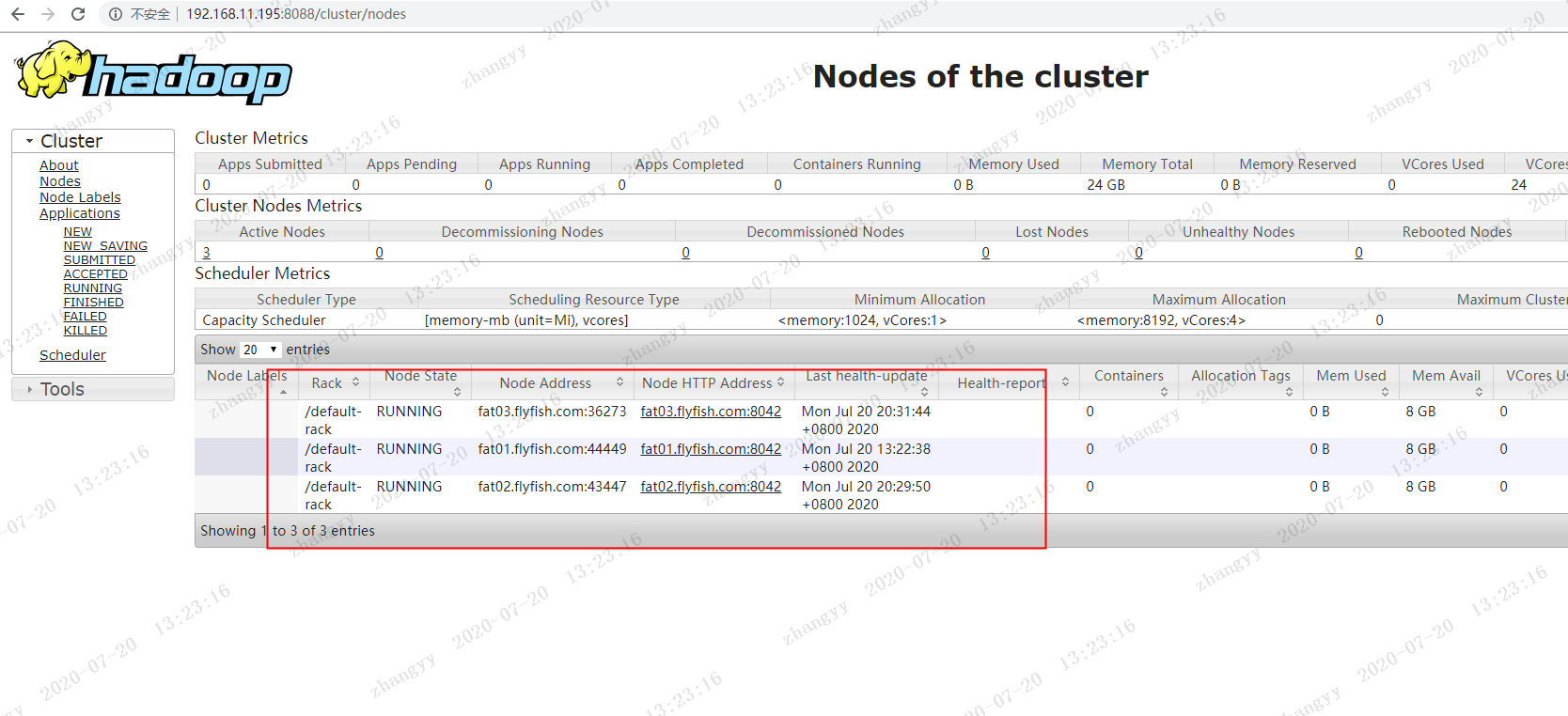
启动yarnfat02.flyfish.comcd hadoop/sbin/start-yarn.sh启动historyservermapred --daemon start jobhistoryserver


打开yarn的界面:http://192.168.11.195:8088
打开jobhistoryserver 的页面http://192.168.11.195:19888
启动角色对比

fat01.flyfish.comjps
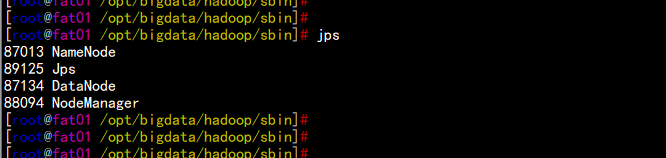
fat02.flyfish.comjps

fat03.flyfish.comjps

至此 Hadoop 分布式环境搭建完成
4.4 关于启动job测试
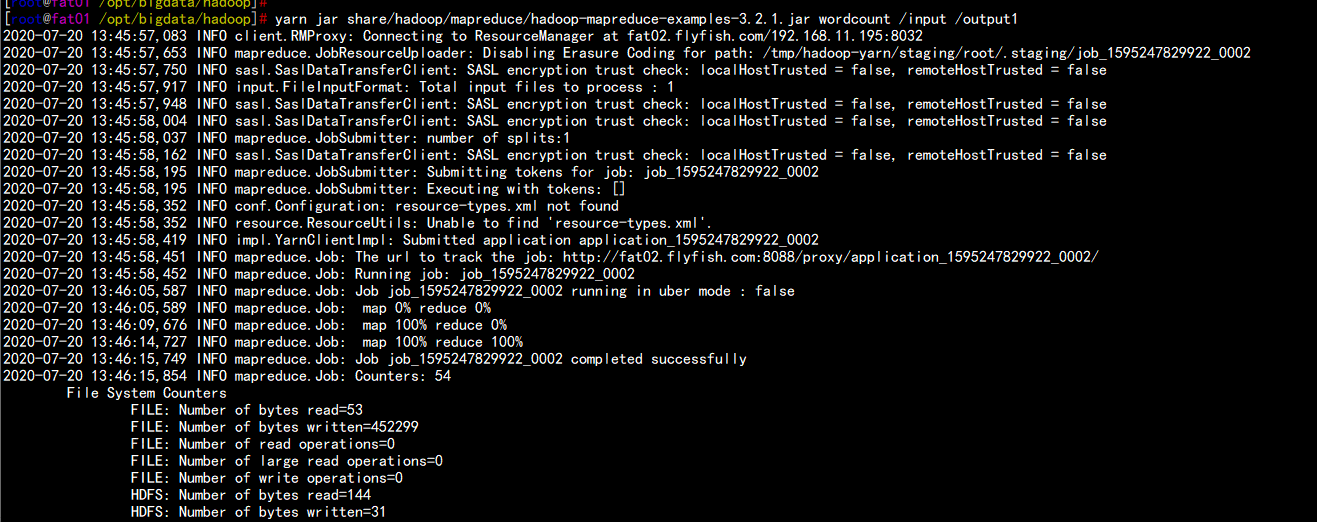
cd /opt/bigdata/hadoopbin/hdfs dfs -mkdir /inputbin/hdfs dfs -put word.txt /inputbin/yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount /input /output1
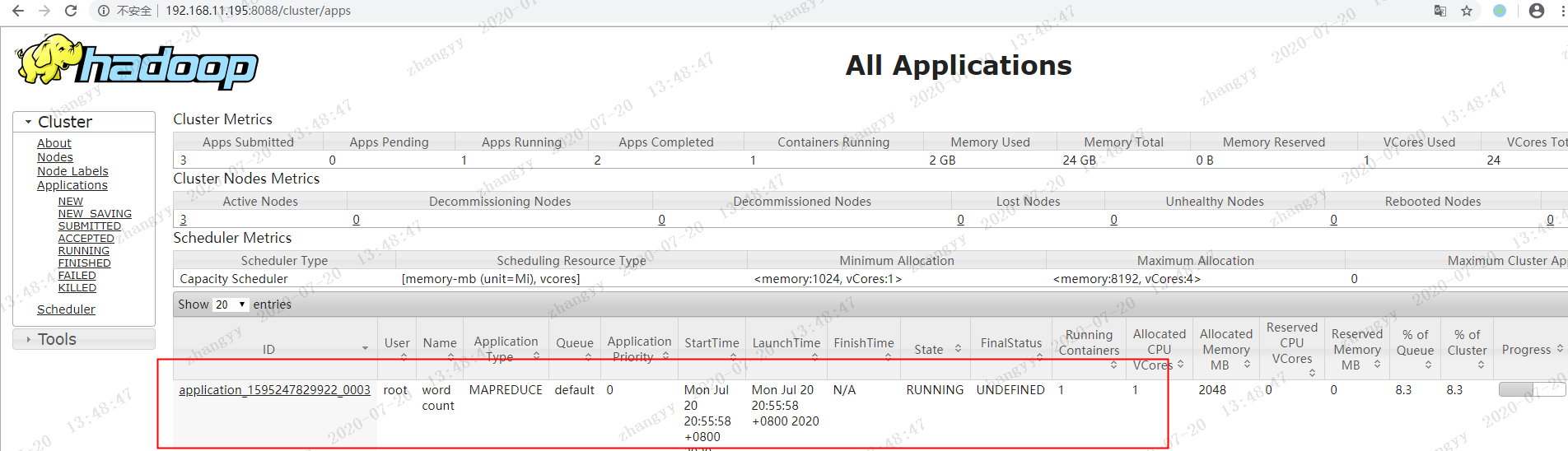
hdfs dfs -ls /inputhdfs dfs -cat /output1/part-r-00000