@gaoxiaoyunwei2017
2018-05-08T06:08:42.000000Z
字数 6155
阅读 1682
负重前行—顺丰数据库运维的求变之路
彭小阳
作者简介:
刘力,顺丰科技 应用数据支持部负责人。2013年加入顺丰科技,数据库团队负责人,主导了顺丰科技数据库架构从非标到标准,从传统到开源,从集中到分布式的技术演进;带领DBAs,从被动到主动,从不变到求变,从人工到智能的运维模式转变。十余年大型数据库架构设计和管理经验;曾任职平安科技,负责银行业务线数据库架构设计和管理。
前言:
今天主题是《负重前行—顺丰数据库运维的求变之路》,为什么叫负重前行?传统的公司做互联网转型历史包袱非常重。尤其顺丰这种业务高速发展的过程中,包袱和急速转型中就像在高速列车上换轮子一样,风险很高。
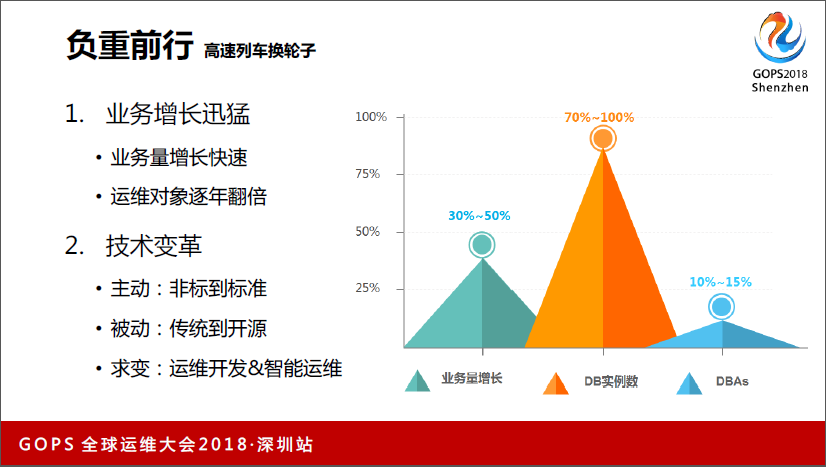
顺丰的业务在逐年增长,另外我们的业务领域也在不断地拓展,从快递到冷链、仓储、金融,我们DB管理的数据实例量也在增加。
在这种状况下,我们还要经历很大的一个技术变革。
第一方面就是最开始的数据库类型很多,我们主动从非标到标准的转移。
另外就是被动的,从上自下的,公司要从传统的领域转向互联网领域。做了一个决策,就是要从传统领域到开源领域的转型,我们被动的接受,也要做。
第三就是开源领域下,维护的数据量怎么做稳定的运维。
我今天讲的内容是:非标到的标准,传统到还源,集中到分布式,智能运维。我今天着重讲一下集中到分布式,以及智能运维的课题。
1、非标到标准

1.1非标到标准洪荒之年
数据库类型繁多,DBAs被技术割裂,忽略用户需求。

1.2非标准到标准穷则思变
面对比较繁杂混乱的状况,我们还是要做一些主动的改变,不然就一潭死水了。

第一,我们会减少DB的数量,因为当时我们的技术能力还主要在SQL这块比较强;
第二统一基础架构方案,这样不会因为一些个性化的事情导致运维的问题;
第三环境标准化;第四关注基础资源状态,存储出问题,网络出问题,主机出问题,是不是你的锅,都是我们的锅,如果不承认的话,这个锅永远存在,所以你要关注它。
第四是主动预防,我们做一个闭环,这样把一些问题通过一套系列的流程和机制全部建立起来,做完这些问题之后,我们整个数据库的稳定性得到提升了,DB可以从反复的扯皮中脱离出来,做真正有意义的事情。
2、从传统到开源

2.1传统到开源之去商化

我们突然有一天从上自下要做开源,转型,这不是我们主力做的,这是从对上层的领导决策方向来做的,你到底是干还是不干,你既然想在这个位置上做就得干,我们要做大力水手,而不是鸵鸟。
我们传统的是拿核心仓储系统,对顺丰来讲是非常核心的系统,当时的转变压力还是很大的,不像一般公司里找一个外围系统看一看,我们一上就上核心系统。另外很多公司的做法是从外面找一些买手专家,拿过来起一个项目做这个事情,我们基本上靠自己团队完成这个转变。
当然我们也从外部引第三方服务商。我们最开始的思路就是,既然它的差异性很大,我们要想到,关键数据和本质在哪里,我们当时想的就是关键数据库最核心的两个:
一是控制事物,如果不管事物的话根本不需要数据库;
第二关于数据库最重要的就是索引,创建索引非常方便。
所以我们抓住这两点:
第一业务逻辑不要在数据库做,它只是做关系型数据的容器,把这个容器保存下来,最后业务逻辑都上升到业务去。业务逻辑无状态的扩容非常容易,四个不够八个,八个不够80个。
第二控制规模,因为我们最开始是没有能力做分布式方案的,怎么办?就把你从业务逻辑上去拆,全部拆开;我们当时逼着研发,最开始八个,其实很多了。一个相同领域的业务系统里面,我们把它从一个业务系统拆成八个业务系统,因为这也没办法,单个处理的性能和能力只要太大的话是无法支撑的。
第三是靠SAN来解决,怎么保证数据不丢失,我们退一步,还是用SAN帮你找,解决自动化问题。因为技术本身对企业不是最新的就是最好的,而是对企业目前阶段,能解决企业问题的技术就是最好的,所以我们最开始自己做一套切换的方案。
2.2 传统到开源之运维开发
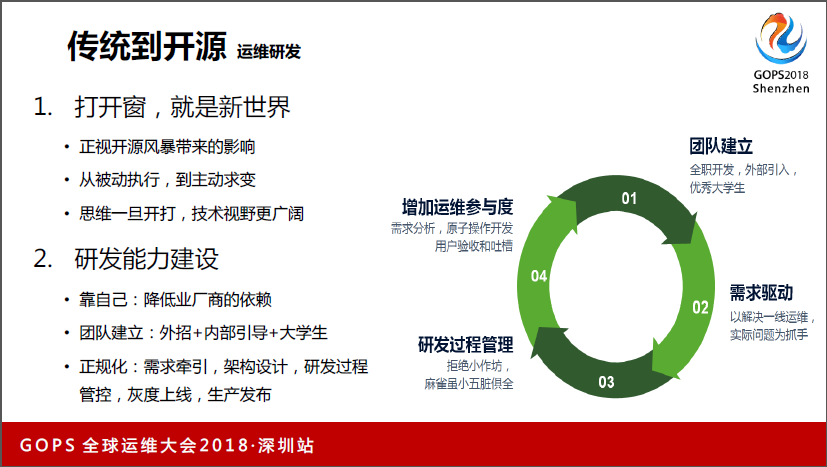
第一,既然是去商化,SAN也要干掉的,所以我们开始着手做自己的运维研发的转型。我们就打造自己的研发团队,我们从外部招了一些相对经验丰富的运维研发人员,两三个,然后配合我们自己内部的大学生,因为大学生是一张白纸,一个有经验的人多大学生往前冲,出成果的机率比已经在运维打造很久的人更高。
第二,团队建立之后,我们发现其实运维经理去管研发团队,会有一些角色上的偏差。如果他们管理的力度不够,发现研发小团队里面自己内部出不了什么成果,可能他一直沉浸在新技术里,但是拿出来没办法用,因为没有运维在里面做驱动。后面我们一切以一线运维的需求做抓手,驱动研发往前走。
第三个,我们研发团队建立之后,从最开始的整个需求、研发、测试、发布都自己玩,最后做规范化的改造,我们有自己的需求小分队,有架构师、有研发小分队,还有针对这个产品有自己的运维分队,把这些东西都隔离出来,各层监督。
第四是增加运维的参与度,现在处理问题主要是运维的问题,所以运维什么地方痛运维自己知道,所以他会做自由分析,第二回做原子操作开发,第三做验收和吐槽,我们建立了专门的吐槽机制,把研发和运维调动起来。
3、从集中到分布式

3.1集中到分布式单实例性能瓶颈
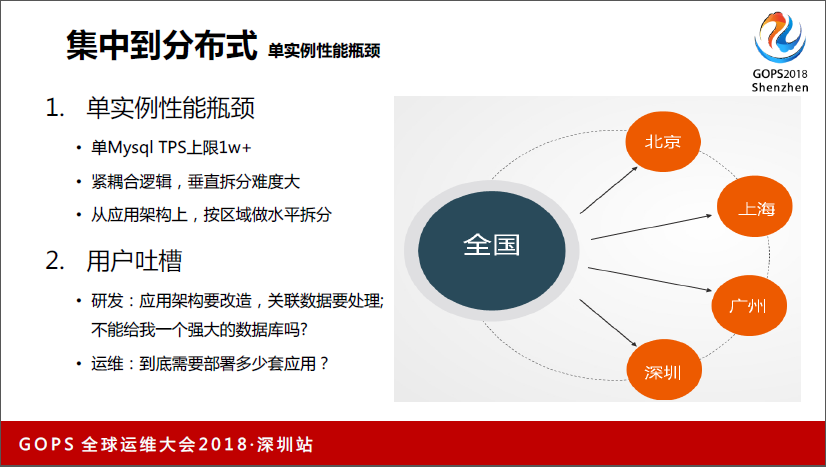
现在谈一下我们从集中到分布式扩展的过程,单个Mysql TPS上限是一万+,但基本上可以到3万5左右,但我们真正用Mysql一般控制到5000,尽量2000,是比较安全的。一般我们讲仓储系统,最开始从一个拆到8个,已经非常多了。但是再往下拆拆不动了,再拆就是数据交互时代,这样失去了拆的意义。
这种情况下我们进行区域拆分,把全国的数据拆到北京、上海、广州、深圳,拆了很多出来,但这样对运维和研发压力很大,对研发来讲,他需要做运营架构改造,至少要做导流,要把深圳的倒流到深圳,北京的导流到北京,这样整个业务架构的前端足够了。
第二关联数据处理,因为不像一些区域性很强,比如滴滴,深圳的单在深圳,北京的在北京,但顺丰这种关联数据要处理,这种也很麻烦。他想你为什么不能给我一个强大的数据库,对于运维来讲,他需要部署N套应用,因为不布一套数据库就要布一套应用,这样我们有一百套数据库就有一百套应用,而且怎么保持一致性也是很头疼的事情。
3.2集中到分布式Mysql_proxy
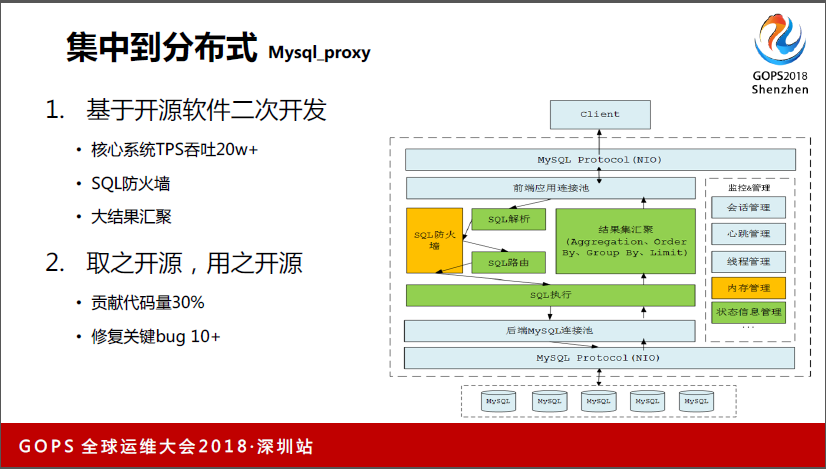
我们后面基于开源的数据库,就是Mysql,做了二次开发。我们当时引入Mysql之前,也是测过一些Mysql等一些产品,我们经过了大量测试,后来发现,结论第一就是Mysql的确能商用了,第二它的基本功能满足我们了,那些读写分离的功能我们暂时都不考虑用,最终我们还是选择用Mysql来做数据库中间件的基石,因为还是在我们开源的思路导致的。
我们基于Mysql做了很多二次开发。我们最核心的运单系统里面,现在在高峰期的达到20万,这算比较高的值,当然跟互联网公司比还有很大差距。第二我们做了智慧防火墙,主要解决DV和研发反复沟通质量的问题,就把基础的迁移到防火墙里面去。
第二获得了大数据的功能,一旦研发有比较差的写法,需要全分片扫描的情况下,而且扫描数据比较大,比如一两百万,这个Mysql就很容易挂起来了,因为它的内存被撑爆了,这样对生产运维有很大影响,所以我们做了大数据会聚的读本。我们是用的是1.5.1的版本,现在应该是1.6.2的版本。
我们把这些功能基本上都回馈到社区去了,里面关键的bug都扣掉了,把我们一些已写好的代码上传到社区,也是取之于开源,用之于开源。
3.3集中到分布式大数据汇聚
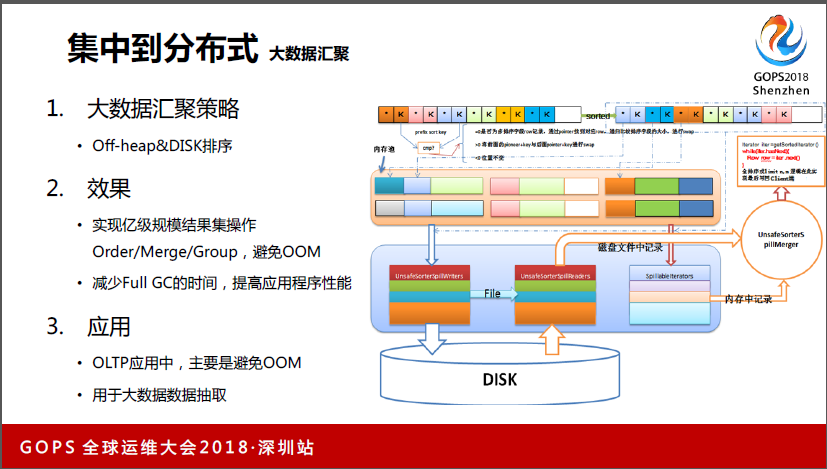
这里着重讲一下两个功能,一个是大数据汇聚的功能,我们把整体排序放到File去了。在正常的业务系统里面,不应该有这么大的排序。我们做完之后,经过测试可以实现上亿数据的聚合。因为你把排序从归类搬出来了,避免OOM,所以应用程序本身有好处。
3.4集中到分布式SQL防火墙
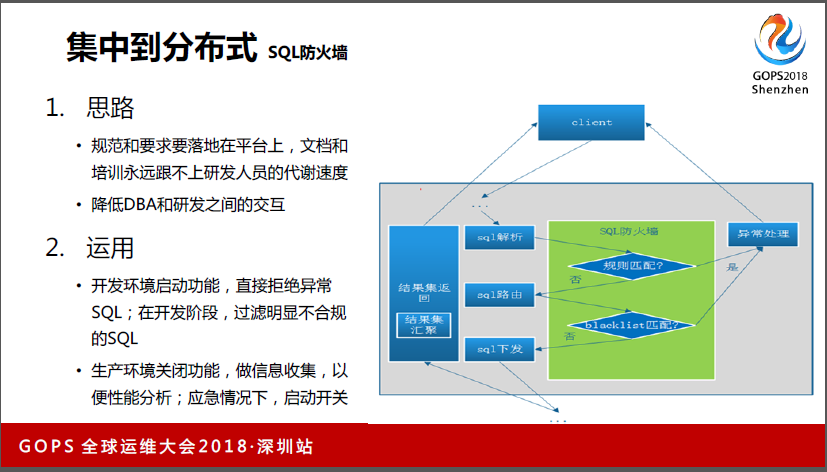
另外做防火墙,文档和培训永远赶不上研发人员迭代的速度,不断有新的研发速度,第二,外包变迁也是非常频繁的事情,很多情况下保证规范能够落地到研发,靠人已经斗争了十几年,没用,只能靠平台了。所以我们把规范和要求全部落地到平台上去。
比如最简单的,Mysql要建索引要求,卡住,根本上不了房间。第二降低DBA和研发之间的交互,现在有审核代码的工具,但审核还要跟研发说不行,沟通程度很高。底层研发人员更喜欢自己搞定自己的事情,沟通成本在我们工作里占了很大成本,所以我们也希望直接通过平台方式把它规避掉。
我们应用在两个地方,在开发的时候,如果你写了一些代码,我帮你跑,研发只要报错就改。这种情况下我也不会直接有人告诉你怎么改,直接平台告诉你。这样就不会有正面的冲突。
第二个我们会在生产环境中,生产环境我们不敢开这个功能,所以我们只做了信息搜集,在应急情况下,比如说出现了一大批高并发的SQL,可能在应用层面没办法剥离,这种情况下直接拒绝异常SQL。但这个我们还没用过。
4、智能运维

智能运维,矛盾转移,研发运维的需求满足,面对膨胀的DB数量,运维复杂度大幅提升。解放DBA双手。对内我们主要做资源池化的动态管理,第一个是HA的逻辑化,像数据的HA大部分带数据属性。这些动作其实计算很简单,但是很耗时间,特别是在成千数据库情况下,就都耗进去了。
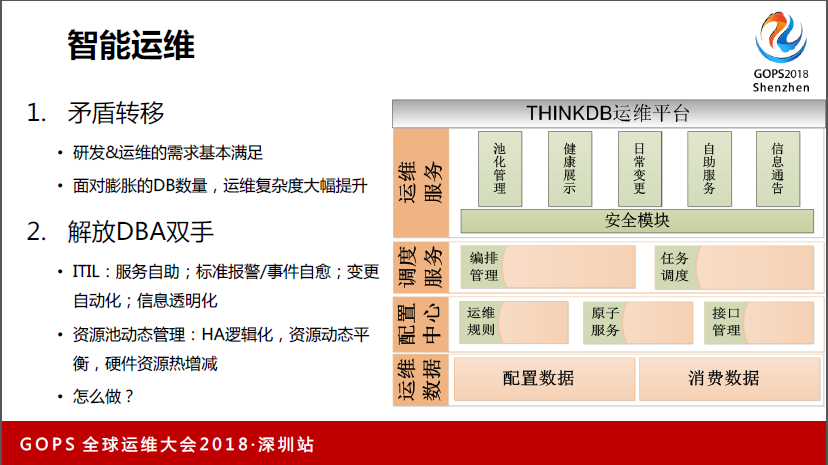
我们现在可以把标准机器直接做库存管理,对这个事情管起来,如果需要把10台变15台,就把这5台加入标准池里面去,标准池是0,它会把一些使用率高的自动往0上做迁移。还有一个减,减分两种,第一种就是做HL,还有主机能用,但是从管理上要剔除,我们会把主机的CPU值设到100,它会逐一地迁移到低的里面去,如果全部剔干净会把它踢掉。
4.1智能运维联合作战
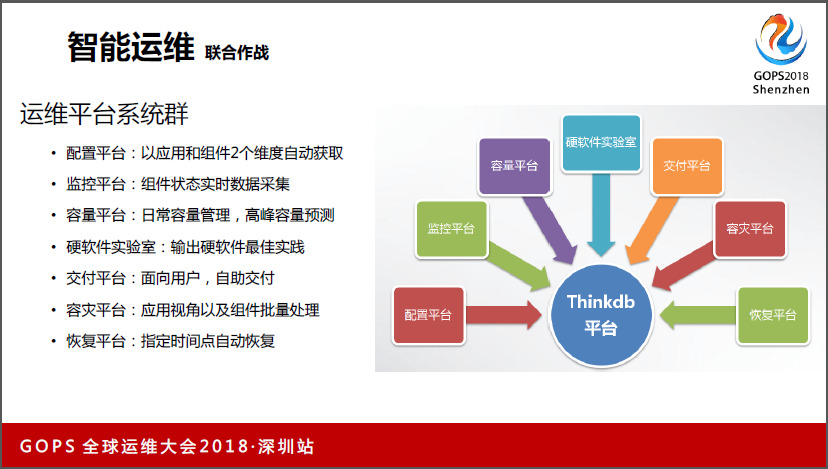
我们目前内部做的一个自动化管理平台就是叫Thinkdb,我们会有两个维度,一个是应用维度,第二个是组建维度,去做配置性获取。
配置平台,就是以应用和组建2个维度自动获取;
监控平台就是组件状态实时数据采集;
容量平台:日常容量管理,高峰容量预测。
硬软件实验室:这个也是近一两年才开始做的,这一两年长期在推动研发去做硬软件的优化,底层也是优化空间,比如这台主机到底现在怎样是效率最好的,能不能通过数据库的配置作为调优,我们觉得这个事情做得很有意义,我们通过一些调整可以把整个数据库的性能提升20%到30%,这种情况下可以在相同的硬件资源情况下支撑更多的数据库。交互平台是面向用户的,自助交付。
容灾平台:应用视角以及组件批量处理。
恢复平台:指定时间点自动恢复。
4.2智能运维解放双手
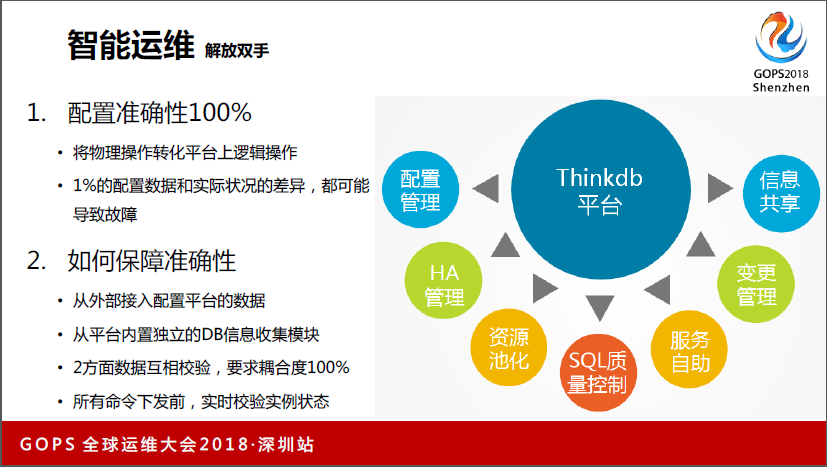
对关键的点我会介绍一下,第一是配置管理,其实配置管理大部分都能做,但怎么样做到配置百分之百。如果我们作为一个自动化运维平台,就要做到这一点,因为你要把物理操作做成逻辑操作,做不到这一点就会导致故障。比如现在好多都是100个数据,但里面记录的是99个,如果批量操作的情况下,漏了一个就会引发故障。
然后我们在这方面从三个维度来做,第一我们从外部有一个配置平台的数据,第二块我们会在DB自己内嵌一个信息搜集模块,这两方面的数据互相交互,要求耦合度100%。第四是在所有命令下发之前,实时校验实例状态,一定要保证此时此刻的动作状态和实际情况一模一样。
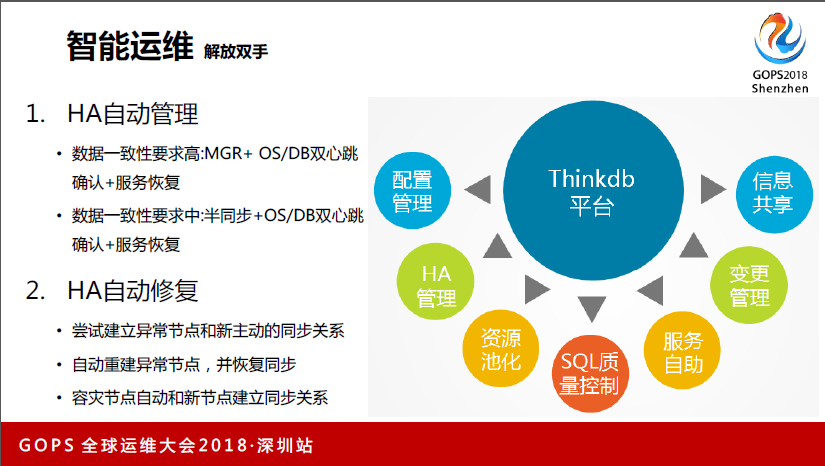
另外说HA的自动管理,我们建立运维研发体系,第一个目标就是解脱HA,我们现在用MGR,这个功能推出的时间不长,但我们已经在用了,所以我们胆子还比较大。数据库一致性的要求我们靠MGR+OS/DB双心跳确认+服务恢复。确定完之后,我们通过切换做应用恢复。
另外数据一致性要求没那么高了,半同步+OS/DB双心跳确认+服务服务恢复。HA自动恢复,尝试建立异常节点和新主动的同步关系;自动重建异常结点,并恢复同步;容灾节点自动和新节点建立同步关系。这个事情可以把HA很多处理的时间省出来。
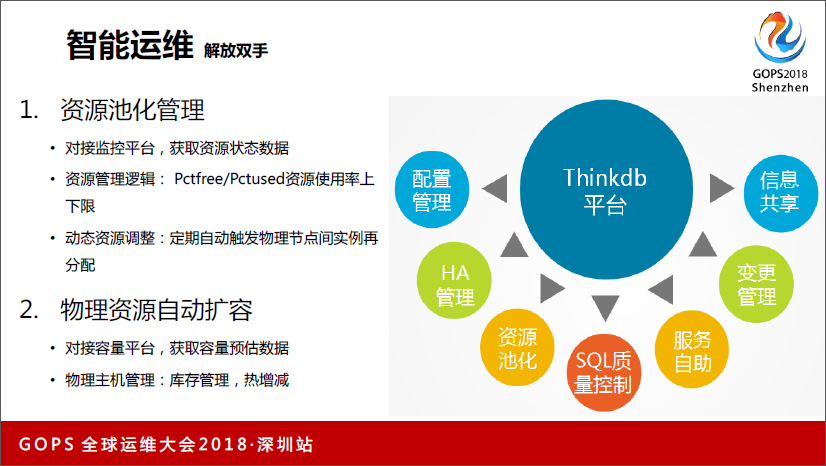
第三个讲资源池管理,我们做了一个资源池管理逻辑,对接监控平台,获取资源状态数据,资源管理逻辑:Pctfree/Pctused资源使用率上下限。动态资源调整:定期自动触发物理节点间实例再分配。物理资源自动扩容:对接容量平台,获取容量预估数据;物理主机管理:库存管理,热增减。
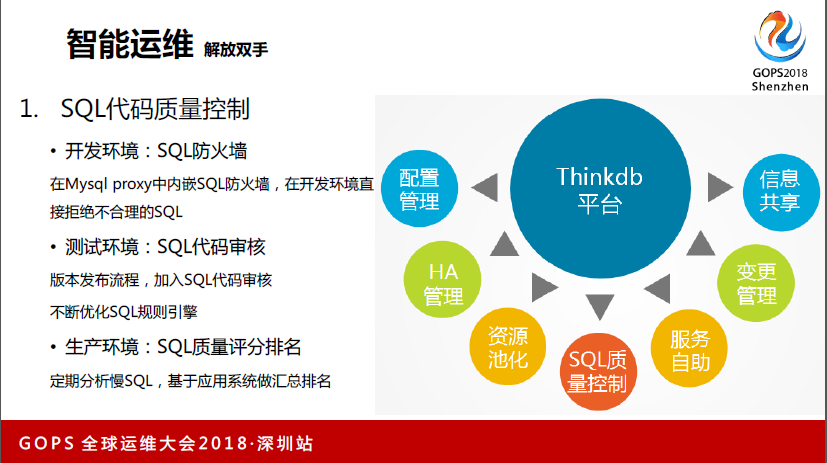
这里谈一下SQL代码质量控制,我们在开发环境,主要通过Mysql内嵌的防火墙拒绝不合理的接口,在测试环节还有个SQL代码审核的过程。这个逻辑本来就成立一个需求,这个需求会进入到防火墙的需求代码里去做一些拒绝或者通过。
第三个就是我们会把生产环节的SQL质量拿来打分,打完分之后,对这个分做一个排列,我们就给到对应的研发老板,效果还是比较好的。我也不说具体哪个系统哪个数据有什么问题,我就告诉你们这类型的分数比别人高还是低,来驱动研发有从上至下的优化SQL代码的举动。
4.3智能运维业务支撑
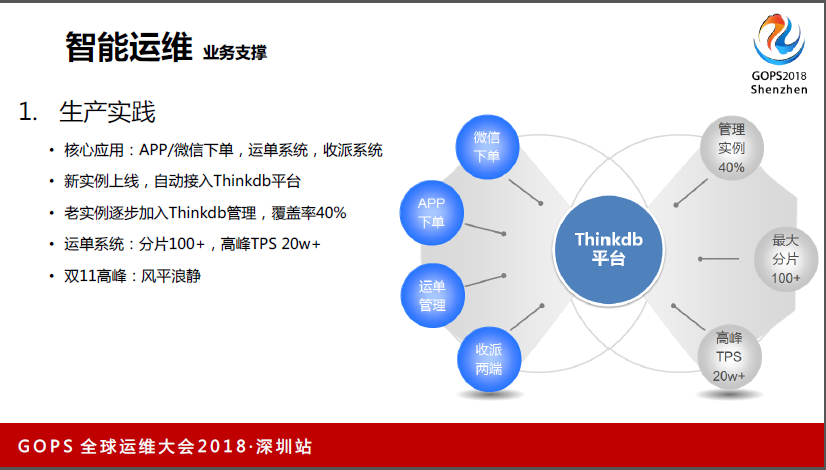
这里讲一下我们Thinkdb在顺丰的运用情况,我们核心应用都纳进去了。然后新实例上线,自动接入Thinkdb平台。老实例逐步加入Thinkdb管理,覆盖率40%。运单系统,分片100+,高峰TPS20W+,双十一高峰很平稳。
4.4智能运维放飞大脑
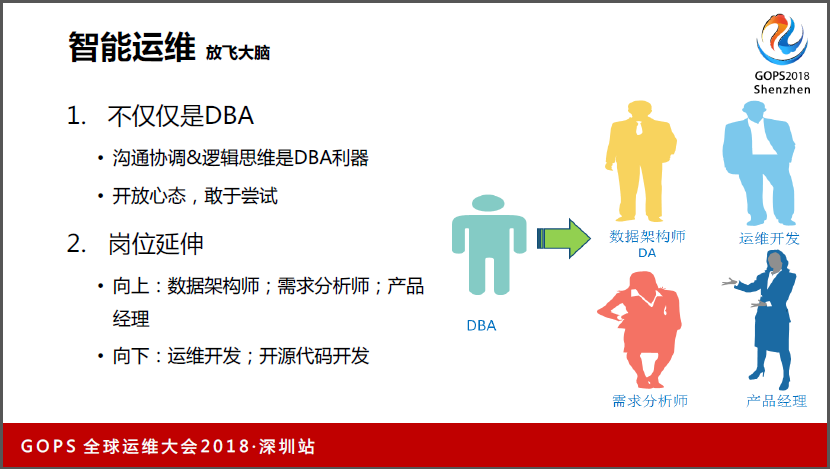
大部分要介绍的都介绍完了,这是一些心得。第一个是DBA的沟通协调和逻辑思维能力是很强的,开放心态,敢于尝试。我们自己的团队里现在有数据架构师,有运维开发,还有需求分析师、产品经理。
我们现在的团队虽然不大,但是五脏俱全,什么都有,大家都愿意尝试一下,天天窝在那一个圈子里大家也会觉得太腻。
4.5心得交流运维转型

这里讲一下,当你把问题看成自己的时候,你的边界在不断扩展,我们最开始比较惨,五年前我们的故障可能每天有20多个,随着我们把应用的问题以及OS的问题,存储问题等全部存储以后,发现这些问题逐渐在消失,因为你发现是自己的问题就会推动去改。
因为对运维来讲就是数据不能用,你能看到你就去搞定。既然是你的问题,你就驱动关联方搞定这些问题,在这个过程中本身他的视野范围也更扩大了。
第二个就是对DBA来讲,架构设计也是手到擒来,因为应用层的东西虽然数量不高,可以通过无限的节点来掩盖一些事情,但你实际上搞不定这一点。所以架构设计对DBA是手到擒来,你可以把所有已知的问题全部当成一个钉子锤下去。
我们在整个过程中,从五年前的故障20次,从非标到标准的时间一个月一次,最近三年的故障已经控制在0次。一方面本身DBA团队也有很多付出,另外研发愿意帮你做改造,这也从上自下因为思路的改变,所以从传统向互联网转型除了技术变迁,最重要的是思维变迁,包括运维和研发的思维变迁,如果他们做不到的话我们也做不到。
最后运维的原罪,因为运维是做减法的,零故障也是100分,你做不到120分,但研发能做到130分、200分。如果你把基础运维已经做好了,任何创新都是加分项。你做出来的东西都是创新,所以你的分数比研发更容易得到。换个角度讲,运维也是一个能够给人开心的岗位。
谢谢大家!
