@gaoxiaoyunwei2017
2017-12-13T11:51:44.000000Z
字数 8941
阅读 1459
全栈资源下的自动化运维灵魂
彭小阳
作者简介:

陈天宇
顺丰科技系统技术管理部负责人,07年参加工作,先后任职于中国电信、平安科技、顺丰科技,专注运维领域10年,从公务员到运维工程师,再到高级小步兵,一路坚守用技术解决问题的理念。目前任职于顺丰科技,负责操作系统相关的技术管理工作。
前言:
首先,我们先发散一下思维,后收敛。天下武功为快不破,互联网时代,让大家可以充分的分享信息,运维大会这类平台再早5年的话,在中国做运维不会这么苦也不会那么累。
本文、我分享的主题是全栈资源下做自动化。做运维到现在,参加过7*24小时值班,抗过机器,敲过代码,也玩过数据库,这个课题也是在帮我回顾总结这些年的运维经历苦难后留下的一些思考与总结。
我觉得我没有遇到运维的好日子,我真正从推板车模式里走出来,才发现原来大家都是这么玩的,大家都在玩自动化,都是以这个方法论、方向在玩,都在向 AIdevops 前进。
好的东西大家都会认同,长的帅的,基本帅的差不多。大家都知道美好的运维长什么样,但达到这个目标的路线是大家最关心的,我们也正在这条路上。
工程师与科学家的不同在于,工程师专注于这件事情怎么做,像步兵一样,一步一个台阶往前进,我接触的大多是运维“工程师”,戏称高级小步兵。我喜欢这样去呼呼我们的同事、包括我自己。下面把思维收敛到具体的内容,看看我们在顺丰的步兵前行记。
一、服务器资源KPI时代

我们回归正题。讲自动化之前,我先讲讲我们所处的资源环境及规则。先讲一下服务器KPI。借用三个经典哲学的问题来思考为什么服务器资源的KPI不能忽视。
我是谁?我们是哪个行业?我们做运维,我们是IT行业;我们在这个行业当中,我们为什么站在这个风口浪尖上,为什么大家这么关注运维?
我前端时间看到有个朋友圈分享的信息:“老板说,你觉得你的公司需要运维吗?运维经理回答说,过独木桥的时候,老板你觉得需要栏杆吗?独木桥上没有栏杆你也可以走过去,但是有栏杆你走的更放心,运维就是一家公司的护航、类似医生。你造一个航母要有人维护这个航母。
”在这巨大的包含了思想、技术、智慧的灵魂流入IT行业的时候,同样需要强大的肉身来装载,肉身在这里我狭义的定义为基础硬件,广义的大家可以理解为运维。服务器资源作为基础架构三大组件资源之首,逃脱不了被KPI规则化。
1.1、服务器资源KPI时代-我是谁

顺丰服务器的增长迅猛增长,2013年服务器数量到2017年翻了20倍。服务器增长快到什么地步,2013顺丰机房的兄弟人手不够,做系统、虚拟化、windows的同事全部前线支援上架。
IT部门目前是纳入成本中心,服务器的每笔采购必须是把背景、技术框架、物理部署架构、上线计划、容量评估依据等讲的清清楚楚,这就需要完整的容量管理体系,在这个体系里哪些点才是key呢?在这快速增长过程中,我们的人员实际上是没有翻倍增长的,这些就是运维技术发展带来的红利。
我常与我们同事分享一个理念:我们追求运维新技术,刷新自己的技能不是为了追赶潮流,而是学习多一种新手段,在解决问题的时候会多一种选择。在这种引导下,现在我们再去给老板汇报预算的时候,都有数据支撑,我们把所有的从底层自服务器安装到OS标准化,到虚拟化模板,到应用、数据库的配置,及容量性能监控采集数据全部入库,并可展示。
还有下面一张图,是摩尔定律的,每26个月晶体管数量翻一番,现在来看摩尔定律遇到最大的问题就是如何解决散热,如果芯片设计不出现根本性变革,摩尔定律可能被打破。
说到这里,大家认为服务器KPI需要设定吗,怎么设定?是看使用率、看故障率、看采购价格、根据应用场景看使用率区间?如果使用率设置为KPI,那就是为performance tune埋坑,数据库、应用优化做的越好,使用率反而更低,不合适。好的KPI应该是服务器资源交付快,快到小时级别;硬件故障率低,低到整机千分之5以下;使用率在考虑HA及最优配置及业务高峰后,越接近服务性能极限越好。后面我们来说这些我们的行动路线。
1.2、服务器资源KPI时代-我从哪里来

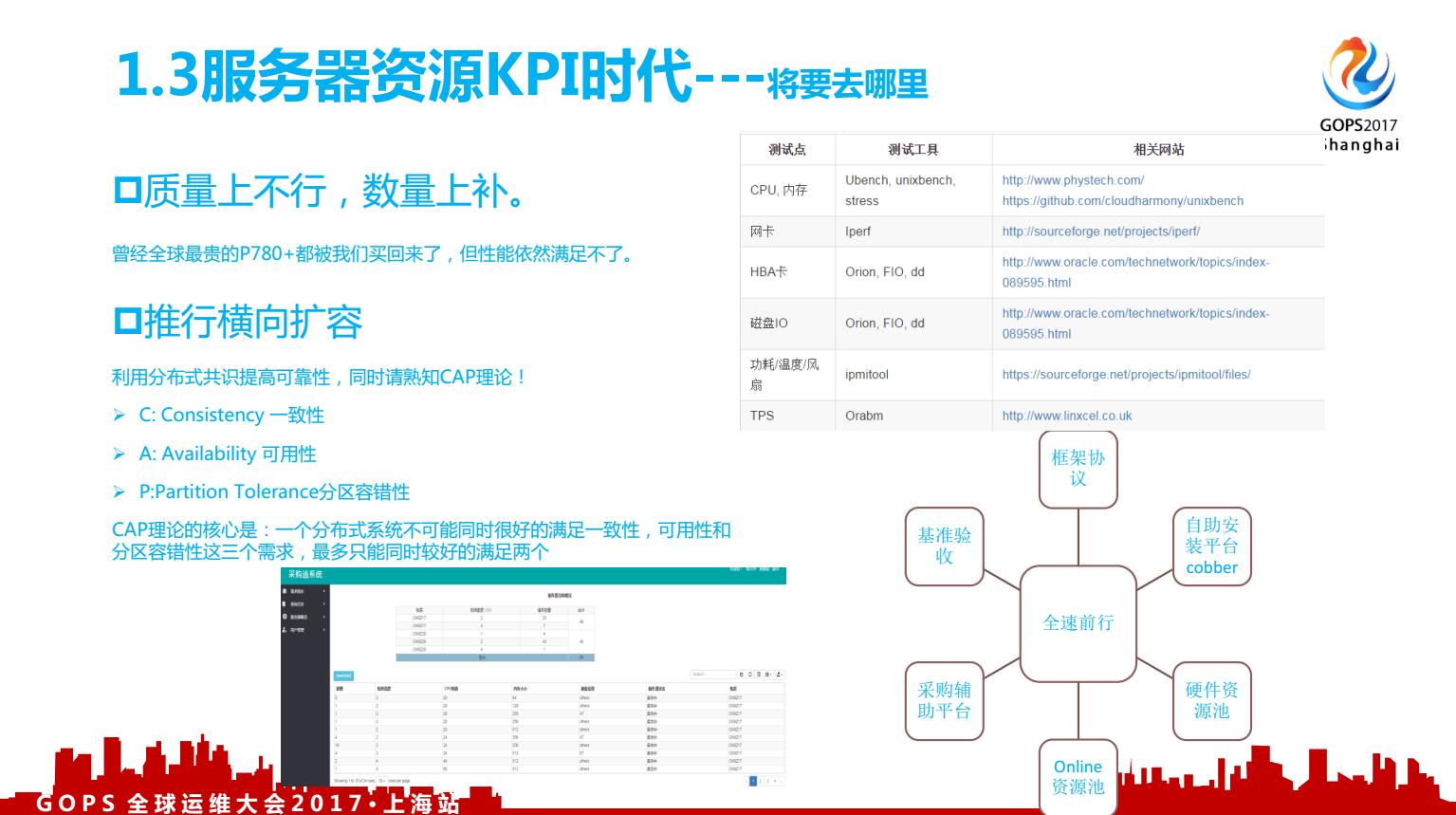
我们从哪里来?这里要回到服务器资源投入到哪个业务上,带来的预估价值上来。之所以是预估价值,是因为这些涉及太多边际成本,我们只能狭义的去预估这个业务的价值,同样从业务到IT投入的价值评估模型建立我们也在进行中。X86服务器不像小型机那样“高贵”,硬件的供应多选择,所以在选择的能力上我们要有,怎么做:建立硬件性能指标体系,看右侧的图就是我们底层用的工具。
明知芯片速度的提升已经达到难以为继的境界,但是人类对速度的追求却并没有丝毫停歇的意思。那怎样在不烧毁计算机的情况下满足人类漫无止凌的贪婪呢?
质量上不行,数量上补:多核结构出现。这当中,美国的一个研究室得到一个结论,并不是买机器的时候核数越高越好,服务器的核数对于OLTP型的应用性能提升最高是在八核的配置下;这些就让我们知道在选型的时候不会盲目追求核数越多越好,也知道应用迁移的时候,核数的增多带来的应用性能提升不一定对等。
1.3、服务器资源KPI时代-将要去哪里
我有个朋友在一家上市的电子公司工作,他们有全国有6个工厂。IT系统基本靠5台小型机承载;然后他问我,能不能也搞自动化?我说,你们用的小型机也挺稳定,而且运维共计就三个人,自动化没有必要做,但可以学习其中有用的理念:精益运维、主动预防。
做运维自动化,很多同事会问你的目标是什么,投了多少人,产出的如何,实用性如何?资源这块,我没办法解决,但目标我们不能变,不能因为资源影响我们运维人对美好运维生活的向往。只有目标不变,我们才会自发的向这个方向走,当大家尝到好处,接受的人会越多,公司也就越支持,自然得到的资源就会越多。
首先强调是说,运维开发,为什么不是开发,它是运维出身的,你代码的逻辑都是用运维的思维沉淀下来写的;我以前以为外面的和尚会念经,我招了一个,然后我让他写个自动化绑IP的API功能,就是VIP的;后来他2、3个小时写出来了,我看了一下,几条命令搞定了;我开玩笑说,你疯了,你入参这个不判断一下,别人输入字符串呢?掩码不判断下,别人输入的不同网段呢,不限定数字,别人输入260呢?所以就是说,做开发的,他会写代码有这个开发能力,但是没有这个逻辑,根本写不出来你想要的东西。
这里有个能力三条边模型,类似字母“Z”,最下面的这条边我们可以叫做我们掌握的运维的逻辑规则基线,类似CAP理论、高可用、灾难应对、容量管理逻辑、应用日志输入规范、安全基线要求等等;最上面的边,我们可以叫做我们要做的事情或者目标;中间的斜线就是我们要达到目标的路径或者说的步骤,你会发现能力基线与目标与接近,斜率越小,也约容易。招一个没有运维经验的研发,就好比基线在地底,你要完成运维开发的目标,斜率接近90度,挺难的。
我开始带团队只有2个人,现在有18个人,我当时因为去内部新生ITclass分享工作心得,赢得两位新大学生的青睐,2个研究生分组自愿到了我们团队;来了之后,我说你给我把所有的工单做一下,而且不用太分边界网络、数据库,这都要理解其中的原理;我会给他们强调:岗位有边界,但是技术是没有边界的(其实是引用的一位科学家的爱国之言,科学没有国度,但是科学家有祖国。)之前大家都是写sh,后面我提要求,所以自动化编码默认都使用python,这种自觉的推动下,大家的这种基本编码能力建立起来了。
为什么在爱因斯坦那个年代那么容易出伟大的物理学家;挺老一辈讲那时的大学老师去讲课的时候,都会很谦虚的说,今天讲相对论,我还太不懂,大家一起互相交流,相对论提出来的时候全世界懂的只有2.5个人;因为当时做物理研究的人很少。
现在做运维的很多的知识充分的交流,充分的去学习之后,大家已经知道了做的好的是什么样,已经知道了蓝图,如何去实现变的有迹可循。走这条路,没钱没资源,你有那么多坑要填,还是负责运维,要交付资源,交付网络,交付各种工单,真做这个事情需要领导认同;给予编制、给予支持、给予容错、给予严厉的价值要求。我很幸运遇到了一个这样的老板,他是这条路线的支持者,给予了我们很大的帮助。
二、操作系统的母体效应

讲到硬件,我们不得不谈谈操作系统。
2.1、操作系统母体效应-认识篇
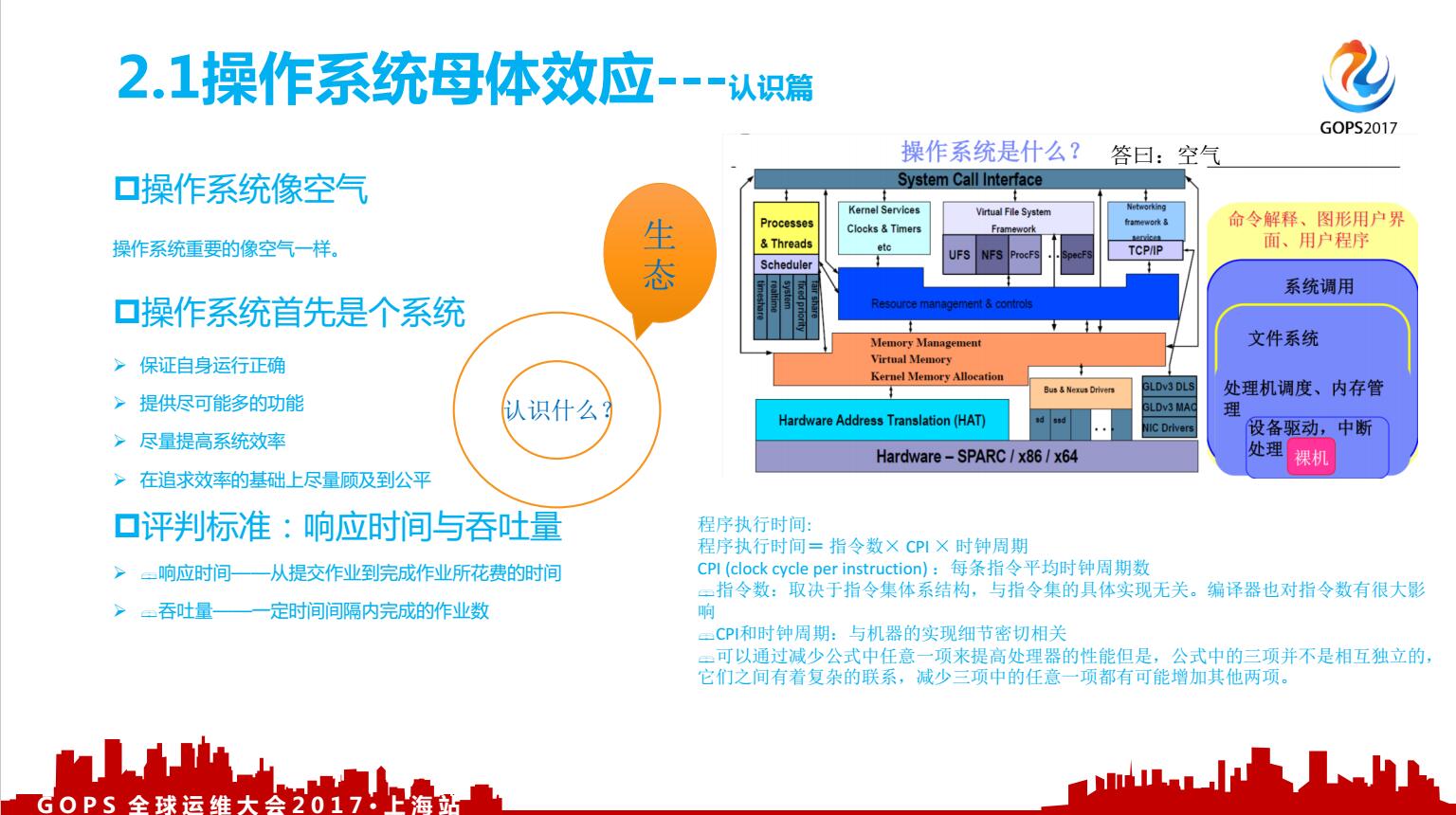
大家目前公司用的操作系统都是什么版本,版本的选择依据是什么,有没有现在生产上用centos7.4的?大家为什么更新操作系统,是被迫,还是有这种比较先进的观念?我觉得我技术很好,就要玩新的东西,这背后的内驱动是什么?为什么你更新你的系统版本。
实际上这个问题,是硬件的迭代带来的一些操作系统版本的变革。操作系统的原理,一致没有怎么变,值得大家花些时间去理解一下。操作系统本身是一个系统,可以通过这个系统了解到很多的技术原理及软件开发的逻辑,可以从底层了解一下,什么叫做很牛的软件,他的好坏的评判标准是什么,大家可以看看右下方的公式,大学里计算机专业的都会学这个。
2.2、操作系统的母体效应-生态篇
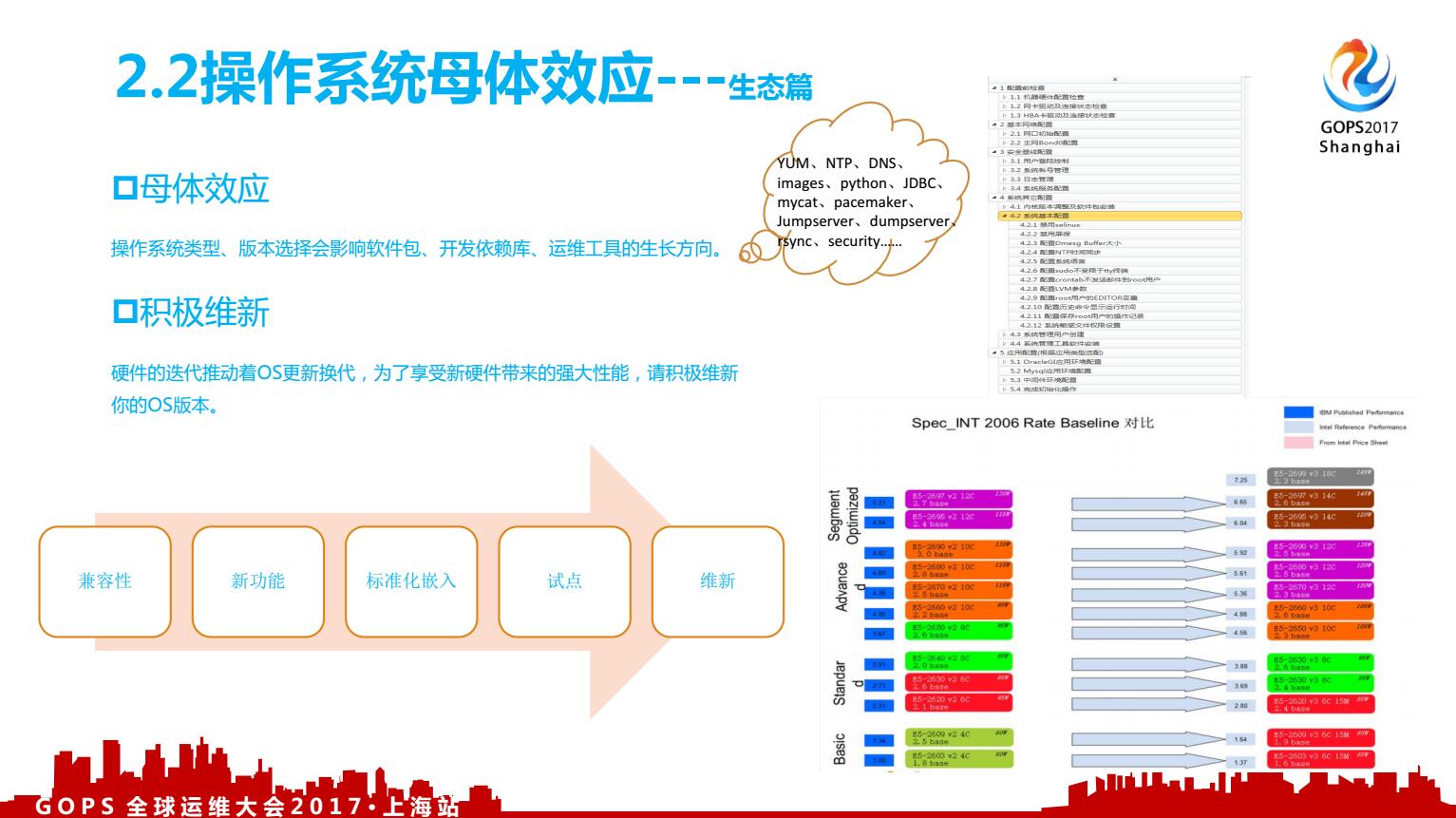
同时操作系统衍生出许多辅助工具,例如DNS、NTP、SAR、OSW、YUM、rsync、SSH、pacemaker、ipmi、megecli等等,来共建了自己的生态,操作系统很重要,作为上层的业务运维来说,对于应用来说是透明的,重要的像空气一样,大家每天都呼吸;因为它重要的就像空气,但是你又不能忽视它,我不知道有没有人被安全基线要求做漏洞检测,要求打补丁包。操作系统生态出问题,相当于空气被污染,当污染出现,大家都会有恐慌。所以我们就要把这些净化工作放到日常工作中,规则迭代中,让操作系统的生态健康不被污染。从硬件到操作系统,这一块每个焊接都是大家需要运维当中的实践出来的,纯粹写代码是不能体会这种生态的。
所以说,其实真正做运维开发最累的是运维,他要把他的逻辑整理成开发需求文档,这个逻辑沉淀的过程,我们的同事可能要脱层皮,思维模式的转变,及谨慎、全面的沟通是必不可少的。
对于做运维来说是大家都不能忽视的环节,底层的参数配置不合理、不标准,自动化运维是不牢靠的,这个是共识,我们要积极的维新,维持我们的软件版本、参数配置、人员脑海里理解的技术规则都是不断在刷新的,但这个刷新的过程是肯定需要控制的,得有个流程、过程,可以看左下这张图,要考虑兼容性、新功能等,快速试点迭代,批量推行。
积极维新带来什么好处呢?最右下的图是因特尔官方网站的一张关于每一代CPU的更替带来的性能提升图,每次CPU更替带来的性能增幅在30%;而每年大概迭代两次,硬件更替之后你要看看与现有操作系统的兼容时间还剩多久,现在的版本是否可以发挥服务器硬件最大的性能?所以硬件的更迭推进操作系统版本的更新,操作系统版本的更新又会给数据库、中间件带来改变,这就是操作系统的母体效应,这就是在做运维开发过程中要考虑进去的场景。
中间件、数据库技术的更新,要站在操作系统的基石上,我觉得IT规模大的公司,公司里面一定要有一个团队或者某个人告诉你,现在的应用标准配置是什么样的,参数怎么用,让整个应用环境是不断的得到净化的,不会出现五花八门的版本、软件,不会有太多污染带来病痛。
2.3、操作系统的母体效应-建设篇

所以操作系统的选择带来你的生态的改变是非常大的,数据库、中间件结合操作系统运维这个是最佳的方向,做运维开发的时候,开发逻辑从数据库、中间件上层往操作系统沉淀是较容易打通的;我们在做操作系统标准化有很多的初始化代码,实际上很多标准需要我们代码里面抽离回来重新写成文档。
借用操作系统内核态、用户态的名词,我这是这么定义的,我跟我们团队这样说,如果你研究的模块你能够看的懂代码并能够根据需要改写,那么你可以把这个模块纳入你的“用户态“;如果你掌控不了,你不知道这个模块底层的逻辑是怎么实现的,那你就把它标记为内核态。
其实操作系统层面,你研究的东西大有可为,性能现场提取工具osw,我们基本上就改写了,根据自己需要的信息重新定义采集项、采集频率,保持时长,更贴近实际运用,另外基于cgroup我们也在做一些工具,应用与多库共计一台主机,某个库发疯失控的场景;例如I/O的任务调度策略有四种Anticipatory、cfq、 noop、 dealine,默认策略是cfq,但mysql数据库场景下dealine才会是最佳实践;CPU、MEM的调度算法同样要根据场景定义最佳配置。
这些”内核态“的深入,扩大了我们的”用户态“,让我们掌握更多的技术武器,来武装我们的运维部队,让大家处理异常情况时不再那么恐慌。看右图,仰望星空与脚踏实地,带这这种心态,我让我们的团队一步步向内核态发起探索。
三、全栈资源的建立

我们讲一下操作系统上一层,我们讲一下我们的资源栈。
3.1、全栈资源的建立-时间成本

我这里给资源一个狭义的定义,就是开袋即食;讲的资源问题,其中两个指标,一个是时间,一个是 稳定性。在业务软件产品迭代这么快的情况下,时间成本同样的重要。那么我们快速的交付一个硬件固件是达到基线的、相关os层、应用层配置是最佳实践的、同时监控、cmdb、堡垒机授权这些是配套配置完整的资源,能否达到分钟级别?部分应用场景,通过KVM、docker平台我们是可以做到的, 这些为我们换来了时间,引用SRE的话来说就是我们有时间去干更有意义的事情。
同步看看右边的图,在追求减少时间成本的过程中,我们应该有一套完整的组织方法论来支持我们,避免走错方向;ITIL是基础,需要用ITIL这个武器来保障我们的基本运维稳中有序,这样才有更多“可自由支配的时间”。有时间之后,我们可以做的事情就可多了,有意思的事情就在时间充裕的情况下发生了,我们开动了集中的自动化门户建设,各专业组实现各自组件的API化。这种从内突破的理念也是在有时间的情况下,大家反思沉淀下来的,并可以亲身践行,因为我们有时间了。
3.2、全栈资源的建立-排兵布阵
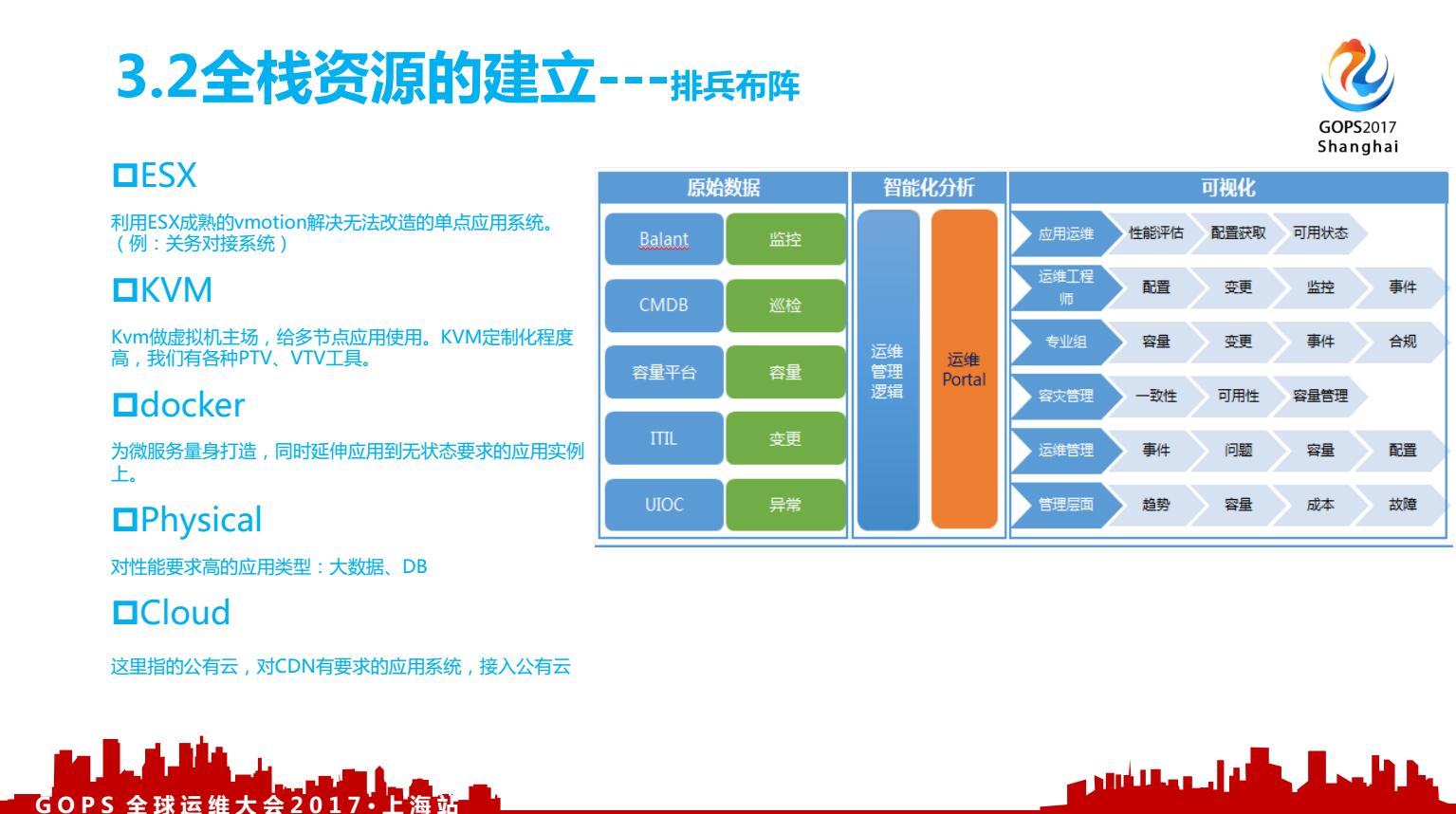
这张图是我们的排兵布阵,每种资源形态都是实际业务场景下催生出来的。公有云确实好用,那好用要加个定语,就是轻量的应用类型,对于大数据量数据库不一定好用。所以大家可以看看我们的资源有五种形态,这五种形态下我们要同步考虑对接到自动化门户,光用ansible是搞不定的,要结合IPMI、监控agent,并且把各类资源定义好标签。
大家可以看看右图,就是我们整理资源自动化的前行方向。另外说说,为什么还有ESX,在于公司确实存在顽固的单点系统,我们的关务报关系统就是单点,并且是顽固的非内部可控的单点系统,ESX的vmotion功能这么完善,所以我们用它来保障这个系统的稳定性。那ESX资源的API我们就要搞定,包含运维管理、资源交付的,我们花两个人力,集中火力,两个月搞定了,现在ESX的搭建、VM交付已经可以自助,但应用场景、及昂贵的license费用,注定ESX不会成虚拟化的主流;我们的主流是KVM及docker。
下面我们来看看docker,我们的docker已为公司核心应用提供服务,并赢得一致好评。
3.3、全栈资源的建立-docker

docker这一块,在2016年中我们开始投产使用,具体的技术点大家可以看看,在docker的使用上实际是需要深入与研发同事并肩作战的,很容易被大家误解为devops,其实不然,但docker给我们带来的便利:底层资源足够的情况下业务系统容量伸缩自如,硬件故障对业务基本透明。
目前我们还是基于Mesos+Marathon架构,我们下一步的工作会引入Kubernetes作为容器管理和编排框架,并在此之上引入Service Mesh作为下一代微服务框架。目前从业内反馈来看Kubernets好用,那么好的东西大家都会认可,并去采用。在使用容器遇到的最大的问题就是,Host主机内核bug,导致当一台服务器宕机后,容器消亡,但连接不释放,导致应用的连接数满。这个问题在我们升级操作系统内核后解决,这里又回到我们提到的操作系统生态,这些都是相辅相成的。
3.4、全栈资源的建立-KVM
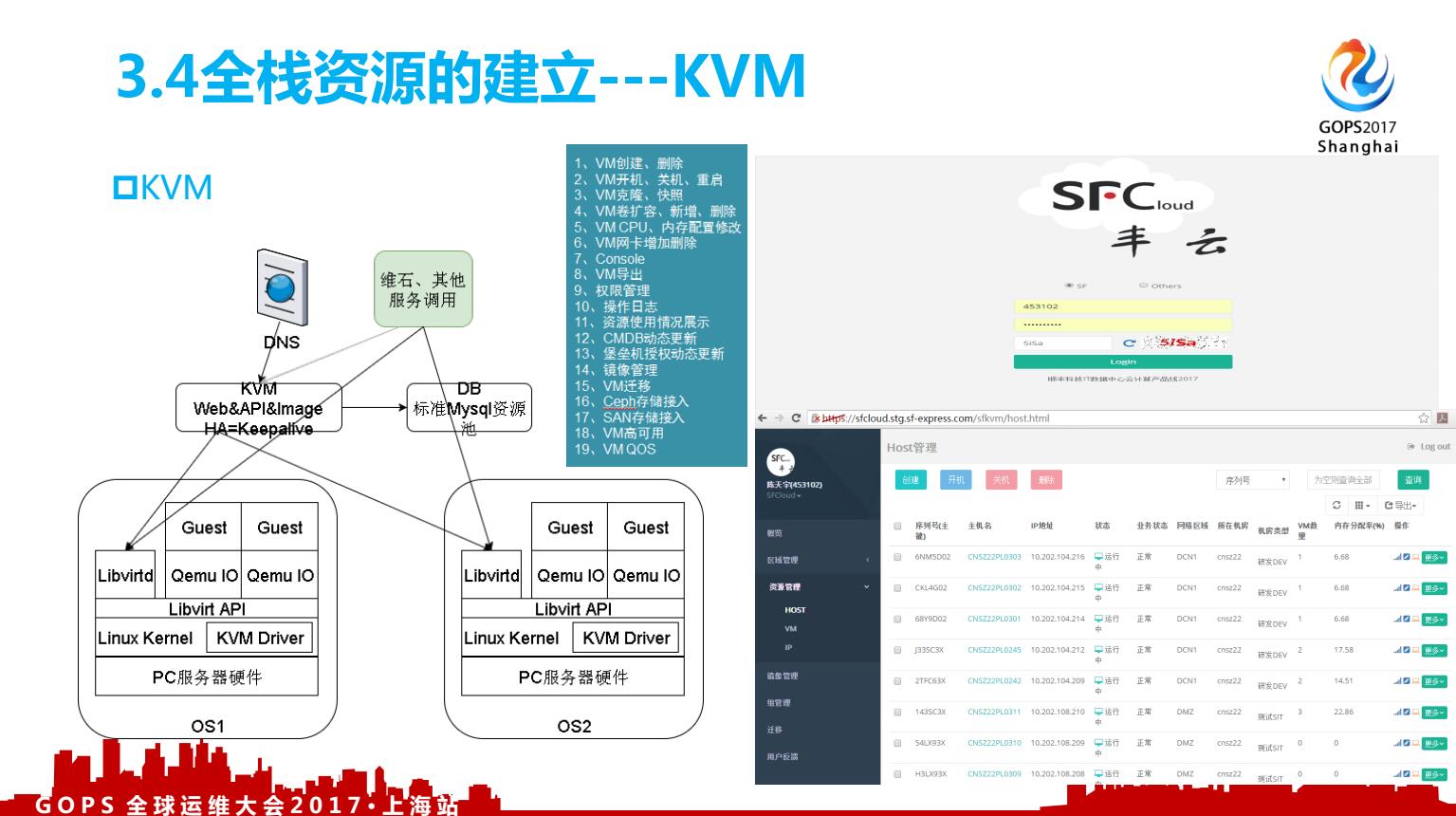
再讲讲KVM,实际上我在内部叫KVM平台,它是基于Libvirt做的管理页面开发,并把我们的容量管理逻辑沉淀进来;KVM的底层思想是在Linux内个的基础上添加虚拟机管理模块,重用Linux内核中已经完善的进程调度,内存管理,IO管理等部分,因此KVM并不是一个完整的模拟器,而只是一个提供虚拟化功能的内核插件,具体的模拟器工作是借助QEMU来完成的。在KVM中,一个虚拟机就是一个传统的HOST主机上Linux中的线程,拥有自己的PID号,也可以被kill系统调用直接杀死,相当于虚拟机"突然断电";在一个HOST 上Linux系统中,有多少个VM,就有多少个进程,可以通过字符命令virsh来查看。
在这里我们讲了一下基本的KVM知识,我们需要对标一下自己在这个平台上开发的东西有哪些价值,同步vmware在虚拟化在稳定性、功能上业内公认是最好的。那么我们开发的功能基本上就会向vmware对齐,找到自己的参照物,才会有基本线规则。谈到如何评判虚拟化技术的好坏,这里有个学术的专有名词,叫做“指令转化率”。Vmware宣称可以做到97%的转换率,只有3%的损耗,我们实测只有90%,不晓得是否我们哪里配置不当,目前没有找到问题点。但我们实测KVM的转换率,确实不如vmware,只有80%左右,但这不影响我们采用KVM做我们的主流虚拟机组件,这个大家应该都懂得。
四、Ansible自动化运维的核心灵魂

讲到最后,我们来完整的讲讲自动化,说到自动化都离不开执行通道的采用什么组件,chef、saltstack、Puppet。我们用的ansible+agent,下面讲讲Ansible。
4.1、Ansible自动化运维-概览

Ansible实际上我们在2014年我们就开始小部分用,那时候我们经常做变更发现我们的机器数量增长太快,如果还是手工做,一晚上也搞不定,我们的同事自发的研究其批量管理工具,发现ansible轻量、好用,大家尝到甜头,慢慢的ansible key的配置就成为了资源交付的标准化中的一项了;ansible底盘就这样无形的被控制了。
到目前为止,ansible的模块已经被我们改的面目全非,但是挺适合我们顺丰自己的环境适应。我们定义十几个模块,sfsoft、changesudo、changeuser、changepasswd、checkafterreboot、checkbeforereboot、oshealth、osinfo、osservice、linux_sec_check、dbopration、dealwithmultipath、get_log、get_top_file、mid_check、osmount、osvip等等,对于放开全部的执行权限,这里要解决的难题就是如何鉴权,让对于的运维人员只能执行对于的指令,并在对的服务器上执行。
4.2、Ansible自动化运维-细看实现

它本身来说, Ansible server是很集中的,本身就是个很大的安全问题存在,如果做好ansible本身server端的安全管控,这个也是个话题。大家可以看看上图,我们通过7种手段来严防死守,把这个安全问题通过其他的手段来弥补掉。说到缺陷,ansible还有个非常严重的缺陷,那就是ansible不能自动发现新搭建服务器资源的ip。我们是通过监控的agent来做新主机的自动发现的。Ansible的好用大家都知道,我们就不多说,主要来看看它有哪些不足,我们针对性的想办法对弥补这些不足项。
4.3、Ansible自动化运维-弥补不足

对于有一定技术功底的团队,技术没有好坏之分,团队能掌控的,我认为就是合适的技术。基于这个态度,我们看的ansible也有挺多的缺陷,当我们要想办法弥补这些缺陷,让这些缺陷无关痛痒,这个时候ansible就在这个团队中生根了,有生命力了。
Ansible server端如何做成分布式?大批量任务下发有任务卡死无法输出最终结果?如何提高任务执行的并发数?这些都是我们使用过程中遇到的实际问题,把server端做成分布式后,很多问题都不会再是问题。那这些问题的解决思路我只是参与,真正解决问题的是我们的高级小步兵们,他们才自动化能顺利推行的根本。
4.4、Ansible自动化运维-灵魂
这几年带团队给我的核心的感触,就是技术是以人为本。团队里有没有能抗起事情的人,解决问题的本质是要找对人。自动化运维的细节,都是靠高级小步兵们一步一步实现的,领导能给的是方向、目标、资源和信任,同样我们作为高级小步兵不能辜负领导的信任,当这种信任被建立起来,整改组织才能迈入运维自动化的快通道。这种运维气质在内心的,形成内驱动,要有改善运维环境志向,我们要把运维做的更精彩。
工作要出业绩,需要一支专业性强、目标很清晰的团队,同时领导的严格要求也是有助团队成长的,用严格的要求去善待我们的队友。专业性是被逼出来的,目标是否清晰是指挥官的责任,所以指挥官不能太多,如果多位指挥官,需要目标一致。绝大多数的运维人,都是高级小步兵,用我们整齐划一的步伐推动运维行业走向美好的明天。
上面都发散的很厉害,结尾我收敛一下:技术以人为本,找对人、招对人,善待队友,让团队形成一股匠心力,把运维做成美好的行业,让运维在前行中更精彩。
