@gaoxiaoyunwei2017
2018-11-13T10:51:22.000000Z
字数 6462
阅读 1520
Zabbix在Fintech环境中的最佳实践 --- 蔡翔华·招商银行
豆沙包
作者简介
蔡翔华
招商银行信用卡中心 技术经理
GOPS金牌讲师
首先跟大家分享一个句子:
We didn't do anything wrong, but somehow we've lost.
--Stephen Elop (Nokia CEO)
VUCA这个词在高效运维社区好几个分享当中都有提到过,现在是变化莫测的时代,有很多不确定性、易变性、复杂性、模糊性,我们现在的需求变得越来越模糊不确定。以前开发是瀑布性的模型,做一个交付可能会有几个月的时间,需求是固定的。但是现在面对越来越多的竞争对手,我们会有很多的不确定性。
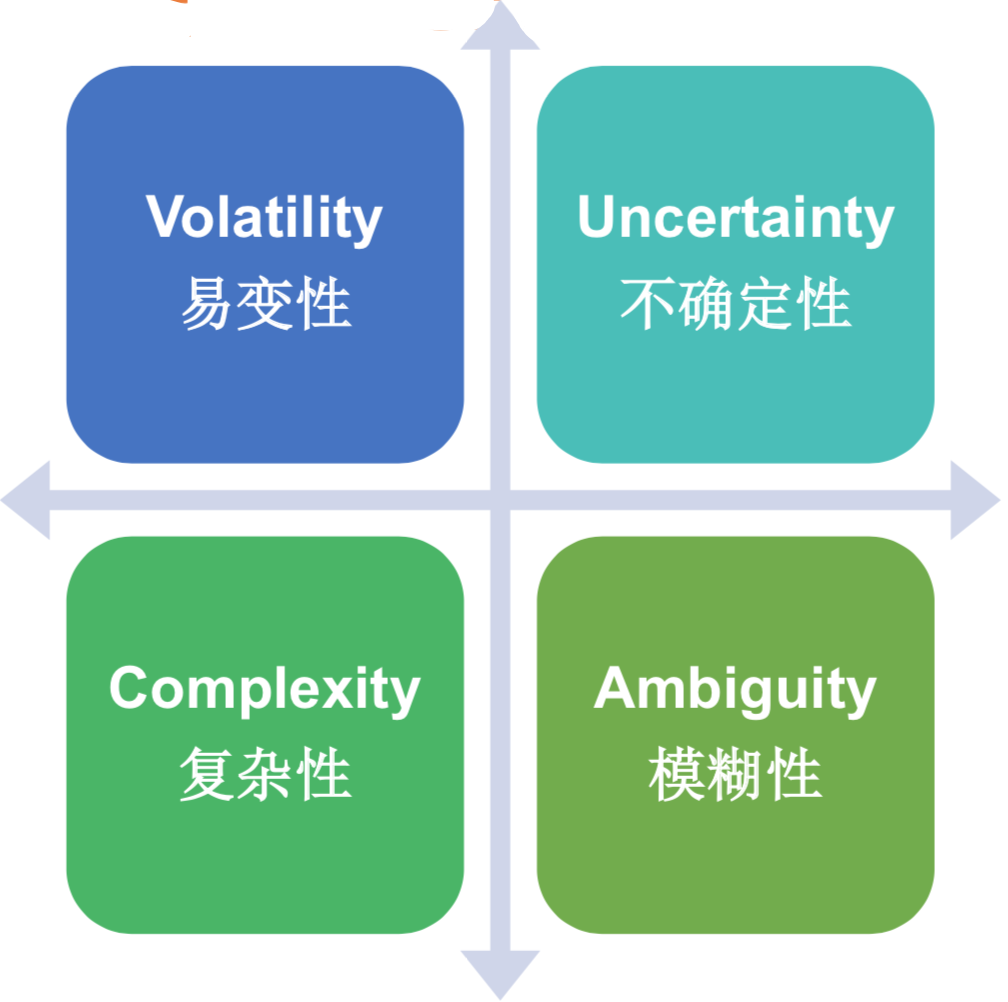
比如拼多多上来一个拼盘的东西,可能短期内也会有一个类似业务的产品,那么这种VUCA的模型,对于底层的监控系统也是有非常大的挑战,包括技术战的挑战,包括人员的专业能力上的挑战。所以很多时候,这种变化也意味着给我们带来了很多这些挑战。
一. Fintech的挑战
大家认为运维的第一要务是什么?
运维是一个消耗的部门,会消耗很多金钱,所以对于我们来说运维的更多要务是止损。我们只有保证线上系统的高可用性,保证我们的业务稳定性,去避免损失。

这是一家公司给出的数据,每分钟它的Downtime给出的损失,这个数字其实对于我们银行业来说会更大。
所以VUCA带来的变化给我们带来很大的困扰,最大的困扰就是基础架构急速扩容,接下来基础架构会有指数级的翻倍增长。原先可能更多使用小机,但是现在我们有虚拟化、大数据平台。现在我们去IOE,我们会引入华为这样一些品牌,在组成虚拟化集群的时候,会不会有一些兼容性和稳定性的问题,我们怎么发现这些问题,这对于我们的运维人员来说也是很大的挑战。
人员技术栈的深度越来越深,最早的时候德勤我是做windows出身,现在对我们来说要精通虚拟化,还要了解一些算法等等。所以对于人员技术栈的深度也是要求越来越高。这就是为什么一些岗位的价格,招聘人员的水平会越来越高。最后一个不同团队之间的协作,从开发角度来说、业务角度来说、运维角度来说他们看到的角度是不同的,业务看重的是业务可用性,运维更多可能看到底层的一个层面。所有这些都是FinTech VUCA时代给我们带来的挑战。
二. Fintech环境下的监控目标
FinTech环境下的监控目标是什么呢?
在移动互联网来临之前,我们更加是传统的银行业,服务器数量、人员数量都是在一个比较小的规模上。现在我们要做很多,因为我们知道信用卡会有两个APP,一个是手机网银的APP,一个是掌上生活的APP。这样导致了我们服务器的基础环境,变成了一个指数性的增长。我们现在可能会有几千台服务器,将近上万的服务器,我们的架构也会从底层的单点服务器,变成很多微服务等等一些方案,而应用数量也是增长了很多,开发语言会从最早的一部分JAVA应用,变成JAVA为主。所以整个环境的变化对IT来说是非常巨大的,我们会引入很多Devops等等一些概念在组织架构里面。
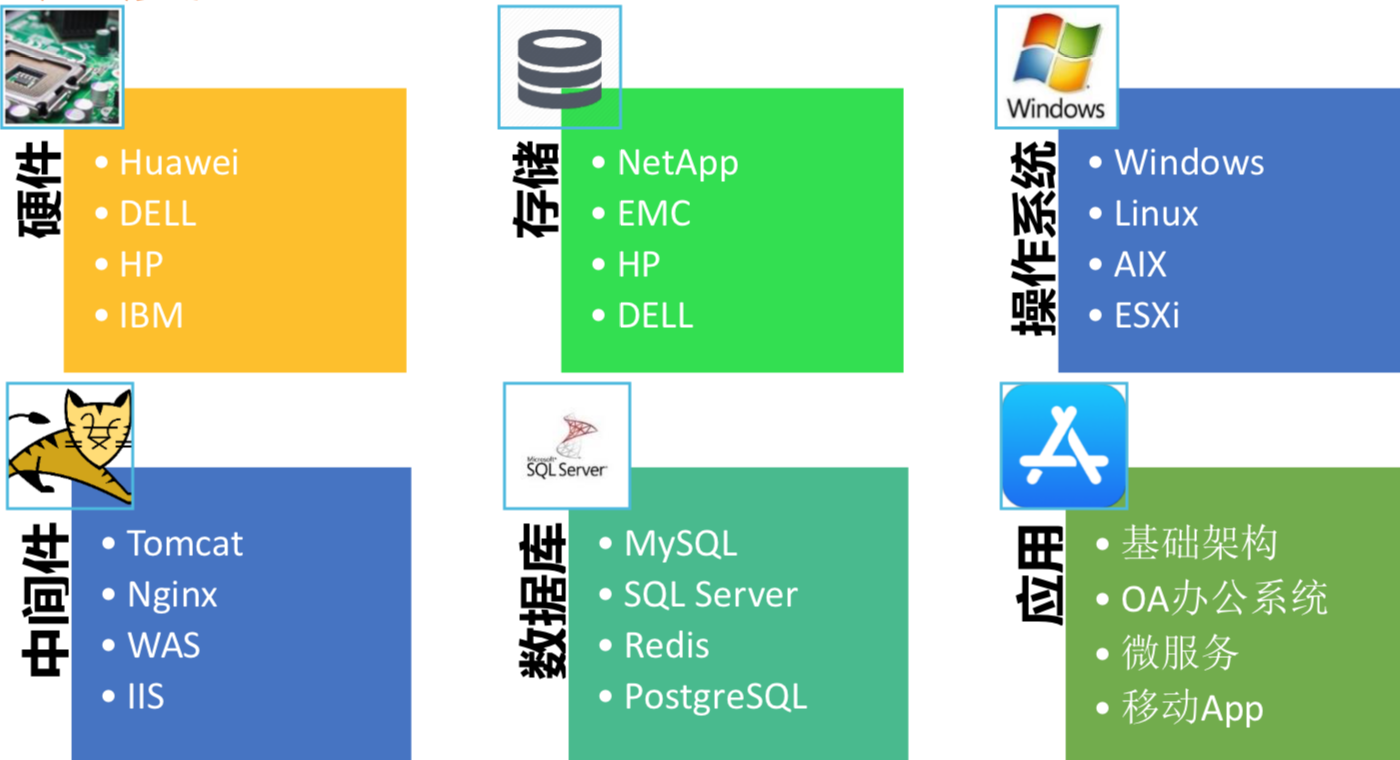
它是一个金字塔型的架构,我们会操作中间件和应用,也会监控底层的虚拟化层、存储、硬件。在每个层面我们监控的东西平台是多样性的。这个技术标准是没办法进行非常好的统一,因为开发人员很多,他们有各自考量的结果,不能说我制定一个标准,只允许你使用这个,这是一个非常不人性化的东西,所以我们必须迎合这种变化。这样的话现在我们的运维团队差不多一比十面对开发,一个运维的人员会面对十个甚至更多的开发人员。我要了解的东西越来越多,我要去了解代码监控怎么做、需要了解有哪些指标。这样导致了运维非常复杂,从技术上也好、平台上也好、系统上也好,非常复杂。
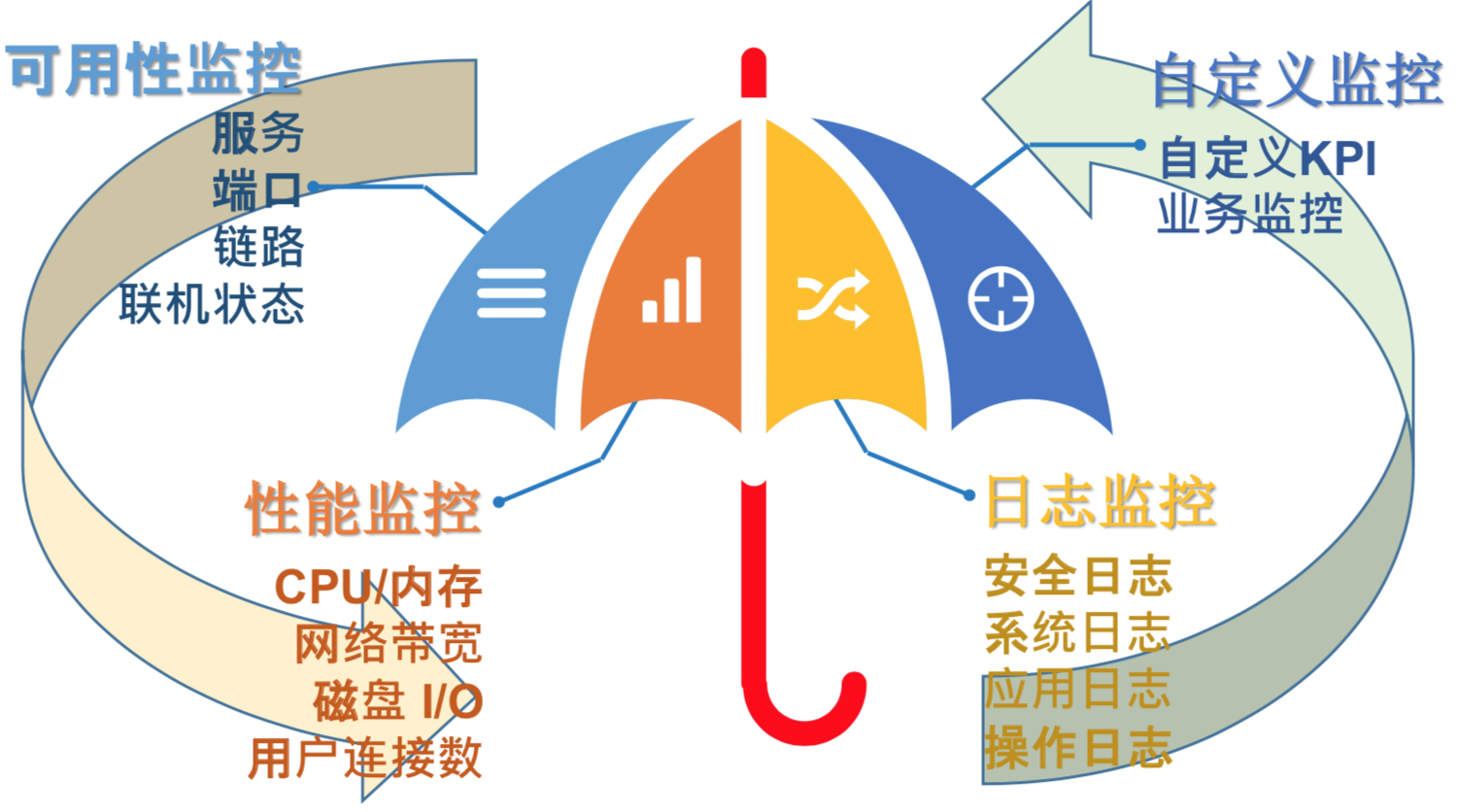
另外一方面,我们常常会碰到一个问题,系统的人员说没问题,数据库说数据没问题,网络上网络没问题。但是还是会发现某个业务是有不可用,我这边把监控深度定义成了四个部分:
第一部分是可用性监控,这是最简单的层面监控,我们只监控端口是否活。
第二部分是性能监控,CPU正常运作,那CPU是不是满足性能的监控,包括一些数据库的性能监控。
第三部分是日志监控,因为在银行里面对审计安全要求非常高,一方面是应用日志监控,第二方面是安全审计追踪,确保我们人员操作的合规性。应用日志也会为后面的一些权利义务跟踪,为故障定位作为参考依据。
最后一部分是自定义监控,我们会有很多来自于业务方面的需求,比如过去十分钟的成交量有多少,这些东西也可以查询到,但是我也希望我的监控系统能够提供这种附加的价值,满足我的监控需求。
所以这四方面,可用性监控、性能监控、日志监控、自定义监控,是深度监控的四个方面。
三. 为什么选择Zabbix?

监控选择产品的话有三种类型,一种像阿里巴巴那种完全都是一些自研的东西,但是自研的投入非常大。对于我们来说,我们现在可能更多的是不考虑吃的好,我们要考虑吃的饱。所以说一方面是自研,第二方面像Zabbix一样,基于一些开源的二次开发,第三方面使用很纯的专业监控产品商业级别的。用商业产品的好处就在于有些帮你兜底背锅,可以帮你做定制化的东西。但是它导致的问题也是一样的,它很注重契约精神。你在合同里面没有写的,它可能不愿意帮你做,或者交付周期非常长。另外就是异构平台的兼容性,我们发现环境里面越来越多的异构的东西单单用一个商业产品的东西,不一定能完全监控。包括自研也好,包括商业产品也好,包括Zabbix这种开源的产品也好,都有这个问题,综合考虑最后我们选择Zabbix。
Zabbix有哪些特点?
- 开源免费,社区支持。它有社区版和商业版之分。
- 分布式高可用。很多的监控软件可能就是单点,没有缓存没有HA等等这些技术。
- 低级别发现和自动发现。随着我们的监控设备数量越来越多,我们会发觉添加监控这一步很烦,要么就是重复添加了,要么就是你发觉漏添加了,出故障之后你才发觉有东西没添加。所以低级别发现和自动发现这两个功能是非常有用的。
- 全栈级的监控。刚才我们看到上面的大图有很多平台,我的确可以有很多的单独平台去做,但是能否有一个平台可以实现全栈级统一的监控?Zabbix可以。
- 可定制。现在很多企业都在做DevOps,但是似乎很少有提到监控,监控在整个DevOps流水线当中是一个怎样的构成,因为CI/CD更多偏向于持续交付,但是交付完之后对于运维人员来说,还要做一个持续监控,Zabbix可以和DevOps流水线做一个很好的集成。
四. 最佳实践&案例分享
最后做一些案例分享,这些东西可能会对大家在实际环境当中使用Zabbix,或者即使你不使用Zabbix使用其他的平台,会有借鉴的作用。
4.1 分布式自动化监控
以前我们的监控就是单点,随着服务器的增加,我们发现会受到一些限制。服务器数量会持续增长,应用的数量本身也在增长。对于增长的话,一方面是数量上的增长,另一方面水平方向的技术栈也越来越多了。我需要有一个平台,而不是多个平台去做监控,因为有多个平台,会导致监控噪音,或者重复添加监控。另外,可能会有一些监控的遗漏,即使这个监控加了,会发觉这个机器上加了监控,但是没有加IOS监控等等。就是监控有效性没有办法确保,很多时候监控有效性都是依靠手工添加解决,但是人是不靠谱的,所以能否把这些东西做到自动化监控。
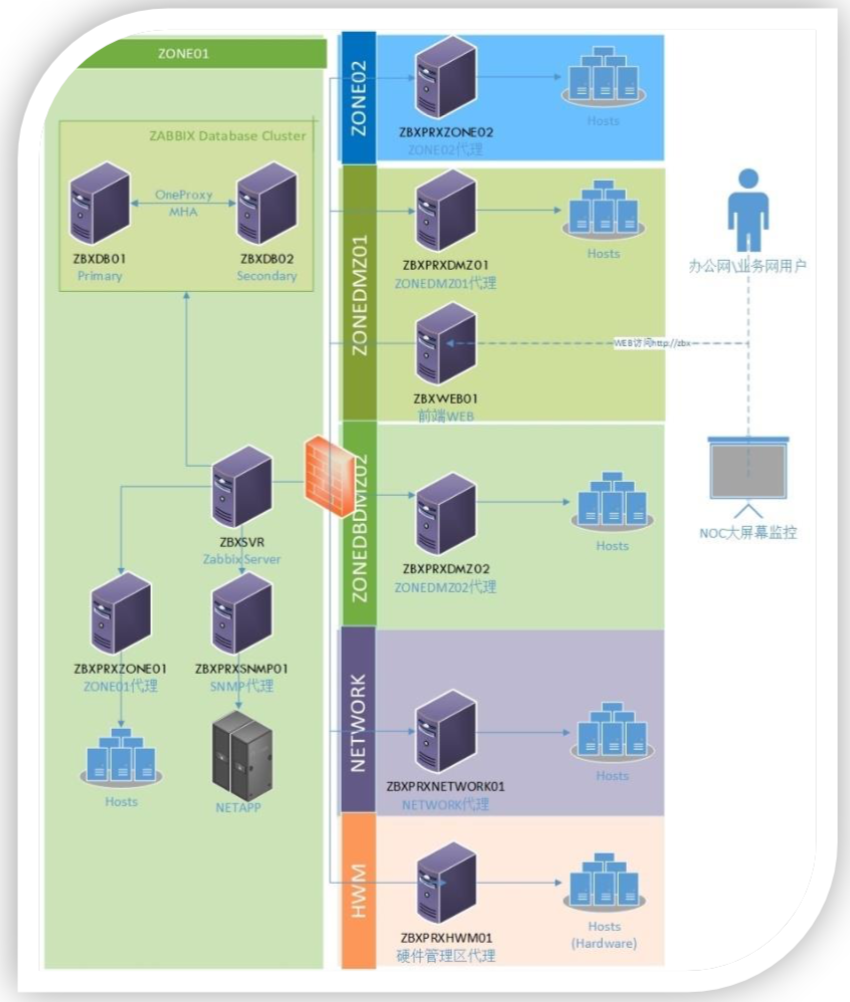
我们整个架构如上图,在每个区域会有一个Proxy,相当于班长的角色,我会收集班里面的所有信息,proxy会去和master沟通,这样的话会避免在防火墙上开很多的端口。这其实也是个分布式监控,我们的Web端部署在用户可访问的区域,我们可以通过大屏监控,把实时的系统状态展现出来。防火墙上只开通了必要端口,这样的话不需要打通很多的网络。每个区域的监控,其实都是由Proxy监控,不需要开通特别多的额外网络。
刚才提到了手工添加的这些东西,我们其实简化掉了。我们每个管理员只需要定义要监控什么东西,把这一类监控的模板和主机关联,然后把主机和人员关联。
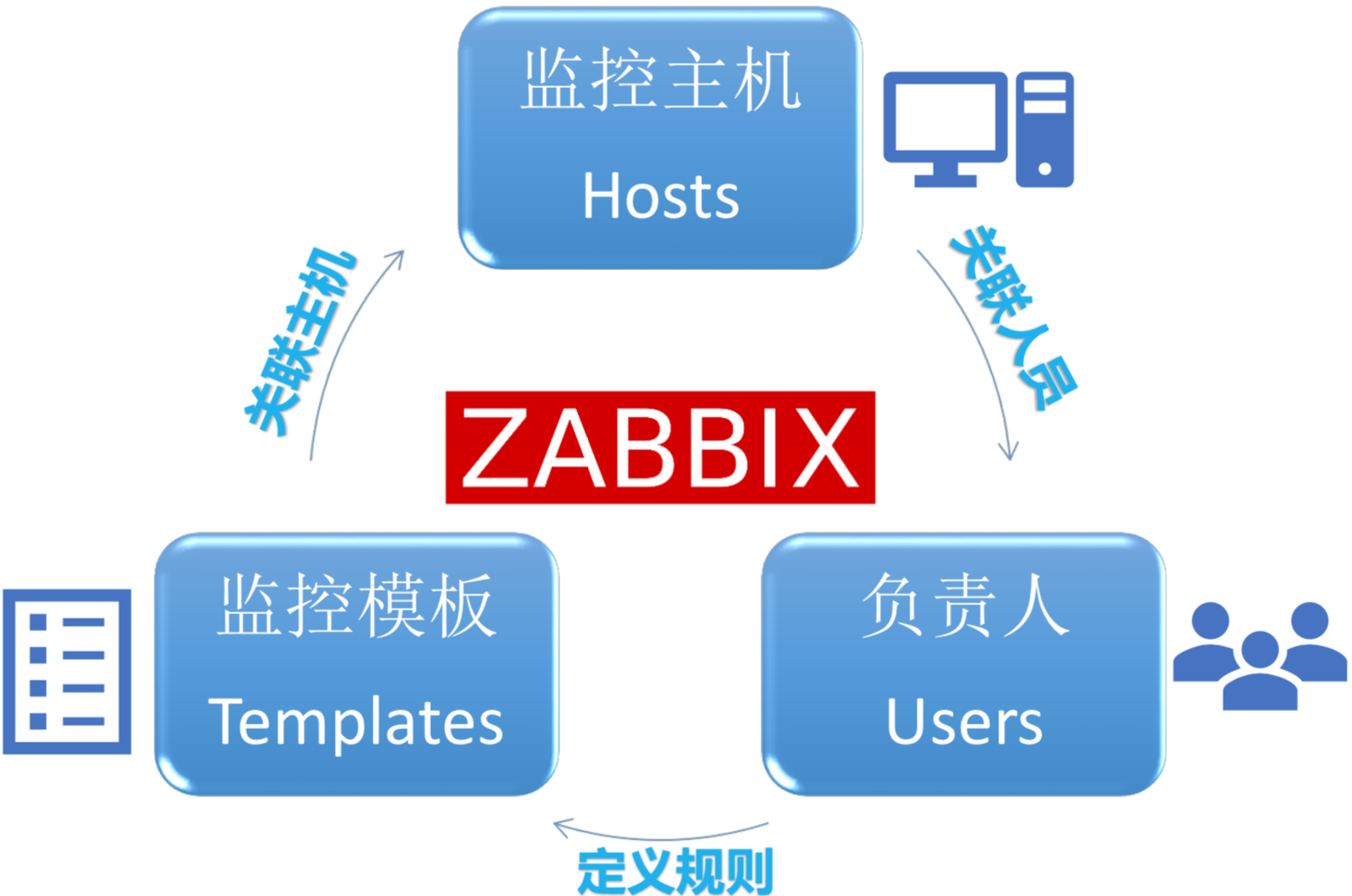
Zabbix这边我定义了去扫比如说B类或者C类网站,而且扫描是定时的,只要你定义一次,之后就会每隔一定时间去做一次。然后发现是Windows,我会关联Windows模板。它会定义很多规则,但是这些规则只需要定义一次,你日后有更新的话就更新,按需更新。更新好之后,你会把这种数据库服务器和DBA的团队关联。这样的话其实我们管理员在这边做的事情就是定义规则,定义规则产生的团队。我只要把这些东西定义完之后,它自动会去扫,每次只要匹配这个规则,自动会做后面的团队关联,自动省去人为干预的不准确性。
它会定时自动添加监控,避免监控缺失或者监控噪音,不需要手动添加监控,只需要定义规则,然后把后面所有的交付,持续的事情交给Zabbix去做,这样最大程度减少了整个环节当中人为不可控的介入,我只要做一次,做完这一次之后,所有的事情都由Zabbix这个平台去做。
4.2 双维度管理
所谓双纬度管理,我们有个痛点,数据库团队可能只关注数据库的一些报警,开发可能只关注一些软硬件的问题,这就导致我们对于监控的要求越来越高,因为视角不同监控的需求也不同。另外我们要确保交互式的监控权限最小化和报警的有效性。
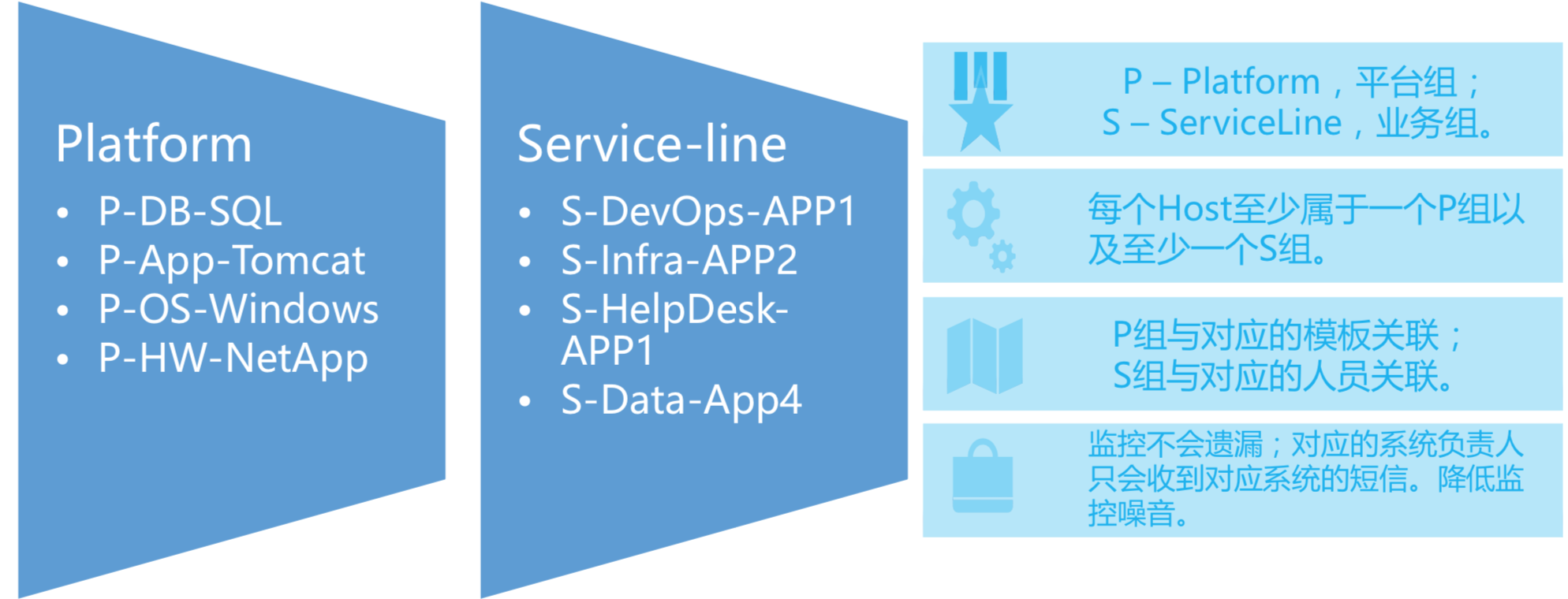
我们把监控定义成了两个纬度,一个平台纬度,一个业务纬度。平台就是指我们上面到底有数据库还是中间件还是操作系统,每个操作系统下可能会有Windows或者其他系统,一个服务条线里面,比如一个用户系统里面,可能有前端的操作系统,也有后端数据库。一个Service,可能会由很多的平台构成的,这样我们确保所有的P组和模板关联,S组和人员关联,业务可能需要知道某个系统放掉之后对业务造成的影响,这样的话通过S组关联,能把所有和业务关联的组关联起来发给对应的人。这样的话监控就不会有遗漏,也不会收到我不想收到的东西,降低了监控噪音,整个监控都是通过P模板做关联,标准化之后,就不会有遗漏了。
4.3 告警通知
我们会发觉晚上凌晨两点收到的报警,其实这个问题我可以明天处理,但是会打电话跟我说,我们会涉及到很多报警没有分级,一些很低级别的报警都会通知你的领导,所以这个时候是有很多监控噪音的干扰的。另外一台系统比如说CPU使用率接近满了或者不足,那么到底不足这个数字是多少?我不知道。Zabbix可以解决这些问题。
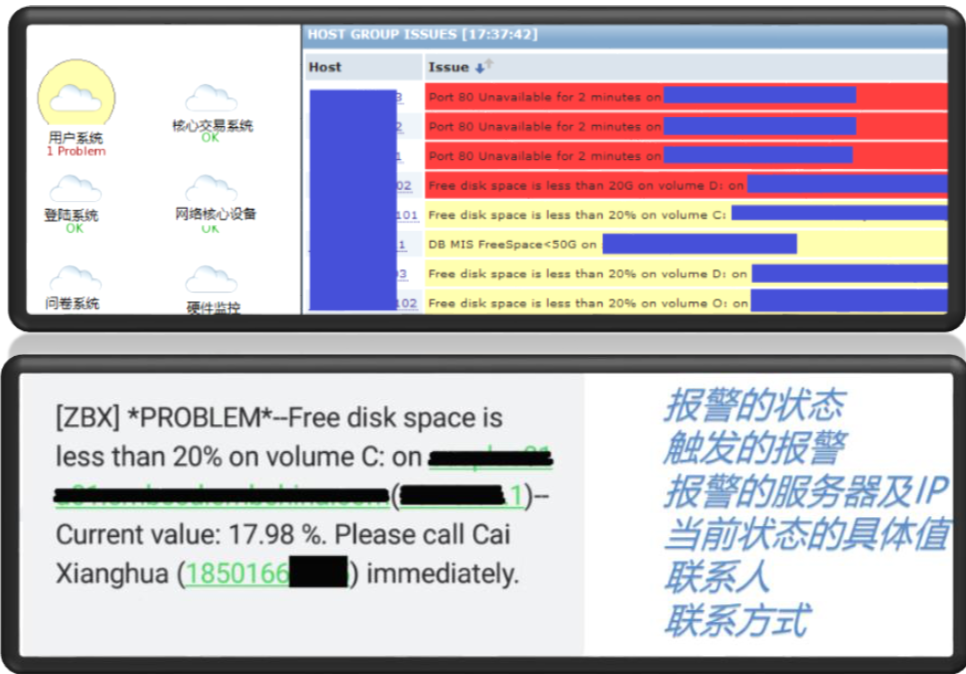
首先告警会区分成三个级别,有些东西很难从定量变成定性的东西,所以我们只用了三个级别。我们会把Warning通知给管理员,一些Warning的东西可能可以隔天处理,但是Disaster必须立即处理。通知方式的话一方面我们会通过大屏展现,另外一方面通过手机包括微信、邮件这种通信方式。通知内容也会非常详细,我们会把目前这个报警是什么状态,是已经修复了还是现在有问题,具体触发什么报警,当前的值是什么,你需要联系谁,手机号码是什么,在这一条五行的短信里面,我们把所有的必要要素填进去。为什么要留人的姓名和电话?是因为收到短信之后,我们有很多的IT专业人员,他不知道联系谁。那我直接把这些东西通过短信的形式输出,直接联系管理员,而不是说我要查很多单找到对应的人,从而快速地把报警内容发布给指定的人。
所以报警一要分层管理,二要多个渠道触达,三要报警内容精细化。
4.4 面板展现
很多时候做监控,老板很注重BI的展现,但是很多平台定制化很差,也不太容易上手,最重要的就是长的比较丑。
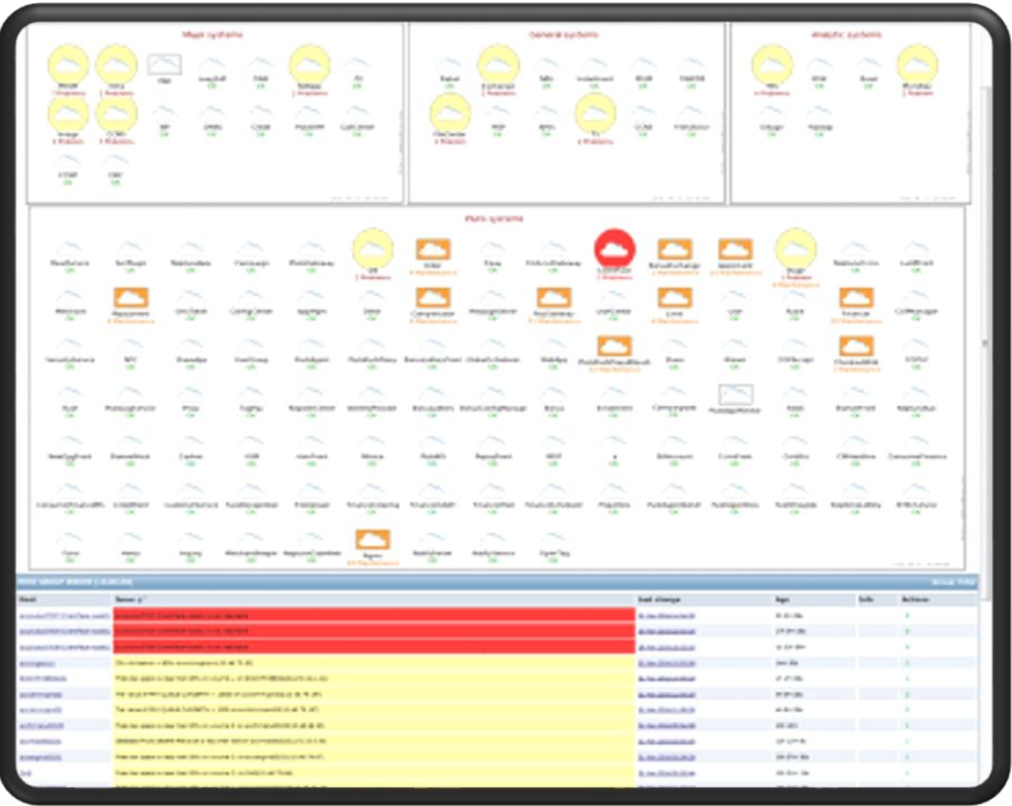
Zabbix虽然也有比较丑的版本,但是现在Zabbix已经到了4.0(上图),有更加好的展现,我们会把所有的系统按照云的方式展现。每一朵云就是一类系统,比如用户登录系统,比如安全系统等等。可以看到这上面有很多颜色,很多长方形或者圆形。每个颜色都代表他的故障等级,比如说红的就代表这个系统有一个Disaster级别的报警,黄色就代表Warning级别的报警,这样也方便管理员第一时间处理这些故障。
3.4版本以后,包括现在4.0的模板,可以做很多定制化。它上面会有时间线,很清楚展现出某个系统里面不同等级的数量。当然也可以通过这种方式把Zabbix的方式放进去,去做条形图或者柱状图的展现,它他非常简单易用,可以通过拖拽的方式把我们需要的数据直接展现出来,而不需要写很多的公示数据展示,另外它还可以支持使用接口做一个可定制的UI。
4.5 自动化带外管理
带外管理是比较高级的功能。我们很多时候会发现服务器莫名其妙宕机了,Zabbix可以通过这种方式做自动化带外管理。带外管理痛点如下:
- 不靠谱! 机房人工巡检不及时、有遗漏。
- 太坑爹! 固件缺陷等潜在问题无法及时发现。
- 太繁琐! HP、DELL、Huawei等多套管理平台,无法统一。
- 成本高! KVM专有设备需要额外购买,额外KVM交换机支持。授权、机房容量都是成本。

上面这三个图分别对应的是惠普、戴尔、华为,这是三个带外的监控界面,能做的事情很类似,硬件上重启服务器,去做划盘的操作,功能也非常类似。
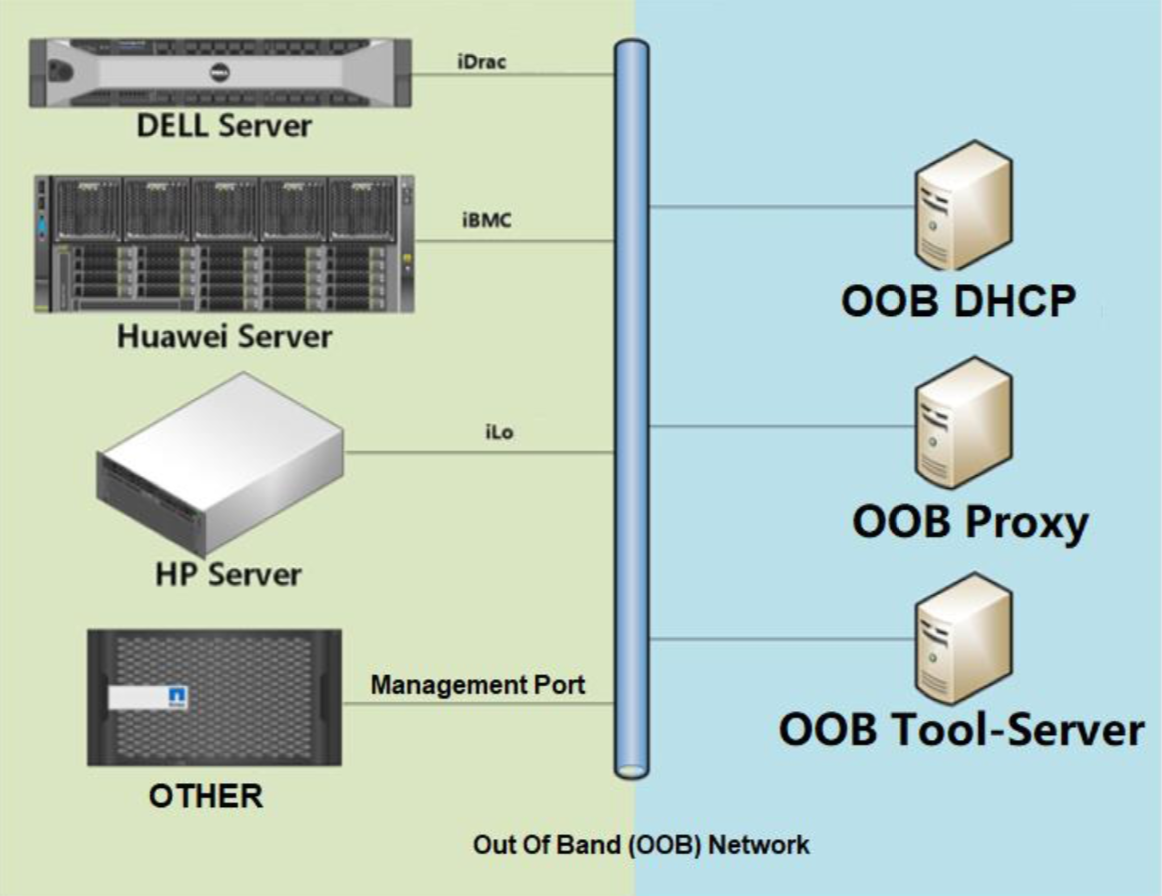
其实我们现在会把这些机器,全部通过带外网络,介入它的管理口,放在带外网络去,给他们分配IP地址。OOB Proxy这个网络会定期扫描这些地址。通过它的管理体制,访问刚才看到的三个界面。这样的话就解决了类似KVM带外访问的需求。它也可以通过Proxy收集一些带外数据,为后续的CMDB提供一个数据上的参考。因为通过的标准协议,所以不需要考虑品牌的差异性。为CMDB提供标准化数据,它是一个很简单的替代KVM昂贵设备的平台。
4.6 持续集成/持续交付
发布应用的时候必然会对中间件造成一些操作,这个时候就会发出监控噪音。那我怎么能在上线的过程当中,或者发布应用的过程当中,把监控不必要的噪音停掉,怎么和其他平台做持续集成,我们现在业务扩张越来越大,比如我们现在新上一个抢购应用,怎么知道这个应用需要多少服务器、多少资源,Zabbix可以提供这方面的参考依据。
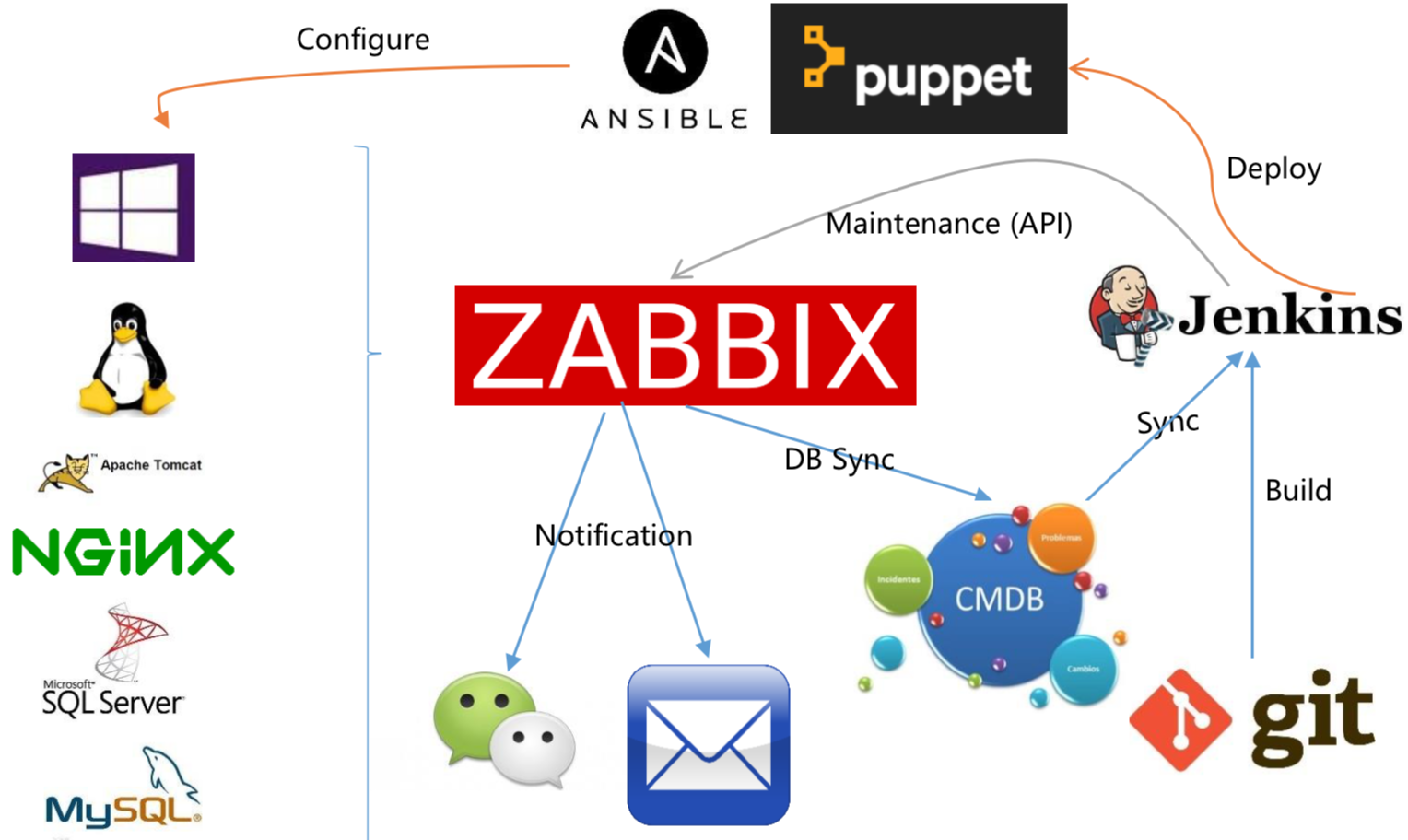
这个图大同小异,我们会有git,也会有Jenkins这样的平台,通过一些配置管理工具配置很多基础平台。Zabbix会调用Jenkins,这样避免了在上线/发布过程当中,有很多的报警产生,同时Jenkins会把它收集的数据和CMDB同步,CMDB的数据也会和其他平台作为共享,保证我们线上配置是最新的、可用的。同时Jenkins也会接入一些通知平台,微信、短信、邮件,会和很多通知平台做持续交付的过程。
所以说通过Zabbix做CI/CD的收益是它可以提供标准的API,和DevOps的流水线做高度集成。它也可以收集很多数据,我可以通过报表或者数据库或者API都做一些数据清洗的调用。因为它会保留很多数据,所以这也会为我们后期的容量规划,做一个参考依据,而不是拍脑袋决定后面需要多少资源。
大家可以根据以上说的这些点,去评估哪个监控平台更适合你们企业的需求。
Zabbix的好处就是开源免费,我相信Zabbix从功能性上来说,不一定有阿里的监控平台那么强,但是它投入的资源非常少,很适合中小企业这种群栈式的平台。从管理成本和本身的花费来说也是非常小的,比较适合中小企业这种不想花太多人力在监控上面的这种公司。但是Zabbix也不是万能的,任何监控平台都不是万能的。对一些非常深入的需求,比如对某个应用做分析,Zabbix可能没办法实现,但是Zabbix还是覆盖了80%的监控需求。最大的收益是我们人工介入很少,通过它的自动发现以及和其他系统集成,其实可以忽略平台本身的存在,所有平台配置一次就好,或者通过DevOps流程配置,剩余报警都会通过自动化报警产生。
现在我们有越来越多的中文文档,越来越多的Zabbix中文社区的伙伴共享了自己的一些心得,社区资源比较丰富,也有定期的线下活动,大家有兴趣的话可以关注一下开源社区的公众号。
