@gaoxiaoyunwei2017
2018-05-28T02:42:43.000000Z
字数 5561
阅读 1974
智能化运维——异常检测与根因分析
白凡
分享:张晨
编辑:白凡
讲师介绍:大家好,我是来自京东金融的我叫张晨,我的主要工作是开发工作,之前做过游戏也做过电商。

1. 概述与背景
1.1 运维的痛点和难点

人肉运维,这个简单说一下运维的难度,现在在做运维有一个什么难点,现在机器越来越多,基础设施大型机、小型机、PC服务器、虚拟机、容器、呈万上十几万的虚拟机。

我举一个简单的例子,在我们京东金融的微服务,大概有几千个,可能不到一万个,然后持续集成,然后敏捷的开发,DevOps的应用,系统变更频率非常大,5分钟上线10个应用,而且改了代码我们都不知道,可能他们的关系可能都变了,数据量很大。

这些东西加在一起,在人肉运维里是不可能实现的,所以才只有了AIOps。
1.2 什么是智能运维

这就是智能运维优势:处理海量的数据,然后在动态复杂的情况下去做出一个高效的判断这些人做不到。AIOps应用在哪里,我今天从运维监控的角度看一下看一下AIOps是怎么落地的。
1.3 智能运维的优势和使用场景
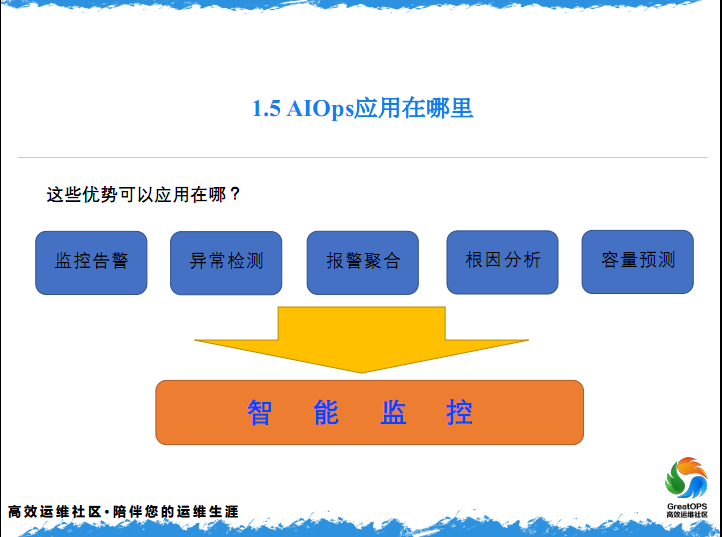
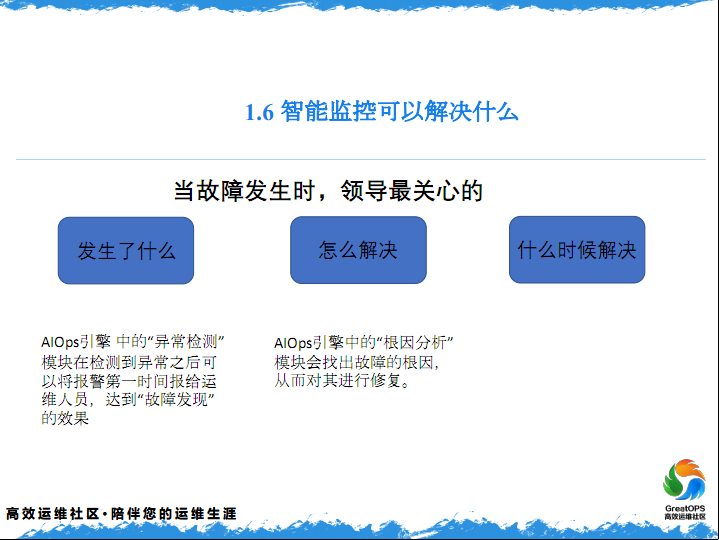
智能监控这个是我们运维平时最主要做的一件事,当发生故障时,发生了什么,怎么解决、什么时候解决,就是在故障发生时。
2. 异常检测
发生时,我们用异常检测来做这件事,怎么解决会用根因分析,找到问题的根本的原因,什么时候能解决,这就看我们的能力了。
2.1 背景与现状

然后运维平时怕什么,就是系统一直在报警,一天收几十条,上百条,我们最怕什么?没有报警是最可怕的,我们以为监控系统坏了,出现问题,我们都是不知道的。
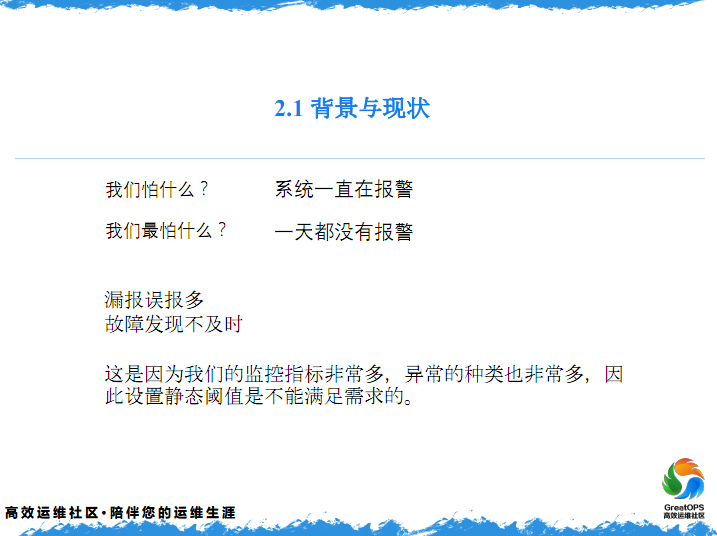
现在现状就是在过去,报警可能误报漏报,我们AIOps落实到智能运维的时候,要解决的就是这个问题。
2.2 传统异常检测
传统的异常的检测,就是基于阈值的,就是CPU高于80%的就告警,阈值怎么设?专家设定,可能有一些比较有经验的运维工程师来设定一个值。缺点很明确,适配性很差,不同的应用和场景的阈值可能又不一样,大量个性化的配置,人工基本是不可维护的。
2.3 动态阈值异常检测
再就是出现动态的阈值,就是正态分布,根据正态分布的概率,自动的调整告警阈值,我们是做电商的有一些促销的时间,平时的这种的正态分布,这种算法是解决不了的,所以缺点无法对一些突发事件根据一些识别。比如说促销的时候,他零点上去了基本上是没有问题的。

2.4 引入机器学习算法
再往前引入引起学习算法。就是通过指数平衡的二次平衡,三次平衡算法,但是有这么一个问题,每一个业务你用到的一些算法可能是不一样的,你这个业务可能是需要这个算法,可能就效果比较好,另外一个业务,可能就需要另外一条算法,才能出来一个比较好的效果,每一个业务都是不一样的。比如说跑批的业务,跟交易的业务,都是不一样的。
怎么出现一种算法,就是这个业务,我们可能需要做一次指数的平衡,那个业务需要神经的网络,每个算法都是不一样的,看哪个业务,适合用哪中算法来算。
2.5 基于基线异常检测
然后这一块我简单地介绍一下,我们自己根据一些业务的情况,来发展的一个算法,基线的检测,我大概给大家介绍一下。
一个基于基线检测,首先会对一个周期内的一个指标做一个动态分布的算法,把他的基线进行一个平衡一下,一般来说是一天,拿一天的指标去做一个算法平滑一下,然后这是第一步。
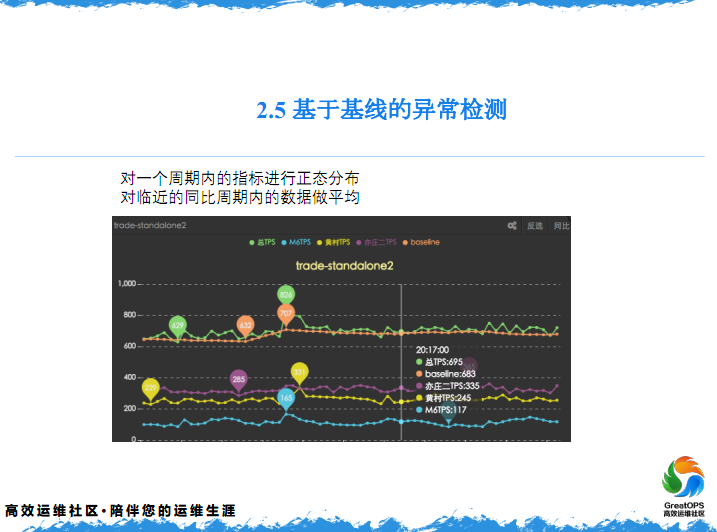
然后第二步,对同周期的数据,我们会根据业务来看,一般来说在电商业务上,以周为单位作为一个周期,也就是说每周的周一他的持续数据是非常接近的,就是你不能拿周一跟周二,大家都喜欢在周一买东西,不喜欢在周二买东西。所以基于电商的特性,把每个周一的数据做一个对比,把每周每一天的数据做一个平均,具体怎么做,这是两步。
第一个是做一个动态的分布,第二步是一个做周期性的平均,首先第一步我们设置两个值,一个是坡度,是这样。我先给大家介绍一下简单的思路,就是说这是第一分钟,第二分钟,第三分钟,我现在计算第三分钟这个点,他的一个基线值,怎么计算呢?我们会拿他左右的数据,把他左右的数据取出来,取多少个这是一个算法来算出来,我们取多少个这是多少个,因为这个值取的越多,就说明周围的数据,对他的影响是越大的,这个可能会根据每个业务的情况来区分,可能是不一样的。
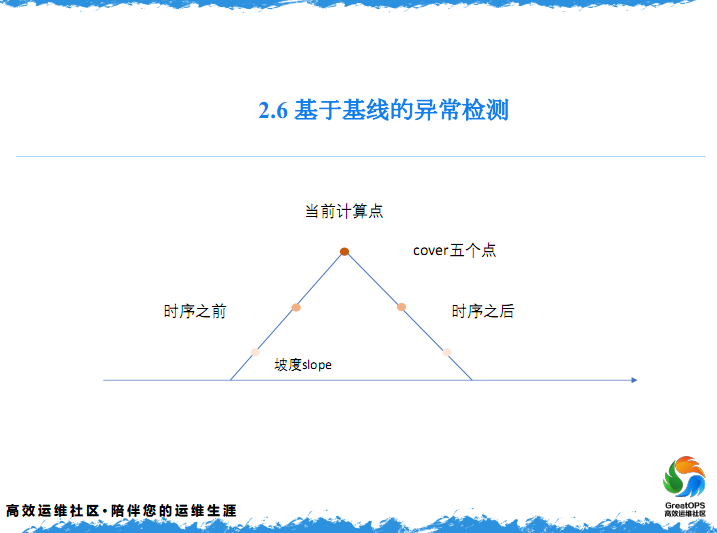
这两个点,可能是加入到基线的曲线上,这个点对他当前计算的点一个影响的大小。假设这是有5个点,5个点相当于平均占0.2%,然后坡度是0.5,就是一个45角视的一个图形,然后计算每一个点的权值,中间这个点,这边一共有三个点,中间这个点就是0.2,他不变,向下一个点,就是0.2减去0.2,乘0.5,要减去一个权值,这个点,在整个点里占0.1两边是对等的,中间的点是0.2、加上0.2、乘以0.5,要计算这两个点的计线值,大概就得到这个点权值占0.4。

然后5个点分别就清楚了,然后每个点有自己的指标值,然后用指标值乘以全值,然后加到一起,就是这一点的一个基线值。

3. 根因分析

我们几年前做根因分析的,也是参考的腾讯的权重面积算法。
3.1 前提条件
首先想做根因分析有一个前提的条件,前提条件是什么呢?有两点很重要。
自动化运维,可不可以直接做AIOps?没有基本的数据,不可能凭空建一些楼台出来。
- 首先对所有的事件做一个检测,这个告警不能随便就告出来;
- 其次,监控要准确;基于这两点,才能做根因分析
- 还有一点这一点是最重要的,需要有一个动态的鼓掌的传播链,如果没有传播链的话,根因分析是做不了的,没有这个链,然后交换机连到哪个宿主机,有哪些虚拟机,虚拟机又连到哪个库,所以必须得有这样的一个传播链,才能做一个根因分析。

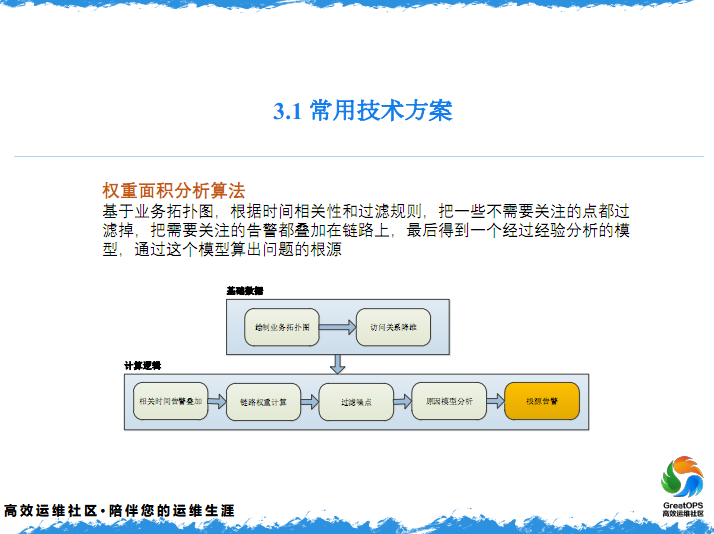
3.2 常用技术方案
要怎么拿到这个链呢?一般来说,会基于一些权重的算法,两部分就是提到的刚才的链,然后底下是整个的处理,处理根因分析的一个顺序。
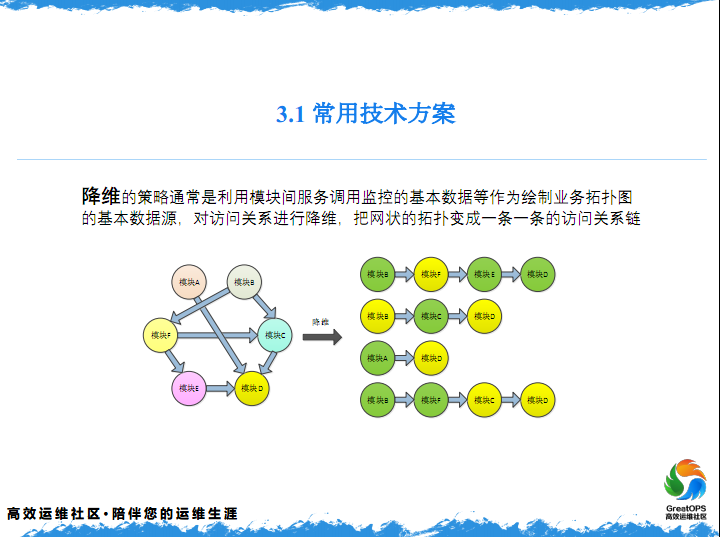
降维是一个很复杂,A到B,到F到D,降维是什么意思,就是把一个图拆成一个链状,应该可以理解一个树状也是可以的,这个东西叫降维。
然后,在算的时候,有三个基本的原则。越靠后的模块,越有可能是根源的问题,因为它是比如都掉它。第二个是相连产生的告警可能是根源问题。比如说他俩都报警,那说明就是它影响了它,是有这么一个关系。

然后,有了这些我们可以计算出,就是根据来计算出它的面积,面积值越多,越有可能是它的根源,这是三个基本的原则。
我简单说两句,就是比如第一块情况,电动模块是4,告警模块是1,这个怎么算?模块只有一个的时候,比如说模块只有一个时候的,就是用1加上4个模块.

这是第二个,用它的模块在整个链构里的数,就是区块数,得到这个模块数的值,当你越挪到后面的时候,这个数就越多,也就是说越往后,越有可能是根源,是这么一个意思。

然后在链路中告警模块数1,这个长是链了中连着告警模块的最大个数,宽=连着或者不连着的告警模块宽都为1+1连着不告警的模块个数,如果有告警连着的,他这个宽就是1。

这是一个有告警的,这个也是有告警的,这个就是1,这也是1,我指的就是代表有告警的,没有告警的,有连着告警的,这5个就是这个意思,这其中有3个1,代表这三个。中间这两个值,代表这个的宽和这个的宽加在一起。
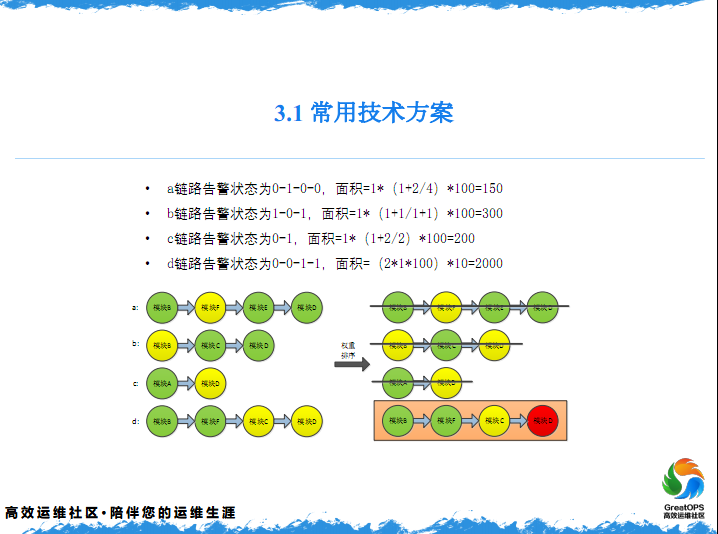
然后1是一个固定的值,然后后面除以的1,就是模块数就是没有告警,连续有两个。1除以中间如果截断了,如果越有连着多的没有告警的,说明就是它和它的关联,就是没有什么关联,就是讲这一件事。
就是这两个报警,中间有两个没有告警的,说明他俩的关联数是非常小的。还有一种特殊的情况,就是前面的模块没有告警,这个后面的模块都告警的,第二个链路情况,就是全部告警了。说的什么意思?就是当这条链路中,最后的模块都去告警了,我们就认为这个的关联是非常大的,而且这个有可能是一个根源的问题,就是它影响了它。所以这种情况,我们就认为它是一个非常重要的一个链路。
3.2 常用技术方案的缺点
然后,这样我们有了算法,把它应用到,这个链路是最有可能的有问题的链路,他上面的告警也是有链路的告警,报出来可能不准确,怎么不准确呢?就是B到C,C到D,属于有告警的情况下,我们是不太知道,它是这么过来的,还是这么过来的,我是不知道的。他有可能是这么过来的,这么过来之后,这个报警可能就没有误报,可能就不会太严重,当然我们做了一个调整。
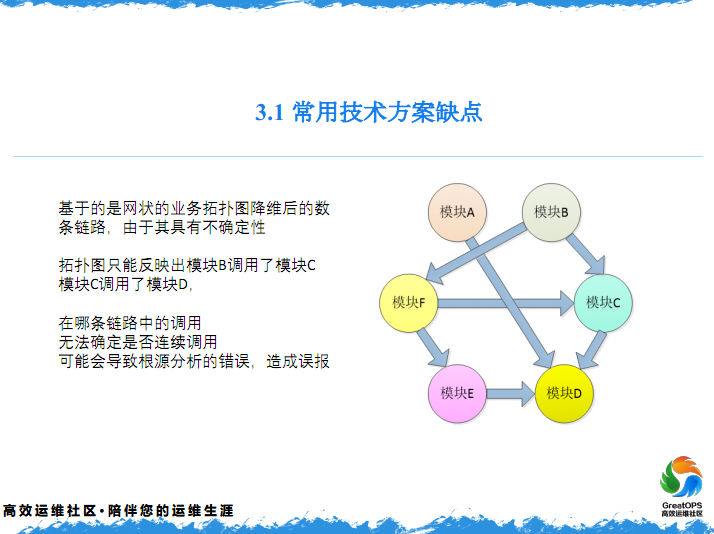
什么调整呢?就是我做一个对比,他们是在这个权重的算法上,采用的很多的AI的技术来做一个调整,然后我们做了一个调整是,一种叫强关联就是强关联的分析,什么叫强关联的分析?看一下这个,这是模块,什么A或者B,这种图不是特别的细,这是什么就是我们可能是两年前做的一个全链路的监控,全链路的监控,这也是我为什么从一开发,转为了一个运维开发,就是开发和运维两个人对不上话,就是开发说的对不上话,然后让我们的运维对我们的开发,我们的任务是什么?就是给开发系统找问题,我们就是干这件事,所以我们就是开发一个全链路监控系统。

3.3 根因分析的改进
我们就是把根因就是监控到每个开发出来的系统每一个方法调用的关系,然后方法内部所有的那些参数,全都给他监控起来,这样的话,就可以把方法,然后我们按照方法来,然后我们的报警也是基于方法的,最后把那个报警,按照方法串联的时候,这个时候基本上就形成了一个关系,所以我们开发了这么一个系统,来做这么一件事。
然后除了这个,刚才我提到需要有一个关系链,大概可以分为两个,一个是软件关系链,一种是硬件的关系链,软件是基于方法中的监控链,硬件是SA,主机再加上做出来的数据库的服务器,这么基于硬件的硬件的两张图,通过技术的通断,相当于软件的一个图和硬件的图,就是两个加在一起,形成了关系链。

3.4 应用调用链
我们的主要的监控类型是网络监控,把这4个系统报警叠在一起这个整个的网上,这就是算根源分析最主要的一个内容。就是把报警叠加到我这两张关系网上,具体怎么来做,大概是这样,就是我刚才忘了讲一点,就是在全链路监控的时候,在nodeid,就是发生过程,整个全链路的日志和全链路的ID,这个是非常重要的,有了它做出了一个链的关系,从软件到供应件到交换机,具体怎么做,因为时间不多了,大概有这儿一步,第一步我们会进行告警过滤。刚才我们说了,有网络、主机、会把告警过滤掉,什么样的话过滤掉,比如说磁盘这种过滤掉,然后第二步,这一步,就是我刚才说的,这个报警过来之后,把所对应的整个链路的点,我们给他按上去,我们有所有的链路,刚才说的这些通过全连算出来的所有的链路,比如说在应用监控上,我们会基于方法基于IP,会定义到那个上面,可能有好几条链路都涉及这个方法,会把这个方法的告警放到这个所有的上面,就是把十亿告警,叠加到这个链路上。

3.5 根源告警原理图
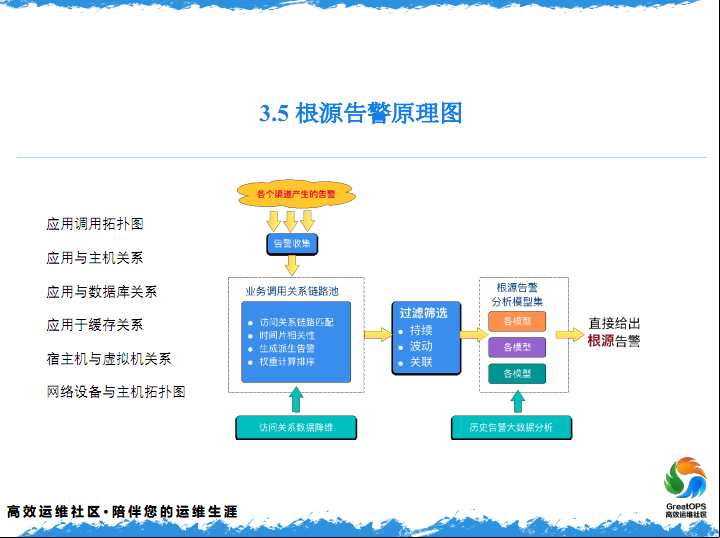
第二个是认为,判断同一个时间窗内不同类型派生告警是否存在关联。只有一个单点的话,是对于我们运维人来说,我们不太会看的,可能这个故障会直接发给应用的负责人,是不会在运维这里去看的。因为你一个单点故障的话,可能只是你一个应用的故障,所以我们这个就发回运营部的负责人,我们运维人是不会看的。
3.6 告警处理步骤

还有计算的链路上的权重面积,最后第五部,我们会把权重面积,比较一下。然后找出他在整个链路上的根源,我们会把同一个根源的,当有一个同一个报警在不同的链路上发生的时候,我们会怎么说,然后第七步就是根据我们的历史所处理的这些情况,来找出一个方案,大概是这么七步。

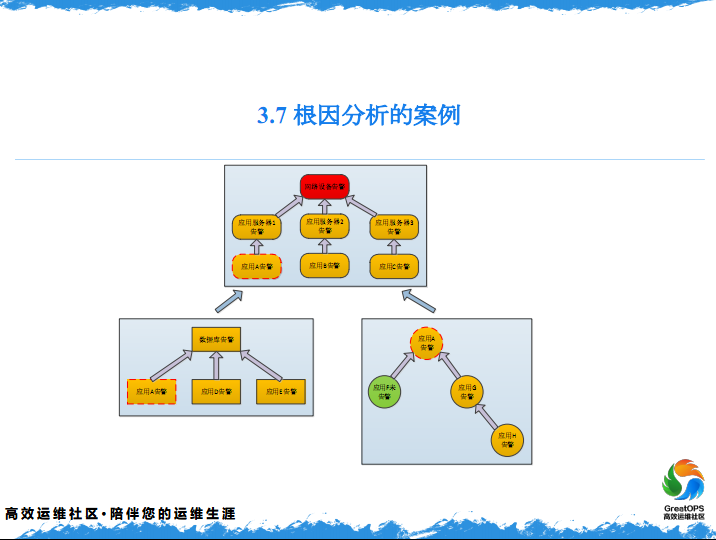
3.7 根因分析案例
然后我会结合一个例子,来给大家解释一下。这是一个应用之间调用的关系,可能这个应用调这个应用,这么调上来,调上来之后,这个时候比方说在这1分钟,发生了几个告警,当然还有很多别的链路可能会叠加出来。

因为这个链路很大,发现当时这个系统报了一个数据超时,数据超时影响的这么多的系统,我们就会认为是一个根源问题,直接找它。这个是基于应用调用链的一个边缘和分析。还有别的调用链,这是刚才另外的一种展现形势,直接列出来,这个时候就可以直接找到应用的开发,有这个问题,就必须解决。
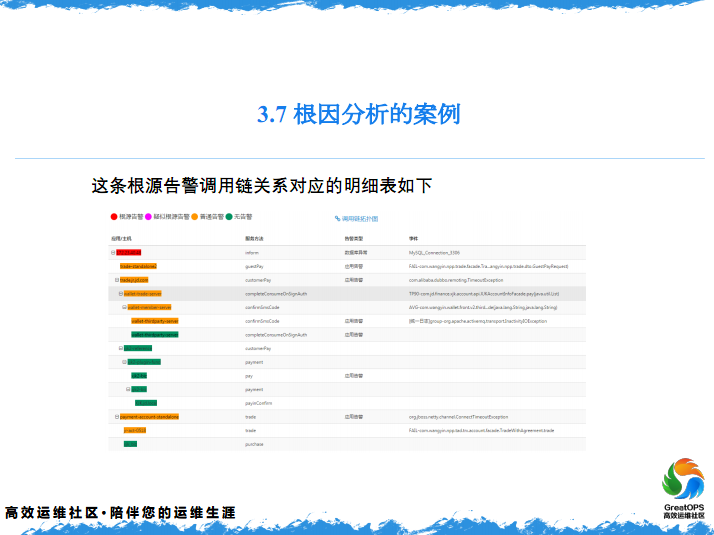
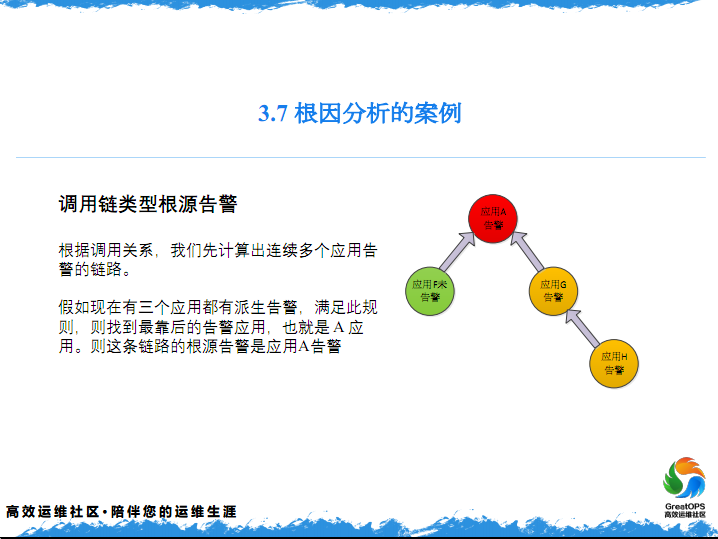
但是是不是这个应用有问题,再来看一下是不是这个应用有问题。
刚才只是列出了其中一个链路上的告警,这里硬件的网络的链路,说这个网络设备出现了问题,就是我刚才说的,就是网络与服务器之间的关系,这个服务器也报警了,说这个网这个服务器网不同,这个网络设备也报警,这个里面A应用也报警了,然后我刚才提到这是两个链路网。
这个A应用告警,他会在应用的滥路上会放上一个告警,同时也会在网络的链路上也会放一个告警,这两个告警是来源于同一个真实的告警的。但是这个告警,是网络监控设备发过来的,会放到这儿,这个是应用监控发过来的,会放在这儿,这样就构成这么一个图。这个图上你会发现,是网络设备告警这是两张图了,就是两条链路了。
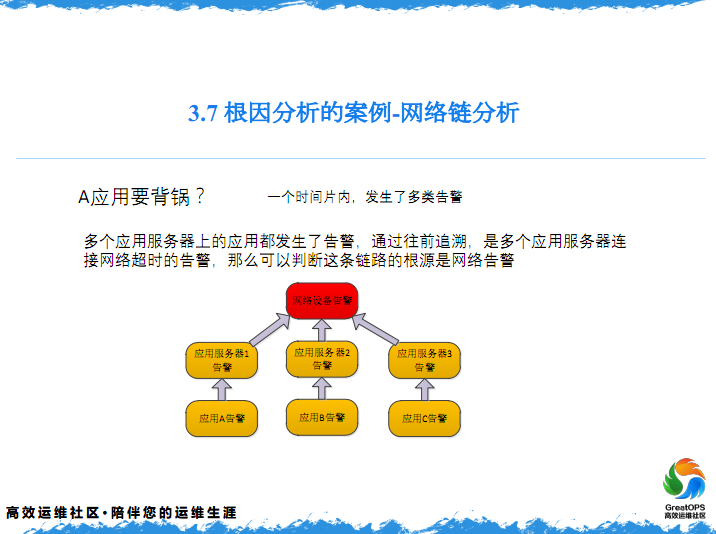
然后这个时候,数据库监控也报警了,然后数据库监控报警,数据库上也有一个条件,就是应用的数据库,就是A应用的数据库,还有B应用的数据库,这个时候把数据库的报警,当然我说的A应用的报警,因为在数据库上,我们会把A应用的告警一会叠加到这个上面,会形成一条链路,有可能是数据库造成这个链路,因为数据库不知道交换机是什么样。
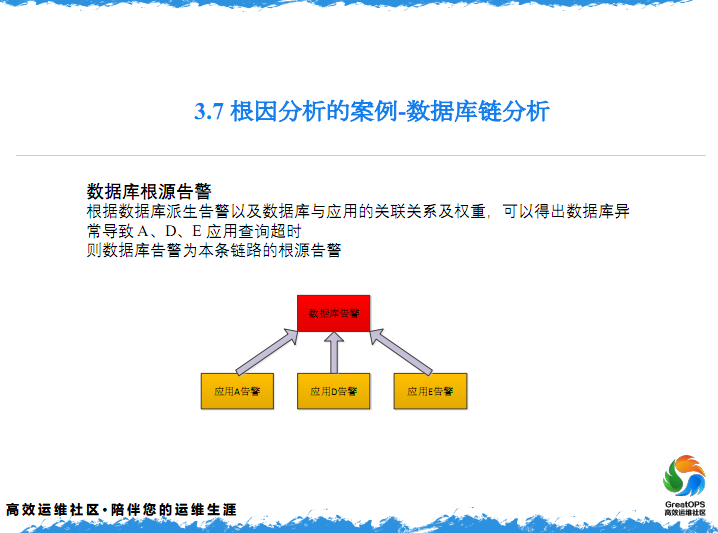
然后这个时候,我们就会做一件告警合并的事,刚才提到就是一个值,就是每一条告警,都会有一个值,然后基于这个KEY值,最后发现一个什么样的事情,我们有一个权重,就是网络设备我们认为是最底层的,数据库得70分,因为网络设备是一个最底层的设备,在这三张图上我们发现了,这个KEY值和这一张图的KEY值,因为他们这三个是来源于同一个真实的告警,这三个KEY值是一样的,这个时候把三个告警进行一个合并,再根据刚才的权重,我们发现一个问题,就是原来是发生在这儿,有一个交换机出现问题了。是因为交换机出现问题,这个应用才连不上数据库,所以这个时候就要解决交换机的问题。
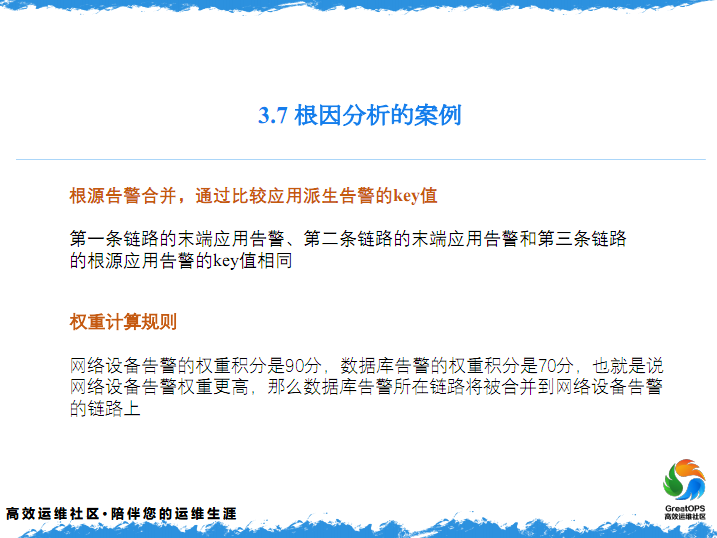
所以这个告警,是运维要关心的,其实运维实际上都要收这种告警,这种的不太去看的。