@gaoxiaoyunwei2017
2018-05-29T09:55:26.000000Z
字数 7183
阅读 1374
一直播、小咖秀大数据自动化运维实践——于邦旭
黄晓轩
讲师 | 于邦旭
编辑 | 黄晓轩
讲师简介
于邦旭
2017年加入一下科技,担任大数据总监
前言
一下科技从成立至今一直专注于短视频领域,我们希望分发给用户更多的优质视频,让用户看到这个世界上的美好。我们公司对于大数据的要求和阿里、搜狗不太一样。当我加入一下科技后发现,在高速成长发展型企业,我们需要大数据做得更多的不是平台,不是让平台做得多么好,让各个部门使用,而是让平台提升用户增长、扩大营收。我带领团队尝试多次转型,最终我们想到一点,我们需要大数据基础平台,更多的不是走到平台化或智能化,而是简单够用就好。在此之上我们有很多想法,希望可以跟大家分享,有些处于高速发展期和成长期的公司可能跟我们面临同样的问题,大家可以共同探讨。
一直播、小咖秀大数据架构

我们先看一下一直播和小咖秀大数据的现状。当我们去考虑一直播和小咖秀整体大数据架构时,我把公司所有需要大数据业务的需求整理好,我尽量把它压缩到只需要到ES、HDFS、Kafka、HBase、Spark等,简单聚焦几方面。原因在于我们投入的人力有限,不想让团队处于每天解决各种各样的开源组件问题,我们尽量把所有的业务聚焦到这几个方向上,好让我们更加聚焦。

由这些需求,我们规划了一个整个一直播、小咖秀的大数据架构。架构分为三个层面,有点像IaaS、PaaS和SaaS。IaaS是我们的ALPS大数据基础服务,分为传输系统Flume、Kafka,计算调度平台是Yarn和K8S,之所以使用Yarn和K8S,因为我们一下科技正在推动所有的应用和业务全面微服务化,未来的发展方向是用K8S解决资源编排、容器调度和服务发现的问题。Yarn是大数据内部的资源调度框架,我们更多想尝试把跑在Yarn上的Spark、Flink、Storm等尽量在K8S上有更好的实践,形成公司架构的统一。在存储系统上更多的聚焦HDFS和HBase,在HDFS方面,我们聚焦于做存储,更多的是原始日志包括HBase以后的文件。
我需要一个运维系统,来支撑传输、计算、存储和上层的数据集成服务、迎合数据应用服务。目前我们ALPS大数据基础服务只有两个人,包括运维和研发。在这之上的数据集成服务,我们只有三个人。在最上面的数据应用服务,像商业智能平台、推荐系统和智能风控系统是我们投入了更多的人力,大概有20多人的规模负责这三个方向,专门解决直播领域和短视频领域遇到的问题,用商业智能平台做精准的数据决策,用推荐系统把优质美好的内容分发给优质用户。在中国互联网上面临防薅羊毛,在搞活动时,黑产会频繁刷我们的接口,去拿他们不该拿的部分。我们整个团队在大数据领域,更多的聚焦点是在上层业务解决实际问题,把数据转化为价值,解决我们一直播、小咖秀在数据增长方面面临的问题。用大数据来引导我们的增长,包括个性化推荐系统,把精准的内容分发出去,解决数据风控上的问题。在投入比来看,我们把更多精力放在上层业务,在底层服务只投入了2个人。你们投入这么少,能做成什么样。我原来在阿里和另外几家的公司做大数据时,更多的是投入一支团队,解决每一个组件的性能,在开源基础上做更多的东西。由于公司业务形态的不同,决定你使用大数据的方式不同。我们公司更多的是聚焦业务,转化价值,我们把大数据基础服务层面做得足够简单,简单到够用即可。在够用基础上还有一定的想象空间,那时候我们做了很多尝试和思考,把之前很多经验做了大量底层开发,用了很复杂的架构,在实时计算和ODPS方面经验的参考,发现两个人Hold不住,这是很多创业型和成长发展期公司面临的问题,如何选择运维系统,如何运维我的大数据。
ALPS介绍
我们内部做了ALPS,我们希望有一天可以轻轻松松的站在阿尔卑斯山顶上俯瞰大数据的世界。有同学说我比较喜欢阿尔卑斯奶糖,所有取名阿尔卑斯。
我之前做了很多尝试和产品,用两个人如何解决几百+的机器,包括物理机、跨IDC,我一直在思考并整理市面上开源的东西,我们肯定不能完全自己研发,也不能用太多的组件支持现在的大数据业务,为了运维大数据的业务而带来运维需要学习更多的组件,我们没有这么多的投入产出。那时候我们把整个运维需求进行精简,如果有基本的运维需求,我们应该具备哪部分,包括配置管理和资产管理是我们传统说的CMDB,监控系统要可监控、可报警,我们在做批量作业时需要批量作业的工具,包括Puppet、Ansible等。我们希望有一天可以跟AI结合,现在没有太好的尝试,毕竟就两个人,但不代表我们没有这个心。
这是我们目前在开源采用的系统,我在这些系统里选择,没有一个系统可以解决我们三个运维问题。Puppet、Ansible解决的是批量作业的问题,Falcon、Elastic、Prometheus解决监控报警问题,CMDB目前没有更好的开源产品。如果要实现这三个基本诉求,我需要开发、维护三种产品,让我的同学学习三种产品,比较浪费人力。有没有一个产品或者一个工具具备这三个特性的雏形,让我们以后可以频繁的迭代、持续的迭代,做出更好的精品。

直到有一天,我发现一个产品——Consul,这家公司做了很多产品,在运维领域,Consul解决了很多问题,它给我们很多启发。这个东西可以让我们以后做得更好。
CMDB完全基于Consul来做,监控报警是基于Consul服务发现做的,我们的作业平台也是基于Consul做的。大家回去可以了解Consul,在很多地方做得很好,可能没有非常完善,它的UI做得不是特别好,但它的核心竞争力解决运维上遇到的所有问题。
我们没有做AI+ALPS的尝试,一直播、小咖秀未来应该把更多的用户服务好,给他们分发更多的优质内容,形成良好的产品体验,而不是告诉他我的大数据平台运维得多么好,这偏离是我们的主业。这是典型的是大数据业务部门如何选择和运维,大数据业务部门和运维分离,由基础运维独立运维你的产品,还是由基础运维运维你的大数据组件,还是由大数据业务团队自己掌控,当中有很多不同。大数据业务团队自己运维,可能面临不太懂运维,我需要掌握运维产品和运维能力,而运维去大数据产品面临的组件那么多,他不了解大数据业务团队包括开发人员所面临的需求和挑战,往往会产生碰撞。如果能够自己做,尽量减少沟通,在一个团队内解决问题。我们团队用一个简单的产品完成自动化运维和运维平台的建设。
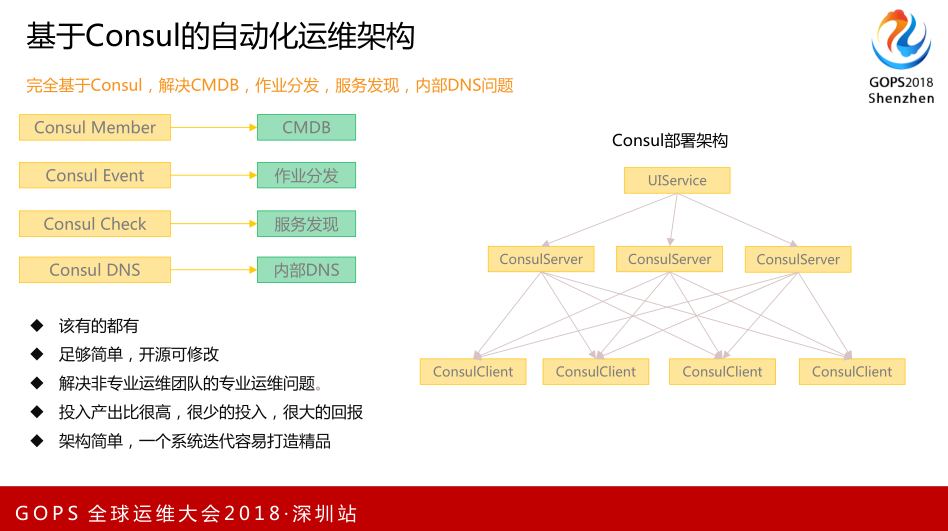
基于Consul,我们做了自动化运维架构。我们用Consul Member解决CMDB,可以动态发现节点,动态摘除。Consul Event解决作业分发问题。Consul Check解决服务发现和监控的问题,基础监控是公司基础运维团队和应用运维团队共同承担的,大数据里有很多基础运维团队不太了解的,他们需要一定的学习时间,我们需要更多的学习运维知识,我们需要把大数据组件的运维转换到到自己团队身上。在业务上会遇到很多问题,一般情况下由我们自己解决,解决后会发现能否尝试我们自己监控,把它做成自动化,保证我们业务的稳定性。所以我们用Consul Check做了监控系统,这只是简单够用即可。用Consul DNS解决内部DNS问题,我们面临很多大数据节点上下线时的解析问题。总结来说,Consul自动化运维架构有Consul Center Server集群,每一个大数据数据业务节点都会安装Consul Client,完全用Consul实现。我们在UI Service上做了改变,让运维更直观的使用产品。
Consul的架构该有的都有,像CMDB、作业分发、服务发现和内部DNS。足够简单,开源可修改,我没有使用大量的产品,我的两个大数据运维工程师完全可以Hold住,甚至将来可以做得更好。解决非专业运维团队的专业运维问题。投入产出比很高,很少的投入,很大的回报。去年12月份至今大数据业务和故障率并没有因为用了Consul后有多大的提升,它就是稳定,不怎么出问题,它能解决的问题都解决了。更重要的是架构足c够简单,一个系统频繁的迭代容易打造精品。可能我们团队将来也会一直往这个方向发展,做类似阿里Tesla的产品,解决企业化部署和企业化交付问题,短期内不会做,我希望把这个想法传递给有同样问题的公司,商业化的公司会帮我们产品私有化部署和落地,选择运维产品,我希望架构简单的思想可以传递给大家。

在CMDB上,Consul Member是怎么做的。它利用所有节点加入其中,自动跟Consul client做连接,定期汇报状态,这是完全它自己做,不需要我自己研发。很早之前,我在其他公司做过CMDB产品,管理过市场上7、8万台机器。当有服务变更后,CMDB与机器之间的联系和状态的更新无法做到同步,用户在CMDB上查询某一台机器,发现在第一个IDC,其实他早早的迁移到第二个IDC,可能是流程没做好,也可能是IDC建设的人和运维平台管理的人没有沟通好,我不知道机器在哪里,不知道他们的状态,不知道他们部署了什么服务。百度最早做服务包,现在做自动化运营、CMDB,我需要在这方面解决,梳理我们的业务和资产,方便后期做自动化运维。
我做了这么多年后发现,投入这么多人,做的东西反而不好。我感觉在运维方面需要在客户端做Agent,解决动态变更、自动发现、状态探测等问题。
一直播、小咖秀更多的关注用户和产品,不会有更多人力投入到这个方向,我需要有这么个产品解决这个问题,Consul Member的特性完全可以解决这个问题。我们可以在一个产品之上频繁的打造,持续的迭代,和不同的公司、社区沟通,建立良好的关系,解决我们未来要做Agent,未来要做动态变更、自动发现和状态探测的问题,把以后和未来的想法全部变成现实。
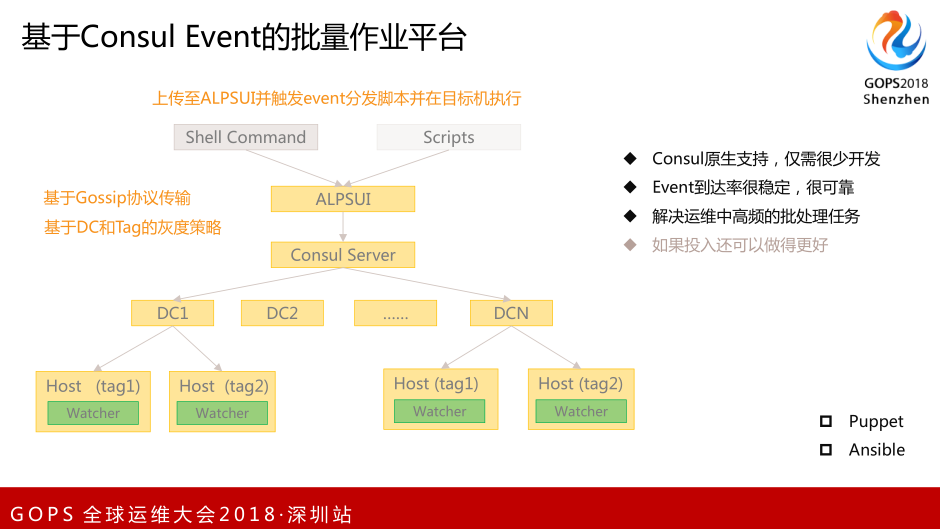
在运维过程中,我们要批量执行一些东西,在一些节点上执行动作、脚本、Job,这个Job是指我们运维要做的比如批量清理日志、批量配置变更、批量状态服务的迁移等。很早之前,我们团队用的是Ansible和Puppet,我不想让我的团队再引入一个新的东西,我想Consul能否解决,结果发现Consul Event 非常不错,它利用Gossip协议,完全基于UDP,他们之间在同一个集群内通过Gossip协议进行沟通。简单的讲,一个事件通过任何一个机器、任何一个Agent、任何一个客户端或服务端都可以触发。触发事件后,每台机器都有成员列表,会优先在alive状态下的机器,寻找三台活跃机器,这三台机器会发给另外三台机器,收敛非常快,在局域网内如果延时足够小,基本上是毫秒级的就可以把事件广播到全网,不需要我和你之间一定要通。这台机器和那台机器有策略、白名单、路由、网关等问题,只要我这个节点和你这个节点之间有一台机器能通,这个事件就能过去。
基于Consul Event做了我们自己的作业分发平台。核心是利用Gossip协议把事件下发到每个Agent,Agent端会有Consul原生的事件触发管理功能,它可以执行一个脚本。当它可以执行脚本后,我们可以在脚本上解决很多东西,包括作业分发和个性化的东西。Consul更重要的特性是多DC管理的工具,可以解决不同DC与DC之间的配置共享、事件下发、策略下发。我们之前在做服务树时,大家会做自动化运营平台,频繁提到服务数概念、服务与服务之间的关系,服务与服务之间的依赖,那时候更多的是通过像CMDB类似CMS的传统管理方式去管理服务之间的关系。
Consul利用Tag,为某些机器打一些Tag,当你触发事件时或执行动作时,利用Tag的机制只感染一小部分的机器,就是你的目标机器。我认为这是够用的,我们现在用起来非常舒服,只需要把日常工作抽象好,开发脚本后分发到每台机器上,在任何一台我自己的操作机上执行自定义的Consul命令,自动执行脚本,部署Hadoop或者做其他的东西。把我们批量作业的工作全部转移到Consul平台上。之所以没有选择Puppet和Ansible的原因,希望我们运维人员不要解决它本身的问题,包括打通SSH等,考虑众多复杂的东西。我希望他们专注于一个点,如果把一个点做足够好,这个点可能会变成精品。Puppet和Ansible某种情况来说比Consul强大,这只是一种业务场景下的选择而已。个人认为Consul带来的作业平台,优点是Consul原生支持,只需要很少的开发,很稳定、很可靠、很快速。
现在不管是高校局域网还是我们的广域网,Consul都很好,主要得益于Gossip协议。我们之前在CDN领域尝试过用Gossip协议做全网状态的探测。同时可以解决运维高频批处理的任务。如果我们要投入更多人的话,肯定还可以做的更好,包括改Consul的源码。我们团队能做,但现在不想做,原因是够用即可。

Consul DNS与Hadoop的集成,在阿里、搜狗和很多公司不算问题,但在处于高速发展期的公司说,这个问题是普遍的。有一定规模的公司,他们管理Hadoop节点时,大部分用Host做解析,每次资源变动都要一定要下发ETC Host的文件,让每台机器知道你是谁,我是谁。其他业务部门要用Hadoop平台时也要更新。这些问题在大公司是不用谈的,很多创业公司和发展公司还是需要考虑的。Consul本身可以解决很多问题,在这个点上,我们做了一个它跟Hadoop的集成,所有机器部署完Consul后,自动获取Consul node名称,该名称自动解析,不需要管理ETC Host。Consul自己有Server,只做A记录解析,其他的没有。这是HashiCorp公司专门提供的Consul DNS服务。所有新节点加入后Consul会自动解析,我们与自己内部DNS打通,包括新节点加入、服务都是标准化的,连节点名称都规划好,再也不用去管理看起来很头疼的ETC Host。偏初创的企业是可以考虑的,这是我们一直想打磨Consul的原因,让它更多的功能结合我们实际运维。

下面分享一个Consul DNS服务发现案例。在互联网公司的互联网发展,像LVS、SLB和其他的服务发现、负载均衡的产品大量被服务发现,etcd、Zookeeper也是如此。Consul本身自己做服务发现,如何用Consul DNS做服务发现和故障的自动切换。我可以把一个服务注册到一个Consul上,解析域名时会返回三个地址,分别是同一个服务有同一个域名,当这个服务不可用时,我们根本不需要做其他东西,这用的是Consul内部事件感知的技术,它可以动态的在解析里摘除,内部看延时是秒级的,这个特性可以应用于很多场景,你可以自己掌控很小的服务发现和自动切换,以及简单的负载均衡产品。当我们有更多的业务加入时,我们的业务没那么大,没有大到像BAT级别时,没有一秒钟几十万并发时,我们不一定要尝试别人走过那条路,那条路的艰辛是从最简单的层面而来的。有时候把一件事做得简单,用简单的方法解决问题时,带来的收益可能更高。当一个请求过来时,它用Consul DNS解析,拿到三个服务的解析,如果一台服务挂掉了,它会自动摘除,请求就会到其他的节点上。
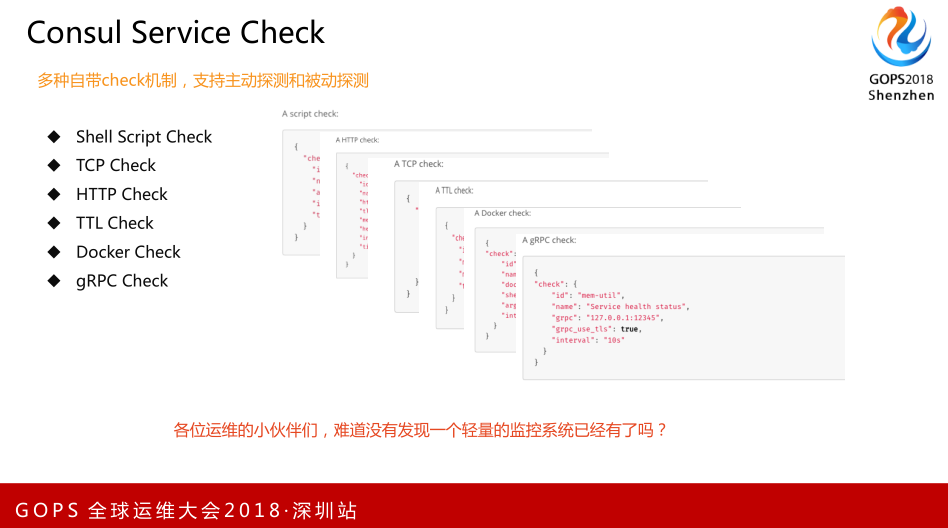
我们在一个运维平台上需要有监控和报警,我们需要做监控系统的开发。Consul本身支持Shell Script Check、TCP Check、HTTP Check、TTL Check、Docker Check、gRPC Check,利用这些check,我们可以做采集节点和采集工具,就可以采集到我们需要的东西。有时候我们去用小米、Prometheus、zabbix时,有的天然集成的包我们可以用,但有很多时候我们需要定制化监控某些服务,这时候运维人员只需要写一个简单的脚本,可能不需要很多的开发能力,写了一些脚本采集信息把服务监控起来,就可以用Consul Service Check去触发和管理。大家可以看看这个服务。
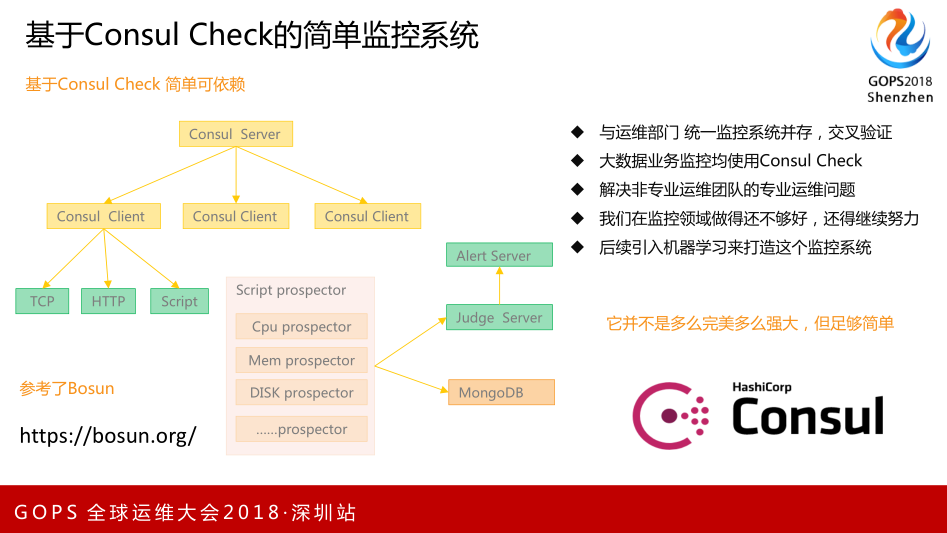
这是我们自己利用Consul Service Check做的简单的监控系统。在Consul Server基础上实现了TCP、HTTP、Script数据采集,我们自己写了一个监控服务和判断服务,把所有的数据存到MongoDB。它并没有很强大,它只是很简单、很够用,最核心的点和整个的骨架都是Consul完成的,报警、业务是我们自己开发的,也是我们自己需要做的东西。核心是如何采集,采集时有很多监控脚本,有没有现成的。我们参考一个产品是Bosun,里面有很多开源采集的Linux、Windows,特别多的采集。之前TSDB和其他开源监控工具都是参考它很多思想和源码。里面很多源码可以直接拿出来写成脚本,放在Consul上直接运行。
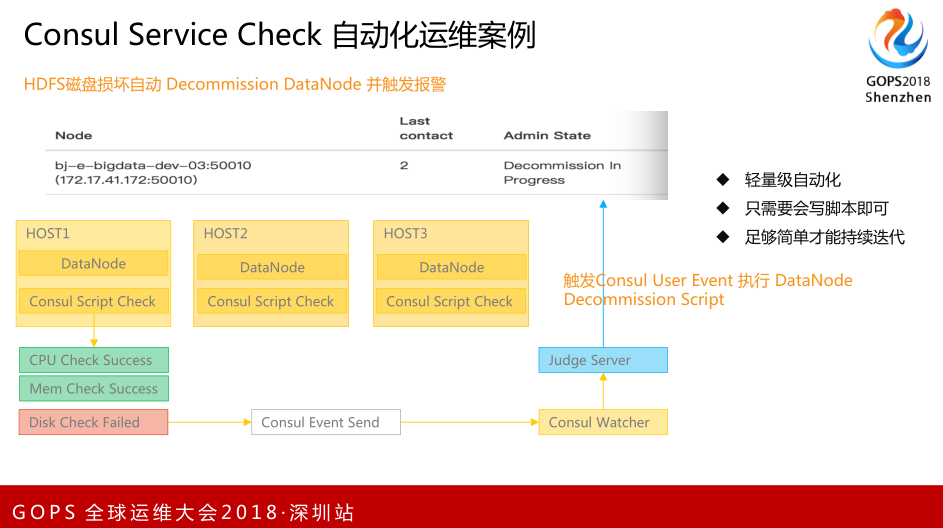
这是Consul Service Check自动化运维的案例,来启发大家可以利用它做很多东西。这是Hadoop一个节点磁盘损坏的时候如何让它做自动化的东西。简单来说是事件触发,自动调Consul Event事件,它会把具备磁盘损坏的节点,自动触发下线的操作。整个思考是在Consul的生态环境内完成的操作。我们只是在讲Consul的特性,大家可以利用Consul Event、DNS、Member等,自己来组织,就像我们去菜市场采购很多东西回家,自己做菜一样。
如果还有明年

如果还有明年,我希望跟大家分享我们在大数据开发套件CloudAtlas产品上的经验。我们把数据处理,内部叫TT,意思是解决传输和转换的问题,其实就是我们常说的ETL,大部分初创企业更多的在ETL领域做大数据的尝试。我们未来想跟大家分享大数据集成服务下,包括自助式开发套件和基于HBase做的数据仓库。我们希望让产品和运营轻松掌控海量数据,就像操作Excel那样轻松。让开发真的在开发一款产品,而不是每天在写Excel、SQL,让数据更加开放,才能让更多人通过数据去转化其价值,提高数据真正的价值。
