@gaoxiaoyunwei2017
2019-03-08T10:09:43.000000Z
字数 7461
阅读 1188
构建银行运维SWAT
白凡
分享:张晓强
编辑:白凡
大家好!我是来自于平安银行 科技运营中心副总经理 张晓强,今天我给大家分享的为“构建银行运维SWAT-特殊武器攻击队”。
1. SWAT的定位
首先我想问大家,谁知道是SWAT?特别对运维来讲,SWAT是做什么的?我先讲下SWAT是做什么的。今天我的PPT做的并不复杂,更多并不是给大家介绍一个具体的工具,更多是一些理念。我们知道银行运维最关键的两个指标是非常高要求的,5分钟内必须要恢复如何做到其实是很难的。我们不仅要在工具上,甚至对故障的流程、理念上必须要有很多的思考,做好银行的运维是一件非常非常有挑战性的事情。
我加入银行的时间不长,一年不到。过去20年我都在互联网企业,在eBay和携程都工作过,来到银行后我把过去在互联网的经验带过来了,大家做的方法都比较类似。
回答一下大家什么是SWAT,SWAT源自哪里呢?叫Special Weapons And Tactics,是美国特种部队。2013年有一部美国大片就叫《SWAT》,是一部很精彩的动作大片,从那天开始我真正知道了代表的是什么。

SWAT在警察部队里是冲在一线的,处理各种紧急情况的团队,运维也是一样,运维故障发生的时间都是不可预测的,所以我们需要有这么一个团队。这样的团队是否需要专职,专门组建呢?也不一定,可以根据实际情况来决定。
对这个团队最基本的定义,首先团队里必须是运维各个领域的专家级,对运维的各个Layer基础价格必须要有专家级人工,因为运维有24小时值班的机制,团队可能不是现场值班,但属于24小时待命的状态。跟警察一样是冲在解决运维故障的第一线。这就是我对运维SWAT团队的定位。
再具体一点,生产运维系统不仅受到银行的关注,同时还会受到监管的关注。监管对银行的要求是如果有一个事件发生超过了30分钟,你就必须要报到监管去,要给监管解释这个事情所有的来龙去脉,甚至监管可以进入银行做进一步调研,为什么要花这么长时间才能恢复故障?要把处理的过程、流程、故障的日志都要拿去做分析,同时跟你讲可能这一块儿做的不好要整改,给你下一个一堆整改的文。我们更需要冲在第一线帮我们快速恢复生产事件。

常见的生产运维事件都是不可预测的,监控系统就是用来发现这些问题。刚刚王总讲了,大机在银行内部是5分钟,30分钟是监管的要求,但事实上5分钟要做到太难了,5分钟甚至连问题在哪里都发现不了。所以有时候并不是简单的技术问题,甚至我们做了很多工具有没有在真正发生故障的时候发挥作用还很难说,所以必须在价值上、团队流程上保证对生产运维故障的发现是属于相对比较稳定的,而不是发现故障只用1分钟,处理另外一个故障的时候却花了半个小时到一个小时。
团队职责大家都懂,我也不具体解释了。再细分一下需要哪些知识,需要对银行的应用架构有非常精细的了解,不要知道应用的架构,还要知道部署的架构,跟技术架构相关的。
还需要知道一些应用异常时的表现和大概处理的机制,还需要知道银行的应用也是关系非常复杂,要如何知道应用之间的关系和依赖关系,还要知道最核心的逻辑是如何实现的。对运维最基本的能力就不一一细讲了。

2. SWAT的武器和战术
关键讲一下SWAT的“武器”,有一本书叫《七本武器》,总结来讲运维SWAT团队需要7种武器帮我们发现问题,迅速地定位问题做根因分析。不断地训练团队恢复故障,分析运维故障离不开4个战术。恢复战术总体来讲无非就是用4种方法恢复生产的故障。

稍微具体一点讲一下,
2.1.监控(长生剑)
这是最重要的。概括来讲监控是不太容易做好的事情,大家都知道监控很重要,真正要把监控做好和落地不是我告诉大家一个监控工具像普罗米修斯等用了就解决了,当然不是。通常来讲会把监控分为三个层次,其实每个层次可以更细化一点。
(1)业务监控。银行、互联网最重要的就是业务,需要知道业务指标是否正常,一定会做业务监控,要知道业务指标在发生故障的时候有什么异常的表现。对银行来讲,银行不在意这方面的指标,像口袋银行更关注的是转账的笔数,这段时间有多少人登陆了口袋银行。为什么要关注业务呢?因为接下来我们要做的是关键路径。什么是关键路径呢?关键路径很多,你怎么定义什么是你的关键路径?出发点就来自于你的业务,如果我要监控用户的转帐业务指标是否正常,除了业务要根据此来定义出关键路径,就需要看转帐从口袋银行进来以后会经过哪几个环节,经过哪些应用的调用关系。不然如果你对你的业务理解的不透彻的话,你就很难定义出关键路径。为什么需要关键路径呢?因为互联网金融化以后调用太复杂了,可能是成百上千,但事实上不可能有能力监控到这么多,所以最最重要的是怎么找出关键路径是什么,而且如果我们把关键路径整体掌握的话基本上就解决了大部分重要的问题。因为很多其他非关键的指标或多或少都会这条路径本身。
(2)应用监控,业务监控是告诉我们生产有没有故障,问题是你要解决故障要知道哪里有故障,应用监控是告诉我们支持业务的系统、子系统、应用出了问题,不一定出了很严重的问题,但如果变慢了也是冒烟的信号。
(3)系统监控,基本所有运维人一开始做的就是基础架构的监控,但今天数据中心规模基础架构本身监控每天会带来一天700、800条,这么多就处理不过来。所以需要的是上层的监控告诉你基础架构的紧急度。虽然你会做聚合,可是你还是想知道基础架构本身的监控告警对业务真正的影响是什么。如果对业务没有非常非常大的影响,你分配和处理的时效就没有那么紧急。但如果业务和应用已经明确告诉你同时又有很明显的指向基础架构本身,那你很容易知道是哪一个基础设施给你带来的问题。

关键路径再给大家细讲一下,我们做的大概方法是会把银行最核心的关键路径,每天大家打开App本身第一个点的按纽是余额查询,我现在在银行有这个习惯,每天打开来先察看一下余额。这就是关键路径,对用户来讲你打开APP如果查不到余额,甚至看不到卡就会慌张,这就是关键的业务。所以这也是我们定义关键路径的切入点。我从口袋银行、余额查询的场景,让运维和开发者告诉我们用户要完成余额查询场景所经过的各个系统和各个基础架构的点,要全部定义出来。这是我们判断的一条关键路径。
有了这条关键路径能做什么呢?你的监控要以关键路径作为切入点。以前监控是扁平化比较简单的层次,但其实监控需要做到的是场景化的监控。以前大家讲的比较虚要做场景化的监控关键是切入点是什么、场景是什么,每一个公司都有自己最关键的场景,银行最关键的场景是用户每天能看到卡里的钱,每天能转帐,跑到网点可以取钱就是关键的路径。定义好了关键路径以后要把系统的清单和调用的关系弄的清清楚楚,明明白白。
如果你连关键路径都做不准,你怎么能解决生产上几千个应用?先不说大的,最差最差的不能那么快发现,但是业务最重要的场景必须要立马知道,而且要非常快。首先你要真的列出来,弄的明明白白,不停地演练关键路径本身,如果出现某些问题的时候应该怎么处理。你的“武器”是围绕着这个打造的,而不是为了每一个监控、每一个报警训练团队是没有意义的,因为每一个监控是独立的,并不会给你带来实际真正有意义的技能提升。团队的技能是围绕着场景打造的,团队要非常清晰地知道根据关键的业务指标定义出来的关键路径的系统关系。最终可能会转化成服务的API和IP地址,之后再进行场景化的监控进行实时探测。这样基本上可以在分钟级发现问题。

2.2 智能告警(离别钩)
今天所有的东西都要做智能化,智能化能帮到我们什么呢?因为规模大了以后告警和预值、阀值的设计会给你带来很大的工作量,所以需要更多智能化的工作。
第一个智能化体现在你的监控怎么跟其他系统联动,我到了银行发现银行有很多系统、很多流程,但是驱动系统和流程的还是人,不是说不好,当规模小的时候可以做的非常好,但到了一定量的时候根本做不过来。流程本身是没有问题,每天面对的海量告警的时候就做不了了。为什么我们要跟变更系统联动?因为银行每天有很多变更很多发布,如果你不跟报警系统联动做变更的时候会产生很多大量的告警,通常告警出来了分配的时候接到单子会问一下谁在做变更,就可以直接知道因为有谁做变更所以导致的告警,所以告警不需要做处理。有时候做网络的变更会给你带来成百上千个告警,靠人工的话效率非常低。所以需要更智能的告警系统知道你的生产在做变更,看似简单但需要做很多工作。
以前的变更流程大多是围绕着ITSM的系统,这套系统没有办法主动地告诉你谁在做变更了,你怎么来建立这种闭环?你怎么知道谁在什么时间点做变更,不仅是人要知道,系统也要知道,特别是告警系统更要知道谁在什么时间做变更,这样才能把很多的告警真正地和场景进行关联,达到聚合的目的,这是更智能化的聚合。
有的时候发布也会带来大量的告警,持续交互的流水线如果一直在跑的话每天会给你带来大量的意想不到的变更。过去人工的方法是知道机器要做发布了自动设置系统变成Offline。我需要系统告诉我出问题了,但一旦设的话你需要知道有法把的系统告诉体在这台系统上发布了,我国才自动屏蔽,这是最好的办法。为了避免大量产生告警,通常的做法是把监控系统给关了。但监控系统关了最大的问题是有时候关不掉,因为是基础架构的东西没有办法根据这个变更单独关掉某一个,有可能你做的是这方面的,但其他方面有问题还是需要告警出来。更多应该站在智能告警角度,所有的告警都应该告出来,只是应该知道告警的源头是什么,通过智能化的场景关联屏蔽掉、静默化。
收敛是帮我们做根因分析很重要的工具,当你应用多的时候一定要知道告警是不是来自于跟同一个应用有关联的,所以你必须要做到基于应用的收敛。基础架构一定要知道是不是来自于同一台主机、同一个网络交换机、同一台机柜。这些信息都非常重要。一个网络交换机出现故障的时候你可能会收到成百上千个告警,就会被淹没。如果没有数据收敛告诉你所有的设备都是接在了这台交换机上,你马上归知道设备的根因就在这里。今天我谈的是理念方面的东西,因为很多东西并不是靠一个工具就等解决所有的问题,你得设置工具本身,有的可以用开源做改造来达到效果,有的要靠自己来研发。

2.3 沟通(碧玉刀)
今天在处理大规模生产故障的时候在沟通方面做的好的团队并不太多,特别是在大规模故障面前如何有效地进行沟通和协作来处理故障是非常难的课题。因为它会涉及到非常多的团队、人、内容,所以如何促进有效沟通是生产运维非常重要的一件事情。
现在我们也没有完全做的非常完美,已经好的工具是电话自动呼叫,举个例子每天收到几百个告警,这些告警如果靠人工分配会很慢,但如果有自动语音呼叫会好很多。当我收到告警的时候知道告警是某一个应用,这个应用是某一个开发、某一个运维的时候应该通过TTS呼叫自动把告警信息通过打电话的方式通知他,这是最有效的一种方式。为什么呢?用来对付开发是最最有效的,最常见的是哪一类告警?就是代码写的不好,上线以后带来性能的各种下降等,此类告警运维接到的时候很无奈,也是打电话找开发说让他们看一下是不是有发布或者做过什么变化,开发说去看一下,然后过半天也没有什么反应。语音呼叫的好处是不需要你去告诉他,只要是这个相关的可能找他,单位就呼到他那里,如果不接会一直拨,拨几次以后一直不接会拨到老板那里。处理的时候必须要进入系统调成已处理的状态,运维团队可以大大减轻人工。以前大量的工作是通过人工的工作,我们银行现在几百个运维对3000多个开发根本对不过来的,如果每个人要看开发沟通让他告诉你解决没解决,效率非常非常低。
短信通知也是告警的一种方式,但是短信通知的场景是当你发生比较大的故障的时候通过短信广播的方式会不及时。当出现任何故障和对业务产生影响的时候会启动电话会议系统,电话会议系统会把开发、运维全部拉进来,也可以主动拨入。当几十个人的电话会议开起来的时候如果团队没有做好很好的电话会议培训的话会是乱哄哄的局面,如果大家有用过应该会有感受,当几十个人拨进去的时候每个人都想说话都想表达,甚至有人在比较嘈杂的环境里会带来很大的噪音。进来的时候要说你是谁,你做了什么事情。标准化地第一时间说出有效的信息。当你不讲话的时候一定要静音,平常开电话会议也是这样,免得环境的噪音带来很大的影响。 每周都在做团队演练,刚才做了很多系统梳理了很多东西,如果不演练的话很难在真正故障的时候会不知道做什么。

2.4 应急处理流程(拳头)
针对每一类场景银行会梳理上百个方案,但其实在这方面对关键性梳理才是核心中的核心。知识库是服务台最常见会用到的,还有如果有应急的管理系统告诉你在故障发生几分钟以后应该通知谁也会帮助你提高应急的响应时间。

2.5 运维自动化(霸王枪)
当你发现故障的时候如果还是要靠手工做很多恢复故障的,最常见的是需要重启几十台、上百台服务器,一台数据器服务期宕了切换到另外一个状态,最常见的恢复是应用服务器自己知道是什么,但通常情况下上去改一个IP,然后应用需要重启,如果没有自动化工具帮助你哪怕你已经知道怎么恢复还是要花很长的时间,这是我在银行看到的比较常见的点。我已经知道怎么恢复了,但是我的能力不够,如果有自动化的工具重启100台可能只需要5分钟就搞定了。银行有特殊的一点不能在办公环境里做这件事,要跑到操作间才能做,因为只有操作间是可以连生产系统,其他办公的电脑一概不行。这时候效率是非常低下的,所以做好自动化运维很重要。自动化运维涵盖很多,今天大多数银行都在学习互联网,要把日常运维包含在工具里,包括恢复故障时用到的命令、操作。这样才能在故障发生的时候有信心用,如果只是在故障恢复的时候用通常已经不起作用了,因为很多东西在飞速变化中,你配置的东西也在变化的很快。

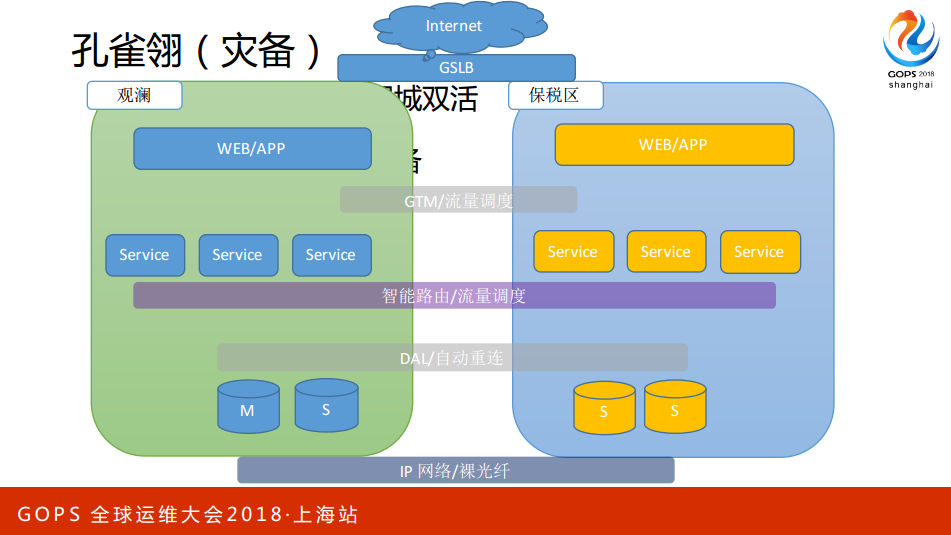
2.6 灾备(孔雀翎)
关于灾备银行是最自豪的,工行、建行基本的配置是“两地三中心”,同城有一个机房,异地还会有机房。但是要真正做好又是一件很难的事情,很多时候我们经常生产出故障大家还是花时间在恢复故障本身,真正切换到其他数据中心的场景非常非常少。为什么?因为很难,系统多、配置多,各种关系复杂你很难判断,切了还可能会导致最大的问题。
过去我们实践过很多,如果你的应用是互联网的话可以比较清晰地分出层次,这样在你的两个数据中心里应该让应用处于双活的状态,这样就不存在切换的问题,所谓的切换其实是通过内部探测服务本身自动实现切换的,很多的互联网公司都做了这方面的探索,因为一个平常没有流量的服务是不敢轻易地接过去的,这个时候你必须把应用和服务、数据库根据应用纬度实现真正意义深的“双活”,这样才能真正地实现数据中心级别的应用切换。
刚开始先同城再异地,对银行的应用来讲,银行是强一次性应用比较多,所以异地很难实现,但是同城是比较好的选择。让你的同城两个应用都处于有流量的状态,这是你实现灾备切换最基本的要求,如果没有这个要求你其实是不敢有任何切换的。
2.7 远程运维(多情环)
远程运维对普通大多数没有什么问题,但是银行是不允许远程登陆操作生产系统的,我交流了很多银行,有些银行没办法但也限制的非常严格,VPN很多银行是不允许的,因为风险是很大的。你要做的还是要依赖于工具本身,远程VPN进去如果可以操作任何秘密的话是巨大的风险,但如果有运维平台一都包含在里面,那风险就相对来说是比较可控的。我们都是通过云桌面来处理,但很多生产系统只能看但操作不了。

讲完了武器后面讲一下恢复的4个大战术。
2.8.回滚
包含了代码的回滚和应用技术的回滚。最常见的是代码本身,如果有很好的发布系统的话能够实现代码快速回滚。对于技术架构本身来讲回滚就是重启服务,恢复到原先的状态,服务状态现在不正常或者有一台服务器内存异常了,应用服务器重启它其实就是回滚,这是最常见的战术之一,也是在做运维变更和开发时首先要想到的,任何一个变更肯定会问能回滚吗?能回退吗?道理是一样的,状态要回到你做变更之前,代码也是同样的道理。

2.9 故障隔离
交换机经常会莫名其妙有些端口出现UP和Down的状态,这个时候你不可能重启交换机,因为它只有一个端口,唯一的办法就是把故障端口进行快速格力。技术架构是冗余化的,你需要把有问题的隔离出去,例如一台服务器有问题赶紧把它的拉出来,某一个端口有问题赶紧处理掉,这个端口属于故障隔离本身。如果你开发代码里有功能的开关,当它发布完以后打开开关发现功能没有像它想的那样工作的时候,这个时候开关快速关闭也是属于故障格力,不需要做任何的操作就能避免故障进一步扩大、恶化.

2.10 服务降级
站在业务的纬度讲更合适,拿银行口袋APP本身,当我出现问题的时候我要保障的是什么?大家想看到的按纽叫余额查询、转帐,这个时候理财产品收益率看不到没关系,所以你恢复的策略是服务降级,把业务本身非关键去掉,不用再给用户看那些没关系的,你要保证核心的业务和路径是什么,你要保证它,当你要选择A或者B到底要断哪一个的时候只能选择之前梳理的逻辑,就是你梳理的关键业务和关键路径本身,其他的通过服务降级去掉。这是暂时恢复核心业务,而不是完全治愈的。乱七八糟的各种高阶的都可以关掉。

2.11 灾备切换
刚才讲的是整个灾备,但你还有很多好的办法,如果你可以基于应用纬度或者建立起来的这么一条路径在某一个节点上都可以实现灾备切换的话,那你可以实现同城A应用在两个数据中心部署,如果我在数据中心A发布了以后出现问题可以立马把它切换到B,这是恢复应用本身最快的办法。这种方式叫“蓝绿”发布,也是以前最常见的。你在A数据中心发布它有问题最快的方法是切换到B数据中心的同一应用,条件是基本需要同城,特别是对异地时间长、距离长的比较难做到的。当你的数据库数据中心A出现问题的时候你需要切换到B,你需要不停地训练团队。这些东西设计出来不是看,如果大家只是理念上的要有这些东西是没用的,这都要通过日常演练过程中不断地强化团队在切换这方面的能力、恢复故障能力的提升,你需要构建一个团队,不停地对它进行演习、战术的培训。

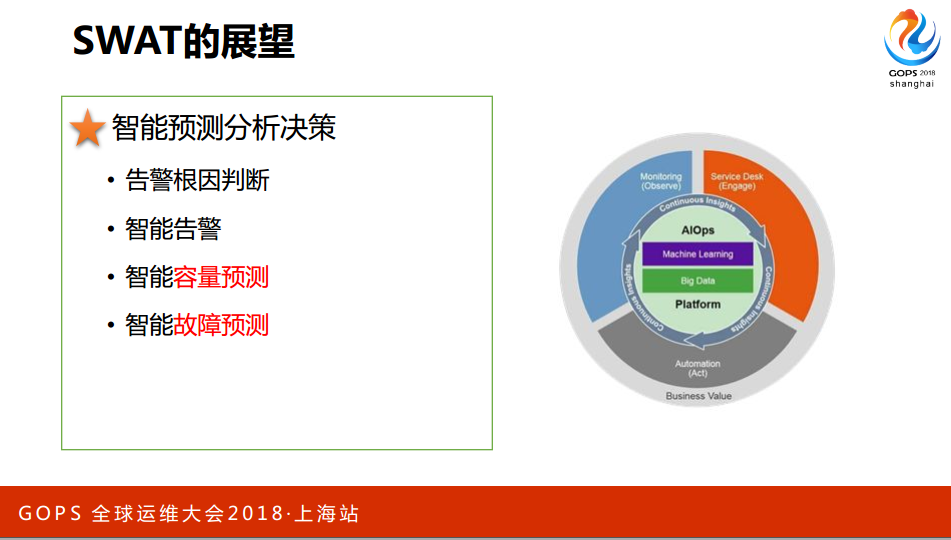
3. SWAT的展望
稍微讲一下展望,做运维的任何一个人哪一天有系统可以直接根因甚至推荐恢复的路径和办法,那这是最理想的,当然这有很多很多工作,这太理想了,我们能做的是站在实际的角度你需要恢复的关键是什么,你可以在这方面做尝试。容量和最好控制量的预测是最好的,像以前普通的硬盘可以告诉你多少时间会坏,如果我们能够做到容量在这方面更靠前的预测,而不是靠真正发生故障以后的恢复是更理想的,对于运维来讲更友好更理想化的状态。