@gaoxiaoyunwei2017
2019-08-30T11:09:51.000000Z
字数 11336
阅读 2192
微服务测试中的服务虚拟化实践
彭小阳
作者简介:刘冉 ,ThoughtWorks高级软件质量咨询师,超过10年软件开发和测试工作工作经验。对于服务器性能测试,Web功能测试,以及测试分层一体化解决方案有较深的理解。现在关注于全方位自动化QA的工作,以及对于Agile流程中怎么实现统一的流程、故事、功能、测试和文档管理,以及质量控制度量。
概述:今天的话题也分分为4部分。第一,遇到的问题,就是我们在微服务中遇到的问题。第二,服务虚拟化,什么是服务虚拟化。第三,我来讲一个开源项目,Hoverfly。第四,我们真实的项目里面怎么去使用这个Hoverfly。
一、微服务中遇到的问题
第一个问题,微服务中经常遇到的一些问题,其实有4个问题,大家可以看一下,看看自己遇到过没有,如果没有遇到希望大家不要遇到,如果遇到了,那可能来探讨一下我们看是不是能解决。

问题1:测试环境被多个团队共同使用,特别是那种大规模的微服务系统,它很多时候都是会被多个团队在共同使用,因为它有很多Dependency,它可能某一个服务又被很多Consumer使用。
所以说,在某一个中间的服务或者说是某个Dependency服务,它是会被多个团队共同使用的,这是存在一个问题的,这个问题过一会儿我们来看一下。
问题2:测试数据准备需要花费大量时间,可能在互联网有些公司测试数据还比较容易准备,但是在像传统的,因为我们做咨询,我们经常去向这种通信,或者是去银行,还有传统的保险,他们那些数据是非常难以准备的。
我曾经在一个保险公司,准备一套数据至少要花2-4个小时,因为他们的整个数据用的像IBM的那套DB2,而且那个业务非常复杂,你没办法操作数据库,这是第一个。第二个他们要从界面上创建一套数据,它完全用的像Minfuren的应用系统,是全Console的,所以你要创建一套数据要花很久很久,而且里面的流程非常之复杂,像保险和银行都是。
所以说,这个测试数据是非常大的一个问题,我上次还去了中国的几家银行,他们也说他们遇到最大的问题就是测试数据创建的问题,包括真实的数据里面,包括数据怎么回滚,数据怎么使用之后的重建都是很大的问题。
问题3:某些服务部署或网络等问题导致测试环境不稳定,这个也是经常会遇到的,可能有些公司的技术很好,没问题,但是我们遇到的很多客户他们的技术本身就不怎么好,所以说他们的基础设施非常之差,就是测试环境里面他们的基础设施是很不稳定的,所以会遇到一些问题。
问题4:依赖服务的版本更新会影响当前的版本,这个可能要单独解释一下。
我们来看一下第一个问题,就是测试环境被多个团队共同使用,这样存在最主要两个问题。

1、同一测试数据可能会被不同的团队修改。可能很多人会说,这样我就多一套测试环境,每个团队用一个环境,但是对于很复杂的系统,你要创建多套测试环境,首先你这个成本就很高,你肯定要创建很多独立的Docker,但是在很多企业里面是没有这样的基础设施环境的,当然可能很多互联网公司不存在这个问题,但是在很多传统企业是存在这个问题的。
2、同一测试数据可能被其他团队占用,所谓的占用就是你的数据一旦被某个人使用了,他可能按自己的意愿在进行使用,这个时候你去用它,你可能会影响到别人,或者它锁定之后,因为有些数据它可能需要锁定,锁定到你,它去使用甚至不能修改,得不到自己想要的。
所以说,这种时候在同一个测试环境里面被多个团队共同使用,主要是会存在这两个问题,可能还存在一些小的问题,最主要是这两个问题。
第二个是测试数据准备需要很大量的时间,这个最主要就是数据关联太多,很多时候数据一旦使用,之后状态无法还原,这个我相信传统企业的客户或者是员工,这个问题是最严重的,一旦使用了,它的状态被修改了,基本上是不可复原的。

像我现在在做的一些像银行,特别是银行、保险,还有就是一卡通,就是跟金融相关的,第二个问题是特别严重的,测试数据可能被刷新或者销毁,这个是由于特定的一些环境,它可能过一段时间需要把产品环境的数据,比如说Stage环境,它需要把产品环境的数据给刷新过来,所以说这个时候可能你自己做的一些临时的,或者创建的一些特定数据就会被销毁,这个也是会存在的。
某些服务部署和网络问题,这就很容易理解了,就是依赖的服务正在部署,可能你觉得正在部署这件事情很简单解决,可能部署就几分钟、十几分钟不能用了.

但并不是这样的,如果这个依赖服务比如它是DAVE或者是一个UAT环境,它就是有人不停的在提交代码,可能就一个小时部署个4、5次,有些做CAD做的牛逼的,号称他10分钟可以部署一次产品环境,你想想如果10分钟部署一次产品环境,他从代码提交到他测试环境部署,产品环境部署,这个测试环境可用吗?大家可以想象一下,这个是比较极致的。
但是,很多公司宣称自己可以1-2个小时部署一次产品环境,如果真的是1-2个小时部署一次产品环境,测试环境这1-2个小时里面至少要部署10几、20次,这是很正常的。
依赖服务正在调试,很多时候服务本身有可能在被特定的一些人调试,而调试的过程中,他有些状态是在不停的变,我说的是某些依赖服务,就是说这个服务可能就不可用了,或者这个服务的状态就不对了。
这种时候怎么办,依赖服务存在Bug,导致某个功能失效,你不能保证你的服务没有Bug,可能上一秒钟它还是好的,下一秒钟可能就挂掉,或者是10分钟之后它部了新版,某个Bug就出来,那就不可用了。
但其实我并不需要他的新版,我只要老版能工作,我自己的测试能调试就可以了,所以说这种时候也是一个很大的问题。
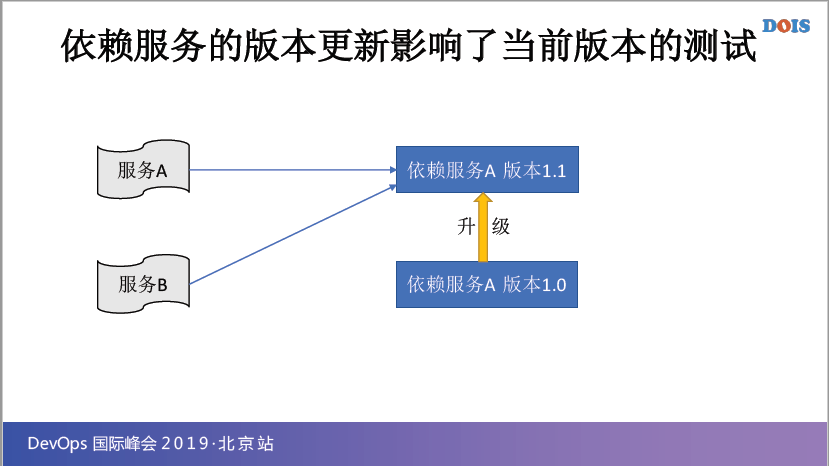
最后一个就是关于以来服务的版本更新,这个可能稍微难理解一点,比如说假设依赖服务A、依赖服务B,它依赖于服务A的产本1.0,当依赖服务A升级到1.1的时候,大家可以想象一下,其实我并不是需要服务A和B,它并不需要以来服务A到1.1,它其实只需要依赖服务的1.0,但是依赖服务A它就是强制升级了。
升级之后由于某些功能或者是某一些像Sigma变掉了,但是它没有做区域测试,它就是强制升级。
这个大家可能知道,有一些服务提供商他就是强制升级,你没办法,它一旦升级以后,意思就是我的服务A、B,必须基于依赖服务A的1.1来进行更改,但是这个时候其实我在产品环境里面,我整个服务A、B的升级发布,还是要基于服务A的1.0,这种情况下就很尴尬。
我怎么办呢?我要么就是拿一套,自己再部署一套服务A1.0的环境,可能对于互联网没这个问题,但是对于传统企业,比如说我现在在做一个新加坡的项目,他们买了一套电子钱包的服务,电子钱包服务一升级,而且这个电子钱包的升级,就是那种供应商非常强势,我升级了就按我的来。
但这样的话,我可能还基于老的版本正在开发新的功能,这个时候其实我发布新的版本,还要老的版本在产品环境上同一个版本,所以说这种情况下,我当前的服务是不能基于新的依赖服务来进行开发和发布的,所以这个时候他就会非常痛苦,怎么办?很难解决,所以这就是很多传统企业,技术能力不是特别高,或者是说基础设施还达不到一定Level这种情况下,传统企业遇到的问题。
二、服务虚拟化
基于这种问题,就会出来一个服务虚拟化的东西,但是大家可能听的更多的不是Service Virtualization,更多听的是Mock和Stub,那虚拟服务化其实在国外已经出来有几年了,大家如果去YouTube上搜的话,Service Virtualization应该是搜到不少视频包括文档,但是可能国内做这块的人还不多,或者说知道的人其实不多,但可能互联网公司有一部分知道,但传统企业基本上是不知道的,可能更多的人还在用Mock和Stub,虚拟服务化是为了多服务而生的一种服务虚拟化技术。
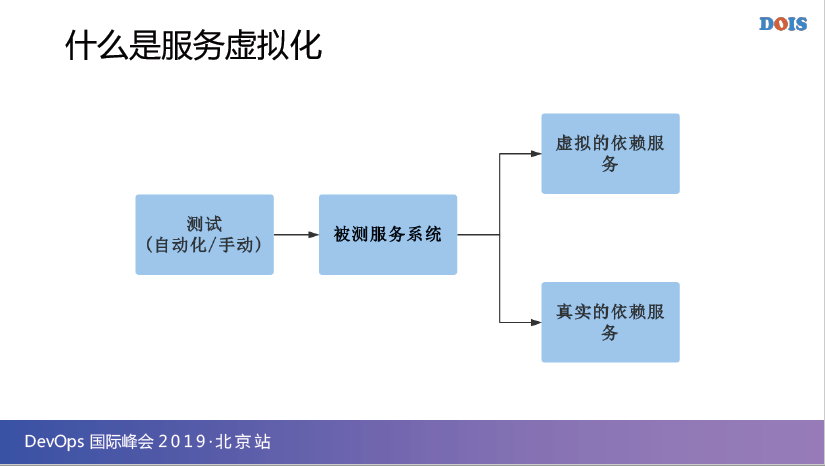
其实,看起来很简单,就是测试是一个被测系统,被测系统它需要访问的一个虚拟依赖服务,它还可以访问一个真实的依赖服务,整个虚拟服务的东西,它是为了去模拟真实的依赖服务,但是看起来这么简单一点,其实它可以做到变化非常丰富。
后面会给大家慢慢来讲解,为什么这么丰富,它解决上面我们列出来那么多的问题是怎么解决,并不是靠这么简单一张图来解决,它会靠很多实际的方法来解决。
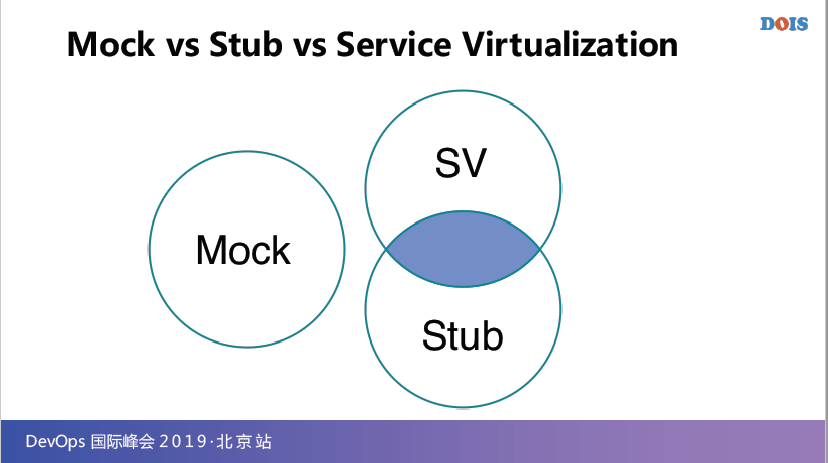
来看一下这个图,这是我自己的理解,可能网上大家一看很多文章、文档都在比较两个东西,就是比较Mock和Stub,其中我看的文档主要是Matingfor那张,就是Mock esnt Stub这篇文章,可能还有很多人理解的是Mock是包含Stub的,有些人说Stub是包含Mock的,这个理解每个人都不一样。
这是我个人的理解,就是首先Mock是个动词,它代表的是一种技术,你可以说是把一个东西给它虚拟化一下,Mock本身你可以理解成就是我要测一个行为,而Stub它更多的是虚拟的一种状态。
所以说,Mock和Stub它是不同的一种东西,但是由于Stub它在传统的已经实现好的Stub技术或者工具里面,它只能做一些比较简单的状态的虚拟,而针对特别是这种大型的服务,很多时候它已有的工具可能就做的不是很好。
所以说在国外有一帮人他觉得我要做一套新的东西,但是我又不想以Stub的这种方式来命名,因为我觉得我做的东西更先进、功能更丰富,所以他们就取了叫Svrvice Virtualization这个东西
所以,其实它只是把Stub进行了扩展,丰富,实现了很多传统意义上Stub工具实现不了勒的一些东西,不能说实现不了,只能说传统意义说的这些Stub工具,比如说像Mock这些东西,它可能有一些功能它不支持,你需要自己手工再去开发,而新的那一帮人他就直接说我全新开发一套这种Stub工具。
但是我觉得它的功能更为丰富,所以我就取名为Service Virtualization,而且它是专门为服务而生的,而实现了很多解决刚才我列到那些服务在测试过程中、环境里面遇到的一些问题,所以说它是专门解决那些问题而产生的一种新的技术,然后重新命的一个名。
三、Hoverfly
那什么是Hoverfly?Hoverfly这个东西,我不知道大家怎么进行做Mock或者Stub,反正我在很多测试社群里面,有些人主要是会用Very Mock,有些人,像我就遇到几个人,他是自己写一套。

很多人可能就简单自己写一个Stub就在那儿工作。但是有个问题是,我都评估了那些工具,它有一个功能是实现不了的,实现不了的意思就是说至少它上前没有。我对于像我们做咨询,我们要快速的帮客户实现一套东西,所以说我们必须基于开源,基于已经实现好的东西,不然的话我们会时间上来不及。
所以,当我去评估,因为我在半年前帮一个客户转做测试方案的时候就在评估各种工具。最终我是选择这个工具,这个工具是两年多以前才开始发布的,发布才两年。而它基本上拥有了我现在能看到的最全的一个功能集,并不是其它工具不行,其它工具至少现在的还没达到它的那种。所以,我觉得它来讲,它基本上包含我想讲的所有的模型,才选择它。
这个我们在我们的客户那儿已经用过了,它首先是开源的,这毋庸置疑。其次它支持虚拟数据,这就是基础的功能,它基于Go开发的,所以你想怎么改就怎么讲。它支持Python和JAVA的扩展,大家都是通用语言,这很容易实现的。而且提供REST API,这一块这个就是标配了,因为现在一个工具如果没有REST API就没有难以进行控制了,特别是在CACD上,还是在真实的环境中。那它提供的什么网络延迟、随机错误之限定速率,这都是基础功能,这些都不是重点。
然后,暂时只支持HTTP和HPS,这是它暂时的缺点,因为现在我刚好在上周遇到一个客户,他们需要去做真实的这种硬件仿真,就是各种采集数据的硬件,那种东西他们是要支持的TCPAP、Sopu、HPTP这些。
所以,当时我跟他聊了之后,我们给他推荐的是另外一套工具,叫Mountainbike,可能不是Hoverfly。但是有个问题是Mountainbike是另外Souoas的工具,但是它的功能没有这个强,但是它支持的协议更多,所以说从支持执行上这一点,这个Hoverfly它还有比较长的路要走,但是因为它的模型来讲,它基本上是比较全的。

下面我们来看一下它的模型,它的模型支持这六种,这六种模型基本上可以Cover住你想去解决上面我们列出来那所有的问题,这六种模型我一个一个介绍,可能前面两个模型是非常简单的。
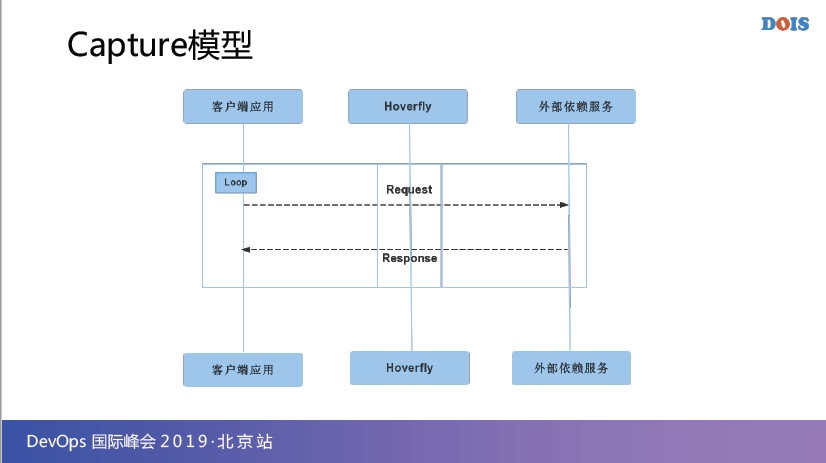
第一个模型就是Capture,就是标准的Record,你把它加成一个Proxy,你所有的服务和外部服务之间的通信,都会把它Record成它特定格式的Sgema,这样的话你可以用这个Sgema来进行各种虚拟。所以,Record功能很多都用,这是个基本功能,必须有。
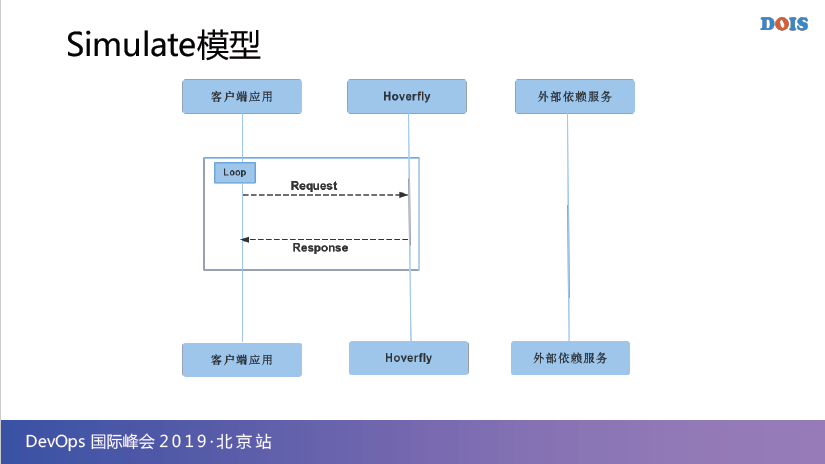
第二个功能就是Simulate,这就是标准的我们曾经所使用所谓的Stap功能,就是我把我record或者是手工写的这个Sgema,放到这个Hoverfly里面,那我就可以进行虚拟化,就叫Simulate,就是虚拟。
前面两个是非常容易理解的,从第三个开始就稍微特殊一点,第三个就是我真实的在我项目里面,为了解决这个问题,我才用了它,如果没有这个功能,其实我不会选择Hoverfly。

第三个功能SPY功能,SPY功能是什么意思?就是我曾经和一个埃森哲资深的测试经理聊过,说这个功能在开源里面有没有?
他说他也没有看到过,但是他在IBM的商用套件里面看到过,在几年之前,但是请注意,那好像是几万还是几十万刀的一套商用工具里面才有,开源里面没有这个东西,现在我也是第一次在开源系统里面看到这个功能。
它什么意思呢?它在中间这个Hoverfly,就是所谓的虚拟化的服务里面,Hoverfly它是以一个Proxy的方式启动,你的客户端和你的服务依赖端,它是中间加了一个Proxy,你的客户端其实是没有代码入侵的,不像那个Wormark,你要是用Wormark的话,其实你需要改你的代码,或者改你代码的配置才能调到。
但是Hoverfly是不需要的,Hoverfly你主要的命令行改一下你的Proxy,然后你的应用程序能够读到系统的Proxy,或者GUM的Proxy,它就能使用Hoverfly,所以它是一个非入侵的一套解决方案,就是在不改变你的系统或者你系统配置的情况下一样可以做到。
所以,当这种情况下,我所有的依赖服务,看一下,当我去请求它的时候,大家可以想象一下,我其实是不想改变我当前的被测系统Consumer所有的配置或者是代码的情况下,我需要当我测某些账号的时候,它返回是假的。但是当我测有些账号的时候,它是从真正的外部依赖服务返回真的。
大家想想这个有什么好处,就是我只要set up好一个Hoverfly Service,那我可能有十个dependency,这十个dependency都接到一个Hoverfly的Brek Service上。
那当我有一个账号,它是一个特定的账号,然后我把它虚拟化,放在Hoverfly里面,那这个账号我去访问的时候,它就不会真的去扩这十个外部依赖,它就直接在这里面Mach住了某一个特定的账号名字,它就把这个我虚拟好的数据,全部以虚拟的方式返回给我的被测系统。
但是,我改一个账号,请注意,测试账号,比如我Tskes,我就给比如一个zipo里面,给一个Taskecoud001、Toskecoud1234567,001就是虚拟的,1234567就是真实的。那这样的话同样的Testcase,不同的测试账号,当它发不同的数据的时候,我的001就是Mach住了某一个特定的条件,它就会返回虚拟的Resbass。
但是,1234567过来之后,在我整个Row里面没有001的数据,它就会真实的去请求我外部的服务,这个时候它就会测到真实的服务。
所以,大家可以想象一下,假设我一旦把这个弄好之后,我可以通过改我的测试数据本身来确定我到底走真实的依赖系统还是走虚拟的依赖活动。而这种情况下,在传统已有的这种Stub工具里面可能是需要自己手工去实现的,至少它默认不支持。但是这个它是默认就支持,所以你只需要把你的规则加到Hoverfly的这个Row里面,它就能实现这个功能。
所以,这个是当时我需要去解决的,因为是我认为在多服务依赖的时候,我只要最小的成本,Set up一个Proxy,并且我有些时候在同一个测试环境里面,我既要测虚拟的,又要测真实的情况下,最佳解决方案,因为只有这样我才能以最低的成本,来既实现了又要测真实的情况,又要测虚拟的情况。
很多时候可能大家会想,为什么会有这个需求,因为很简单,很多时候我的测试环境不一定,我不能把我大规模的回归测试依赖于外部服务,我可能大规模的回归测试我可能就依赖于虚拟的数据,但是我依然要测一些外部服务,为什么呢?因为我担心外部服务的升级怎么办呢?那可能升级之后,我的Sgema改了,就会产生一个Bug。
所以,我会把一些所谓的重要的场景,依然是跑真实的外部服务,这样的话就算它的外部服务的Sgema改了,我依然会被通知到。但是,我的可能89%是到回归测试,依然会正常的得到结果。
因为这样的话我可以拿一部分Case来测试我真实的被测系统自己的大部分逻辑,但是我一样会拿小部分case去测这个被测系统和外部系统所谓的集成。因为很多系统现在做契约测试是非常难的,很多系统是没有契约测试的。
那没有契约测试的时候,你要怎么快速的去知道你的系统和它系统之间的契约是否被破坏了,就只能通过集成测试,但是集成测试你也不能做大规模的,因为外部服务有可能崩掉之后,你连自己的测试都跑不了。
所以,这是一个比较经典的解决方案,当然你可以完全自己实现,但是别人已经实现了,就可以拿来用了,我是一个坚持不想自己重复造轮子的人,因为已经有了,我觉得只要能用,并且是没有问题,那就非常可以了。
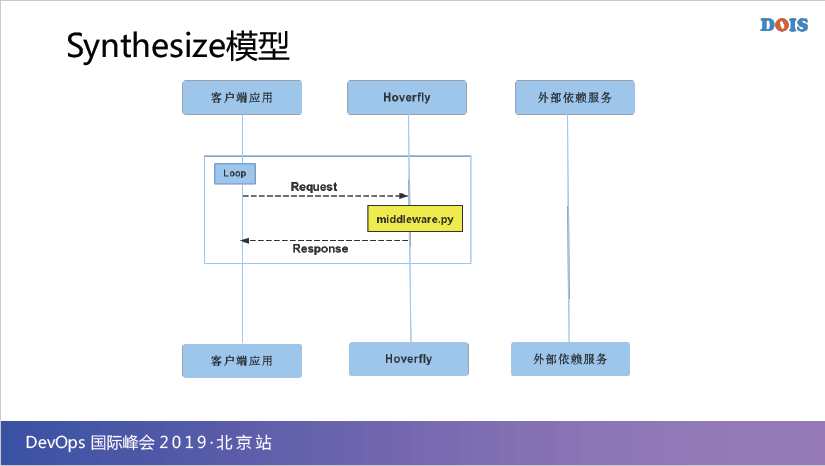
第四个模型,Synthesize模型,这个模型最主要的它解决的一个问题就是说在我第二个模型,就是Simulate模型的时候,因为它只能返回一个固定的值,但是很多时候我要测的是一种状态,它的状态可能有很多种,那这种时候怎么来实现不同状态?肯定就要有一些逻辑在里面,业务逻辑。
所以,这个时候其实Hoverfly提供一种插件的模型,就是说你可以在这个Hoverfly给一个插件,当某个request来了之后,我可以对这个request进行加密解密,进行一个特定的判断,之后再返回一个特定的resmas,所以这就是它的这种Synthesize模型。
可以对request进行判断、处理,对Response进行一些特定的组合,并不是一个固定的值,或者说固定的某一到两个值,可以是非常丰富的值。
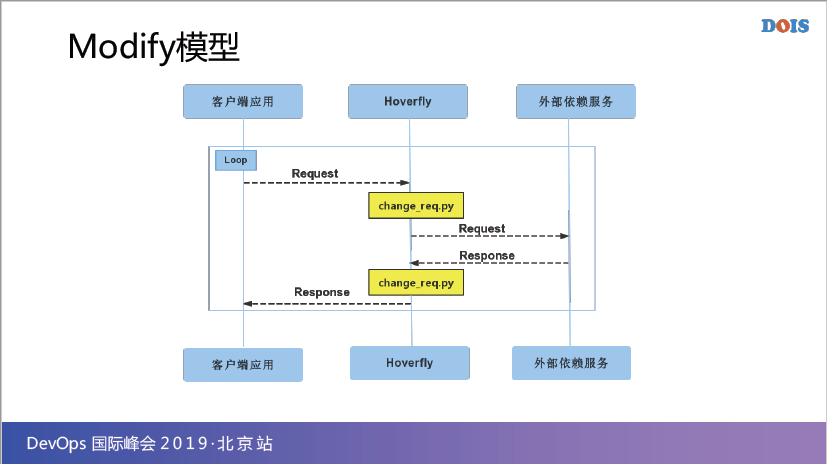
下一个模型就是Modify模型,Modify模型它就是真的request来了之后,它可以把request改成某个特定的东西,发给外部依赖,那外部依赖回来的request我可以又改成特定的模式返回request,这个是为了去完成某些特定状态的虚拟。
比如说我就要模拟我的request里面被加了某些东西,或者某个request里面,我就是故意很长时间,或者是做一些混淆,产生一些特定的case,那这种情况下,其实我是需要根据真实的依赖返回的某些数据,只是改某些特定的数据的时候就可以用这种模型,这叫Modify模型。
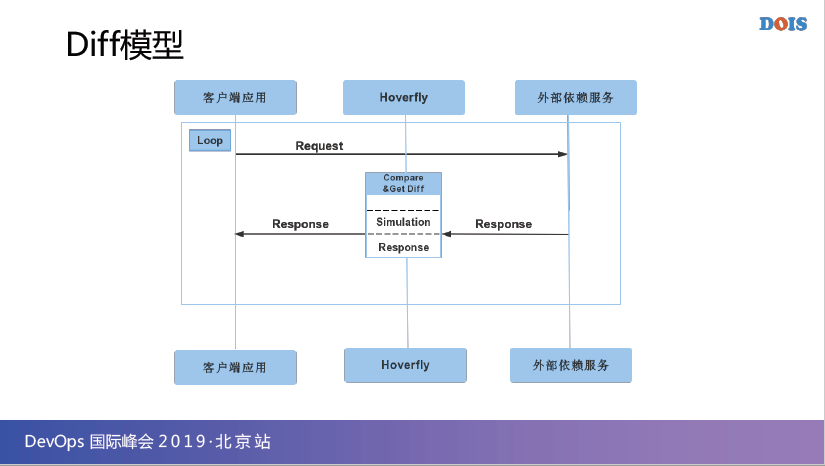
最后一个模型叫Diff模型,Diff模型我认为它相当于尝试在解决契约测试问题,契约测试很难解决的,我前几次在外面其它大会讲就讲到,契约测试我现在见到的能做出的公司非常之少,因为确实业务部门组织结构的问题导致你契约测试根本就做不出来。
然后,当你做不出契约测试的时候你会发现,你要怎么去和你的依赖系统进行这种所谓的快速检查,它是不是Brken已有的契约,你就很难做。那可能很多人会说我就写集成测试,但是集成测试也有很大的问题,你要写代码对不对?你要写我要去访问它,它回来是不是就挂了。
那Diff这个模型怎么解决呢?它就说我通过测我的被测系统,当我去一测它某个API的时候,请注意,是测被测系统的API,它和它的依赖服务的返回,会被保存起来,当我下一次跑第二次的时候,它会把上一次的和下一次的进行比较。
如果下一次的,就是第二次的和第一次存储的Sgema有不一样的,那这个时候它会报警,就会给你一套日志,告诉你,OK,你两次调你的Dependency返回的,Dependency和你的被测系统(所谓的客户运营端是我的被测系统)的值是不一样的。
这个时候其实它相当于就做了一部分你的被测系统就是你客户端,和你的依赖系统之间的一种我认为是一个被动的契约的检查,虽然它不属于契约测试,但是最多就算一个契约检查。
所以说这种时候其实你不需要去主动写这两端的契约测试,你只需要把你的API测试写完之后,每次你运行下一次,它就和上一次比较,运行下一次和上一次比较,就能不断的提示你,到底你的Dependency那端有没有有更新,如果有更新你马上就知道了,甚至你不需要去判断你在这个case本身有没有失败、成功。
所以,你的这个测试本身,甚至连assertion都不用写,你就写一个测试,就叫我被测系统调用某个snorw,它只要能成功返回,不管它是返回200、300、400,只要它这个cmae有不一样,它马上就报警。
所以,你可以写一个准确说不叫测试,准确来说就是对你的被测系统写一个场景,你连assertion都不用做,你就可以完成简单的所谓契约检查。
这就是现在Hoverfly支持的六大模型,大家可以想一下,你们所了解的,或者说你们现在正在用的,或者说你们自己开发的所谓的这种Stub系统有没有这六个模型,如果没有的话,你们是不是尝试也在做这种东西。如果尝试在做,它已经有了,其实大家可以尝试用一下。

为什么要选择Hoverfly?这个解释一下,服务虚拟中心化,它是基于Proxy模型的,所以说它只要加一台机器就可以了,我在客户那儿就是申请一个专有的inkes ajent,就让它Swbato Hoverfly,然后大家所有的依赖服务的请求都要过它,就可以了,然后我就要控制它一个中心端,我就维护它一个就科技了,不像vorymork,我要启很多个,理论上vroymork它推荐的方式就是一个vroymork只虚拟一个Dependency,这样的话我要有十个,我要去请十个vorymork的Dependency。
非侵入式的,我刚才解释过了,它是不需要改动被侧系统的代码或者配置的,它最多改的就是你GUM自己的prout或者是操作系统linakes的Hdprukec配置就OK了。
灵活性,它支持各种模型,使用非常方便,我个人觉得非常方便,因为你需要管理一端,然后你只需管理它的Sgema模型,最多你还用写一下你的控制端就可以了。
开源软件,这个不用说了,昨天有一个分享是说开源正在蚕食整个软件世界,肯定我都是选择开源,像我就是玩开源的,所以说基本上在测试行业里面,我在尝试所有的比较好用的开源测试软件都在尝试在客户那儿去使用,我一般不会在客户那儿推荐或者使用商用的测试软件,一般都是做开源的。
四、Hoverfly在我真实的项目的实践
第一个,这是我的一个被测真实项目脱敏之后的架构,我有一个被测系统、被测服务,只是其中一个,其实我有很多个被测服务,这只是其中一个。它其实会调用到六个领域API,相当于是它的依赖服务。
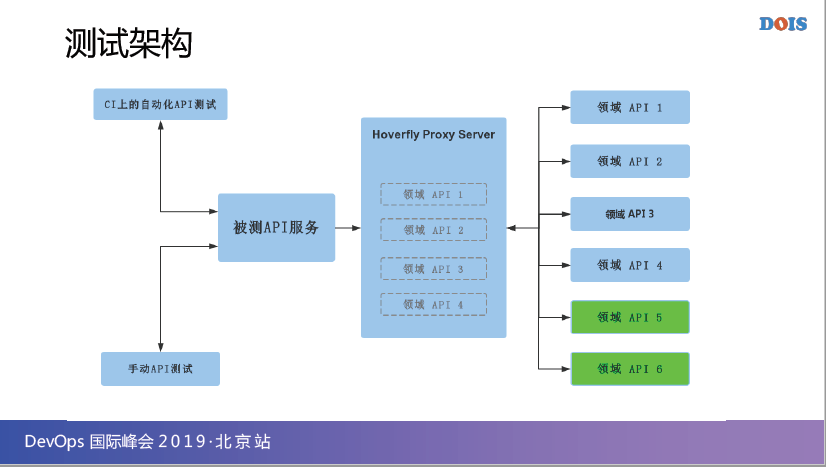
那这个时候我只要在中间加一个Hoverfly Proxy Server,并且我只要把其中四个领域的API虚拟化,我当时只虚拟了4个,因为这5和6当时是非常稳定的,而且数据也比较固定,没有什么变化,所以我只需要虚拟其中4个。
那这4个虚拟好之后,我的API测试,手动测试,请注意,我不仅仅是自动化测试,手动测试在测它的时候,依然可以用这些数据来进行测试,所以这是个基本架构。

我的实践是首先我会在AWS Instance,因为我们的Jenkins是加在AWS上的,所以说所谓的Agent sowr都是AWS上的,所以我就建了一个AWS instance,把它的模式设置成Capture,这是两个命令。
Start,它其实就是一个二进制运行文件,你把它拷上去,或者是你把它放在一个特定的repo,或者是你直接从网上下来也可以,反正随便你。
把它装好之后,你只要允许这两个命令,你就可以启动了,它就开始Capture了,没有更多的命令了。
请注意,这种方式只能适合于HTTP,如果是HTTPS,你还需要假如你的证书,因为大家知道,作为Proxy要去拦截HTTPS,必须是使用自己自定义的证书,这个可能大家注意一下,如果你是HTTPS,你后面还有一串参数,这个参数就是跟上你自定义的证书,这个可能大家应该知道的,所以说就没写了。
发送请求到被测的API,调用真实的外部服务,这个时候所有的请求全部会记录下来,然后记录下来之后我就把它导出来,为什么要导出来呢?因为我要把里面的一些测试数据改成特定的测试数据,不然的话我以后真实的数据我也访问不了。
那我把它导成一个Simulation,一个命令就完了,导完之后差不多是这个样子。它就是Request,给了一个Sgema的格式,你只要找到你特定的,比如说它的这个请求里面有一个Request,里面有一个参数,比如说这个地方有个Wanlue,你把Wanlue或者它的那个Acant改成一个特定的Wanlue,这个时候Response改成你特定的Response,相当于是一套虚拟的数据。
其实,这个Hoverfly里面我们又把一个东西拿出来,就是它里面有很多规则,就是你的这个Simulation的文件里面可以写很多规则,这个规则包括我的延迟时间,比如说我还要等20秒还是30秒,都可以写在里面,我是对某个特定的数据呢?还是对某个特定的UIL,或者对某个特定的子UIL,这些都是有规则的。
大家应该知道它定义了一套匹配的语法规则,这个语法规则全部只要写在Simulation文件里面,就是不用额外写,写Passen、Java代码是哪种时候呢?你需要对Response进行处理,或者对Request进行处理的时候才做。

所以说,你如果进行简单的虚拟,你只需要改这个Simulation文件,然后你把这个Simulation文件改成特定的伪造数据之后,又把这个Hoverfly切入到Spy,然后把它import你改好的这个Simulation,就完了,就是它整个更改模型导入导出数据都是不需要宕机的,它不需要关闭重新来,它都是可以实时进行的。
所以说只要我的Hoverfly一启动,我就不会关它,除非我晚上为了省电关它一下,但我整个测试过程中是不需要关,它不管是更新中间模拟的数据,还是说你要改变各种模型,都是可以不用关机的。
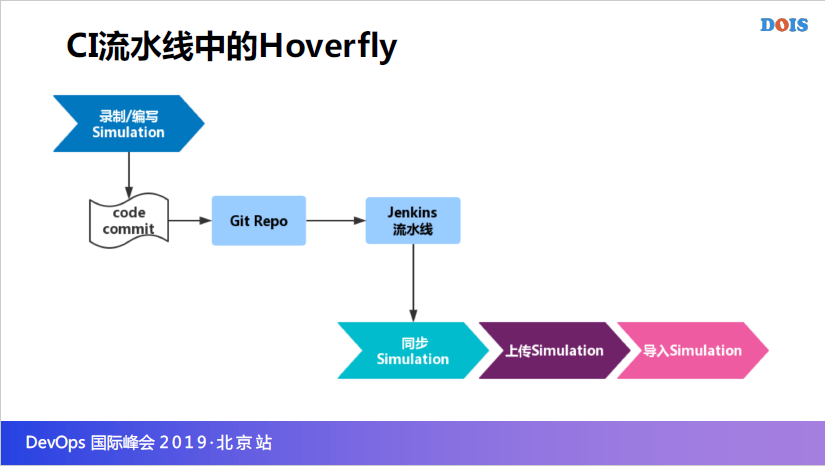
最后我是把整个Hoverfly的流程都放到CI上,这步是需要手动做的,就是录制和编写Simulation,然后我把它录制好、编写好之后,把它放到了Git Repo里面,那Jenkins流水线是直接从Git Repo里面拉下这个Simulation。
所以说每次我改好之后,我只要把我的Simulation push到我的Git Repo里面,CI就会主动去拉,拉完之后直接上传到Hoverfly的机器上,直接导入到Hoverfly的instance上,就完了。
所以说,对于我来讲,我只需要关注的是更改我的Simulation文件就可以完成所有工作。
最后的时间,就是使用真实的测试数据,对API进行小规模的集成测试,刚才我也说到这一点,就是使用伪造的数据对API进行大规模的回归测试,在这种测试环境和测试数据都不稳定的情况下,但是如果你的被测环境,一它非常稳定,二测试数据非常容易创建,三数据非常稳定,并且你是独享的。
可能在你没有我之前最开始列到的所有问题,你是可以不使用这套技术的,但是如果你遇到了一些问题,当你解决不了的时候,你可以用这个技术来解决,它是一个非常小的技术点,但是有些时候往往可以解决你很严重的测试相关的问题。
