@gaoxiaoyunwei2017
2017-10-24T02:31:35.000000Z
字数 7812
阅读 1666
京东全链路压测军演系统
wt
前言:在京东的成长
我来自于京东商城,现在在技术平台部负责全链路压测,运维相关的工作,我个人2010年3月份加入京东的。
当时京东还在苏州街呢,在一个居民楼里,条件非常差,当时面试的时候就是我原来的老板,就问我三个问题,第一个问题就是你现在上家单位负责什么?我说我是做运维的。第二个问题就是lives会不会?我说会。第三个问题,薪水。
接下来是部门的总监找到我,问了一个问题,你觉得你的薪水高吗?我说不高。他说挺高的,比我都高。接着HR面我。通过面试的这些细节就可以了解到当时京东的技术力量特别薄弱,当时所有的线上环境都是.net环境。
后来我加入以后做运维相关的,最开始接手第一份工作就是做CDN,后来是网络,紧接着是负载均衡和DNS,除了数据库没有做过,运维的都做过。
2016年以前我还是一直做网络负载均衡CDN相关的工作,后来由于部门的调整,我去了商城的一个基础架构部门,牵头第一个工作就是今天我们的主题全链路压测,在京东之前是没有的,主要压测任务都是各个团队,因为原来在京东它的压测量非常小,随着京东的业务越来越多,在我之前所有的压测团队特别累。
大促遇到的头疼二三事
今天的主题是全链路压测,在这之前京东的压测任务主要是由各个团队去完成的。
刚开始京东的压测量非常小,随着京东的业务越来越多,之前所有的压测团队都非常累。主要有以下这些问题:

通宵备战、凭经验值资源规划
每次大促之前所有的研发、测试都要通过通宵的方式加班加点的压每个系统,到底能不能支撑大促的流量。基本上每次大促都要增加上万台服务器。每个系统可能要根据压测的结果去评估我到底需要多少服务器。例如我去年双11一百台服务器扛了多少量,今年618的预估量是多少,我的服务器资源经过这次压测又要增加多少,基本上都是凭经验。昼夜排队性能压测
由于压测团队的压测资源比较少,多的几百台、少的几十台,要相互借用。当压某一个系统,基本上每个系统都要从0开始压,一次压测就是一晚上。每个系统都要进行排队,比如今天压交易,明天压网站。数据不准确,影响线上
之前所有的压测都是通过内网进行的,压单个接口,带来的问题就是压的数据基本上不够准确。因为内网压测,京东现在都是万兆光纤,内网网络延迟都在0.5ms左右,跟线上的用户从公网到应用的网络延迟差距太大。如果广州的用户到京东去访问首页,可能解析到了广州本地的 CDN 节点,但是交易相关的动态服务还是要来北京的。广州到北京的专线网络延迟大概是30ms左右,如果当地的网络质量有问题,网络延迟可能会更高,一百多毫秒、甚至有丢包情况。这样对于你的系统来讲,你需要等待它的网络延迟进行 TCP 连接,它的压力肯定是不一样的。
如果它的延迟在零点几毫秒跟你建立连接和上百毫秒的应用跟你建立连接,服务器的性能肯定不一样, qps 也不一样。
跨团队压测协助太多
还有就是跨团队协作的问题。例如,压购物车,购物车涉及到的促销价格的各个部分都需要配合。价格已经压过,可以承载上千万的并发。但是购物车今晚要压,价格需要配合,还是要留人值守。跨团队存在很大的问题,每次都要大量的沟通,今晚上我要压力,各个兄弟团队一定要配合好我,一定要安排人你、不要压挂了。
上下游系统性能各异
大家都知道购物车涉及到的上下游关系很复杂。京东的购物车涉及到促销、价格、优惠券、广告,都需要进行配合。它们的性能肯定是不一样的。比如说广告能扛上千万的 qps ,促销只能扛一百万,价格肯能也是千万,但是另外的几个接口可能只有几十万。那么对于购物车来讲,它最终的qps只是上下游中qps最小的那个了。单一服务不依赖其他服务压的时候可能达千万。
如果上下游一起做压测的时候,服务的 qps 可能就是性能最低的那个接口的 qps 。上下游 qps 最小的那个系统就是你的瓶颈,你能扛一千万、你依赖的上游只能扛一百万。那么你的qps就只有一百万。
因为各个系统有不同的部门负责,他只关心自己的系统能扛多少。这样导致大促的时候用户访问的不是一个系统,是N个系统的组合。之前面临的问题就是各个系统性能不一,导致我们总的 qps 一直上不去。
单一系统内网压测
最后就是之前一直是单一系统内网压测。为什么叫单一的压测?是因为串不起来、没法串,有的系统可能做得好一些,直接压线上。把线上流量导入自己的系统,第二天汇报压测能扛一千万。大促一样挂,因为它依赖的上游系统只有一千万,来到的用户有一百万就垮了。因为压测涉及到网络、运维、系统以及接口,压测团队要写脚本,跟研发进行对压测数据的准备。这些工作量特别大,压测团队特别辛苦,运维的兄弟也要一起熬夜。
常用压测工具
我们常用的压测工具,估计在场的压测团队都比较熟悉。
- load runner:大家第一个用的估计都是这个,点点就会玩了。
- JMeter:研发的兄弟应该用过,自己压的时候这个工具其实挺好的。
- nGrinder:是一家韩国公司基于Grinder开发出来的,免费的。在京东没有全链路压测之前一直用这个。尤其是交易,可以做集群和场景模拟。
- Gatling:这个可能用的不是很多,我们的团队广告部门原来是用这个的。之前测试团队在京东是一个大的团队,属于运维体系。
- ab:估计运维的同学用的比较多。你要压一个小服务用ab直接就能搞定了。还有很多其他的压测工具,在这里就不一一介绍了。
右边的图片是京东第一版规划部署图,当时想的很简单,要把线上所有系统相互依赖的接口串起来,不是单独的压一个接口。因为每年618、双11京东都有备战,提前三个月左右。
每次备战的时候都有架构师去检查各个团队的系统备战情况,梳理各自的应急预案,各个团队提到最多的就是压测遇到的问题。
- 第一,就是资源不够,压不到我想要的量。
- 第二,压的时候其他部门不配合,需要架构师团队帮忙协调。
- 第三,压的是压线下的,不敢压线上,线上的不敢承诺能扛多少量。
全链路压测ForceBot
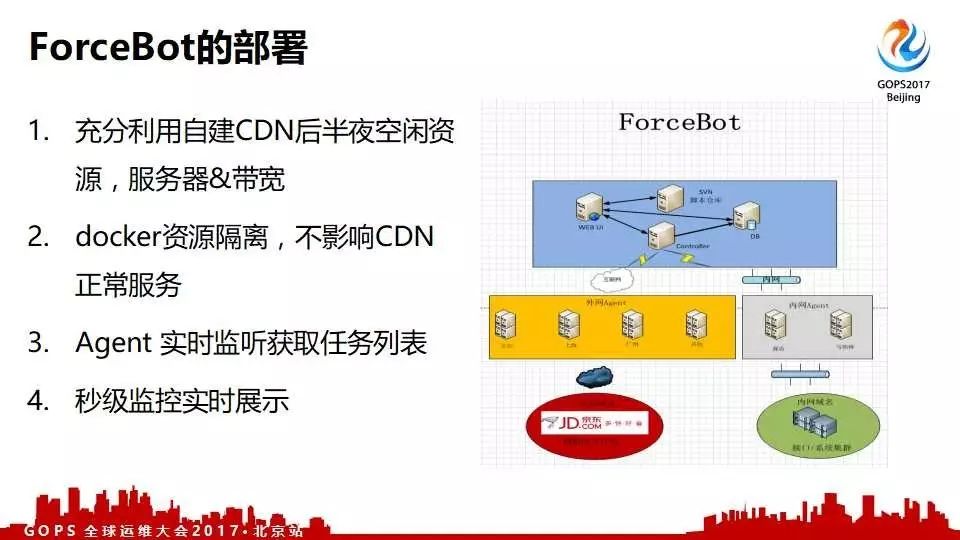
当时我们各个架构师拉到一块,聊压测的时候,我们说能不能做个压一次就能知道所有系统的瓶颈的东西。后来老板刘海峰说我们弄一个全链路压测。去模拟用户从公网访问进来浏览、下单、购物、支付,查看订单等所有的行为。用暴力机器人去模拟人类的动作去做压测,这个靠不靠谱你去调研一下。
当时和各个团队去聊,说我们想做这样的事情。大概情况是这样的,首先把压力机铺到全国各地。京东自有CDN,后半夜带宽和服务器基本上都是闲置状态,我们可以在后半夜利用这个资源。
通过这些压力机去模拟用户访问京东,从首页到搜索下单。在压力机上部署一些我们的监控去实时的获取任务,这些压力机都有定时的ID,去访问任务还是跑脚本都是动态的。
压测需求
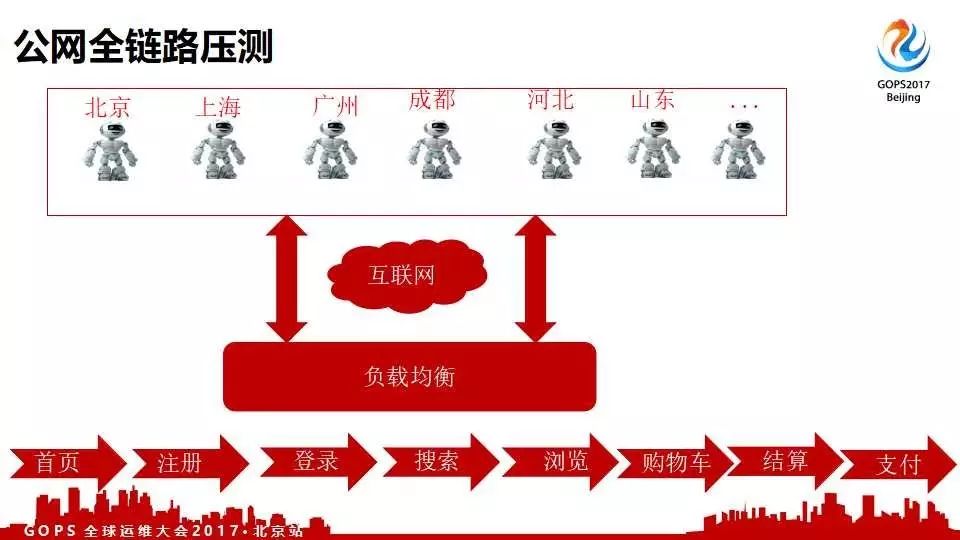
另外一个架构是我怎么实时的看到压了多少、压力机的性能以及被压系统的性能。后来我们就做了一个简单的秒级监控。第一版也是最早的一版,基本逻辑是这样的:
- 从公网模拟用户从互联网,进来负载到全网,做各种的相关的模拟。
- 在全国部署ForceBot,通过互联网模拟用户tcp连接的漫连接的信息。
- 直接到北京数据中心负载均衡,直接就会压公网的VIP、线上的系统。
- 注册、登录、搜索、浏览、购物车、结算以及支付,压的是京东的金融支付,不是微信支付,
- 只压自己的系统,看能不能扛住。
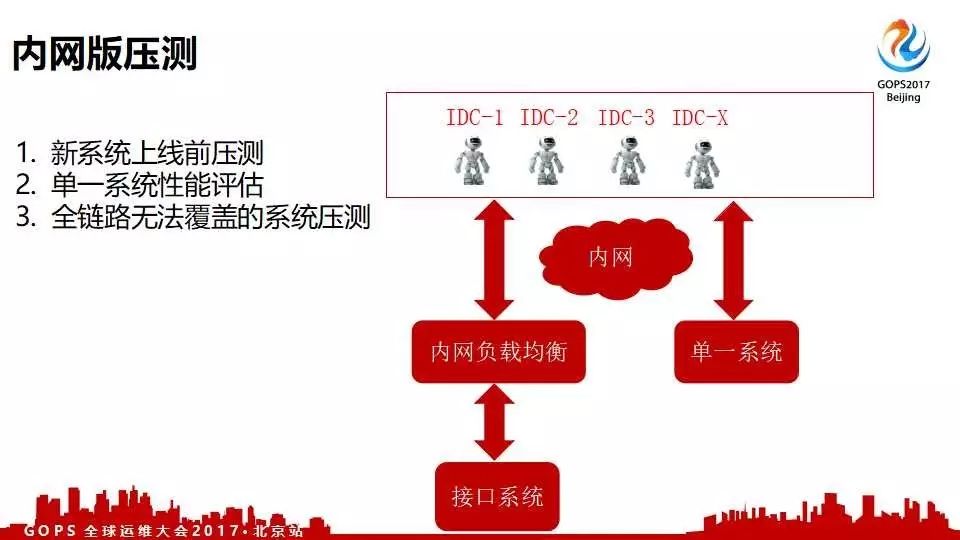
当然还有一些内网的需求,例如内网有一些接口不提供给公网的用户,但需要用统一的压测平台做全链路压测。所以在这个基础之上增加了一个内网版的压测,原理也是一样的。在IDC里面模拟服务内网之间的调用。
第一代全链路压测架构
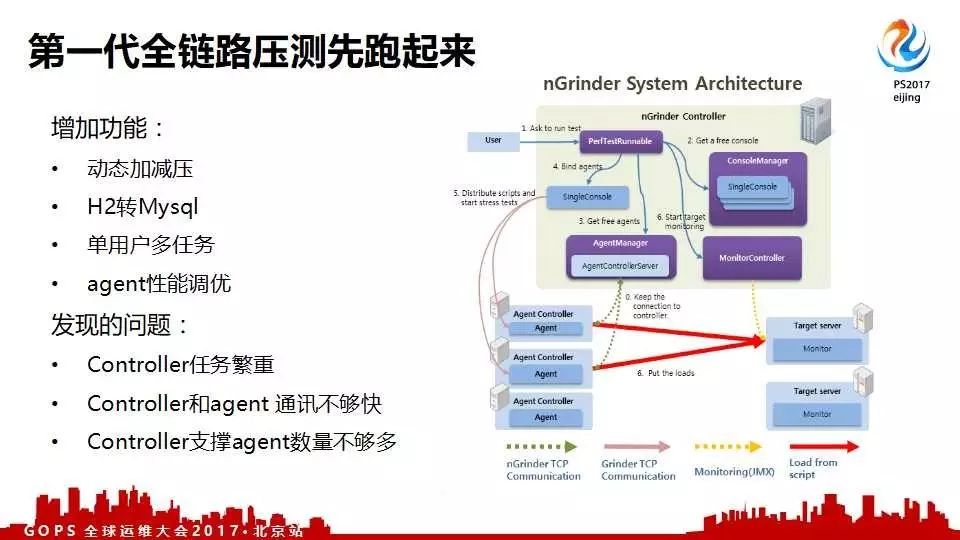
第一版版全链路压测架构图是使用的nGrinder,让全链路压测先跑起来。
之所以选择nGrinder,第一是脚本这块,第二就是它确实性能和各种功能也基本上比较完善。所以我们直接将nGrinder拿过来用,简单的把它的一些需要改动的地方二次开发,
例如增加动态加减压功能。各个压测团队对这个功能的诉求很强烈。我压一个50万的qps,但是服务器还能扛,CPU才使用50%。如果用现有的压测软件,需要把任务先停掉再重新启一个任务来看能不能压到它的瓶颈。
所以我们增加了一个动态加减压,就是当我流量达到10万的时候系统CPU和各种性能还比较OK,还想来点流量可以在平台上直接加50%的量。如果达到我们的预期了,想看一下掉量性能的时候,在平台上直接减到0就可以了。
nGrinder原生用的H2数据库,之前没有听过,调研之后发现H2是一个非常轻便数据库,对于内网小量压测没有问题。对于几千台压力机全链路压测它确实有问题。后来我们将数据库转到了mysql。
最后加的就是单用户多任务。nGrinder一个用户进去只能跑一个任务,这个任务跑完后才能跑第二个任务。有的场景需要两个任务一起跑,它原生的是无法支持的,所以这块我们实现了单用户可以跑N个任务,只要有压力资源可以随便跑。
还有就是agent性能调优,原生的性能有点问题,经过优化性能提升了30%左右。第一版的controller任务繁重,同时controller和agent通讯不够快,这是我们遇到的几个最大的问题。
ForceBot全新架构
去年下半年针对第一版的问题做了架构全面升级。主要分为以下七个方面:
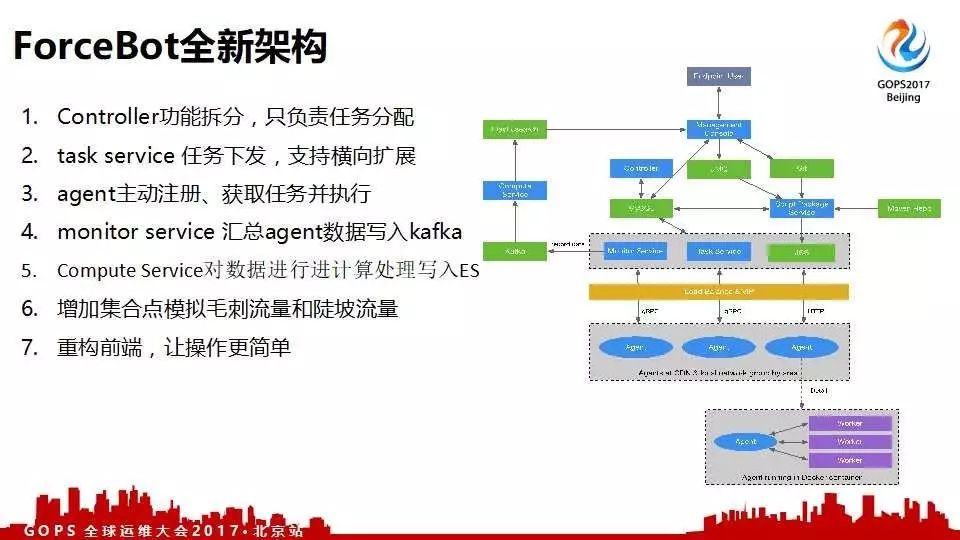
- 第一个方面,就是把controller功能拆分,只负责任务分配。
- 第二个方面,是我们自研了一个任务下发的组件,支持横向扩展,之前是controller负责的,现在将其拆出来单独做了一个控件。
- 第三个方面,是agent主动的注册获取任务并执行,原来是由controller主动下发任务。
- 第四个方面,就是监控,monitor service控件去汇总压力机的数据,例如压力机的qps、延迟、事务处理的成功与失败的数目。汇总完后写入kafka,kafka往数据库写,由平台去数据库查询数据展示动态的图。
- 第五个方面,写了一个控件将kafka里面的数据处理写入ES,有平台进行展示。
- 第六个方面,就是增加了一个模拟毛刺流量和陡坡流量,毛刺就是流量瞬时上升,几秒揪下来。这个功能对于京东来讲非常重要,例如0点大促的时候,基本所有的用户都把想要买的东西加入到购物车等到0点抢购导致大量的应用0点大促毛刺特别多,直接上去四五倍流量、几秒就下来。最关键需要考虑系统瞬时并发处理能力,所以这个毛刺功能就是模拟用户抢购的场景。
- 第七个方面,就是平台能实现的让平台实现,让前端更简单。
京东黄金链路全覆盖
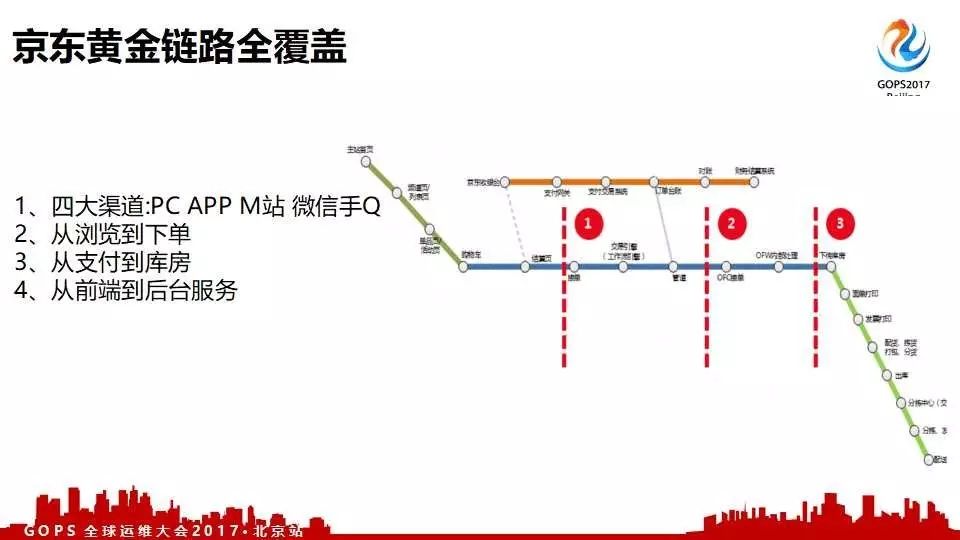
全链路压测目前已经覆盖京东所有的黄金链路。
首页进入京东的第一个就是进入首页。第二个就是搜索,列表页,只要跟用户看得见、直接相关的都属于黄金链路。第三个还有价格、促销等一些隐形的黄金链路。
目前我们已经覆盖了四大渠道,PC、APP、微信手Q还有M站等。四大渠道,从浏览到下单,从支付到库房,最后一个就是从前端到后台服务这些都核心链路都已经覆盖了。
压测流量识别
为啥要识别?
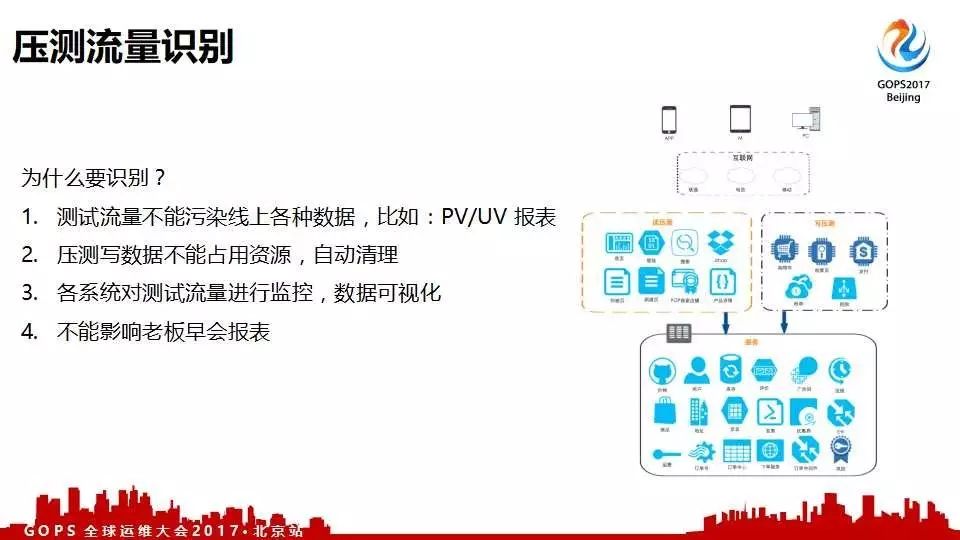
另一个大家很关心的就是模拟用户的行为直接压线上系统,这些系统压测流量要不要识别。答案是肯定的,肯定要识别这些测试流量,否则与线上区分不开,污染了线上的数据。原因有三:
第一,提交订单购物,可能每秒就能生产假的测试订单上百万,金额比较大,支付各种环节,第二天一出报表老板一开会发现昨天销售额怎么提升了一千万倍。
第二,压测量一分钟可能就是平时几十天的量。压测数据最终肯定要落库或者是缓存,所以每次军演压测完成后这些数据肯定要清理的,不能一直占资源。
第三,各个系统要识别出来各种流量是多少,军演的流量是多少,正常的流量是多少。让数据可视化,让研发的兄弟知道我们的压测量是多少。
最后一点就是不能影响老板宝贵的报表,不能为了做事而去做错的事情。
如何识别流量呢?
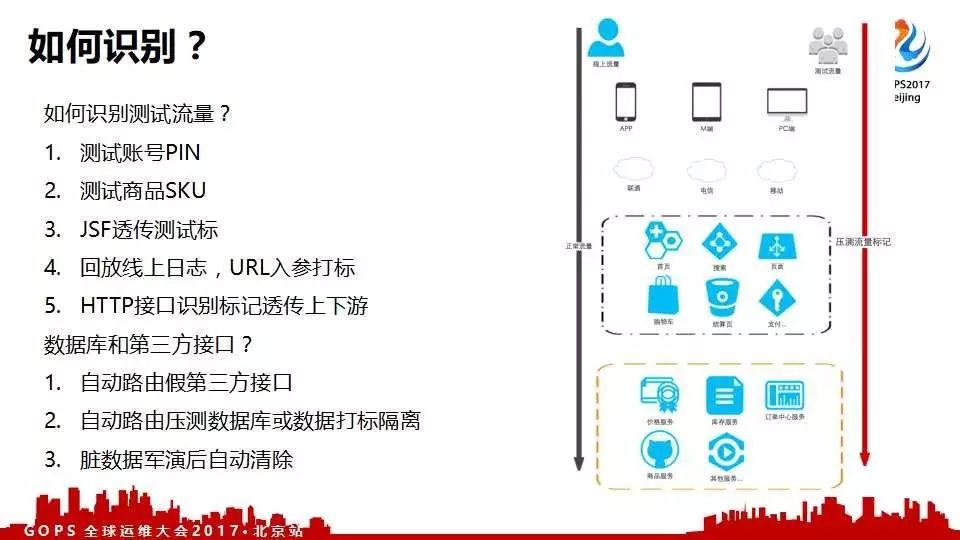
对测试账号有个特定的标记,下单以后看这个P就知道是一个测试的。当然这些测试账号肯定不能让真正的用户注册到,我们会将其锁定和其相关的也要锁定。
还有测试的SKU,针对商品下单,肯定要下测试的SKU不能下正式的。例如,库存有一百台苹果手机,几毫秒就抢光了,真正的用户怎么办?肯定要做测试的商品模拟下单。
另外就是通过中间键去透传测试标。每一个测试流量上都会打上这个标记是测试的请求,让所有的系统都要识别到。怎么打标呢?肯定要从最源头开始打标,后面的系统才会获取到。
针对读的压测问题
我们回访线上的日志,通过脚本回放,在UA里面入参打标。通过APP网关发送请求回放日志在UA中插入一个特有的标记,这个标记代表的就是全链路压测过来的流量。还有一个最主要的就是数据库和第三方的接口怎么办?数据库肯定最后要落库,第三方的接口依赖银行,银行肯定不配合。同时,假设开测试通道也没有任何意义,因为全链路压测毕竟是想知道京东自己的系统性能是多少。因此对于第三方接口自动识别到测试流量后,直接路由到假的第三方接口。
压测数据库和线上数据库隔离问题
目前线上在做的有三个方案:
第一个就是用测试的数据库。当然这个方案我们是不推荐的。如果线上数据库性能非常高,你又路由到你的测试数据库,最重压过来的流量导致测试数据库和线上数据库都有压力,同时也会造成很大的资源浪费。有些团队说我的数据库不是瓶颈,最大的瓶颈是系统,此时为了后期清理脏数据方便可以落到测试数据库中。
第二个就是在现有的数据库上建一张新表,这张表和线上的表结构是一模一样的。系统去识别流量,通过识别到的测试流量路由到测试表并写入。这个时候也有个问题,测试表里的数据和线上表里的数据肯定不是一一对应的,肯定比线上数据少。当真正大流量过来时,查询修改这些数据,对数据库来讲数据量不一样,它的性能肯定也是不一样的。当然如果数据量对于他们来讲是小意思,这个方案对他们来讲也是可以的。
第三个就是在现有的数据库的线上表里新增一个字段。当系统识别到这个测试流量,就在这个字段上加标记。这个方案其实是OK的。线上的数据库、线上的表又是线上的数据和线上一模一样,但是改动量非常大。
如何清理掉脏数据?
压测数据占用了太大的资源,在缓存里或数据库通过标记自动的清理,人工清理要累死的。这块目前京东没有做到平台化,还是由各个研发各自清理。只要告诉他们结束了,各种数据指标已经拿到了,大家就可以清理脏数据了。他们各自都有自动化脚本或其他清理工具,后期我们会一块融合到我们整个平台里和研发兄弟一起清理。因为这个风险极高,弄不好把线上数据库删了那就完了。
压测数据构造
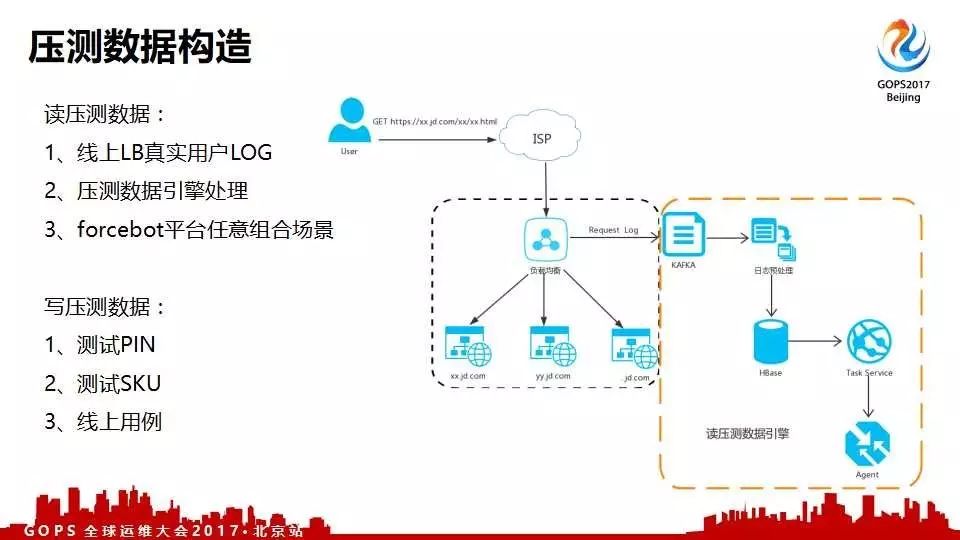
还有一个压测兄弟最关心的问题是压测数据怎么构造。京东的测试团队原来有几个渠道。第一个是我了解线上和所有的业务,我可以自己造数据。第二个,让研发的兄弟配合我,他提供压测数据,我写脚本。所有的流量进入的第一个系统就是负载均衡,因此负载均衡有线上所有系统的日志。将负载均衡日志进行处理分析并呈现。
第二个是针对写的压测数据。写的压测数据肯定不能那线上的,线上的都是真实的用户,不能帮他们下单和支付。只能靠手工构造,构造的内容就是测试SKU的线上用例。京东有个点击流系统,会记录每个用户进入京东先点哪后点哪,整个生命周期一步一步到哪,最后去哪都在这个系统中。通过点击流拿到用户的这些线,去写全链路压测的脚本,例如60%用户的用例是先去购物车了还是先去其他的。
如何有效的推动系统改造?

我们作为项目来讲,我们也不能去定义一个唯一的标准,涉及到的系统太多了,涉及的研发也非常多。例如,我定义一个怎么清,方案一,你必须这么清,但是有的人会调出来告诉呢这个方案不靠谱,人家要用方案二。所以我们会迎合研发的兄弟,他们觉得怎么靠谱就怎么来。
这也是为什么我们一直没有将清脏数据放到平台上来做的原因。我接这个项目的时候遇到最大的困难就是怎么推动系统改造。你不是刘老板,更不是李克强,人家肯定也不听你的。为了推动系统改造往前走,我是怎么做的呢?
先找他们老大。例如交易那边改造量是最大的,他们的老大之前工作的时候就很熟悉、经常合作。最开始找他聊,我们现在要搞一个全链路压测的项目,对你们团队来说意义是非常重大的。给他讲现在怎么做的压测、痛点在哪里。咱们一起拯救所有的压测团队和研发的兄弟。由于涉及到系统的改造风险特别高,尤其是涉及到交易这块。测试的流量没有识别到,当线上生产了。线上直接扣款到库房以后就真的生产了。
第一个,先跟各个研发团队的老大聊,先把老大说动了。老大觉得支持这个事情再安排具体的人。调动他们团队的研发一起开会,指定一个统一的标准。全链路压测要实现哪一步,怎么识别、怎么打标。
第二个才是跟各个老大们混好关系,并让他们指定接口人。这个接口人非常重要,肯定要有技术能力。如果随便定一个,一开会,什么事都说回去问问架构师怎么做,这是很坑的。
第三点就是要自上往下推。如果要从一个工程师到部门主管到经理,网上一步一步汇报,那时间会拖很长的。例如,和工程师讲改造一个接口要识别,工程师的回答是周会他会提一下,这样一来经理知道了,认为有风险得汇报一下。接口还没有动过,已经一两周过去了,很耽误工夫。
第四点就是所有接口人每周开一次项目周会,让项目经理跟进所有的进度。例如,去年做改版的时候涉及到的研发兄弟跟接口人有六百多人。如何让这六百多人能够重视起来?这时项目经理督促各个相关联系统的研发推进进度就至关重要了。
第五个就是有问题例会拍板解决,别墨迹。比如去年开会的时候,为了传一个标的事情不知道怎么两个部门的人就呛起来了。当时我就直接拍一个方案就可以了,只要考虑能实现、靠谱就行。有些事情需要快刀斩乱麻,该决断的时候就要当机立断,不作出决定会延误整个项目。
如何压测
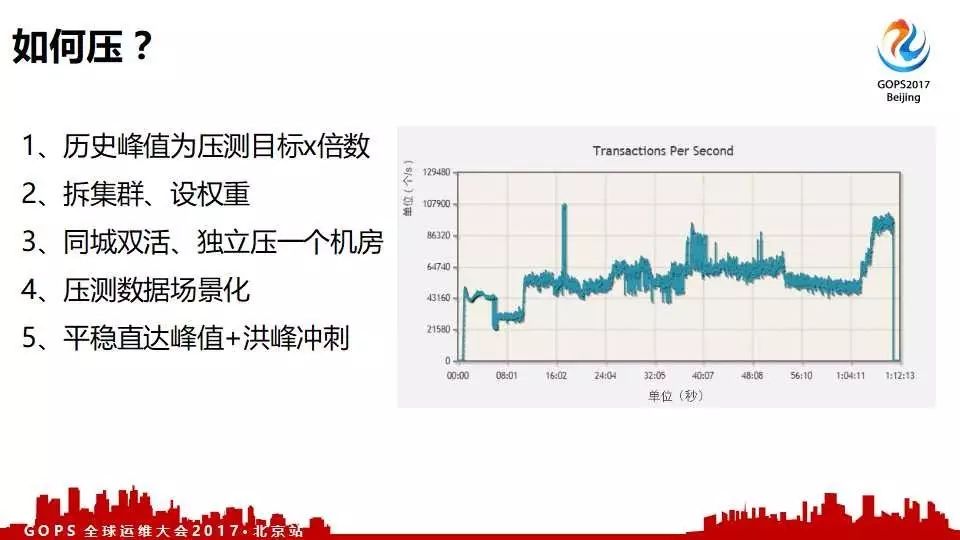
下面给大家介绍一下我们怎么去压的,到底是压一千万还是一百万,我们定了一个标准。我们以历史峰值为准,乘以N倍。例如,我们历史上618所有系统的峰值是多少,那么今年双11要怎么压,乘以三倍。
第二个是我的系统不是很重要,但又是黄金链路系统的接口服务,所以就用到了第二个拆集群、设权重。保障你的集群没有真正的用户流量,或者有少量的用户流量配合全链路压测。
第三个就是京东商城现在所有的核心业务都已经实现了同城双活、异地多活也正在做。每次军演全链路压测之前都会将一个IDC的流量切到另外一个IDC,把机房腾空去做全链路压测,所有的压力计都往这一个机房压。
第四个就是压测数据场景化。例如,一个是日常场景、一个是大促场景。日常场景流量都是平稳的,只要达到平稳的并发量qps就可以了。大促场景就是毛刺。大促基本上都是提前选好想要买的商品,零点促销,大家零点的时候就狂点,流量就五倍十倍的翻。
ForceBot的挑战与未来

目前CDN团队给了我们大概一千台物理机。京东的流量在不断的上涨,下次可能就需要五千台物理机了,所以我们要拿现有的资源去优化。一千台机器是不是可以模拟出两千台物理机的性能,这是我们接下来需要深入研究做的事情。
第二个就是覆盖京东所有场景的压测,做自动化。因为现在有些人工参与的,例如,构造一些压测的数据等等。我们要把它做的更自动化一些。
第三个就是压测日常化。因为现在搞军演压测都是放到后半夜的,同时需要有人看着的。希望对日常的压测做到无人值守,压完以后自动的出报表。如果压到某个系统有问题,系统自动停止压测或者报警。
第四个就是根据历史的全链路压测数据就能自动计算出系统要扛多大量,需要多少资源。还有就是日常压的时候由于服务器性能不足导致压力上不去,我们就能联动docker系统自动的去扩容系统。这样就不用拿着压测报告申请资源了,每周压一次,然后出整个京东所有的核心链路的系统压测报告。
