@gaoxiaoyunwei2017
2019-02-14T06:36:52.000000Z
字数 6602
阅读 1533
千万级日活背后的系统运维技术支撑
luna
作者:顾贤杰 资深系统运维专家
作者介绍:顾贤杰,是网易杭州的运维部的资深运维系统专家,在运维这块大概工作了10年左右,从大三开始进入行,很凑巧那时候差不多是2006、2007年,互联网刚起步。也经历了运维从小团队到大团队,从脚本化的年代到自动化、平台化。
今天我分享的不是我们的业务有多少,实际上我来讲的是我经历过很多的业务上遇到的问题,我们对运维的一些思考还有一些探索。最后是一些云上的应用情况。

1、系统运维的挑战
首先我们看一下在网易实际上有很多的挑战,网易大概20年的时间,时间挺漫长的。我进去的时候刚好公司成立差不多9年到10年的样子,我们之前经历过这么多的挑战,包括日常运维挑战。有很多的技术债务,很多的技术都是很先进的,一些产品增速可能远远大于我们人员的增速。还有突发运维挑战,可能跟其他业界同仁一样,有产品的突发性需求和外部突发事件。
这是一些复杂的产品线,我们的团队实际上是一个挑战很多的团队,首先从基础设施。
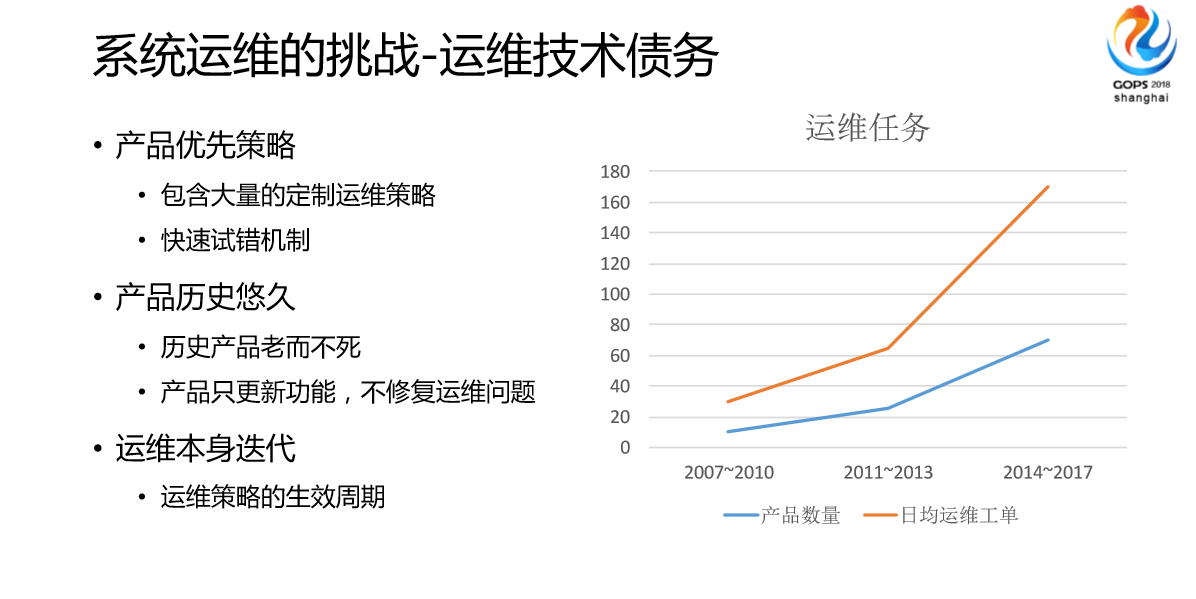
我经历10年的运维以后,我感觉我们在说起DevOps之前,我们面临的情况是这样的,所有的线上运维实际上不被重视的,一开始领导不重视,感觉产品赶紧开发完上线就可以了,我们面临很多技术债务。比如说产品一定要上线,没有开发完怎么办。运维有办法去,这就是定制的策略,还有一些快速试错,出问题了,我也不知道代码哪里有bug,你们帮我们调一下。还有产品历史非常悠久,我们的网易通行证非常老,代码从公司成立没多久一直到现在,可能比不上银行业的那种恐龙级的ID架构,但是也不算太晚,我看过他们的代码。还有很多产品,像时间非常悠久的,他们的产品线从公司的创立之初到现在一直在运行,从来没有停止过更新,从来不会出跟运营相关的问题。

最后是我们运维这边本身也会产生的一些债务,比如我们原来对一些技术方向的探索或者说我们没有想过的DevOps,没有想过AlOps相关公司,原来做很多的方向我们是错的,但是错了这次接下来可能就没法很好去调整,这需要慢慢通过大众技术改造来替换。
旁边这个能看到,(图)这是我们2007年我的感受是这样的,为什么这个曲线是这样的?如果按照我们正常的业务发展曲线的话,我们大部分的任务通过自动化做掉了。
跟大家一样,我们也经历过很痛苦的运维困境,比如说On Call,沟通困难,和开发不在一个频道。还有重复说明,多次反馈同一个问题。
还有我们日常运维变更,我们也会除去On Call以外,日常很多都在日常变更上,我们跟很多公司一样,我们日常变更花了很大的精力做原有产品上的改造,因为我们代码太老了,我们的基础设施太老了,都10年以前了。很多的产品我们实际上还是有些产品非常强势的,大家对网易有所了解的话,知道我们网易是一个比较垂直化的,每个工作或者每个产品团队它的需求有些是非常强势的,老板比较看重,可能突破了一些运维的理念,所以我们会上一些不友好的方案。

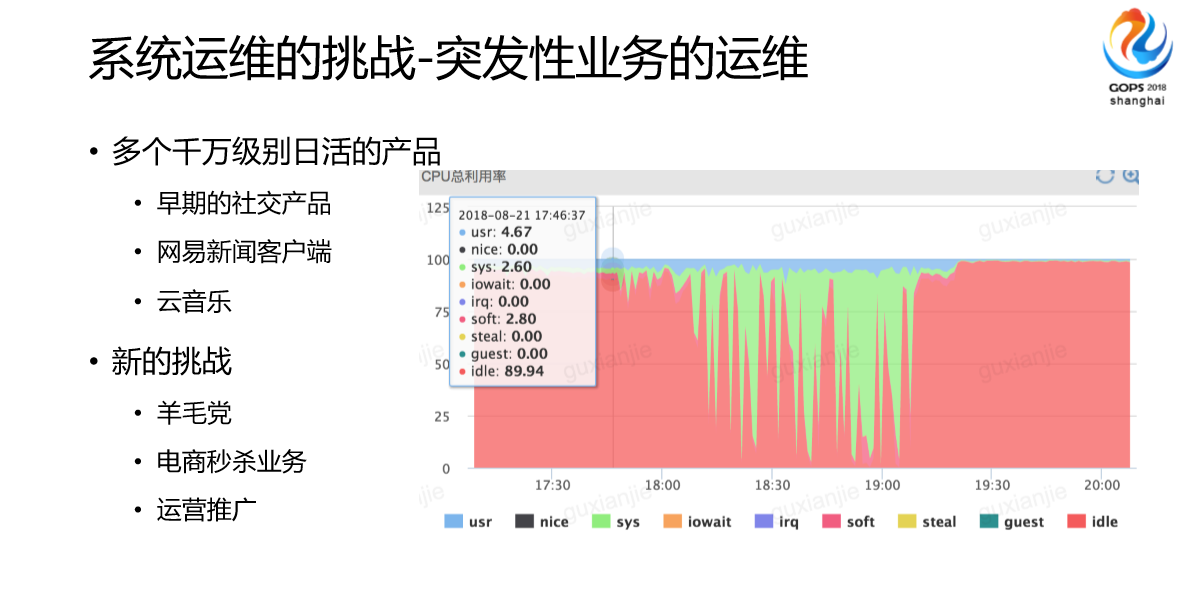
当前我们现在最大的痛点就是这些东西,首先是千万级日活的产品。我们网易有网易邮箱,我们千万级的产品非常多的,我们当时很明显,比如说博客。当时有一天一下子引入了超过我们预期很多人数,还有新闻客户端,还有云音乐。另外是我们的团队公司也会有一些更商业的东西,比如说羊毛党、电商秒杀业务、运营推广。
这个是非常典型的预期内的突发,这个预期内是我们已经预想到了线上流量情况,这个对我们运维来说,归根到底就是挑战。因为你也不知道它下次是进货10%还是50%,你不知道。
还有一部分是运维推广,我们也会跟其他团队一样,(图)这张图可能跟之前一段时间云音乐做的性格测试的时候,我们其中一台机器的表现,虽然后面我们通过价值的方式尽量去优化了,但是这个行为不在我们预期范围之内。
我们针对突发问题面临一些困境,我们跟其他友商一样做了很多流量平台,监控报警平台,但是也会发生一些没有压到的,导致整个平台受限,现在我们处于比较好的时代,大家对运维比较重视,所以我们现在能做一些运维相关的策略来对开发或者产品做一些事情。
还有一些突发的问题,这个就不用说了,大家都遇到过,突然之间报警了,我们也不知道哪里有问题。
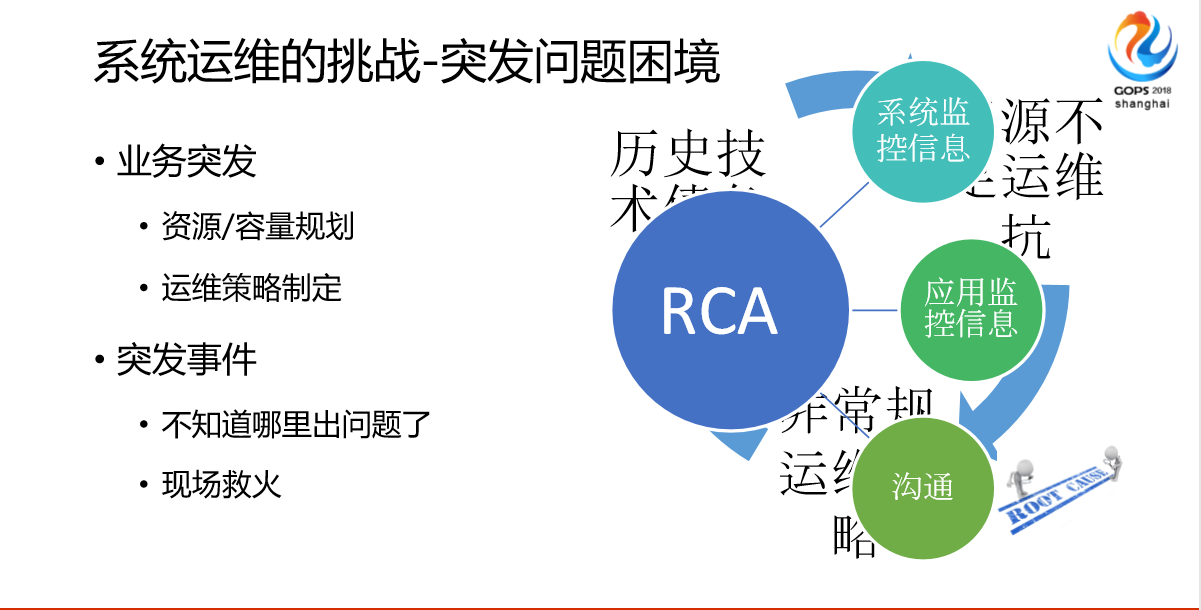
总结起来,我们发现问题、发现突发问题,有历史技术债务、资源不足运维扛、非常规运维策略,综合循环起来导致的问题。比如我们的技术债务导致我们的框架不适配,一旦发生这个问题,我们定制性的东西可能只有我们特定的人知道怎么去消融。资源不足运维扛不用说了,非常规的运维策略,大家有没有用过云上面的东西?云上面会做一些比较定制化的逻辑,这些都是非常规的,我们经常遇到一台机器重启了,重启以后不符合预期,为什么?因为我们做了非常规的运营策略。
和其他大厂一样,我们的平台也在不断建设,我们这边做了RCA分析,我们基本上通过系统监控信息、应用监控信息,应用的日志,还有一些沟通。因为RCA这个问题大家可以说能解决,你的分析能解决90%以上的问题,但是还有10%跟人相关的。我们把沟通也列到其中很重要的点上。
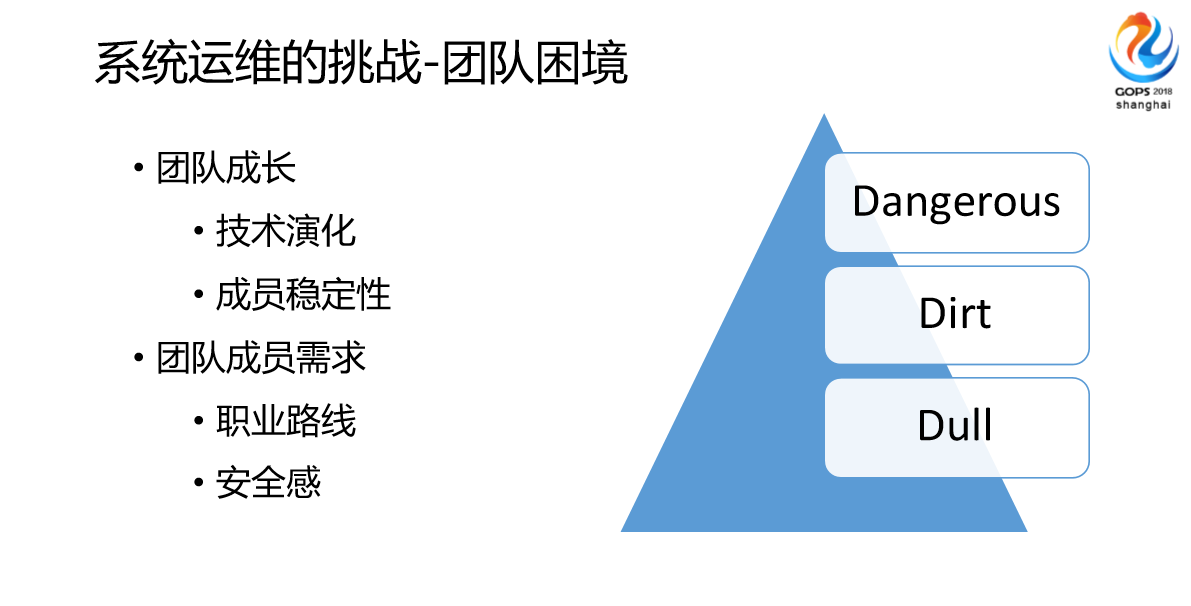
基于我们之前这么多运维挑战,这么多运维问题,我们发现,因为我们这边也是团队,我们带领团队的时候,技术演化、成员稳定性方面明显受到了以前系统的制约,因为老的系统经常会导致成员不愿意运维。因为你一线招的人都是90、95后,他们不愿意做很枯燥的工作。还有成员本身成长的需求,比如说我要做DevOps,我要做架构师,他们多有自己的诉求。比如我现在手头上运营了好几个系统。我们团队面临的问题三个点,比如说Dangerous,非常枯燥,很多东西管理界面这种配置非常脏,我说的“脏”是指手段不是很优雅,我们会做非常多的Dangerous,非常的危险。比如我要做一个自动化,我关掉一个检查,OK,我们觉得很庆幸做过了,但是还是有硬件故障。就现场来说,或者说整个人类的生产力发展来说,枯燥、脏、Dangerous,3D的工作应该被自动化取代,所以我们会考虑在做应用的时候会考虑很多自动化的东西。
2、运维工具的演化
第二个我们来考虑一下运维工具的演化。我们也和大家一样经历过运维演化,我也做过很多的脚本。然后我们也经历过自动化工具时代,最后是自动化平台,我们这边也有一些内部应用平台。我们工具的组织方式可能从担任维护,比如说担任维护一个模块统一变成repo平台。

就10年前到现在,运维感触最深的就是规模变化,我们10年以前的互联网,我刚去公司的时候差不多是网易博客刚刚创建没多久,分析不超过100台,我们随便搞搞,一天看完也就那么几个小时,没有什么区别。后面发现业务增长太快了,这个速度增长不是平稳的过程,是非常陡的曲线,我们发现我们的规模支撑能力或者处理能力明显遇到瓶颈,会发现整个变更和操作中间有点问题基本上就废掉了,还有一些效率优化。原来我一个团队只要应对好我们团队的需求就可以了,我跟开发很熟,开发什么明显就知道了,现在我们团队是多样的,他们的需求不一样,而且他们的需求一上来就跟你说,接下来1分钟就变更完,这个对我们运维工具非常大的挑战,而且马上执行完,马上有结果,但是执行大家都会去执行,怎么保证变更稳定性呢?我们在工具设计选型的时候很大的一块考虑是变更的稳定性,或者是说一致性。
最后一块是成本。成本是公司大领导给运维一个很大的压力,要通过技术的手段来优化服务器资源或者说你线上产品的资源消耗。
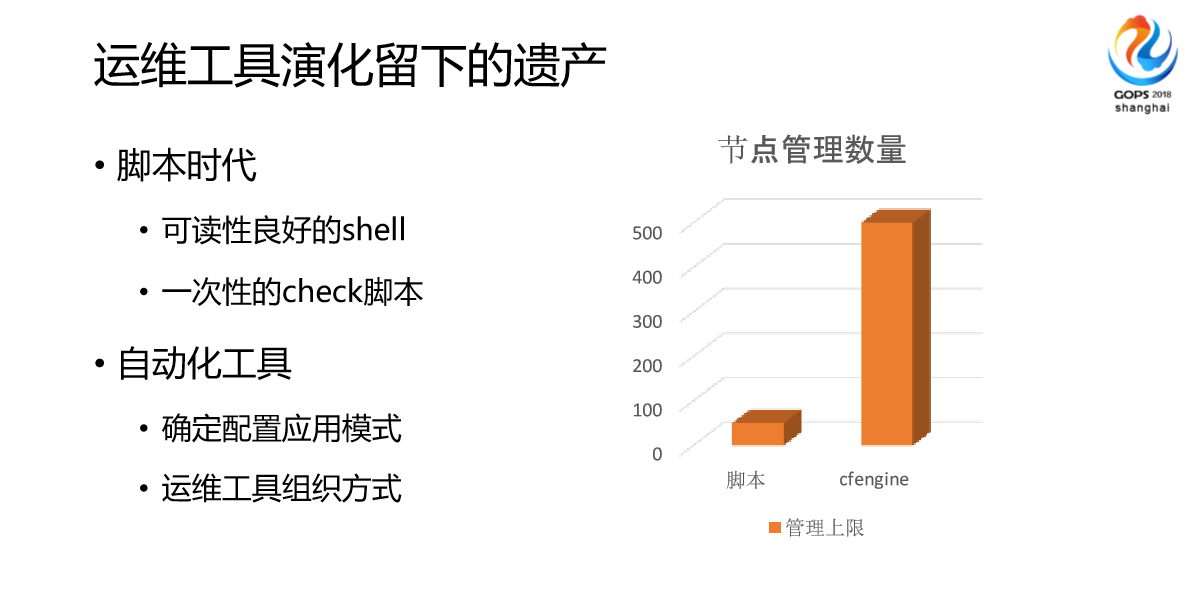
这个是我们之前杭研很多年用的一些配置系统分发方面的工具演化过程,我们脚本用了6个月,那个时候基本上是产品开发型,后面开始用cfengine,后面是puppet2.0,然后再是puppet3.0,我们随着这个做了相应的演化,从脚本开始做自动化,然后开始做模块化,会做分装、二次分发,后面会做平台+服务。平台就是很多的操作不再是简单的配置,而是一个平台。

在整个演化过程当中,不是说脚本好或者不好,我们的运维工具是往前发展的,我们发现每次发展都会带来沉淀,比如说脚本我们写了很多,但最终只有部分可读性良好的脚本,或者一次性Check的脚本留下来,还有一些自动化工具。左边这个柱状图是我们早期做运维的时候发现一个瓶颈点,我们基本上发现这个脚本超过50台到100台之间基本上会面临一个瓶颈,那个时候可能是某个执行变更不流畅,后面我们用cfengine发现也是一个瓶颈。
3、运维能力的服务化
第三部分是我今天分享的重点,差不多会讲述一下我们在做运维工具的一些想法和思路。
和大家一样,因为我们10年前开始做运维,也对业界的潮流自动化、平台化也有去跟,也有去关注。我们内部也是因为业务的倒逼或者公司体量上升,或者运维的压力等等多种因素,我们也在考虑做一些自动化、平台化方向的工作。比如我们运维团队运维开发用DevOps的逻辑,我们面向产品专门对接的特殊团队,我们称之为工作小组,比如说面向电商的,比如说面向云音乐的我们执行SRE的体系,两套体系都有用到。
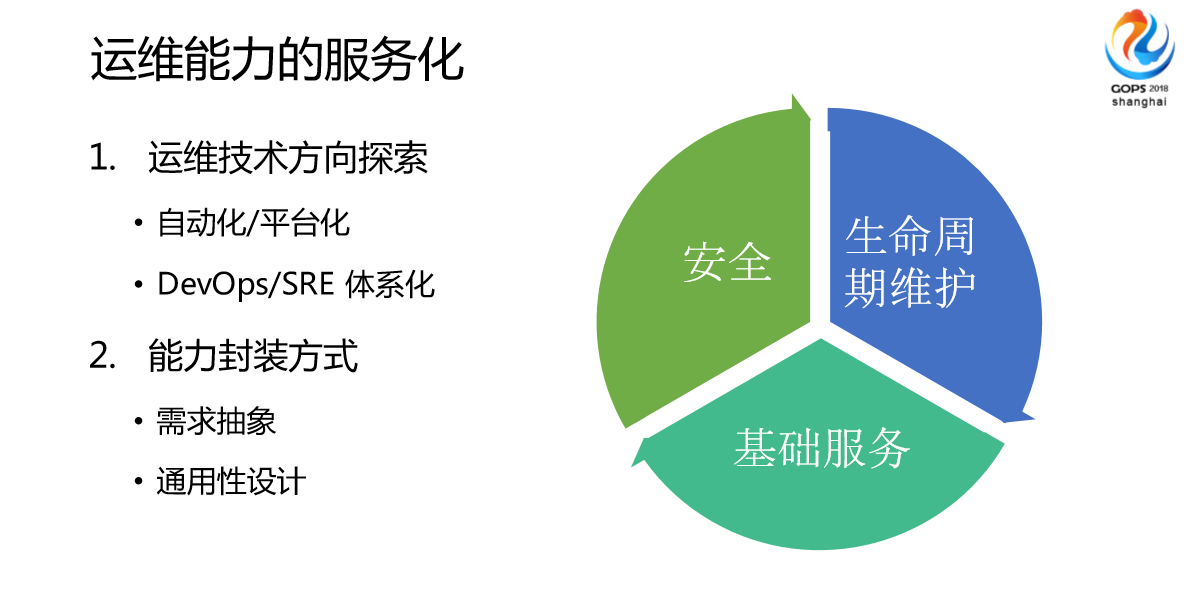
我们系统人员在这边实际说做了大概三个方向的服务化的一些探索。
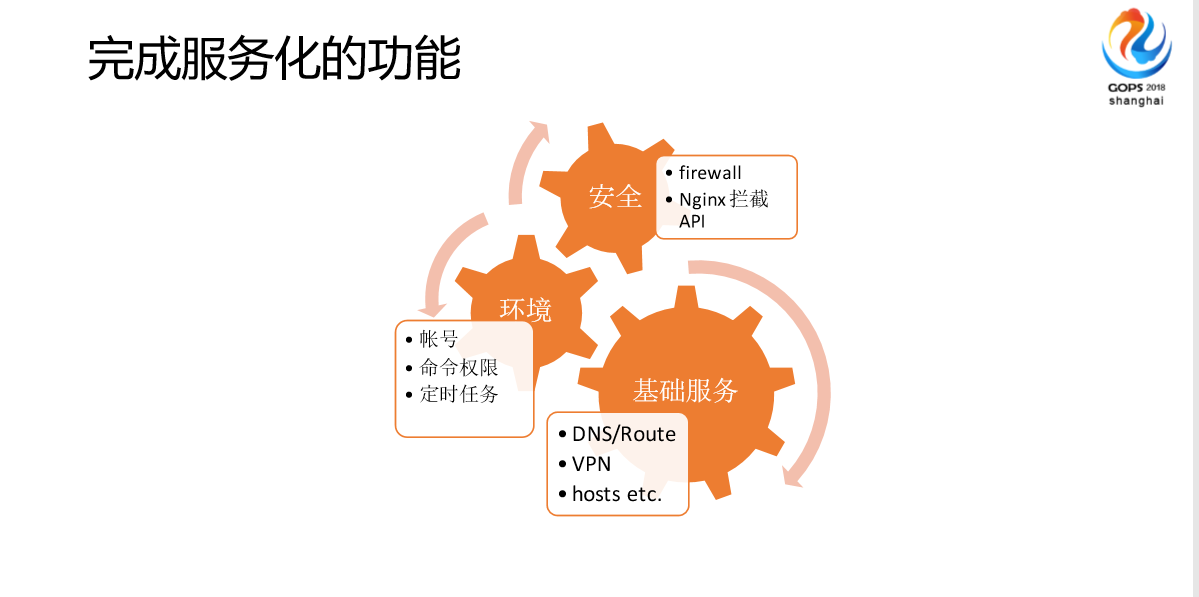
首先是安全,另外是生命周期维护,最后是基础服务。我们发现基础服务这块目前是我们整个集团对后续做的比较多的事情。我们对整个系统运维提供的能力,比如说语言需要运维服务器上面操作一个东西,我们现在都在做一些分装,变成一个不需要人登录服务器的操作,这种变化的方式,我们把需求抽象,做通用性性设计来实现的。
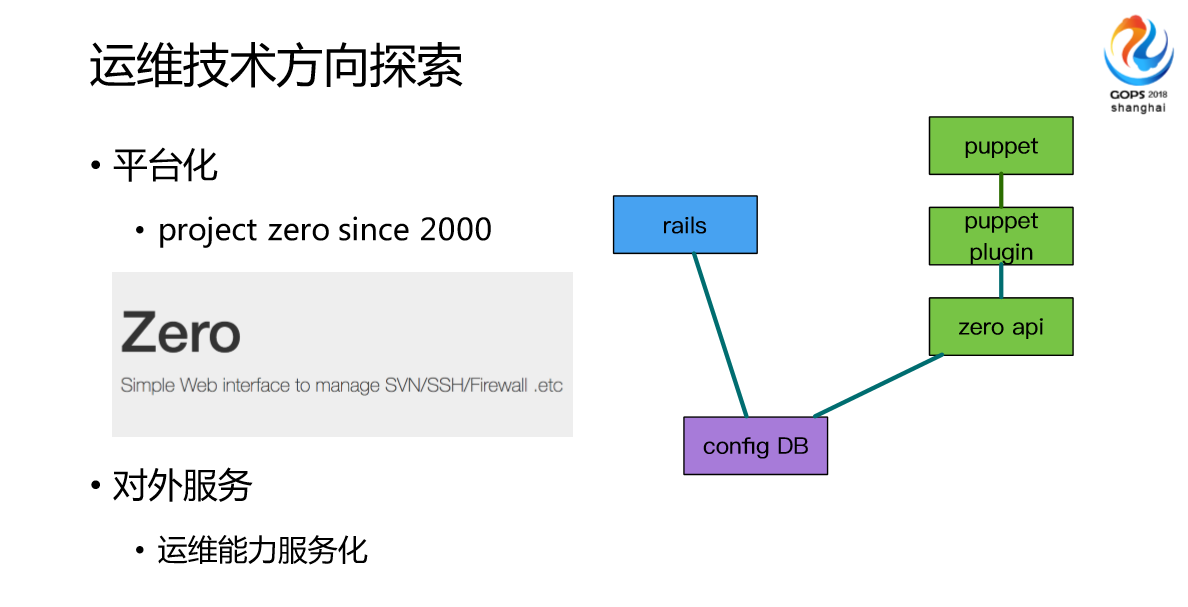
这是我们很早做的一些平台化探索,我们第一个项目叫Zero,我们一开始做的是统一的基于Rails的外部开发,没有花多长时间,比如说防火墙或者说比较长的定制化,整体架构很简单就是rails数据库,通过插件的方式实现配置的一致性。我们现在做的是运维能力服务化,我们发现之前的自动化平台给运维用的,现在我们的团队很多的业务团队对运维的要求实际上更复杂了。单纯只是说有一个平台让他们用已经不满足了,他们需要对整个业务逻辑嵌入运维的要素,实现深入的定制化设置。
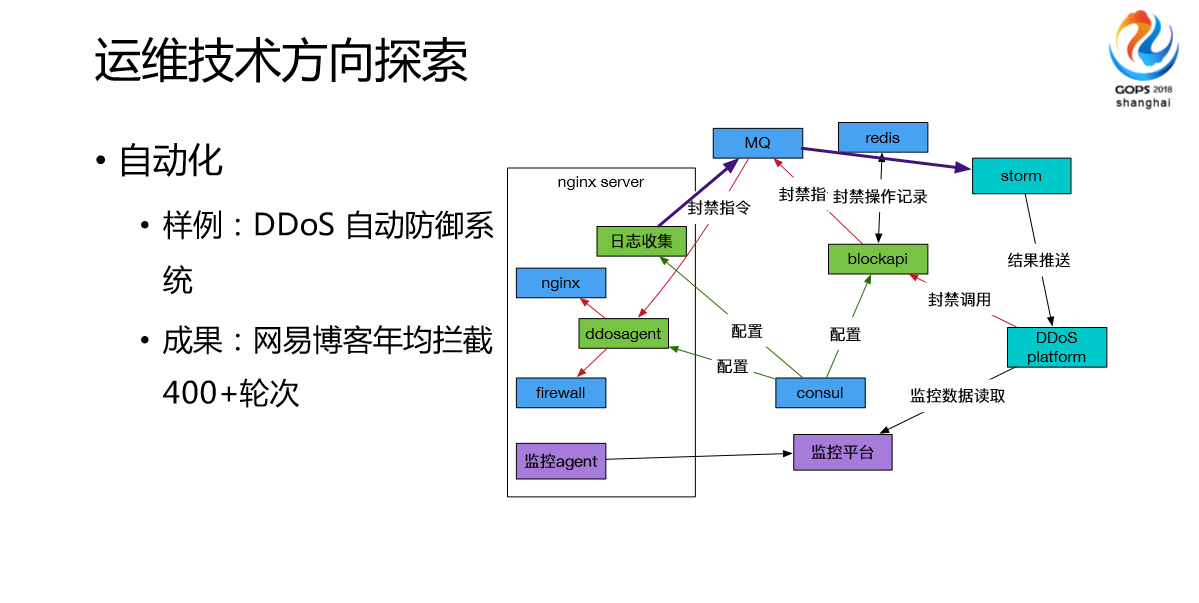
这是我们最开始对外实践的方向,比如说我们DDoS自动防御系统,之前用于网易博客的安检,网易博客差不多1月30日下线。我们网易博客经常被攻击,我们在2007、2008年博客很火的时候,团队经常应付一些攻击之类的东西,也很痛苦。后面我们做了一套完整的方案来实现跟专业的安全员的流动,我们把所有的东西变得服务化以后,通过我们运维提供的一些日志服务或者一些平台做一些分析,来做大数据的扫描来实现攻击的识别,然后取得很好的成效。
然后是我们对DevOps SRE体系化的探索,当前我们做的DevOps或者说SRE这块主要集中在所有平台的互通,不仅仅是运维平台,而是说我们的运维工具或者说运维实现的一些CMBB,或者是监控系统,或者JAVA系统的东西,实现产品自己定制的工具平台跟我们的运维平台相结合。我们也关注一些工具的快速迭代,上面的图就是一些DevOps、SRE这边的区别,我们团队是DevOps和SRE都有设置,根据工作的方向可能都会有偏重点。

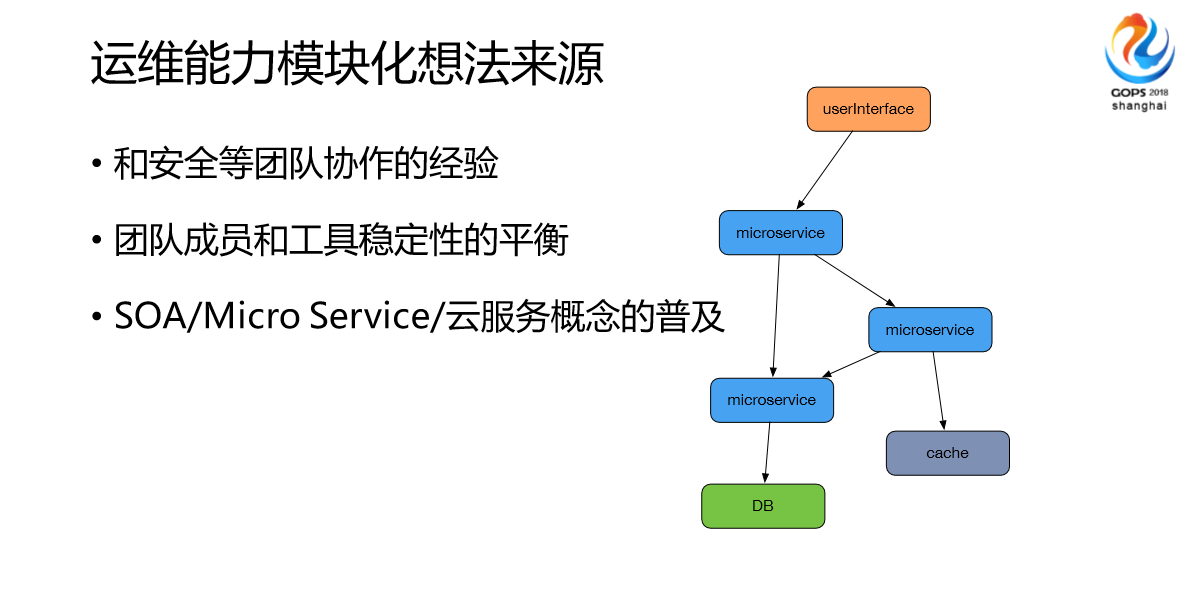
因为跟信息安全团队合作DevOps的经验,看到了运维能力对外提供以后,带来的效益是非常显著的,比如说团队有DevOps的需求或者SRE的需求,团队成员和工具稳定性的平衡。我们这块做模块化和运维能力的服务化也是被业界,比如说软件服务器一些开发思想所启发,比如说SOA、Micro Service、云服务概念的普及。
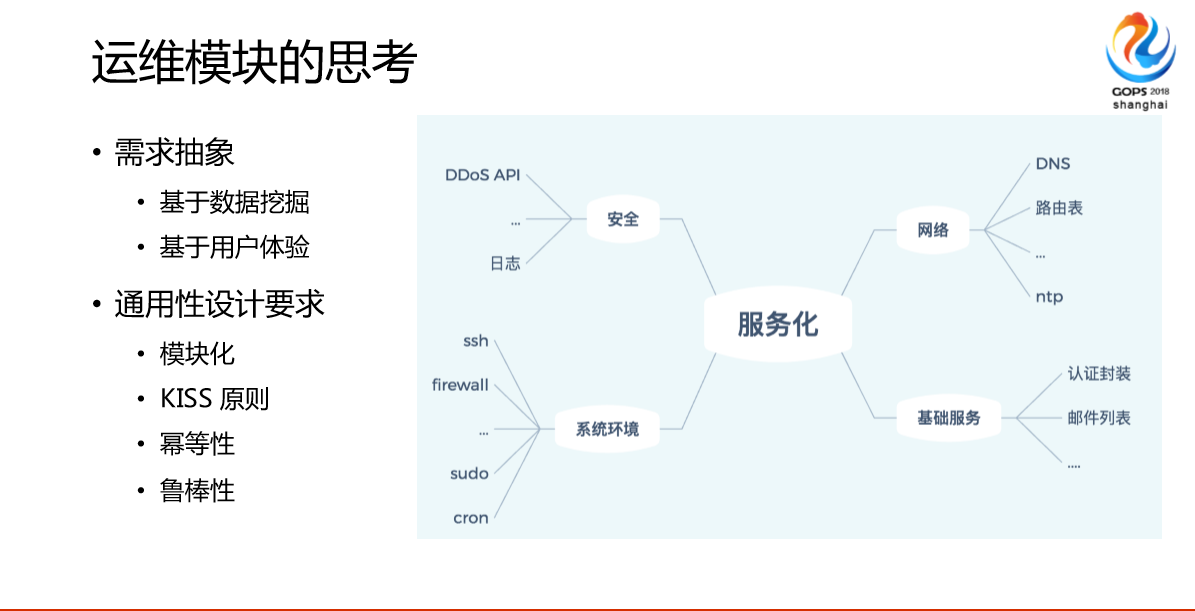
我们也在做一些探索我们怎么去做的时候,我们基于系统安全或者网络或者是技术环境,首先是一个脑图,比如说安全的数据挖掘或者说系统环境相配置的用户体验来试试,来决定是否要做模块,这些模块我们提了一些需求,首先模块,输入输出是固定的,如果它不在,我可以重新很快造一个出来,替换老件模块,我们允许它出错,外部调用方式尽量简单,这样开发迭代速度越来越快,最好的模块是一些简单的命令,还有运维方面的简单需求,比如说我们要求服务是幂等的,在我们的系统里面考虑你加一个文件,这个文件是什么样的,是确定的,第二次去调不会是重新创立一个文件。
最后是鲁棒性,我们的模块都是非常鲁棒的,因为我们做模块或者任何节点都会挂,我们设置软件的时候考虑这一点,我是开发的配置挂了以后怎么办,我们当前模块化思考这块基本上能做到我们的,我们不会导致线上生产事故之类的。
然后是需求抽象,我们对运维的一些所有的日常整理成文档,系统任务做了统计,然后做了大数据挖掘,来生成决定我们具体要做哪个方向的模块,我们这边数据的话至少会有一些服务器的数据,这些数据每天会产生,我们持续跟进这些数据的用途或者说提供方式。
这是我们做过的样例,比如说前端做React,服务DNS、LB,数据是Cacge、PG、MySQL,我们团队里面有些是用脚本做的,有的人用JAVA,模块都是尽量简单的。
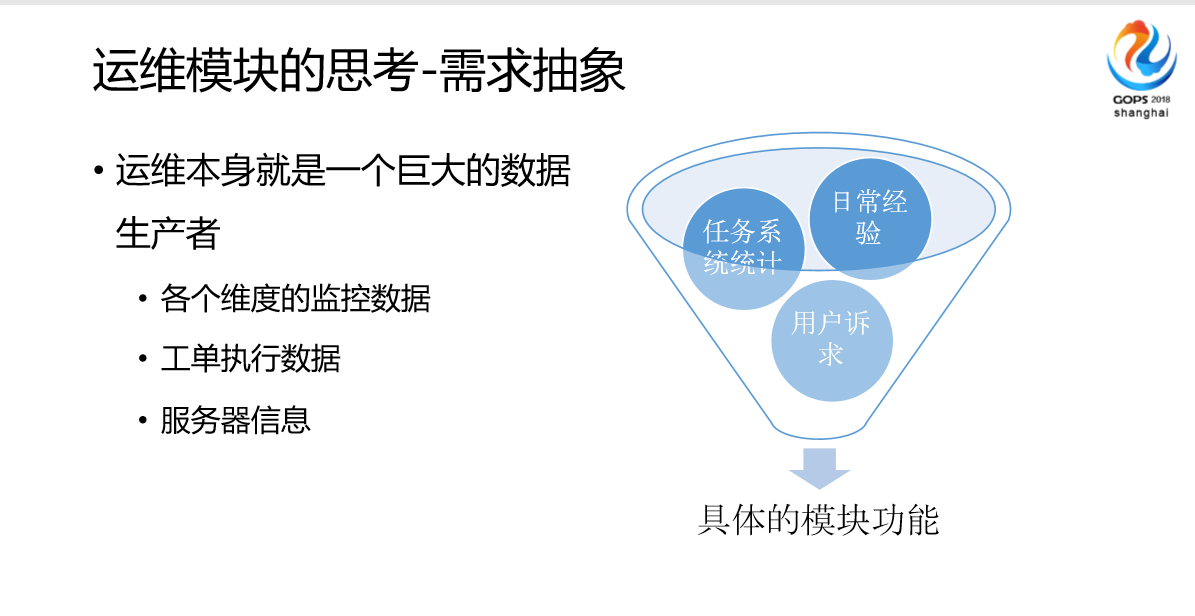
接下来是一些我们模块演化的需求,我们在实施做这些模块服务的时候,最核心的是功能,功能做完以后先在内部试用,实现需求,紧接着做安全,然后是有监控,看一下目前是什么样,要知道这个状态,最后是容错。

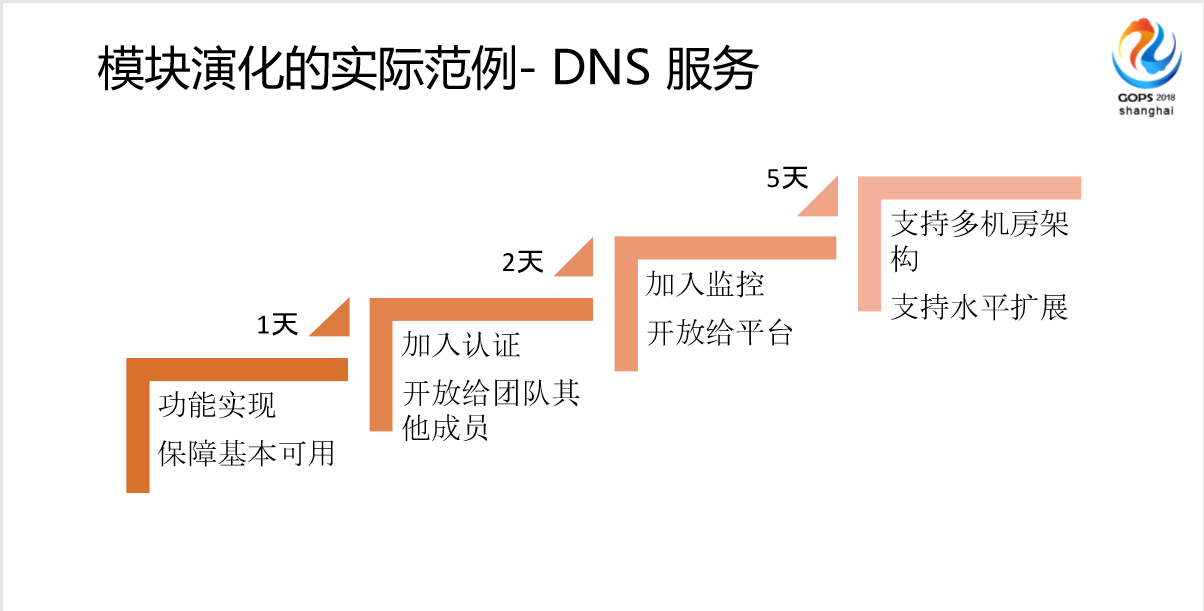
这是我们一个模块化的示例,我们基本实现完以后,开始“吃狗食”,发现很好用,然后对外开放,我们花了一天时间,第一天加入认证,第二天,发现大家挺好用的,接下来又把监控完成了,开放给平台,最后是支持多机房架构,支持水平扩展,为什么拿这个做例子,我们发现自己用DNS的时候,只是维护服务器的机器列表或者说都是信息,后面开放给平台的时候,我们发现他们平台对应用方式完全不一样,他们用DNS做了服务发现,做了高能切换,这是我们完全没有想到的。
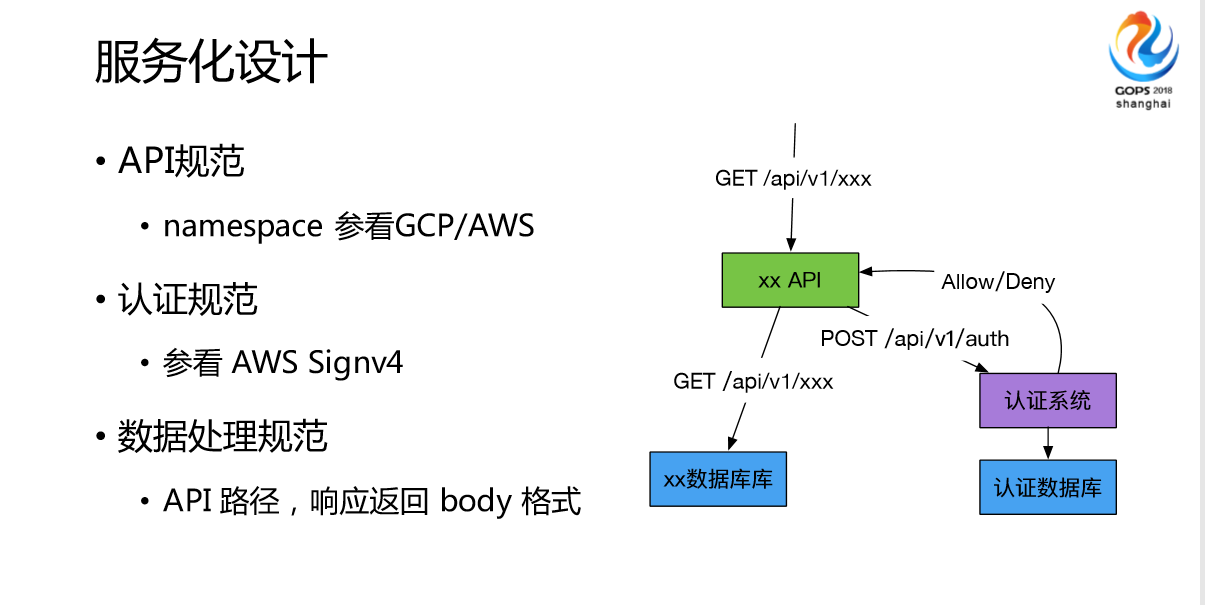
我们所有的服务都是对开发友好RESTfull API、模块解耦,无状态。模块一发布方式是各个团队独立迭代。我们发现我们的监控平台都迭代了2-3次。我们做这些模块的时候我们参照了业界的评判,也考虑到我们的服务要上云的,也用的强认证,参看AWS Signv4,不像有些运维一样,我们都是标准的语音服务化的,我们对API的数据格式都有严格的限定,这是我们API的工作方式。
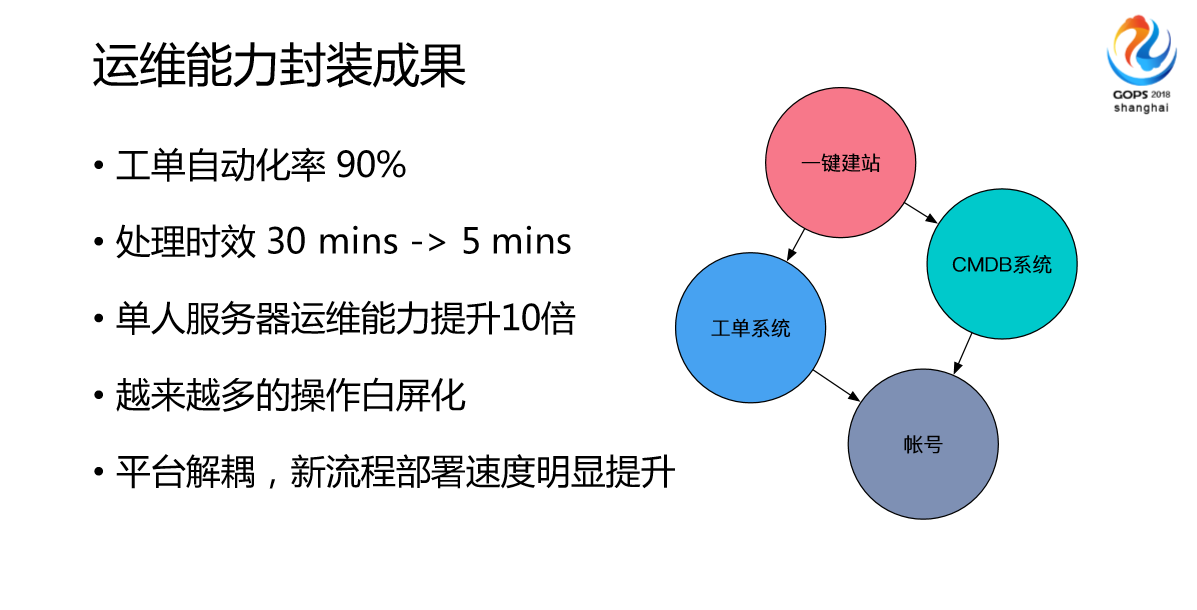
我们发现在第一个平台,实际上我们迭代花了差不多3年,第二个花了2年,最后一个花了一年。发展是越来越快了,为什么?因为我们很多服务变成了模块化,它的集成速度越来越快了。然后是我们做的一些功能,我们做了安全、环境、基础服务,做了很多这样的功能,成果就是自动化效率提升了90%以上,处理时效直接缩短了,服务器运维能力上去了,很多操作不需要重启,迭代速度明显加快了。
4.应对云的挑战
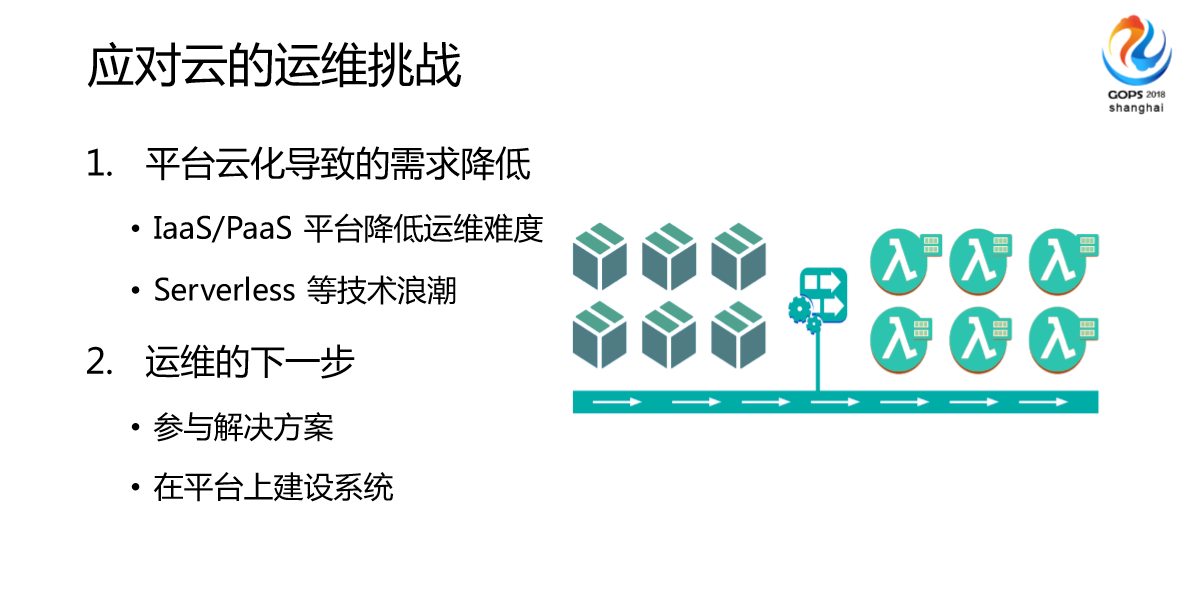
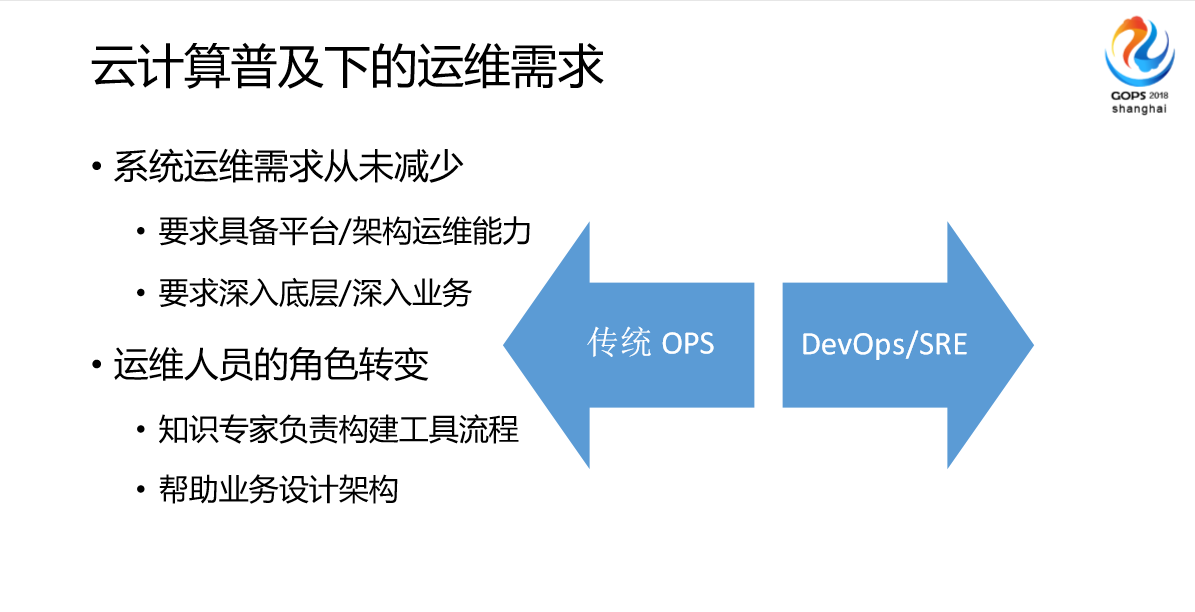
最后讲一下我们对云平台的思考,我们在有库的时候结合我们团队的经验我们发现,很多时候都可以通过平台来解决。这个时候我们做了一些探索,主要是解决方案的探索和平台建设的探索。我们认为在云环境下,传统的OPS是被淘汰了,DevOps、SRE的趋势越来越明显,我们的团队一直在招人,但是一直没有找到合适的,基本上我们系统运维的需求主要是平台、业务能力,对运维的技术能力要求高了,还有对技术深入要求高了,我们要求深入底层、深入业务,另外一个是跟智能化相关的,比如我们做知识专家,做一些流程构建,帮助业务做一些架构。
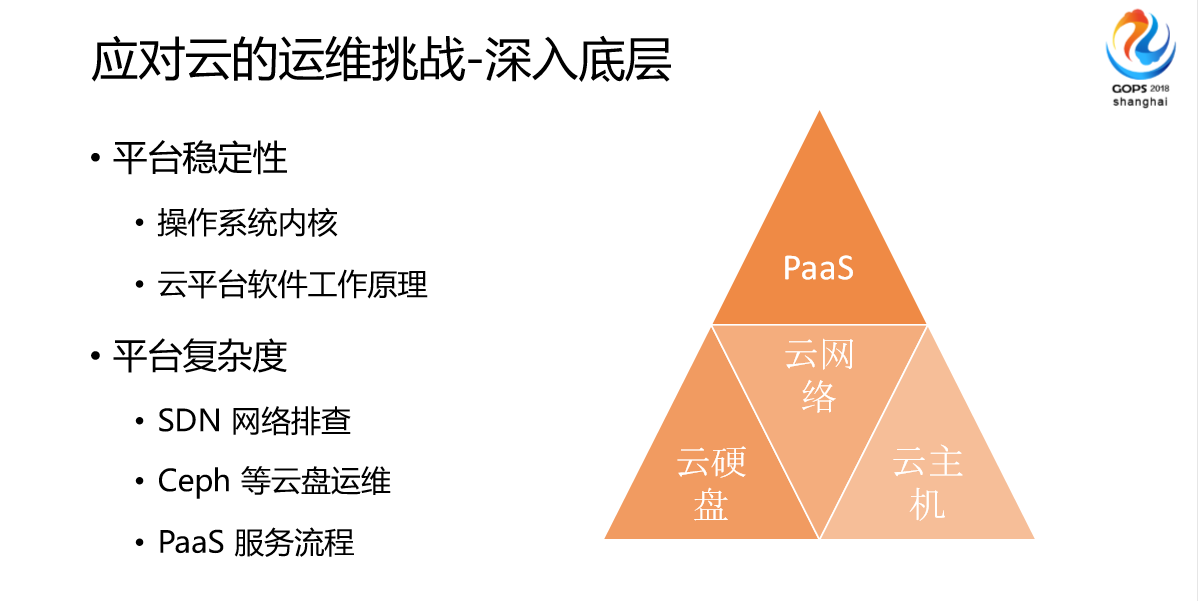
目前我们在云里面的最大的挑战就是深入底层这块,我们网易云采用自己的SDN网络,对运维需求是越来越大了。这个平台基本上底架是存储、网络、主机,上层就是PaaS。我们现在最大的平台来源于SDN网络排查,我不知道大家公司的Ceph运维规模有多大,还有PaaS服务流程,我们运维这边也是深入参与到团队整个PaaS服务流程开发中。
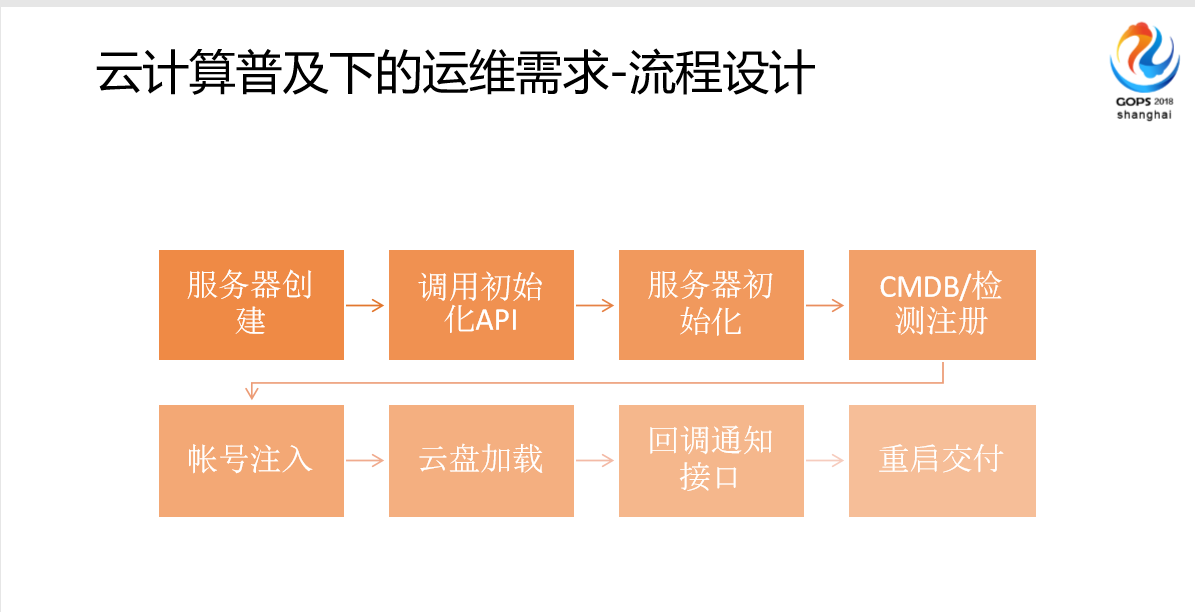
这里讲的是很简单的理论设计。我们现在做流程,剩下的都是通过API,自动化来实现,我们叫语音计算平台。在初始化以前,会做帐号注入、云盘加载,回调通知,然后重启交付,这是非常多的流程,这些都是靠运维的经验沉淀转化来实现的。
最后我讲一下我们在应对云计算这个情况下做的一些探索性的工作,我们在做一个基于云的,就是说大家所有的云,比如说阿里云有SOD,腾讯云有GPW之类的,但是就业务来说,实际上单纯的一个云计算很难满足一个业务需求,我们做了一个基于AlOps的开发,整个流程通过运维来主导实现相关的,比如说能力的分装,一些流程设计,由业务开发和我们一起来把整个流程打通。我们这个经验来看的话,后面我们DevOps的趋势,主要会做云上的,可以基于平台上的。这些建设最后会转化为实际的生产力提升。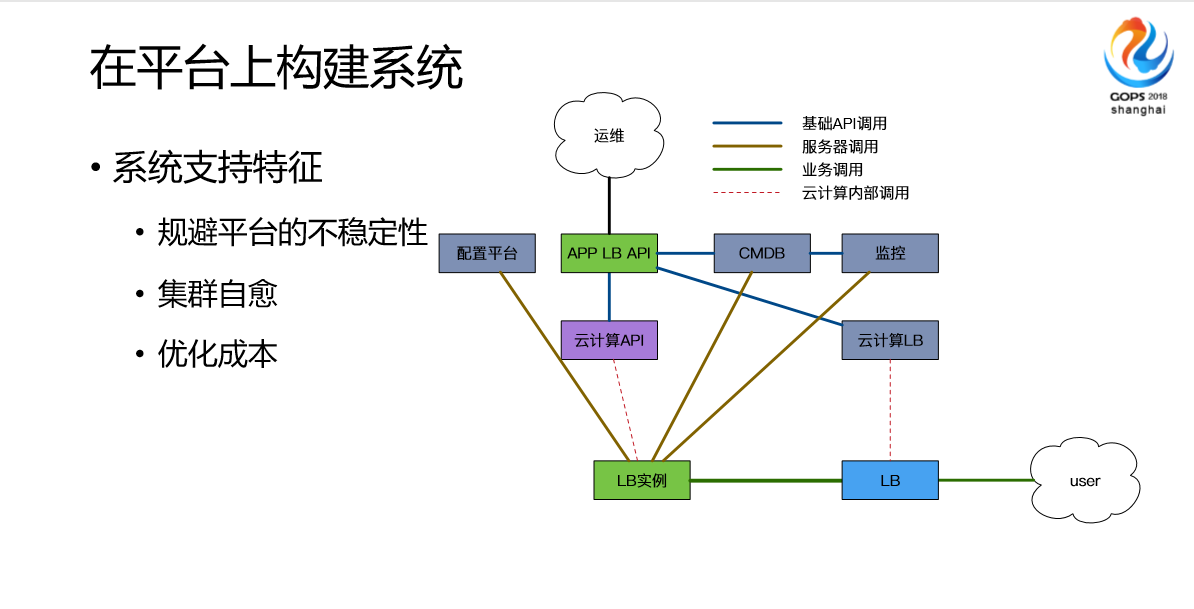
OK,今天我给大家讲一些关于服务化的,在网易的一些实践,一些经验。谢谢大家!

