@gaoxiaoyunwei2017
2017-11-13T07:59:09.000000Z
字数 4736
阅读 1202
SRE at Airbnb:On—call and incident Response
毕宏飞
前言
我叫 Cameron Tuckerman-Lee,来自于 Airbnb ,今天跟大家分享 Airbnb 的部署和实施。说一说我们SRE的团队,首先我是 Airbnb SRE 的工程师,之前的话我是在 Google 和 Airbnb 网站合作的一个项目工程师。今天我们会从以下三个节点去分享:
SER的定义,如何从 DevOps 的角度看待SER
SER在 Airbnb 组织和云架构的深入探讨
未来Ops的趋势
一、如何从 DevOps 的角度看待SRE
首先我们说说 DevOps 的团队,这个是大家熟知的。
从运维团队来讲,可以做集中式的Ops,作为这样一个类型来讲还是不错的。

它的好处是你整个的团队做一个相应的问题,并且他们有专业的职责。有的时候做测试或者是做网络运维包括安全,你用这种方式还是有劣势的。首先,如果你是开发者,总是想发起一些新代码,但是业务团队总是要用原来的代码,而且包括运维团队,尤其是对于我们代码库不是非常熟,所以这个到最后会有一些分歧和摩擦。
还有一种是分布式的Ops,我们把它分开,这对于亚马逊来讲的话,就是把它分成单个团队。

一个团队做软件的开发,比如说他们做代码的开发,包括运维和快速的响应。有一个团队做新的功能,有一个团队做运维。如果这个团队已经开发了这个代码,下一个团队就能够执行了,所以开发者就能很好地被嵌入到构建相关的系统,并且能够简单实施。但是我们SRE在 Airbnb 做的话,我们看到一个劣势,首先是一个专业度,有一些搜索他只知道搜索,他是不是要知道 Unix 或者是其他的语言呢?所以实际上这是会影响到的。而且除了这些,做可靠性的时候,他们的标准化也不一样,A团队和B团队他们沟通时可能语言也不一样,实施方案也不一样,所以最后我说说不同的 Team 怎样形成相同的机制。
在 Airbnb 我们使用的是一个混合方法,我们有两个团队,我们使用的是一个综合的方式,提升它的整个的可信赖程度。

在这个方面,我们既能够吸取两个方面集约的方式,分散风险,又可以提高可信赖性的同时也提高敏捷性。研发人员现在还希望能够做基本的操作,所以他们能够做一些可操作的服务。但同时我们有一些中央的团队,还能够做一些细微的调整。 Google 也说过一句与我的观点非常相似的话,作为一个软件工程师不是发生什么重要,而是你应该以怎样的方法来应对,因此我们如何在 Aribnb 使用这个方式。
二、SER在 Airbnb 组织和云架构的深入探讨
在 Airbnb 有三个团队:
- 云基础设施,主要负责总的协调作用
- 核心的可靠性,他们会确定运行的时间,提供新的服务,提供新的可靠性
- 嵌入可依赖性,在产品团队中临时嵌入SRE,以解决特定的可靠性或可用性问题,这就是一个短暂的,暂时的帮助过程,这样的话我们可以提升可信赖性,尤其是一些基于项目的看到信赖性。我们就不用考虑整个公司的状况,用辅助的团队帮助我们就可以了,因为我们只是需要做一个随叫随到待命的团队,所以嵌入的并不是有什么不一样,他们只是为了帮助我们提供更好的服务。
2.1 基础设施
接下来我们谈谈语音基础设施,它是一个团队,语音基础设施是非常重要的。我们需要提供一个具体的例子在 Airbnb ,我们经常使用EC2,所以最开始的时候我们是非常小的公司,那能不能去做EC2呢?
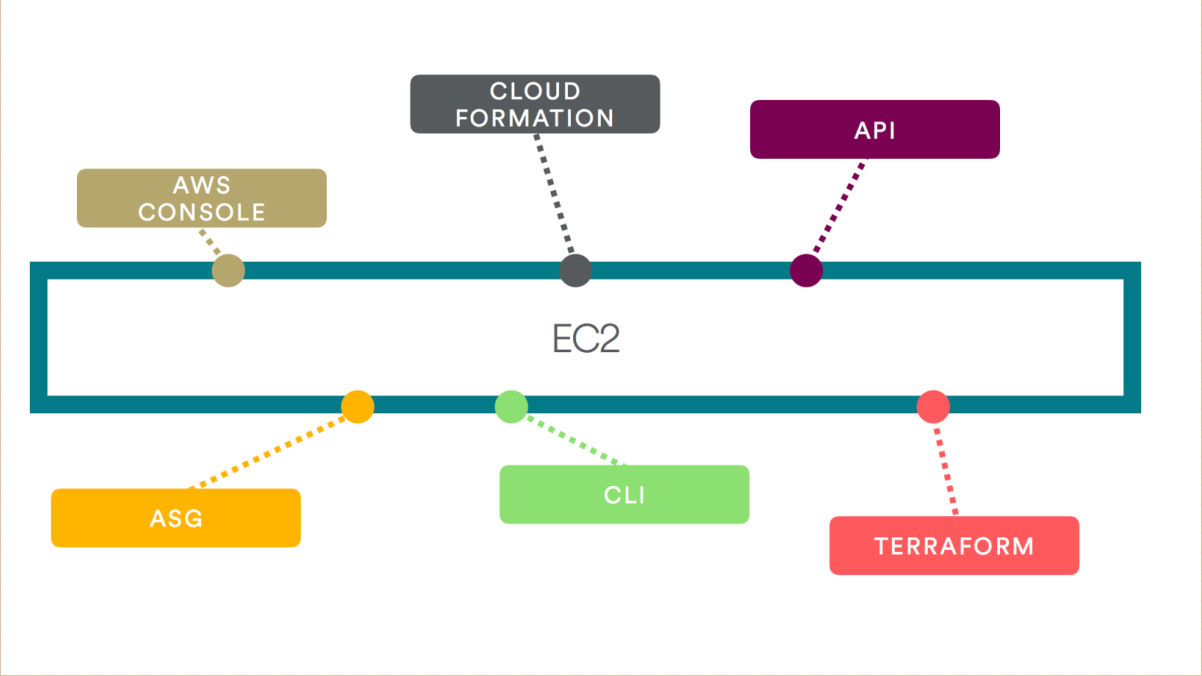
随着时间的发展,有非常多的人跟大家说我可以优化,我可以做得更好,我们能够建立相关的工具。我们发展到后来,不同的团队有不同的工具,他们希望有不同的UI,或者是一些自动化的团队,还有一些想的就是我的代码其实挺好的,我们有一些云的形成过程,还有一些公司我们是在代码上做了研究。突然之间你有非常多的方法做服务,每个人都有自己的方法,其实这是没有办法实现的,因为太多的方法了。所以你一定要保证安全,保证系统的可执行性、可信赖性,所以我们没有办法统筹协调所有团队的诉求。
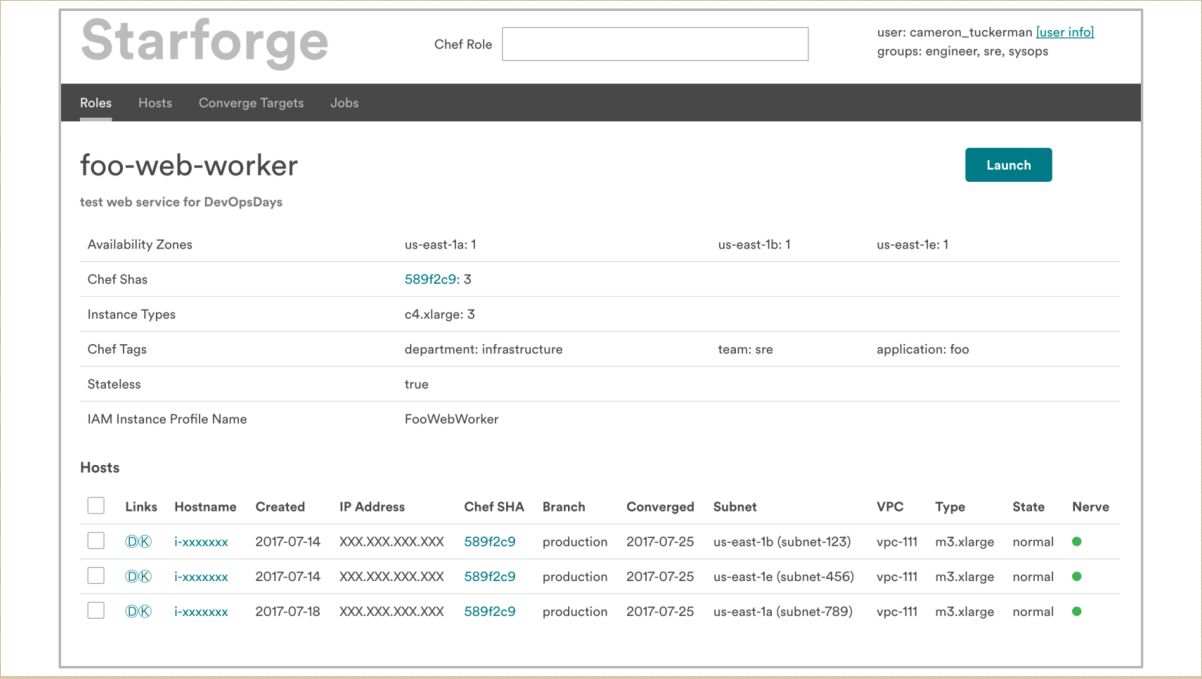
其实团队的想法是很多样的,在 Airbnb 我们有一个 Starforge 的系统,这是一个很好的工具,帮助我们提供一个公开的渠道,同时我们也会有很好的方法。如果我们用两个例子决定哪个是最主要的方法,我们可以发挥不同的作用,提出不同的观点,现在所有的团队都用同样的工具,就是 Starforge 。
2.2 核心可依赖性
接下来谈的是云的可信赖性,可信赖性在 Airbnb 有三个表现形式。

第一个是运行时间的测量,在一个非常理想化的世界大家可以做任何的服务。在 Airbnb 的服务,看一下他们的运行时间,看一下他们的服务状况,然后非常自信地答出答案。有的时候是非常难去测试任务的时间,其实是 因人而异的。你答应客户什么时候交付就什么时候交付,这是承诺的过程。
第二个是问题和报警发生也很正常的,我们需要让他们知道是有问题发生的,唯一的是我们必须快速地解决问题,对自己的问题负全责任。我们有志愿者、有前端工程师和后端工程师,还有PM帮助我们解决问题,他们之间互相合作,所以出现问题就会预警。
第三个是解决方案和应对,有的时候真的出现Bug的话,服务崩溃了我们就需要立马去解决,我们需要和客户之间,内部和外部都要达成协议,有效沟通。
2.2.1 运行时间的测量

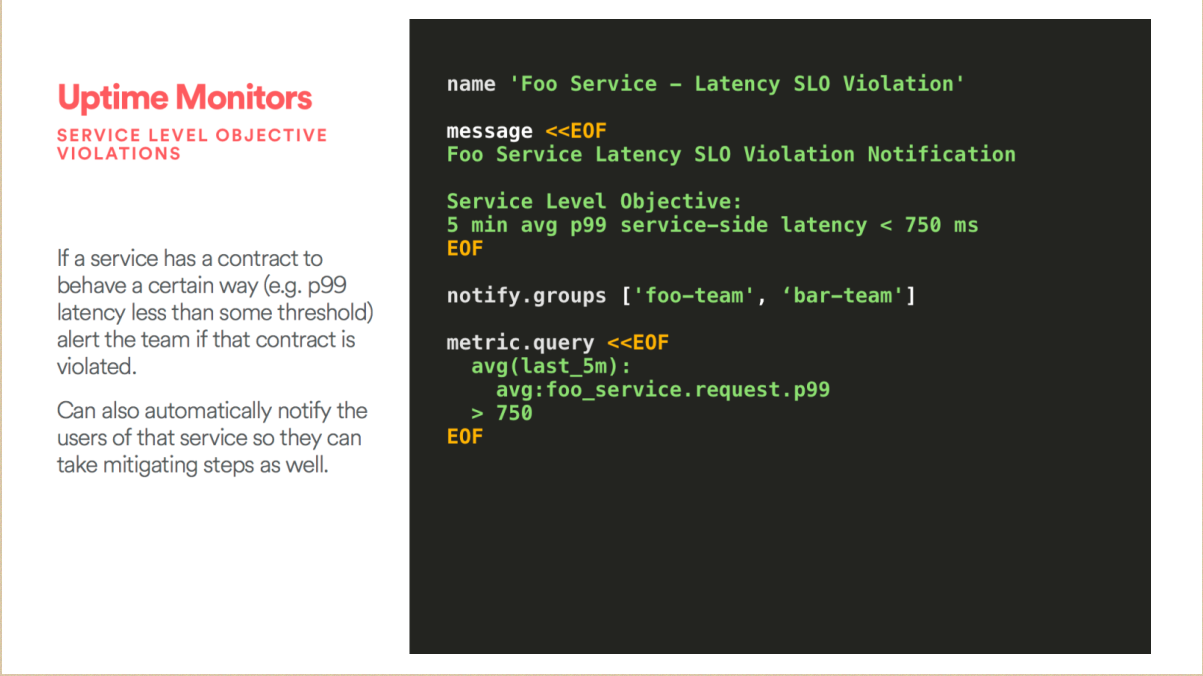
在 Airbnb 有一个强大的系统是SMI,如果你是服务供应商和提供商,我就会问你有没有一些指标是能够测量你服务延迟的呢?那就是SLI,服务指标的系数。同时你会跟公司其他人说,这些指标是什么?能够帮助我们达到什么样的目标?如果你想要有这样的服务的话,你延迟了,每5分钟对你的损失都是非常大的,所以你的公司需要达成不同的目标,那就是我们的SLO,服务水平的指标。我们需要去计算服务延迟的时间,需要在可信赖度和敏捷度之间达成一个平衡。如果你承诺你每5分钟延迟不超过1%的话,那你就必须要达到。如果说你要发布这样一个特性,我非常确定这一定会成功。那如果你没有那么自信,你没办法达成这个目标的话,就不能够在敏捷度和可信赖度之间达成平衡。你有一个非常大的预算,可能会发展得更快。那如果你没有办法去估计的话,发展得不好你是不能接受这些变化的,所以一定要去提升自己产品服务的质量。
2.2.2 预警检测
我们在 Airbnb 预警应该是采纳不同人的意见,需要非常快速的知道发生了什么问题。

如果我们想要看一下所有的服务,客户也需要知道出了什么问题,必须快速地解决问题。我们有一个观点就是说报警就像我们的整个结构一样也应该有代码,因此报警也有代码。为什么报警也要写代码?我们需要深度防御,你需要高度你的用户,告诉他们如何保护自己的网络,给加一个防火墙就会万事大吉,同样的方法也要保护自己的用户让他们免受Bug和回归的影响。因此报警的时候我想说的是叫 Interform 的这样一个结构,这个代码是非常强大的,这是什么样的代码呢? Airbnb 有一个名字的有信息的,这个信息和文件是有帮助的,帮助我们看到出了什么问题,看到到底出了什么状况。如果在凌晨一点没有人去帮助处理这个问题,这个问题就会一直在。如果有一套预警,每一个服务都是有它的级别,它可以相应的自动化。
接下来我们看看这张图,首先预警其实是有一层一层层级的预警,不光是一层。
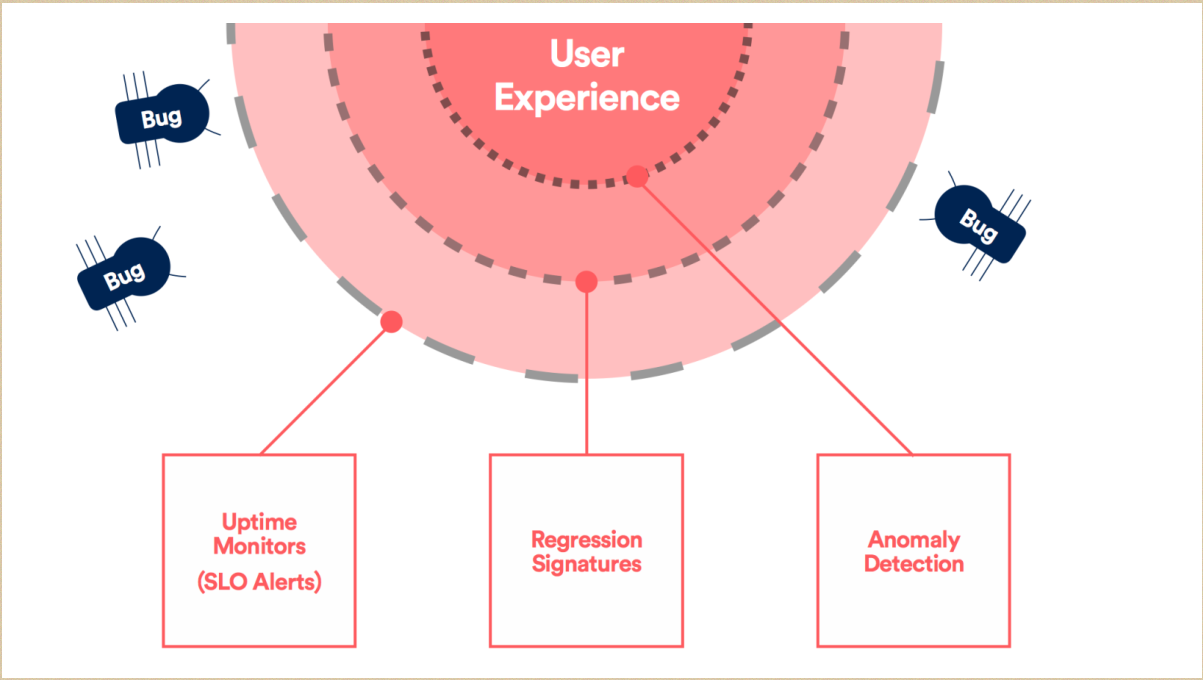
这当中如果有SLO的预警,你必须进行隔离,隔离是找出当中的BUG来进行除错。这个当中是有响应的,我们是建议做一个响应的预警。在某一个层级出现SLO,我们做相应的SLO的预警,它的一个越级的预警,通过这种方式高度某一个层级是怎样的。
下一个防火墙就是回归,这个相当于一个除错的疫苗。
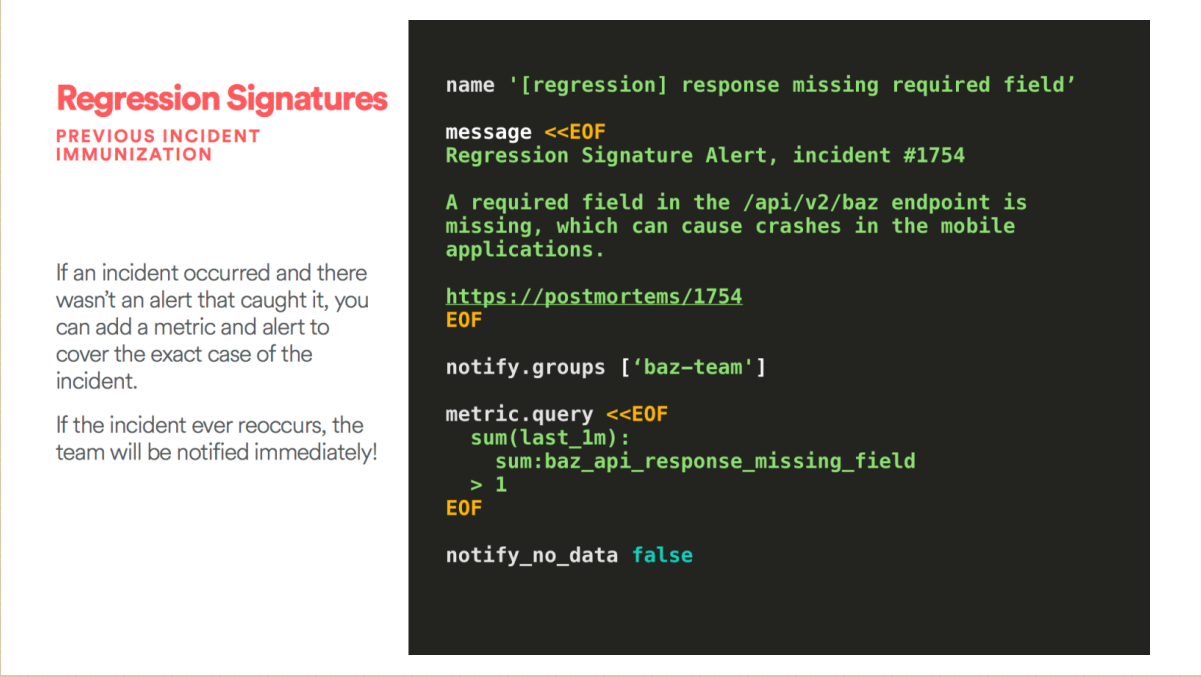
首先要确保它的文本没有错误,你要相应的工具,有了这些其实还是会犯错的,如果每次有这样的预警就说明有这样的事件,所以提供这样一个环节来除错。比如说通过两个小时来搞清楚出现什么问题,然后除错,这个时候非常累了。你会发现两个礼拜前也出现过这个问题,比如说它API的问题,然后它还会传输错误的信息和数据。如果每一次都是这样的话,你进行存留记录,之后工程师可以很快地除错。
实际上 Anomaly 的识别本身是一个自动的,并且毫秒级就可以很好地识别,可以让你发现这些小小的BUG。而且它在特定的层级,不会影响到其他层级的预警,这方面我们做了简单的机器学习,包括通过我们的一些数据仓库来进行识别,因此从层次方面我们来更改预警,这个的话可能会影响到一些小批量用户,会有安卓系统的影响。
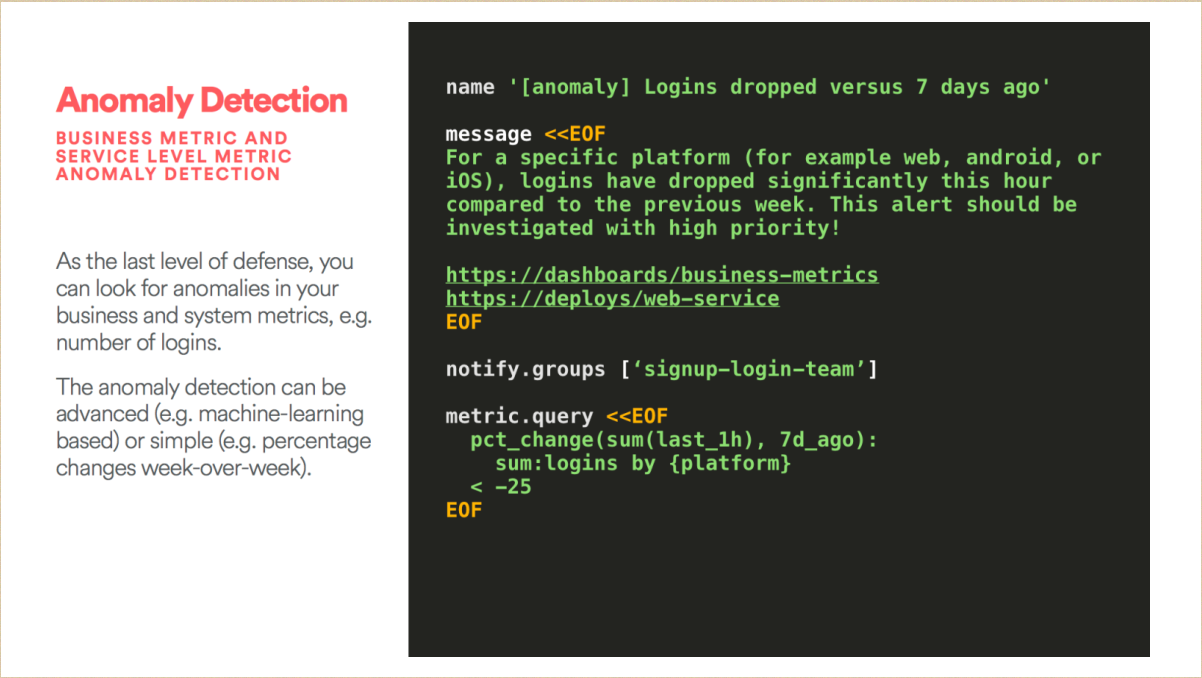
那么这当中会什么?这一个BUG以前没有看到过,但是通过 Anomaly 的识别,可以进行相应重复错误的识别从而进行除错。在我们在生产环境之前,我们要确保 Airbnb ,SRE团队做了很多的工作,万一有事情发生的话,相应的团队要知道如何快速地响应和解决问题。
2.2.3 解决方案和应对
有人说错误总是发生,有的时候是大问题,有的时候是小问题,如何有效面对呢?SRE团队如何有效解决问题, Airbnb 这边有这样一个报告的工具。
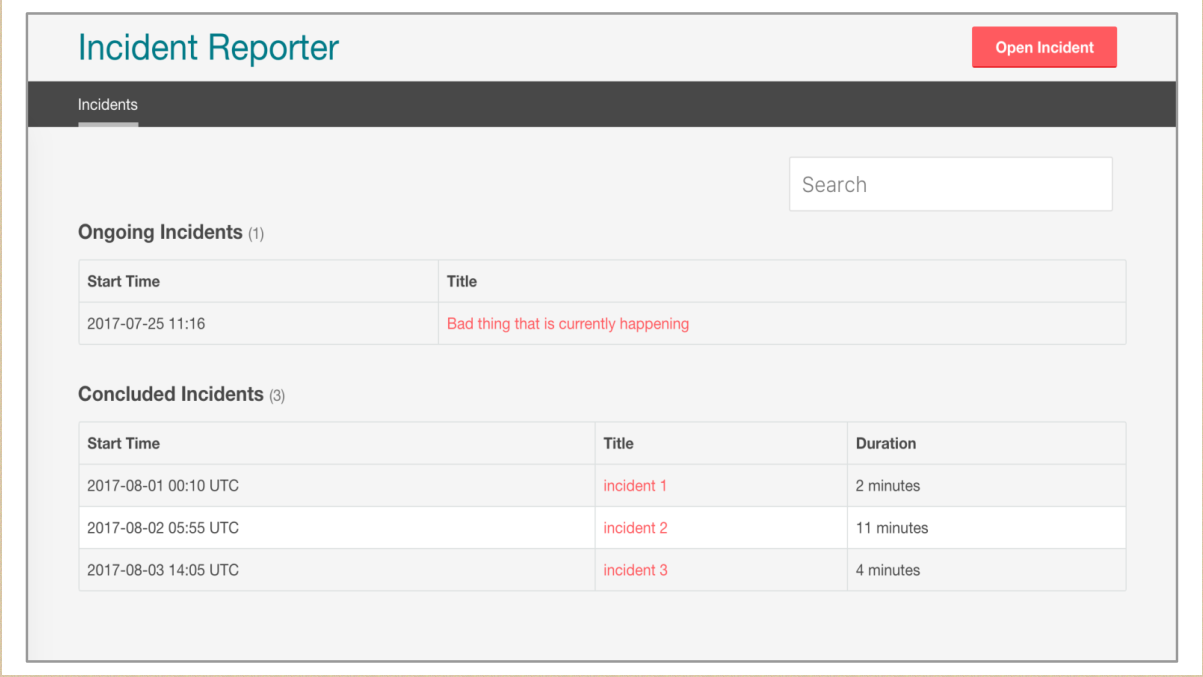
在实验当中快速地识别和报告,然后在这之后我们有快速的学习和积累经验的过程。所以说出现小问题没问题,快速地除错。如果它是数据库的问题或者是服务器的话,其实是有很多的经验,我们的工程师会发 Email 有什么样的问题,有些团队已经除错了,有的还没有。如果出现问题发十封邮件,有人说没问题,我可以5分钟解决问题;也有些人说,突然出现的问题我需要几个小时解决;还有些人会说这个问题可能不大。你发这个邮件的话可能是统一发,但是会得到不同的答复。实际上这个还会有什么?还会遗留,在回归方面还会有遗留,这方面也会告诉他们相关的事情,就是你必须十分钟之内来解决 Airbnb 的问题。
我们这个事情报告器的工具怎样做,事情发生以后它可以很快地进行跟踪。在我的想法当中说这个事情是非常昂贵的事情,发生了以后再培训是很昂贵的,可能一个小小的停止是1万美金,如果培训不到位可能1万美金就丢了。这个事情在 Airbnb 是有很多相关的事件,他们会受到信息的影响。我们看到有很多的团队在发生事件以后,他们可以相互帮助的,比如说 A Service 出现问题,可能B正在实施这样的事情,当中没有停机的问题,所以它可以帮助A团队解决服务的问题,或者是帮助他们尽量快速地解决问题,避免重复发现这个问题。所以说他们相互之间可以协调,告诉对方之前我们发现过这个问题,可以相互交流经验。所以如何快速地解决问题,如何快速地避免问题,我们有 Respone 这样一个平台进行沟通。

三、Ops未来的趋势
接下来和大家说一下未来的Ops,在 Airbnb 现在做得还是不错的,并且我们也看到了整个行业是尽量想解决问题,但是有的时候做的工作并不是非常理想,而且我们做的工作尤其是 On-call 对他们非常累。很多公司说工作和生活的平衡,而我们是说呼叫和工作的平衡。有的时候工程师得到一个呼叫,半夜两点起来干活,我们有没有更好的方式,不必每一个 On-call 都回应。其实不管怎样说, On-call 不断发展,工程师也在不断成长当中。所以在 Airbnb 他们在学习,我们也可以很好地量化他们所学习到的,或者是实践到的。我们有很好的一些工程师,因为他们进入大学已经学习了很多的数据库和计算机方面的技术,但是在工作当中,还是会有相关的他们没有接触到的东西,对于我们这个的话可以给到很好的学习机会,从错误当中学习经验,从而避免下一个错误。

还有一些问题作为我们行业的 On-call 如何进行测量?花这点时间去识别,这点时间去解决,为什么花这么多的时间?因为没有教科书告诉你怎样解决,或者说就是这个呼叫和生活的平衡。比如说2点呼叫,他们等到5点才回应,这都有可能。所以我们这边是有知识的排班,有些人可能是第一天获得问题,第二天回答问题。在 Airbnb 我们是非常智能化去进行这样一个安排,我也非常希望听到大家有没有什么真知灼见。
