@gaoxiaoyunwei2017
2018-08-28T06:19:50.000000Z
字数 9403
阅读 1220
DevOps后军:腾讯企业级持续运维实践体系与工具平台--梁定安
黄晓轩
讲师 | 梁定安
编辑 | 黄晓轩
讲师简介
梁定安
腾讯运维总监、腾讯织云负责人、腾讯学院讲师、腾讯云布道师、DevOps专家、高效运维社区金牌讲师、复旦大学客座讲师、《DevOps三十六计》主编之一。
运维体系化建设的经验丰富,在腾讯SNG负责运维自动化、立体化监控、智能化的运营规划与团队管理工作。在腾讯云toB业务,负责运维解决方案织云产品输出,参与了多家大型企业运维一体化项目。
前言
容器代表了未来,他给整个行业提供了一个标准化的方法,让工具和工具之间可以更好的去沟通。以前传统的企业级的解决方案,更多的强调是买一个东西回去,我给你做好了,你只管这么用,但是实际上,特别像互联网这种企业变化一天一个样。我们现在在当下强调的一些工具、产品,必须要可定义、可编程,不管你是用开源的产品实现,还是用商业化的产品。我们现在应该用一种全新的视角去定义我们的软件级的产品。
我今天跟大家聊一下腾讯企业级持续运维的实践与工具平台是什么样。之所以说是企业级,是因为我们现在在谈很多云计算,云原生的技术,包括Docker也是新的技术,但是我们没办法否认一个很现实的问题,我企业本来就存在了,我怎么样把我整个技术体系朝未来的一个方向去变。希望我这个分享可以给大家一些思路。
今天主要跟大家聊三个内容:
- 用云量上升带来的运维问题与解决方案。未来的基础设施,无论是公有云、私有云还是混合云,这是必然的一个趋势。怎样解决运维带来的问题。DevOps怎么样把你的需求从项目管理、代码管理,通过Docker,通过CI发布到生产环境,发布到生产环境用户在用了,从运维的视角,我觉得整个过程才仅仅开始。因为你还要面临着后面的运营、监控、反馈等等一系列的问题。我们只是说现在在云计算这个时代,把这些问题从传统的数据中心搬到云上,要怎么样解决。
- DevOps持续交付运维技术发展路线。DevOps强调的持续交付,对于运维,我的技术怎么适配他,才能帮助我一步步相对平滑的往云上切。
- 构建异构监控下的智能化持续反馈。AI是未来,AIOps是未来的一个趋势。在整个技术发展的过程中,能不能够为将来的AI化埋下一个伏笔。
01 用云量上升带来的运维问题与解决方案
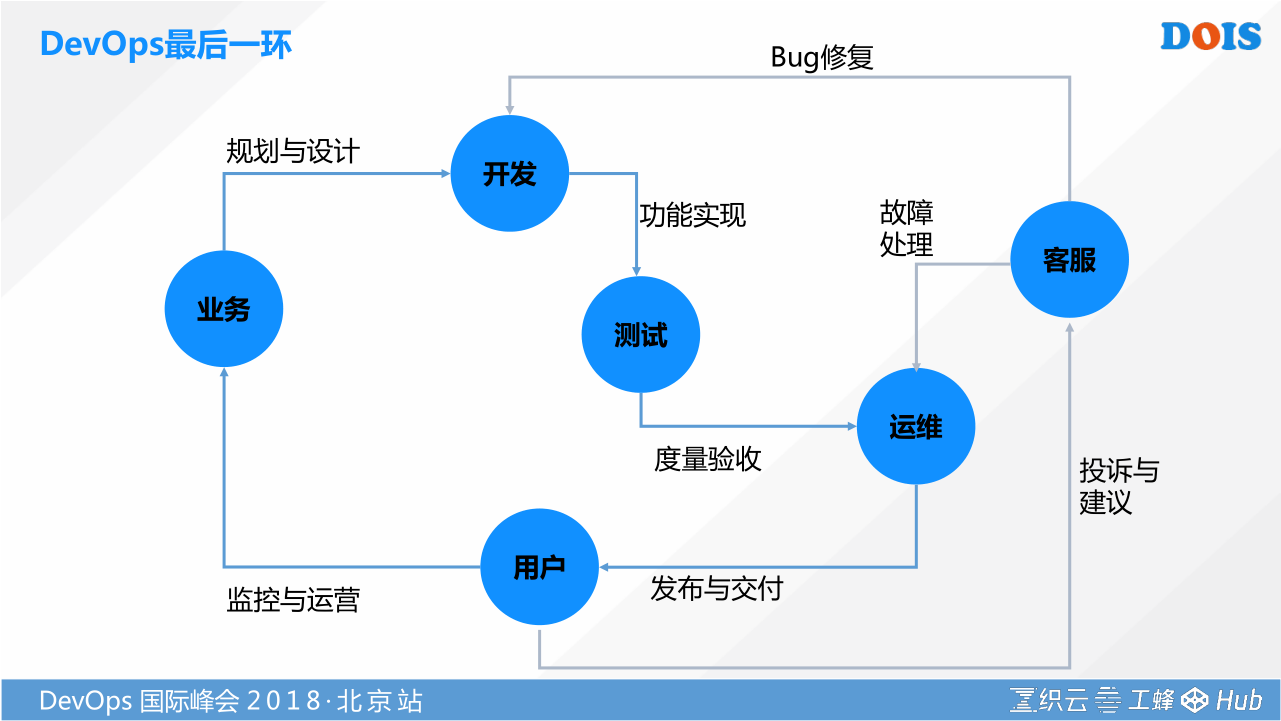
我是做运维的,就是处于最末端。在DevOps最后一个环节,我们承担的意义和作用是很大的。
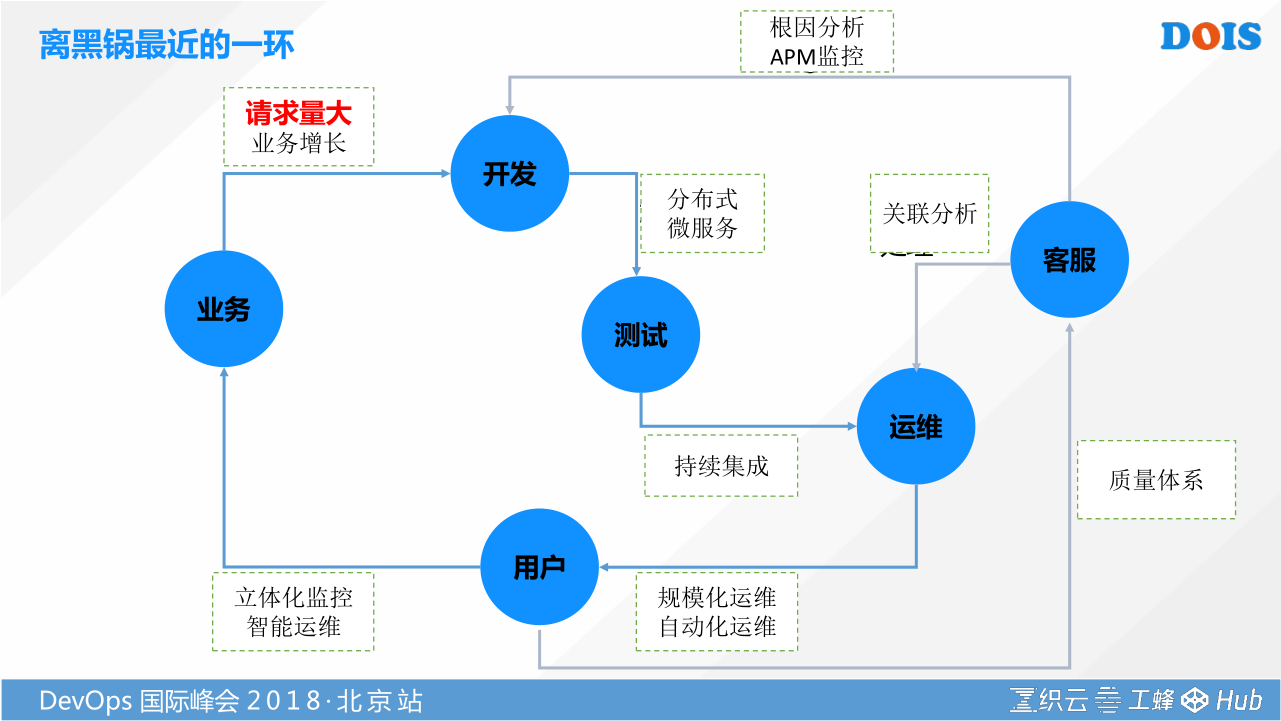
人在家中坐,锅从天上来。为什么会这样呢。因为我们随着业务跟云、跟互联网技术、跟互联网业务形态不断的结合,所以我们的业务势必会遇到一个问题,就是并发量会不断的增大。你的业务增长,你的开发的模式从原来的集中式一定会朝着分布式、微服务去走。然后你的测试又不断通过一些持续集成的工具去提速,最后整个企业的效率瓶颈就在运维。你不仅仅要解决每天业务由于新特性发布要处理的一些变更工作,不断的要构建环境,不断的去部署,不断的跑一些批量的脚本,你还要面对的是每天监控给你带来大量由于分布式,由于云量增多,带来大量监控压力的挑战,怎么样去解决。

我今天跟大家一起在这儿探讨一个传统的企业,如果你要朝这种新型的云计算的架构去走,你必然会遇到的四个运维的难题:
- 设备托管,多个机房,链路复杂。你的设备慢慢由托管变成交给云厂商。之前友商出了一个故障,锅就甩给运维,我不追究他究竟是什么原因,但是他说明了一个问题,鸡蛋不要放在一个篮子里,后面必然是多机房、多云管理,这时候你怎么样解决混合云管理。链路变长之后,你的关联分析和根因分析的问题。
- 外购软件,无法标准化,难以保障运维质量。其实现在整个企业的IT都在找寻一个标准化的方案。标准只会带来一些僵化,怎么样去解决最轻量的标准,又能够让我们工具最大效能的去结合起来。这是我们要面临的一个问题。
- 硬件运维思路,转型自动化运维过程艰难。大部分企业过去的运维团队为什么他的效能没有像互联网这么高。我觉得有很大的原因是很长一段时间都是在建设一个能力,就是头痛治头,脚痛治脚的能力,但是这些能力没办法相互打通,就很难走到自动化智能化的时代。
- 非代码级变更,规模化业务对持续运维的挑战。除了代码级别的变更,每天运维还要负责大量的变更,这就是规模化带来的挑战。我每天可能20个人维护集中式的主机,但是现在是分布式的,拆成1000个服务,还是20个人维护,相当于一个人维护几十上百个服务。这个时候我的思路如果不改变,工具不改变,就没有办法适应这种挑战。
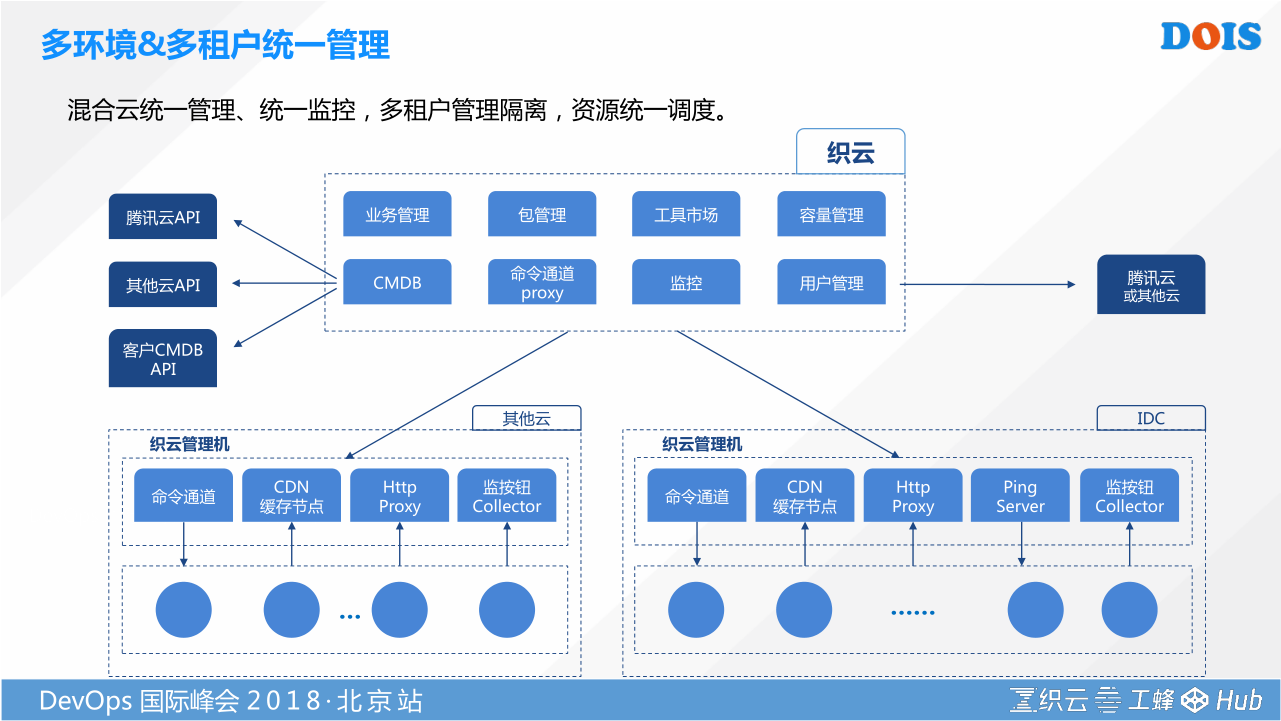
织云在这样一个多云、混合云的挑战下,我们首先提交给我们客户的解决方案,就是我们的多租户、多云的管理能力,来为我们的客户提供这样的方案。这个方案包括几个层面的技术。
第一,我们要有技术手段去连通我们各个云平台。如果大家把运维看作是在基础设施联合的最紧密的一个角色的话,我们必须要有能力去实现我的文件传输。你怎么样去从管理到你传统数据中心,管理到你的腾讯云,管理到你其他的云。怎么样去管控他,怎么样传输命令给他,特别是对我们传统一些企业级的客户,我们还不得不面临一个问题。我如果是一个集团,就像上汽集团,他底下有30多个子公司,每个子公司都得独立一套结算的方式,独立一套成本考核的方式,独立一套运维管理的模式,这时候是我们混合云统一管理所需要的问题。织云通过跟各个云API网关的打通,通过我们C-S架构的传输方法,我们可以直接连通不同的云。如果是公有云的模式,我们还可以走外网反向代理的形式去管理到你。
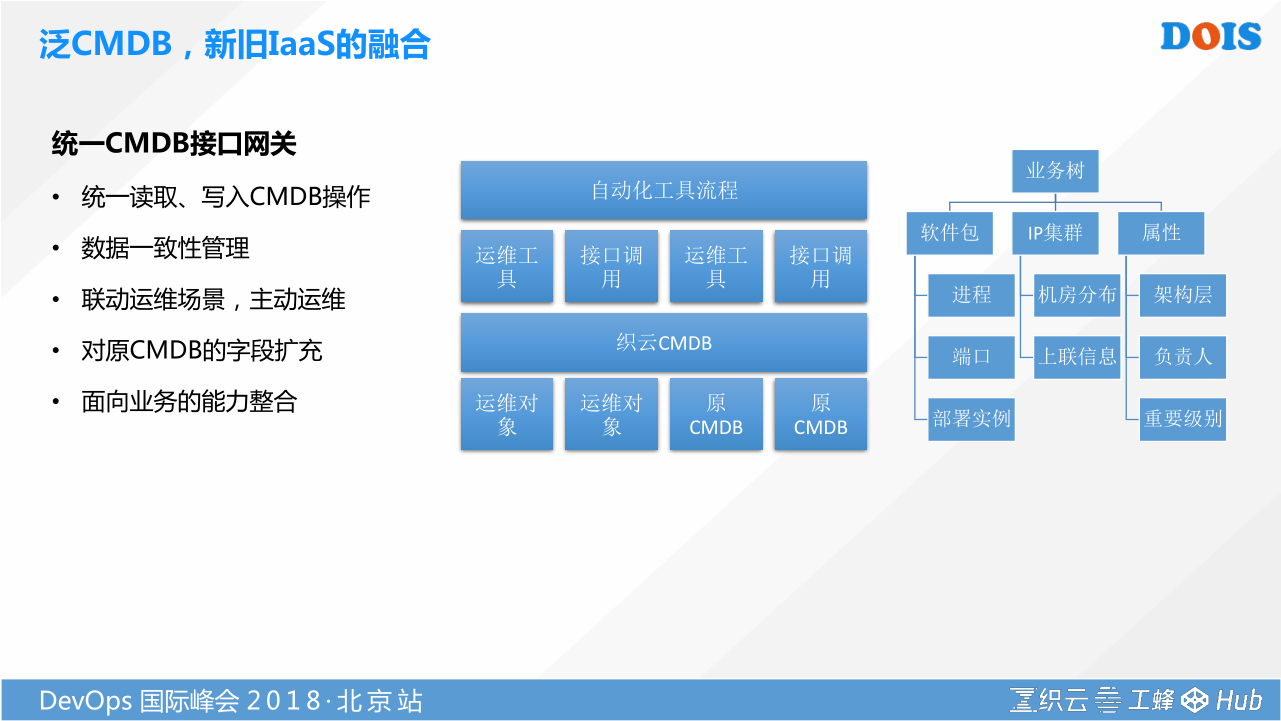
这个时候我们遇到了一个问题,多云管理怎么很好的去标识。你在不同云,我需要用什么样的方式,究竟你是用外网代理的方式,还是用IP直联的方式,我跑不同云你的配置是什么样子的,你的操作是什么样子的。这个时候我们提出了一个泛CMDB的概念。在运维领域,有越来越多解决方案的厂商,他们都会有CMDB,但对于传统企业要解决新旧技术的融合,他没有CMDB是不可能的,可能会有很多个版本,不同的团队有不同的CMDB。这个时候我们提出了一个泛CMDB的概念,是一个解决方案通过提供CMDB统一的网关,来解决统一读写的问题。腾讯有自己基于自身这种大规模运维解决问题的场景,我们提炼了一个通用的CMDB数据模型。这个模型预估可以解决70%-80%的问题。针对企业的个性问题,我们可以通过融合企业不同的原来CMDB所纳管的对象,然后通过统一的接口,让我们更上层的一些自动化的工具更好的消费,从而实现我们接口的统一和数据一致性的管理。最终是要让我们的运维场景,让我们的工具编排之后,能够不断的去消费我们的CMDB数据,从而让我们CMDB真正具备生命力和活力。
02 DevOps持续交付运维技术发展路线
讲完这两个基础,由于上云量我们要解决的技术问题,我们接着来聊聊真正运维我要解决的并不是说怎么样去设计好我的CMDB。我要解决的是整个技术路线怎么设计好,帮助我一步一步走上未来的架构。
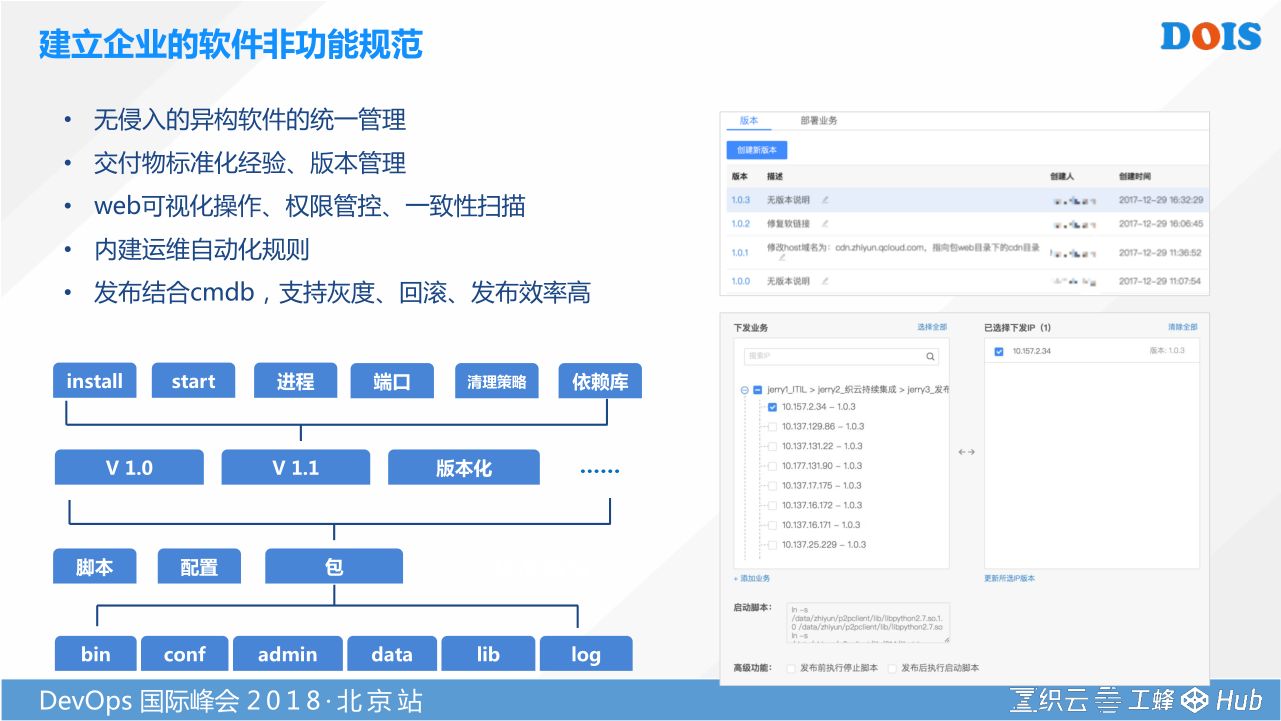
对于很多传统的企业来说,架构并不是从0开始的,所以他从以前软件包管理的模式走到容器的模式,势必要有一个过程。这个过程他可能会长期存在。这个时候,我特别希望用腾讯自己的实践案例来跟大家介绍一下。腾讯我们有一个软件包的管理方案,这种软件包的管理方案针对的是以前的制品库怎么发布到生产环境的方法。这种方法我们把他称之为运维发起非功能规范的管理手段。其实很好理解,我们通过打包的方法,把我们的每次发布所需要用到的一些配置文件、Lib库、插件、脚本,通过一定的方法组合成软件包。同理可以运用在我们的配置文件和脚本。通过平台提供的这种版本化,还有集中式的传输、编排能力,让他更高效的完成对发布的管理。但是可以思考这样的一个场景,在传统的架构下,如果我仅仅是要扩容一个服务,或者说我需要去批量的修改一个配置文件,可能我们前面不需要走整个CI的过程,他是纯粹一个运维的行为,或者我要打一个补丁,这个时候我们就需要统一的方法。在多云的场景下,有可能会用到很多技术,就像文件压缩、文件分片上传,甚至是P2P,因为有时候在腾讯的场景,我要传超过10万个节点的场景,怎么样去解决。这就是我们提供出来的一些成型的经验。大家如果继承这样的一个经验,首先可以版本化,其次就可以让工具和工具之间更好的理解这次操作他目标的对象究竟是什么。然后通过跟CMDB的结合,你可以看到,他是直接可以关联出我的软件包所需要去操作的一个IP范围在哪里,而不是像以前我们贴IP。如果我贴错了,有可能会产生一些故障。这就是我们建立企业非功能软件规范能力。
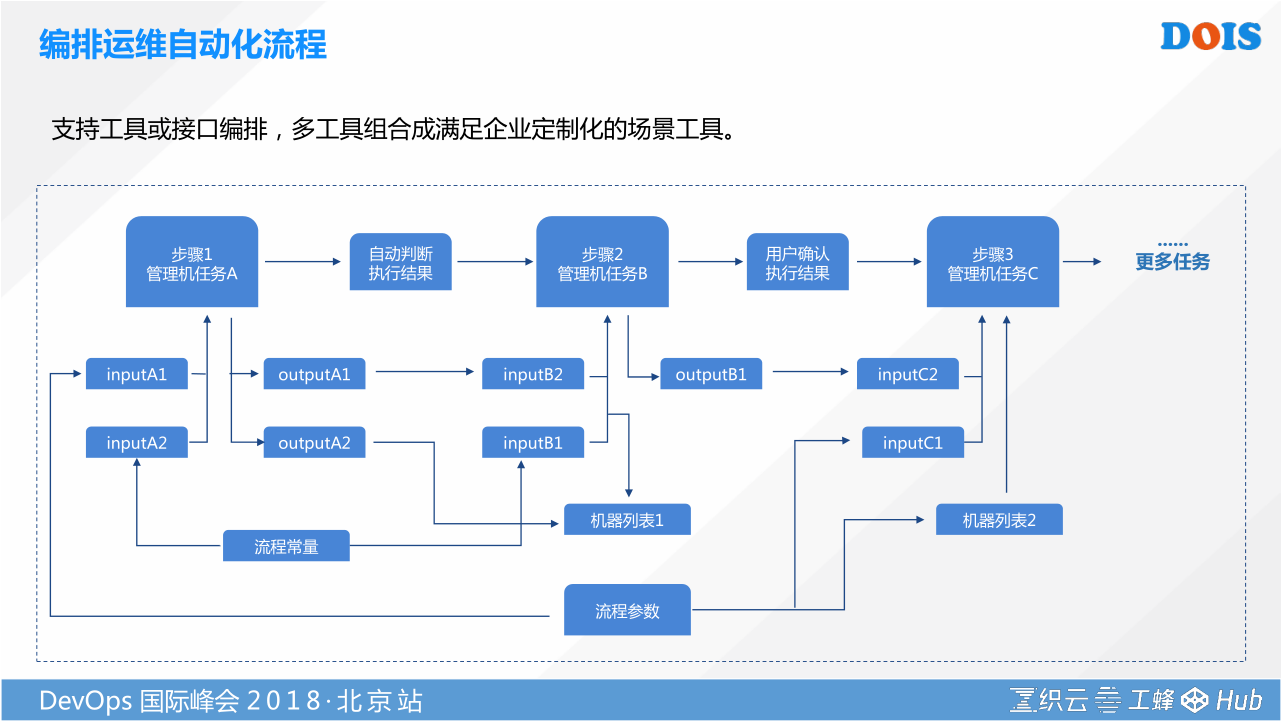
建立非功能软件规范能力之后,我们有了一个统一操作软件对象。那怎样知道我每次运维的动作,每个场景究竟怎么做是最适用。并不是说腾讯基于自己的实践做了这样一个电子流,要求所有的公司都要遵循,这不现实。我们在织云里面提供了一个针对运维场景的工具编排工具。我主要介绍一下,他服务于运维场景的这种操作。运维是一个组织,并非个人。任何组织他要高质量高效的完成一个工作,他需要这个组织下的每一个人都用同一个方法完成这个事情。我们又希望通过提供运维解决方案,让组织具备可编程可定义的能力,这个时候抽象的看,运维所有的场景都是由若干个工具,或者说若干个运维系统接口的调用,通过编排来实现。究竟我是走一个审批流程,他才能自动的跑这个工具流,还是我通过一些监控数据智能的决策和触发他做这样监控流。这就取决于我们对场景标准化的抽象,如果能放给机器自己去做,就调用机器的一个接口去做。 更多强调的是,让我们具备可编程、可定义的能力。
刚刚讲的两点主要的:首先,我们把运维的管理对象,通过包管理的手段,把他构建成一个软件包。你可以认为是一个逻辑意义上的容器。其次,通过我们的编排,实现了包怎么样传递,传递之前我是不是要屏蔽告警,是不是要写CMDB,是不是做完之后我要写一个通知告诉谁,这都是工具编排的过程。
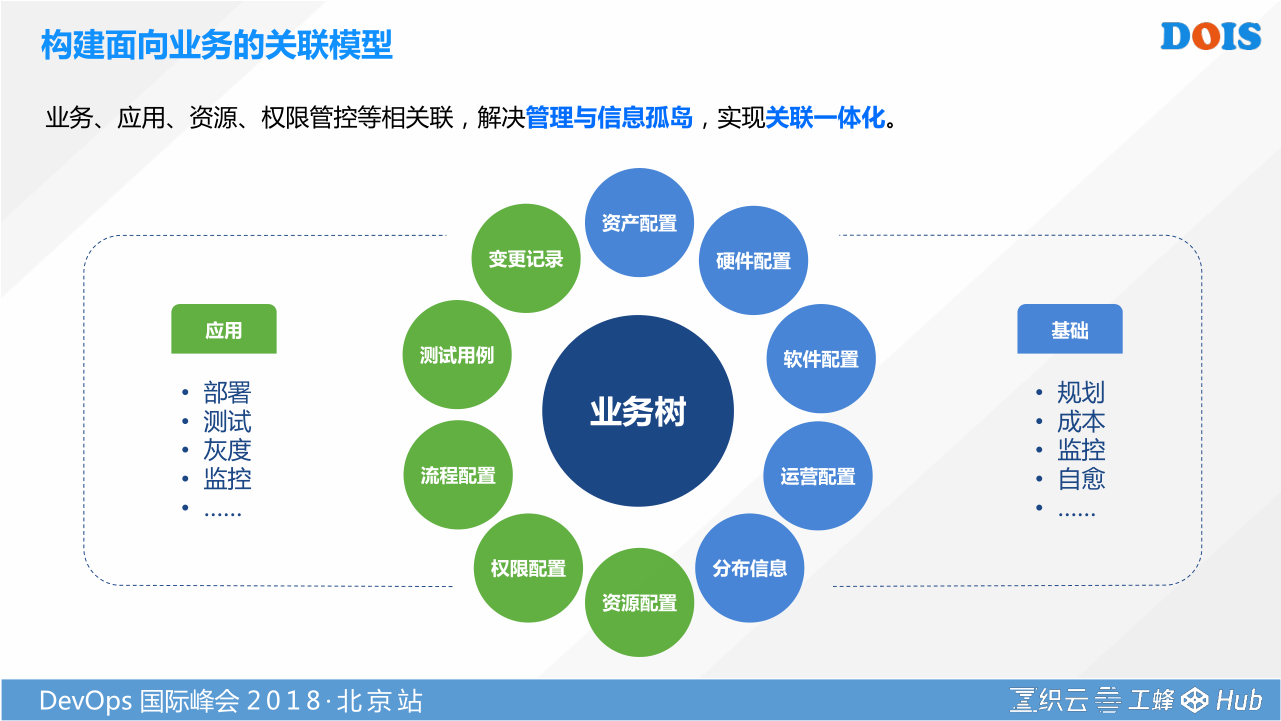
在基于泛CMDB的结构,我们希望运维做每一次场景化工作的时候,都能把信息打通,这是我们解决的一个方法。我们通过CMDB管理模型,把运维每次操作管理的节点抽象出来,把他称之为业务树。每个业务树会有叶子的节点,就是我们每次变更,站在分布式服务的角度,每次都是对服务的一个变更。这个服务会在CMDB模型里面记录两部分核心的信息,就是他的基础信息。基础信息可能跟IAAS息息相关,类似资产、硬件、软件、云服务商等信息。运维工具识别到云标签时,要知道调相应的API。还有运营配置,运营配置就是这个服务,或者这台设备的响应级别是什么,负责人是谁等等。还有应用配置,应用配置就包括资源配置。资源配置是软件包是什么,配置文件是什么,甚至是我发布依赖的容器是什么,还有权限的配置,谁可以来操作。这个应用部署之后需不需要去统一的权限门户那里申请权限等等,还有他的操作记录。
我们通过对基础配置项和应用配置项的抽象,把这两者结合之后,可以把运维的一些工作、场景都抽象出来,消费这两者的数据,就可以实现某种场景的自动化。
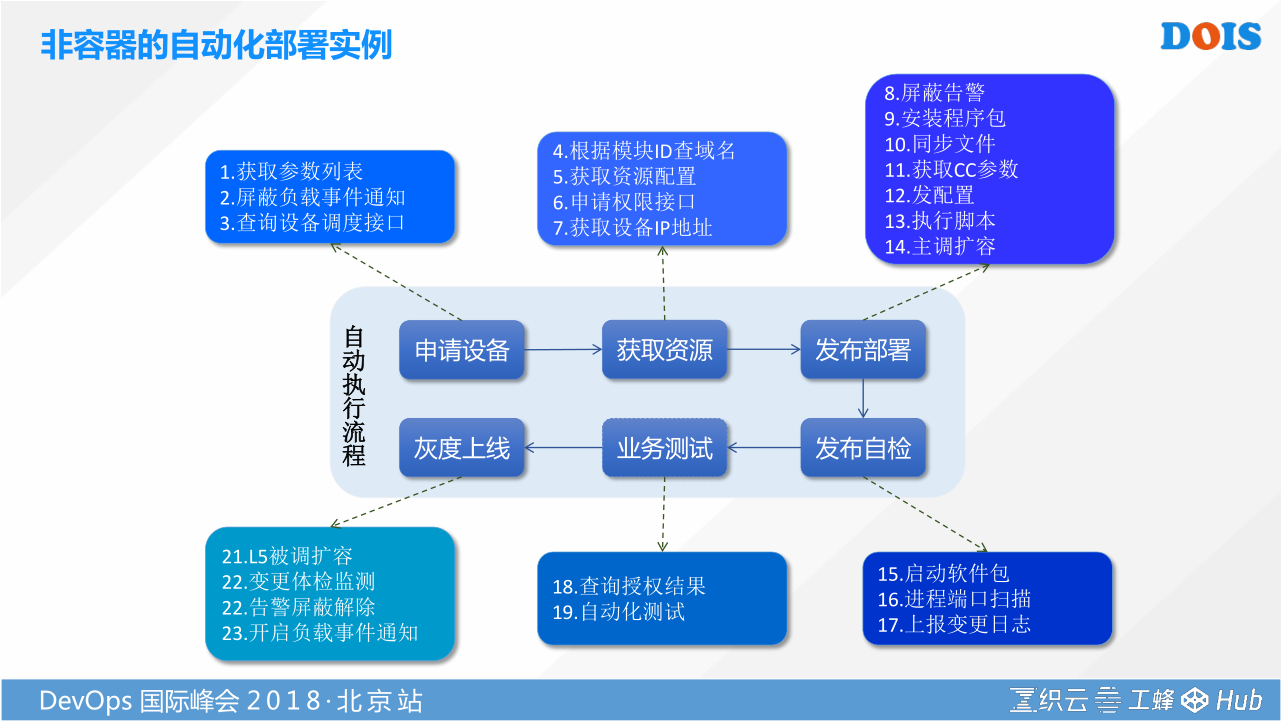
这里举了一个在非容器自动化部署的案例。大家可以试想一个场景,假设生产环境某个服务的集群,他的CPU高负载了。我现在要对他进行一个扩容部署。如果简单的来看,他是6步操作:申请设备、获取资源、发布部署、灰度上线、业务测试、发布自检。事实上在腾讯里面是把这六大步拆分成23步的这种最原子的一些功能进行编排,从而让这些具体的一些工具,可以被最大化的复用,被最原子化的抽象,以此把我们的经验传递,提升运维的效率。在提升效率的同时,我们也保证质量。
【图:无人值守自动化流程执行案例--当突发流量到来】
这里是截图的一个case,我们经常遇到这种情况,当他的流量突发,会产生告警,这种告警产生之后我们是不是自动或者由人点击一个按纽,自动把这种规则的方法推到我们生产环境,从而解决我们的一些运维每天要去救火的问题。如果做到这一点,是真正意义上运维的自动化。
【视频部分】
这里我有一个小视频,帮我播一下视频。
(播放视频)
我刚刚讲了很多,我们专门在腾讯内部录了这样一个视频,其实这个是织云无人运维的能力,刚刚我们基于我们的CMDB模型,可以在我们平台基于我们的业务树去绑定这个业务树所需要的资源,这是一个规划的过程,绑定了依赖的软件包、基础Agent、依赖的配置文件、依赖的脚本,可以通过我的编排,把这样一系列的脚本,通过一些公共的能力,例如传输、执行、验证、发通知的这种方法自动化的执行。
接着,录入完资源之后,我们是给我们的服务来进行了压测,大家会看到他的请求量会逐步的上升,逐步上升之后我们会收到企业微信的提示:你的服务高容量了,我们正在后台帮你自动的扩容。自动的扩容,我们已经按照我们提前的运维标准化的要求,已经编排了一个过程,去解决他,他就会一步步的通过编排系统传参入参,通过CMDB不断的读取对象所需要的输入参数是什么,然后我们会不断的收到企业微信弹窗提示:我现在已经扩容完成、部署完成、质检也OK、我现在要灰度上线。甚至是基于这样的能力,你还可以包装出更丰满的功能,例如你可以包装出你发布的体检,灰度的过程还需要看哪些参数,来逐步的让人的经验能够让我们的工具完全的都继承,这个方法就是基于我们的数据模型还有工具编排去实现的。
【视频结束】
这是我们对持续运维能力的一个产品化的包装。
03 构建异构监控下的智能化持续反馈
运维每天的工作,除了要去处理很多需求,无论是这个需求源自于业务的上线,还是源自于我自己安全、打补丁的一些需求之外,还有一个很大的需求,就是要监控服务,保证他的质量。

在腾讯我们很早面临到了一个问题,运维人员很少,运维对象的规模越来越大,就带来一个问题。如果用传统的头痛治头,脚痛治脚,我发现这个点有质量问题,就部署一个监控系统,这个监控系统可能是监控主机的,一个主机监控可能有上百个指标,为了实现立体化监控,我就会有很多监控系统。很多监控系统直接带来的问题,就是监控系统是不是没有误告警,都很精确。如果你都是准确的,但规模很大,云很多。假设每个监控都很准,但是他全部发出来的告警,有原因告警、现象告警,这些告警都是准确的,都是命中了一些阈值或策略。然而我的运维人员已经去到一种状态,是看这种监控信息已经看不过来了,那怎么办。
这时候首先我们要解答几个问题:
基础监控。我们的监控是不是已经立体化的去覆盖了。在腾讯,我们习惯性的把监控按层次去划分,从基础监控开始,他覆盖了网络监控、主机监控,这在腾讯云企业级的解决方案里面都有包括。
组件监控。因为我们有很多云组件,有很多中间件,这些组件是不是可以基于一个不需要通过理解他的业务逻辑就可以监控他服务的情况,这是对业务深入程度的不同。
日志监控。
应用监控。
下面四层的监控都是头痛治头,脚痛治脚的监控。
数据银行。就是因为这里的点部署的太多,直接导致了人已经看不过来了。这个时候我们提出一个数据银行方案。说白了就是运维大数据平台。他解决的是异构数据实现统一的接入,通过一定数据的索引和规则,可以把这种数据进行一些组装,进行一些维度的拆解,升维或降维,再经过一些异常识别的方法(阈值、环比、同比、统计、AI等),最终把他输出图表或者告警。
端到端。端到端的分析,其目标是最大化的收敛线上告警,找到原因告警。
舆情监控。这是腾讯很有趣的一个实践。把他拆开来看,是一种NLP技术在运维团队的一个使用。因为我们在做社交业务运维的时候,经常会遇到一个问题是用户通过手机移动端或者PC端使用服务的时候,他们请求可能根本都没有发到服务端。端到端以下都是客观的、技术的指标。但是技术的指标,哪怕成功率是100%,有可能用户都被劫持了,他的客户端都crash掉了,我们监控不到他的质量。这个时候我们通过一些自然语言,用户可以在APP端去反馈问题,然后我们去解决他的问题。
基于这种对文本型自然语言解析的能力,我们做了一个运维机器人,他也是一个解决运维这个角色不断的被频繁骚扰、打断、咨询、提需求、问问题的这种实践。
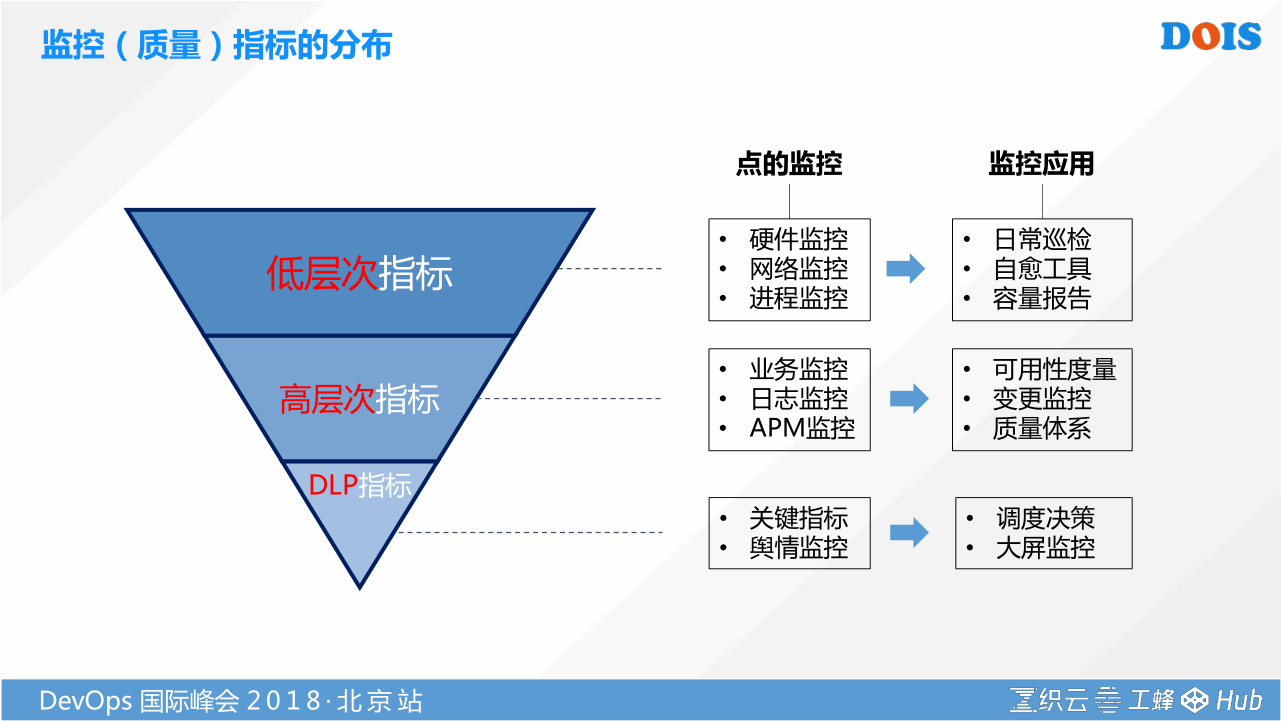
我们主要希望通过一个正三角的方案,构建一个倒三角的能力。通过我们管理的方法,把低层次的指标,通过我们的规则去实现一些自动化、自愈、管理能力。通过我们对高层次指标的抽象,量化构建质量体系,最终形成一个DLP的方案。DLP是我们内部根源分析的方案。
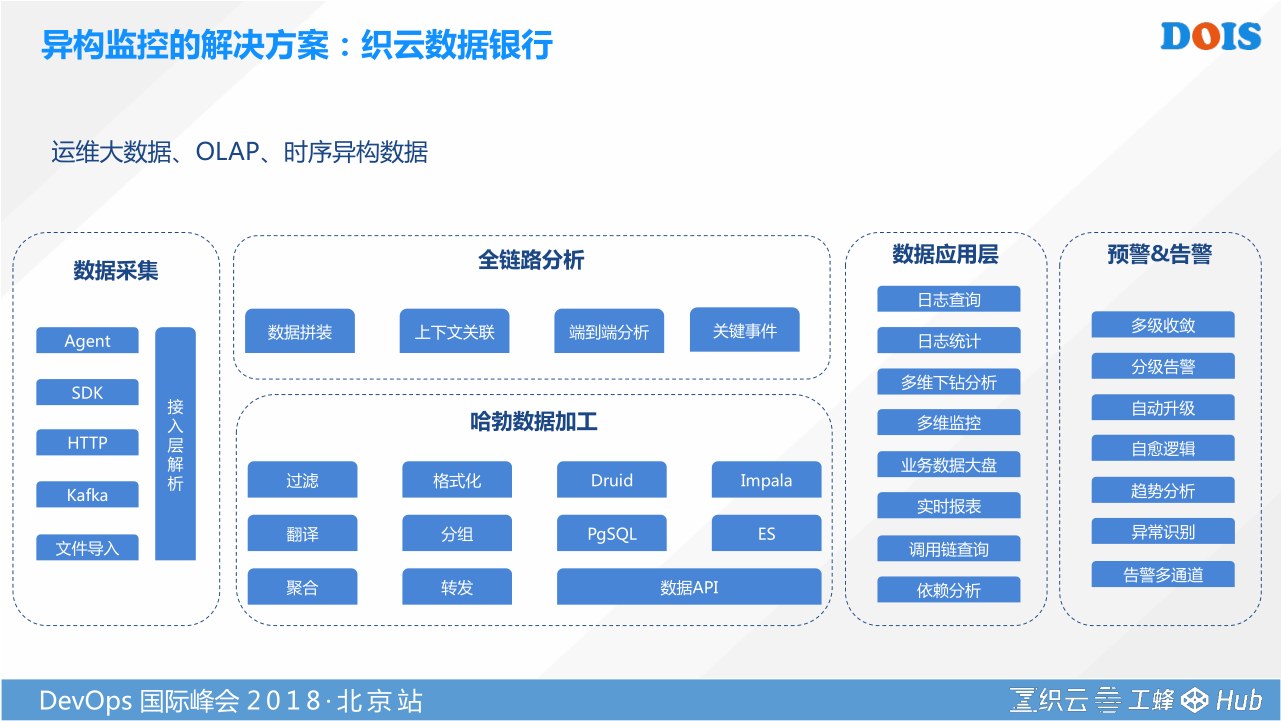
怎样把低层次的指标,IAAS具体反映的指标,把他包装成业务最核心的指标。这就是我们数据银行要解决的。大家回想一下,所有头痛治头,脚痛治脚的监控点,形式是不一样的。网络监控、日志监控、主机监控、云服务监控、API监控等,其来源的形式不一样。我要对所有的监控数据进行全局的加工,就必须要有一个方法打通他。为此,我们把整个运维监控持续反馈里面用到所有运维的数据,砍成四大段:
- 数据采集生产的问题。所有不同监控源头的数据,我们提供了统一接入的方法,把全局打通。这个功能有一个很好的好处,大家以前有没有想过一个问题:所有的监控系统自身准不准,监控的监控你怎么做。通过这个方法,我们是可以实现的。例如:每一个监控源,假设Agent代表一个数据源,他上报数据量有没有陡降,上报的字段符不符合我们格式的要求,有没有一些非法的字段,有没有按照协议等等。其实都是可以在数据统一采集这里帮你实现监控的监控。
- 运维所有数据的处理都是时序数据。对于时序数据的处理,是有一些通用的技术,可以被提炼出来的。例如需要对这些数据进行正则,把他格式化,某些字段要进行翻译(例如:把客户端IP地址翻译成运营商、城市、省份等等,把身份证号码翻译成年龄等等)。然后进行分组,比如这几个IP属于这个业务,这几个应用属于某种等等。还有一些统计的方法,加减乘除的方法,这些都是共性的,我们把这些共性的能力统一归结成多维的数据加工能力。
通过数据能力抽象,我们再往上层走,可以基于规则或者基于一些算法,来实现数据的拼装。所有监控数据都是来源于IP,上报的时候都有他的源,在CMDB构建了一个业务树的模型,就是IP地址跟业务树相关,业务树上面又有应用程序,应用程序又跑了这些端口,这些端口又对应了业务的成功率、请求量、返回码。这样的一个规则可以帮我们串起来很多,我们不做任何AI的前提下,是可以实现上下文关联,某种场景端到端的自动分析,甚至还可以提炼一些关键事件,把关键事件作为收敛低层次监控指标的一种方法。 - 数据应用层。数据怎么用,究竟是用作日常故障排查的日志分析,还是用作监控视图和大屏做统计分析,还是用来做调用链的分析。这是我们数据的一个场景。
- 预警、告警。最终在数据应用的场景之外,就是统一告警。这么多数据源对异常告警策略的配置是很繁锁,如果我们加了无阈值的监控,我所有告警都不需要统一的配置。我的收敛也可以做,不同的监控点有可能会相互依赖做决策,在统一告警可以做多级收敛,甚至是分级的收敛。这都是依赖于数据的集中存储和处理。
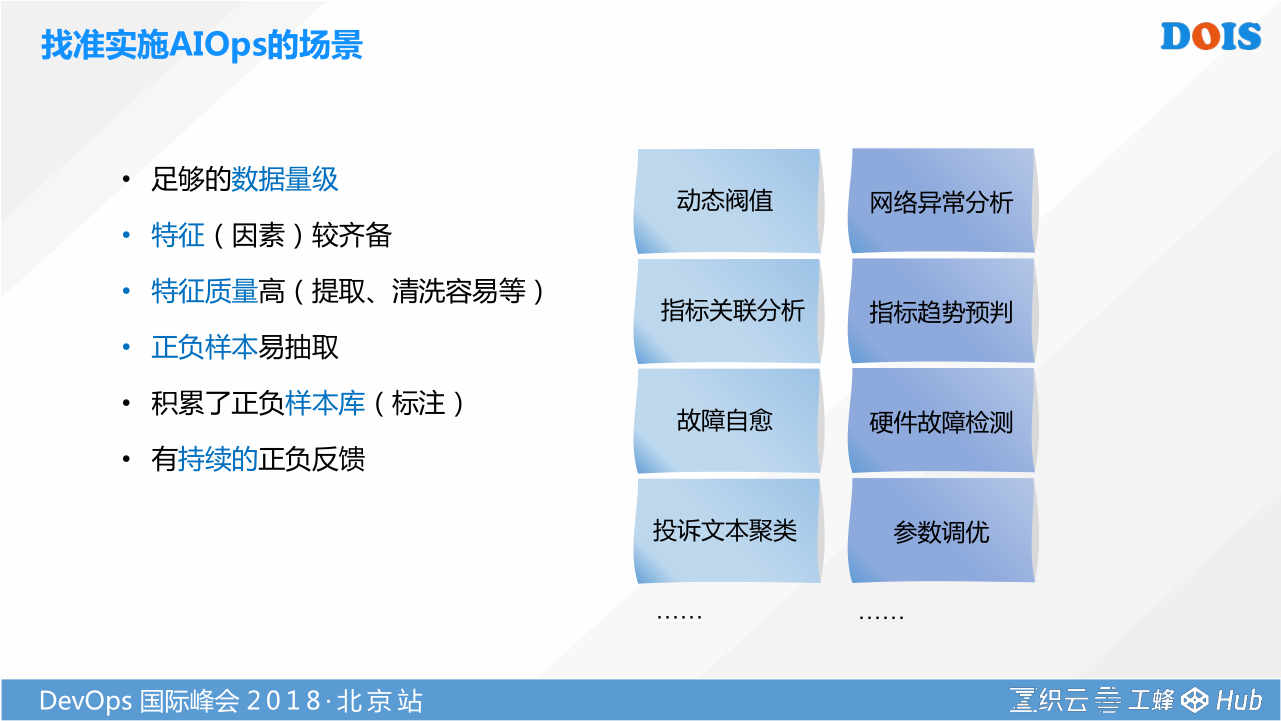
有了一个大数据的平台,这时候我们就可以聊聊下一步你怎么样走到AIOps的场景。大家都在聊AI,或者很多企业都在聊AI,或者都在尝试用AI,但是有没有思考过一个问题,这一切所有机器学习的算法都是跑在有足够数据量级前提下。在腾讯是有这样一个数据基础。你的特征是不是齐全,正负样本是不是易于抽取。在腾讯我们实践了很多这种场景。例如:指标怎么样去关联分析;故障怎么样自愈等等很多场景。我们并不是说AI能解决运维所有的问题,现在提的所有AI都是在辅助运维做一定的决策,做一定工具的触发。所以更多的是希望,我们在做这种企业级解决方案输出的同时,带上腾讯自己已经实践好的经验,能给大家去解答大家的一些运维场景的问题。
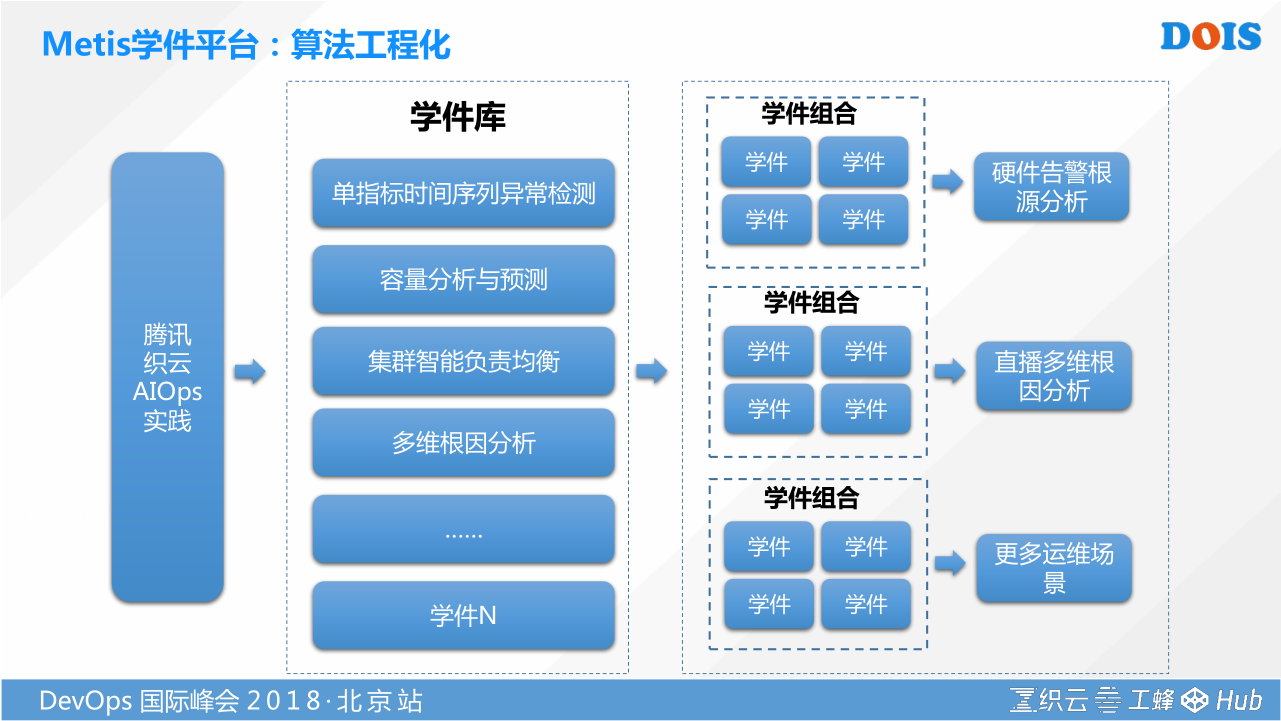
腾讯训练好的场景,直接拿过来未必是适用的,那你怎么解决这个问题呢。这时候我们就想到了一个方案,这个也是参考了南京大学周志华老师,《机器学习》西瓜书的作者。他提到了学件,我们希望把每个算好的这种模型都可以开放出来,开放出来通过一个叫做Metis的学件平台。开放出来之后,不同的企业要去使用的时候,你是可以看得到,为什么腾讯的无阈值是这样去做的。我为什么要先跑一个统计判别法,要跑一个孤立森林,要跑一个有监督。因为不同的数据模型是不一样的,我基于这种平滑的模型训练出来的这个结果,通过Metis的平台提供了API,你再按照我的数据协议传进来,这个平台经过一定数据的积累,通过历史数据的分析,他可以预测出下一个点是正常还是异常,他给你一个0或1的判断。你又可以基于自己的业务形态不断的训练他,你去标注说你分析对了,分析错了。然后以此让我们的API能力能根据不同数据集特征情况,最好的适用于各个企业的具体场景。这个平台我们预计会在Q3开源出来。
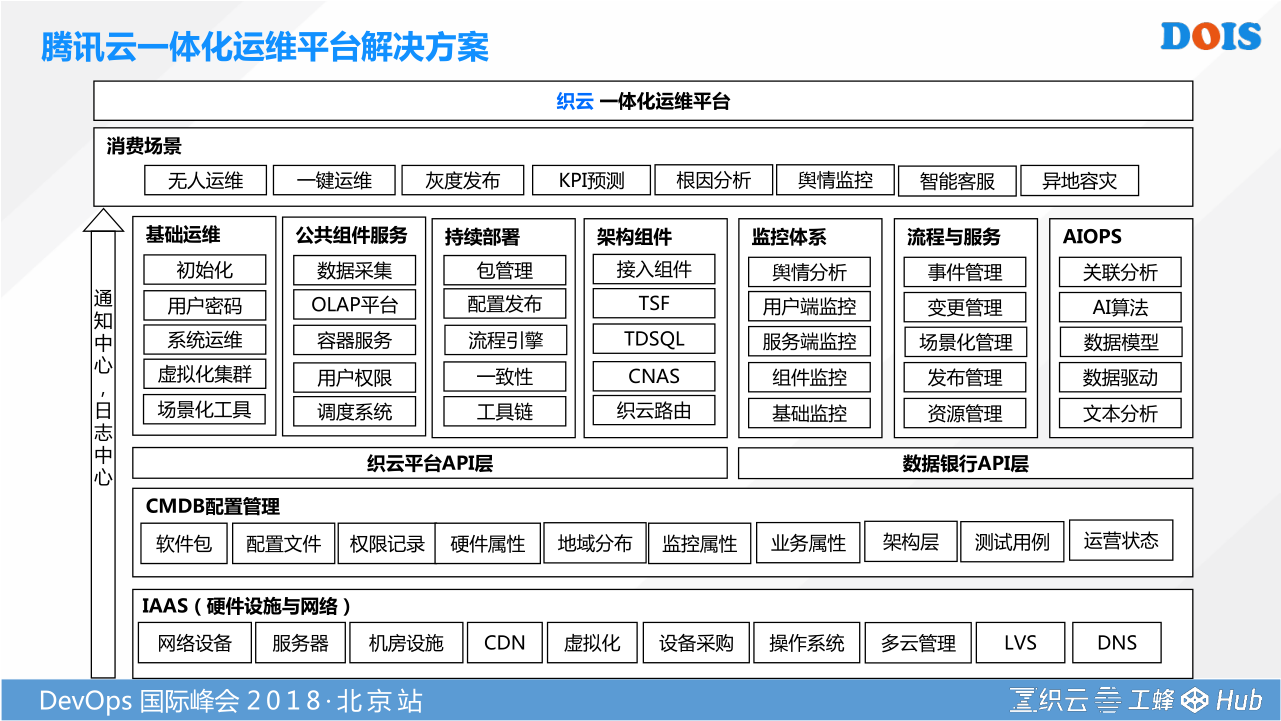
讲了这么多,最终我们希望站在持续运维,持续反馈的角度,能够给我们的企业客户输出一体化的运维平台的解决方案。这个解决方案有很多功能,我今天只是抽取了一部分功能,但是有一点我其实想跟大家分享一下的。他是一个层次化的平台,从IAAS层到CMDB,一直走到我们应用的一个场景。我们IAAS层现在原生的可以跟腾讯的一些云,腾讯的私有云,腾讯的公有云打通。但是我们现在对外输出的一个过程中,有大量的一个场景是插拔在其他云上面。通过我们的CMDB解决这种异构配置数据的融合问题,通过通用API的平台层,或者有些公司也把他称之为通用的数据消费层,让上层基础的运维工具可以去消费他,从而找到我们的场景,从而走向我们集中式的运维,让我们所有多环境管理都能够在一个平台完成。
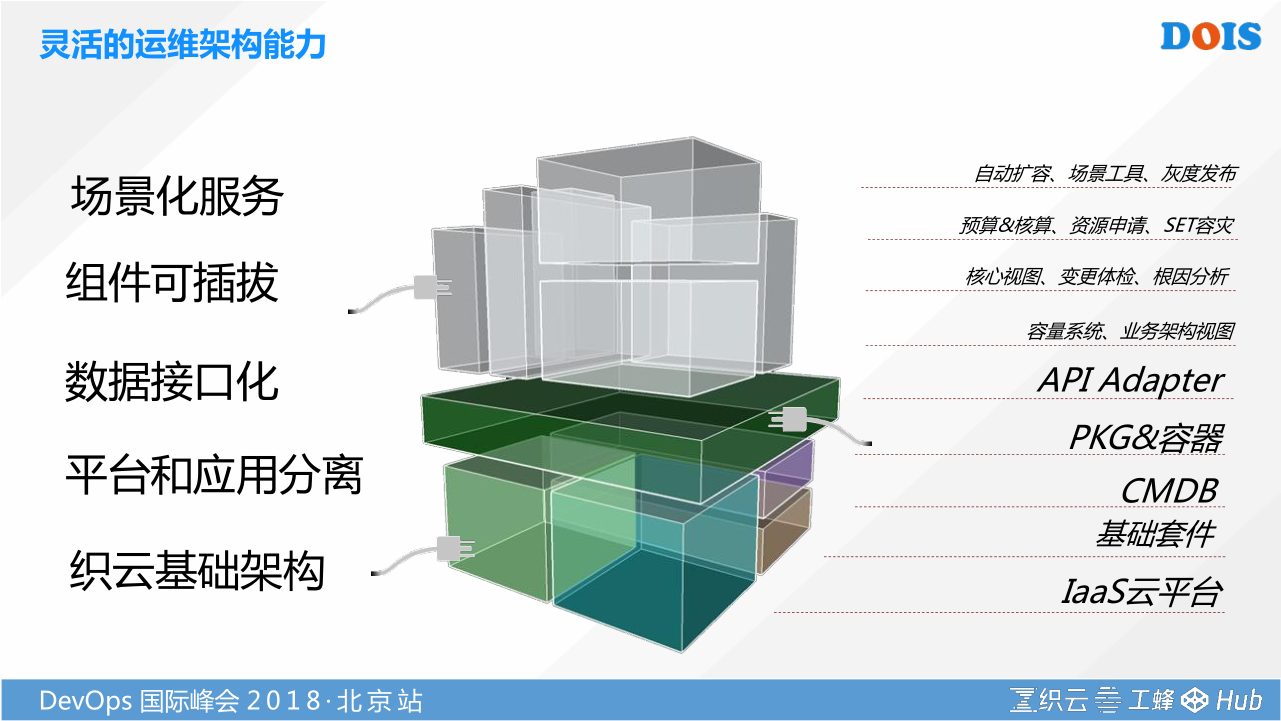
怎么样做到的呢。我们本身设计平台的能力,并不是希望通过这样的架构把大家框死,更多希望提供一个更开放、灵活的平台。整个织云,我们自己的后台就是一个一个的微服务,服务和服务之间的调用。我们把所有的API都托管在我们自己的API平台。企业客户可以很灵活的基于自身的一个需求,如果你觉得就是CMDB和工具平台好用,包管理不好用,你完全可以不用我的包管理。你用自己组织的方法,得出你标准化的对象,然后对他进行编排,最后写回我的CMDB。这些都是可以的,找到自己最合适的一个场景。
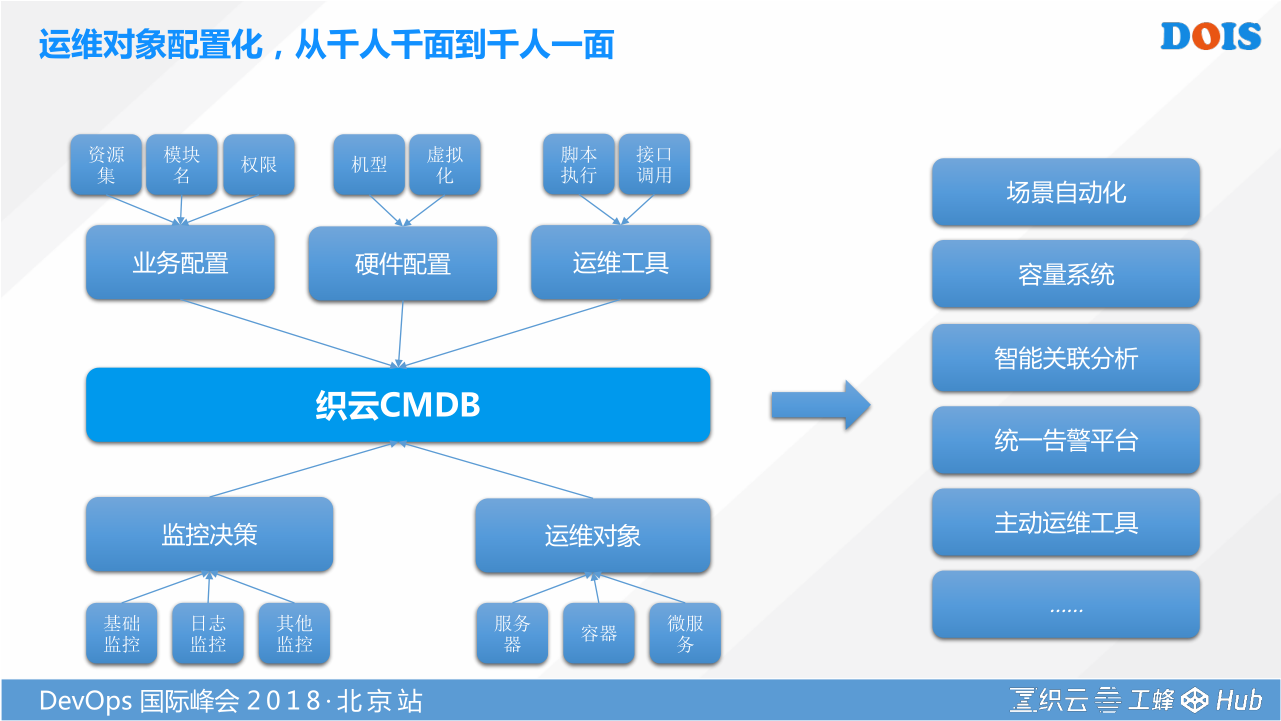
最后我们尝试在解答一个问题,我们希望对运维工作所涉及到所有对象的抽象和配置化,形成一定经验的数据模型的对外输出,从千人千面的需求场景,让我这个千人一面的灵活架构技术可以去支持,最后是找到企业要落地的,能解决问题的场景。这个就是通过我们CMDB的组装,把所有的规则都依托于他去承载,然后去对外输出。
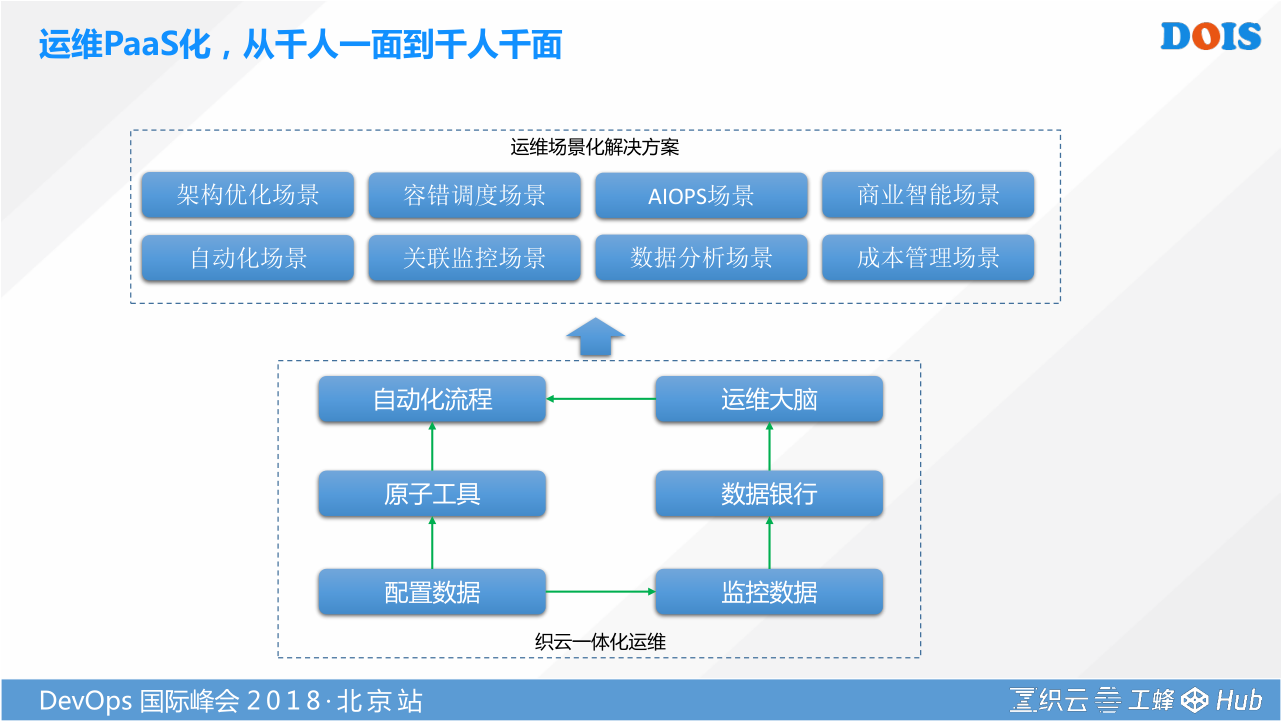
我们又希望通过提供PAAS化的能力,让我们千人一面的这种平台能力能够走向千人千面。我讲了很多,他核心的思路就是把我们数据配置化,通过工具消费他,自动化的流程找到应用的场景。同样配置化的数据也可以做用于监控数据,监控数据也可以通过配置化的数据进行组装、关联。通过数据银行打通所有异构的监控数据。异构的监控数据在特定的标准化的场景,事实上可以做决策。这里就把人解放出来,走向无人运维的场景,再去走向自动化。这就是我们的核心思路。
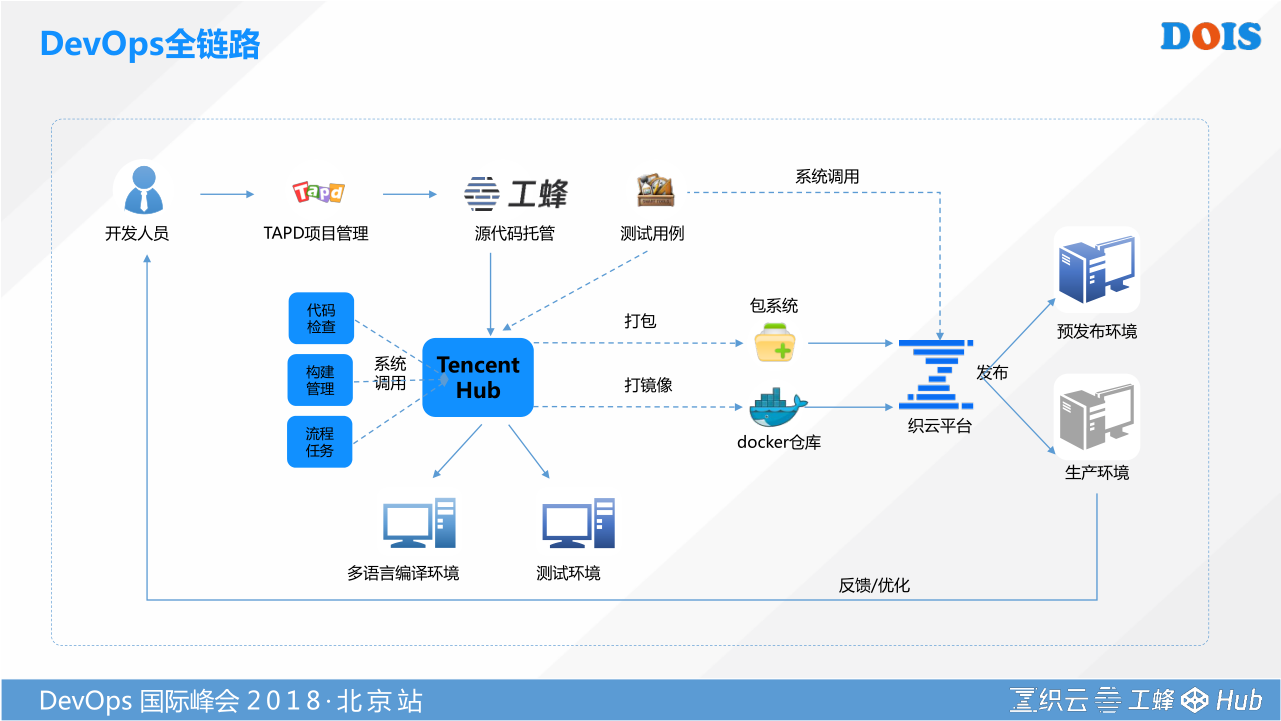
最后再点回来,在整个腾讯企业级DevOps解决方案里面,我们有很多TAPD、工蜂、Tencent Hub等,通过容器跟我们运维平台打通,你发布之后我怎样监控你,怎样持续给你输出质量的数据。然后非容器的方案就依托于织云。织云有自己的一套制品管理包装的方法,可以直接对接你的Git仓库,我的平台可以无缝的管理,把你管理好。通过织云去实现基础环境的打通。
我的分享就结束了,谢谢大家!
