@gaoxiaoyunwei2017
2018-11-21T08:12:40.000000Z
字数 5903
阅读 1054
玩转AIOPS --- 趋势 · 场景 · 算法
豆沙包
作者简介
赵宇辰
美国伊利诺伊大学机器学习方向博士
听云首席科学家
现在说AIOps说的很多,其实谈到AIOps已经十年了,听云作为一家只专业做AI运营的厂商也服务了十多年,我们在各个行业,金融、保险、互联网、高科技等等都服务了上千家的企业,在这十多年里,我们也趟了很多的坑,也踩了很多的陷阱。
所以,今天很高兴和大家分享我们怎么看待这个市场,怎么看待这两三年的变革。我会先从趋势讲起,再慢慢过度到算法。
一. 数字化下IT的五大趋势

“软件正在吞噬世界”,这是Marc Andreessen说的,他是硅谷非常有名的VC,这个说法是他在2008年提出来的。一晃十年过去了,这个说法是非常的有远见性,他认为可能不光是高科技、互联网企业在用软件,可能各行各业,比如运营商,比如银行、保险等等,可能都建构在软件之上。
微软最近股票涨的挺好,他们的CEO曾经说过一句话 -- “Every business will be a software business”。
我们想想,我们以前去银行的时候,都要去银行柜台拿着存折去存钱,去查询余额等等。现在我们统统都不需要了,所有这些操作都可以在网上进行,所有的这些都通过支付宝、微信,包括银联都可以很快地进行操作。
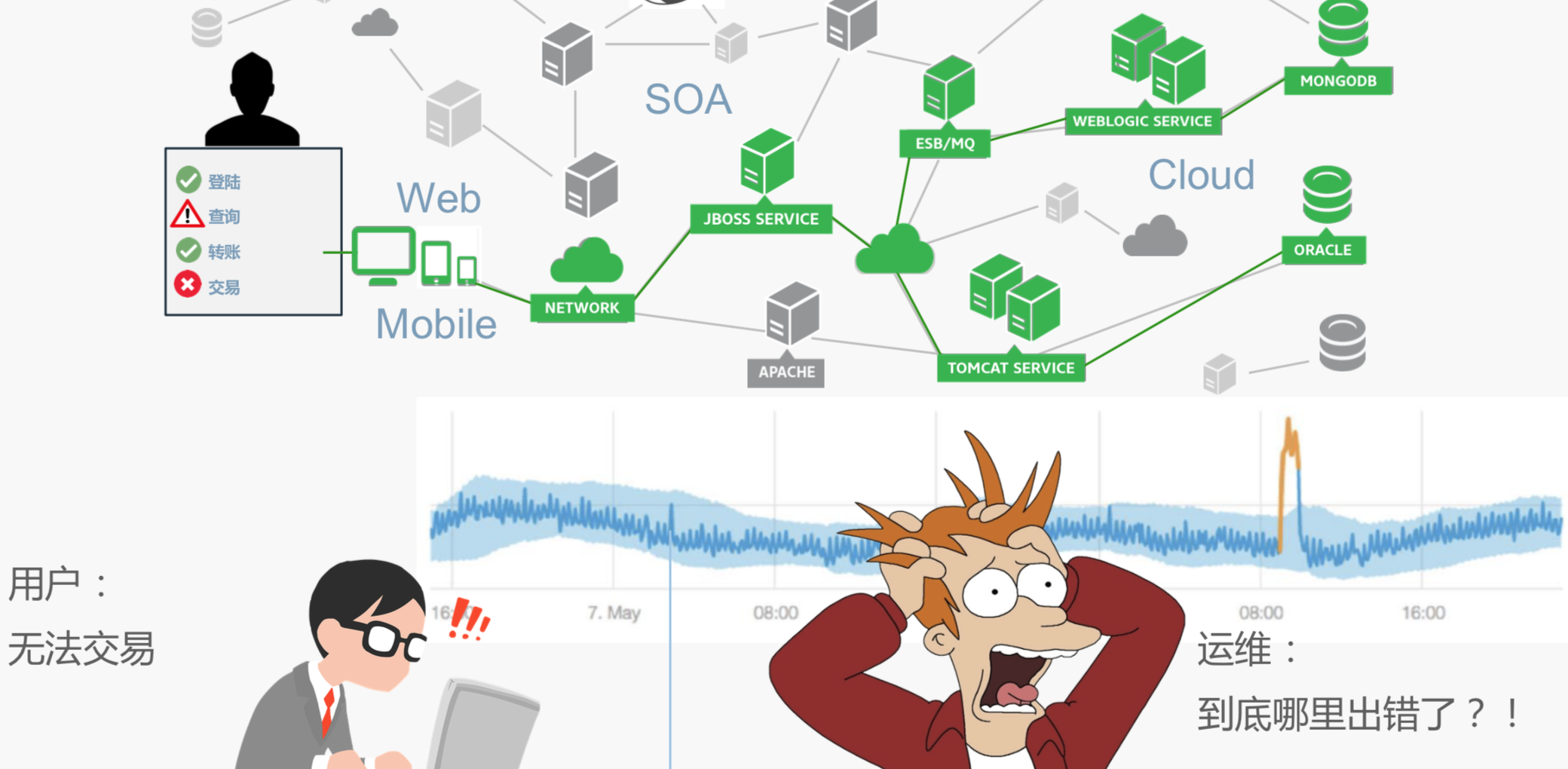
当我们把所有的线下业务搬到了线上,我们最头疼的就是会碰到这样的情况,比如说用户会大量地抱怨这个软件不好用,能不能赶紧修复一下,然后登录失败、登录不进去,会给一个比较低的评分,对于一个企业品牌来说,这是一个不小的打击,我们有时候甚至戏称,最长的等待可能就是加载中,我们一直在等待加载状态,这是一个非常不好的体验。
我们看到应用的性能不光是IT运维的事情,而是直接影响到整个商业以及业务的事情。所以,如何能保证应用的正常运行,对于我们的业务来说是非常重要的。
1.1 业务需求极大增加了应用的复杂度
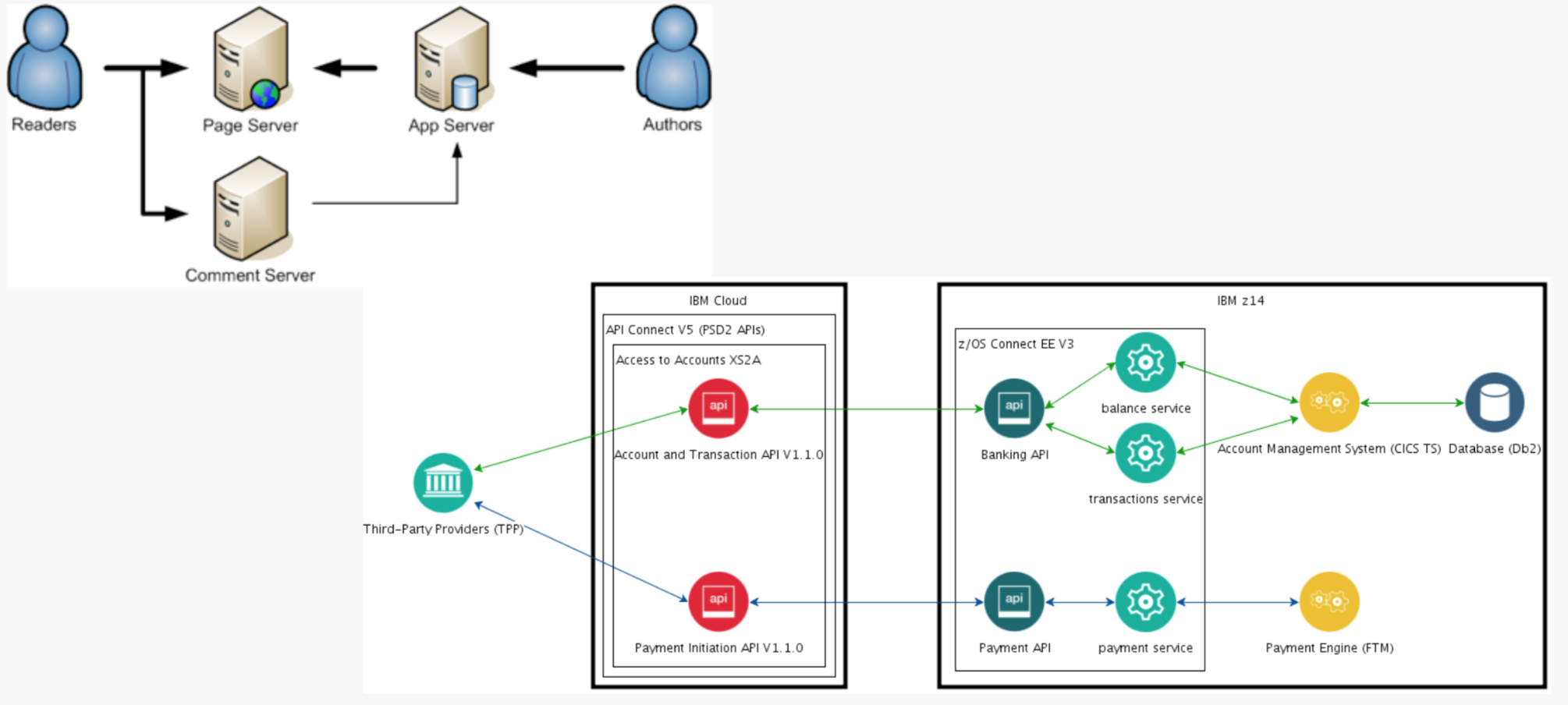
曾经的运维其实是非常美好的,那时的运维可能只有两三台机器,一个外部前端机器、中间件还有后部的终端机器就解决了。但是这样的美好时光一去不复返,我们看到越来越多的服务架构在不同的体系上,用不同的编程语言进行编写,同时不同的模块都在不同的时期编写,并且可能是不同的团队去维护的。更可怕的是他们还有不同的编程语言,就算对于同一个编程语言来说还有不同的版本,这对于我们的运维来说极大地增加了它的难度。
同时,现在不管是传统企业还是高端企业都拥抱数字化,比如进行余额的查询,做一个转账,很简单的按钮可能在后端数据之间的交互,我们会从前端走到网络,然后再到后台的中间件,包括逻辑处理,最后到了数据库。如果还有云,比如大数据的处理方式。
现在随着云计算以及开发大数据、微服务等等新的技术,给运维带来了更加大的挑战。这是我们看到第一个非常明显的趋势,业务需求的增加,使应用的复杂度极大的增加。
1.2 考虑多个数据源以及跨团队协作
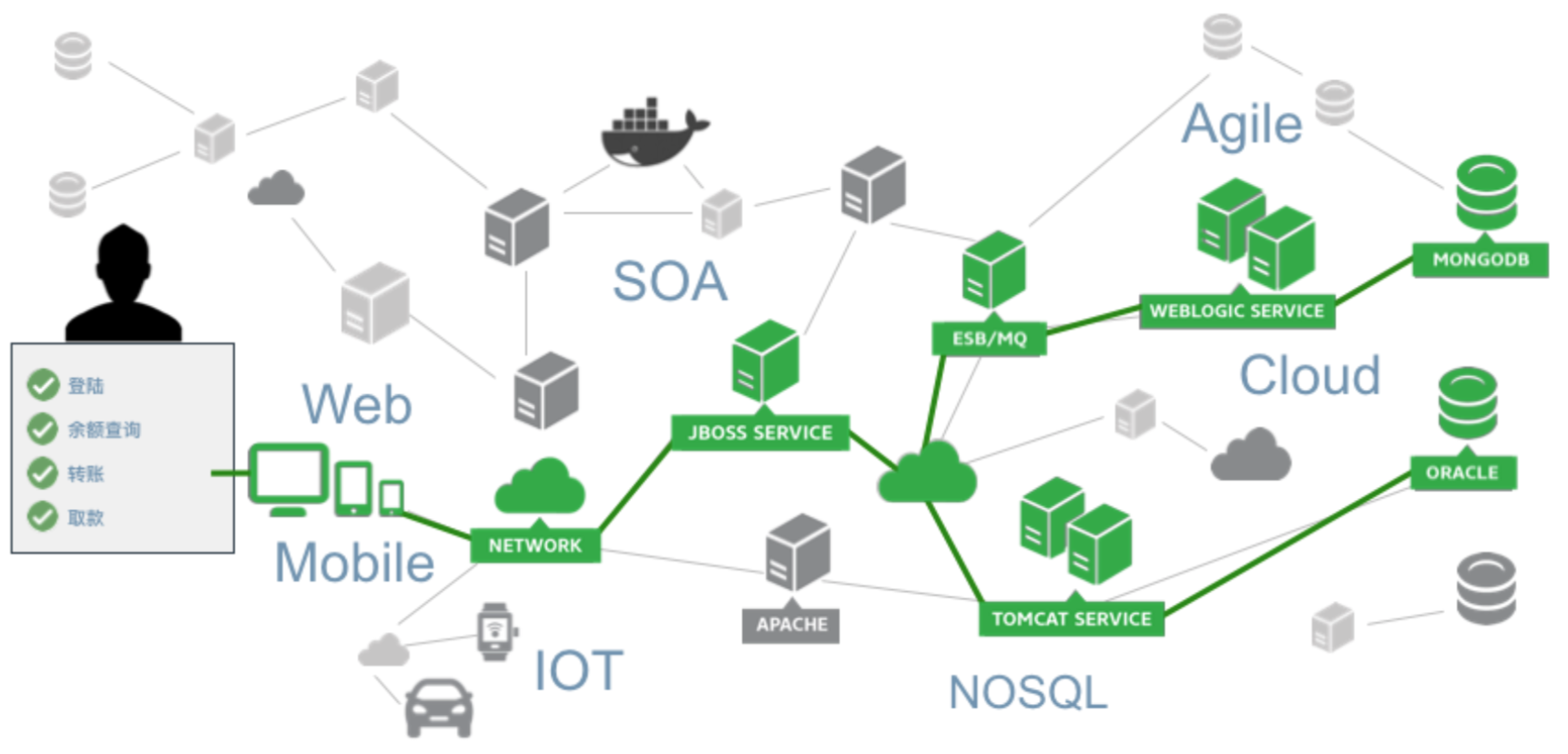
对于整个系统来说,我们的前端和后端都需要监控。前端现在也有很多,以前的只有浏览器,现在有了IOS、安卓、微信小程序等等,还有硬件的服务器、网络,在这之上还有不同的应用,还有新一代的大数据框架。
一套应用如果出错的话,很有可能是某一个部分出的错,没有任何系统能保证它的出错率为零,所以都有可能出错。
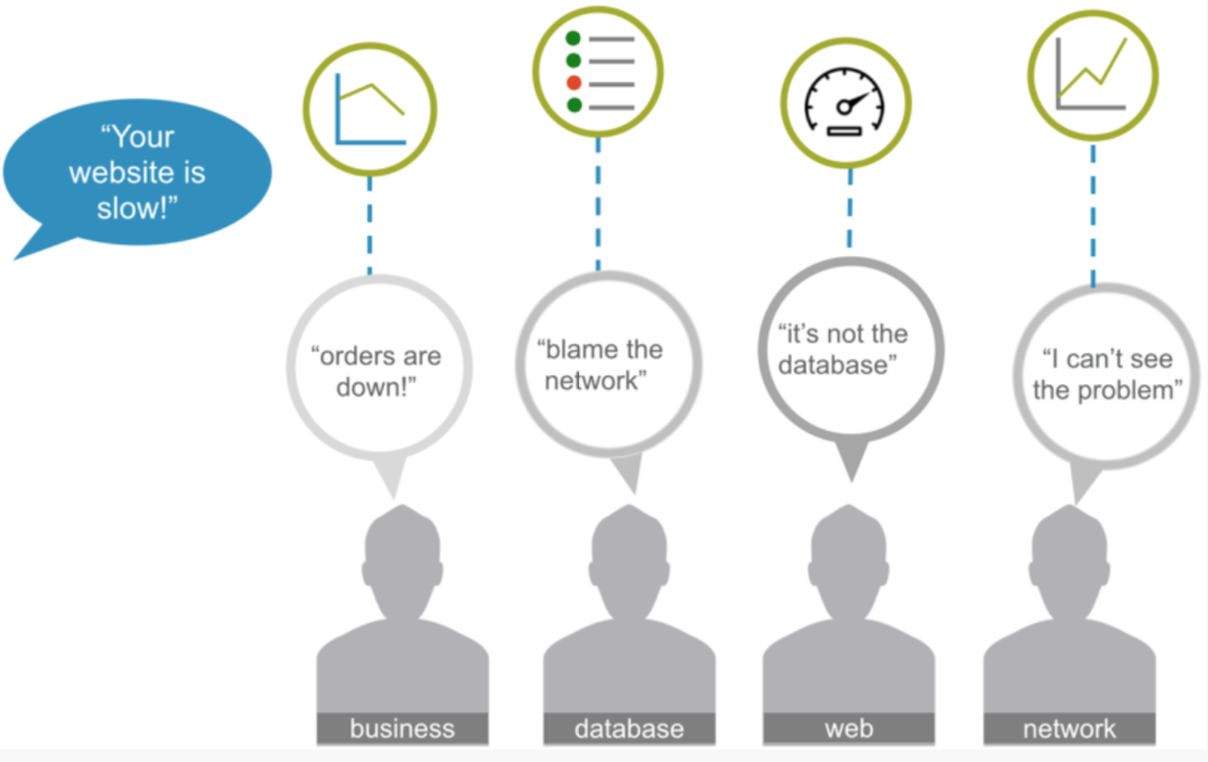
上图的例子,假如说我们我们只有网络监控,没有APP监控,有的用户会抱怨,说你的网站很慢,这时候怎么办?假如我们做了网络监控,可能业务人士,左边的这个会说进来的慢,订单量小了,影响业务了,你们运维能不能赶紧修一下?DBA团队说DBA没问题,数据库没问题,那肯定是网络的问题。外部一看,好像也不是数据库的问题,但是网络的同事说也不是网络的问题,所以会造成很多团队互相踢皮球的现象。
这是我们看到的第二个趋势,解决IT问题需要考虑多个数据源,有可能偏网络的,也有可能偏业务的,也有可能偏日志的,都有可能。同时,我们解决这个问题还需要去跨团队协作,没有一个完整的团队能解决他们所有的问题。这对于运维来说有了更大的挑战。
1.3 人力增长远小于数据的增长
对于IT从业人员来说最熟悉的就是仪表盘和警报,天天离不开的就是不同的仪表盘和不同的指标数据。

我们来看一个虚拟场景,假设每台服务器有10个仪表盘可以去监控,我可以有10个不同的指标去表达服务器是否正常运行。如果在一个复杂的应用场景下,我们假设有10个指标,在我们刚刚看到的美好日子里,只有三个服务器的话,只有30个仪表盘,30个指标去监控,相对来说日子是比较舒服的。
但当应用逐渐变得更复杂的时候,比如有了一百多台服务器,上百台、上千台服务器的时候,我们就有有上万个指标,这对于使用人力去盯屏的方式解决这个问题就不太现实了。
所以,在一个上线系统里,很有可能会有成千上万的仪表盘,如何对于这些成千上万的仪表盘进行监控,这是一个非常大的难题。
以前我们需要对这些指标做一个阈值的设定,比如我们设一个上限,设一个下限。实际的场景中,如果有上千万的指标,这个指标很多时候不像CPU指标这么容易能设定一个上限一个下限,比如系统的吞吐量,如何去设上限和下限呢?手动的设置需要非常多的时间。
同时,我们业务不停地增长,我们好不容易花了好几个星期的时间把业务的上下限各种阈值设好了,但是业务需求是不停变化的,比如过一个月、两个月,又是指数级的增长了,这时候如何应对业务的需求?
刚刚我们一开始提到的有一个看不见的问题,各个团队只能看到自己的部分,但是如果我们把这些数据都收集上来,我们有这么多的仪表盘,这么多的数据,这么多的指标会有一个看不完的问题。
所以,这是我们看到的第三个非常显著的趋势,就是人力的增长远远小于数据量的增长。传统上我们靠铺人,靠招聘用人力来盯屏的方式已经远远不能解决数据增长的问题。
1.4 数字化的演进和推进
随着数据化的深入,IT系统的数据类型也变得越来越多、越来越复杂。最常见的,以前看的最多的就是指标数据,比如说CPU使用率、吞吐时间、网络延迟、参数等等。其实我们看到不光是有这些指标类型,还有更多的不同类型,比如说分类数据,比如说区域名称,中国就这么多的省市,我的区域选择是有限的,用户IP也是有限的,浏览器类型也只有几种可以选择的类型。
所以,对于分类数据如何去处理呢?它们的处理方式是不是跟时间序列的处理方式有所不同呢?除了这些数据,其实还可以更复杂一些。比如说我们会有一个竖状结构数据,假设一个公司有很多的应用,每个应用有自己的模块,每个模块有不同的节点,一个节点里有非常多的进程,进程里有很多的调用栈,从我们的业务来看分成大业务里面有不同的子业务。再看统计,我们也是用一个竖状结构,比如秒级数据拿过来变成分钟数据,然后变成小时数据,以至于到天,这些统计型的数据也自然形成了一个竖状结构。
我们看到刚刚竖状结构已经非常复杂了,还有更复杂的--应用调用追踪。
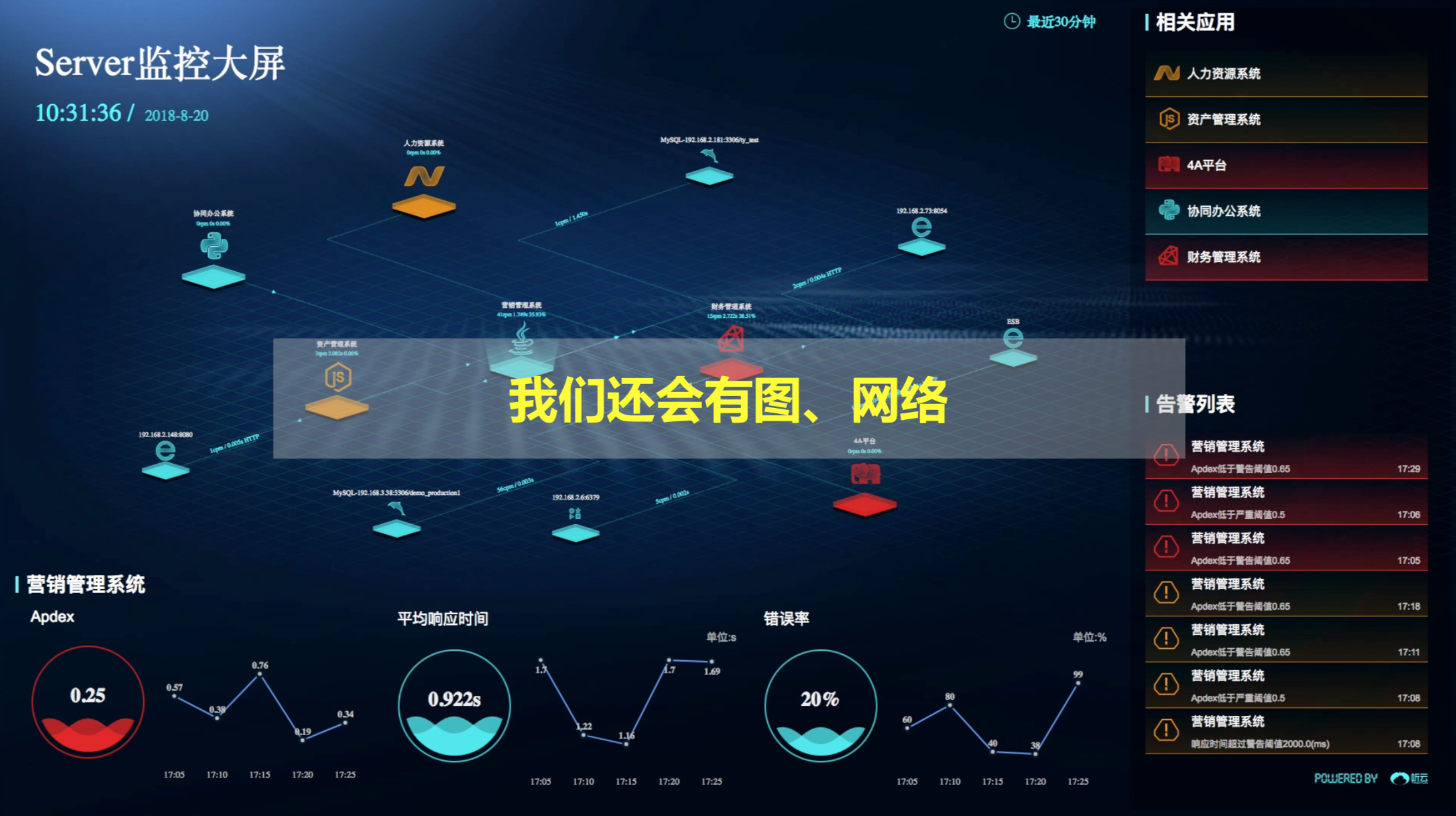
我们可以看到这些模块之间非常复杂的调用关系,他们自然形成了一个图和网络,在做根源分析的时候,比如我们一个数据库出错了,往往会把错误追溯到其他的上游的节点,上游的节点也会相对受到影响。我们需要通过图和网络追溯到真正的根源里去。
以上这些都可以把它归为结构化的数据,还有非结构化的数据,最常见的就是日志,还有很多的错误信息,还有堆栈信息等等,这些数据形成了非结构化数据,有点像自然语言一样。
我们看到其实运维已经慢慢走入了深水区,不光是我们开始说到的时间序列,还有分类数据,还有竖状数据、图的数据、非结构化的数据。
那么有没有一种黄金办法能搞定所有的数据呢?可能是不存在的,在我们的认知里面,没有一个万能的钥匙能解决所有的问题,所以对于每一种不同的数据,每一种不同的场景,我们需要不同的方法获取他们,他们的数据定义不一样,分析它们也需要不同的算法。
这是第四个趋势,数字化的演进和推进,我们所见到的数字类型也越来越多。同时,这对于我们从业者是一个挺有挑战的事,对于我们的要求也越来越高。
1.5 IT角色转变
最后一个趋势,是一个IT角色的转变。
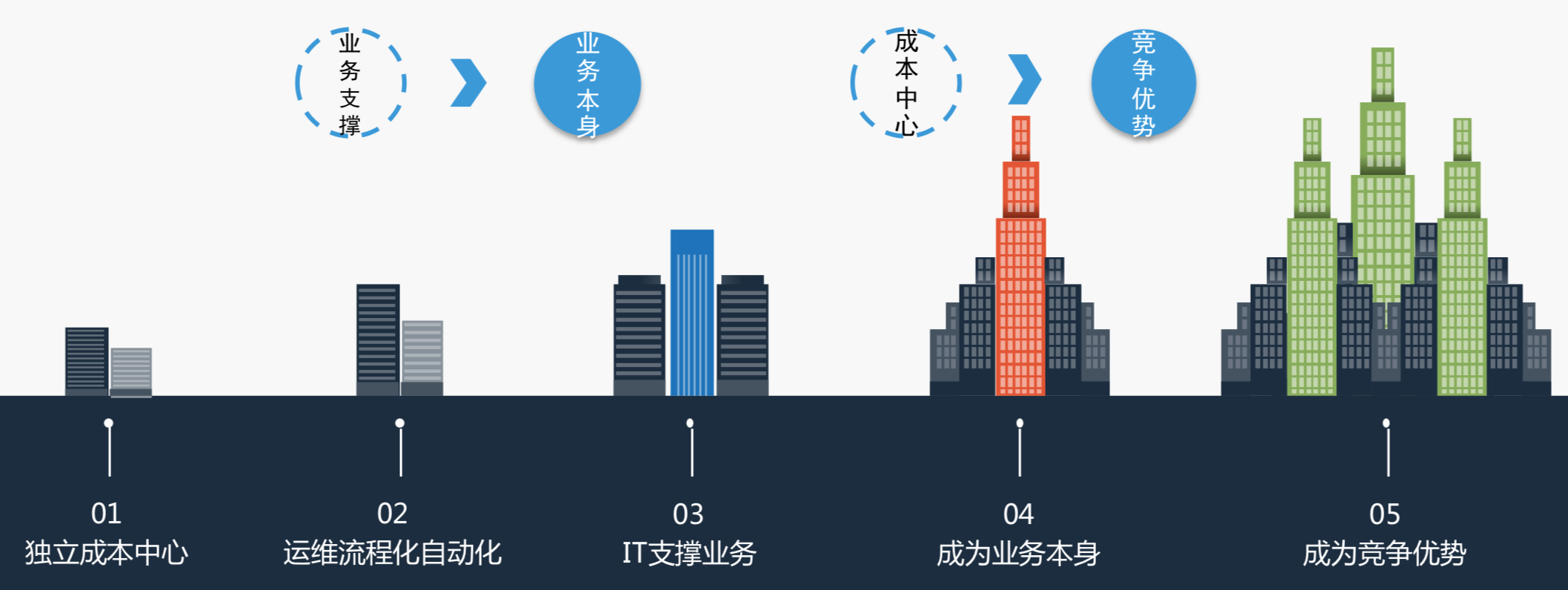
最开始有很多的IT公司会认为IT是一个成本中心,当逐渐堆人已经堆不上去了,就会考虑是不是能做运维流程和自动化呢?我们把人的双手解放出来。到了第三步,考虑IT能不能支撑这个业务,逐渐可能IT会变成业务的本身,最后可能IT会变成一个竞争的趋势。
我们看到中国很多的公司还在大概第一到第二个阶段,这是采自Gartner的报告,很多的互联网企业出身就是在第四个阶段,比如说线上支付、打车等等,已经逐渐成为业务本身。美国的一些公司已经有了竞争优势,比如说快销很出名的ZARA,利用高科技,利用数字化技术,能让产品服装从设计到出厂到店里不会超过几天的时间,包括沃尔玛在这方面的投入也非常大。
所以,我们看到一个趋势,以前大家觉得IT是一个成本中心,慢慢我们看到,IT必将会成为一个企业的竞争优势,同时IT效率的高低直接影响到这个企业的成败。
这就给IT人带来一个挑战,我们的角色不光是只要做好份内的事,管好我的主机就行,可能更多的是怎么把IT的业务和实际的公司业务相结合起来。所以我们看到这个趋势复杂度增加,数据源增加,数据量增多,类型多种多样。但是,每一个都是向上的箭头,没有一个是容易的事。
但是其实不用焦虑,因为我们认为新一代DevOps等于运维+数据+算法,这个算法有点像金字塔,是金字塔最上的东西,在金字塔下边一定要有数据和运维场景作为支撑。
现在很多人在说大数据,其实运维中间的大数据真的是很大的一个数据,比如刚刚提到的例子,查询账户余额。其实在业务上是很简单的按纽,可能在业务数据库里就一行,但是在运维里面经过了十几个服务最后传回来,可能有非常多的日志还有非常多的程序代表了它的信息。这么大的数据量怎么弄?用人已经搞不定了,所以需要用算法,用机器学习的方法来解决问题。
二. APM三部曲
前面讲的是偏宏观偏趋势,下面讲讲具体的场景和落地的范围。

APM应用性能监控,我们一般会分为三步,第一步叫做See看见,第二步叫做Act行动,我先看见了,我对我看见的东西做出行动,最后我还要知道,把这个信息知识Know沉淀下来。
对于这三部曲,我们AIOps可以做什么呢?
See看见
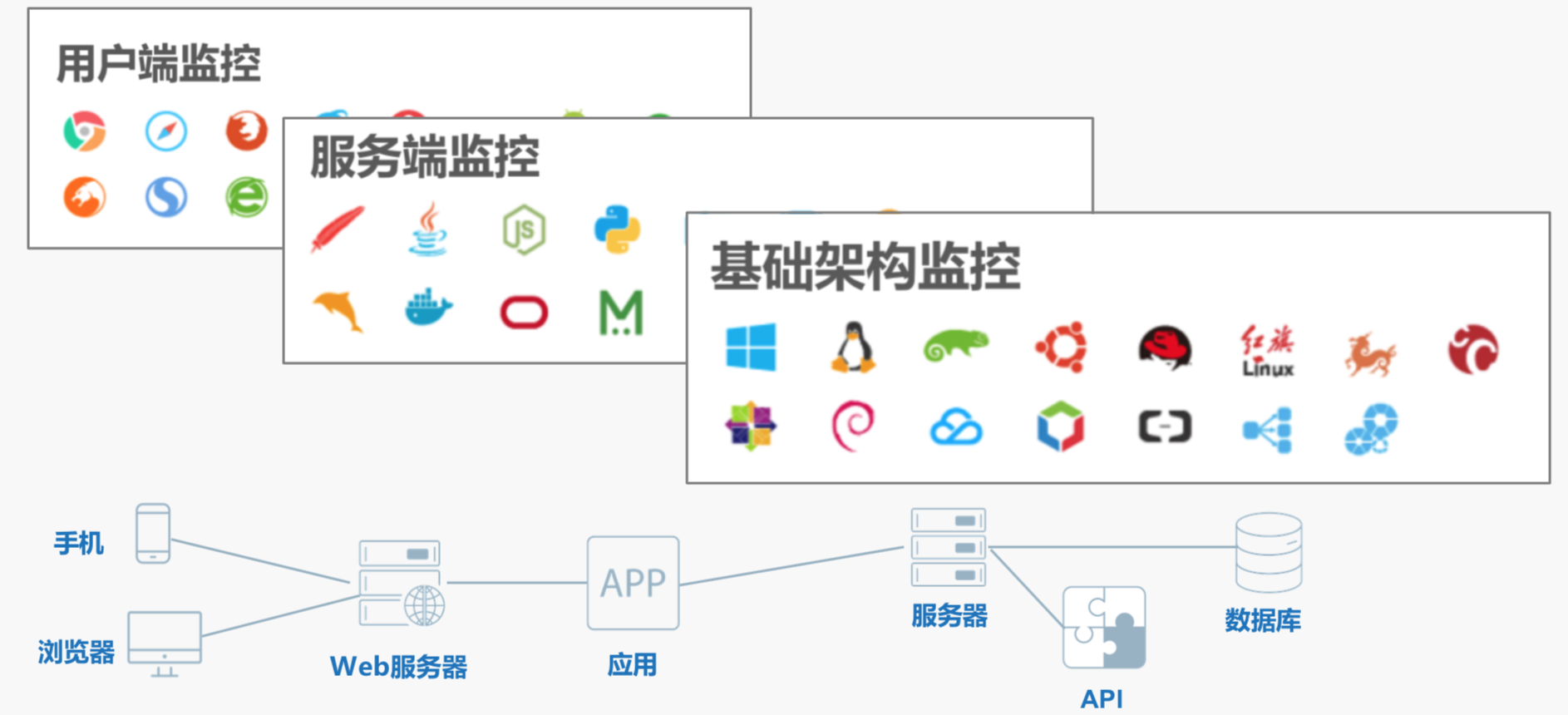
为了解决我们之前看不见的问题,我们必须要把所有的数据都采集到,比如说刚刚我们提到如果没有一个手机APP监控的话,很有可能后端团队在互相推诿,实际还找不到真正的根源。不管从用户端监控还是服务端监控还是基础监控都需要把数据采集下来,这就像盖楼房、金字塔一样,一定要把地基打牢。只有获得全面流动的数据才有数字化的成功,否则就像盲人摸象一样,只能看到系统的一块。
这些大屏也是很好的工具,能帮我们看到全面的范围,从用户的体验,从全端一直到后端都能全员地追诉起来。
Act行动
前面只是把数据先沉淀下来了,那怎么去行动呢?比如说我们运维最怕的就是这个场景,用户说无法正常交易,这时候看到查询已经很慢了,用户说交易已经做不了了,这时候运维的人可能看到一个端到端的指标,端到端的错误率,需要端到端的响应时间大幅度的提高,这可能有上百个服务器,怎么解决这个问题呢?这是压力非常大的事情,因为排查的时间越长,对业务的实际损失就越大。
能不能用机器学习的做法来做呢?因为我们能把大量的、多维度的数据给沉淀下来。我们能把前端、后端,服务器多维度的信息拿下来,然后用AI技术能看见多维度对于当前的慢响应或者错误效果是非常显著的。以前可能需要运维人员进去很多不同的机器看,有点像老中医需要有足够的经验才能判断到底哪里出问题。现在AI算法擅长的是无脑计算,因为它计算能力比人强很多,所以可以利用它海量的计算能力,用智能判断出来可能哪一个是潜在的根源,同时会给它打一个0到100的分数。
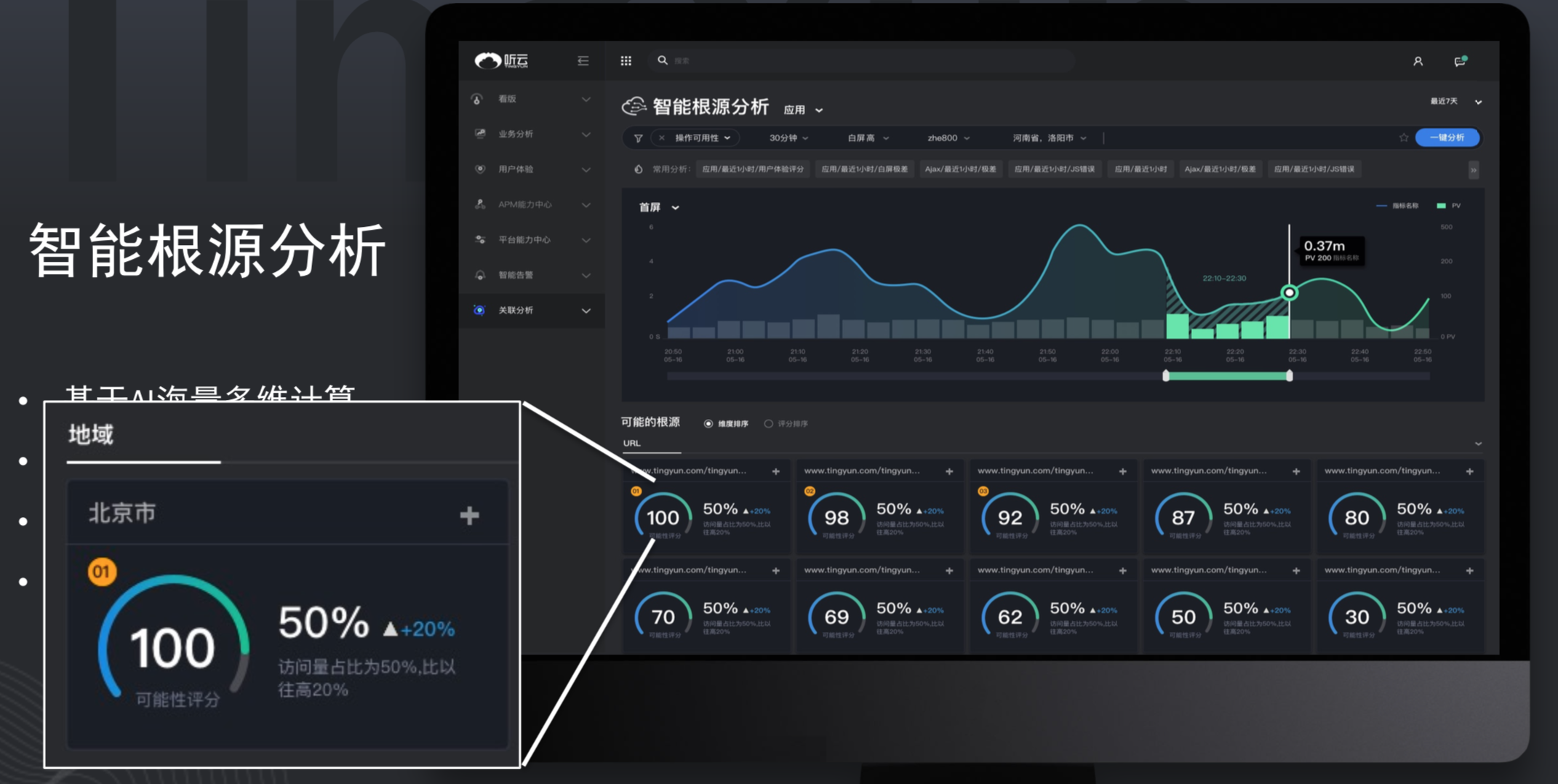
比如上面的场景,我们就能很明显地看出来北京市可能是非常显著的可能根源,因为今天用户说反应慢了,用户为什么说慢?我们根据这个一下能看出来北京地区可能存在问题,再加到分析的条件里进行一键分析,这样我能定位到具体哪个操作可能产生的慢响应,或者哪个URL超时造成的慢响应。
刚刚讲的是根源分析的例子,还有一个例子是智能报警。传统上来说,我们如果来看报警的话,会有很多的阈值,如果手工设定太繁琐。那怎么办呢?我们能不能用AI做未来的预测?这方面有很多的算法已经很成型,包括在华尔街,算法做股票的预测,这样用户只需要简单地设计我们需要监控的指标,系统可以自动地把指标根据历史的状态找到它们的周期性,找到它们的上升趋势、下降趋势,同时判断是不是超出正常的范围。
Know沉淀
行动是我看见了系统出错,我可以做一些行动,最后我需要沉淀下来。
我们再举两个例子,一个是从海量信息里去找到大量的信息,比如说很常见的例子就是运维里面可能拿到非常多的日志,一天一个T都算正常的,包括拿到非常多交易链的数据。

其实之前我们做日志分析的时候,我们发现打开一个日志工具时候,它可能有一千页,但很少有用户会看到第三页,其实跟大家搜百度、谷歌一样,搜第一页什么样,最后一页什么样,看看大概就有数了,其实很多人没有机会看到中间具体每一行每一列代表什么信息,能不能用机器学习算法把这些特征提取出来,就像上图右边显示的一样,我们只是展示一个国家的纵览图,而不展示每个街道是什么样的,通过机器学习算法把这些特征找到。因为人能接受的数据量相对来说是比较小的,但是机器的接受数据量是大的,所以使用机器学习作为中间的缓冲,接受大量的数据,处理过后再到我们人去消化可以做出更有效的判断。
我们看到机器学习现在发展的越来越多,包括大家能看到的机器学习可以下围棋,可以打Dota等。它可以让这个机器不断地进化,主动去学习。通过一些隐性的信号,传回我们的智能大脑里面去,让智能大脑把客户的反馈,用户的反馈给提取出来,让算法变得更好。
前面讲了很多,那么什么是AIOps?
我觉得很难定义一个AIOps,但是AIOps最终还是以AI、以算法、以工具为基础,并最终需要把这些落到不同的场景里去。
今天我们看到了五大趋势,应用的复杂度增加,多数据源、跨团队协作,数据量的增长大于人的增长,数据的多样性,我们IT不光仅仅是简单的IT,而是慢慢向业务扩展。
那我们怎么去应对?就需要以运维为基础,数据为基石,在这个数据之上,构建我们的AI能力,然后通过APM三部曲,看见、行动、沉淀,希望能给大家带来启发。
