@gaoxiaoyunwei2017
2018-12-10T10:06:33.000000Z
字数 11328
阅读 1355
中小金融企业如何开心玩DevOps
白凡
分享:李晓璐
编辑:白凡
讲师介绍:大家下午好,我叫李晓璐,我是广州证券的IT架构师。
在分享之前呢,我们先把分享的题目稍微改一下,把玩转去掉,叫开心玩DevOps。因为DevOps内容广而大,刚才有的同学会说精益、敏捷DevOps是什么关系,上次我看到一张图,说DevOps的工具非常多,有上百种,那理念和方法就更多的。
比如说精益啊,敏捷啊,然后持续地改进啊,它可以说是一种文化或信仰,所以玩转DevOps是很难的事情,我们只要开心地玩一下就好了。另一方面我们在公司内部实践这个,DevOps的过程我们本身是抱着玩玩看的心度,就是玩技术,然后通过大家的努力持续改进DevOps的过程和内容。
言归正传,我们分享三部分,这三个部分是我们在实践DevOps这一个过程中的经历的三个阶段:
1. 从0构建运维平台 —— 先解决温饱问题
首先第一个阶段是我们花了6到10个月的时间搭建了集中的运维平台,那接着呢,运维平台出来了,然后会有一些精细化的需求出来了,这样我们需要自己动手做一些开发,我们基于自己的开发框架,做了运维相关的内容,甚至说跟运维没有关系的一些系统,已经不跟运维不再相关的系统了。
1.1 构建背景
目前呢,我们搭建了DevOps持续的集成和持续交付这样一个系统。整个的过程中呢,我会跟大家分享我们自己的一些心得体会和经验,希望分享和过程中也会讲技术细节,希望给大家带来干货,也会讲经验和方法。进入主题之前,这有两个原则性的东西要说明一下,后面所有的内容都是围绕这两个原则开展的,脱离了这两个原则,后面我们一些经验和方法是不合适的。
第一个原则是适当性,这一个适当性在证券行业是通用流行的词语,它说明了一个投资者进行投资的时候呢,金融单位它是要有这一个义务和责任告诉投资人,根据你的历史投资的背景,投资的习惯,包括你现在都有哪些资本、资金,然后你对风险的程度做评估,你适合做哪些金融产品的买入。
同样这一个道理非常适合IT企业。刚才有一些同学会讲,刚才提了一个问题,说领导认为这一个DevOps对没有做好怎么做OPS,其实我有一些地方我认同,首先我们应该首先要要看清我们自己到底具有哪些资源和成熟度,然后做下面的事情,否则的话,如果我们看得特别远,但是我们资源资金不够,做这些事情可望不可及,往往收到的效果不好。
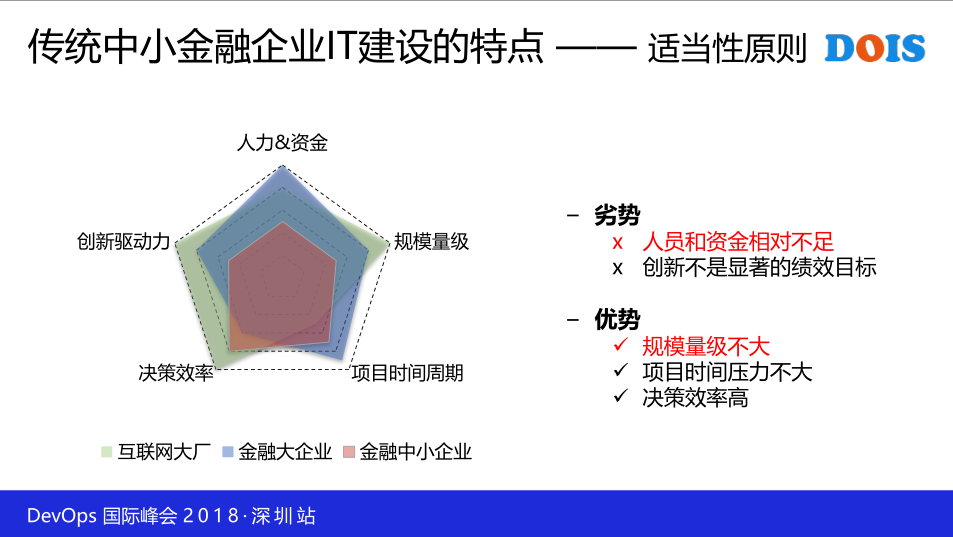
这里有五个原则,我本人加入广州证券,去年加入的,之前一些大的公司,比如说华为,特别大的公司,对这一些公司都相对来讲有了解吧,我分了五个维度,参照物是互联网大厂,还与大企业,还有我们看了一些大企业作为参照物,分五个维度:
第一维度是人力和资金。在这样的维度金融大企业它的优势明显,我做过一些对比,同样的一个方案呢,其实金融大企业它的资源是我们中小企业资源的五到十倍之多,所以他们有资金和资源做这样的事情。那么对于互联网大厂相对来讲少一点,反而会少一点,因为他会投入人去做,而不会投入更多的钱做这样的事情。对于我们中小企业相对来讲很小,我们人员的比重都非常少。这一个呢,是我们要认清的本质,所以基于这个劣势,我们后面要做DevOps也好,做其他的系统也好,要看到我们有哪些东西。第二是规模量级,很显然互联网的规模量级很大,他动辄是十几多万、几十万管理的系统和这种规模和量,交易的并发量也是很大。其次是金融大企业,那么对于我们金融的中小企业来说呢,这一个规模就小很多,我们可能是互联网企业的几十分之一这样的程度,这反而是我们的优势,所以我们要看到优势和劣势的所在。规模量级不大,这就意味着我们做某些事情的时候反而容易成功。举个例子,我之前在一个深圳坂田的大企业里头,当时我们做运维平台的时候,考虑最多的,最让我困扰的是什么事情,就是说性能。因为管理的机器都是几万个,甚至十几万这样一个规模,很多时候要考虑和解决的问题是何性能方面,对于现在中小企业来说,这一个不成问题,反而能实现,工具拿来就可以用,对于项目周期来讲,金融大企业它的项目周期是很长的,往往是一年、两年的时间给你做这样的事情。那么互联网企业呢,它的时间要求比较高,所以互联网公司经常加班到深夜。然后决策效率这一块说一下,决策效率这一块互联网大厂效益毋庸置疑是非常高的。举个例子我有一个朋友去了阿里巴巴,刚去的时候他不适应。有一回他给团队的发了一个邮件,说要实现什么功能,两天了以后同事没有反馈,他忍不住了,跑到同事的座位上说我前两天给你发邮件,这一个后续怎么处理。这一个同事很诧异地看他,因为他们文化不一样,说这一个东西我已经编码实现了,今天已经上线了。所以这是互联网的效率,它是完全不一样。
- 另外是创新的驱动力,创新驱动力的话,很明显,互联网大厂有这一种考核,他希望公司引领技术的发展,这一些呢,就是我列举出来的,传统中小企业金融企业建设的特别,我们要认识优势,然后做这一些事情,有了这一个前提呢,就是企业的特别决定思维方式,这样的原则是我们要用工具化的建设思路,那工具化和工程化的区别呢,工具化不是我们搞很多开源的工具,形成这样一个数据,然后我们是希望保持工具的这一个原生态和纯粹性,这一点很重要。就是说我们不要轻易修改工具的某些特点,而是用一些黏合剂把这一些工具串联起来,然后形成一个一个的平台。
- 然后工程化的思维方式,就是说我可以从零开始,因为我有费用和人力,我有资源,我可以根据我自己企业内部的需要从零开始创造这样一个工具,甚至我可以让某一些厂家按照我的需求打造这样一个平台出来,这是工程化的思维方式。工具呢,它的特点是拿来主义,我们不要自己造轮子,因为发现了想要的工具有很多,你选一个合适自己的,当然这不是选最好的,最好的是最贵的,你选自己合适的就可以,最后是注意偶合性的设计。不要轻易地修改源码。然后克服满足太多个性化的需求。要尽量适应这一些工具。其实这里有一点啊,我个人理解吧,好的一些工具呢,它本身都是很多经验方法的一种沉淀,就是说它是前人总结出来的,是实际需求落地下来的。就是说你没有按照自己的思路去扭转它,你要去适应它,适应中你会发现它有道理,这样节约了时间。对于工程化的思维方式呢,我们一般的做法是找一些特别靠谱的厂家,对于金融大企业来讲,很多人会找一些靠谱的厂商帮助我们成长,这是关键点。另外互联网大公司会招聘很多技术大牛实现这样一个目标,它的优势特别明显,长期来看的话,很容易达到比较高的满意度。那么劣势也很明显,就是他的总体人员的费用和成本是比较高的。就是刚才汇丰银行也好,民生银行也好,他们的题量够我们做好多年的项目。那么我们简单来说的话,对于工具化的设计方式就是找好的工具,利用八二原则,投入20%的精力收获80%的结果。对于工程化的思维方式呢,我们找一个好厂商,实现打90分,或者95分,或者是更高的一些分数。
那我是去年加入广州证券的,刚到公司的时候花了三个星期的时间,做了一些访谈,就像我之前跟招商做访谈一样,然后做调研的分析。我们发现不管是大厂还是小厂,他们对整个运维的期望是在监控这一层面,即使是深圳比较大的,名字我不说了,它让我很诧异,说你不要想做自动化,怎么想着做一个自愈,或者是DevOps这一块,你想如何有故障的时候尽快的暴露出来,监控就是这样一个需求。
1.2 一体化监控平台构建
当时我们公司监控是这样的,有几个彼此独立的小工具,比如说机房监控,机房监控是买了一些机房的设计,他送了一些监控。然后对于其他的一些系统来说,它是非常简单的,比如说IP啊,端口的这种啊,然后看存在不存在,根据这一些信息,那么参数的调整呢,也是非常麻烦的,改一个参数的话,你要硬编码,对于这一个监控策略呢,因为比较简单,经常会造成误报,数据的整合就更不用说了。大家感到就是凑合着用,系统可有可无的状态。所以我们着重解决这样的问题。

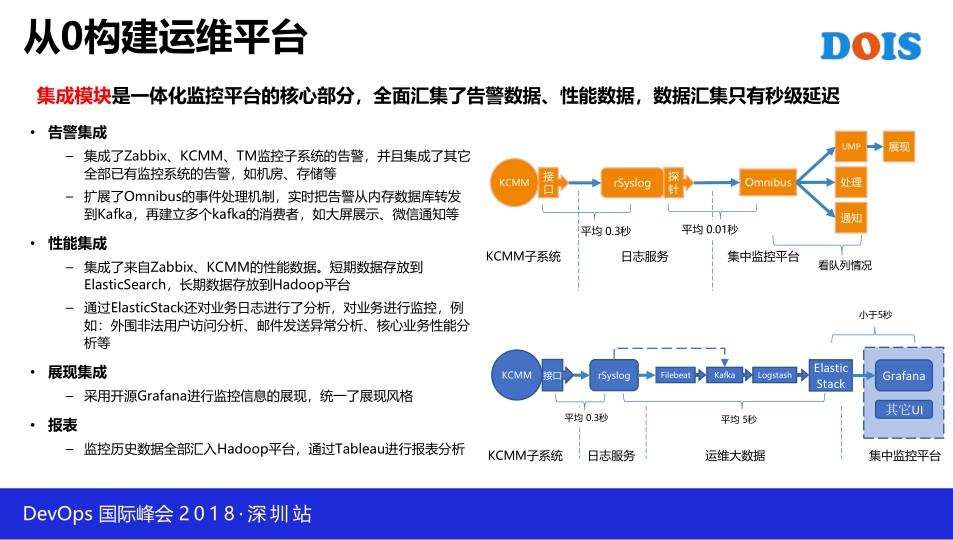
建了一个一体化的监控平台,这一个平台我们新做了三个系统,其中Zabbix是我们自己开发的,然后KCMM这一个核心业务系统监控是我们采用第三方的一个工具,至于为什么要用KCMM待会儿会讲一下,另外我们通过抓包分析做了交易性能的分析,目前是涵盖了我们所有的基础设计以及基础架构里头的操作系统啊,中间件啊,然后日志啊,包括我们现在做一些偏业务的东西,就是已经不再是中下层的内容了,也是往上做偏业务的东西。那么对于这一个一体化的监控平台呢,集成模块是最核心的部分。那么这一个集成模块分成了几类,我们把所有的告警信息,不管是自己在项目中新建的,还是以前子系统的告警信息全部集成到一起,那么这一个告警集成,因为我们对告警的性能要求实际上要求非常高,这一个平均下来能达到0.5秒这样一个时间,就是把所有的告警信息收集起来。

然后是性能整合,性能整合后面还有一些小故事。我们把所有来自于开放平台和非开放的平台数据全部汇总,汇总到Zaddex还有后面说的这一个平台。然后再进行展示。然后报表也做了一个集中的报表系统,应该说报表这一块应该不是说做,不是做了一个,是利用已有的一个报表分析的系统,那这一边的话,特别是说一下KCMM集成模块。那么KCMM模块集成模块是这样,它本身是一个精致的工具,为什么要引用这一块呢,这是因为我们券商有遗留的系统,那遗留的系统它不是BS架构,是CS架构,所以它的运行状态是对外没有接口的,不会暴露出来,比如说我要看到系统的运行状态的话,他是一个CS的客户端,然后你一点,它从绿色的小箭头就变成了一个暂停符。然后这个窗口下面会滚动着一些信息,然后有不同的颜色。那这种你是没有办法通过第三方接口拿到信息,只有厂家有,我们跟厂家协调沟通,他们把这一个接口专门为我们开放,而且我们认为这个接口的开放是通用的,我们不会担心这个厂家把接口封闭住。因为一旦开放了,就形成了统一的版本。
这是我们监控平台的技术架构,目前说分四部分,第一部分所有开发平台的话,我们都会用Zabbix UI去做。为什么选择Zabbix后面会有一些介绍,这里头我们会把网络的监控,然后机房设施的监控,然后系统的应用等等系列,反正开放平台的东西,全部用Zaddix去做了一个统一的监控,包括一些业务的应用,只要是开放平台的。那么对于这一个核心业务监控,我们是集成了KCMM系统,KCMM是非常重要的监控核心交易的,比如说集中交易啊,柜台啊,这一些只能用KCMM去做,就是传统遗留的一些系统。
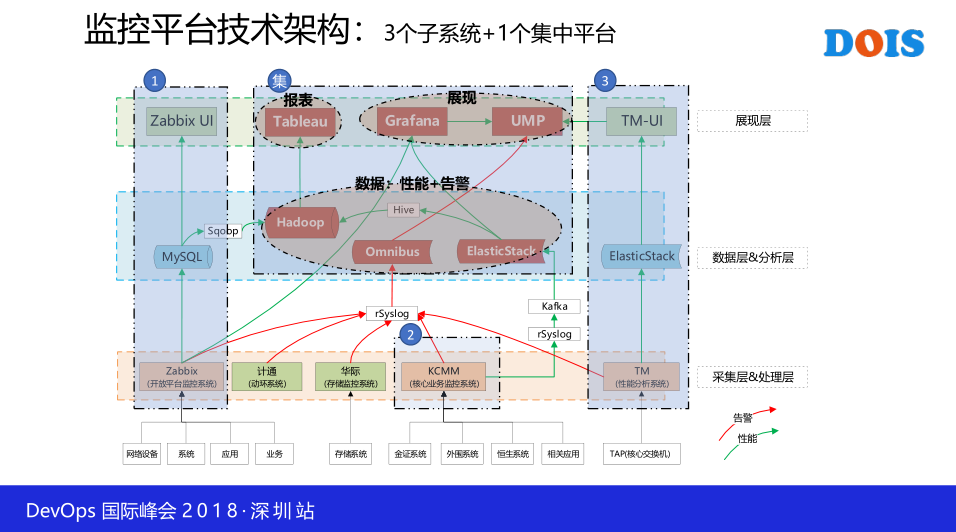
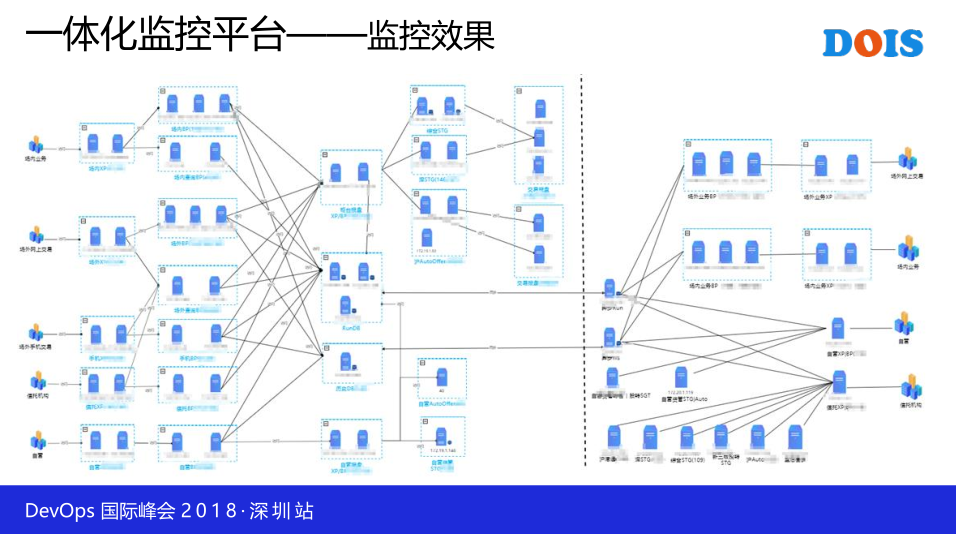
另外这是通过抓包分析拿到的数据,这不是对我们特别关键的。最重要的集中监控平台,这里汇聚了所有的告警信息,性能数据,以后还会绘制配置信息,短期的数据呢,我们会把它放到ElasticStack这一个站,它会存放一个月这样的一个数据量,然后长期的数据呢,我们会把它入库到Hadoop这一个系统。那到Hadoop呢,大概是一个这样一个数据的汇集,也就是说今天的数据在晚上凌晨就会把数据导进去。然后所有的告警信息通过Omnibus进行汇聚,然后通过TM-UI进行呈现。
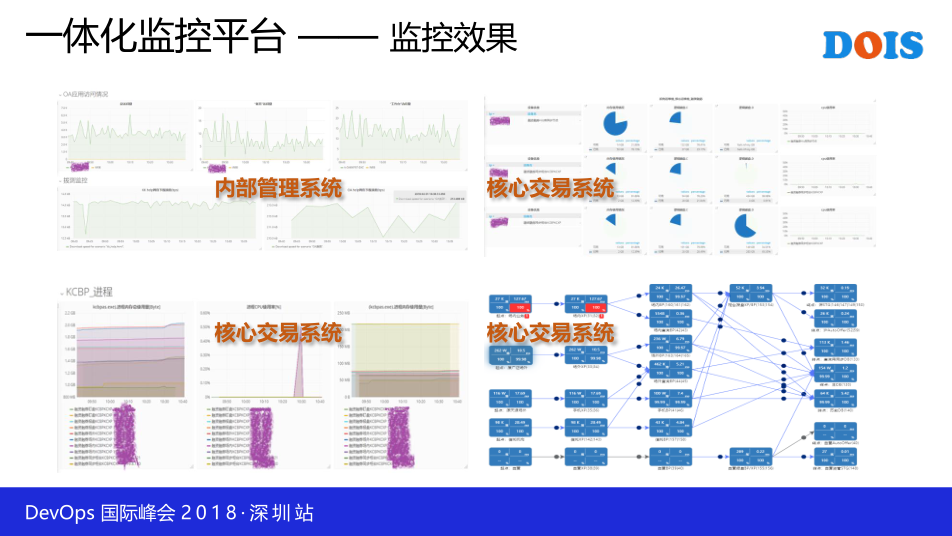
Grafana是负责所有性能数据的查看,UMP是我们厂家开发了一个统一的平台,把所有监控的监控界面的工具全部整合在一起。这是我们一体化监控平台的效果图,包括我们CMM系统,BA系统,OA啊,包括一些核心交易。像核心交易的性能数据以前是完全没的,包括这一些TOP,这个是通过抓包分析的拿到一些TOP信息。这是整个监控平台,统一的一个Platform,不管是从哪里来的数据源呢,我们都在一个统一的平台呈现。这是我们做的一个东西,当你的告警发生了以后,我们会根据优先级,然后自动条到告警所对应的业务TOP上面去,能够让我们快速诊断判断这个问题的发生。
1.3 谈谈工具的选择
还是坚持之前说的那两个原则,我们不去修改,我们只做黏合剂这样一个功能,另外也考虑到各种工具间的关联关系,要把它串起来,这一些工具不是孤立的,一定要串联起来。
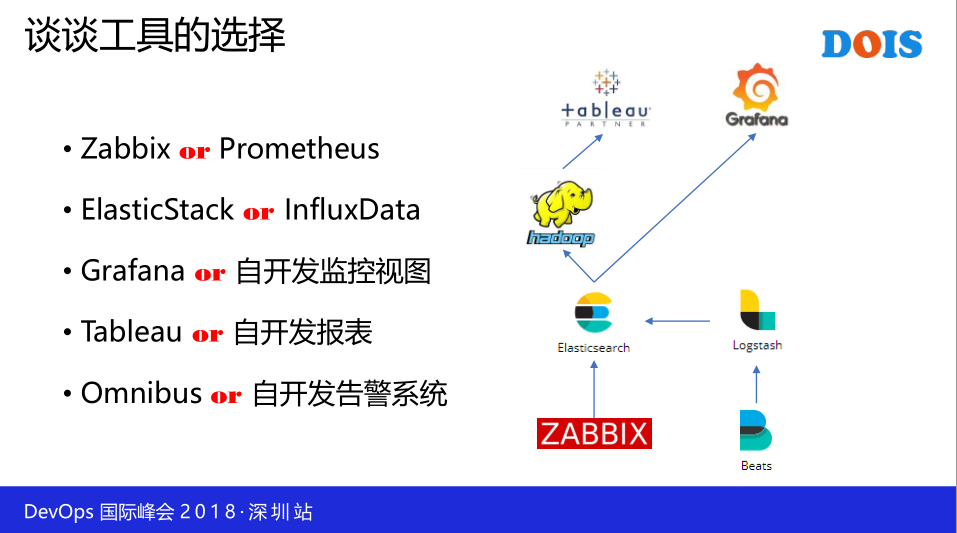
所以像开放平台的监控,我们当时考虑了很多种,可能Prometheus是一种,然后Zabbix是一种,还有其他的,甚至说其他的技术栈我们也去考虑是一下,最后在Zabbix和 Prometheus之间选择了Zabbix。
并不是说: Prometheus他的技术比较差,其实 Prometheus的技术我个人认为是要比Zabbix要好的,但是 Prometheus是有一个缺点,这一个缺点是我们觉得比较麻烦的,就是它的监控策略的定义是以APR的形式提供出来的,它没有很好的界面,所以我们不会根据APR去做监控策略地界面,基于这个理由呢,我们就选择了这一个Zabbix对于持续数据呢,也有很多选择,比如说Omnibus。
然后ElasticStack这块,还包括InfluxData这一块,最后选择了 ElasticStack,原因是InfluxData非常不错,但是他收费,它高可用的这一个下面收费,所以没有办法,这是这一些厂家逼的,就是说我们选择了这一个ElasticStack。
那么Grafana这个呢,我们天生地对比了一下,就是摒弃了自开发的监控试图为主,以Grafana为主,因为Grafana它对接的数据源是非常丰富的,因为它的灵活性也是足够高。那Grafana做不到的一些视图呢,我们通过Prometheus或者是我们自己开发,后面会讲到一些开发框架,我们自己开发一些作为一个补充。但是主要还是以Grafana为主。它的灵活性也是非常高,Grafana呢,我们会开发一些作为一个补充,但是主要还是以Grafana为主。
然后这一块,其实我们也做了一些报表,就是自己手工开发,大概做了两个月,我们发现一个效果是非常不好的,所以大概两个月的时间我把这一个卡掉了,就是说我们不做这一块了。我们用Tableau,因为Tableau是我们公司已经买了这样一个工具,有好的工具为什么不用呢,那Tableau大概花了一个月的时间,所有的报表就出来了,非常的方便,拖拉拽就可以完成。
Omnibus 和自开发系统,这一个不用讲的,Omnibus有很多的金融单位都会用,反正在未来的两到三年内,我还找不到任何的开源和商业能够替换Omnibus,其实也没有什么理由。
另外呢,还要主要串联,就是我们找这一些模块,他们之间是有关联关系的。比如说为了把数据通过Tabloau作为开发报表,把ElasticStack设置的数据呢,就推报这一个Tabloau平台中去,结果发现这一条路是对的。
1.4 有几个问题可能需要探讨
第一个问题是我们是否值得开发一个统一监控策略定义的界面,对于我们中小企业来说,我们觉得没有必要,为什么这样说呢,首先有一些监控系统是封闭的,他没有任何接口,你没有办法对它进行拓展开发。当这一些没有办法进行二次开发系统出现的时候,你整个要做集中的监控策略管理的梦想会成为泡影。另外一个,究竟谁会经常使用这一些监控测量。大的部门会经常调整,但是对于中小企业来讲,他的工作重点不是这些,而且有一些东西定下来了以后呢,一开始可能不太稳定,但是后来定下来了以后,他就不太会调整了,所以也没有必要去做,这是我们得出来的经验。
通知管理这一块不讲了,事实证明微信是一种更好的方式,他的时效性和表达能力是远远强与短信和邮件的。这一块我们也做了开发。
最后一点是非常重要,重视推广,不给是DevOps平台也好,监控平台也好,任何一个系统出来了以后,新的东西呢,或者或多都会受到内部的一些抗拒,这时候我们应该花更多的时间推广,就是所谓的内部运营,那么在推广这一个监控平台的时候呢,我们甚至走到很多团队座位旁边,坐下来问他。就是这一个平台用得怎么样,哪些功能模块觉得用得不舒服,是不是需要修改,要改哪里,这就需要男生女生谈恋爱一样,就是男生跟女生说,我哪里不好,你告诉我,我改。女生说,这里不好,那里不好,我改就好了。最后改的东西呢,大家是满意的。其实我们分析的一下,其实这种就是DevOps的思路,就是持续改进的思路,而且我们更加彻底,我们不是说拿到需求,我们是走到使用者跟前问需求。另外一个,我们永远会做一些前景,就是我们会做更多的功能,会想在使用者的前面,比如说我们发布一个版本,其实新的版本,一些新功能大家关注都已经有了,就等待第二次发布,就是永远走在大家的前面,这样才能够敏捷起来,才能够被大家所喜欢。

2. 基于微服务的运维开发框架 —— 满足精细化要求
前面温饱问题解决了,系统故障发现了,精细化的需求就提出来了,我们做这一些事情呢,不是为了做事情而做事情,不是为了做DevOps而做DevOps,不是这样的。也不是为了做开发框架而做一个开发框架,都是有实际需求和要求的。这是我们跟大的企业不同的地方之一,大的企业呢,我为了引领,或者是为了树立标杆,我可以没有需求,但是我为了做一个榜样,我可以做这样一个东西出来,我们还有很多的事情要做。这是我们一个出发点,做一个开发框架出发点。大家提到个性化需求,围绕厂商提供的框架,因为厂商的系统有框架,去实现有问题。另外一个我们会想到,假如说厂家撤了以后,那需求提出来怎么办,无非是这几个方式,你给厂商交钱,厂商给你做。
还有一种自己实现。肯定我们要自己去实现,我们有一个功能给厂商一提,厂商说这一个功能50万,你做不做。肯定是要做,是吧。你不做谁给你做,没有给你做。另外一个我们有一个前提,所有的数据都已经汇聚了,信息汇聚了,怎么样玩这一些数据,使用数据,我们是完全可以把控的,基于这一些前提呢,我们就做了这样一个开发框架出来,当然了,内部的技术沉淀也是我们考虑的一个因素。这一个框架给大家简单介绍一下。
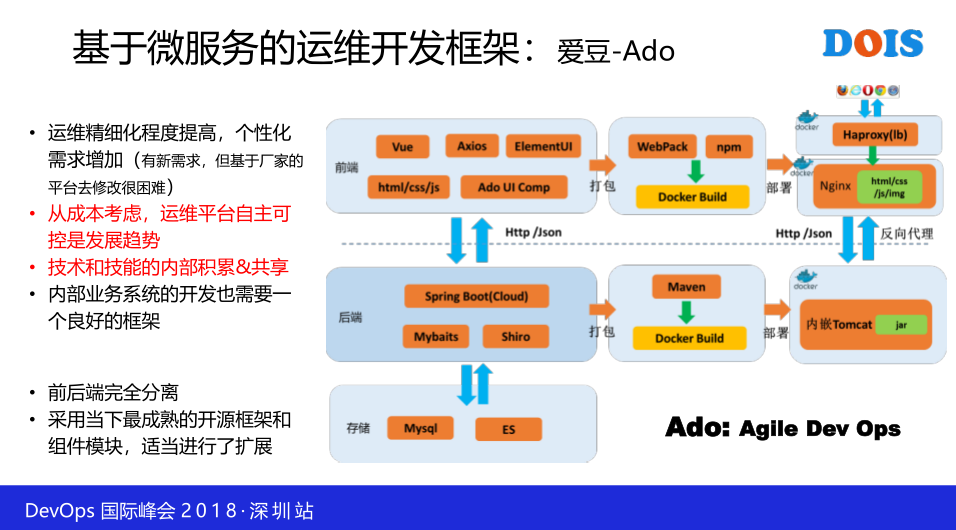
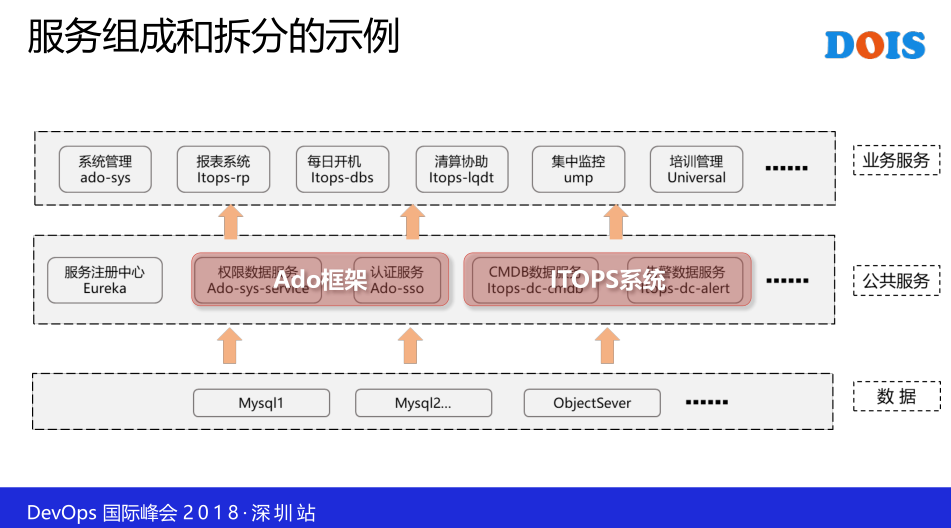
它前后端完全分离的框架设计,一开始的话,我们要做一个东西不要落后,要有先进的理念。前端我是通过Vue,然后出发后端Spring的需求,前端是通过容器进行布署的,在一开始我们就这么去定义了,就是不走弯路,就是一开始我们定义自己开发的所有的东西都用容器化进行部署,后端是用Spring,做了一些权限的管理,然后做了一些服务的注册和发现,同时也是用容器进行布署,整个框架我们起了一个名字叫Ado框架,是DevOps这样一个框架。
这里举个例子,我们利用这一个开发框架做了一些系统,最上面的一层使用这个框架做的小的子系统,比如说这一个大屏展示,名字起得不好,就是这样的风格,其实是一个大屏展示的系统。然后每日开关机,这一个券商是非常熟悉的,他们每天都会开市闭市,开市闭市呢,之前是用比较土的一种方法,就是大家会打印出大概五页的东西,每一个人打印的东西不一样,然后做完开市系统检查之后检查打一个勾,然后把打印出来的东西签一个字。
我们看起来是非常老旧的方式。然后第一个用这个开发框架做出来一个系统,就是每日开机一个系统,就是通过电子化实现,然后方便于做统计分析,也极大地提高了效率。应付审计的时候就不再把那些材料翻出来,而是系统导出数据据就可以,还有辅助的系统,还有非运维相关的系统,因为这都是有需求的,我们自己内部的一个培训管理不太好用,不太好用的原因是交付完了以后撤了,过了一两年如果没有花很多钱的情况下,它不会对漏洞进行修复所以我们做了一个系统,大概几天就做出来了。包括我们把它放在阿里云上去了,包括签到都很方便。
中间这一块是做系统的过程中我们归纳出来一些服务,比如说权限、认证,还有告警这一些服务,其中认证服务呢,我们其实这样一个认证服务公共开发的方式,他的方式是很复杂的,我们需要导入一个价包,做大量的配置信息,这一个非常的不方便,所以基于这种情况下,我们自己开发了一个服务,就是专门提供统一认证的服务。
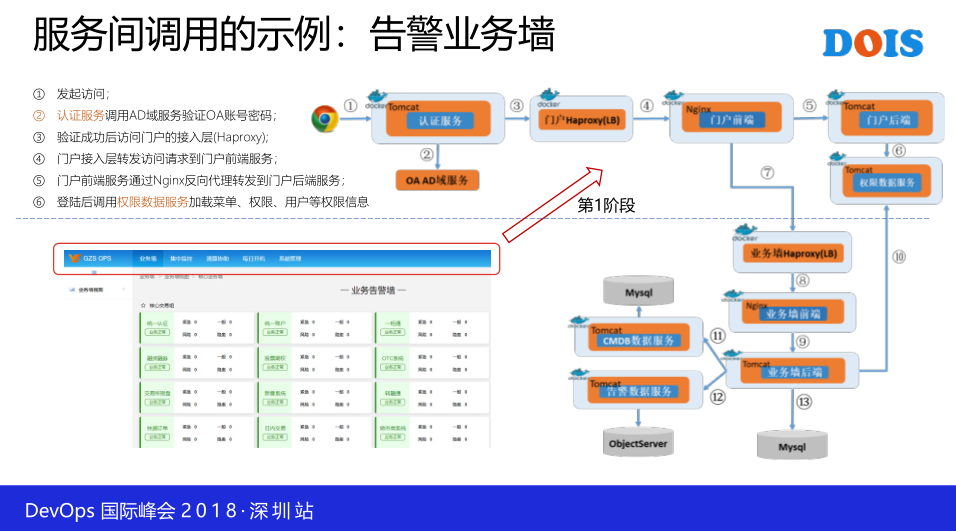
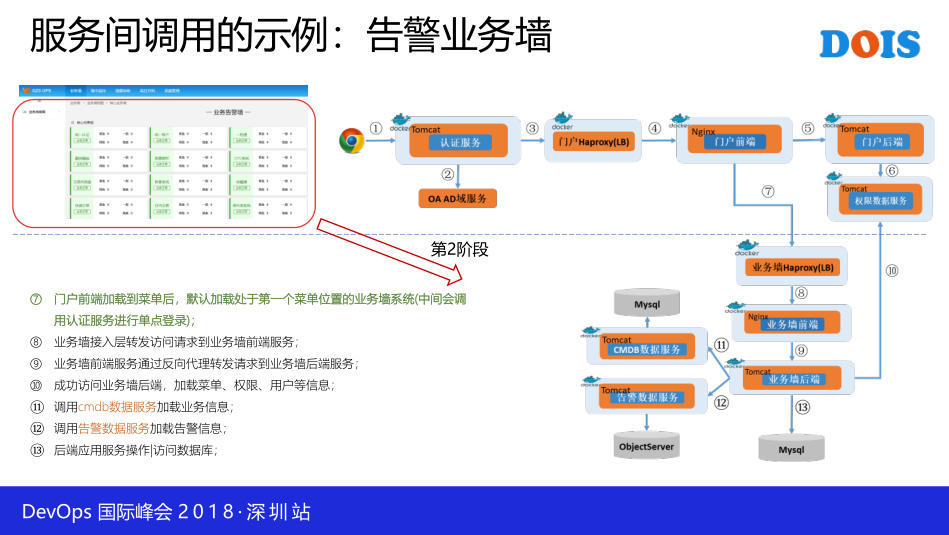
这一个呢,这是给大家说一下这一个事例,同时公共的服务我们自己的框架也用,比如说Ado框架也用了这两个服务,然后也用了这两个服务。这一个详细展开了,这是我们框架的调用关系,所要强调是整个所有的模块都是容器化进行布署,然后一个系统其实是分了三个容器,所以至少有三个,他可以是更多个,最前端是一个负债均衡的示例。所有的请求先发到HAproxy,然后再到前端,前端是Nginx,然后后端是潜入Tomcat的一个呈现,所以至少有三个。最上面是整个框架这一块,然后对于框架下面某个具体应用的话,同样是有三个,这样的话,当你开发出来的业务,你发现用户量大的时候,你可以敲一个命令,通过UI点一下,你可以对外部端进行一个横向弹性伸缩,就是非常方便。
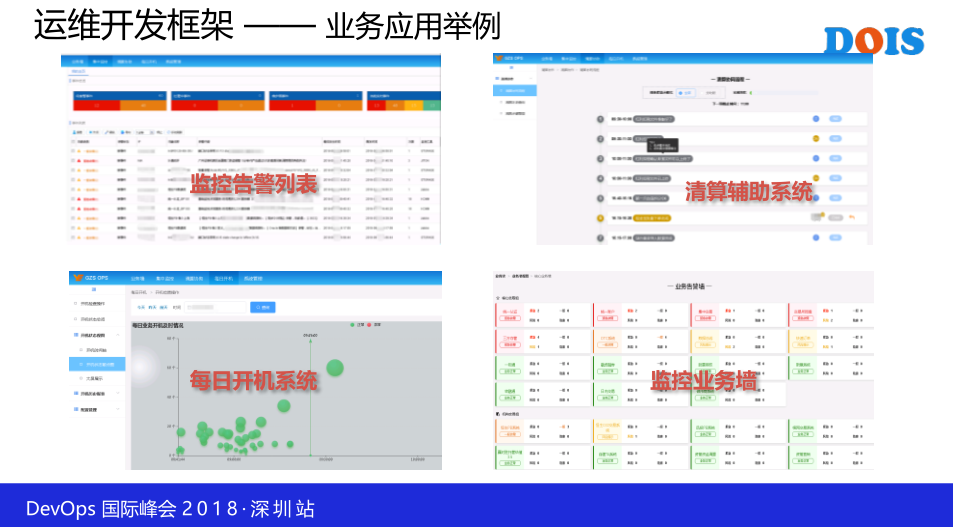
这是我们基于这个框架开发出来应用的居于,这一个告警啊,业务墙,其实不止这一些。对于这一个开发框架给大家一些建议,一开始不要追求开发框架的完美,就是说合适的才是正确的。还是一开始我讲的那一点,要适当,就是说不要看到现在什么东西最火、最牛你就冲上去,要合适的,要适当的。比如说开发框架我们想过开发平台,所谓的拖拉拽,就像南京平台一样拖拉拽,形成这样一个开发出来的东西,但是实际上我们没有能力去做的,不是说我们没有这个技术能力,我们没有人和资源。
举个例子,深圳有两个非常大的企业,他做的开发平台他会花至少200人以上的开发团队,花三年的时间,大概投入几千万这种投入,他才做出一个东西,我们是没有必要。对于中小金融企业没有必要。你花50万买一个可视化开发平台就可以。然后要尽快地迭代,我们框架刚才看到这一个技术站了,我们中间迭代很多次,因为一开始考虑模块化的设计,虽然有有一些模块迭代变化了,但是我们还是比较快,其他的重视培训这一些不讲了。
3. DevOps持续集成 —— 走向开发&运维
第二阶段我们自己做了很多开发。然后这样会自然而然我们需要提高开发的效率。这一个东西不是领导讲了,我要做一个DevOps那我就做,因为这是要有实际需求的,并不是说我怎么怎么样,然后再去做DevOps。其实前面的内容介绍里头,我们看到我们做事情的一些方式和思路呢,也是这样,虽然说我们没有和团队讲我们要作一个DevOps的团队,但是我们思路和方法已经也DevOps的一种思路和方法。
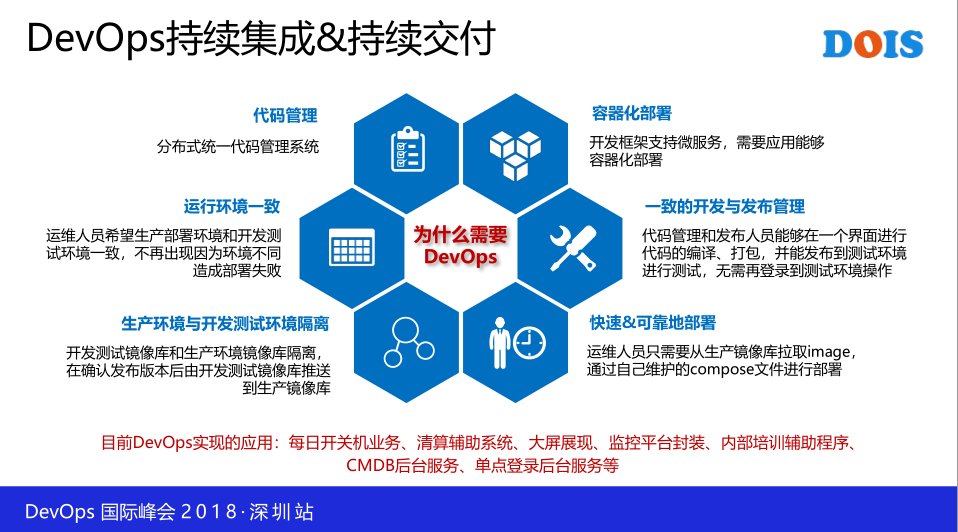
这是我们做DevOps的原因,而不是说其他人的,这是我们自己做的,这是DevOps的一个初衷,第一要做很多系统,要有代码管理,代码管理我们就选择Git,不会选择SVN。
然后不会选择容器化的部署。这在一开始就定义下来要做容器化的布署,但是我们要进入两个阶段,第一个阶段是我们没有用容器化进行布署,先把框架做好,框架做稳定了,后面所有开发成系统了,大概几天的时候就进行容器化的布署了,这是比较快的。
第三是一致的开发和发布管理。我们希望在同一个界面里面作程序的打包,上传,编译,以及发不到进行测试环境去,我不希望在外部端点一点,不希望敲一些命令工具,这些事情是比较低效的,是重复的,是低效的,是没有价值的事情,对于没有价值的事情我们要把它做成自动化,这也是我们DevOps的初衷。
然后是DevOps的部署,用上了容器了以后,你就会发现容易很容易,你会容器上瘾,有一个不太好的感觉。就是说容器化,这样这一个DevOps会将一些运维人员的工作丧失掉,这是客观存在,有一些大的企业经常做一些发布和部署的工作这样会消失,但是会产品新工作机会,比如说你构造大DevOps的平台,或者是做一些文化的培训。另外是生产环境和开发环境隔离,运营环境一致,这是容器带来的好处,目前所有的系统都是用这一种方式去运作的。
提到DevOps呢,我们就会看到非常关键的一块,就是流水线。DevOps有一个理念,我是非常认同,就是持续改进,他的理念很多,什么敏捷,什么精益,其实DevOps的精髓就是持续不断地改进,那过程二是我们一开始用的一个Package,这一个是比较简单,所有的工作都是在Master去完成,包括打包成镜像,把它弄到镜像仓库里去,包括我要从镜像仓库去拉取形成一个版本,然后完成测试的一个部署。这一块当时对我们来说是适用的,用了一段时间了以后,我们团队提出能不能做得更高一点,就把代码的扫描和单元位测试加入进去,我们现在把代码和扫描给它加进去了,然后做了一些管控。
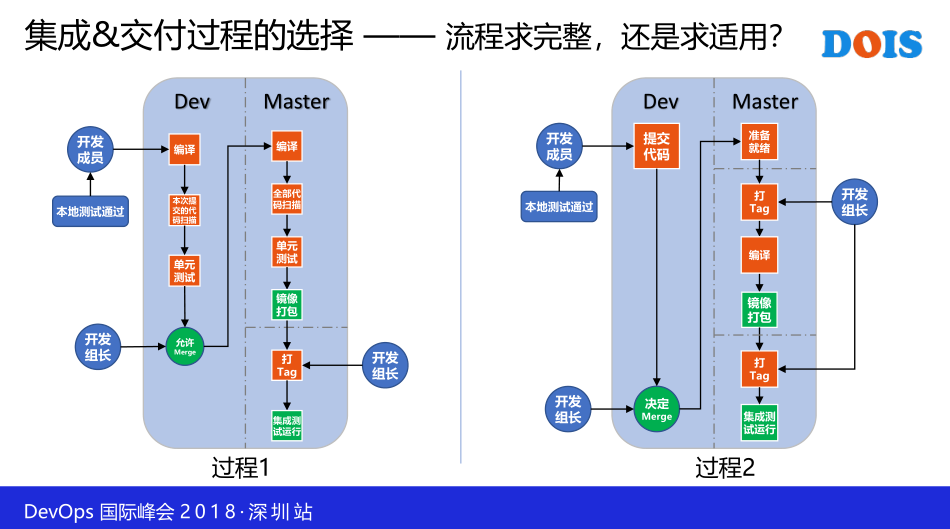
这是我们现在交付的,他把这个代码提交到Branch的分支,然后这一边跑一些CA的一些服务器,它是单独存在的,它可以是容器化的这种跑,也可以是虚拟机,或者是物理机,它会拉取代码,然后再进行编译,然后再进行代码的部分扫描。什么意思呢,我们用SonarQube去做,它对你本次提交的代码进行扫描,扫描完了以后会反馈到你的代码仓库里,告诉你的代码会存在哪些问题。
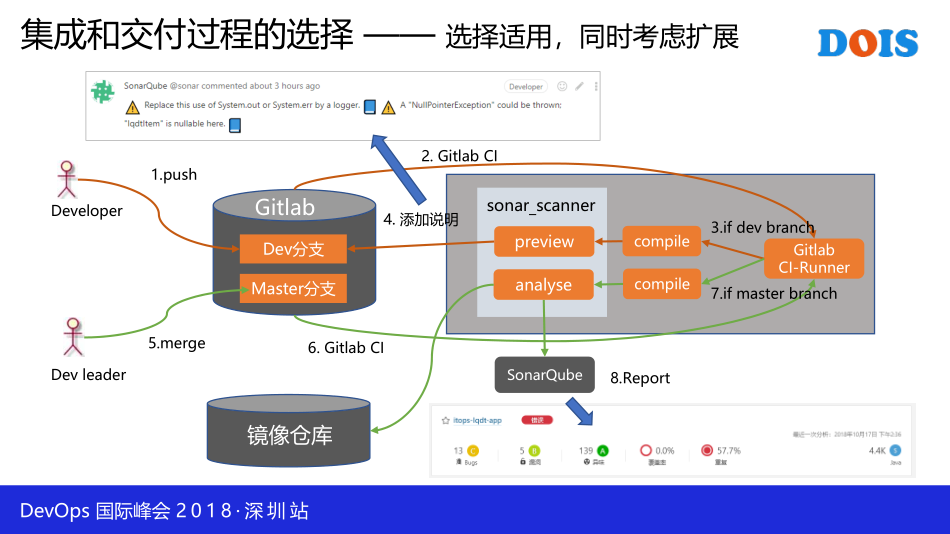
比如说前面这一块呢,它会告诉你空值指针的异常应该被抛出去,等等这一系列的东西都可以抛出来。当开发的组长认为是OK的话,它就可以进行默置,然后再自动处罚这一个流水现,然后进行权代码的扫扫描,就做一个分析,然后分析的结果可以在SonarQube这一个里面做一个呈现。当这一个分析没有问题,它通过了,它会把代码推到这一个代码推到仓库里面去,是这样一个过程。
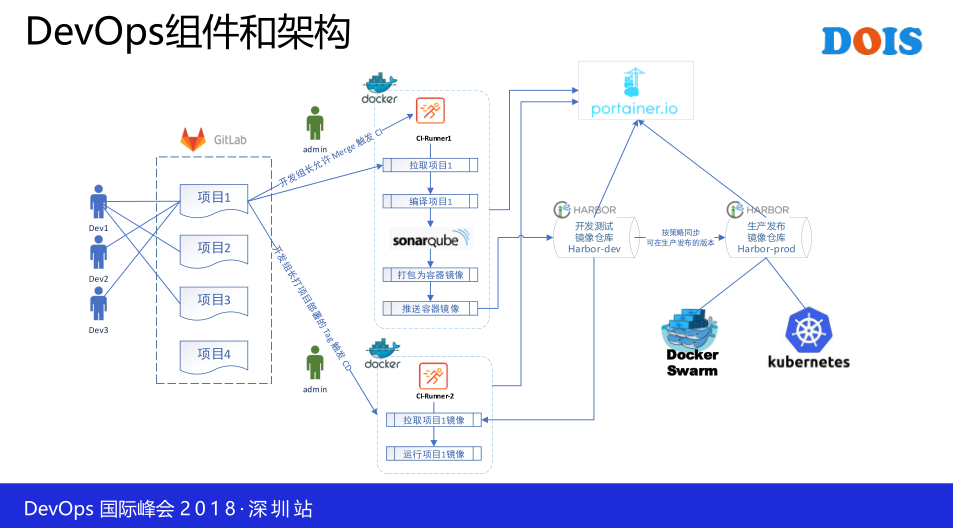
这是我们使用到的一些组件盒架构,基本上这一些都是开源的东西,开源是免费的,不收费的,大家可以参考一下。当然这里要给大家讲一下,不是特别大家只用开源,当你在做Docker的过程中积累的经验,有很多的团队做这一些的时候,当它不够的时候,你公司的领导会给你费用和人员,让你搭建更成熟的DevOps的平台,甚至说是引入一些敏捷的培训些等等的东西,就是自然而然就有了,而不是刻意地去做什么。这里代码的管理是用Gitlab,然后CICD呢,那它可以跑到容器里头,也可以是其他的,有很多种。然后这里会有一个区分,你编译的时候,你代码进行编译时候,你IO比较好的一些机器,跑到这一些上面,然后是开发测试的时候,你可以选用一些内存和CPU比较高的机器,所有的这种配置呢,都是在CI的一个文件去进行配置的。然后这里的仓库呢,我们是用Harbor,然后生产和测试环节呢,进行一些同步,按照某种策略。
那么对于容器的监控呢,我们是用Prometheus进行以监控。那么对于部署来说我们还是用Docker做这样一个布署,为什么不用k8s呢,很简单,就是后面会提到。
详细的过程不展开了,然后只是几个关键点说一下,我们在构建每一个项目的时候都会有一个项目群组,而这一个项目群组呢,会包括外部端,还有APP端,另外它还有一个整体代码发布的东西,就是为了部署的需要。另外也是趟过了很多坑,开源呢,其实说实话吧,是一个特别费劲的事情,所有的问题都得你自己去解决。而用到一些商业套现的话,你可以去问厂家,所以我们趟过了很多坑,这是我们其中趟过的坑,详细的细节不说了。它可以解决一些问题。有的时候,你的image它是静态的,然后你的实际生产是另外一种配置,为了解决这个问题。当然你用k8s的话,它是另外一种方式,就比这一个更加灵活。
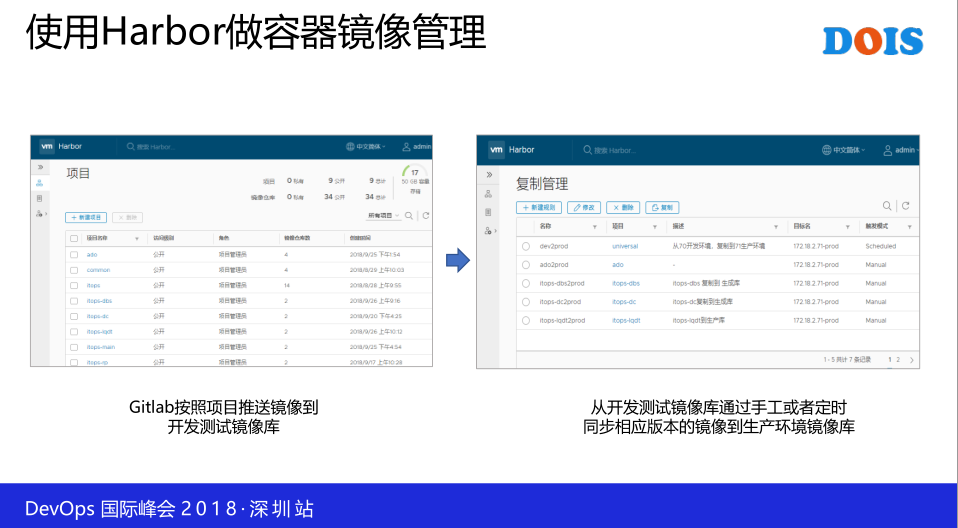
这一边看一下Harbor,Harbor这一块是目前最好的,我觉得还是比较简单的,但是没有办法,只能用这个。
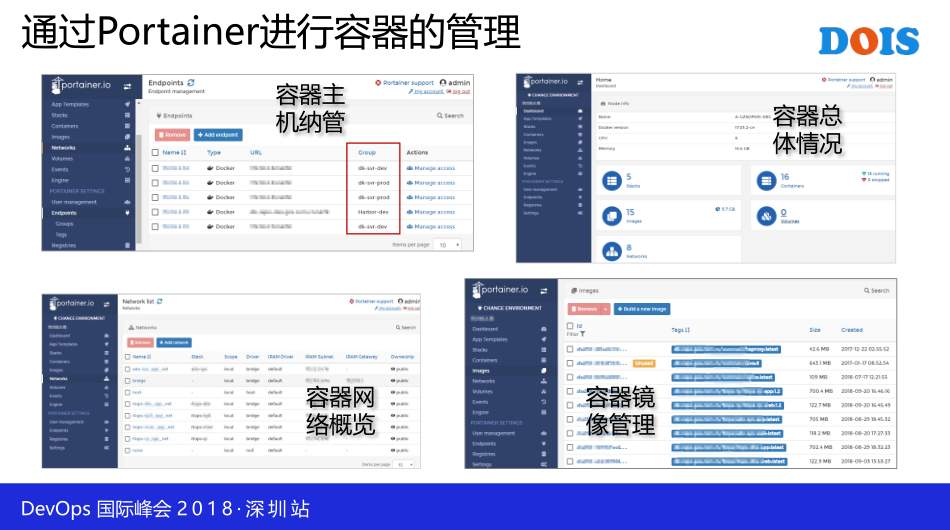
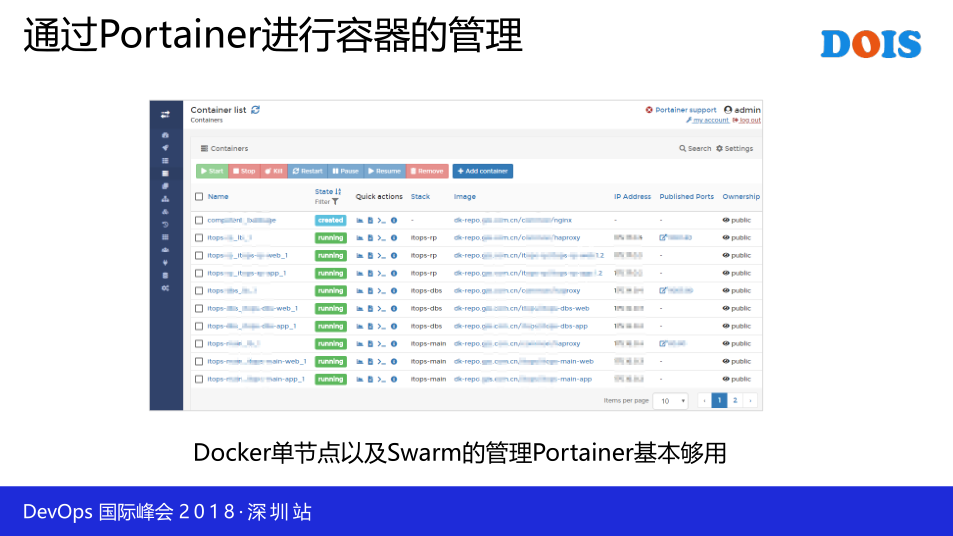
这一个是Portainer,Portainer呢,对于容器的管理,我们觉得已经足够用了,不需要找别的。
关于DevOps的一些体会,传统中小金融企业DevOps的驱动力,题量小,工程师文化不足。或者是工程师不足,而不是说工程师文化不足,工程师是不够的,这一个时候我们采用自上而下通过文化建设的方式是行不通的,你推了,人家不理你,他有别的事情要做。反倒是你构建一些工具能够提高效率,这一个时候可能才是DevOps的起点,其实DevOps另外一个精髓是效率,你把效率提高了,这一个DevOps就达到了,我们想要的一个结果。

另外是适当裁剪DevOps的过程,不是每个企业,或者是不是每个业务,尤其是传统的业务呢,它并不适合DevOps完美的这样一个过程。另外为什么不选K8S,我觉得很简单,跟前面一样,K8S很好,但是要投入很多。所以我们不是不选,我们现在正在研究K8S,可能年底的时候用K8S, 可能是间接地使用,可能会使用Rancher,对K8S进行一些分装的东西。另外一些就不再展开了。

最后感谢一下我的团队,我们的团队虽然说不是打着DevOps的旗号,一开始我们不是这么定义,但是大家都是不断地改进,用代码优化流程,提高工作效率,这是我今天的分享,谢谢大家!
