@gaoxiaoyunwei2017
2019-04-29T07:41:58.000000Z
字数 5155
阅读 1282
支撑数亿用户的小米服务可用性体系
白凡
分享:李博
编辑:白凡
讲师介绍:大家好,很高兴收到大会的邀请来这儿做分享。我分享的主题是小米的服务可用性体系。简单做一下自我介绍,我叫李博,从入行以后就一直做运维相关的工作,之前在百度负责大搜索的稳定性工作,现在服务小米,负责小米的服务可用性。

我的演讲分为四部分:
第一,服务可用性故障回顾;
第二,服务可用性面临的挑战;
第三,小米可用性服务体系;
第四,我们的实践。

1. 服务可用性故障回顾
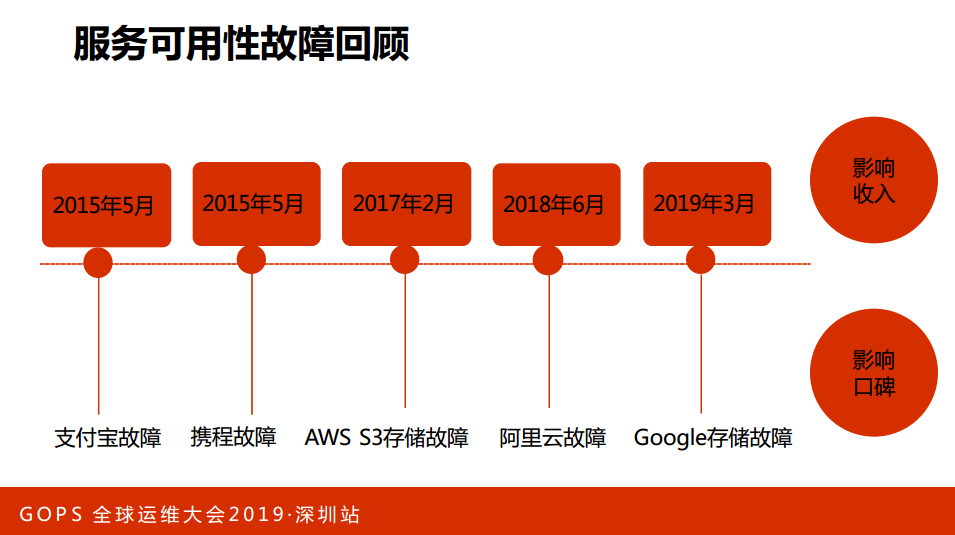
随着科技的发展,人们的生活越来越离不开互联网了,可以说互联网是无处不在。与此同时,互联网的故障对于人们的影响是非常大的。从2015年到现在列举了几个故障,我们看一下,2015年5月份支付宝的故障,当时支付宝光缆断了,导致人们数小时无法使用支付业务;
第二,携程的故障,携程的数据丢失,导致数十个小时无法访问。这两个事件导致中国服务可用性越来越重视,提升到了一个高度。
后面两个事故有一个共同点都是云厂商,现在好多业务都在上云,2017年2月份AWS S3储存故障,导致好多业务受到影响。
去年6月份阿里云有一个故障,影响了上千家的业务受影响。业内大牛Google,2019年3月份谷歌的存储有故障,导致他们的应用无法使用。故障,一是影响人们了使用;二是影响到公司的收入;三是口碑。
为什么讲口碑这件事情呢?比如说我的应用好用,那么大家肯定是一股脑地推荐,如果说不好用,大家说这个应用不好用,我不用了。口碑严重影响公司。波音的737MAX连出两次业务,全世界都轰动了。现在我出行的时候都看飞机的机型在订购机票。对于波音来讲,好多客户都觉得波音有这样的隐患,我未来采购可能会采购空客。
2. 服务可用性面临的挑战
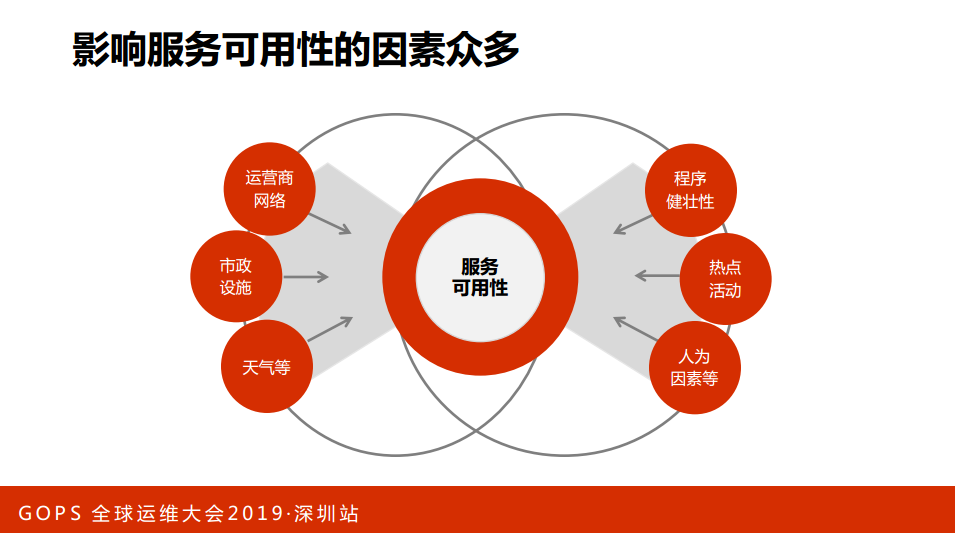
我介绍一下服务可用性面临的挑战。服务可用性是一个复杂的工程,分为两端:其中右端部分是内部的:
第一,程序的健壮性。比如说我们的代码很牛,容错很牛,那服务可用性好一些;如果代码写得不好,服务可用性低一些;
第二,热点的活动。比如说双11的活动,米粉节的活动,这些活动大量用户流量的到来会对我们服务稳定性产生隐患和影响;
第三,认为的因素。大家都是工程师,基本上在座都是工程师出身,人在工作中难免犯一些错误,比如说AM和RM。
人的因素是非常重要的一环,我刚才分析是内部的,内部的环节都需要进行管控,做好了内部是不是代表我们的服务可用性有所提升。不然的,我们看一下外部的部分:
第一,运营商的网络。比如说运营商做一些改造之类的,那很有可能会影响到我们的服务。
第二,市政设施。之前遇到过一次,我们机房突然间掉链了,然后就开启了各种各样的共赢模式,有一段时间电力没有跟上,后来开始温空调什么的。
第三,天气。天气我也遇到过一次例子,有一次是大西洋的飓风影响到我们美国泡泡店,导致我们美国泡泡店出现故障。我们内部做好了,那么外部一定要做好,这是影响不稳定性的两大端。
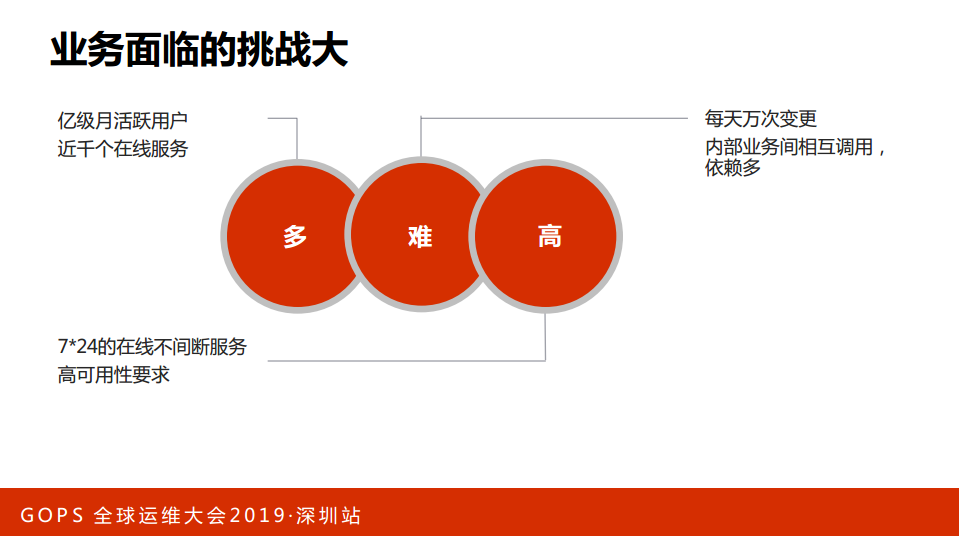
结合小米看一下业务上面临的挑战:
第一,多。我们有近亿月活跃用户、近千个在线服务;
第二,难。我们每天有近万次变更,大家都知道变更是很高危的操作,很有可能形成服务可用性。二是内部的业务依赖很多,我们平均一个在线的服务依赖近十个在线的服务。
第三,高。我们提供互联网服务,要求7×24小时不间断地服务,结合这两点可以看到服务稳定性是非常有挑战性的工作。
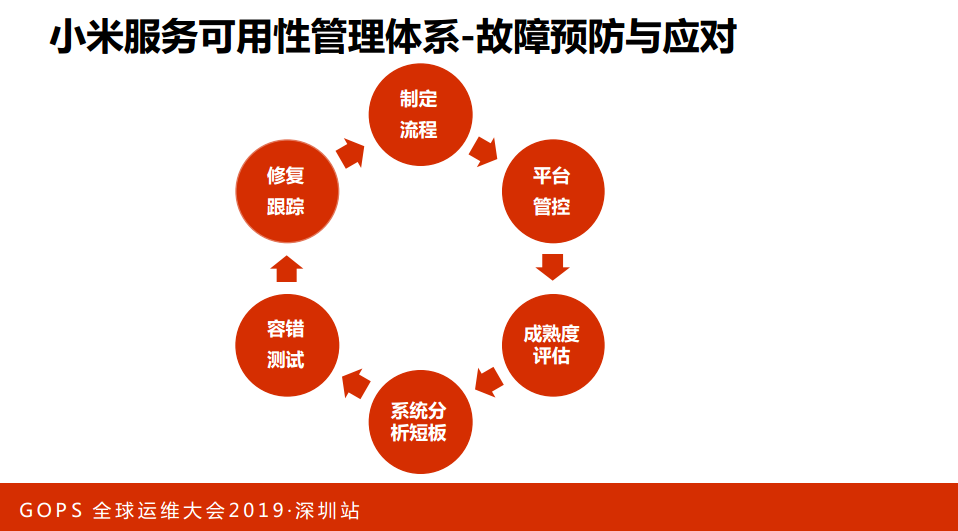
3. 小米服务可用性体系
先简单介绍一下小米的服务可用性体系。我们结合业内的实践和小米的沉淀,我们总结了几点,核心的思路就是控制风险,分成三块,主要采用事前、事中、事后三个阶段来控制和降低我们的风险。
第一,故障前--预防。
我们的主要目标是减少故障的发生;故障中,主要是缩短MT+;故障后,主要是深度对故障进行剖析,减少故障重复发生。这是有关系的,故障应对做得好,后面压力就少,对于我们个人就有更多的精力来做一些其他的事情。相反,如果这两个阶段做得不好,后面的压力非常大,导致我们运维的人疲于奔命。

下面我展开讲一下每个阶段所做的一些实践。简单讲一下故障前,故障前的核心词汇是“预防”:
一是系统分析服务的短板;
二是人为因素,这个阶段主要是通过建立流程,有了流程以后,我们还需要确保流程能执行到位,那么我们怎么去监管呢?我们觉得平台是一个比较不错的办法,所以我们通过建立流程和平台来双管齐下,共同对这一块进行一个把控。
第二,故障中--应对。
预防和应对中间有一个交叉的地方叫做“容错测试”,主要是通过主动的测试来提高故障的处理能力,发现未知的问题。应对重要阶段是预案及演练,核心业务具备跨己方房子切流量能力,有了预案之后还不够,需要确保预案定期演练,执行预案的时候快速生效,不会出现示小。
第三,故障后--总结、改进、跟踪。
做了一些关键指标跟踪,包括服务可用性、故障修复率、MTTA、MTTR、MTBF,后面实践的阶段还会着重讲。

4. 实践
我们看一下实践部分:
实践一:业务成熟度评估。小米有近千个在线服务,而我们的运维同学少之又少,另外有一点,运维同学的能力可能是参差不齐。对于近千个亿,我们怎么能性质有效管理起来。之前是Case by case解决问题,效率低。
二是无法量化业务成熟与否,有人说业务成熟度好,体现好怎么体现呢?怎么去量化,针对两个问题提出了业务成熟度评估这件事情。做这件事情能够解决我们两大痛点:
第一,系统分析服务短板,提升服务质量;
第二,量化我们业务的一个成熟度。

业务成熟度评估标准,截取了几个关键的指标:
第一,服务容错能力。
一是服务降级,我们要求核心的业务必须具备服务降级的能力。举一个简单的例子,比如说浏览器业务,浏览器业务下拉的时候会出现信息流的过程,如果服务端出现异常,如果没有容错就会出现白屏。我们要求这样的业务必须要有这样的方案,举一个例子,信息流业务出现问题了,那可能有一个非个性化的解锁,那这就是其中一个降级的方案之一。
二是机房冗余。我们做过统计方式,跨机房、切流量是最有效的止损办法。
三是容错的测试。上面降级方案有了,机房的冗余也有了。我们能保障它实时有效了,保证它快速止损吗?其实是不能的,我们必须要有一个验收的能力,所以提出了容错性的测试。
第二,数据备份。大家觉得数据备份的应用很熟悉了,其实不然,数据也是更重要的,我们对数据有几个要求:
一是,重要的数据一定要异地备份;
二是业务的场景不一样和业务的需求不一样,提出了分钟级、小时级、天级延迟的备份。
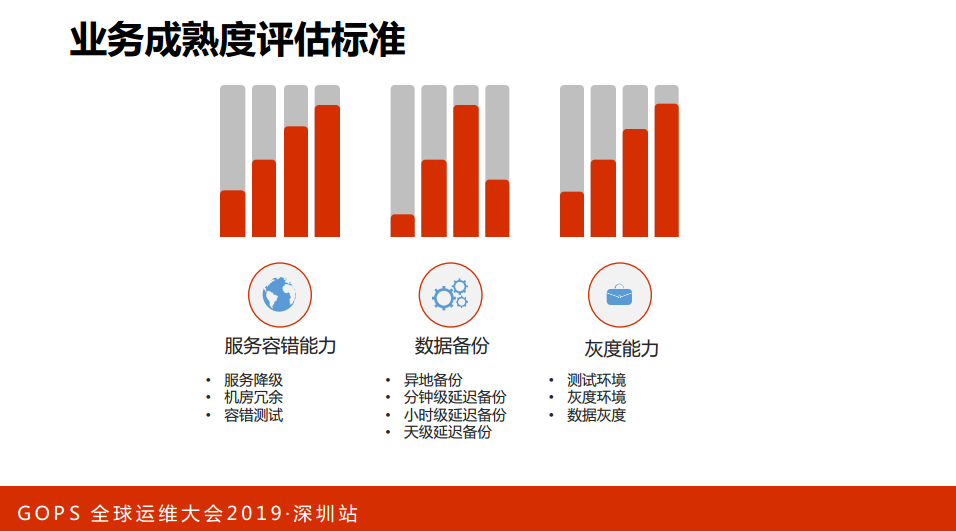
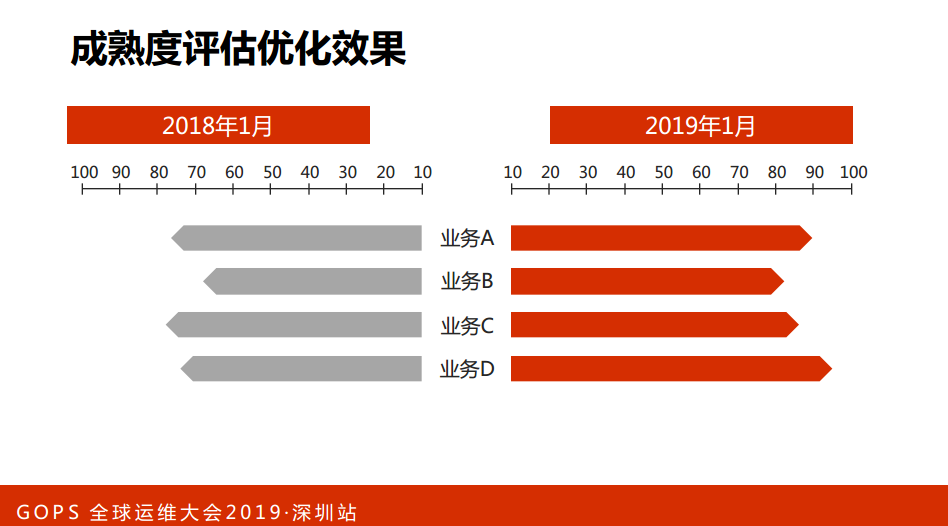
第三,灰度能力。变更有一定的隐患,为了降低隐患,我们有灰度能力,我们进行了单元测试、集成测试可以上线了,我们要求必须在测试环境进行测试。测试通过之后才能发布到灰度的环境,那么灰度这个时候还是要进行一个考察。灰度没有问题才能进一步发布到集成。这里面提到数据的灰度,数据其实某种意义上来讲,数据比代码更重要,因此我们对于数据的要求是必须进行灰度发布,必须在线下进行测试,测试环境和灰度的环境。这张图是我们实行了之后看到的效果,因为有一些原因没有例具体的业务,支撑业务A实现之后,业务的成熟度都有了比较成熟的明显提升。从一定角度上来说,业务的稳定性保障就是更高了。
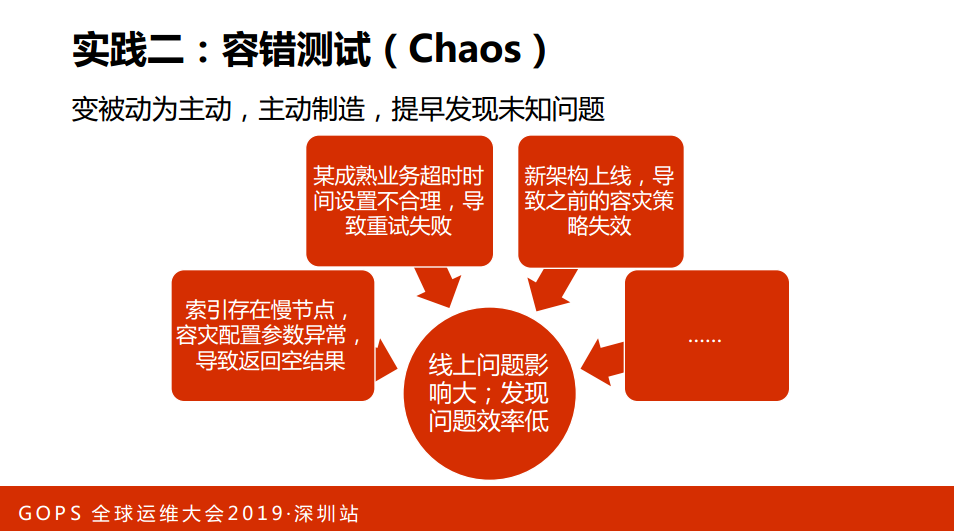
实践二:容错测试(Chaos)。前两天阿里平台也是发布了他们的Chaos的一个系统,这方面小米也有一些实践。
第一,索引存在慢节点,容灾配置参数异常,导致返回空结果;
第二,某成熟业务超时时间设置不合理,导致重试失败,这是一个成熟业务,已经上线几年的时间,突然间出现这样的问题;
第三,新架构上线,导致之前的容灾策略失效。
这是我列举的一些线上问题的,线上的问题和隐患非常大,一旦在线上爆掉,运维同学受不了,业务同学也会很难过。这些反映出来一个问题,我们发现问题的效率还是太低了,因此,我们转变一下思路,我们变被动为主动,主动故障、主动制造,提早发现一个未知的问题,提升我们故障处理能力。
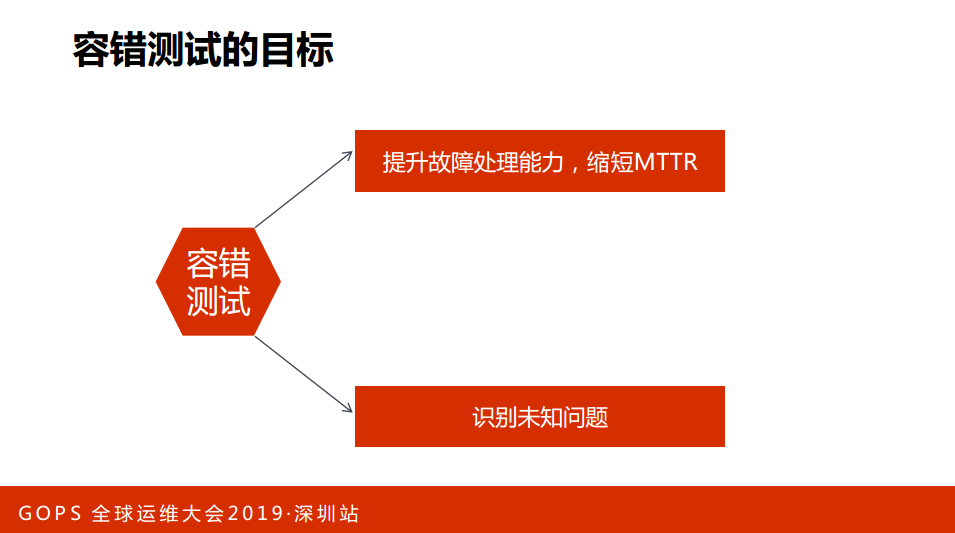
我看一下容错测试,我们的目标:
第一,提升故障处理能力,缩短MTTR;
第二,识别未知问题。
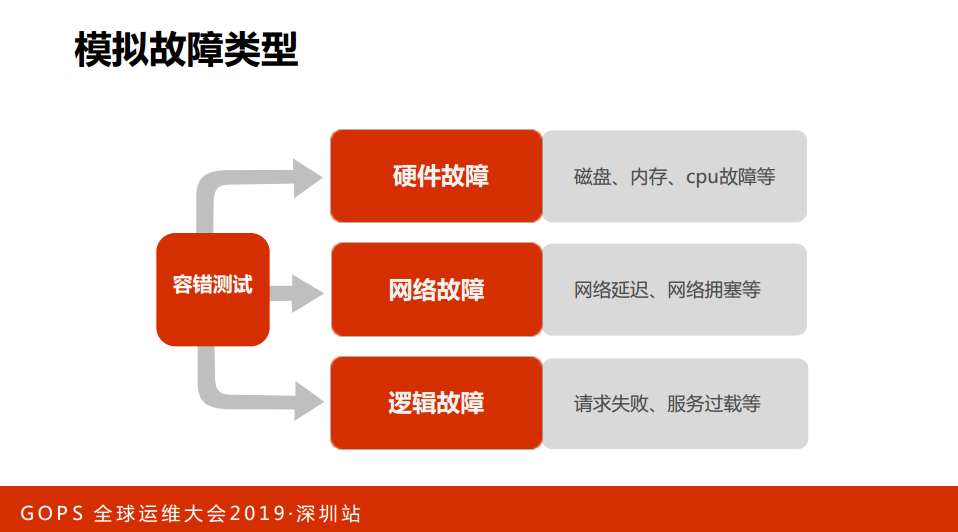
通过两个手段为用户提供更优质的在线服务。这是我们现在能够模拟的一些故障类型,简单介绍一下:
第一,硬件的故障。包括磁盘、内存、CPU的故障;
第二,网络的故障。网络的延迟和网络的拥塞情况;
第三,逻辑的故障。请求失败、服务出现过载等等,那么我们现在都能够镜像管理。
介绍一下故障的全流程,主要分为三块:
第一,测试前,制造阶段,我们会去跟制造沟通,根据疑问,制定测试方案,测试方案要有回滚方案;
第二,测试中,前面的剧本写好了就根据剧本做一个测试,过程中要评估表现,看看是否符合假设。如果有不符合假设的情况下,我们要制定前面沟通方案。
第三,测试后,进行复盘的操作,评估过程中的表现,我们做到识别分析,最后识别故障。

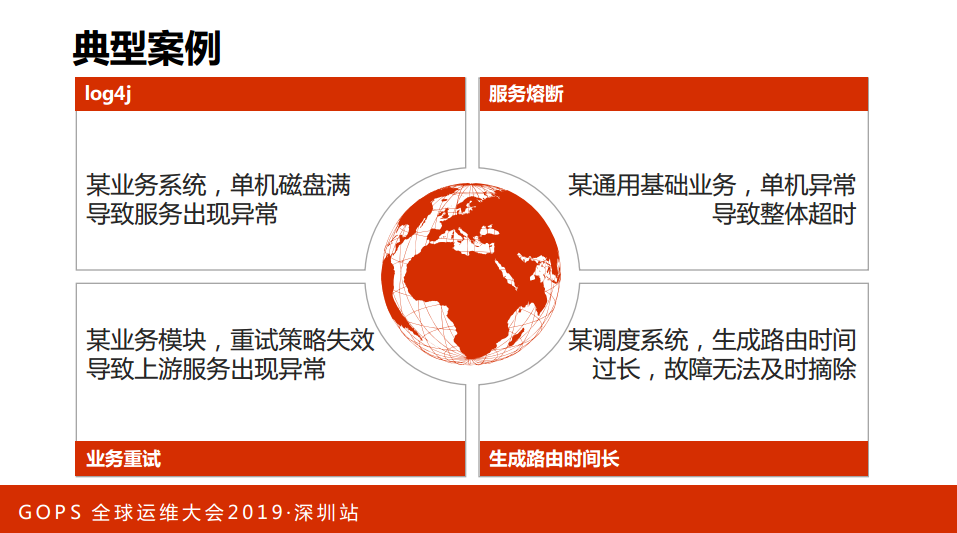
介绍一下我们遇到的典型案例:
第一,Log4j,大家知道可以异固的一些磁盘,我们测试的时候发现磁盘满的时候,业务系统出现不可控制的情况,发现的问题,一部分没有添加相应的配置。这都是被预期的情况;
第二,服务熔断。某通用基础业务,有时候发现单台机器异常了,后端请求资源,发现单机异常导致整体超时,后来发现有一个代码写得有问题,做简单的业务革除。
第三,业务重试。我们发现重试一直会失败,怎么回事呢?后来发现重试的策略调度到了一台机器上。
第四,生成路由时间长。这是内部一个调度的需求,我们故障不多的时候,预期机器最长一分钟左右居然能够自动地摘掉,发现5分钟过去了,这个节点还在,后来发现是其中一块儿代码有异常,导致超过6分钟的时候才能够被摘了。
这些问题都是比较典型的,我们做Kills发现的问题,从另外一个角度来讲,如果没有Kills,有些比较难在线上出现,或者出现的时候比较低级,影响用户使用我们产品的满意度。
实践三:质量管理平台
做一个统计,在座的运维管理同学多吗?还是不少。运维的同学,看看每天是不是一直在忙这几件事情:
第一,出故障之后,我们需要定位,故障解决了吗?为什么这么慢,这就是故障解决的效率;
第二,故障跟进质量,形成三个条路,老板会这个故障解决怎么样?这个故障解决完成了,三个问题三个人。
第三,影响故障的可用性指标。

我们能不能更智能一点,更自动化地来解决这些问题。我发现调研结果是可行的,我们做了一个事情,做了一个质量管理平台。
那质量管理平台提了几个:标准化、流程化、平台化。质量管理平台主要做几件事情:
一是关键质量指标管理;
二是故障管理;
三是问题管理;
四是事件管理。

我们介绍一下质量管理平台,管理界有一句话叫“没有度量就没有管理”。我们首先第一步,明确我们关键的指标,那么我们经过调研以后确认,最终确认了四大关键指标:服务可用性、故障平均恢复时间、故障平均严格时间、故障修复率。我们的平台能够自动收集、管理这些数据。那么有了指标之后,我们需要这些指标进行一个跟踪,我们做了几件事:
第一,故障通道。出现故障达到事务级别的会进行一个通道,让其他同学吸取相关的经验教训。
第二,故障自动修复。我们通过故障自动修复减少故障的重复发生。
第三,质量通报。包括日、周、月级服务端质量报告。日、周是让每位同学了解自己的情况,月级是让老板或者相关方知道服务质量,让他了如指掌,树起质量人人参与,人人负责的意识。

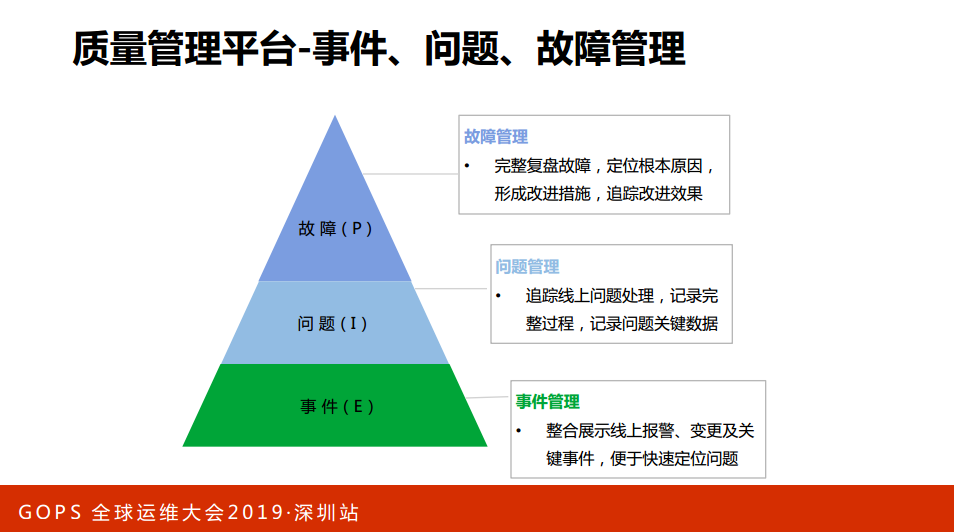
质量管理平台-事件、问题、故障管理。事件,什么叫事件?小米每天有上万个事件,这些事件会有很大的概率会导致线上故障,因此我们整合展示的一些线上报警、变更能够便于快速地定位,提高故障性的效率。
第二部分,事件有一部分可能会升级为故障,系统识别之后自动变成最终线上的处理,记录关键的流程和关键的数据。第三部分就是故障,其实有一部分问题会升级为故障,系统能够自动完整地复盘故障,定位根本原因,形成改进措施,最后达到改进的效果。
这是我们产品的一些图,这部分主要是做服务质量。
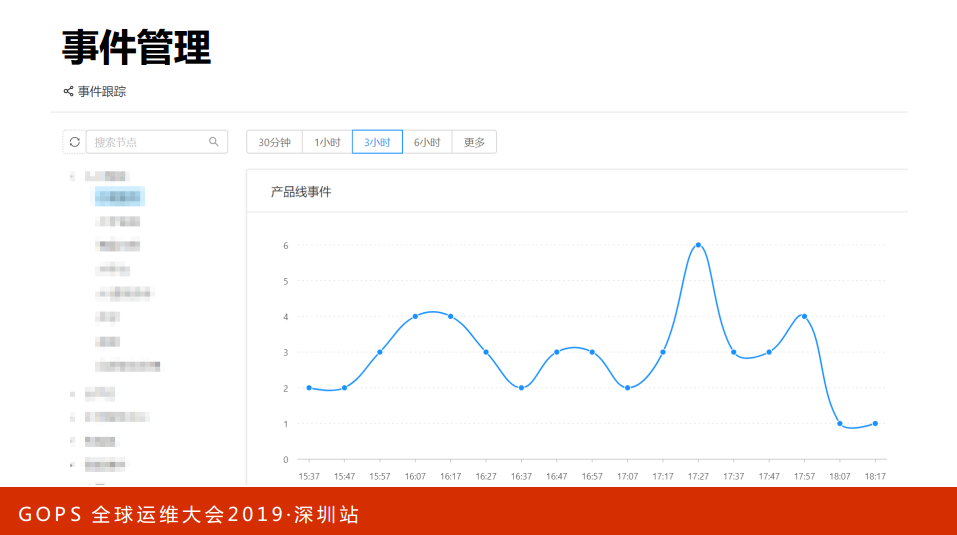
这是事件管理的质量报告,每个点代表了一个事件。
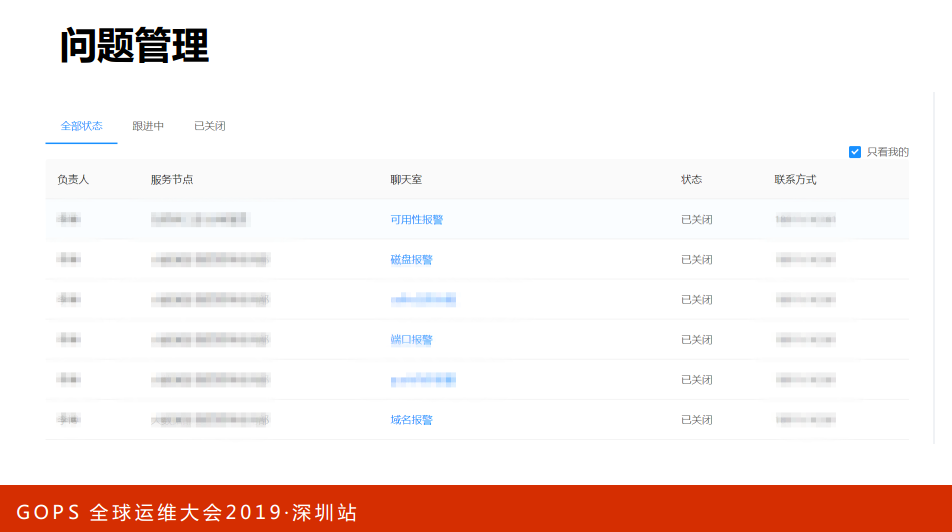
这是问题管理的一个图,负责人、问题的名字、跟进的状态。
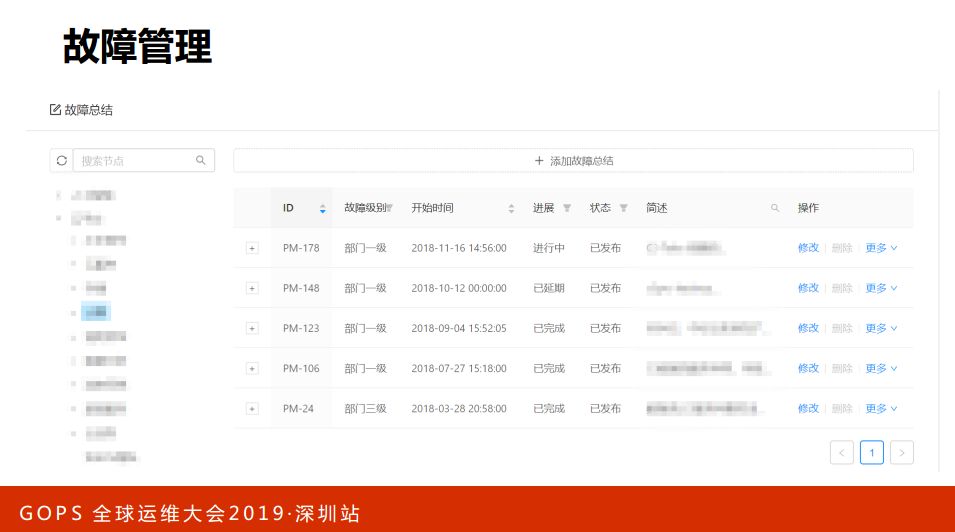
这张图就是故障管理,这是故障需要跟踪定位的,做了一个会话,这都是线上的一些数据。
最后一部分,这是我们的移动端,我们运维同学对于移动端的需求还是比较强烈的,因此,我们开发了一个移动端,这就是我们在线的一个案例,这就是我们的报警的一些信息。这些是我们相关的一些产品的展示。比如说在这儿会查,比如说网络组会选择网络组展示,通过电话就直接播过去了。这是我们移动端的一个展示。
我简单总结一下,服务可用性有两块:一是故障预防与应对。预防通过平台、流程做管控;二是成熟度评估和系统分析短板;三是容错测试、修复跟踪,这样去形成一个闭环。这是事后质量故障一个跟踪,触发点就是质量管理平台,质量管理平台对质量进行一个复盘,对质量进行一个修复跟踪,另外能够自动形成质量指标,形成一个自动的质量报告。这也是质量跟踪的一个闭环。最后贴一下我们的公众号,欢迎大家关注我们,一起成长。