@gaoxiaoyunwei2017
2020-11-17T10:09:02.000000Z
字数 4894
阅读 1577
云原生体系下的监控能力演进-王漫雪
彭小阳

作者简介:王漫雪,中移在线技术经理,他是致公党的党员,海归,在运维苦力行业是难得的美女熊猫,在PPTV网络电视工作中接触到运维开发,目前负责提升公司整体的研发项目!
本次演讲从5个部分给大家讲监控的血泪史。
一、背景
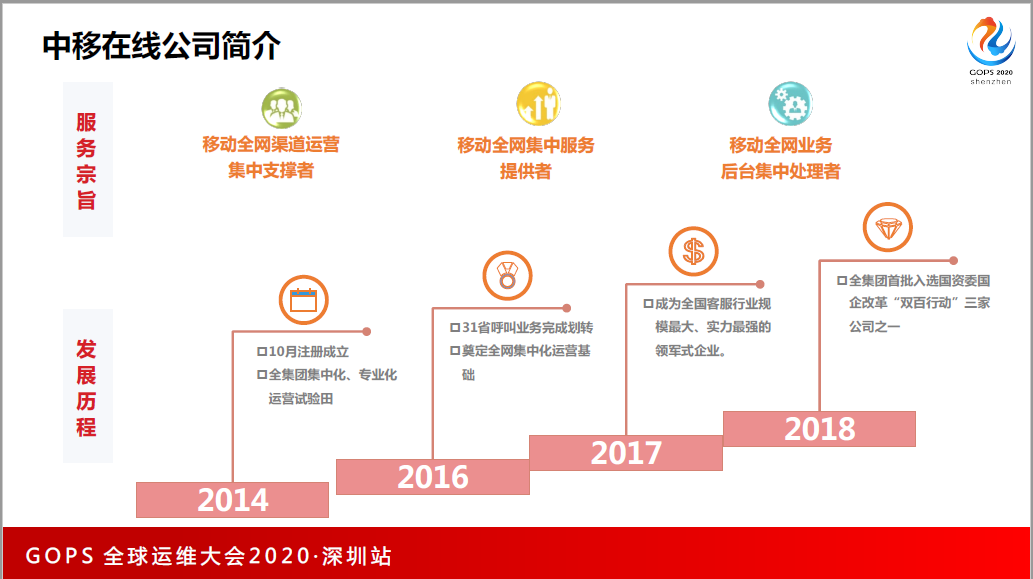
第一,中移在线公司的介绍,很多人问我是哪一个公司,是中国移动吗?我得好好介绍一下我们公司,我们是中国移动集团旗下的专业子公司。我们公司是做什么呢?下面坐的同学有多少给10086打过电话?大家用的这些系统背后都是我们公司做的支撑。
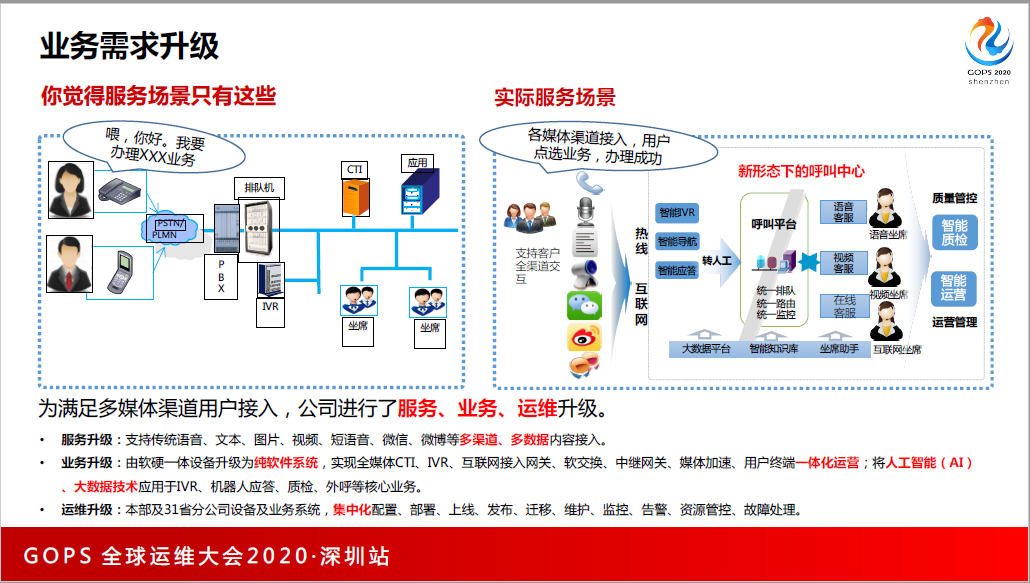
广东省的朋友们如果用5G手机,也是用5G套餐,会发现客服业务也不断演进,以前只能打电话,打完电话以后会听到查花费是按什么案件,现在直接语音说“查话费”就可以直接办理业务多播就是我们的业务升级。
业务升级给我们带来了非常大的挑战,9亿用户,支付宝今年2020年公布出来的用户数据大概是9亿左右,微信的用户数据在12亿左右,抖音今年的用户数在5亿左右,而我们是9亿,充分证明,通过用户量,我们IT的规模直接逼近了一线的互联网公司。
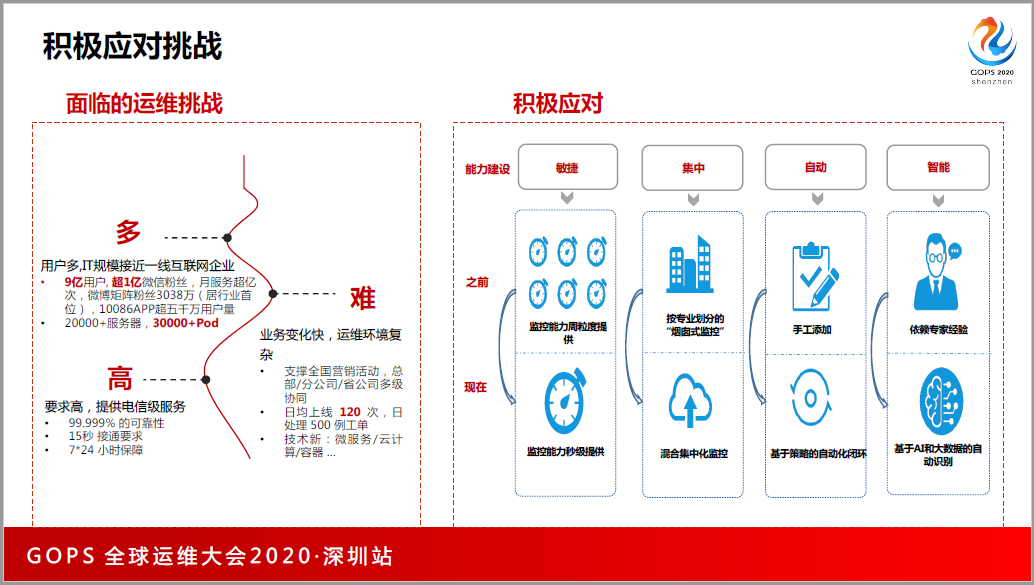
因为我们的业务变化很快,采用了很多的数据,导致现在业界都在说敏捷开发,我们每天上线120次左右,这是对于传统行业来讲非常大的数量,我们的变更很频繁。同时服务的要求也非常高。
二、出路
面对这么的的运维挑战,我们该怎么做呢?传统行业的人都有一个困扰,自己手下没有互联网的精兵强将,我们还有很多的厂商,如何去做独立自主、属于我们、我们也能快速实施的一套运维平台呢?

我们决定了还是要拥抱开源,站在开源工具的肩膀上,2017年我来在线的时候,在线的系统还是非常传统的服务,15分钟采集数据,知道有问题的时候,发短信给我故障了,我当时就不能忍受。
以前是网络设备的厂商做,数据库的厂商也提供了一套文管系统,新时期需要跨层、跨域,并且实时可视化的系统,我们比较了很多的技术评估后,选择站在了Zabbix的肩膀上,一个月的时间,就可以把监控系统铺上线,3个月之内把公司总部+31个分公司所有的基础设施的监控全部覆盖。
它也非常的稳定可靠,在生产环境跑了3年,基本没有出过太大的故障。可视化的看板,我们也利用了开源的工具,叫Grafana它满足了报表制作的需求。同时高效低成本,Zabbix本身资源消耗非常低。
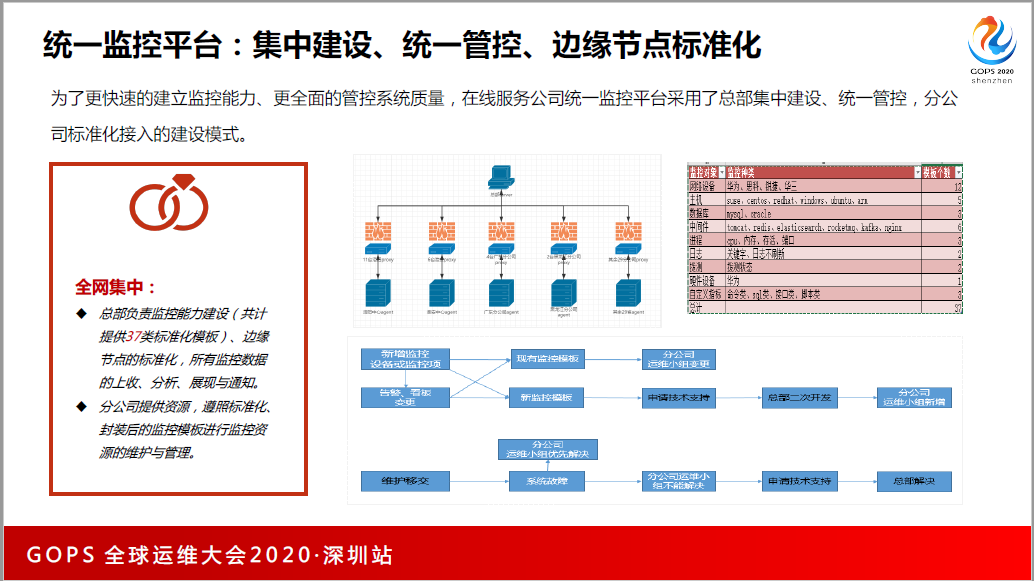
为了更快地把开源和监控能力铺开,我们当时选择的统一监控平台,总部集中建设,在很快的时间,通过Zabbix比较成熟的模板,我们自己也开发了监控的标准模板,也做了边缘化的标准化节点方案,总部负责做监控能力的建设,我们的分公司只需要监控能力的维护。
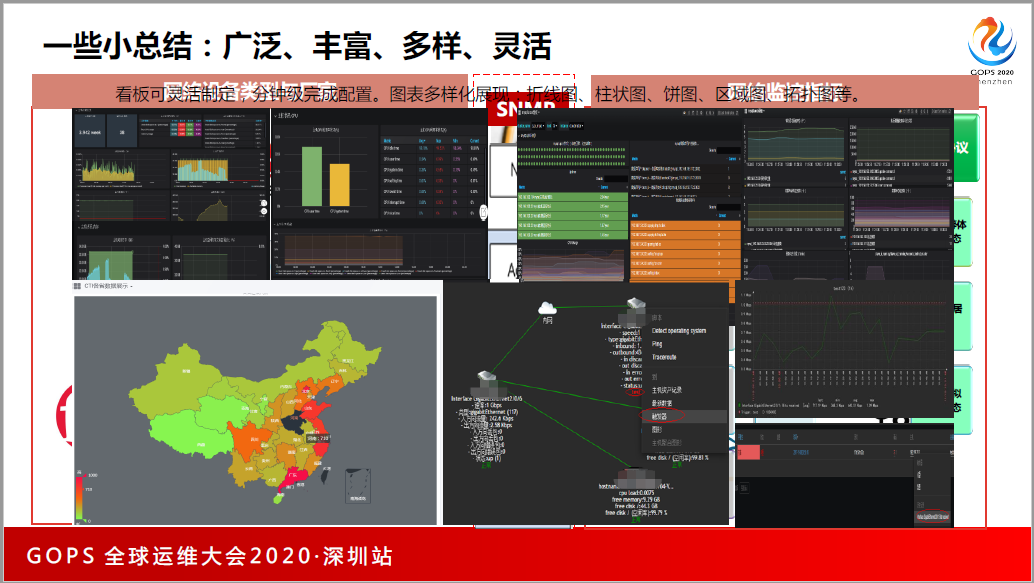
这些是我们利用Zabbix做的业界通用的、所有的中间件。这些是我们的网络设备,中国移动的网络设备都是集采,通过开源工具我们也进行了集中监控。半年的时间,把全网的2万台主机覆盖。
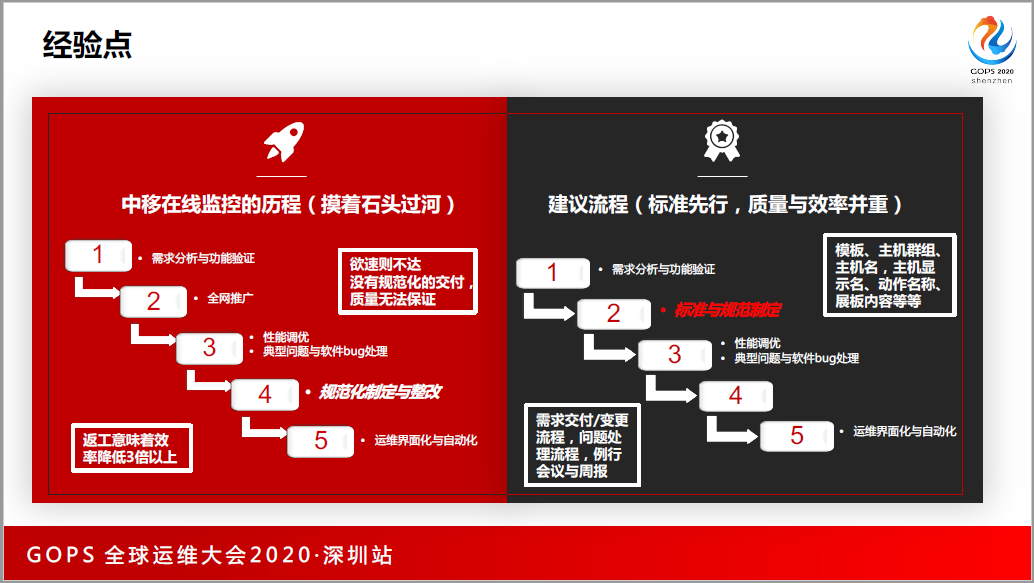
在基础监控或者是标准化监控铺开的血泪史,在线监控的经历,当时是摸着石头过河。我们做完需求分析,把标准化的模板做完之后着急全网推广,推广的过程当中,随着监控指标的增加,我们出现性能的问题,包括从底层到上层都有,我们都分门别类去解决,最后发现我们缺少标准化的规范制定,甚至数据模板的制定。
标准化做得太迟的时候,全网某一个监控数据铺开,这些数据不能满足某一方面的需求,还得重新添加,重新添加的时候没有自动化就跪那了。
三、问题
在运行维护过程中也遇到了很多的问题。
问题1,200万监控指标,业务出了问题仍然不知道。

后来做了研究,发现我们之前的监控系统主要覆盖的基础设施管理和应用系统的管理,对于业务的监控,那时候觉得这不是我们的事。
后来发现,作为一个公司,从公司层面来看,或者是从业务系统层面来看,业务系统的健康度是最重要的。怎么办?我们引入了应用系统监控的工具,ATM,它帮我们把业务系统的工具链拉了出来,我们学习了谷歌的SRE五项黄金指标,把核心KPI指标拿出来,做监控。
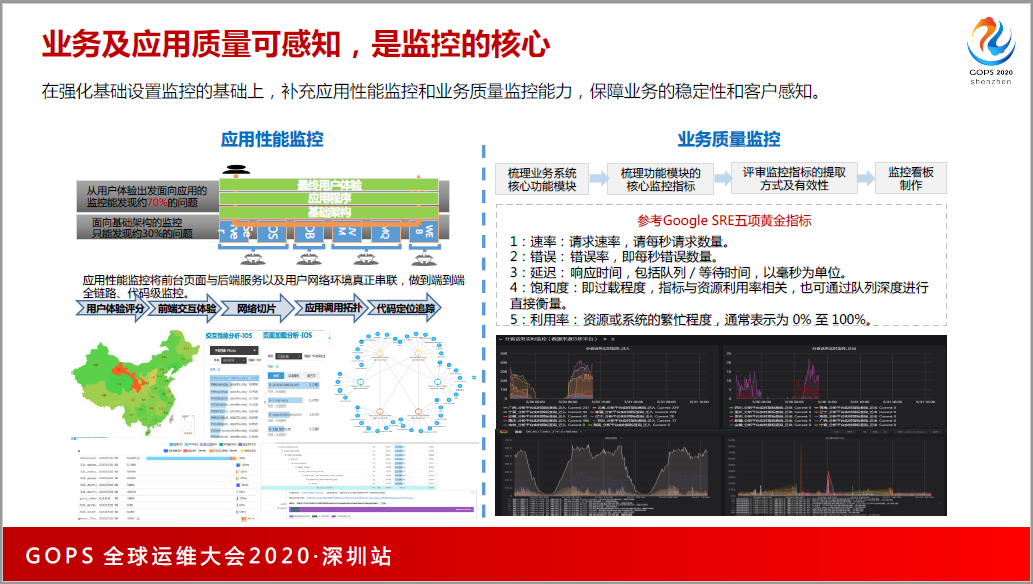
这个时候又迎来一个问题,业务系统说列监控指标,他们也不知道列什么样的,能不能给他们模板,这时候我们也很崩溃,最后我们通过五项黄金指标给大家列了一个表,请大家针对这个表去思考业务系统的KPI到底应该怎么办。

我们发现,业务的监控帮助我们发现生产系统70%的问题,我们也做了监控的分层,很自豪的告诉我们的领导说,现在也是有理论支持,能告诉你能够分几层,每一层有什么核心指标,能够给业务系统列表,哪些业务系统加没加全,监控数据的覆盖度够不够。
问题2,海量的日志是否有利用价值?
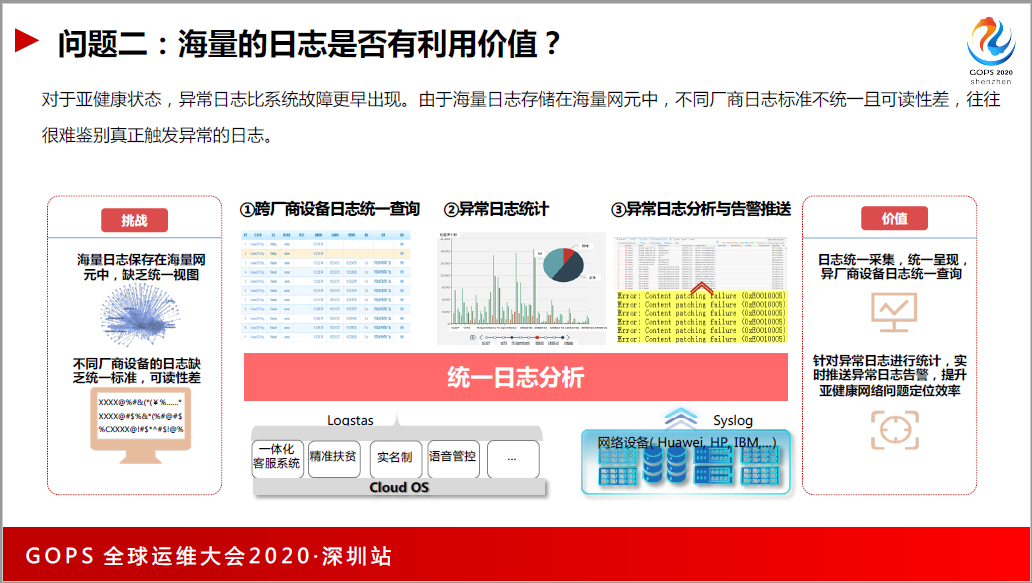
公司的基础设施很庞大,无论是网络设备,还是操作,还是业务系统,无时无刻不产生日志。海量的日志到底有没有用?对于亚健康的状态,异常日志比正常的日志出来的快,我们能更快速发现告警。

我们也做了统一的日志平台,分有插件的和无插件的,我们把所有的日志放在统一的日志平台,做跨层的分析和应用。
把各个分公司的日志实时传到总部做分析,还实现了基于全链路做的日志的下钻,包括调用面的分析,当业务系统挂的时候,能知道业务系统影响了业务系统B或者是C。用户以前只是说卡顿和慢,但是不知道慢带哪里,通过这个分析就能清楚看到在A应用上耗时多少,在B上耗时多少,最后在数据库能耗时多少,能清楚知道节点在哪里。
日志平台的相关数据,一天处理600条日志,日志的集群节点大概在400家左右。这个数量相对来说也是比较感人的。
问题3,容器上的监控怎么做?

这是我们公司的技术,底层的云计算也变革了,以前(英文)比较火,越来越多的公司去选型,选择去做云原生的升级,把业务系统切到了容器上。我们公司也是,去年一整年把80%的业务系统全部迁到了容器系统上,这对于运维来说也是很大的挑战。
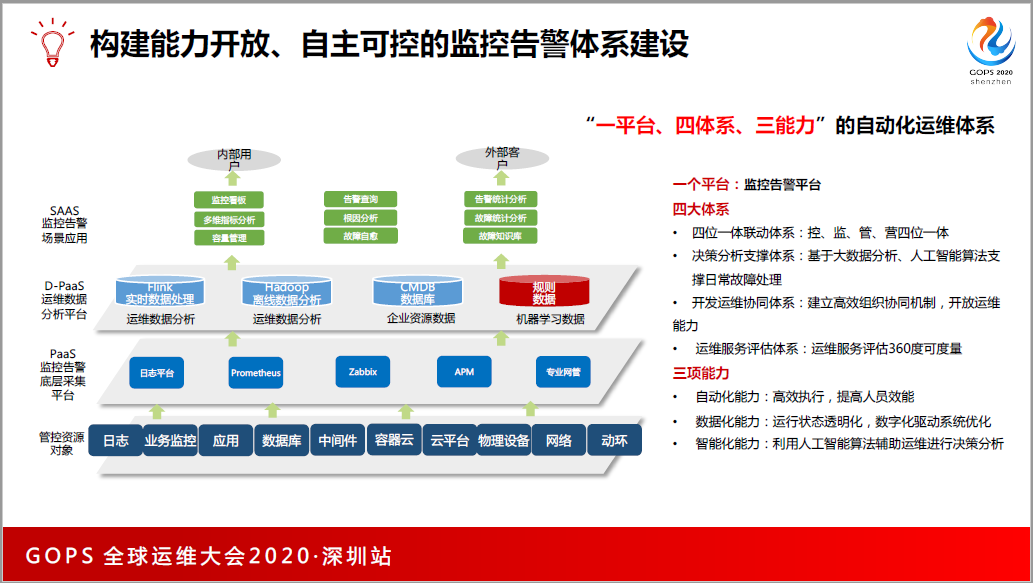
最关键的是,系统上容器,业务系统监控应该怎么做?目前我们的生产大概有3万多的(英文)同时在跑,因为我们公司的容器平台主要是基于K8s技术二次开发,我们选了K8S的天然支撑普罗米修斯进行了监控,包括监控里面速度机的性能监控、云资源的使用状况、容器的状态、性能组件的、集群事件的,包括(英文)之间通信的,我们分了这些维度,然后把监控系统搭建出来。
(PPT图示)下面这张表是跑在容器上业务的比较有用的监控指标,比如说入口访问量,Nginx的,业务接口运服务治理等等。
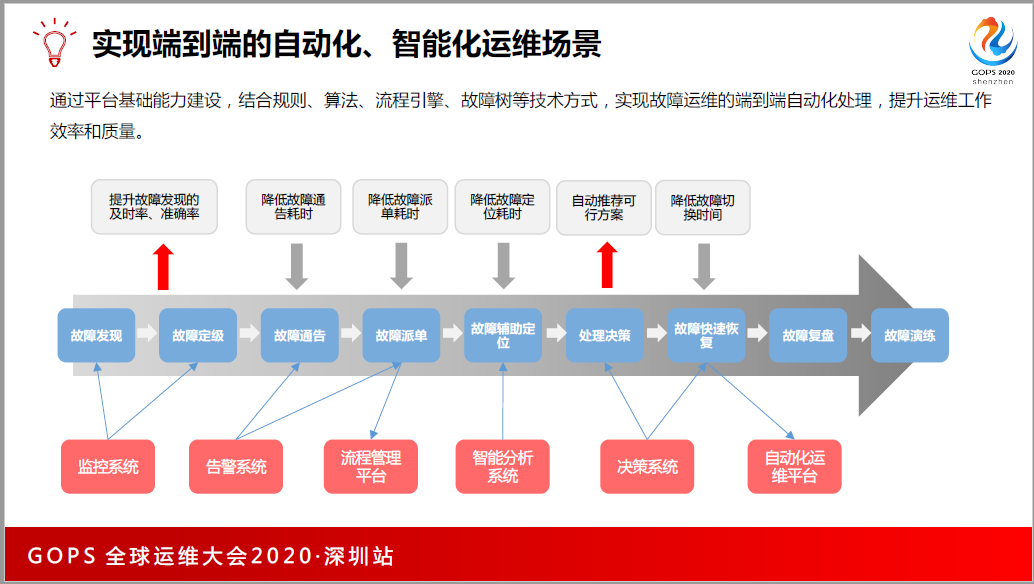
刚开始可能只有一个Zabbix,后来我们有了日志,我们需要去整合我们的监控平台。我们把之前的开源工具全部用来做监控数据的采集,我们把采集的数据放到实时数据处理、离线处理里面。
最后上层做了很多的监控应用,而这些监控应用又串串到了故障的处理当中,比如说监控系统会更早发现故障,最后通过数据决策分析,会通知大家哪些该切换,哪些该重启,然后实现故障自愈。
四、沉淀
我们还遇到了一些新的问题:
1.自动化提速
运维团队负责全网监控的时候,有一段时间我经常被投诉的问题,不是为什么出现了故障没有提醒,而是支撑得不到位。找我加了监控,2天内才做完,怎么不能快点?这个时候怎么办?31个分公司,每一个分公司一天提一个工单的话,那一天就31个工单,工作量非常的庞大。
那我们得想办法去解决这个问?我们经过一系列的思考,决定要自动化,因为前面已经标准化了,85%的监控需求,全部页面化,大家通过这个监控自助的页面,只需要通过工具,就能帮你做监控预检。大概6个月的时间,现在整个监控平台只需要2个自由人员去维护,就从每天做工单的恶梦当中解脱出来。
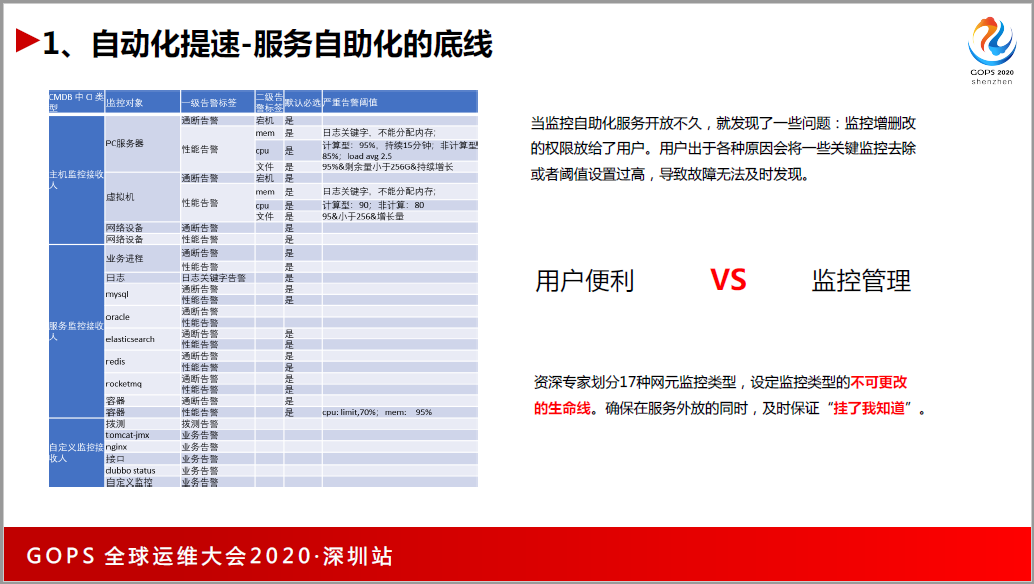
过渡的自动化的开放也会带来问题,把服务全部放给了分公司的朋友们,这会带来一个问题,有一天老板又找我,出了故障,我怎么没有发短信?监控告警都覆盖了,查了一下日志,是某位业务团队的兄弟,不想出短信,就把监控给删了。老板给我的要求是可以自动化,但是得保证挂了得知道,要不然把自助化工具关掉。
怎么办?跟各个业务线的专家制定了一个生命线,有17类的监控,细化到 CPO具体的指标,这17类的监控是不能改的。你再去提某一个分公司上线了100台主机,你加主机监控的时候,默认把主机生命线的监控加进去,这个阈值不能改,也不能删,保证系统挂的时候,短信告警会通知到你多播就是在自助和监控之间找到了平衡。
2.数据化赋能

这些数据有什么用?可以按照各种维度去进行业务系统相关的处理,把数据都放到大数据平台以后,监控系统本身的数据库的压力就没有那么大。经常有人问我,这么多监控指标,数据库怎么放?利用数数据做了应用的扩展,下面会具体讲。
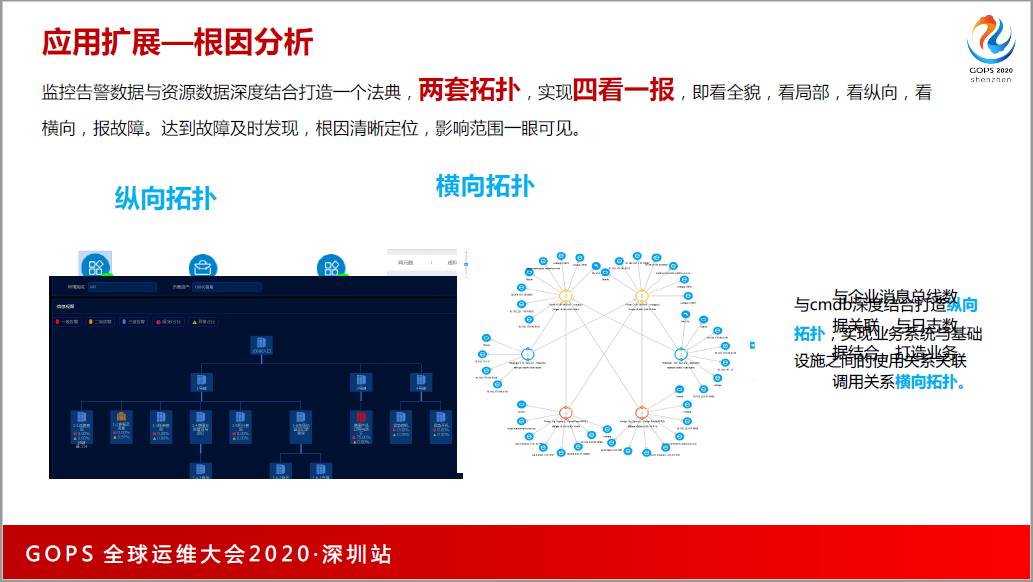
搞了这么多监控,能不能给一个大屏,能够看到哪些核心业务系统什么时候挂,比如红灯的时候,我一点就能够知道它挂在哪儿,这是做监控通用的需求。我们就打造了一个法典,两套拓扑,与cmdb深度结合打造纵向拓扑,实现业务系统与基础设施之间的使用关系关联。
我们又跟企业的总线数据关联,与日志数据结合,打造业务调用关系横向拓扑。比如公司内部有很多接口的平台,左边是一个接口,右边对应5个接口,因为你不知道哪一个接口挂了会影响到你的业务。当两个拓扑放在一起的时候,就可以拿到一个作战地图,能告诉老板这个业务系统到底好不好。

同时,我们也做了自动的扩容和自动的重启,以及自动的接口关闭。一般的容器平台都会带有一些CPU,那些东西出来的时候,依然会影响到用户的使用情况。还有接口的自动关闭,特别需要业务系统的配合,如果业务系统不做改造,肯定会报错。
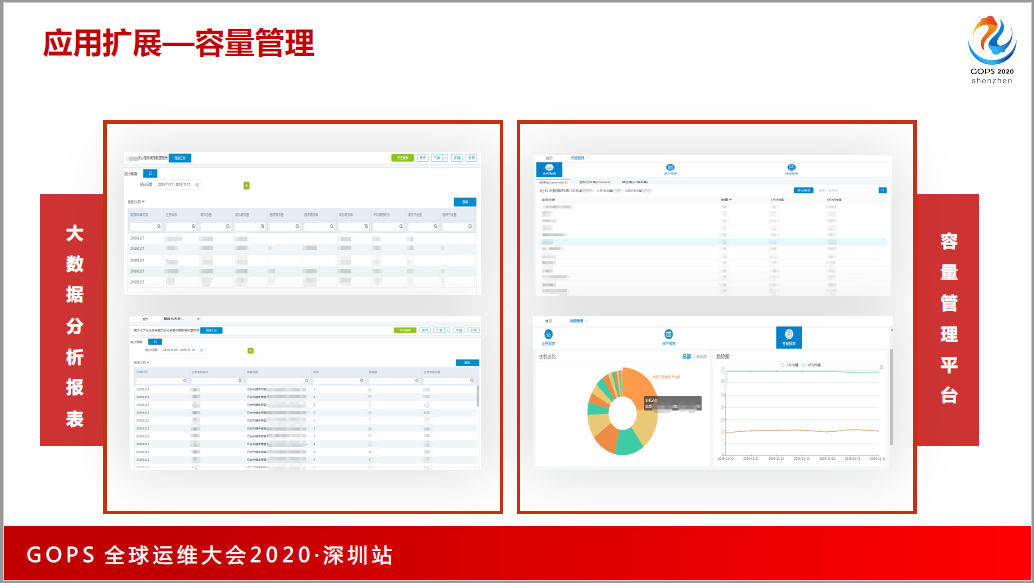
最后是做了容量的管理,做工具的,天然的使命,除了赋能,另外就是降本。降本怎么多播就是要靠精细化的管理,把监控的性能指标跟CMDB做结合以后,可以清楚给每一个业务团队拉一张招标,会告诉你业务团队申请了100台机器,平均的利用率是多少,有哪些不太均衡,是不是可以缩容?容量管理给我们节省了好几百台服务器,一台物理机20台,如果和老板说节省了30台物理机,那创造了多大的价值?
我们现在有3.4万主机,2606万监控项,600亿的日志。
五、蜕变
最后说 AIOps 在监控告警方面的尝试。
AIOps 有3要素,数据、算法跟计算,作为传统行业的人来讲,有没有数据,符不符合人工智能的要求?算法,有没有算法工程师,能不能优化算法,也不一定。看了很多业界成功的案例,我们挑了最基础、也是绕不开的东西,就是指标的异常检测。

当时为什么做这件事情?2600多万的监控项,团队的运维人员只有50名,一人每年收到2千多条短信,我们分析我们为什么会产生这么多的告警,有没有必要产生这么多的告警,我们的告警是缺少一定的压缩和关联,非正常的高告警有很高比例的误报,业务系统不知道核心的KPI应该设成什么样。还有漏报,70%的原因是没有办法准备设立告警阈值。
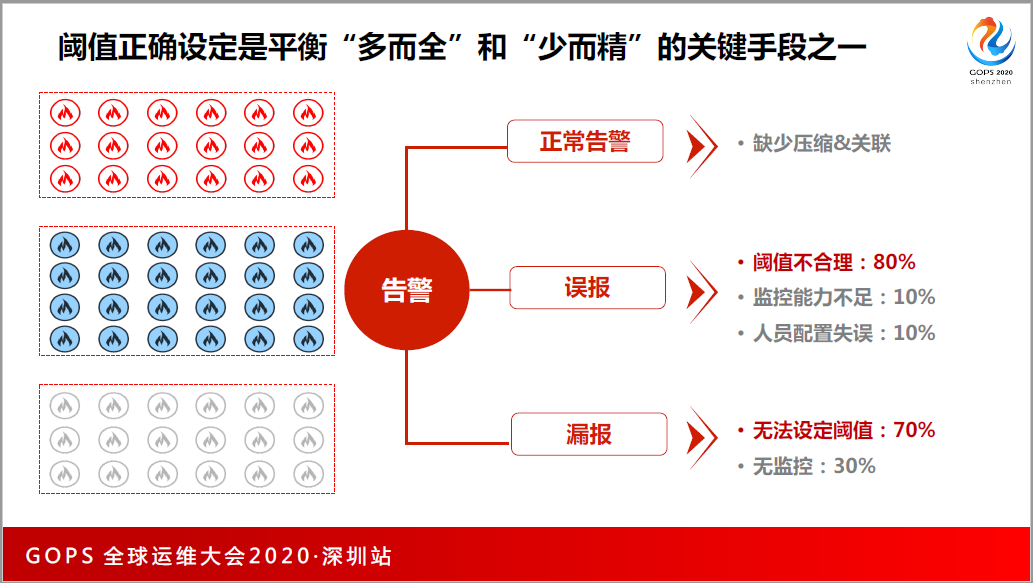
告警阈值设计的经验怎么来的?一开始都是拍脑袋,网络设备的CPO应用率超过多少应该告警?大家的脑子里都有一个值60%,后来我们有了这个累计,不盲目去拍60%,也不是每台设计都设60%,可能就看这个指标历史3个月的走势,根据每一个指标设定它合适的阈值。
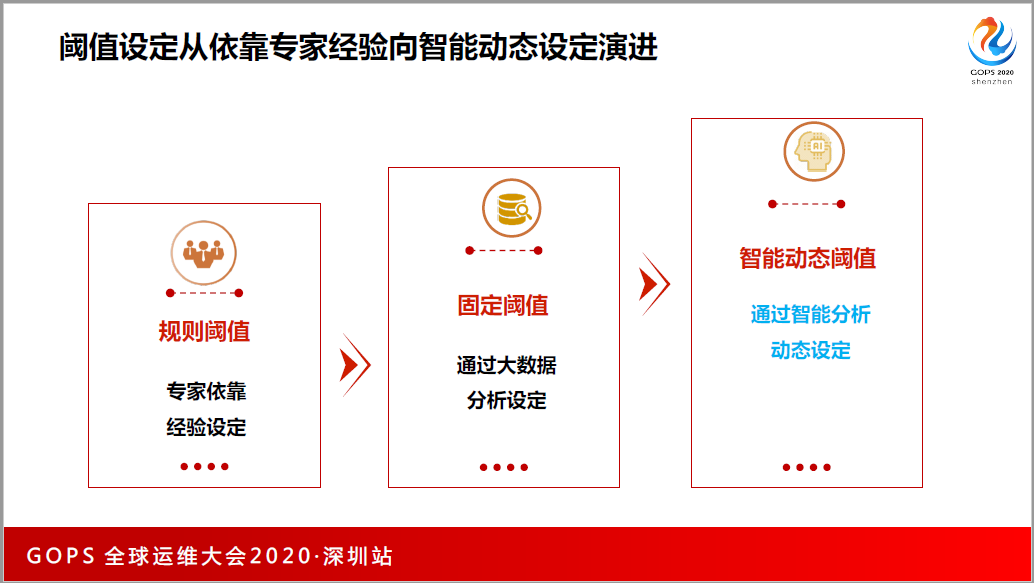
每一个公司都有不高峰期和低谷期,比如我们的客服系统,每个月的月初和月末我们都是最忙的,繁忙的时候,CPU利用率上去是很正常的,这个时候干嘛还要告警?没有通过智能化,只能拿到死的告警。如何通过人工智能得到动态会变的、又符合应用系统规律的阈值呢?
我们通过结构化的实时数据,通过AI,这个东西在业界比较成多播就是指标的异常检测。
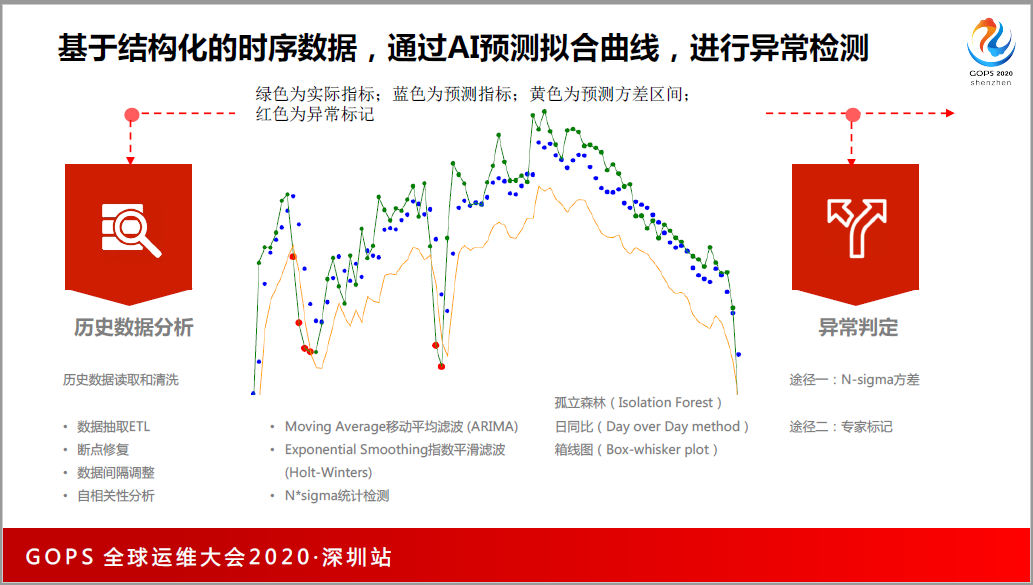
它的原理是什么呢,把为期6周的历史数据拿出来,把采集断点的数据修一修,把毛刺过虑掉,然后可以用LSTM预测算法等,通过学习历史数据,预测未来的趋势,预测未来趋势之后,会得到3条线,绿色的是实时的监控系统的指标运行趋势,蓝是预测的,黄是预测完之后交叉的结果,通过这个,比自己设固定阈值要更准确。

这个功能已经上线,告警准确率可以提升到80%,告警覆盖率提升到95%,同时告警配置的人也有所下降。指标的异常检测,可以不需要你有标注性数据的,算法也不需要有太高精尖的算法工程师,也不需要GPO服务器。
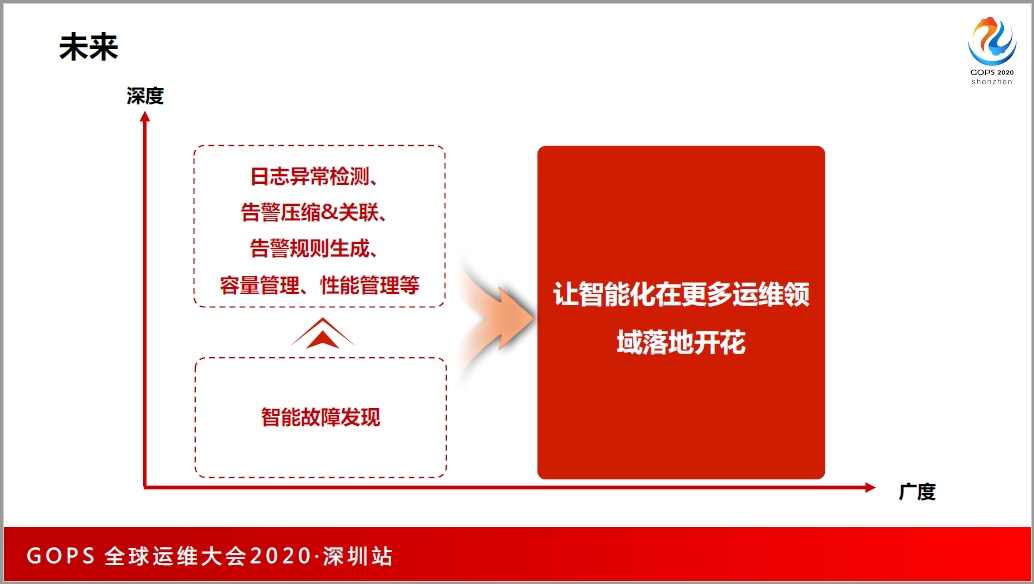
在未来,人工智能,AIOps也是慢慢可以进入传统行业。我们现在也做日志异常检测,日志智能的告警和关联,包括实时预测。