@gaoxiaoyunwei2017
2019-06-24T07:46:11.000000Z
字数 3572
阅读 1770
万亿数据量下的美团点评实时监控系统的演进
北哥
讲师简介
孙佳林
- 美团基础架构部

本文将通过上述三个方面来分享美团万亿数据量下的实时监控平台。
1. CAT介绍
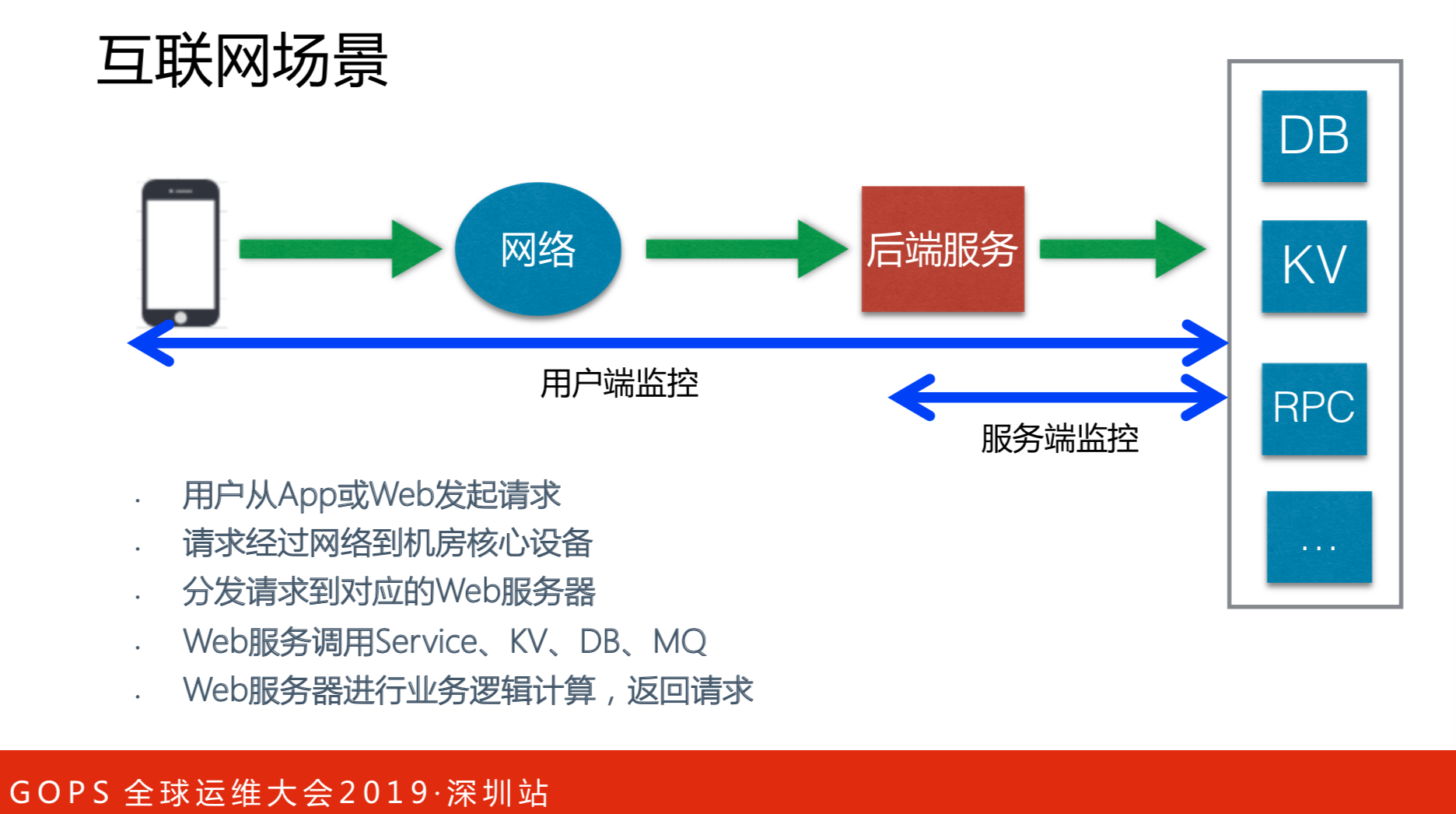
以美团外卖为例,图中的场景下是用户从APP发起请求,经过核心网络到后端服务,再分发到对应的服务器,然后返回数据。
这里细分为两个端监控:用户端监控和服务端监控。用户端监控需要从用户角度监控每个请求是否正常的,这个意义就在于一次APP发版或者热更新,更新有没有问题,比如运营商出了问题。

面临的问题有:
- 用户端监控。需要掌握用户最真实的使用情况,比如打开美团外卖网速怎么样?页面加载速度怎么样?
- 服务端监控。异常发现和根因定位,这是本文的主题,也就是AIOps,但不是我们的核心目标。性能瓶颈在哪里?线上运行的系统指标是否正常?这些系统指标如果正常,并不代表应用是健康的。
- 运维运营。需要掌握每个服务的KPS是不是很高,服务请求是不是很慢,以来做降级、熔断、扩容、缩容的操作。

CAT就是中央应用追踪,最原始只有服务端监控,这部分是本文讨论的重点。在2015年,我们加入了更多用户端监控。CAT不仅仅是指AT,还包括前端这部分。下面分别介绍下部分用户端监控,重点介绍服务端监控。

用户端监控主要阐述三个方面:
- 用户端大盘
- 用户访问监控
- 用户资源监控
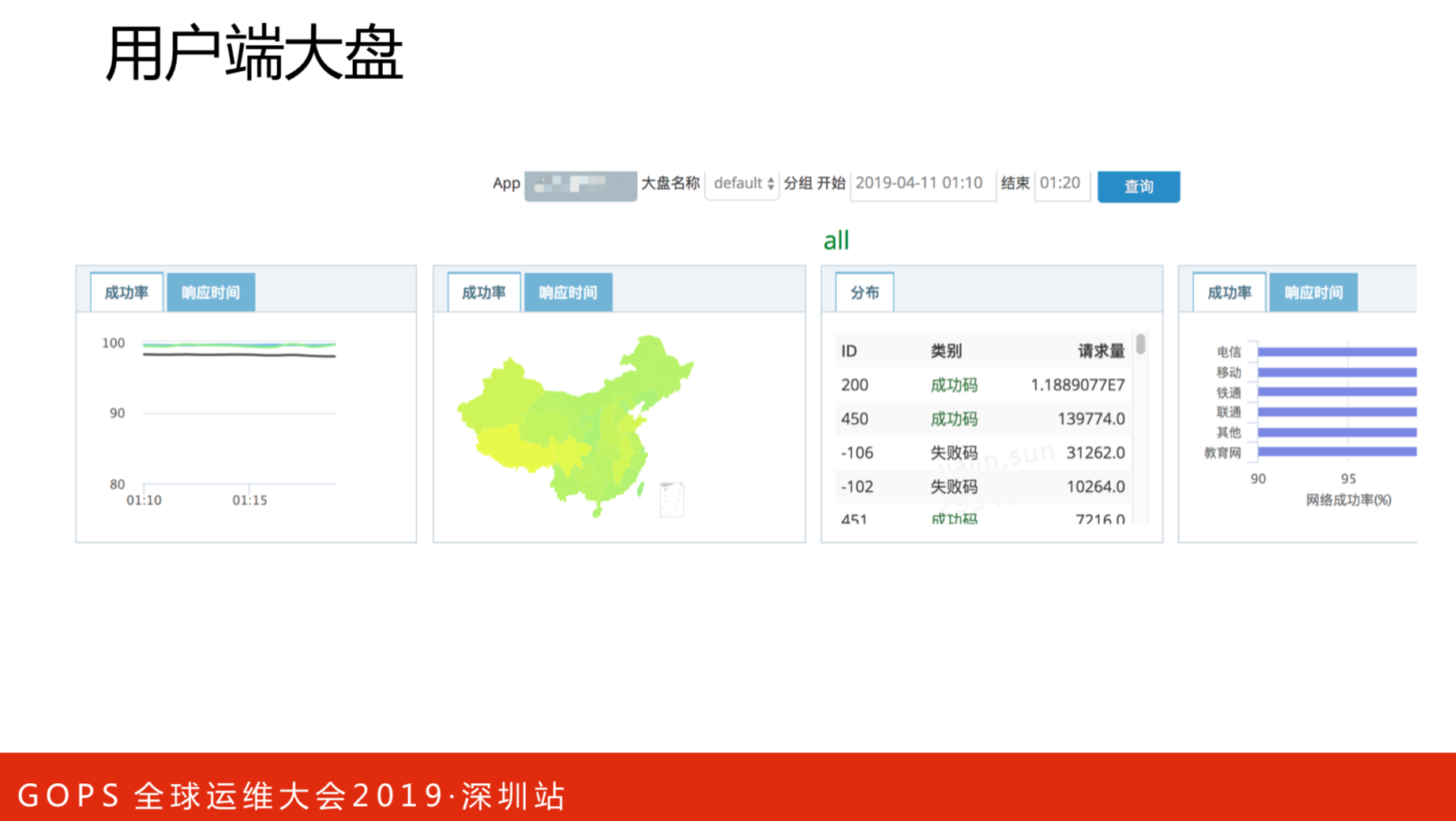
这是用户端大盘,比如到中午饭点了,需要上美团外卖APP,能知道全国用户使用情况的简单直观图。西藏、新疆网络稍微差一点,该地区3G比较多。甘肃有段时间的成功率非常低,也是通过大盘发现的,跟运营商沟通后成功率从99.9%到99.99%以上。
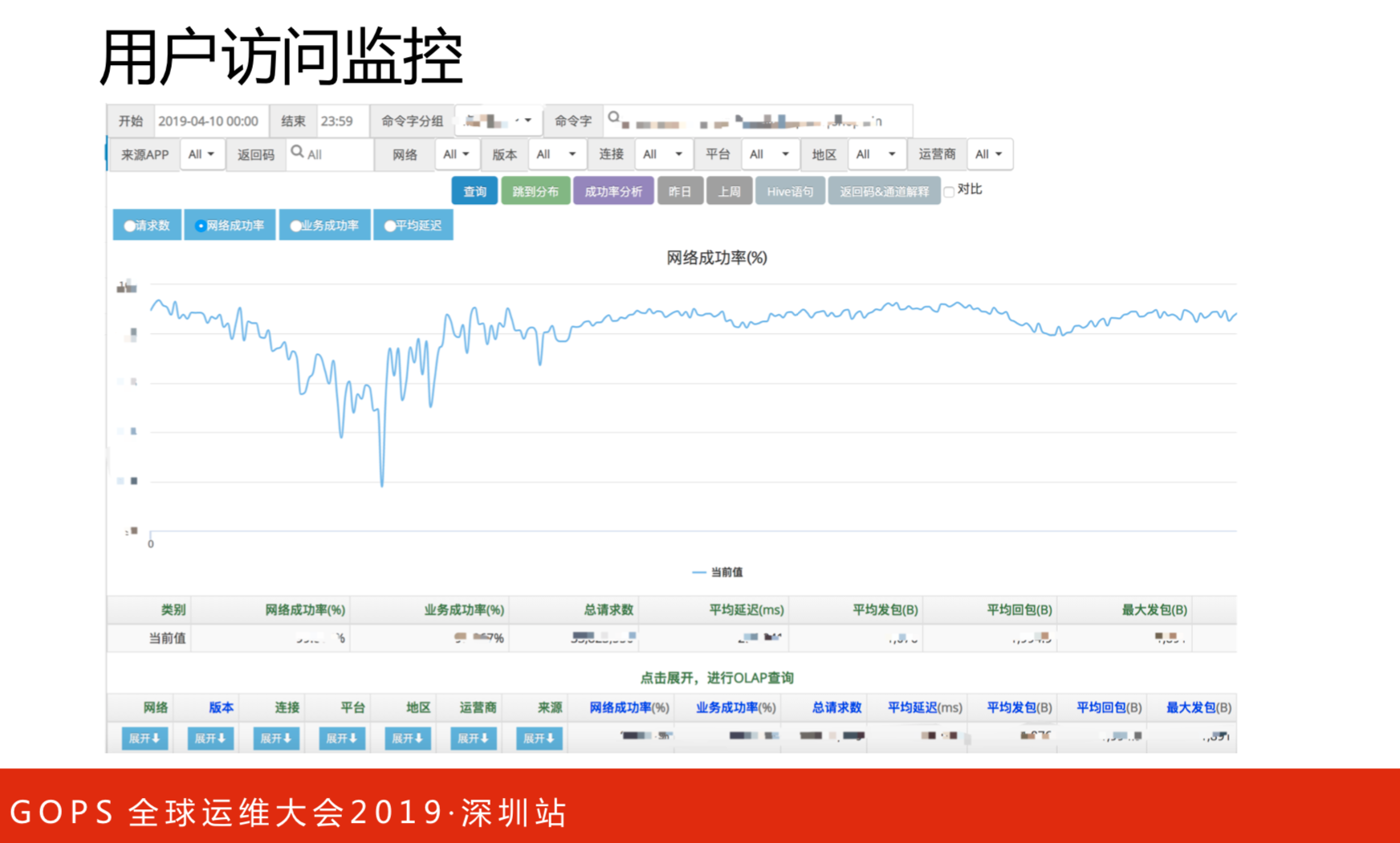
仅仅有整体是不足的,如果某一个时间里出现了红的地方,我们需要知道是哪个接口出了问题,就需要通过用户访问监控来监测。用户访问监控有很多维度,比如时间、APP来源、wifi还是4G,安卓还是苹果,版本等等。
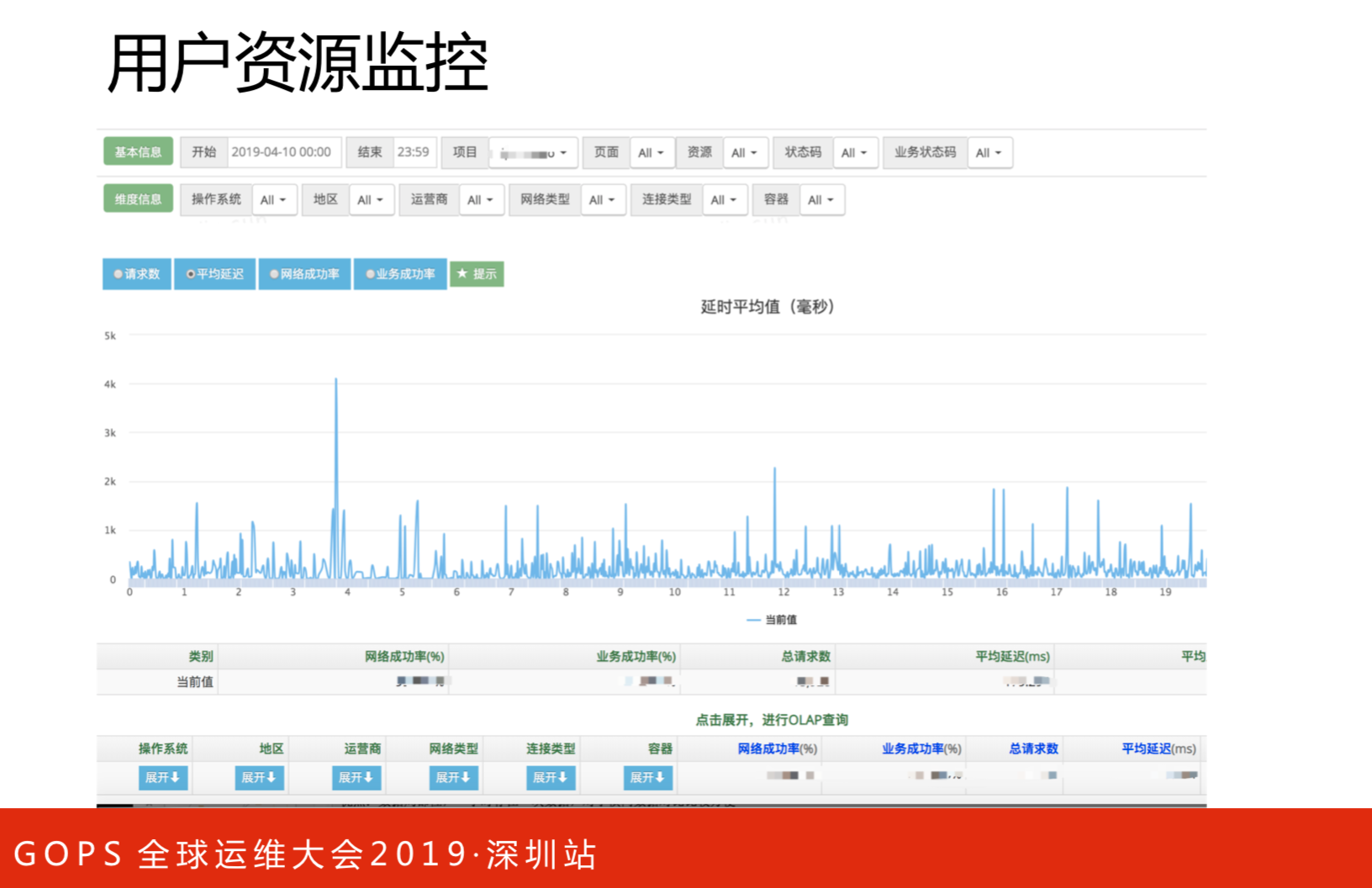
用户资源监控与上面的用户访问监控类似的,不再赘述。
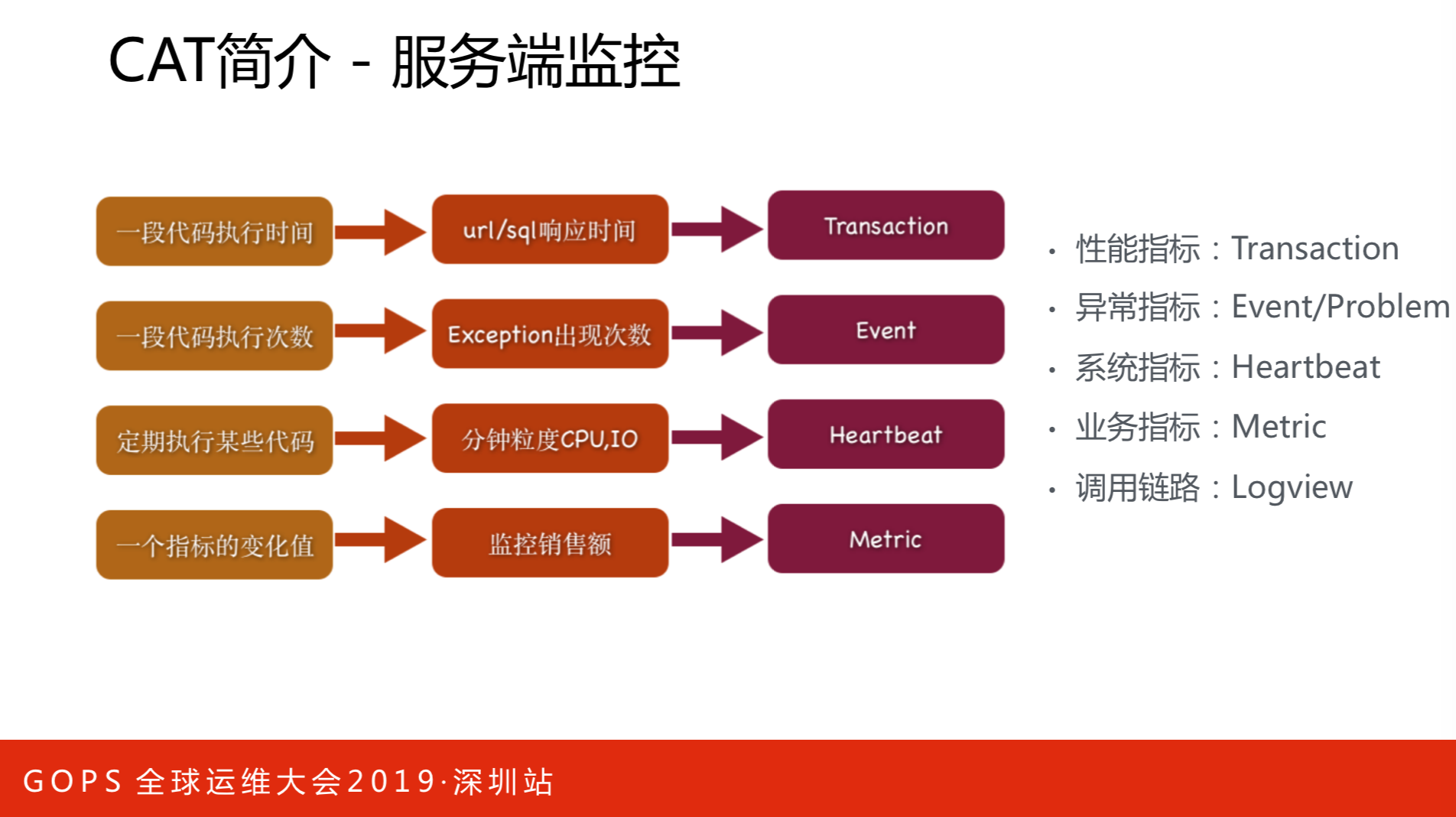
服务端监控指标有:性能指标、异常指标、系统指标、业务指标和调用链路。衡量数据库的方案是性能指标,比如打开美团外卖,一家商铺用户端看到的是一种场景,从服务端看又是一种场景,究竟哪个环节出了问题,中间会有网络监控还有后端监控,这属于用户端监控。要定位一个问题,往往要多个环节去定位,定位服务端的性能。如果打开商户页面发现出错了,这时候需要知道哪些异常指标,要到异常指标里面去看。业务指标不再关心机器级别,只关心这个服务宏观的表现。业务指标会有多个tack维度,比如我们需要知道支付来自哪些渠道。还有调用链路,这是CAT比很多监控好的地方,它通过一种模型解决调用链路和统计指标。
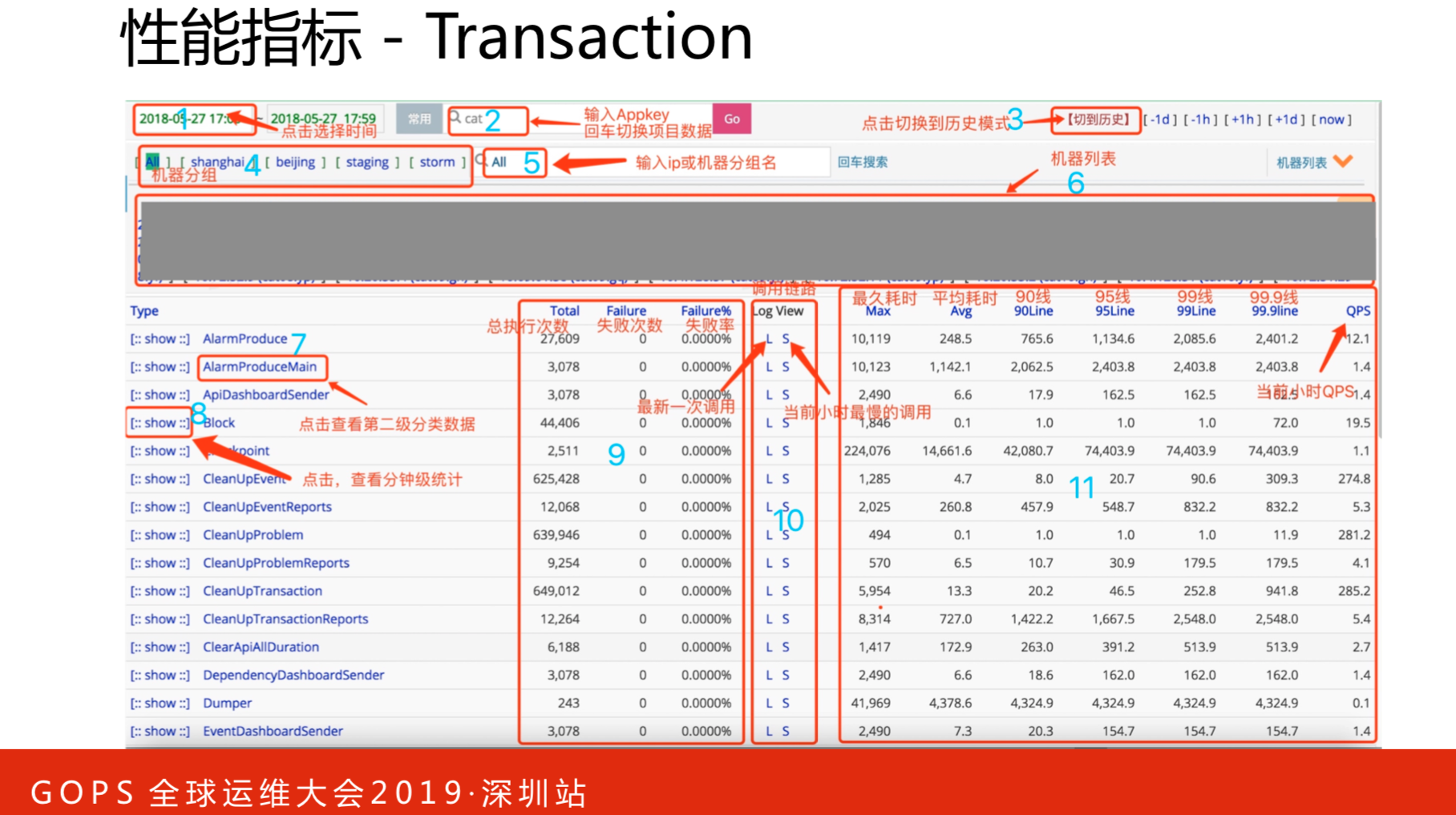
这是性能指标,各个维度指标的详细情况,可以点开每个指标查看。也可以根据维度指标进行报表形式的对比查看。
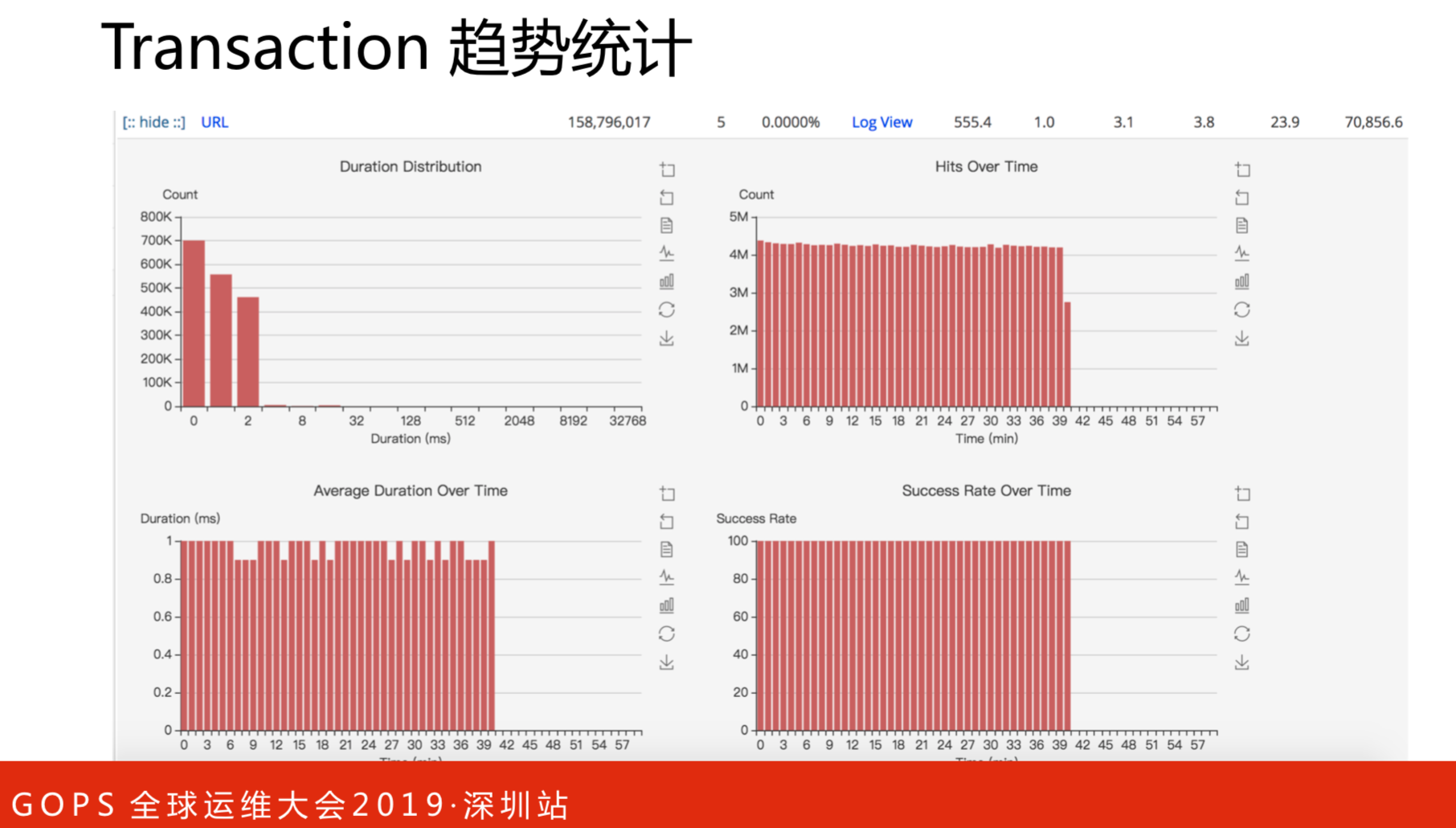
这是性能指标的趋势统计,报表形式的。整体所有的请求访问趋势、整体响应时间和成功率。报表跟指标的区别在于报表是可以横向分析的,比如URA请求,每个请求之间对数据库的访问关系。还可以根据分组进行筛选,也可以自定义分组,做性能指标的对比。

在设计的时候是自上而下的概览,再去看有没有问题,前面有一个用户端大盘,是从用户端去看有没有问题。按照不同的部门,可以知道每个部门最大的错误排行榜,但这并不意味着错误一定是服务出了问题,比如超时。
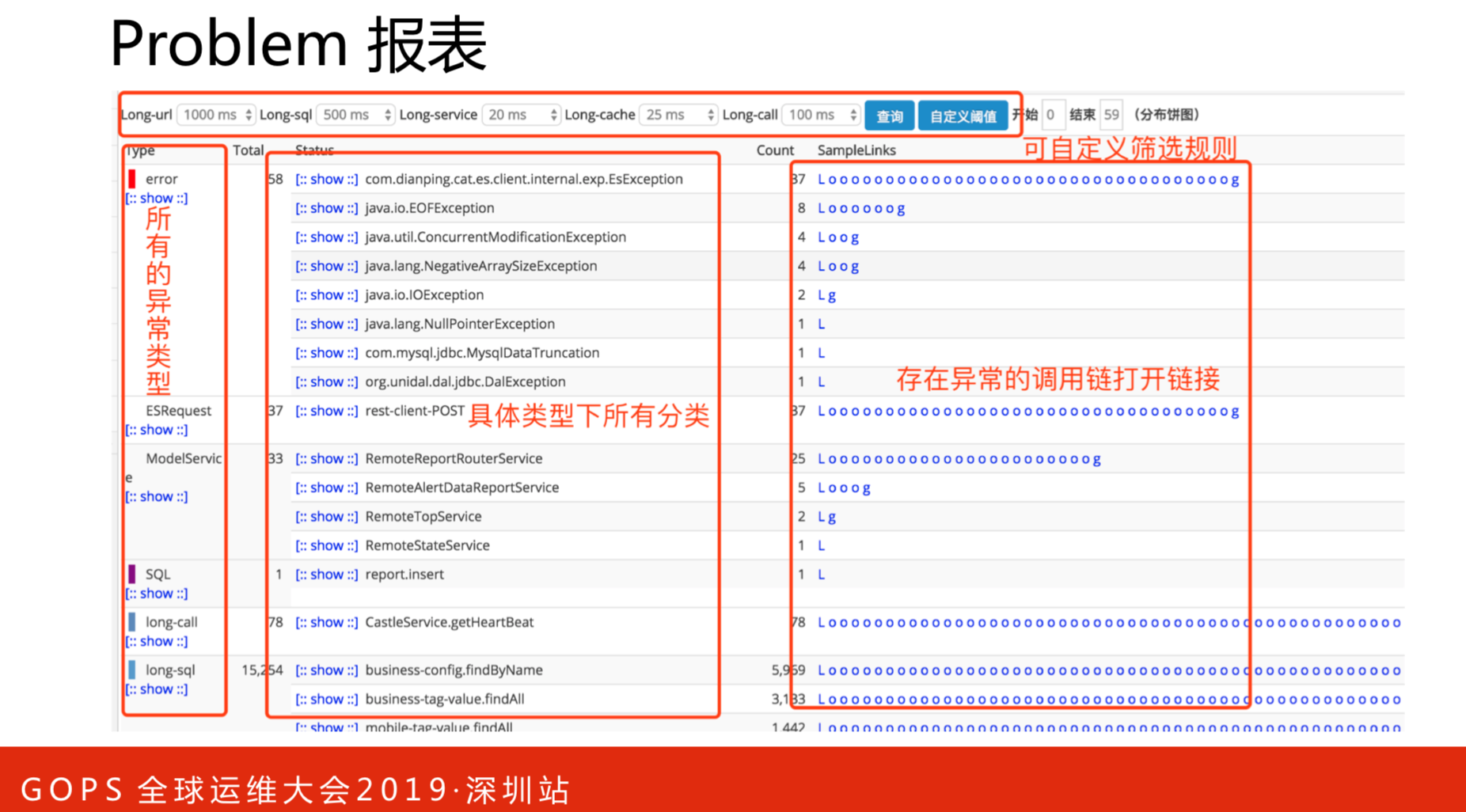
Problem报表帮助诊断分析服务有哪些问题。一般的常规做法是把异常或者错误打到日志里,排查问题查看日志就非常低效缓慢了。通过该工具可以非常高效的发现问题。
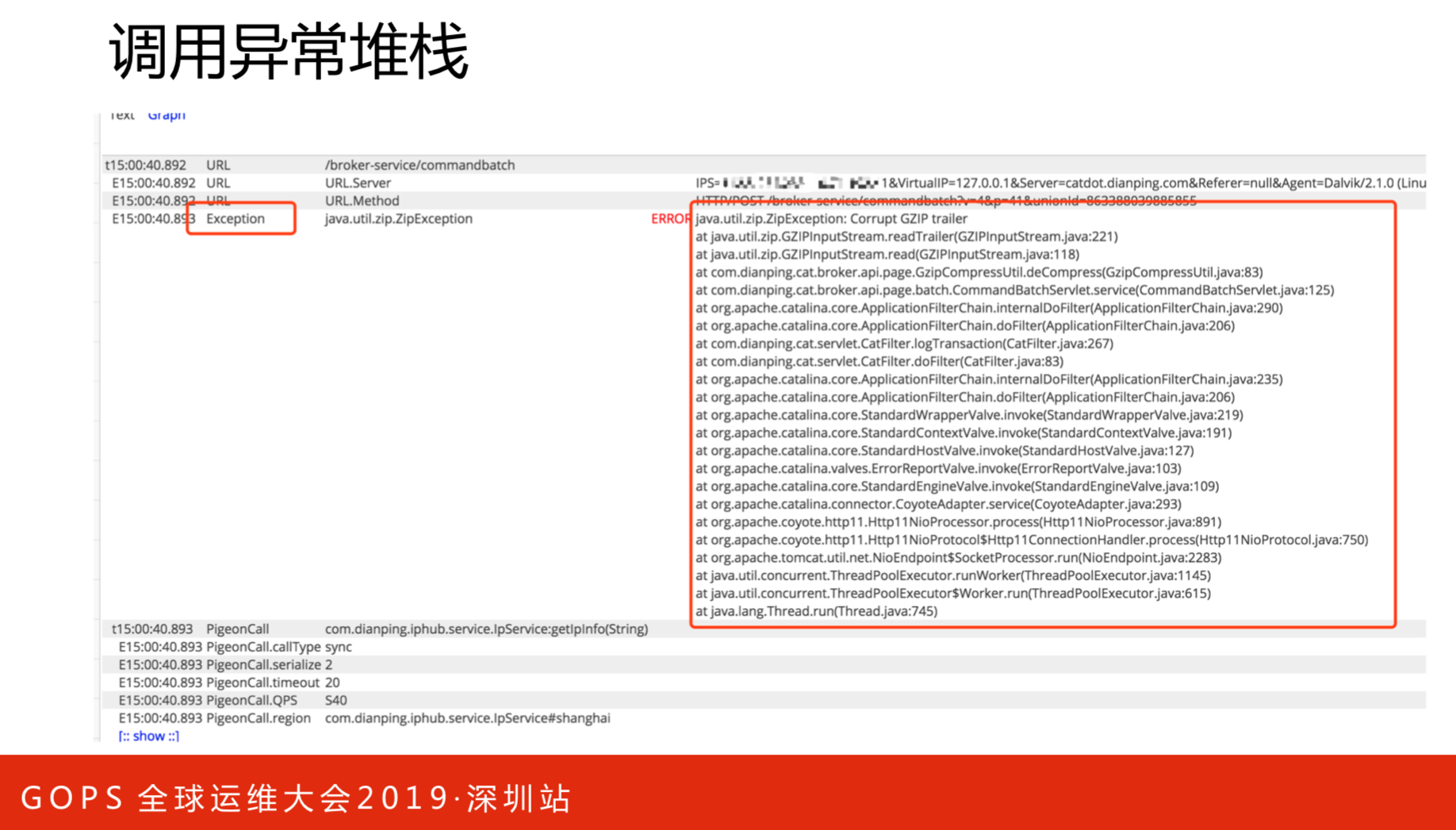
调用异常堆栈,这次请求出错了,理论上来说在APP端打开页面,可能是500或者做了降级操作。这里还有时间线序列,比如请求耗时在哪些地方等等。
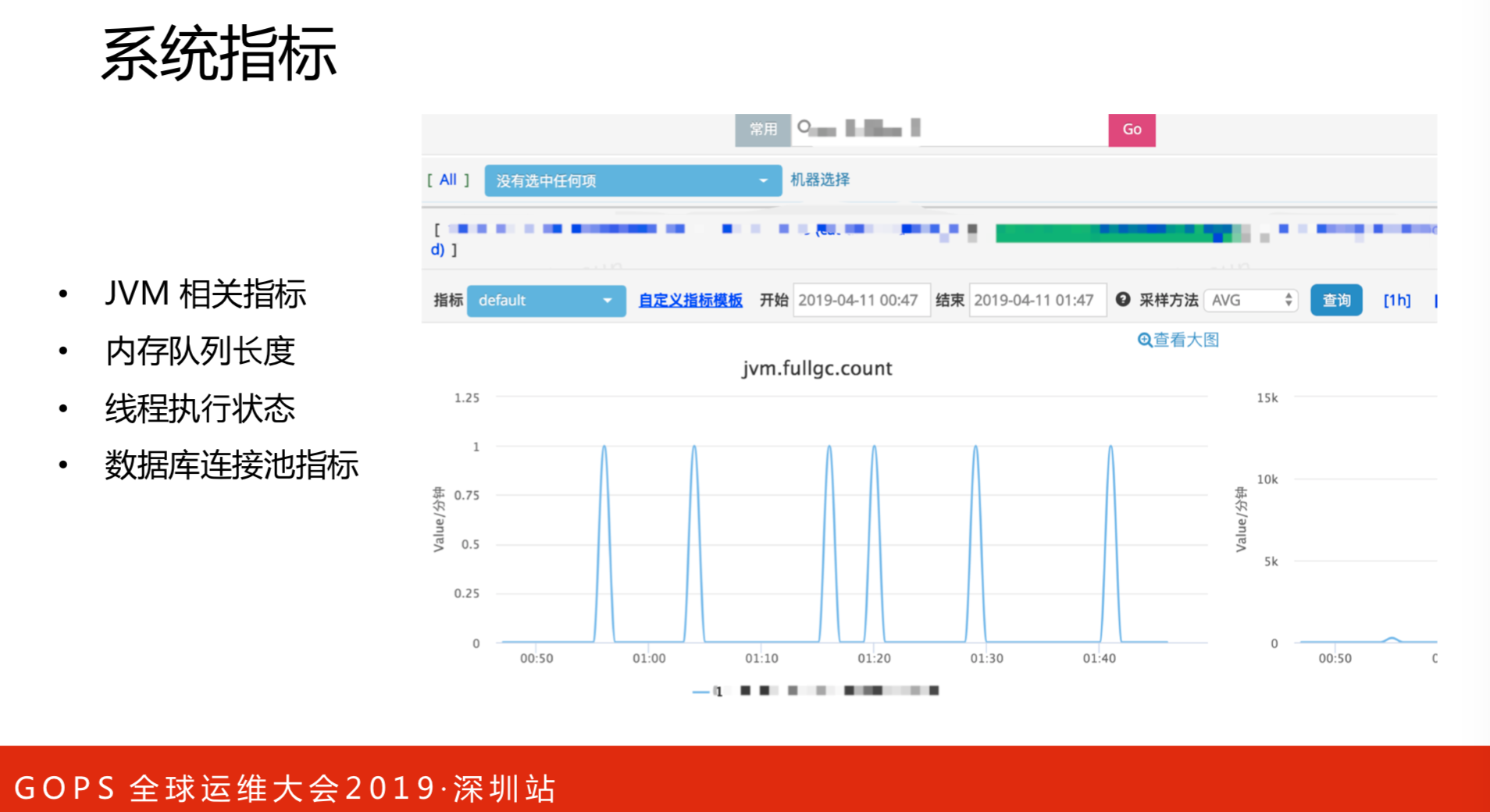
系统指标:
- JVM相关指标
- 内存队列长度
- 线程执行状态
- 数据库连接池指标
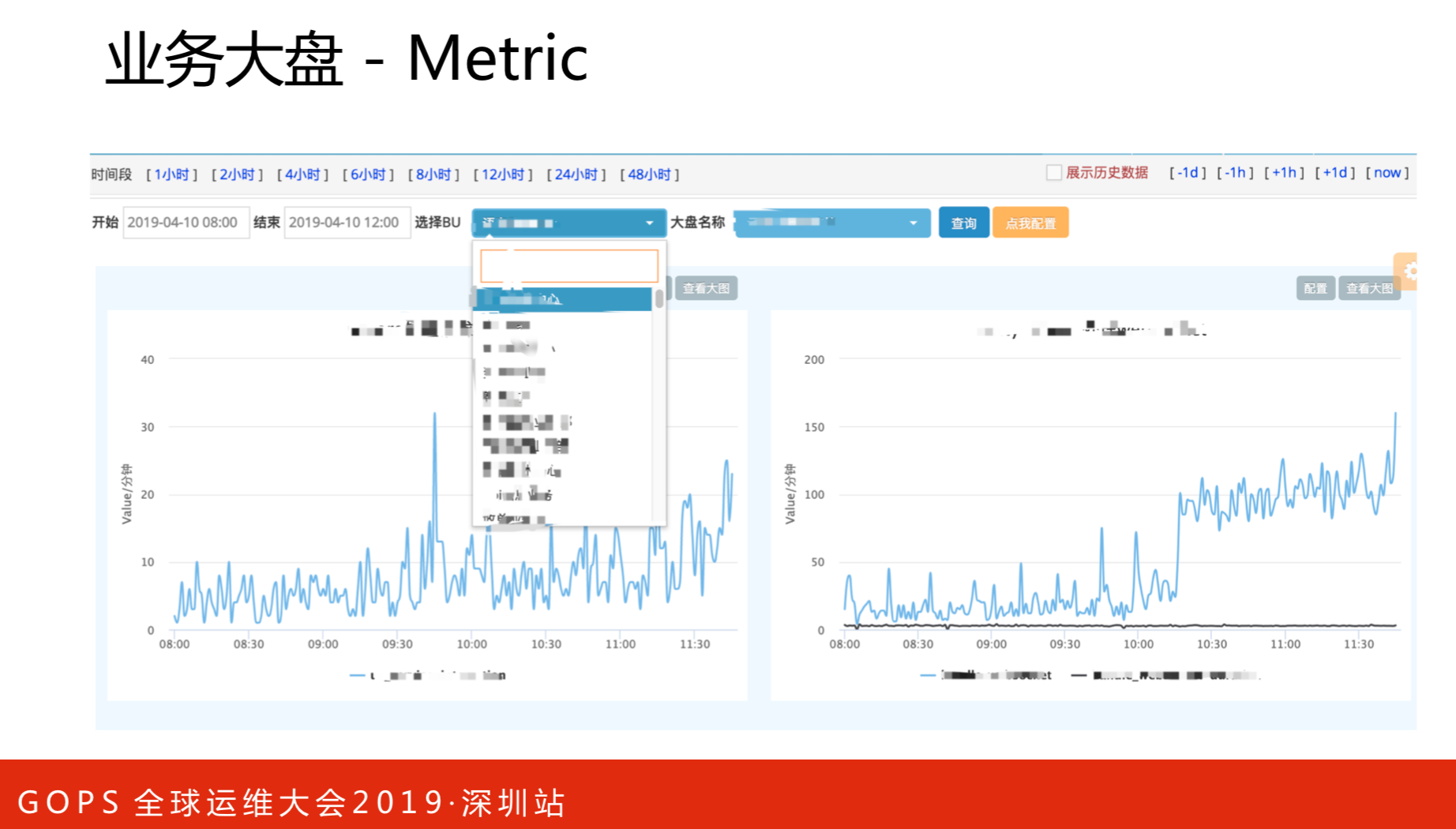
业务大盘,比如需要知道某个订单支付的来源来自银联、微信还是支付宝,可以在这个图里展示。

所有的监控数据不是凭空出来的,都是需要提前埋点。我们是通过CAT API方式,大部分应用在接入基础架构组件的时候都会默认接入CAT。
2. 架构演进
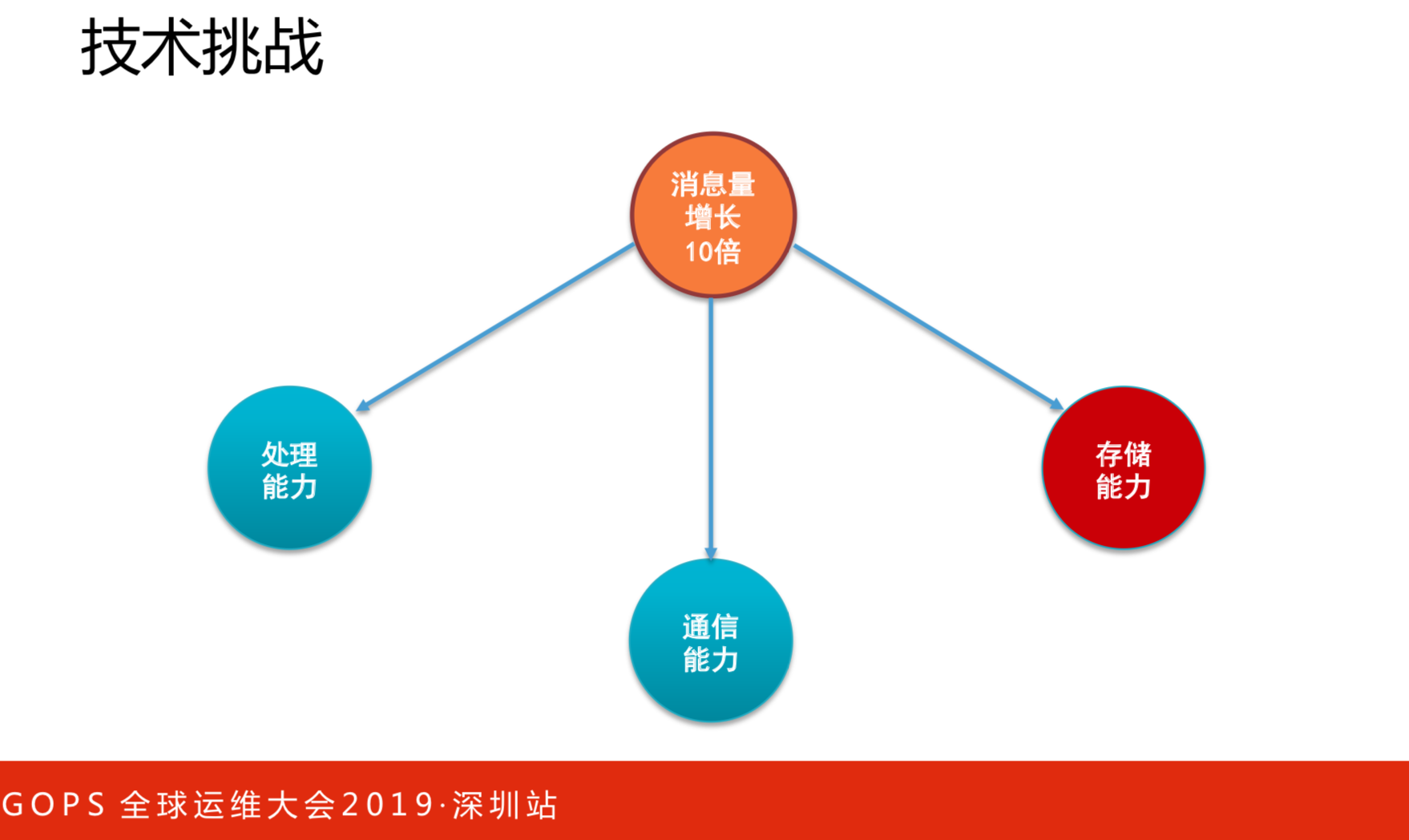
如果大家做过CAT或者开发过CAT,这对你来说非常有帮助。从2015年开始,因一些融合的原因,导致流量增长很高,我这里写的是10倍,是保守的概念。皆因三四年前我们做了下面几点才支撑起亿万级数据量下的实时监控系统。
处理能力
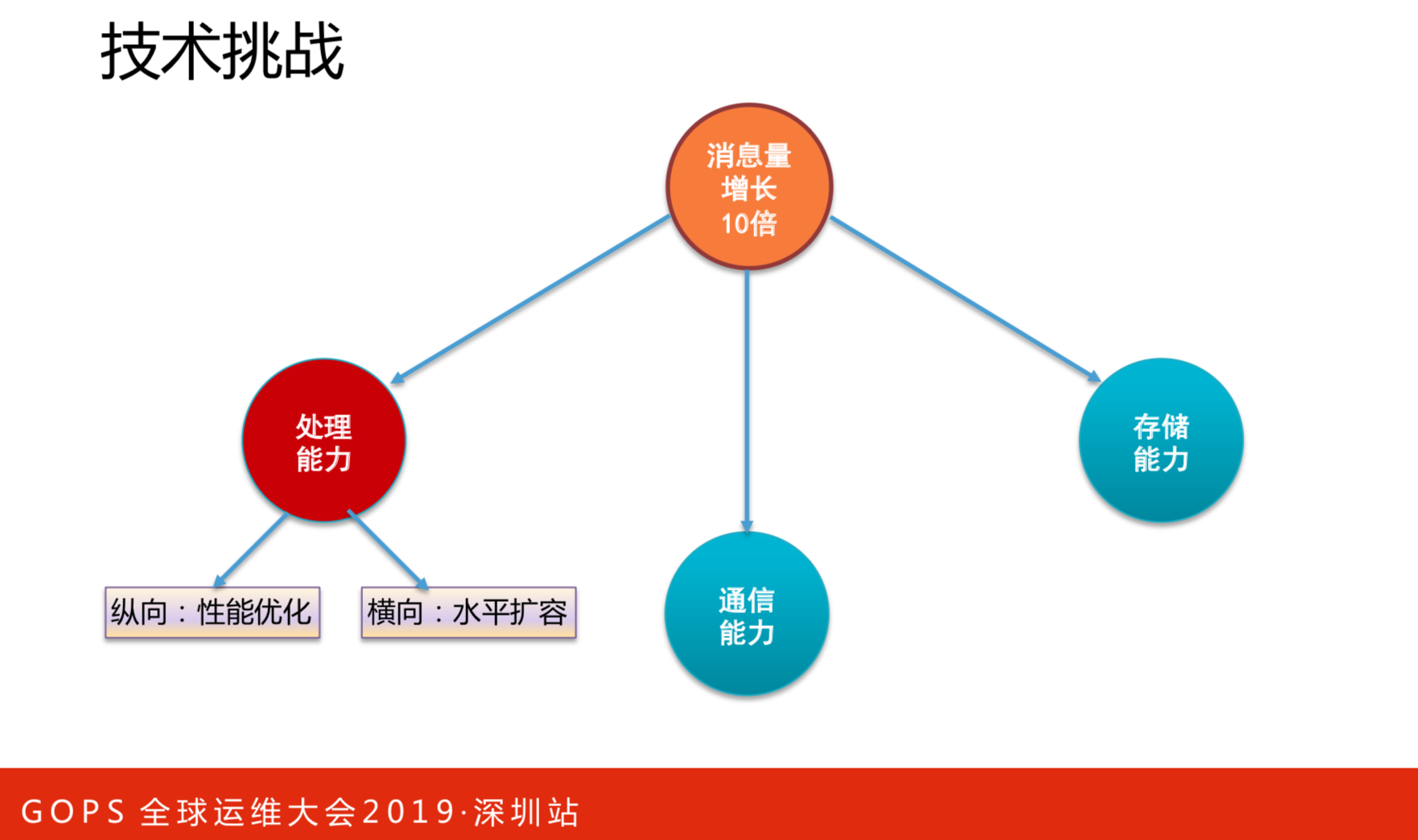
处理能力:
- 纵向,性能优化
- 横向,水平扩容
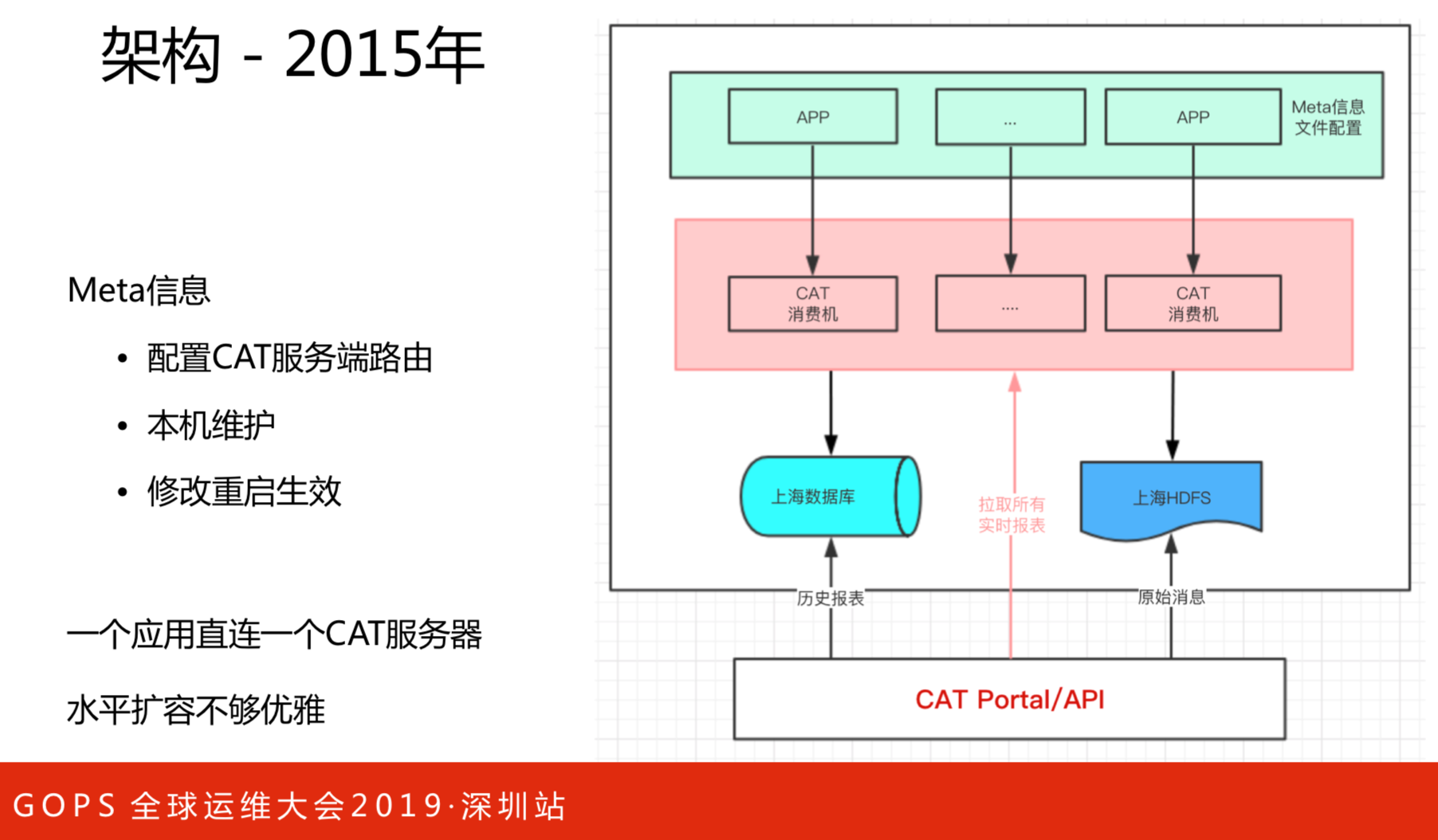
这是2015年的架构。这个架构有三个问题:
- 配置CAT服务端路由
- 本机维护
- 修改重启生效
一个应用直接连接一个CAT服务器,水平扩容不够优雅。
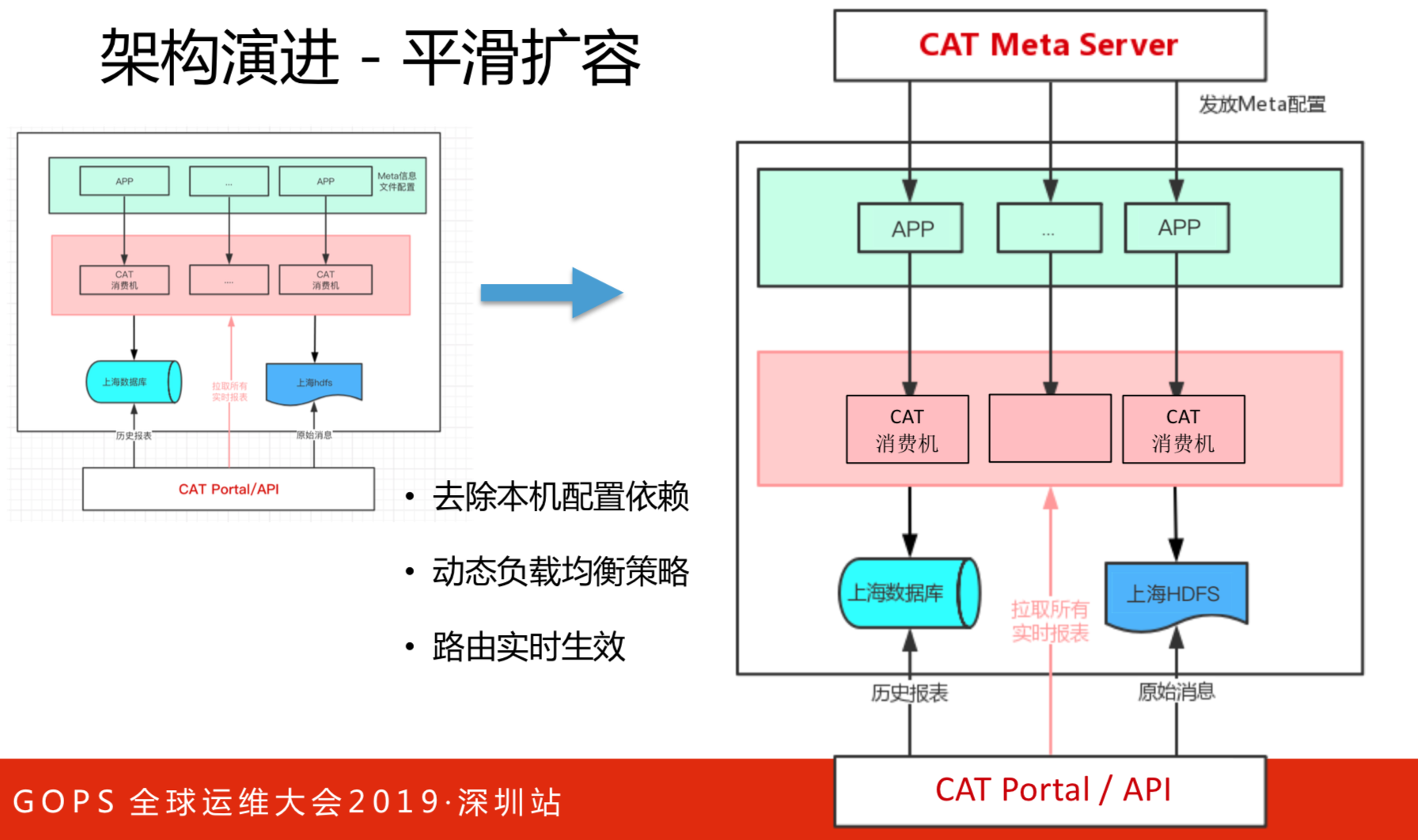
这是架构的改进,主要是为了解决上述三个问题的。去除本机配置依赖,动态负载均衡策略和路由实时生效,便于水平扩容。
通信能力
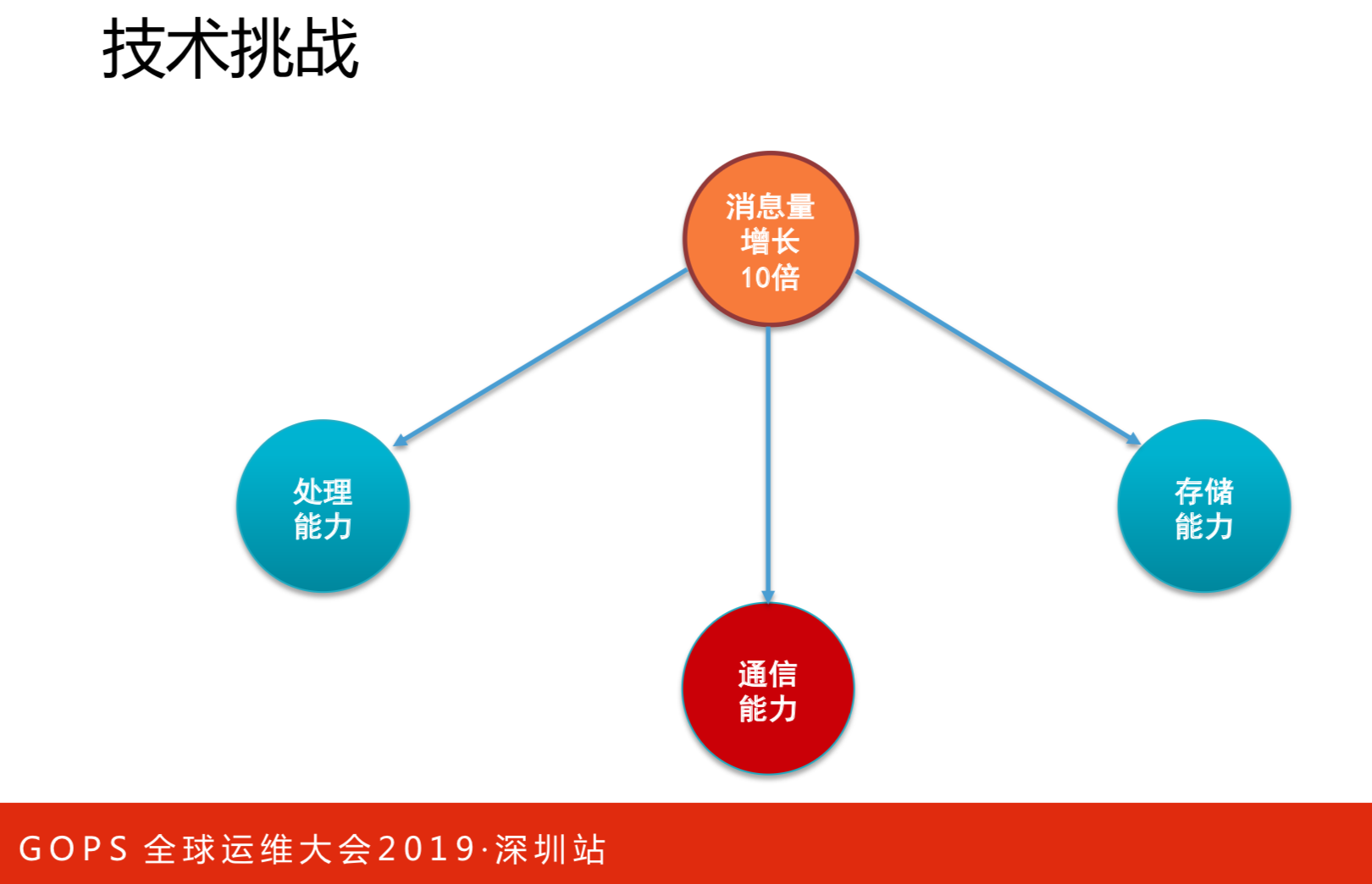
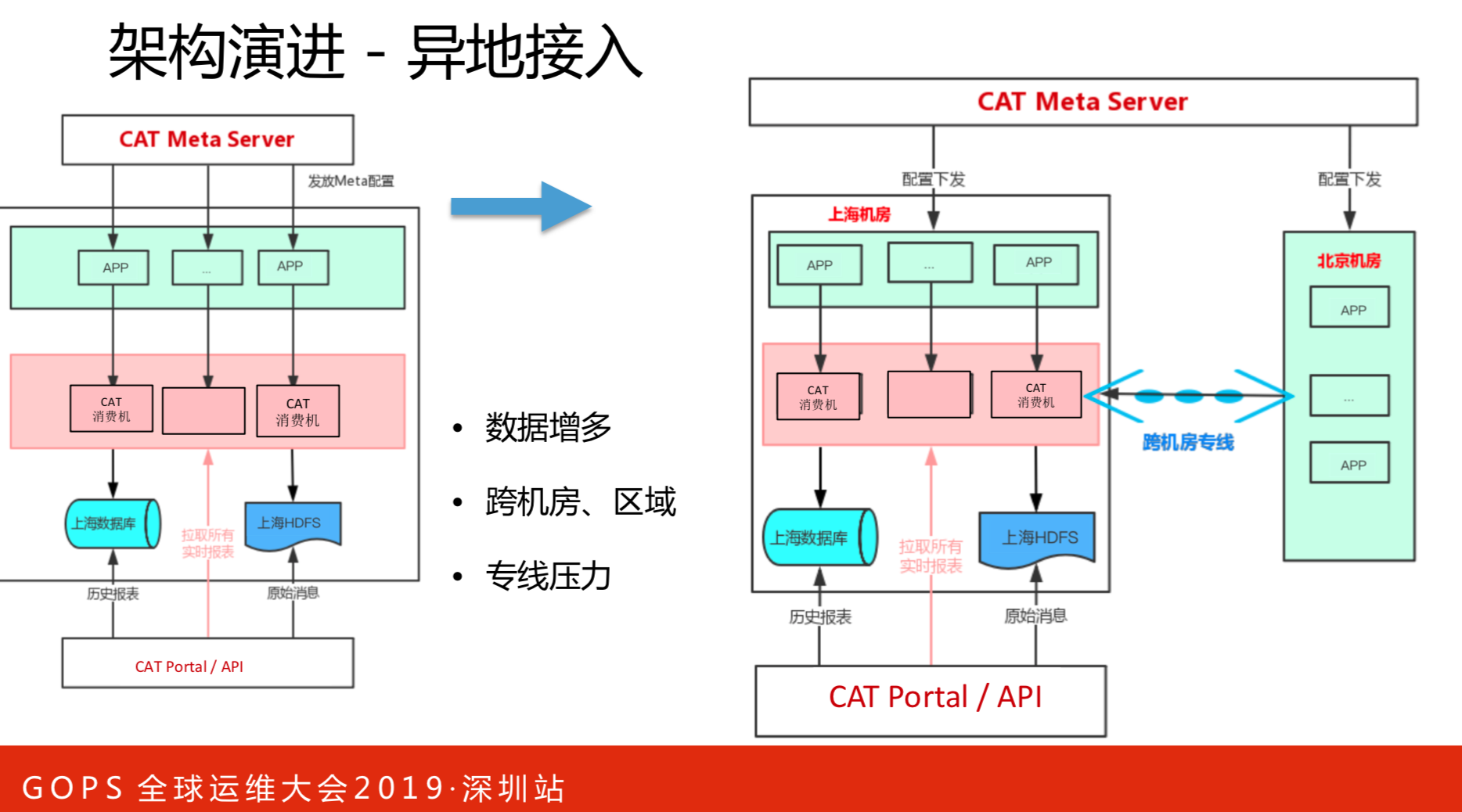
通信能力方面首先这个量是不断增长的,可能成倍的增加,我们集群原本是20台,现在是100台。北上机房融合,把北京的应用全部接到上海来,所有的输入都控制在一个机房。我们这时候只是把CAT布在北京端,输入输出落地还是会跨机房来写的。输入是一些打点、告警和监控信息。落地一部分是统计数据,一小时写一次,写到数据库。还有一部分原始数据,比如调用链数据、对栈日志,先写本地磁盘。
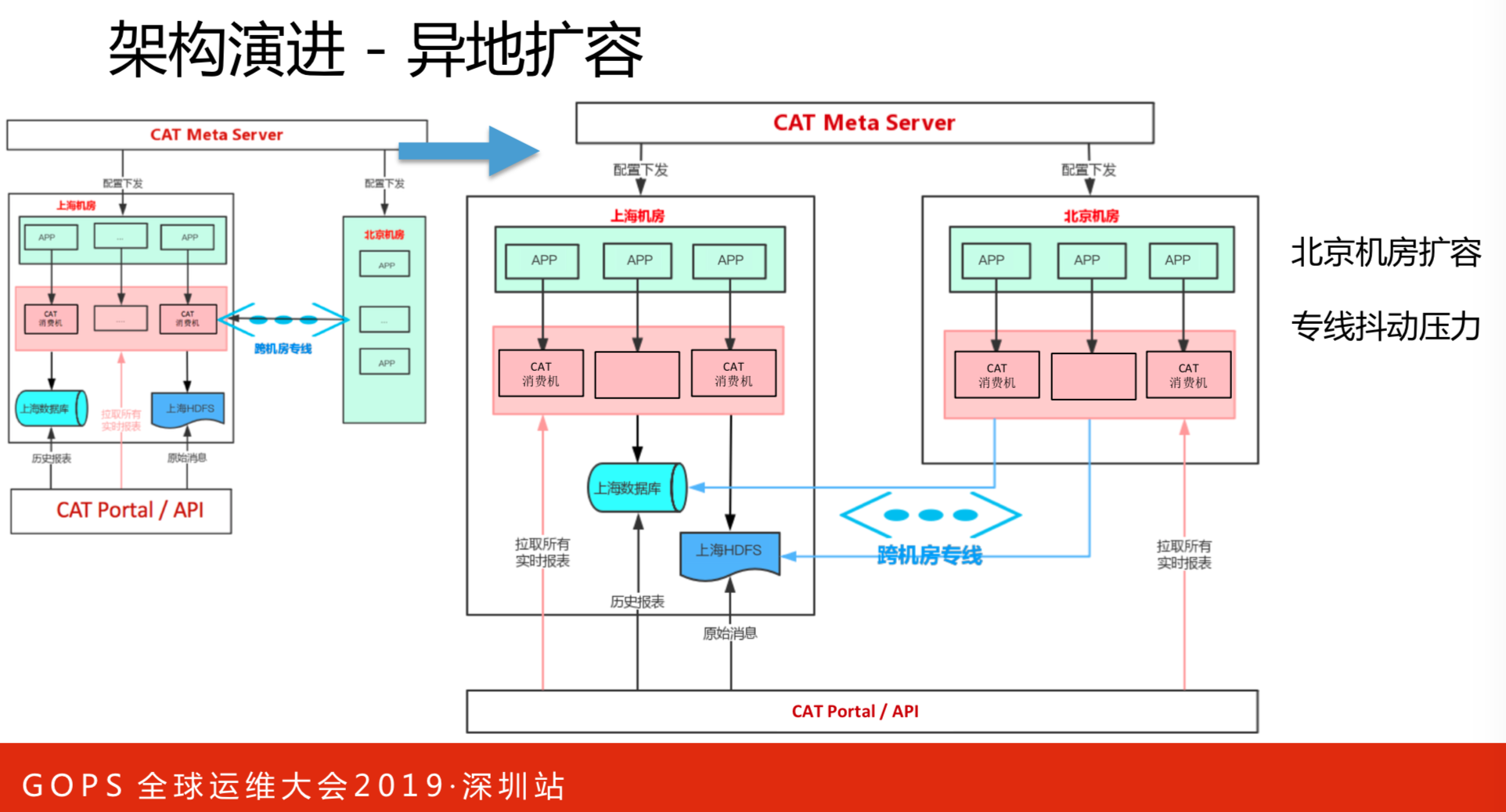
在北京机房进行扩容,这对机房间专线有压力。
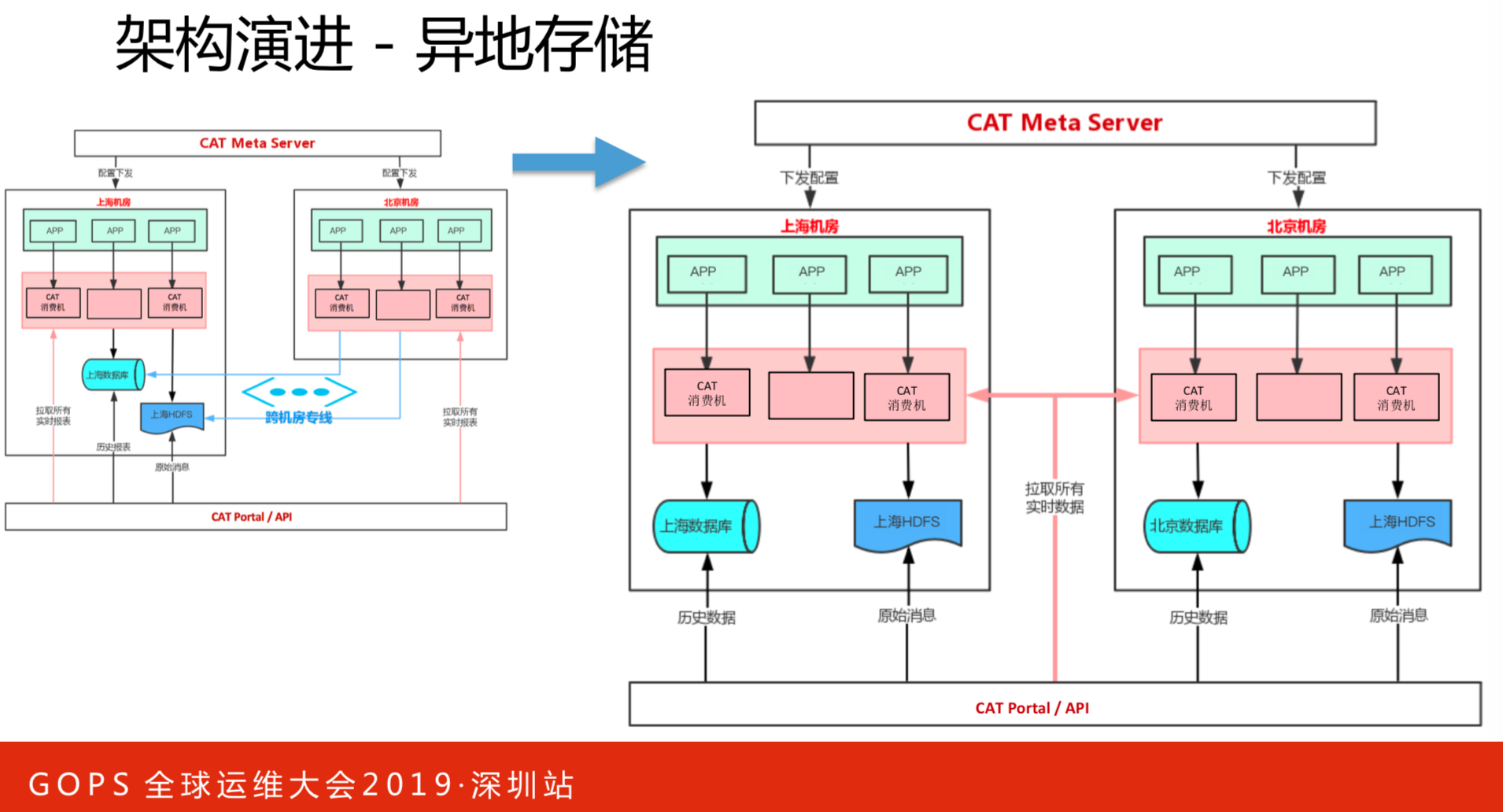
异地存储解决部分流量问题。
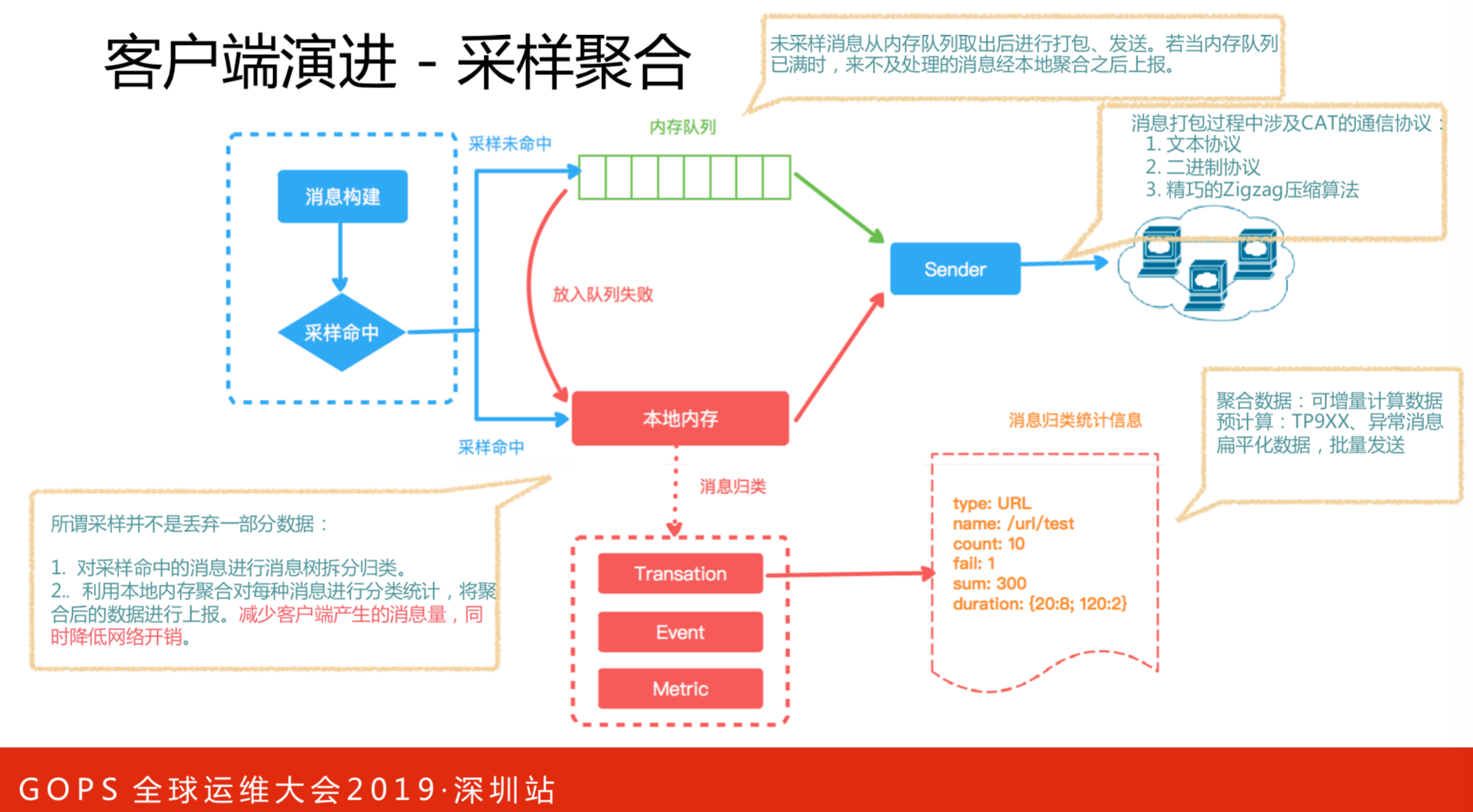
在很多监控系统里,采样都会有一个问题,如何准确的上报数据。在这上面我们花了很多工夫去做,比如一百个请求,打开了一百次同样的页面,如果只上报一次,能够保证整个数据是可以的。响应时间、请求数,怎么做到统计完整?在客户端上我们把它原始上报,还会对一些数据改成二进制数据,且进行Zigzag编码,可以有效的控制数据量。通过聚合采样,将数据量降低,同时保证基本的调用链路不丢失,而且数据还是准确的。这也是CAT区别于很多采样逻辑比较重要的点。
存储能力
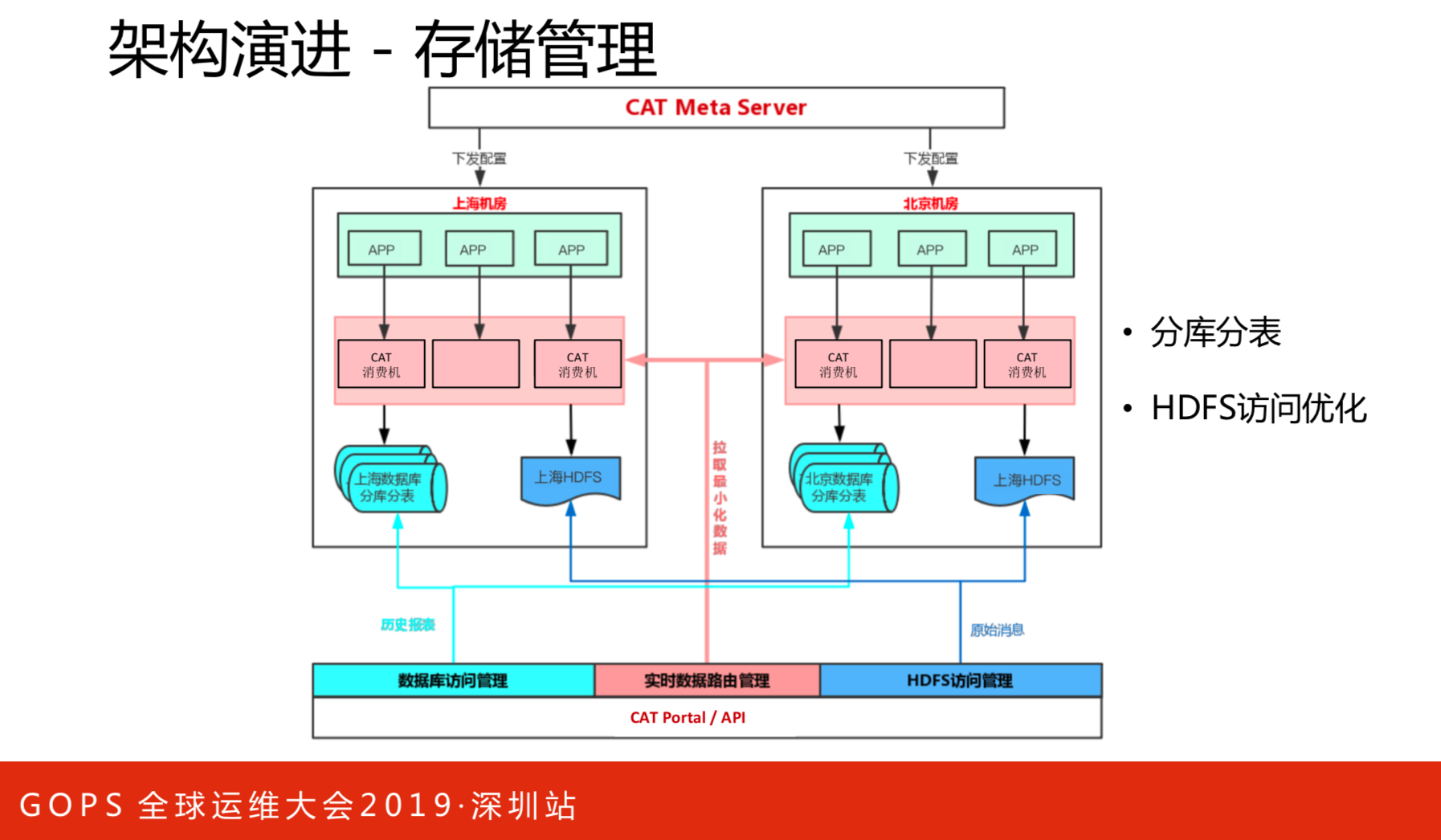
这么多消息链,最终还要落地本地磁盘上。指标会可以越来越丰富,每个指标的请求量差异很大,有的一天只有一个,有的一天上亿个。对于存储上首先分库分表是最基本的策略,还有HDFS访问优化,根据路由信息进行编译的。
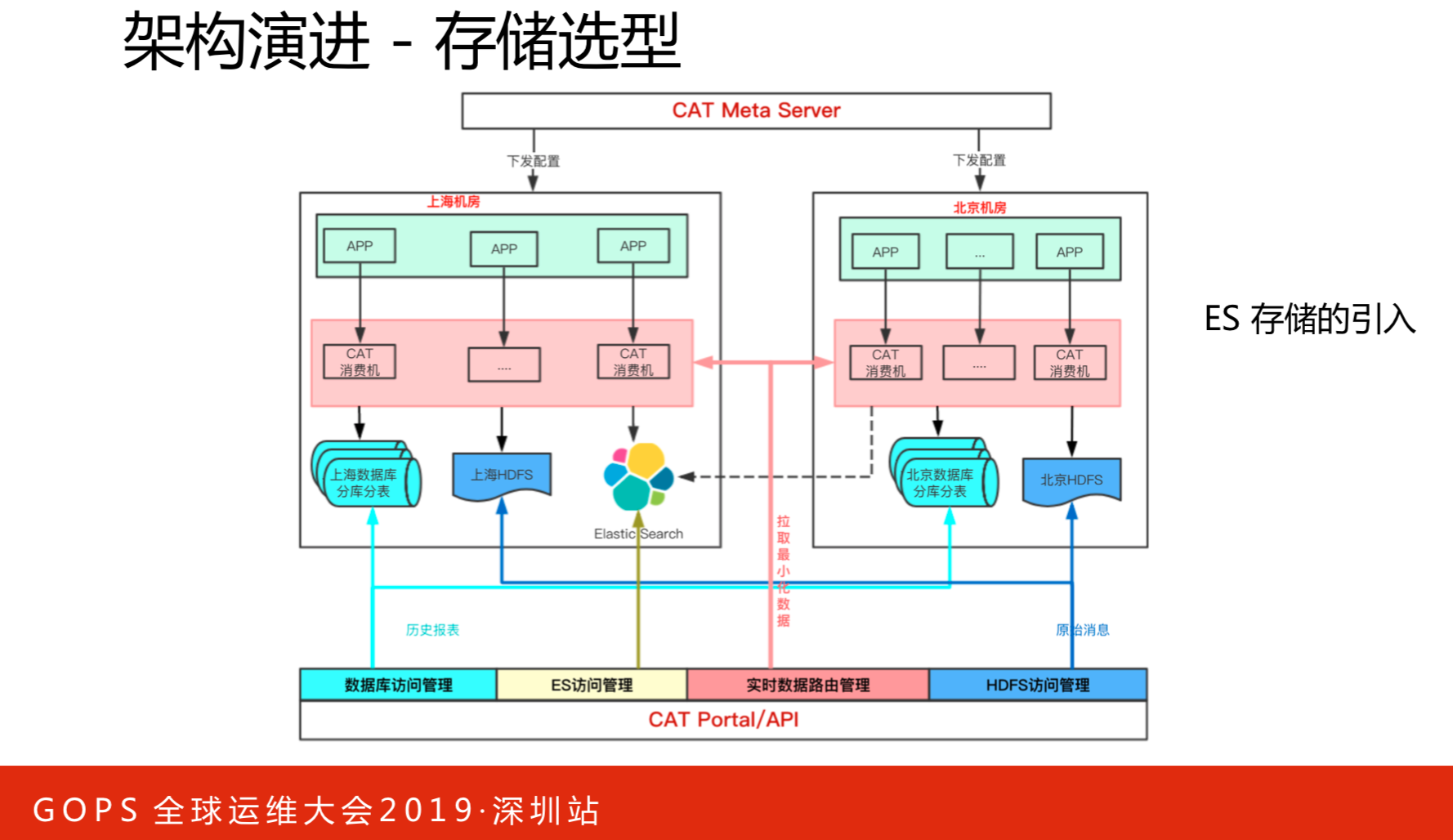
存储管理部分,比较通用的部分,还有一部分就是数据指标,比如数据指标,原本是报表,这样对于跨时间的大查询是不太合适的,原来我们也调用好多,后来选择了ES,到最后的架构就是我们异地机房内部数据的输入落地都是在机房内部,但是输出,因为输出毕竟是一个写多读少,所以我们不在意输出,输出没关系,我任意一个机房部署都可以,甚至两部分都可以,北京的、上海的,然后这部分数据是从内存里去拉取数据。
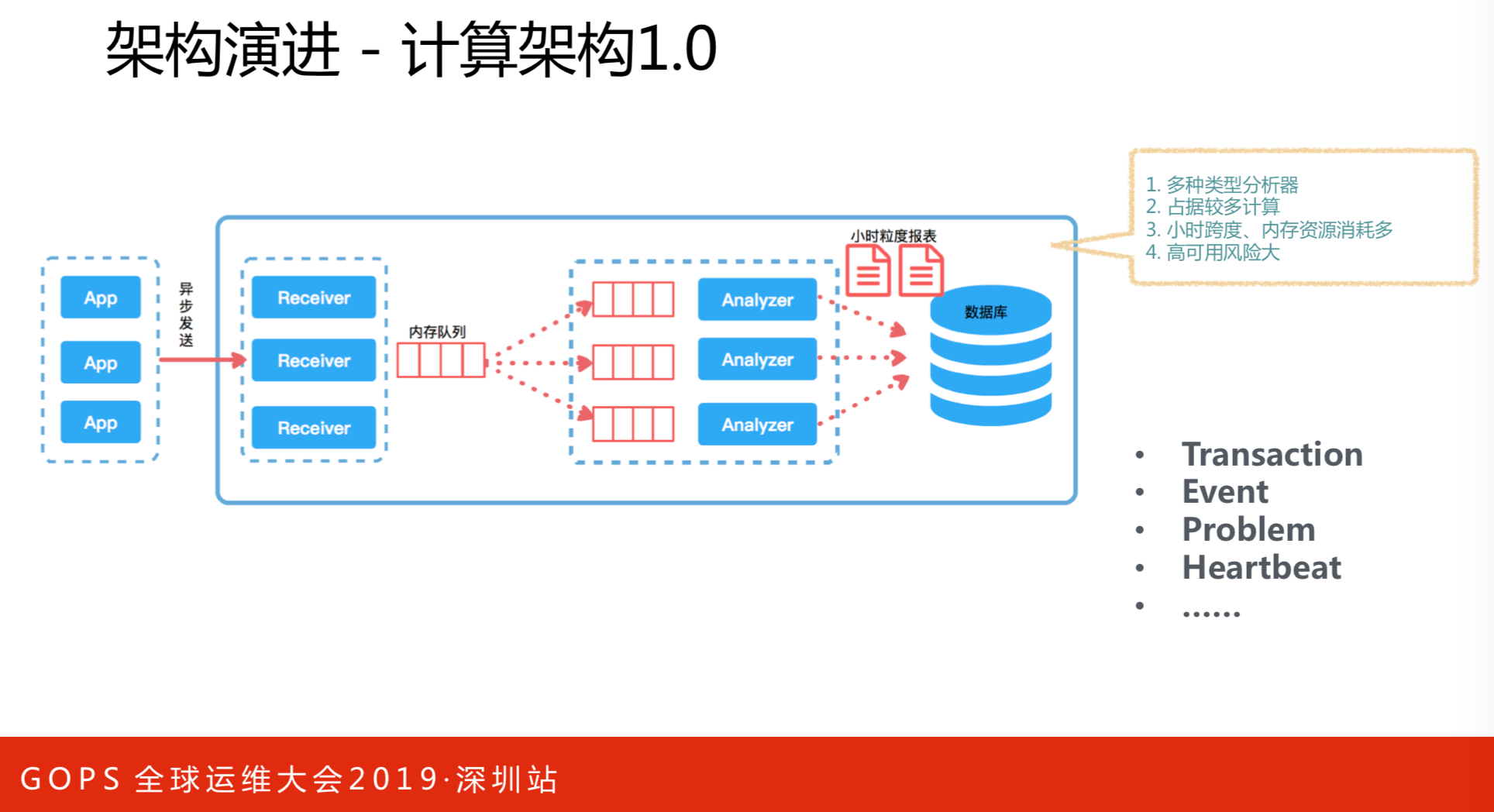
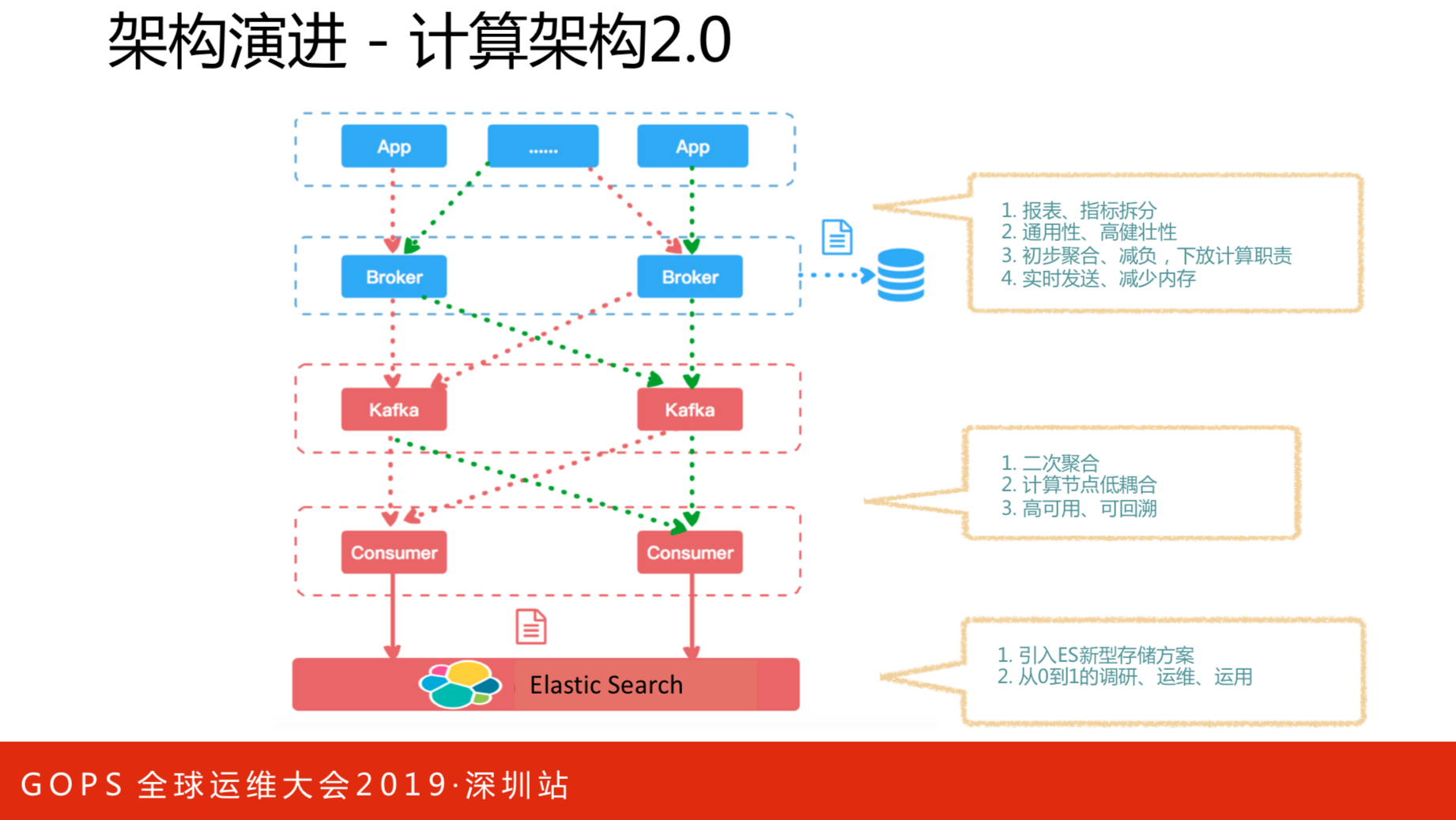
计算架构1.0和2.0版本的对比情况。计算架构就是数据流向,前面提到了水平扩展,没有纵向方面,这里涉及到纵向还有存储的选型。原始架构所有数据放在内存里面,一小时放一次,这样做的好处是访问一小时内的数据非常快,等于是一个缓存服务,所有报表都是这样的。不好的地方在于小时跨度内消耗比较多。将报表以指标数据拆分,把这部分数据通过通用模型写入KAFKA里,然后通过consumer对数据进行二次聚合,最后存入ES中。
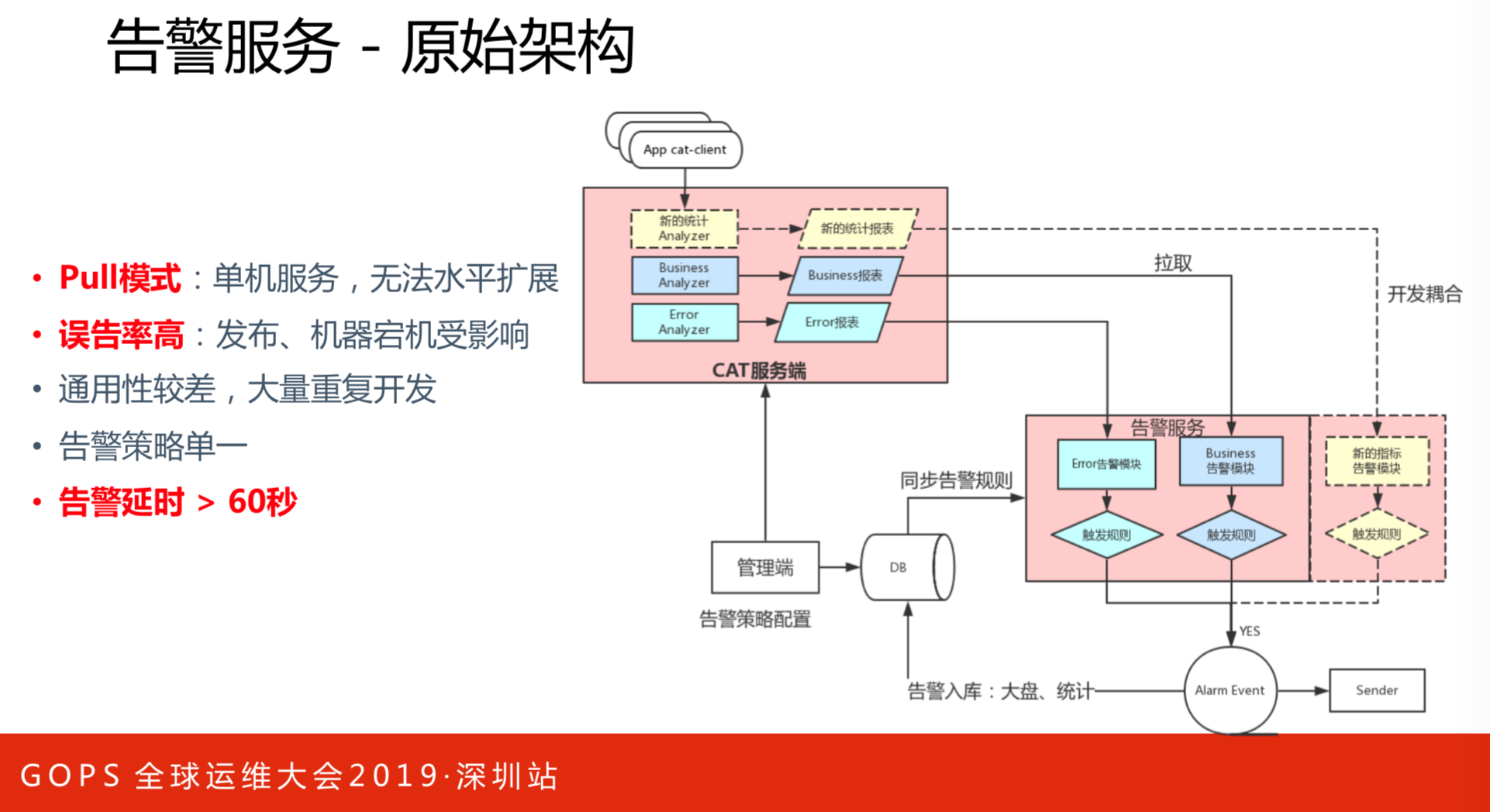
上图是告警服务的原始架构。存在的问题如下:
- Pull模式,单机服务,无法水平扩展。
- 误告率高,发布、机器宕机受影响。
- 通用性较差,大量重复开发。
- 告警策略单一。
- 告警不及时。
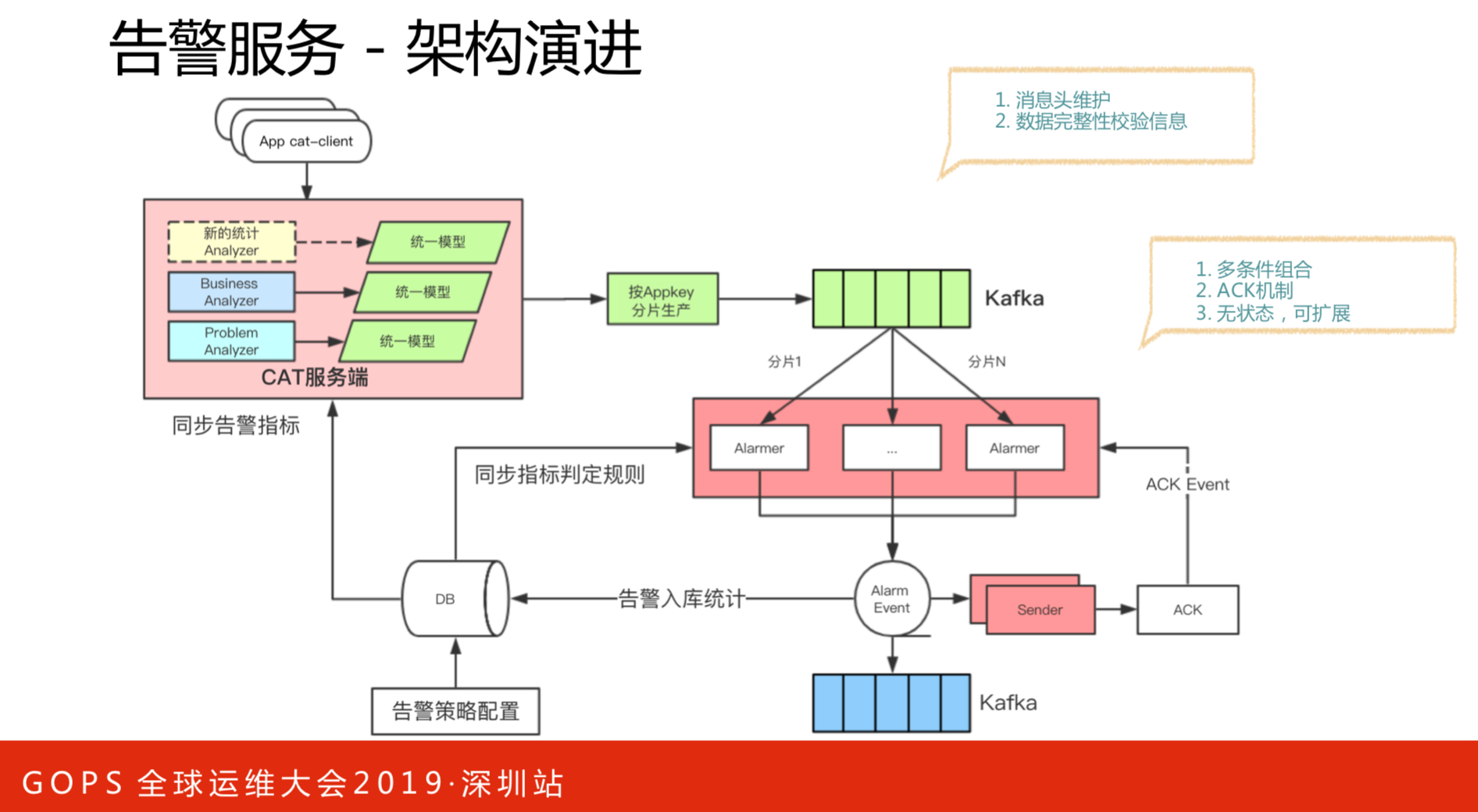
这是对告警服务架构进行的改进,能保证高可用性和可扩展性。这里引入了KAFKA,所有数据全部统一模型到KAFKA,还可以保证消息的完整度。比如一个应用分布在北京和上海机房,数据的完整性要得到保证。多条件组合,原本的告警策略单一,引入新的方式之后,可以做很多策略。告警入库统计,弹性扩容,或者降级熔断都能够实现。
3. 开源社区

2014年我们就在维护开源社区,在2018年10月份的发起了CAT2.0版本,有一些巨大的更新:
- java依赖精简。这个系统比较老,新开发者需要比较长的适应周期,我们对CAT技术栈进行了升级。
- 支持多语言客户端。如c/c++、python、Golang等。
- 采样可补偿全量。
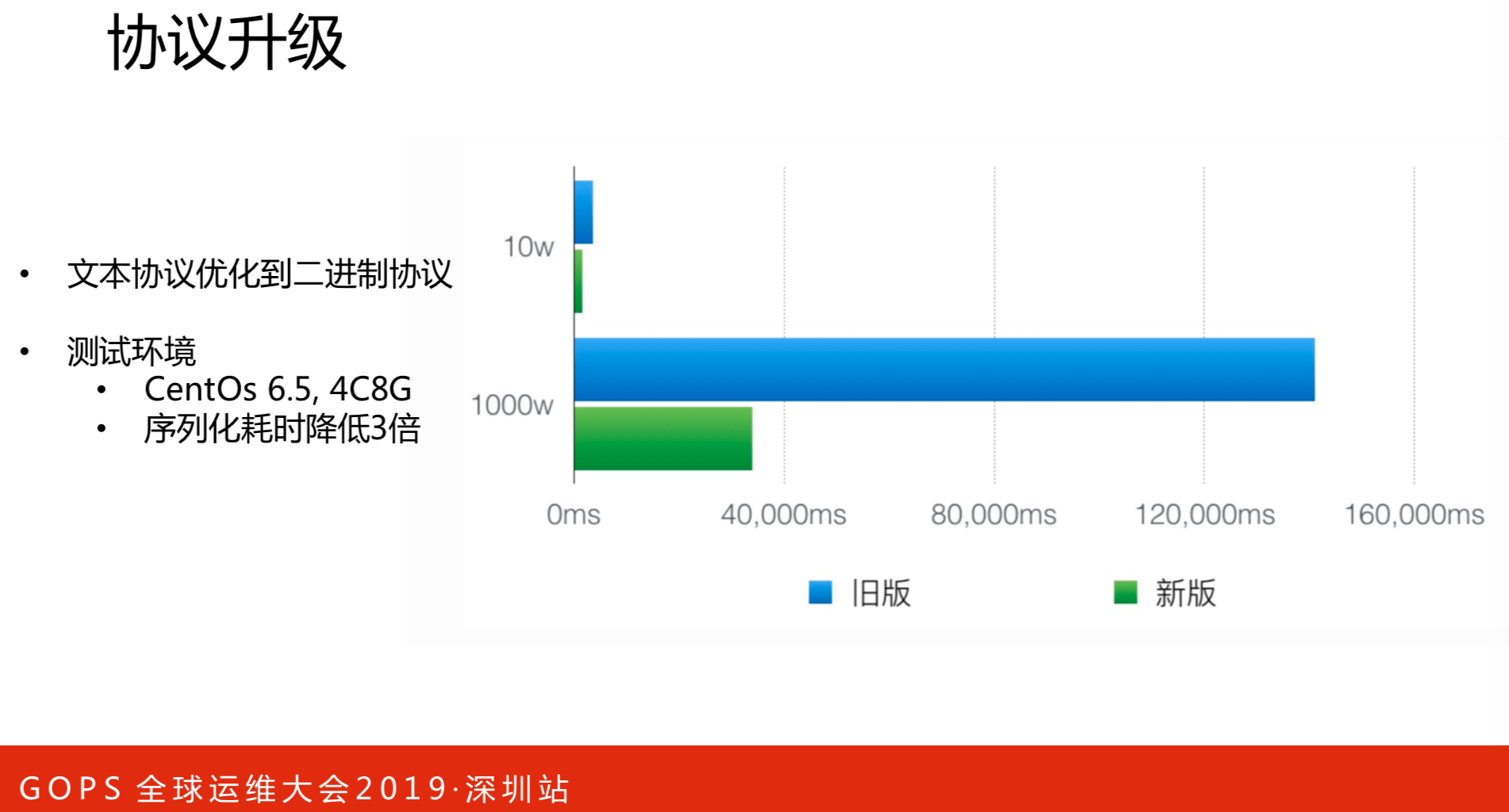
协议升级是在处理能力的性能纵向优化的,将文本制协议优化到二进制协议。效果是很明显的,右边图是新旧版本的对比情况。新版序列化耗时降低三倍,数据量也有大幅度的降低。

存储存在的问题有以下几点:
- 机器负载高,不稳定
- 单机网卡近2Gb,流量大
- 机器IO压力大,文件数较多,退化为随机写
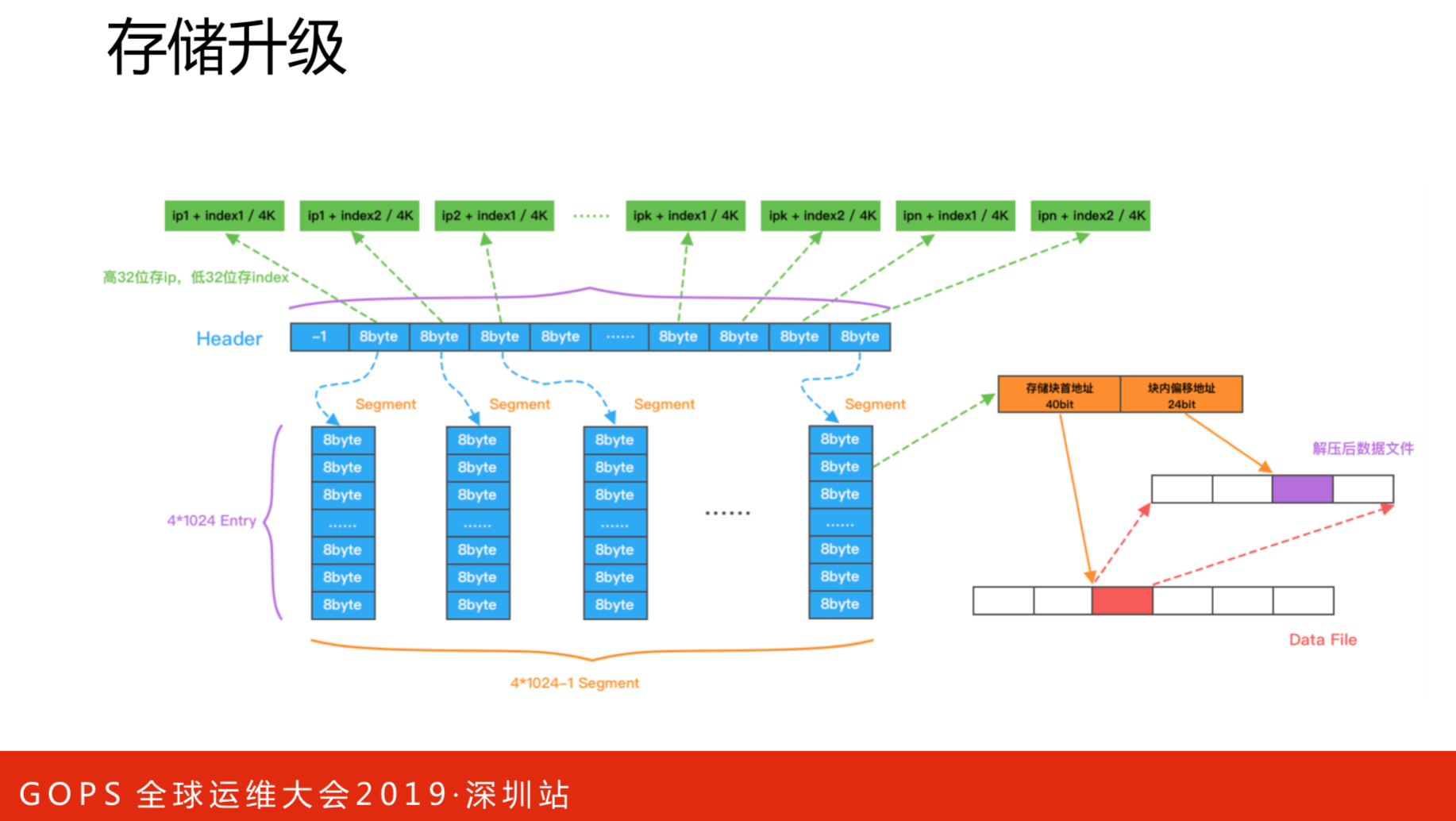
CAT不是一个文件写,也不是所有文件写,是基于一类文件写在一个文件里。比如一个应用,把所有IP,一千台机器写到一个文件里,这么一个简单的操作会带来非常复杂的一些逻辑,大家可以阅读下源码,这里就不展开分析了。
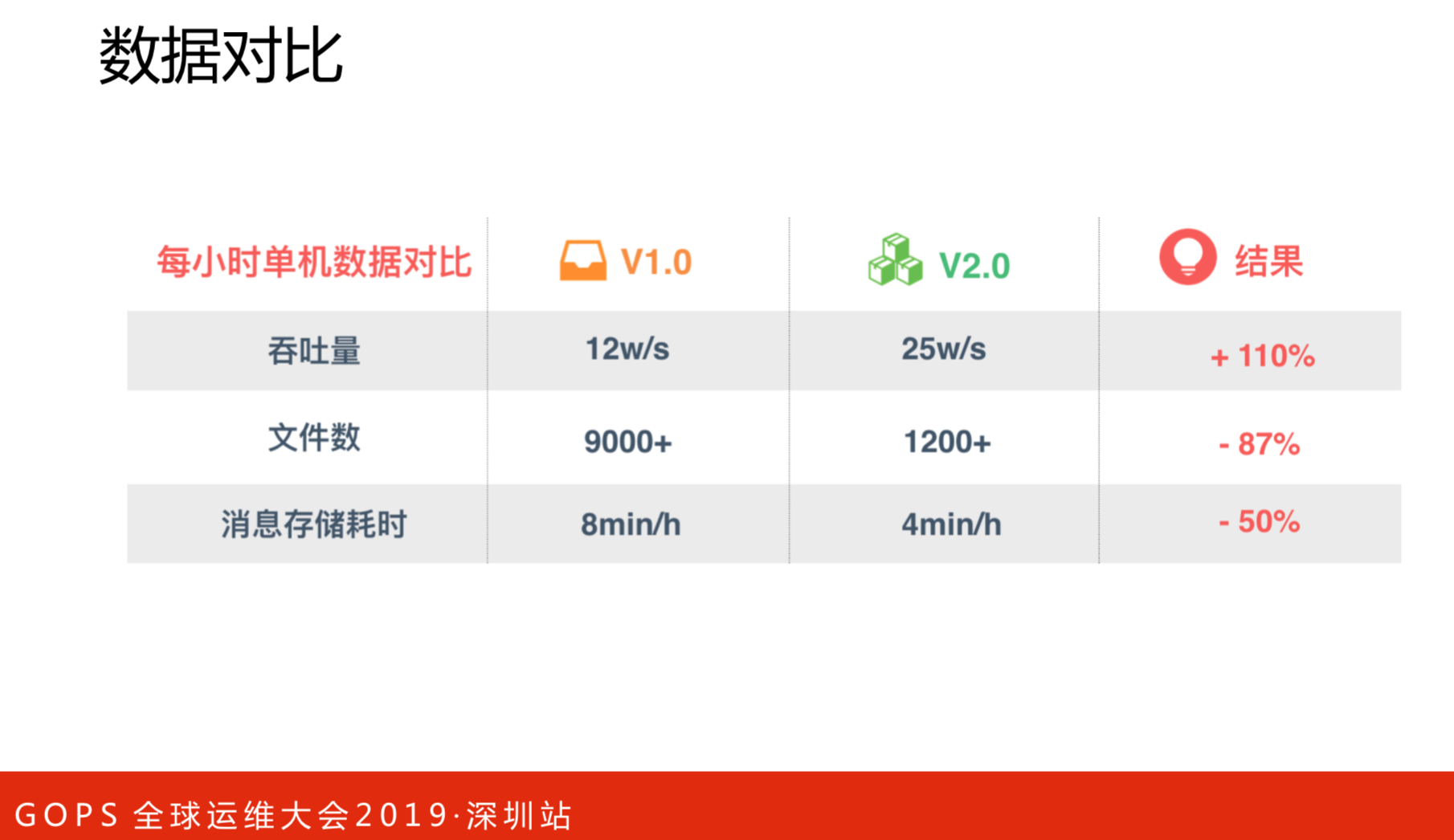
上图是数据对比的测试结果,吞吐量提升了110%,文件数降低了87%,消息存储耗时降低了50%,效果非常明显。

现在CAT有了新的logo,我们会持续对CAT开源支持,首当其冲的就是技术栈的升级,全部去掉陈旧自研的开发框架。还有产品体验上也得到了加强。上面是开源建设的链接,希望大家多多支持多多交流。
