@gaoxiaoyunwei2017
2019-02-14T06:41:38.000000Z
字数 7123
阅读 1251
智能运维:质心算法实现网络故障无差别自动定位
luna
作者:朱锋 网络运维监控专家
谢谢大家,其实很荣幸今天来到这个舞台来讲这些东西,我今天的主题是叫智能运维,我们用的质心算法实现网络故障无差别自动定位,我来自广东移动,一直在监控一线的工作,说简单点就是监控值班人员。
今天上午讲的平台我不太懂,架构我接触的也比较少,所以说今天只能讲一个我实际工作当中的案例,其实是一个小而美运维的实践。
看到目录就和他们不太一样,大家都是做运维的,都知道运维的困难非常多,但是我们运维人的办法更多,办法比困难多,很多办法的效果还不错,特别在DevOps时代,运维开发,然后人工智能这些工作,运维的未来其实是非常值得期待的。

1. 困难--有很多
第一部分先做个广告,大家接触过的都知道,2015年移动推出VOLTE业务,VOLTE就是高清语音业务,发展很快,现在基本上已经有4个多亿的用户,最大的优点,接通时长非常短,2.7秒,推出高质量的语音业务是有代价的,代价是网络越来越复杂了,目前这个网络是我们接触的最复杂的一个业务。

这个其实就是一个简单的视频,当初的时候我们内部培养要花很大量的精力,当时让我们自己人掌握VOLTE的流程都花了很久。这个图也是当时画的,2015年画的第一版,今年更新了第二版,也是给内部人员学习的,基本上是我们的这种核心网的示意图。为什么放图在这里呢,其实只是感受一下网络的复杂性,因为我们维护对象就是他们,我们要保障这张网络的可靠。
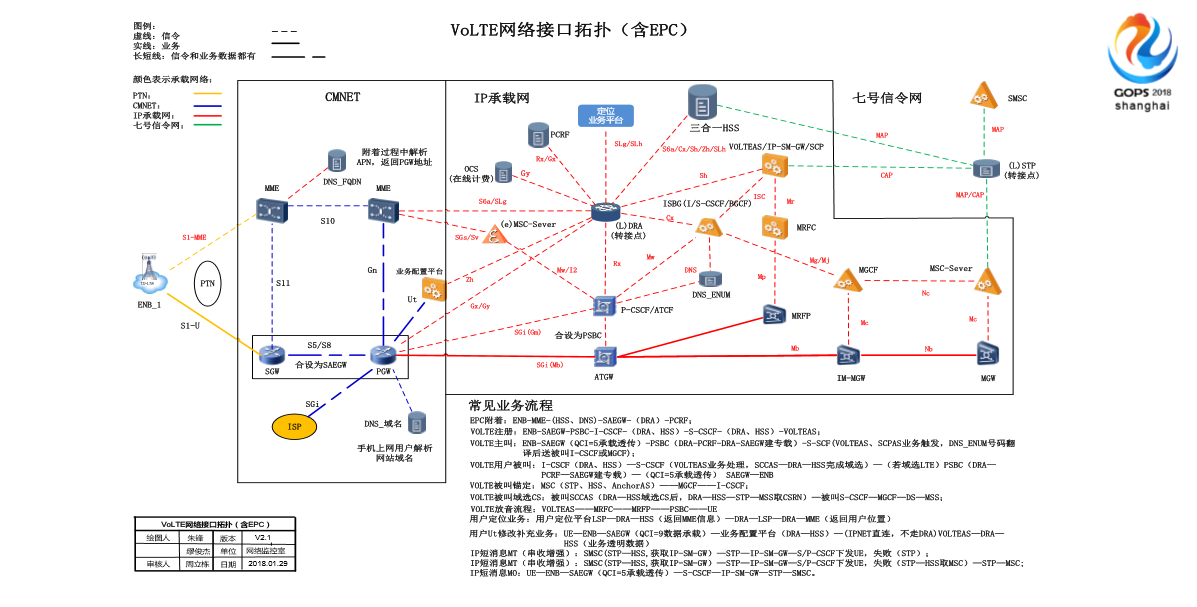
其实左边这块就是接入网,就是用户直观看到的各种铁塔,这边是中间以前4G的核心网的架构,简单就是这种基本逻辑的核心架构。右侧比较多的红色虚线连起来就是复杂的VOLTE新引出来的,具体不展开讲。我们跟互联网的企业差别非常大。
同样也是来体现这个复杂性,不仅是说刚才的图讲这个原理业务非常复杂,但是我们移动端还有另外一个特点,我们的网络是中国最大的,而广东移动也是我们中国移动基本上全国最大的省级网络了。
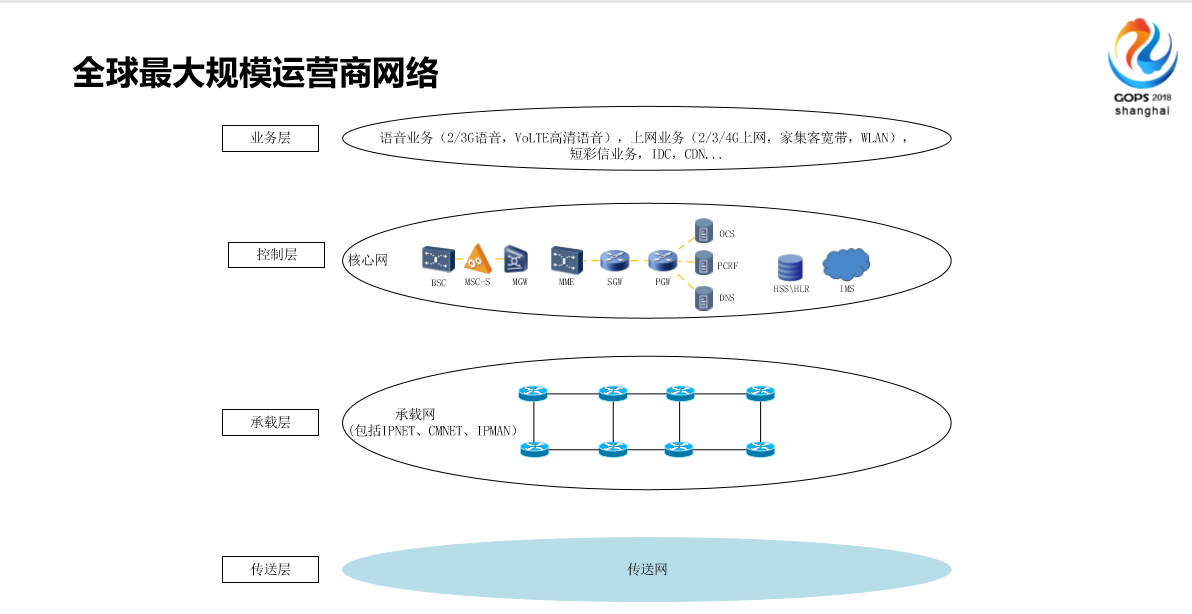
右边这个图系我们内部画的简单的示意图,我们的网络基本上分这种概念,底层这几层是庞大的传送网,基本上就是动力设备这些保证连通性的,中间是一种承载网,大家知道路由器组成的,上面才是我们的核心就是控制层这块,根据技术的演进,从以前的2G到现在的5G,每一代的网络侧重特点不一样。在这些网络当中我们提供了多种多样的业务,现在的业务越来越个性化了。
简单给大家看这个数据,之前放了一个数据在上面,这是目前我们广东移动的数据,登记用户数目前大概1.2亿,这个是总的用户数,全部在网的,不包括物联网。4G用户数占了三分之二,有8000万的用户已经在使用4G业务了,说明老人机还是很多的。4G用户当中其中7100万开通了VOLTE功能,有3600万正在使用VOLTE功能,家宽业务今年发展比较快,这两年刚起步,现在广东是1200万左右。流量今年长得很猛的,今年各个省推出了不限量套餐,以前我们日流量14个PB,家宽流量好像40几个PB,话务量我们日均2000万,什么概念呢?如果按照我们1.2亿总用户数来说,也就是平均用户每天通话10分钟。这是我们业务的规模,非常大的,支撑这个业务规模我们的网元数130万以上,日均会产生530万以上的告警,我们会派发3万多的工单。
所以说其实我们的挑战非常多,简单这里列了两个,一个是随着技术的发展,我们的核心网已经由过去这种单一的网络演变成多网协同,多链路交织的。我不展开讲,基本上就是说主网的结构会越来越复杂,我们的通信的网连形态跟互联网是不一样的,我们的网联形态非常多,业务需求比以前更丰富了,以前用户能打电话,发短信、上网就可以了,现在越来越复杂,越来越个性化。现在问题多,这是第一个挑战。
第二个挑战是NFV演进,我们以前自己叫CT工程师是做通信的,我们维护的是通信网络,我们的设备都是专用的,大部分都是专用的,也就是说我们都是各个厂家定制的不同的功能,而不像大部分接触的都是服务器我们现在大家说NFV演进的功能虚拟化了,以前专用的设备不用了,现在全部用X80服务器,加载不同的软件实现通信的专用的设备,对我们来说是网络更复杂了,是整个通讯更复杂了,右边的这个图,以前我们有一个叫OTS(音),现在可能惠普给我们提供了一些服务器,把这些服务器组成一个资源池,然后华为说你按照我这个设计。
基本上就是左边这种列的总结,不会太展开,基本上我们提的这几条,对我们的人员要求不仅要懂CT,还要懂IT,我们做“ICT”融合的人才。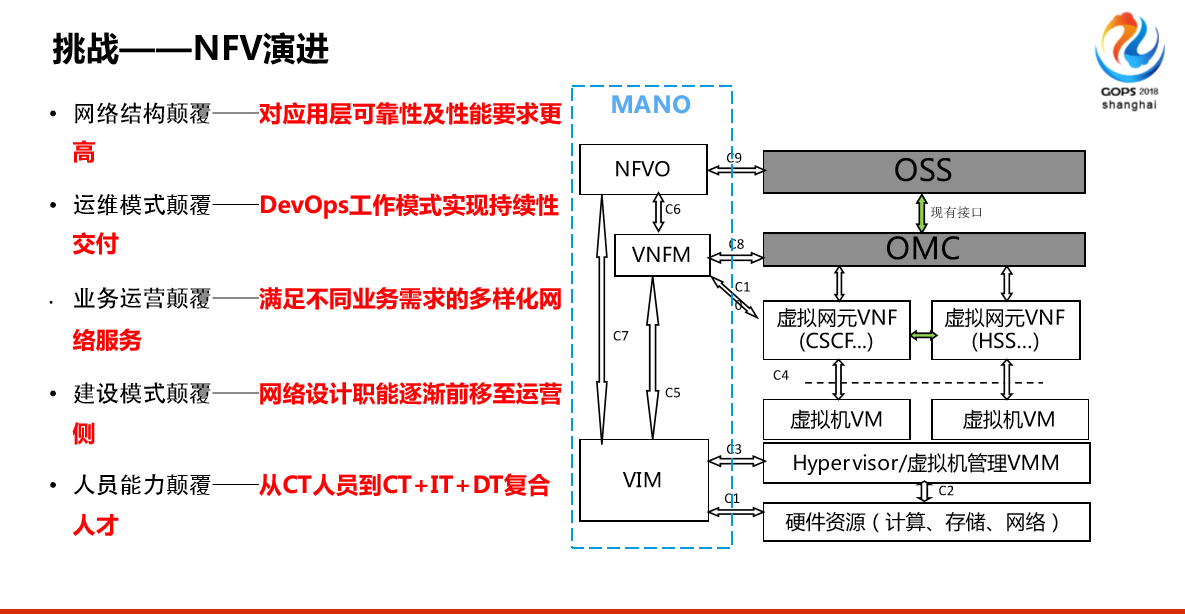
其实网络这种变化,我们现在内部的职责现在在调整,现在我们可能要成立专门的IT资源的部门,底层的这种。
看一下我们的工作环境。(图) 看起来高大上,其实挺苦逼的,全年无休,24小时加班。平时日常工作就是一忙起来就是三五个人聚在一起,要协调处理了。没事的时候相对好一点。特别是春节,节假日我们是比较更苦逼一点的,平时还能休假,一旦到了节假日你没有任何理由请假。刚才说了我们的网联功能很多,我们的维护或者说我们的工作流程,我们保证130多万网联正常的工作,我们怎么干的呢?现在还在干的套路就是用不同的采集机,把信息都采集上来,每个省不一样,第三方厂家把这些信息汇总起来,我们那些监控人员就是跟着它,有问题赶紧处理,最怕的就是出现红色的,红色的时候可能要影响业务了,第二怕的就是突然闪屏了,满屏幕都是。
看起来高大上,其实挺苦逼的,全年无休,24小时加班。平时日常工作就是一忙起来就是三五个人聚在一起,要协调处理了。没事的时候相对好一点。特别是春节,节假日我们是比较更苦逼一点的,平时还能休假,一旦到了节假日你没有任何理由请假。刚才说了我们的网联功能很多,我们的维护或者说我们的工作流程,我们保证130多万网联正常的工作,我们怎么干的呢?现在还在干的套路就是用不同的采集机,把信息都采集上来,每个省不一样,第三方厂家把这些信息汇总起来,我们那些监控人员就是跟着它,有问题赶紧处理,最怕的就是出现红色的,红色的时候可能要影响业务了,第二怕的就是突然闪屏了,满屏幕都是。
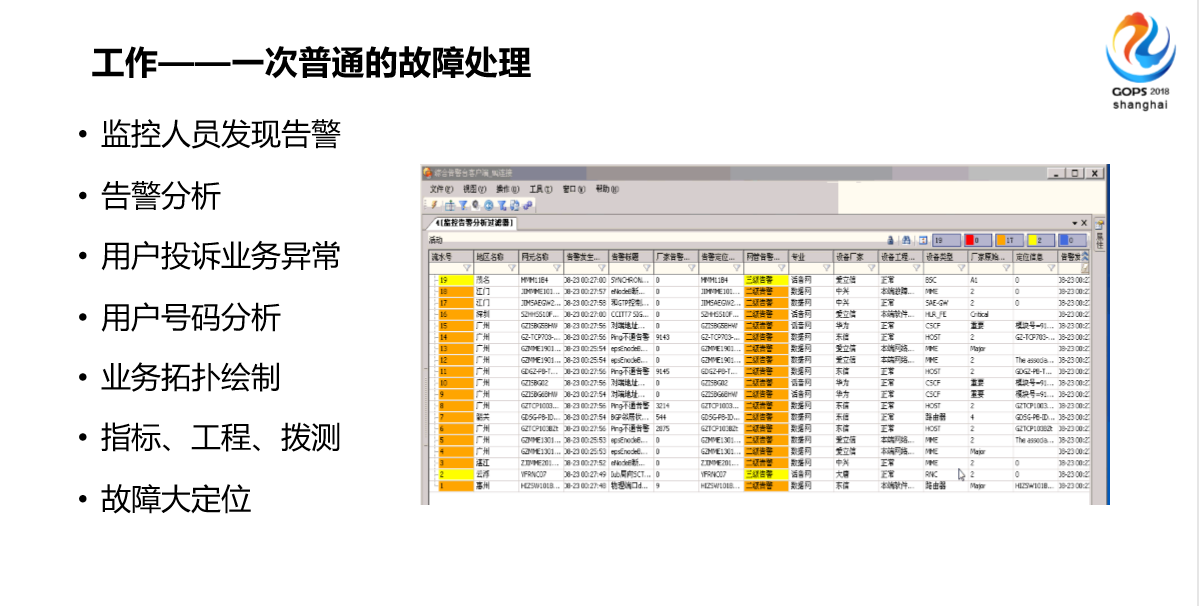
所以说我们的工作基本上大部分就是盯着它,重要的时候,像这种一次普通的故障处理会涉及到很多东西,比如首先发现告警,或者说你收到10086转过来的投诉,一旦有10个用户以上的投诉我们就怕了。
如果这个时候有投诉,要结合投诉的信息,因为投诉基本上打投诉号码我们对号码进行分析,号码做分析主要为了结合这种业务,包括拓扑绘制,前面Spark是全链路的拓扑,我们可能绘制这次故障,这次用户投诉相关的图,绘制这个图很需要经验,非常复杂,你到底画哪些,哪些不画,因为要把关键的信息呈现出来,我们要查工程,工程就是变更,我们要多测业务指标,我们的监控相对来说做的比较前一点,我们不仅仅是说看到就行了,我们做了很多后台专业的,所以我们要实现一个定位。
其实说困难很多,总结得不是很到位,其实基本上网络这个东西越来越复杂,所谓的四代共生,2345G都有了,最关键的是对我们的人员要求更高了,我们的人员流失非常大,越来越招不到高质量的人才。以前大家知道招聘平台是挺严的,现在大班可以进的。所以说我觉得运维人员还是不足的,我们整个一直在做的都是想谋求运维转型,当年我们想做这个方面转变的时候也没有想到这些高大上的名词,就是想工作简单一些。这是困难的一部分。

2. 办法--比困难多
分享一下办法,其实办法说高大上一点,标准化、自动化、智能化,大家都提了。我们今年集团提了一个IT换人战略。我们当年想改变的时候,我想不到IT化,我只是想面临的这些问题处理起来少一些,不要遇到下一次故障的时候会自己再背锅,类似于这种,没有及时发现,没有及时处理,仅仅是这个想法这个出发点。
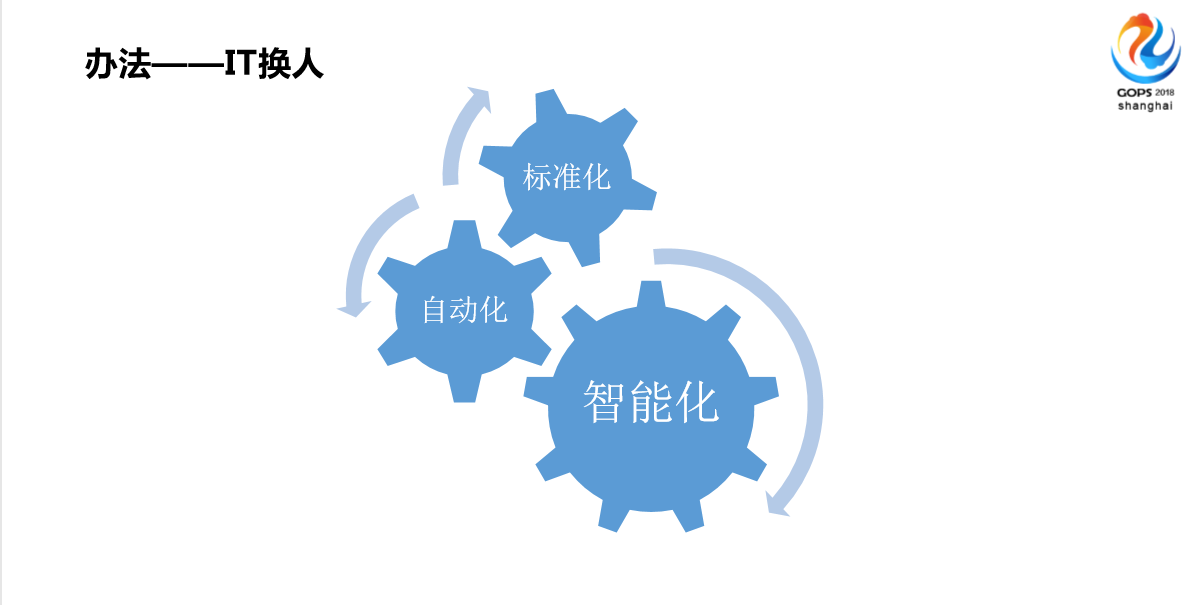
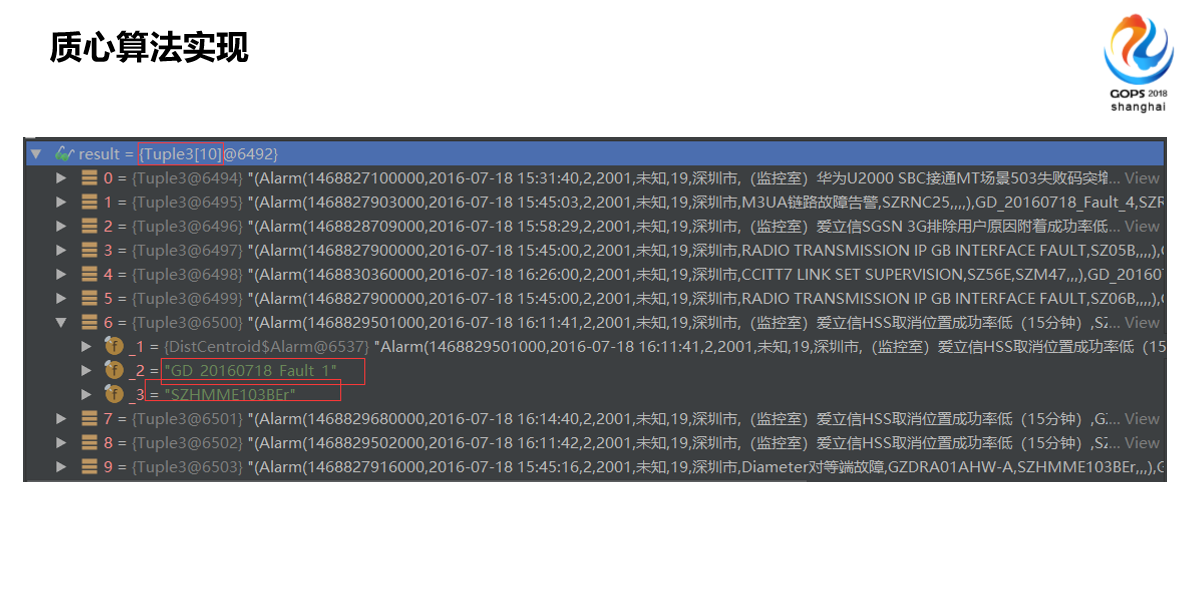
首先我们做了一个标准化的事件距离模型,这是干嘛用的?刚才大家看到的,以前我们处理告警的时候很重要的一步,特别是海量告警的时候,我们首先会做关联分析,以前做关联分析非常依赖于专家经验,他知道A标题和B标题,A告警和B告警关联度非常大,我们把这些规则提给厂家,然后他们做配置、开发、实现。但是现在虽然还在干,但是已经越来越不能解决各种遇到的问题了,主要是网络太复杂了,技术更新化太快了,我们学4G没有多久,马上又学5G了,所以说再厉害的专家不能在短时间分析关联出来上千条告警,我做这个事的出发点,2016年中的时候一个非常小的故障,当时我们三个工作五六年的老骨干在一起花了基本上快半个小时才大概找出来原因,700条告警。
当时觉得很郁闷,那次觉得以后不能再这样了,再这样肯定不是办法。所以当时,记得那段时间失眠,晚上睡觉的时候基本上会想这个问题,基本上快忘光了以前的数学知识,会想着量化,把以前定性的分析变成定量的,我量化任意两个告警的相关性,第一个考虑的是距离。

有这个想法以后,当时经过了一系列的优化,大概有这个结果,为了这个结果基本上首先我们拓展了,虽然开始的出发点我们想做告警,其实后面我们做的不仅仅是告警,是我们运维接触任何一条异常事件,一个客户投诉了,一条日志,我们提炼出来目前主要这个事件发生的时间和位置,当然其实如果考虑精确一点的话是应该发生什么事,这三个因素。
其实我们在做的时候发现前两个因素更重要,什么时间、什么位置发生的异常点。这是我们提炼出来的因子,可以说是因素,这个模型我们想定义标准化的距离,当然距离越小越相关,这里面再点一下,这里面发生的位置其实与我两个位置之间找到定义距离,其实有考虑过类似现实世界的物理距离,我们所维护的是运维的虚拟世界,我们考虑的是虚拟世界的拓扑距离。我当然还是想总结出类似万有引力这种公式,当然这很难。
我觉得两个事件间的距离肯定跟它发生时间差是有关系的,以及它发生的位置和位置的拓扑距离,这只是我尝试的一个理论公式,后面我实际做的时候是一个近似值,我觉得工程和理论是有差别的。
看一个我们通信网络的例子,图画的不是很好,这是2016年我说的让我下定决心来转变的出发点,当时这其中挑了两个事件,一个是BSA,它控制了你们看到的铁塔,一个BSA可能控制一百个铁塔链路。另外一个负责DRA,出现的业务故障到底明显告诉你的最多的这也是我们花时间做出来的,我们做了一些提取和优化才能够在这条异常信息里面呈现更多的信息。
这两个事件在我的标准模型里面简化成距离是0.15,为什么是0.15呢?差了16秒,它们两个的拓扑,实际上按照原始的套路应该要+1,当然后面我忘了A点到E点的网联,所以说由于这个DSC(音),这个依赖于我们的资源关系,网络的拓扑结构,这个数据我们是有的,所以说我们依赖于这两个节点之间的这种连接关系,我们定义了这种事件,这个叫逻辑之间的配置。当然还有其他的连接关系,比如说两个网线插起来,就是基于这种关系。
简单说一个例子,说明这个事是可行的,是一个理论的考虑点、出发点,有了距离还不行,得有算法,刚才说了传统的告警关联基本上是定性的,因为标题都是文字的,不同厂家,华为是中文的,电信还是英文的呢,就是需要定性的专家来定义。
一旦有了标准化的度量以后,一旦定量以后它就可以自动来学习了,机器学习可以来分类。2016年我对这个只是小白,只是听过这个概念,但是怎么干这个事不知道。所以2016年中开始看书,发现其实有很多成熟的算法,你们应该比我知道的更多,比如说聚类分类的算法,当时结合自己通信的业务场景挑了两个,一个DBSCAN、还有最近邻。一开始两个都用,后来优化了,我们结合在一起了。我采用了聚类DBSCAN里面的EPS邻域的概念,然后采用最近邻的概念,把两个结合在一起做了实时的关联算法,可以说是两个结合。

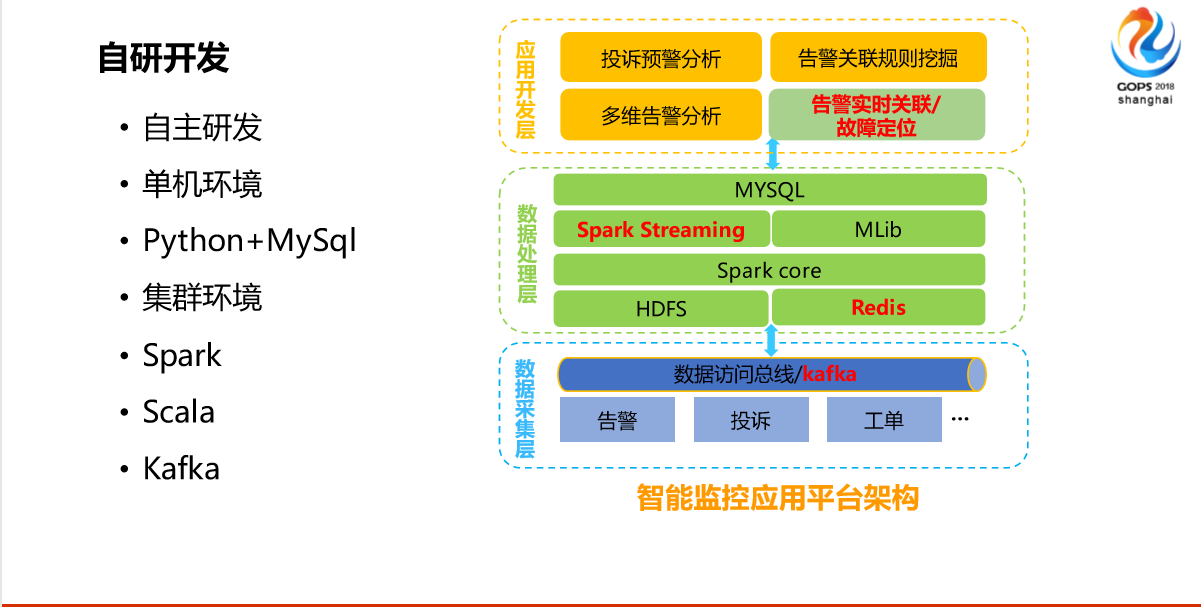
前面这两部分介绍了距离和算法,有了理论的基础。其实在以前就算有这个想法也没用,为什么?因为我们运营商有这个想法也开发不了,我们的套路是你有想法你有需求你提,会有第三方的厂家帮你开发,会有排期的流程,基本上随便哪怕一个小的需求可能半年,半年需求出来以后跟你想的完全不一样,这是没有办法的事。可能当时不具备这个条件。
我觉得这一点也是不可或缺的,就是现在移动公司在转型,在推我们内部做自研开发,相当于推了我们CT的工程师要转学IT的东西,我们集团要求每个员工都要懂编程,还要考试,我们广东移动从2016年开始组织自己员工自研的开发大赛。
3. 效果--还不错
现在有了这个条件,自己开发的这种条件,如果是以前的话还是做不出来的。当时2016年,我接触的IT还相对早一点,我2016年有这个想法以后就开始学。当时学语言就写Python,JAVA我不会,写不来,写Pyhton因为它简单。特别现在很多脚本都是Python写的,所以2016年底的时候,很简单,我们就是一台服务器单机的,用Python的思路把距离、算法实现了,然后存到库里面去,看起来不友好,看起来不爽,又开始自学前端,当然前端那种界面做出来了,效果能看出来。
基本是上这样,基本上从2016年有想法,到2017年有了可以看的前端,基本上一年多的时间,后来集团公司发现还可以,觉得这个想法可以做,然后全国挑了5个省来试点,试点了半年确实可以,那就做。
所以说我刚才说的办法这部分有算法,有模型是一方面,但是赶上这个DevOps好时代,自己能开发的,什么东西掌握在自己手上,其实我们现在内部开发人员开始学Python,学的东西越来越多。
总结一下我们整个为了解决之前的困难的办法,我们也不算发明,有了一套新的理论,我们自己现在去实现它,然后慢慢优化它,这个优化的过程现在一直在运行的,今天我们集团公司内部开这个讨论会,只是会议通知比这个晚,我没办法,所以优化还是在一直优化的,这个掌握在自己手上。
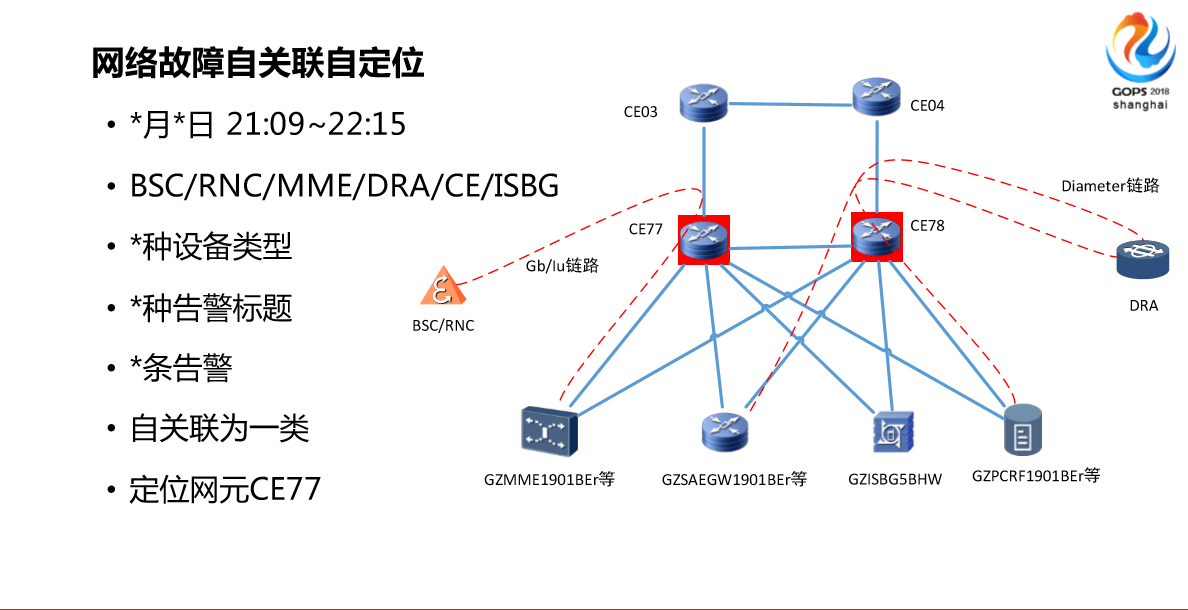
简单看一下效果,效果我觉得还是不错的。看四个方面,第一,大家可以感受一下,右边(图)夜班的时候,值班人员发现刚才那个窗口少了,一个告警出来,我们基本上是DSC、RNC、MME、DRA、CE、ISBG等不同系统的,我们列出来的系统有7种设备类型,35种告警标题,总共是5000多条告警,我们的系统是自关联为一类,会自动定位网圆EC77,事后还有一些专家,后面专家分析就是CE77和CE03,因为他们的传输还是最底层的,传输的节点有问题,另外一个问题就是有一定的依赖资源,你想知道底层传输的东西,你拓扑信息了解得越多,它的的定位关联越准确。
再举一个例子,我们叫做精细化的变更管控,变更就是我们说的功能操作,我们的网络不仅大,变更非常多,每天都在做操作,日均两百起以上,我们主要的功能操作在夜间做。从12点经常做到4点,这段时间做。
变更的影响也是非常大的,70%都是变更告警,变更导致的。我们影响大的故障都是夜间告警。有了新的架构我们是怎么做的?我们现在把变更当成普遍的异常事件了,它有变更操作时间和变更操作位置,所以说会自动告警进行关联,反正套路是一样的,没有更多的调整。
关联以后的效果,我们发现和过去的方式有提升,提升了25%。还有一个提到精细化,精细化是什么意思呢?以前变更或者变更管理是比较粗放的,只要这个网联有操作,那个时间段产生所有的关联都打上这个标签,但是这个是不合理的,有可能这个操作只是很小的这种调整,但是由于工程人员的失误或者其他原因,可能会遭到投诉。
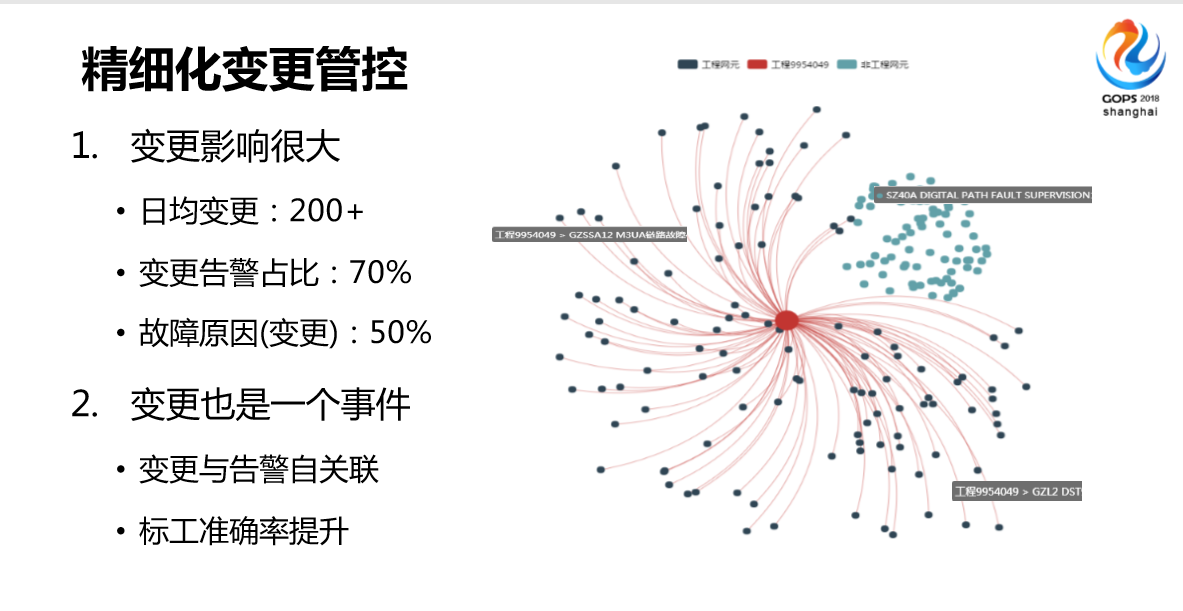
以前的话,这种工程处理可能不及时,因为大家知道夜间的时候人相对少一点,告警会多一些,工程告警我们既然知道有人在操作,所以相对处理的不是很及时。
有了这种标点以后,我们做进一步分析,就是这一类工程会导致哪些告警,不会导致哪些告警,我会学习后台一些规则我会分类的,比如说一类工程会导致1234,而不会导致3456,就是更精细化了。
这是第三个应用,建立了一个智能研判系统核心算法,也是平时故障处理的时候用的,故障处理更多的用在批量投诉,超过10个用户以上投诉的时候,我们会串联这些东西。当然以前案例的分析也可以做,只是现在把算法作为其中一个核心算法,就是说你一旦创建了这个故障的这种案例,会把这些故障期间相关的警告点全部收上来,算法自动把它关联成若干类,相对来说以前可能关注5000条,现在已经帮你关联好了,三类,定位的力度、范围是多少,这是我们研发系统这块。
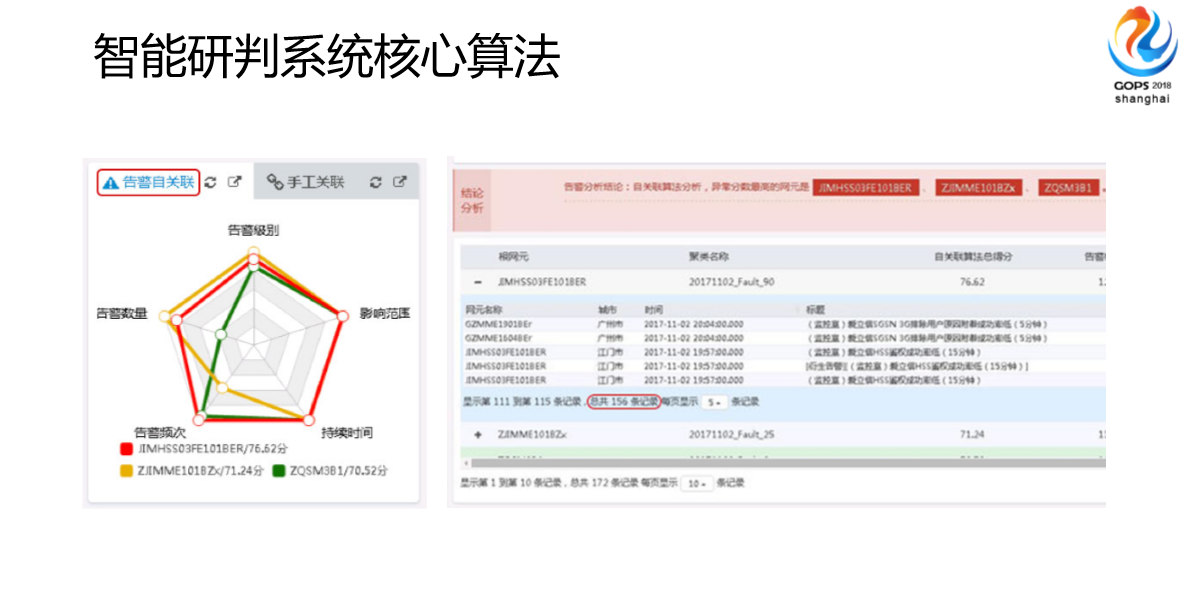
这个是我们集团开发的界面,就是我们现在在做的,到时候和各个省级推广的就是这个。底层架构比我们更全一些,只是说这些算法,我们广东公司最开始做的基本上今年在全国开始通用了。

4. 未来--值得期待
简单讲一下未来,从我个人成长历程回顾一下,我觉得因为我站在最底层运维这种有代表性,我参加工作应该比较早了,2009年进移动开始做运维,其实到2016年的时候我很迷茫了,为什么?在那个环境里面该掌握的都掌握了,后面不知道该干什么。
2016年中的时候有了算法的灵感,开始学习IT的知识,觉得可能是推开了一个新的大门,那个时候有点后悔当时为什么不学计算机。2017年基本上省内应用,第一次接触DevOps这个名词,当时邀请专家给我们做一个讲座,我们才知道有了这种很标准的东西,2018年全国应用范围相对广一些,学的东西更多一些。从这个角度看,对运维现在稍微有些想法,觉得其实很多东西还是可以做的。

我一直觉得其实整体处理的思路的转变,从定性到定量,我一直觉得不仅仅是用于通讯行业。我之前写这个材料的时候,我始终担心我举的互联网的例子,到时候你们看起来根本不是这么回事,今天早上我想了一个新的例子。我昨天晚上在这边酒店睡觉的时候,空调没关,早上起来流鼻血有点感冒的症状,其实事后想一下,这两个事件是有关系的。我再拓展一样,怎么能够把这个应用到医疗行业呢?比如说现在的穿戴设备越来越多,大家手环各种东西,如果在将来穿戴设备特别多的时候能够进行全身的检测包括周边环境的检测,就拿昨天晚上来说,我戴着手环温度低于10度,有一个告警的信息,第二天有异常的流鼻血的信息,后台自动关联你今天流鼻血因为昨天晚上某一个点温度低了有关系。更近一步的,三甲医院的医疗资源,大数据的平台有了支撑,第二天有不舒服的症状,可以跟周边环境的变化数据自动关联在一起。

更多的可以实现预测,像昨天晚上一样一旦温度低了,可能就会来提醒温度调高,这是展望。
不展开提了,刚才提到了标题因子,其实我们也在优化,更多的东西也是在尝试着在做,包括算法方面的,包括定位出来或者自动的处理,时间关系就不讲了。

谢谢大家!

