@gaoxiaoyunwei2017
2018-01-02T06:44:51.000000Z
字数 7820
阅读 1690
DevOps道法术器及全开源端到端部署流水线
毕宏飞
作者简介
赵舜东
昵称:“赵班长”,速云科技CEO;曾在武警某部负责指挥自动化的架构和运维工作
,国内首批Exin DevOps Master授权讲师、中国SaltStack用户组发起人、运维社区
创始人、DevOps学院创始人;著有《SaltStack入门与实践》、《运维知识体系》、
《缓存知识体系》;2008年退役后一直从事互联网运维工作,历任运维工程师、运
维经理、运维架构师、运维总监。现创业专注于企业DevOps运维服务和在线教育。
前言
我们今天分享的主题是叫 DevOps 道法术器以及全开源端到端的流水线。我上小学是班长,初中是班长,在部队是班长,后来做别的也是班长,所以大家都叫我班长,我也就把之前非主流的名称改成了赵班长。现在自己创业了,做 DevOps 运营服务和在线教育这块。
今天我们的分享主要从以下4个点来分享:
1、DevOps的道法术器
2、如何构建一个真正的DevOps平台
3、全开源端到端部署流水线
4、全开源全链路自动化运维体系
一、DevOps的道法术器
1.1 DevOps是什么
首先我们分享的是 DevOps 道法术器,现在越来越多的企业在学习 DevOps ,既然学习我们就要成体系,要搞明白 DevOps 整体的概念,从更高的纬度来看待 DevOps 。从能搜索到的文章来看几乎有一半的人误解了 DevOps ,首先 DevOps 是开发和运维的缩写,很多人就会被一些其他的机构引偏了。很多人说 DevOps 是让开发做运维,这是瞎扯;还有人说是 DevOps 是让运维写代码,那是培训机构为了让你花钱去培训,所以才这么告诉你的。还有人说班长你有没有看过《SRE运维实践》怎么说的,谷歌说的是用软件工程的思路做运维,不是让开发做运维,只不过人家叫了SRE这个职位,就是按软件研发工程师来招聘的,也不是让研发来做运维。
我们来看一下 DevOps 是一组最佳实践,强调IT专业人员在应用和服务生命周期中的协作和沟通。服务的生命周期我们做运维可能比较熟悉,就是IT服务管理一条服务流程, DevOps 关注这两个生命周期,还关注我们这些专业人员在这两个生命周期中的沟通和协作。

DevOps 这个概念大概是2008年提出的,我们在2010年的时候提出类似的概念,和这个完全没有关系,我们提出了叫做面向运维的开发,那个年代什么测试驱动开发已经很火热了,我们说的是面向运维的开发。当时我去给研发洗脑,我就问写代码为了干什么?没有人敢回答。我说写代码是为了上线运行,没有人反驳。我说既然是这样,是不是要按照上线运行的方式来写呢?也没有人反驳,然后他们就这样就被洗脑了,因此就要按照上线运行的方式来写。我们老板是比较专业的,他说未来我们的所有的项目经理记住一个指标,这个项目的可运维性,这个项目开发完了是要上线运行的,能不能做监控,能不能做防控,安全层面怎么考虑的?最早我们有一个项目用户中心上线,我们讨论技术框架选型,研发说要用RPC框架比较快,另外一部分人说用PTC标准的。最后只能PK,RPC的这个最后肯定是要出错的。所以当时这个项目就不具备可运维性,最终这个项目下线了。当时我们讨论要不然就自己搞一个RPC的框架,在框架里面实现所有的功能,要不然就老老实实的基于RPD协议。当时我们所有项目经理开会,要求他们一定要有运维的需求,如果运维需求不提出来是不能开这个评审会的,因为需求是不完整的。 DevOps 强调的是合作以及交付和整个基础设施变更的自动化,从而实现持续集成、持续部署和持续交付。 DevOps 目前是双态IT的实现之道,所以说 DevOps 并不是开发和运维之间的简单暧昧。
那 DevOps 是什么呢?你现在可以理解它是一组最佳实践,它还是一种文化。 DevOps 是2008年提出来,2009年有 DevOps 支付,就发起了 DevOpsDays 的活动。 DevOps 专家工资比开发者要高出38%,所以学习 DevOps 可以实现弯道超车。
1.2 DevOps 道法术器
1.2.1 道
DevOps 的道法术器,这个道指的是什么?指的是总括性的原则,我们讲 DevOps 是快速交付价值,灵活响应变化。我们在日常的项目交付,一个功能只要上线才能产生价值,上线用户使用到了你这个才能产生价值。之前我们的研发和运维,研发写代码,然后搞一个交接文档,再打一个包,告诉运维你自己做吧,运维打开文档看,按照文档操作一遍发现不好使,然后运维和研发之间开始PK,一般运维都会输。但是谁最关心价值?老板。所以我经常说越关心用户的人往往离用户最远,因为他离用户有这么长的职能链条。现在很多企业来学习 DevOps ,就是 DevOps 可以缩短前置时间,这个需求从提出到上线的时间,灵活响应变化。
1.2.2 法
法就是全局打通敏捷开发相关标准,以后我们就靠这种标准,以前干事情没有标准,现在有标准了,怎么去做这个研发与运营一体化能力成熟度模型?
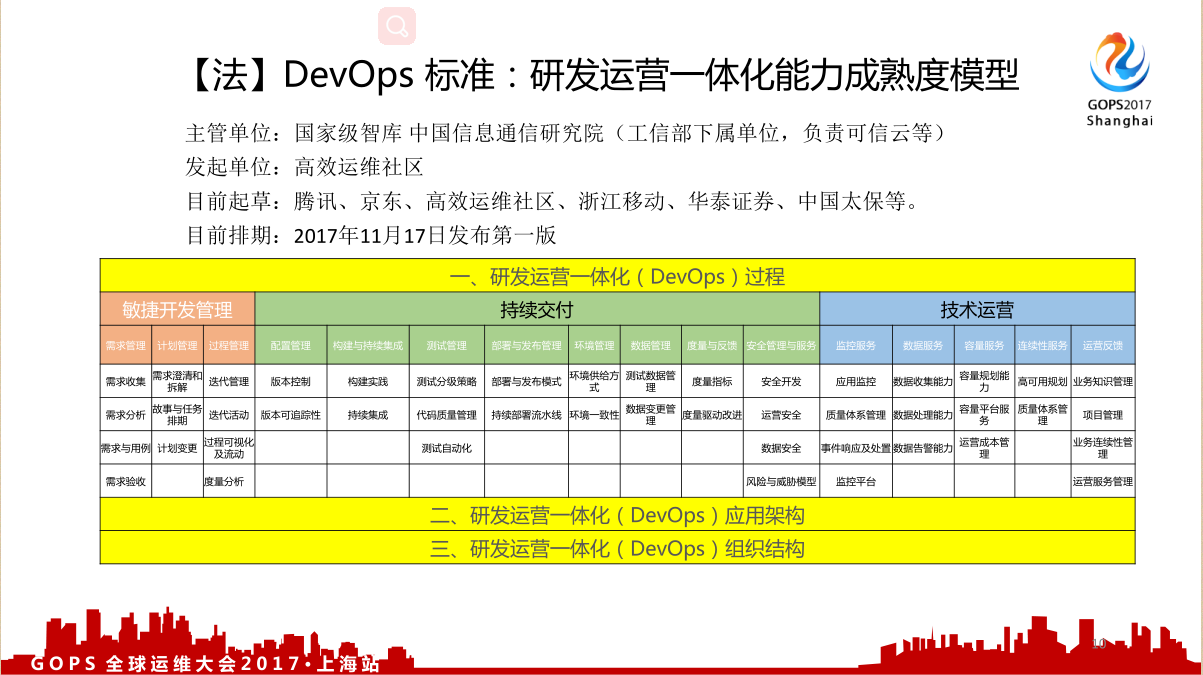
因为最早还没有这个模型,比如你到一家企业说班长你看这个 DevOps 做的怎么样,现在有 DevOps 自己的能力成熟度模型了,就可以对照来参考了。
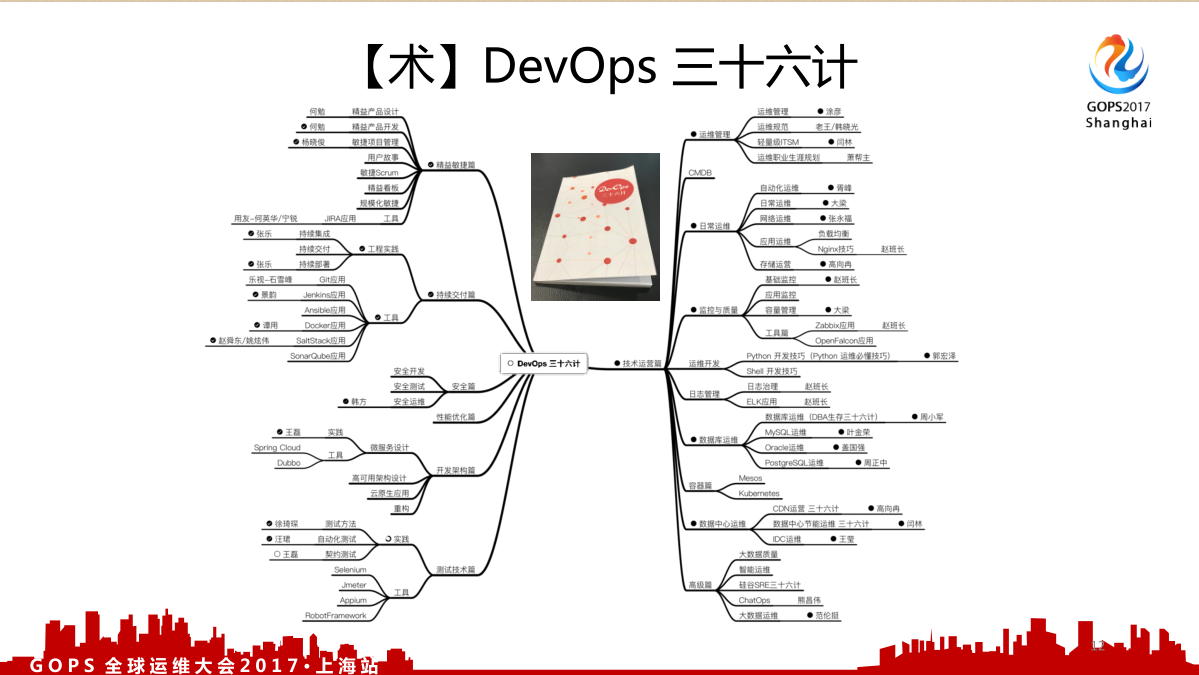
1.2.3 术
“术”就是事件的一些方式和指导原则,就是 DevOps 三十六计。这个 DevOps 三十六计基本上涵盖了各大公司在不同的,包括工具实践、精益敏捷、持续交付等等他们一些经验的分享。
1.2.4 器
“器”主要是讲全开源端到端部署流水线1.0版,在19日那个大会会发布V2.0。2.0相对来说就更全面一些,包括工具链的选择上也选择了一些更流行的工具链做一些调整,整个工具链也是基于一个施展项目来构建的持续交付的流水线。
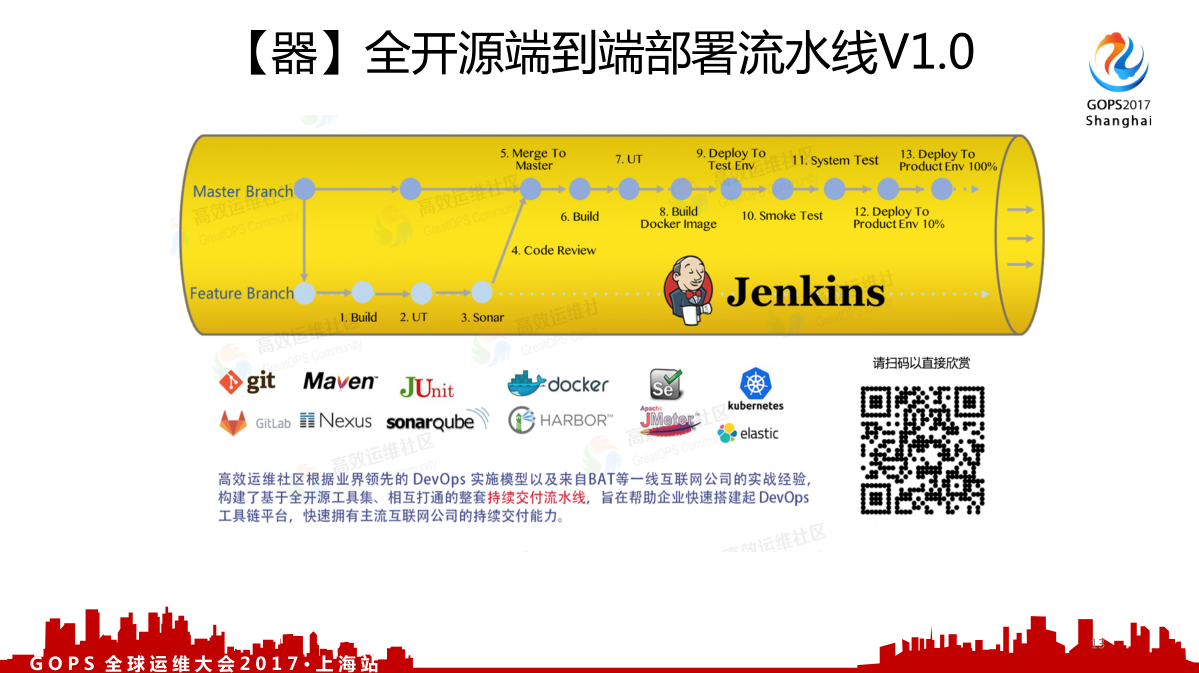
很多人看到这个就会说班长你上面画的东西我们都会,这些我们全部都用,我说你们串起来了吗?这就相当于英文字母全都会读,但是单词不认识。
二、如何构建一个真正的DevOps平台
接下来分享我们如何构建一个真正的 DevOps 平台,这个之前分享过,为什么还要再分享一遍呢?因为经常会有人在QQ群发,班长你看我们做的 DevOps 平台,我花了一个星期学的,做了一个管理界面,然后用百度画了一个特别漂亮的图,上个月我涨了五千块钱的工资。去年到今年 DevOps 火的时候有很多的这样对应的工程师的工资有点虚高。我问他 DevOps 是什么?他说不就是运维和开发嘛,我说不是。一个真正的 DevOps 平台应该具备四大基本模块,实际模块可能还要比这个多。
2.1 DevOps 平台四大模块
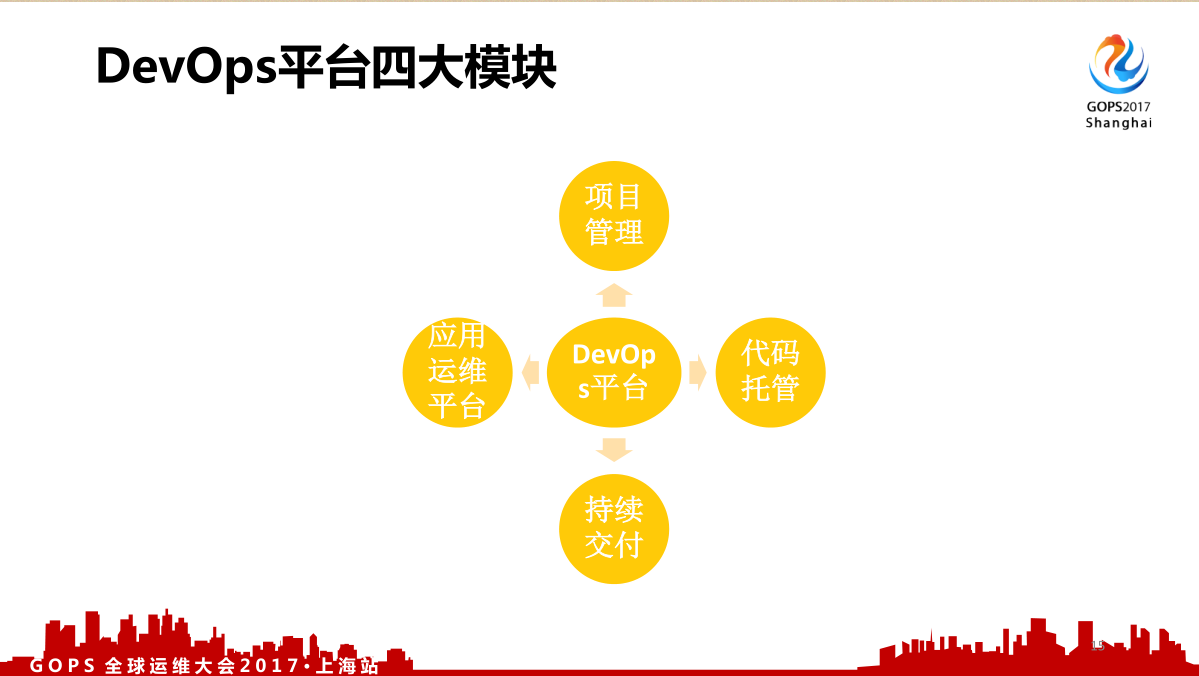
- 项目管理, DevOps 是干吗的? DevOps 是关注、应用和服务生命周期的协作,整个 DevOps 平台要包含应用生命周期的管理,以及服务生命周期的管理。应用生命周期的管理第一个就是项目管理,我在你这个平台上先创建一个项目,项目需求管理、Bug等等这些管理。
- 代码托管,写代码是不是需要代码托管,我要代码仓库,要做提交,还要做分支等等,你需要有这样一个代码托管平台。
- 持续交付,我写完代码要提交,能不能帮我做自动化的部署,做代码的评审,那就是持续交付平台。
- 应用运维平台,为什么加上叫应用运维平台?因为现在越来越多公司把基础设施这块划分为单独的部门,很多公司做的变革是这样的,把应用运维或者说业务运维拆到各个业务线上去。运维部还在,运维部做基础设施,或者做的好一点就是做PASS平台。很多时候你做着做着就会发现你在做一个自己的内部小运维,未来在这个上面就是买对应的产品和对应的服务。
我认为一个完整的 DevOps 平台是这样的,它应该是一个圈,能形成一个闭环。我们做IT很多时候如果能和自己身边的东西结合起来,你就发现能找到别的一些思路。我记得有一句话,你要成为一个计算机专家,首先你得是一个数学家,其次你得是一个哲学家,然后你才能成为一个计算机专家,因为计算机的体系结构就是从哲学原理演化而来的。
2.2 四大模块对应的开源工具
DevOps 平台四大模块每一个我都列比较常用的工具:
项目管理目前比较流行的一个是 Jira ,一个是 Redmine ,而且现在 Jira 和 Redmine 都有一些插件性的工具。
代码托管基本上是 Gitlab 的占比在50%以上,还有就是SVN。 Gitlab 的相关功能,就是在按照我刚才说的 DevOps 平台在做,首先是项目管理, Gitlab 可以做简单的需求管理。第二个是代码托管,第三个是持续交付, Gitlab 可以做持续交付流水线。运维方面 Gitlab 现在好象也出了对应监控的东西,所以研究完 Gitlab 之后发现他们野心很大,他们想把整个 DevOps 的产品线全部做下来。
持续交付平台目前有两个主流的:Jenkins 、Gitlab 。
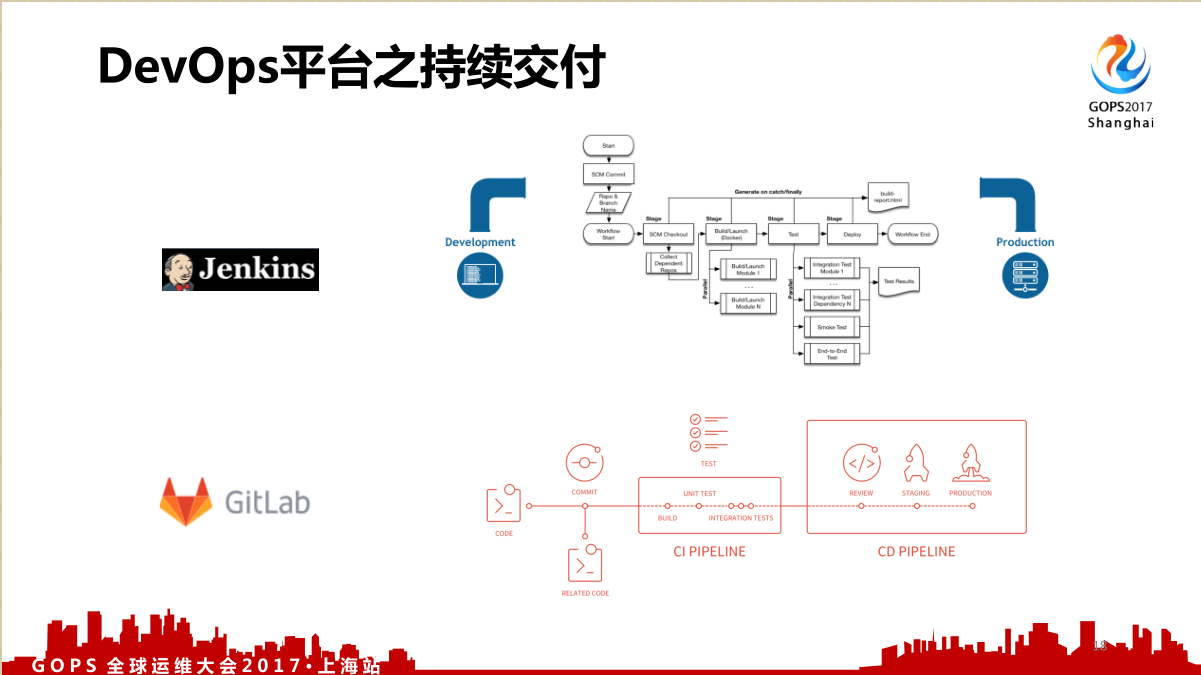
对于一些中小企业,比如我们就十个人, Gitlab 就适合你,不要搞那些复杂的项目管理,最简单的需求管理,用 Gitlab 做就可以了,这是我的建议。如果你真的是在50人以内的研发团队,我觉得一个 Gitlab 就可以搞定一切,这个也比较省事。
2.3 开源的运维平台
开源的运维平台腾讯蓝鲸算一个,我拿一个之前做过的运维平台简单说一下。
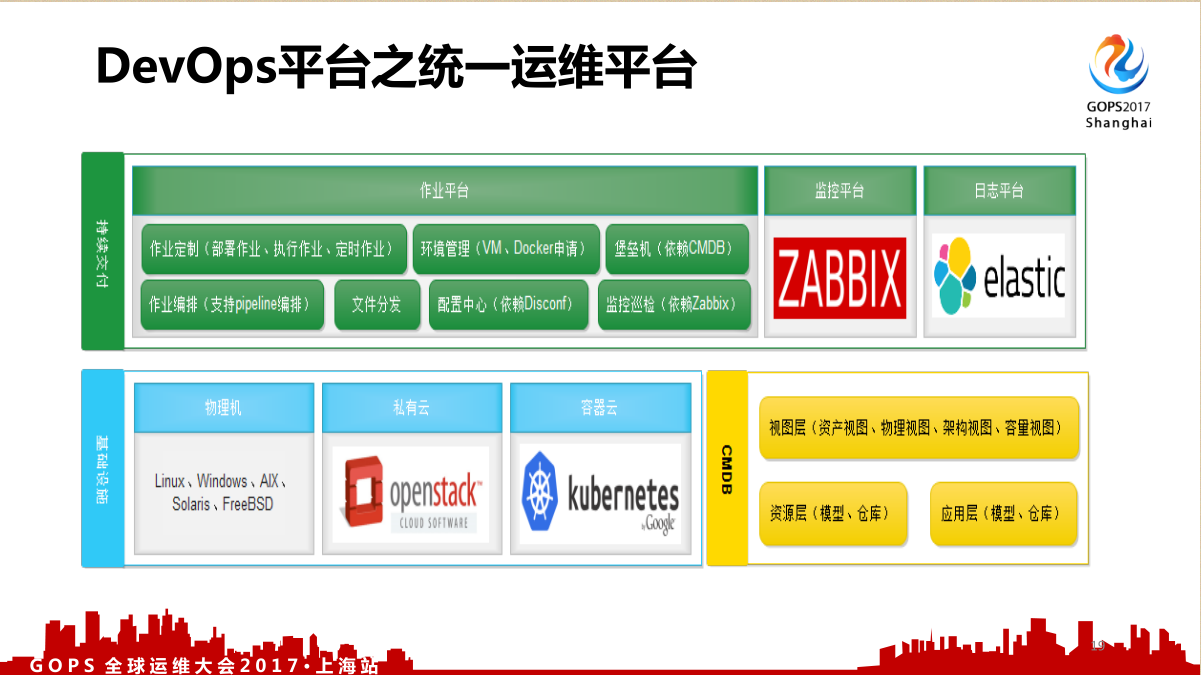
运维平台可能包含着基础设施这一块,从物理机的管理,到虚拟机的管理,然后到容器的管理。CMDB 分为视图层,资源层、应用层,这样你的关系链就比较容易梳理。视图层就可以基于资产、物理、容量、业务和应用做各种各样的试图展示,因为在整个资产管理里面所有的关系本身就是图。我就不用图,那个我懂,但是你到业界看看,那些很牛的产品有几个能成功的?没有,那个太复杂了。所以说现在业界需要一个更简单的 CMDB ,你能非常清晰的把整个资源应用视图管理起来就可以了。
怎么评价一个 CMDB 好不好?这个应用和其他应用之间有没有耦合关系,是松的还是紧的耦合?有就认为它做的很好,但是好象业界 CMDB 都实现不了这个。当时我和厂商PK,我说我不是你们竞争对手,我是做运维的,我最基本的需求你们都实现不了。再一个就是你 CMDB 能否跟报警系统关联起来,我遇到过凌晨我团队的值班人员来电话说出大事了。
我:怎么了?
他:我们那个证书过期了,晚上量还挺大的。
我:资产系统有没有?
他:有。
我:有没有报警?
他:没有。
我当时就说你在做 CMDB 资产管理的时候,能不能和报警关联起来?这个证书是明显有过期时间的,这样的过期时间为什么不和监控关联起来?如果不能,你这个 CMDB 就是做的不好。
还有一个就是作业平台,当时也面临很大的问题,当时有什么需求呢?有一天晚上有一个打补丁,晚上有很多定时任务,都要去查这个任务,那就面临一个问题,晚上我是零点到四点要停机,所有定时任务基本疯了,打开一看一百多行,我要找到零点到三点哪些连接到我这个数据里面。基于上面说的那些需求就要做作业平台,包括部署作业、执行作业、定时作业。还有把部署的那一块也要做在上面,还包括环境管理、堡垒机、作业编排、文件分发等等。
现在业界有没有做的比较好的 DevOps 平台?我们就拿BAT来说:百度有百度效率云,但是这个里面没有运营管理;阿里他们有云效平台,但是云效平台好象也没有运维,但是阿里云里面好象有运维这方面的功能,包括阿里云那个项目管理,那个代码托管好象是 Gitlab ,他们跟 Gitlab 官方是合作的;腾讯有蓝鲸和织云,包含了项目管理、TBD、代码托管、持续交付、运维,腾讯算是有了。当然还有其他的国内做的比较好的,像平安科技,招商他们都做的比较好。
三、全开源端到端部署流水线
软件交付的原则,这个主要来自于持续交付那本书本。
一、为软件发布创建一个可重复且可靠的过程,要记住三个字,可重复。你这个过程一定要是可重复的,不能说每一个项目过来都是一套单独的;
二、将几乎所有的事情自动化;
三、将所有的东西都纳入到版本控制;
四、提前并频繁地做让你感到痛苦的事情,你频繁的做就不会觉得痛苦了;
五、内建质量;
六、"DONE"意味着"已发布";
七、交付过程是每一个成员的责任;
八、持续改进。
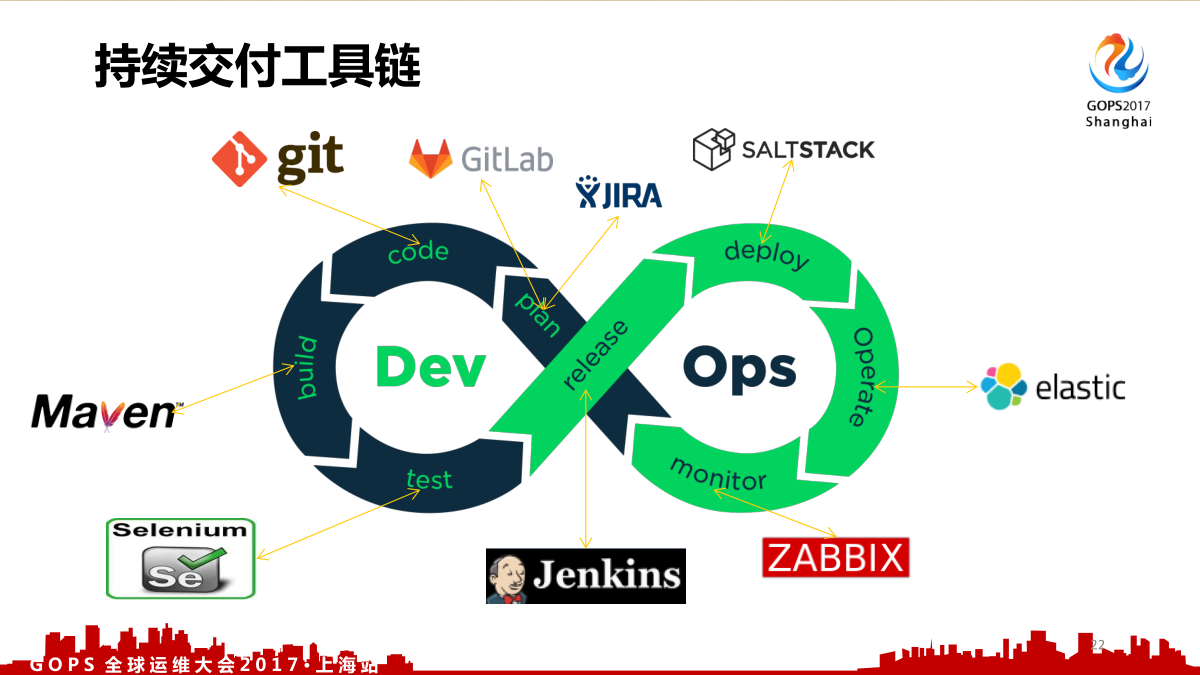
这个是持续交付环,大家经常会看到这张图。这个持续交付环从计划、编码、构建、测试、发布、部署、运维、监控,它是一个环状的,大家明白发布和部署的区别吧?部署只是一个动作。
我们经常说现在做软件设计的要落后于工业一百年,来看一下这是福特汽车在1910年的时候,他们做了一个汽车组装的流水线,之前组装一辆汽车需要12.5小时,使用这个流水线变成了93分钟。所以落后工业至少一百年,一百年前人家就这么玩了,DevOps 从2015年在中国火之后,这两年的趋势是非常快速的上涨。

软件交付流水线是指软件变更从提交到版本控制库,到发布给用户的整个过程,这个是流水线来做的,而不是手工。软件的每次变更都会经历一个复杂的流程才能发布,这个流程包括构建软件、一系列不同阶段的测试与部署等,需要多团队协作完成。交付流水线对交付流程进行了建模,并支持查看,控制整个交付流程。
3.1 持续交付流水线
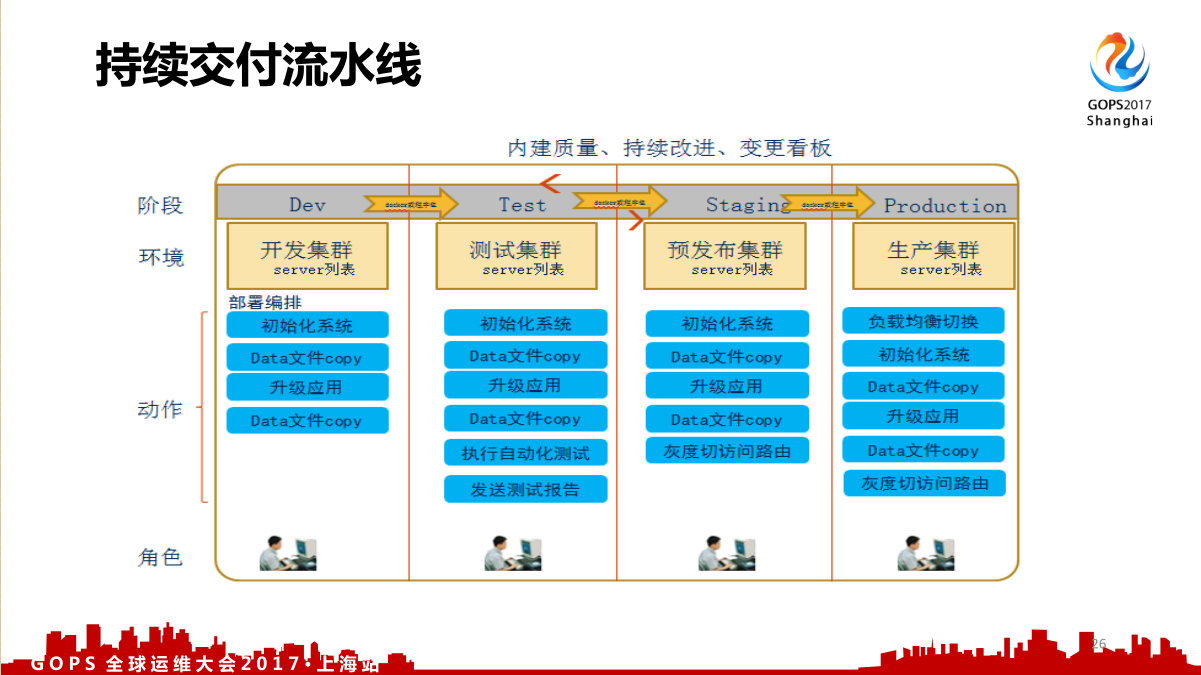
整个持续交付流水线也是要分环境的,比如从开发、测试、预发布、生产,或者叫预生产,也可以叫预热。预热一定要是生产环境,预生产环境就是把生产环境集群的某一个节点拿出来,用户访问不到但我们自己能访问,然后做内部测试,这个叫做预生产环境。我看到很多企业不这么干,他的预生产环境还是测试环境,并没有连生产的数据库。我说你这个不叫预生产,然后他不信,最后就有了 Test1 环境,一直到 Test5 环境,因为老发现它不是生产,这个预生产不停的重建,一直就达不到预生产的条件,我说你就老老实实的把生产一部分的东西拿出来做生产测试。
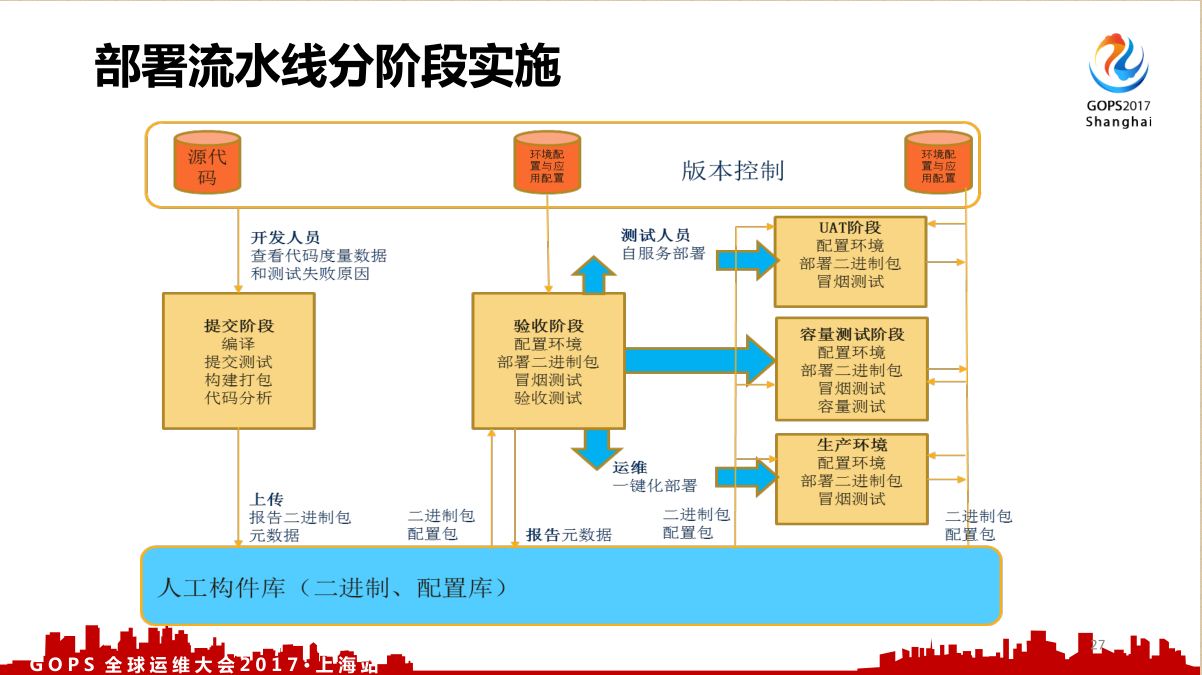
部署流水线这张图是从持续交付那本书来的,这本书出的比较早写的也比较好,讲的是部署流水线分阶段实施,我们要把整个流水线分阶段。比如说提交阶段,有编译、测试、打包、分析,再接着验收阶段,还有UAT就是用户体验测试,容量测试和生产环境。很多的企业是没有容量测试的,不是所有的环境都要有。之前我看到有一个人分享他们的自动化扩容,我就偷偷问他,你们有做容量测试码?没有,我们测试的一塌糊涂。我说你逗我呢,你都没做过容量测试,你这个扩容怎么来的?你怎么知道这个压力扛不住了?我说你那套流程是为了让它实现自动化而自动化,根本就没有数据没有指标。我得搞明白我这套服务到底能支持多少的QPS,这个要测试。
这个是一套可靠可重复的流水线,从编译和单测、模块测试、系统测试、预上线、生产灰度到生产全量。

这个里面是有人工干预的,有人就问我你们那边怎么不自动?我说这个能实现,而且能上线,有些业务确实可以这么干。但是大多数业务是要人工干预,比如有的上线要审批,或者变更要时间窗口才能做变更,你得有一个人工干预。但是我又说了,从代码到上线,你可以不这么干,但是你要具备这个能力。如果让你这么干,你当前的流水线、工具能不能实现这样的?你具备不具备这个能力,和你用不用是两回事。所以你会发现很多东西到企业落地的时候,会有很多的变化,只要不打破整个流水线的原则,我们都认为是合理的。但是有一些流程可能是需要改的,我见过一个流程,告诉我说班长我们这个规模特别大,现在同一分钟有一千个项目在建立,我说这个集群就大了去了。当时我就在想各种方案,后来我知道为什么了。比如所有的项目都在下午六点的时候去点,因为着急下班,我说你这个光通过技术没有办法解决,最好改一改流程。平时都闲着,不允许用,一到六点都来做,就是买了最高级的 DevOps 也不能完全解决这个问题,未来你要有两千个项目怎么办?除非说你到了BAT那个级别了,你真的可以花大价钱花成本去做这个东西了。
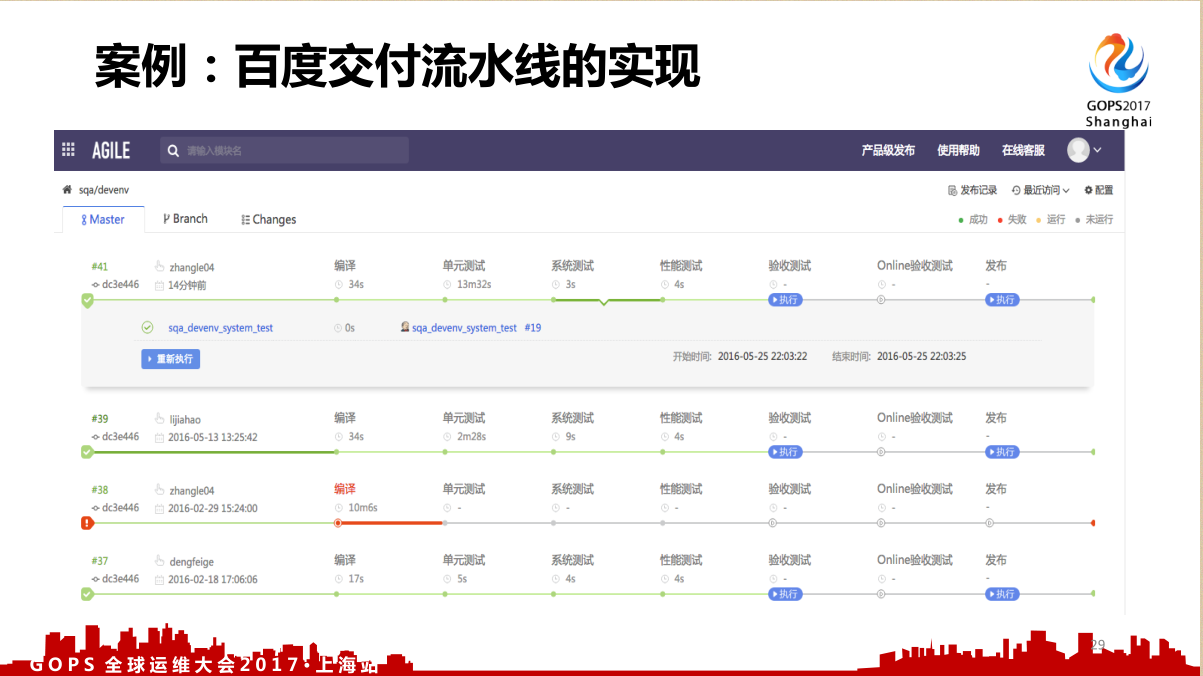
这是百度交付流水线的案例,首先是分阶段,编译、单元测试,并且会显示某个阶段用了多长时间,也会显示是谁提交的,什么时候提交的,整个的流程都可以展示。
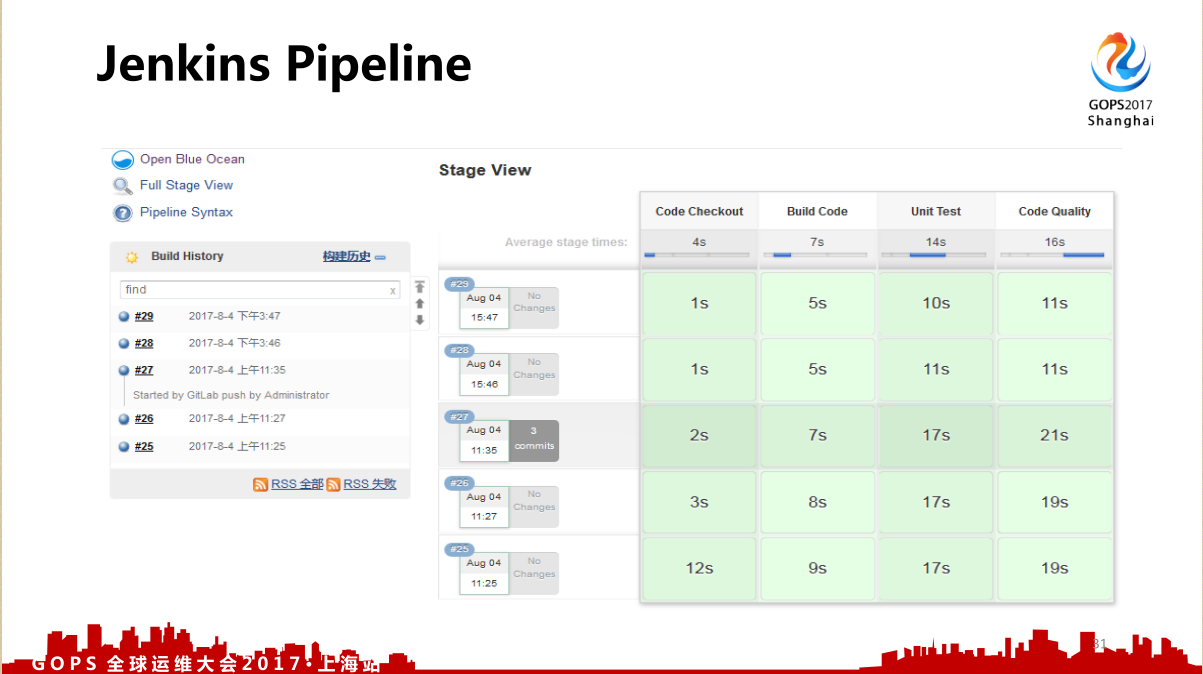
3.2 Jekins的Pipeline如何实现
现在 Jenkins 很火,那就是 Pipeline ,比如说这个 Pipeline 怎么实现的呢?
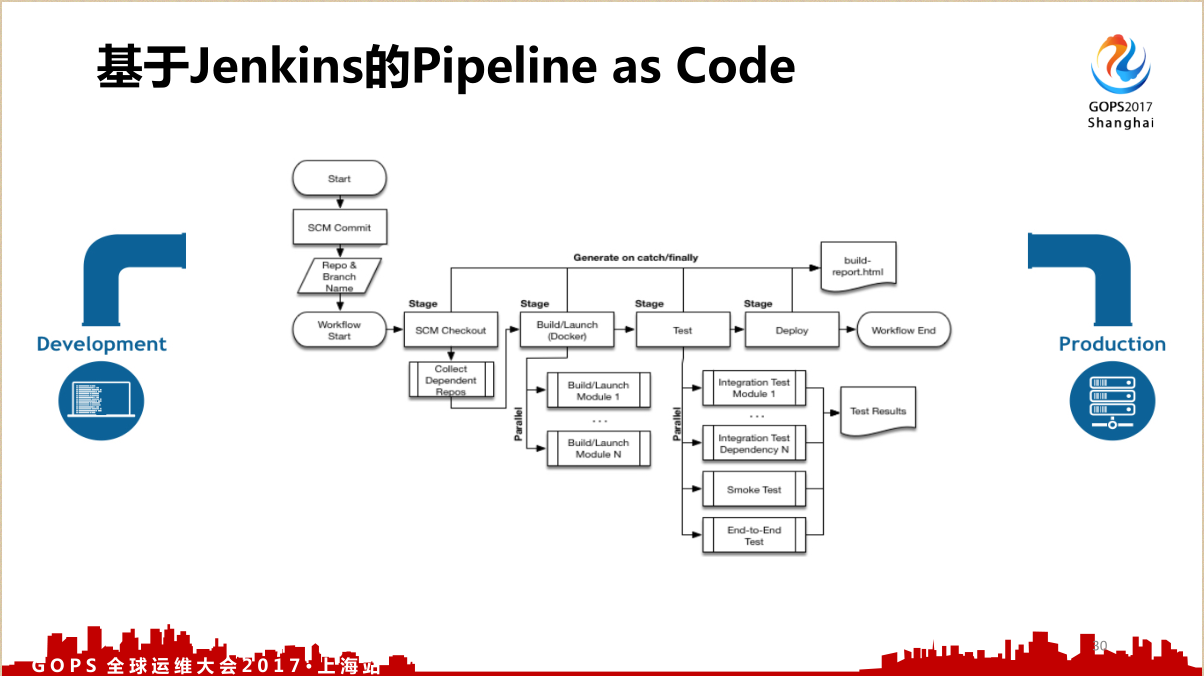
第一个是和 Gitlab 做集成,在 Gitlab 可以看到这次构建的状态,然后分为几个不同的步骤:代码检验,这个验证的ID就是 Jenkins 的ID,然后是拉代码, Jenkins 其实就是一个编排,一个非常简单的脚本,就可以实现这样的一个 Pipeline 的功能。
3.3 自动化流程设计
自动化部署的两个目标:一键部署,秒级回滚。一键部署无需运维参与,用户无感知;秒级回滚是故障处理原则,正常回滚和紧急回滚。很多时候我们不按照这个来,一上线有问题了:研发工程师来了说五分钟以后搞定,然后不行;项目经理过来说我来,五分钟就可以,然后五分钟以后还不行。最后问我,小赵怎么办(当时我还不叫赵班长)?我说30秒,因为我那个集群只有20几个节点,30秒所有紧急回滚,重启完毕。以后我再处理故障的时候,我们的CEO、董事长都在后面,就会问班长你要喝什么水,中午想吃什么我给你买,我呢则带一帮人在前面处理故障,这才是真正的老板。好的老板就是不要打扰别人干活,你把饭买好就可以了,故障你又解决不了。
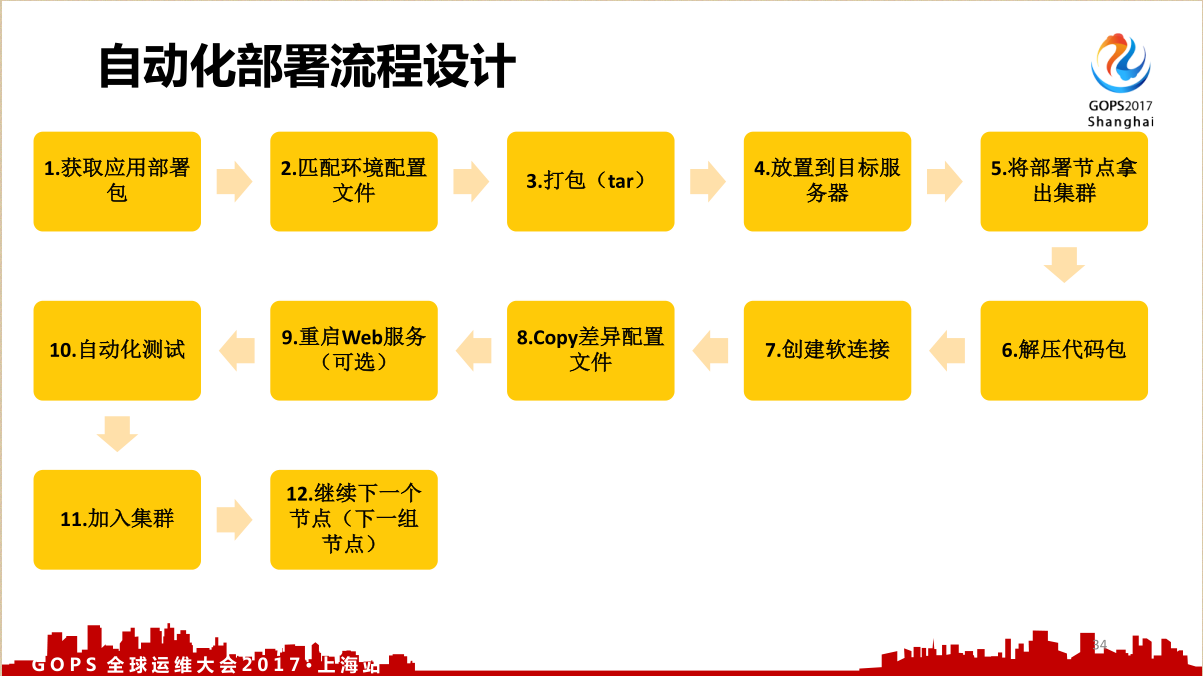
这是自动化流程的设计,最核心的点是两个:
- 通过软连接的方式做整包部署,整个自动化部署的一个奥妙全在这里;
- 将部署节点拿出集群,这个检查是有时间间隔的。正常部署某一个节点,是应该把这个节点先拿出这个集群,部署好了最后再用上去。
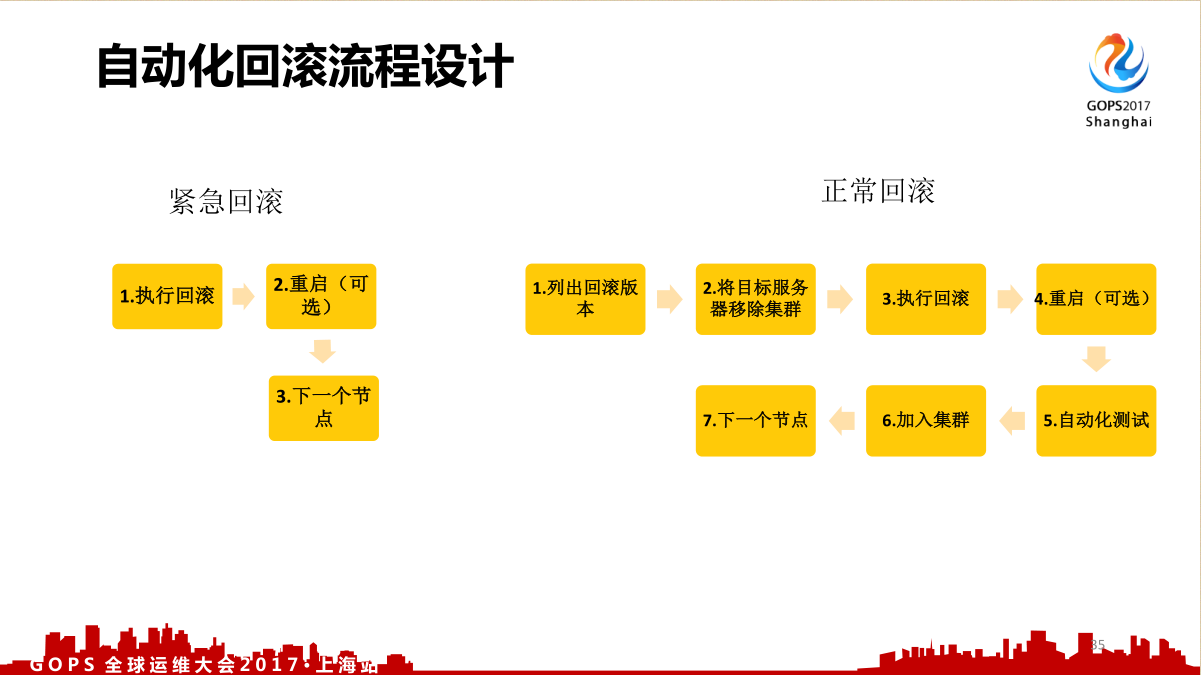
自动化回滚这个就简单了,无非就是删除软连接,重新创建上一个版本的软连接,需要重启就重启,如果不需要重启就完事了。
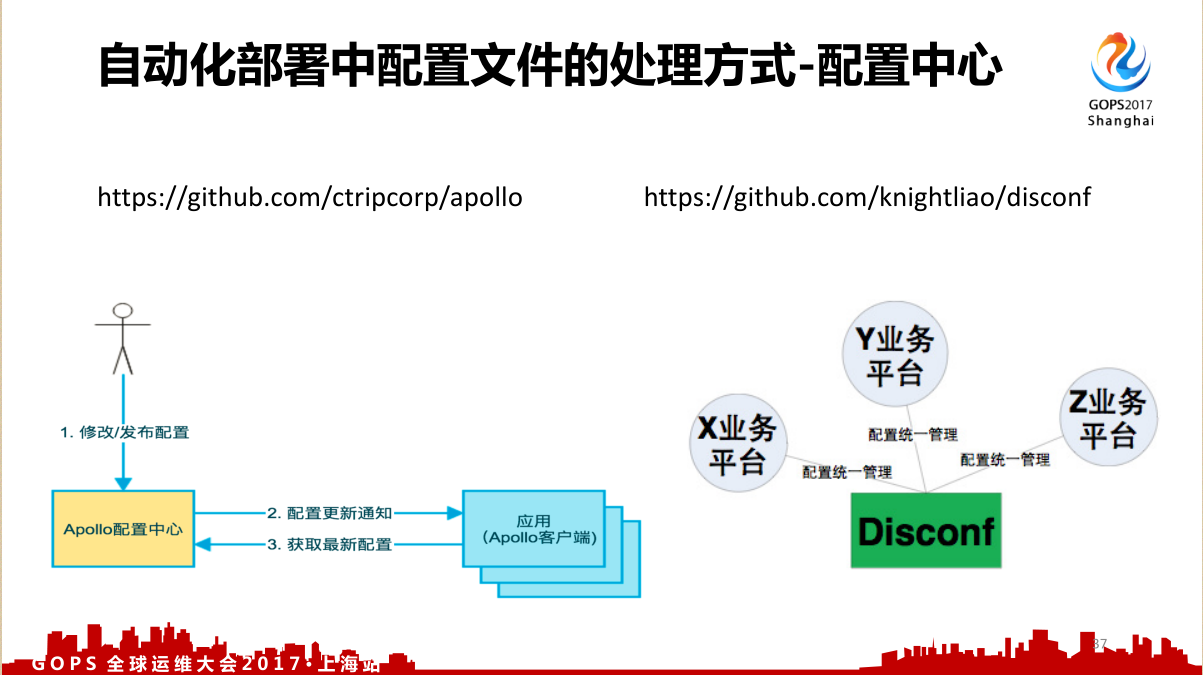
3.4 配置文件处理
每次线下都有人问我配置文件的处理这个问题,我们做自动化部署的时候, DevOps 的要求是一个部署就要部署掉所有的环节。
第一个是一个配置文件对应多套环境,最早写P2P的时候大家就知道,启动的时候传一个参数就是用哪一个配置文件来启,这种的适合小项目。
第二个是多个配置文件对应多套环境,这个就涉及到在做部署的时候你要知道当前是生产还是测试,然后把对应的配置文件拷贝过去,这个配置文件谁管呢?这个可能需要一个专门的配置管理工程师来管这个配置文件,就是这个配置文件的变更。
第三个是配置中心统一管理。现在大家做微服务可能对配置中心都比较熟,但是配置中心还得有人去变更。我列了两个现在比较流行的配置中心,一个是携程的阿波罗,一个是百度的 Disconf , Disconf 比较老了,携程这个比较好。
3.5 A/B测试与灰度发布
在发布的时候你还有两种,一种是A/B测试,一个是灰度发布。
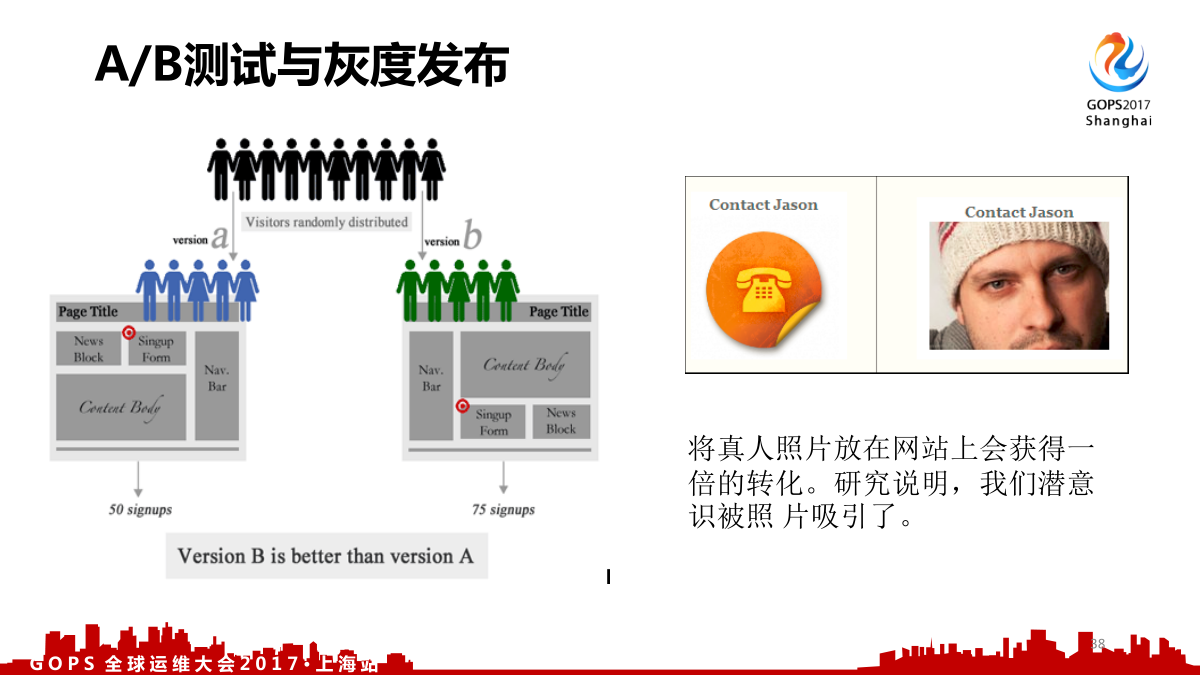
比如这两个你们喜欢哪一个?大部分人相比电话图标更喜欢这个人脸,因为不自觉的就被人脸所吸引了,这就是A/B测试,因为我们潜意识被这个照片吸引了。

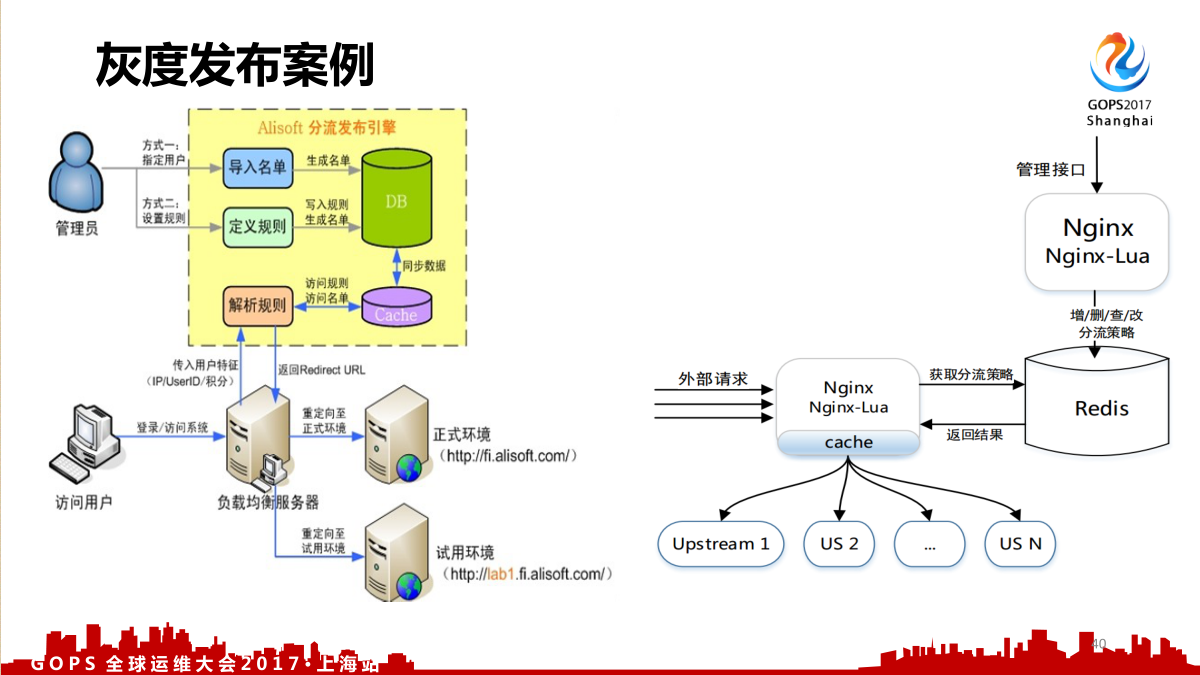
灰度发布就是让某一个产品发布逐步的扩大使用群体范围,灰度发布有很多的目标:可以提升产品升级影响用户范围;更早的获得用户反馈提升质量,大家QQ有没有经常收到一个框子,说让你下载一个新版本,可以及早的反馈问题;让用户参与产品测试,最后有互动。灰度发布的重点是不一样的。
下面这个是灰度发布的开源案例。
四、全链路自动化运维实践
这个是我之前做的全链路自动化运维的体系。
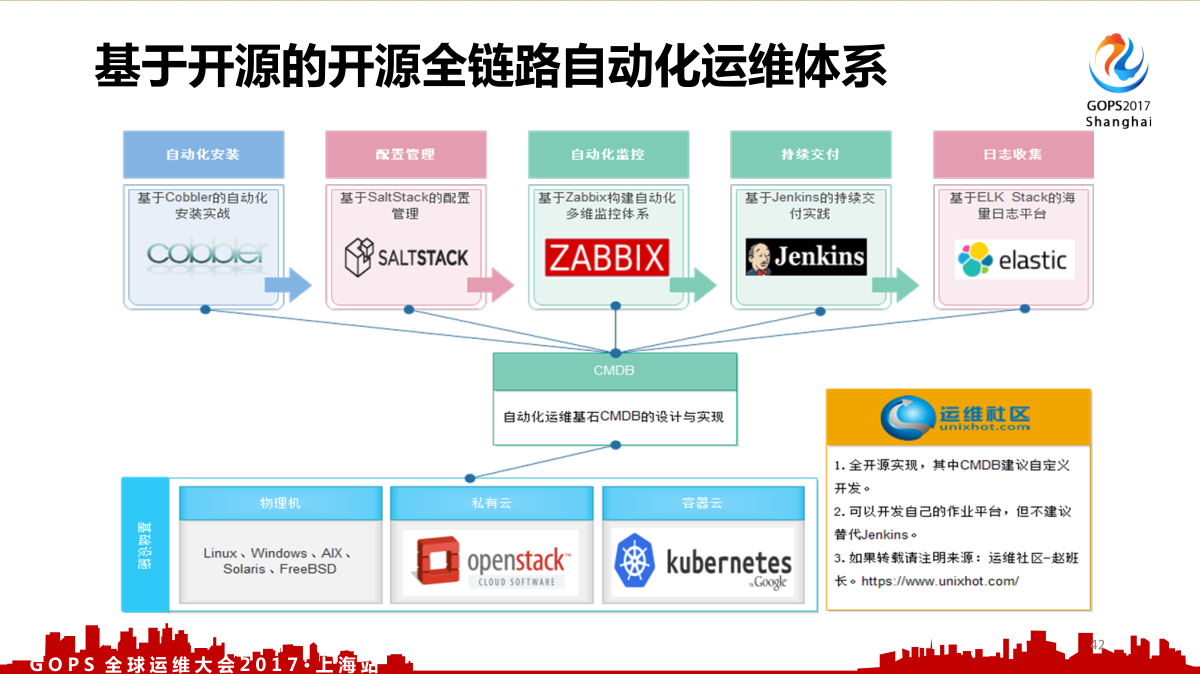
- 基于 Cobbler 的自动化安装施展
- 基于 Saltstack 的配置管理
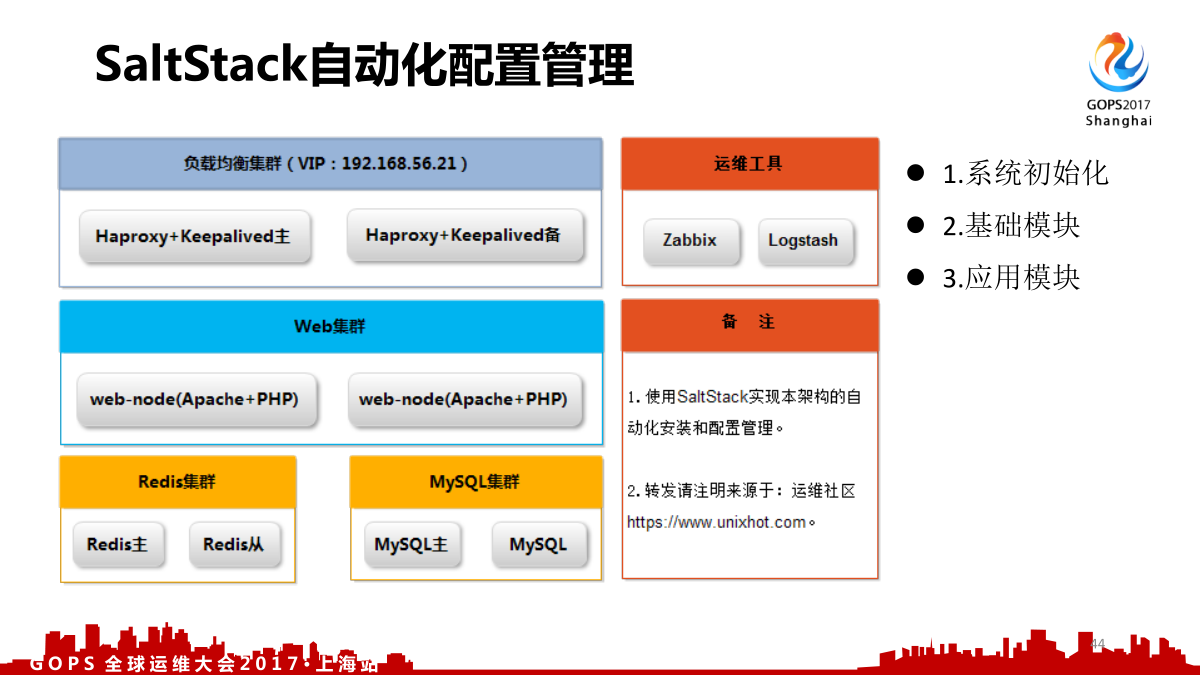
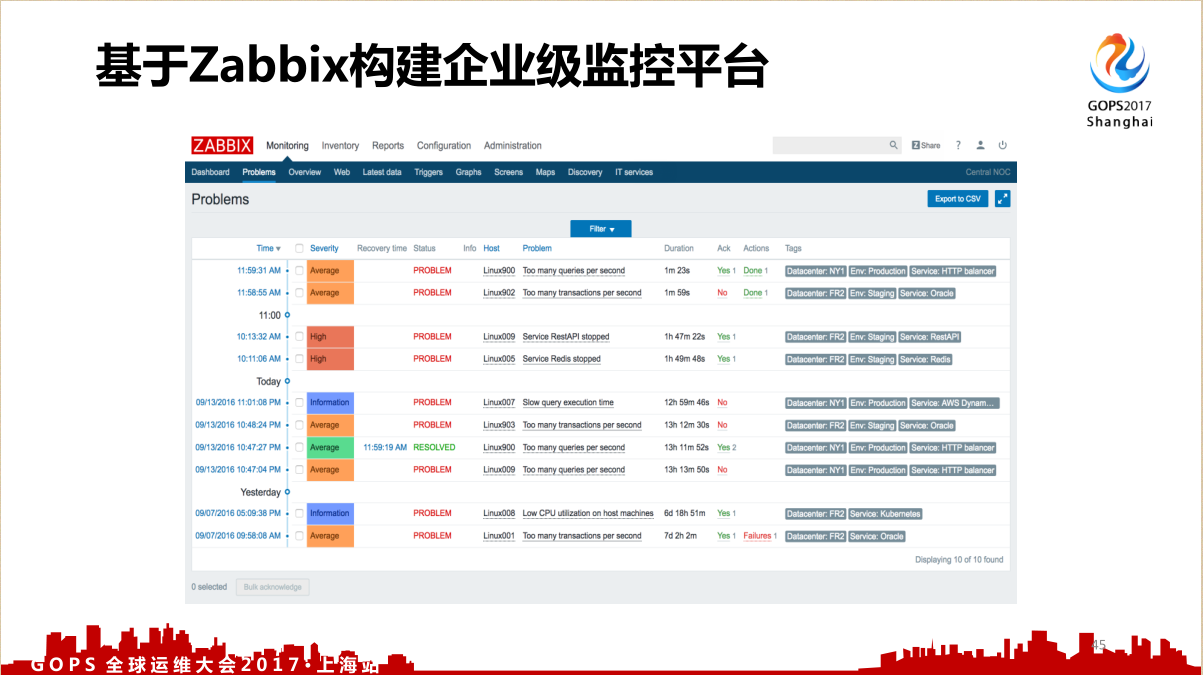
- 基于 Zabbix 构建自动化多纬监控体系
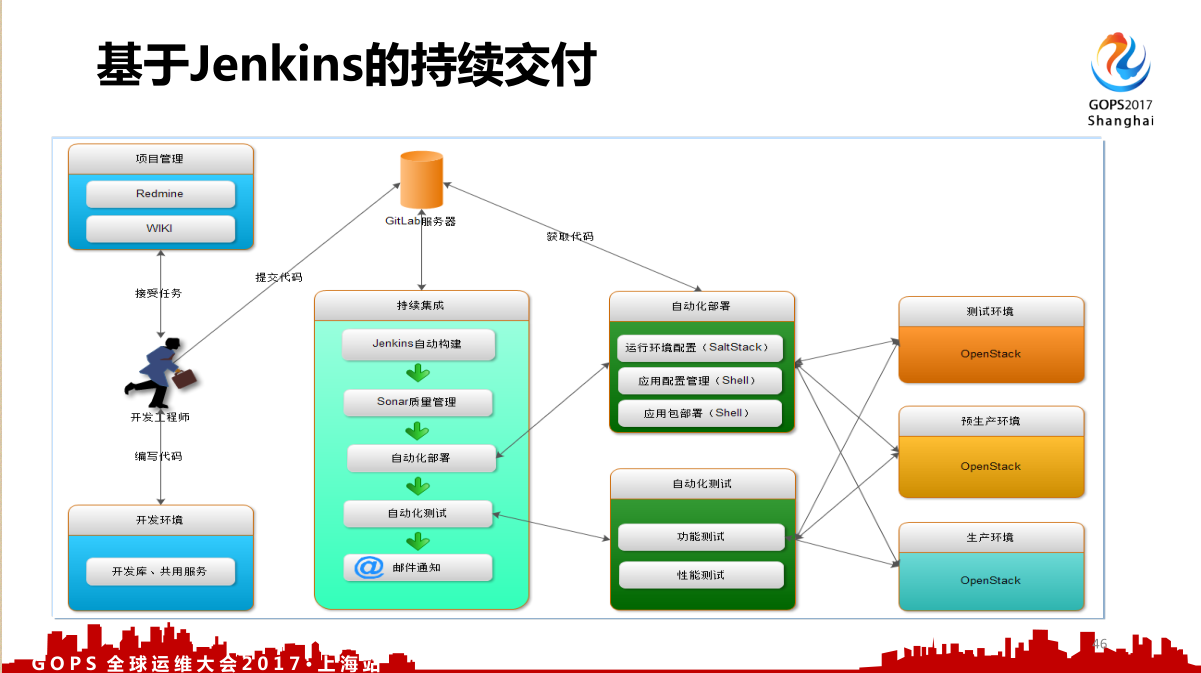
- 基于 Jenkins 的持续交付事件
- 基于 ELK Stack 的海量日志平台。

总结
我写了一个运维知识体系,我发现很多人学习不成体系,这个到时候可以直接去搜一下这个就可以了,这只是一部分。

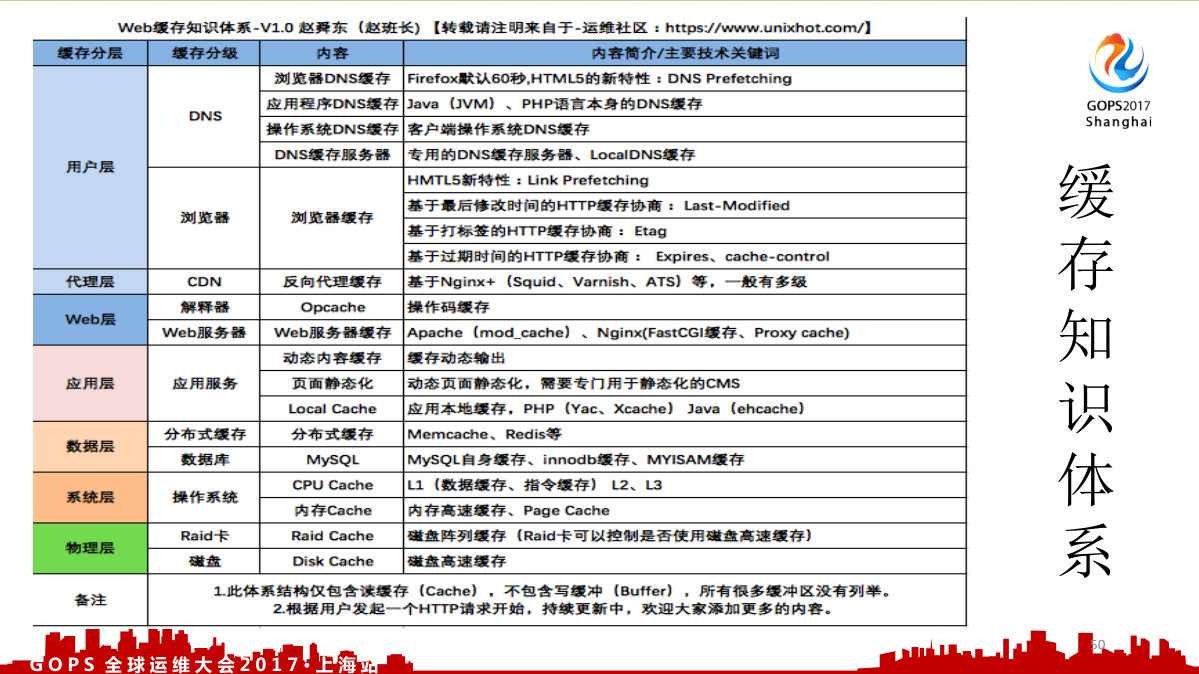
还有缓存的知识体系,我当时问各个工程师,一个请求一直到最后到底要经过哪些缓存?然后发现没有一个工程师能告诉我,甚至有一个工作十几年的也不知道。然后我们就开始召集人研究,看看到底要经过哪些缓存。