@gaoxiaoyunwei2017
2019-11-29T08:27:07.000000Z
字数 6651
阅读 1269
银行领域大规模X86分布式系统无阈值智能监控应用实践
白凡
分享:袁纯良
编辑:白凡
这个是我分享几个主要的内容,讲一下现状,说一下我们对无阈值监控应用的技术,第三是说我们规范化应用的关键点,第四是介绍一下我们推广方面的成效,最后做一些展望。

1. 银行领域大规模X86分布式系统监控现状
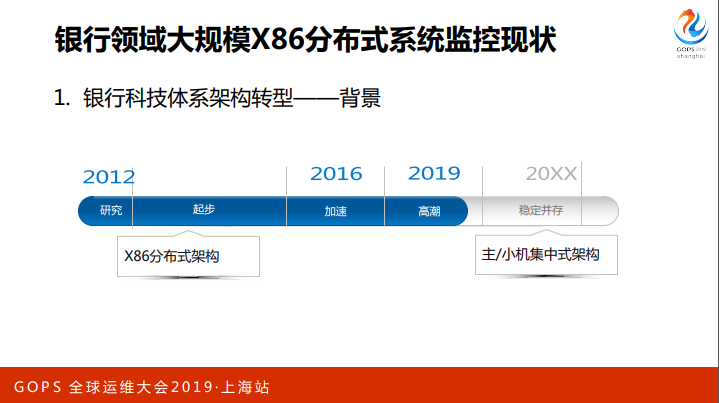
首先给大家介绍一下我们的背景,无阈值智能监控作为一个全新的技术,它的出现有相应的背景和需求,这个背景就是我们银行科技体系最近几年以来做的一个事情就是架构转型,隔行起点不一样,大家都做这个事情。
这两年逐渐的进入到了高潮期,我们中行有很作系统要从主机集中式架构X86上,这个是要持续下去,一直到最终形成一个两者并存的稳定的格局,但会以X86分布式架构为主,这个是我们一个大的背景。
这个事情对我们有什么影响?我们觉得是两个方面,第一方面就是好的影响,这个是毋庸置疑,这些事对我们银行很重要,因为它首先是可以让我们开发成本大幅度降低,这个是一个。
第二让我们场景迭代的更加敏捷。
第三让我们系统运行的更加的稳健、安全。
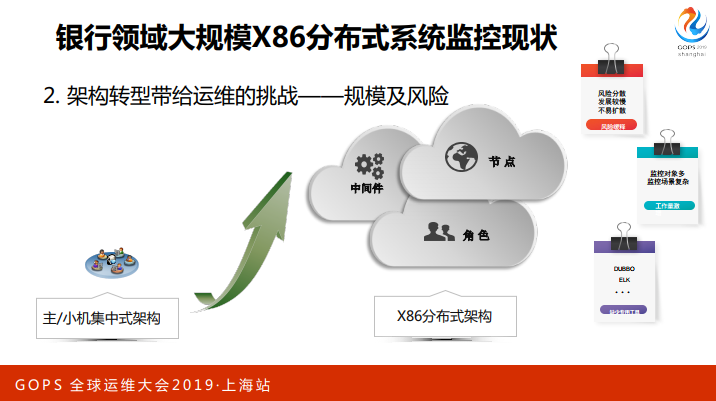
对我们来说,首先一个就是X86分布式架构是风险缓释的体系,因为是各个节点,不多节点有不同的角色,和以前的集中式不一样,集中式的系统如果有一个地方有问题就不得了了,千方百计要隔离开来,尽快的结果,大家很紧张。对X86来说,我们是紧张一点,坏了一个相当于是一个动态的别的节点可以顶上来,这个是运维角度的风险缓释。
另外就是监控的对象很多,因为它复杂,角色有很多,架构也是很复杂,监控的场景也是没有固定,非常非常复杂。对我们来说,更重要就是它的量大,这个是大家可以理解的,原来是几个点,现在是变成了几百个甚至是上千个,我们银行的系统很多,这个系统瘫痪是有很大的问题,所以我们工作量是很大。
还有一个是适合我们银行用的开源软件,用于监控的不是很理想,没有专门的工具。像我们用的比较多的工具都是一些网页式,去手工操作,你想实时它的风险点在哪是不行的。这个是给我们带来的挑战,这个挑战主要是规模化,而且是结构变得复杂了,这个是我们一个现状。
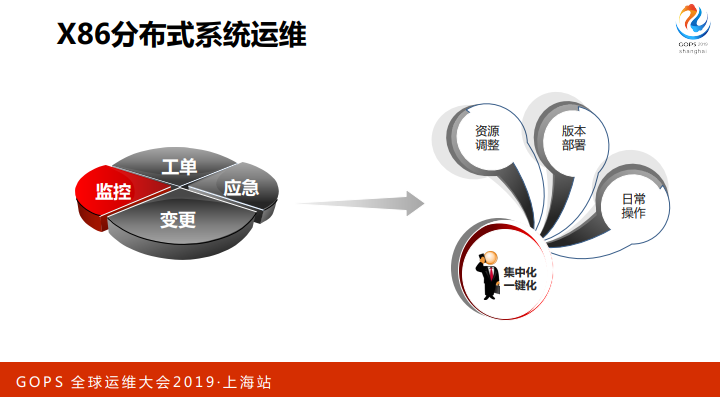
我们X86系统运维以后要做什么工作?围绕规模爆炸式的增长,我们日常做的运维就是这几块,应急、变更,监控,工单。还有资源调整,版本部署,日常操作,这个是集中化,一键式的操作。这个是我们可以做的一些工作。
工单是另外一块,我们也做了一些智能工单。
对监控来说不是这样子了,监控是很复杂,是动态的,各个节点可能版本都有变化。蓄积节点的资源也有变,你也不知道什么是它的合理的变化区间。
我们这个监控是不能够在现有的基础上,现有的传统方式下修补或者是改良,我们也做过尝试,这些都不理想,没有办法的面对加工转型给我们带来的风险。
我们把这个传统的监控面对架构转型的局面中存在的问题总结了一下,这些点是我觉得比较全了。
一刀切,就是不能个性化设置阈值,这个大家很理解,因为毕竟多,而且复杂第二是固定的,固定的阈值不会变,你要变是很麻烦,要走变更的流程,不能随着业务的变化来变化。
第三是误报,这个是一个大问题,真正有价值的报警是占的比例很少,大部分是不要做任何处置的一个告警。
第四就是滞后,所谓的滞后就是触发了才报警,但已经有异常,但是没有触发你就不知道,这个是滞后性。
第五就是孤立,其实这个监控项之间有关联的。

这些问题我们用全新的机制,全新的方法来改变。
X86系统监控也是有它自己一个发展的过程,我们也是可以看一下。第一个就是固定阈值,这个是传统,简单也是用的最普遍。第二是做了改良,就是多段阈值,它的策略就是划不同的时段,不同的场景搞几个分段的阈值,你在这个场景下触发就告警,不触发不告警,这个是用于确立的场景,它的缺点是非常非常的复杂,稍微一变就要重来,这个是很头疼的事情,无法推广。
第三是异常检测,也是几位嘉宾介绍过,这个是现在做AIops的一个热点。我们说这个异常检测是适用不是很广,这个做流量检测的时候很有效,对我们银行来说不是像检测突起就异常,我们有很多这种情况是正常的,不能说是一个风险,或者说是异常的。
最后就是我们提出无阈值的监控,这个是面向风险概率的,具备自适应的能力,这个是大概的X86监控方式发展。

2. 无阈值监控的理念及技术
首先说一下理念,我们提出全新概念的时候,我们脑子里面有这种想法,还有我们想达到什么目标?
首先就是业务时序特征,什么意思?对所有银行来说,不止是银行,多行业都是这样子,它的业务有明显的时序特征。这个就是指周期性,24小时是什么情况,一周是什么情况,一年是什么情况,这个是时序的特征。业务上的时序特征会带动后台一定具备这个特征,这个是肯定的。我们把这个生产系统比作一个人,人的心跳都是非常有规律,是因人而异,和人不同的身体状态也是有相应的规律。
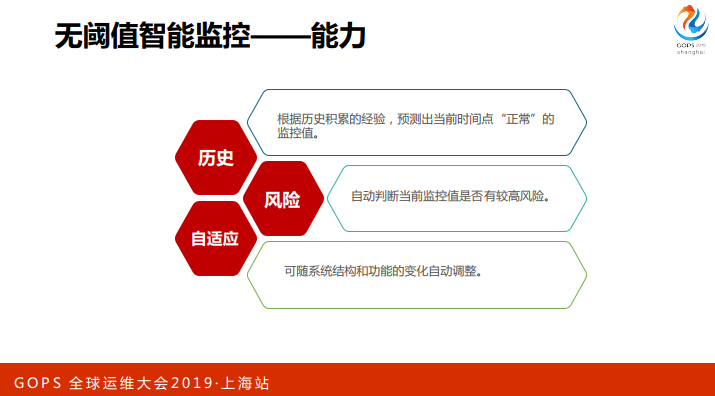
第二,我们觉得从理念、目标来说,无阈值智能监控要普适性,就是不同节点的设计化的差异,这个是一个目标,不然不可能做规模化应用。
第三是自适应性,适应系统的动态的变化,它变了以后可以自动的感知建立新的运行特征,这个是他要具备的一个能力。
第四就是对银行来说是风险完全可控,对我们现有的生产系统没有任何的,或者说基本上没有介入,这个是无创的,风险可控的。我们有这个理念和目标,我们就会开发这个系统,达到这个目标我们觉得是一个成功的无阈值智能监控系统。

对无阈值智能监控系统要具备什么能力?三个。
第一就是最重要就是智能的能力,可以根据历史的数据自动的判断当前的系统运行的风险是不是一个正常的,是不是在一个正常的运行区间里面,如果不是的话可以判断当前的风险值是多少,风险概率值是多少,这个是第二点就是面向风险概率。
第三是自适应,这个告警也是自适应的,这个是它的三个关键点。
从技术上来讲,我们觉得是最重要的核心技术就是三类,第一是时序预测,这个大家比较了解,就是做回归,根据历史情况做预测。根据历史监控数据预测当前的情况,这个是它的第一个逻辑。
第二就是异常概率,或者是面向异常概率,基于异常概率的风险感知。大家知道做统计分析的话预测和实际有误差,根据这个误差建立模型,看看当前的监控是否异常。
第三类就是自适应风险告警系统,这个是我们总结的一个比较重要的能力。它本质上就是根据异常累计,异常时序累计值的数据判断是不是要告警,如果达到一定的百分比就会告警。这个比例和数据具体值是多少,百分之几,或者说中间用多少的CPU没有关系,这个是一个概率的基值,是自适应的告警模型,这个是三类技术。

3. 规模化应用关键点及解决方案
再接下来说一下我们在规模化应用中碰到的问题,和怎么解决的,实际上我刚刚说三类模型怎么协同工作。
先说一下银行系统对监控工具的要求,首先是非侵入,这个是硬指标,不能为了监控去把版本变更,这个是有问题的。
第二是漏报率低、误报率低。不能漏报高,这个是硬性要求,有问题没有报是很严重的问题。误报率要求最好是低,误报率高的话人会累一点,值班的会辛苦一点,漏报率一定不能高。
第四就是成本低,我们架构转型了以后,X86分布式系统量是很大,一定要具备规模化应用的能力,这是我们对监控工具的要求。

在这个要求之下,我们采取了什么样的规模化的策略?
我们说一下规模化应用几个关键点,大家很容易理解了就是多场景预测的准确性,这个是最基本,要预测准确。
第二就是并行建模及预测,这个也好理解,对每一个监控项建模,一定是并行的建模,然后做预测。
第三就是跨平台的治理,这个是面临的共性问题,我们也有自己的方法。
第四就是模型的自动选择,这个是很重要的一点。在我们系统中用了很多模型,每一类模型有不同的实践方法,模型不可以人去选,人去选就没有意义了,没有办法规模化推广,是自动训练。
第五就是自适应的告警,前面说了这个告警不能漏报,不能误报。
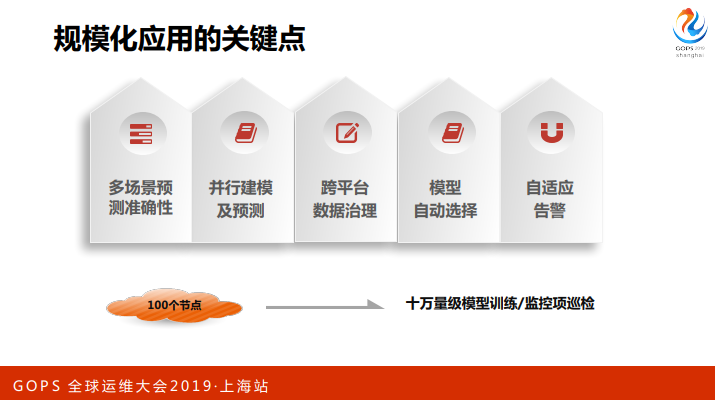
我们有一个分布式的无阈值智能监控系统,这个可以实现10万量级的,100个节点来做。像我们行,我们数据中心或者是监控项大概是几百万,现在我们的规模是下移的过程中一部分是X86,一部分是集中式的模式。在未来几年,这个X86规模会迅速的膨胀。
说一下多场景下预测准确性的问题,我们刚刚说过时序特征,银行的业务的时序特征带动的社会也有时序的特征,包括批量也是这样。银行的批量时间也是大部分都是比较固定的,很容易学习到这个长征。
当然极少数一些是无法预测,绝大多数有时序特征,包括三个,一个是周期性,第二是趋势性,第三是特殊时点,因为银行每年有特殊的时点像春节抢红包,还有双十一。
根据不同时序特征建模,分成4类,时序线性相关,第二是时序非线性相关,像TPS。第三是非时序性相关,监控项之间线性相关,典型就是CPU和DPS有很强的关联性。第四是特殊时点,就是双十一、春节高峰。
对不同的时序特征建模,就可以更好的刻画,更好的做预测。你最后要选择合适的时序分析工具像线性回归,还有ARIMA,以及深度学习,PROPHET。
我们采取这些策略可以保证多场景下的预测的准确性,我们总结这些不同的时序特征可以覆盖所有的场景,这个是我们的策略。

第二是并行建模及预测,这个并不是我们一个新的技术,这个是可以保证大规模并行能力很重要一点,我们把核心算法做了规模化的部署,用到一些人工智能或者是机器学习的算法,实现了云端的并行建模。我们还做到了计算压力的动态分布,我们是用一些工具和平台。
核心的计算资源,特别是GPU,我们是通过资源去化,动态调度,实现了最少的资源发挥了最大的功能。

第三就是跨平台的异构监控数据治理,这个是我们面对一个共性的问题,我们也是用了比较低成本的方式来做,我们做的就是实时数据抽取引擎,这个包括直接读取,用第三方工具,还有参数化,可配置,完成监控项时序字段的分解,这样就可以实现实时数据的抽取,对生产数据分离也不会对生产有压力。

第二是海量的存储,我们用了HADOOP,MAPREDUCE进行并行的计算,这个是跨平台的数据治理。
这个包括一个方面,就是我们模型训练的时候有一些数据的处理,这一个就是噪音数据来源,这个是大家见过不是很多,就是这个监控的数据噪音是什么样?归纳了几种,一个是随机噪音,你不知道怎么来。第二就是投产变更产生的噪音,比如说停机起机,这个很正常。还有一个就是采样工具,我们用第三方采样工具,有的时候莫名其妙有一些噪音。这些噪音数据一定要识别,而且要处理,识别不出来的话一训练的话这个训练就完了。
第二是缺失的数据补齐,我们用的一个就是区间众数,第二就是用PRPHET预测补齐。你用其他的方式的预测补齐也可以。
第三是异常数据的清理,第一个就是面向异常概率,这个是我们比较满意的一块,比如说一个起伏我们判断是异常,可能它也不是异常。比如说他是正常的,我们训练的时候就不应该清理掉,这个是要面向异常概率的数据清洗。
第二是投产后的取消清理,投产一两天我们会取消清理,那么一些正常的就开始工作了,这个是异常清理的流程。

下面说一下模型自动选择和预测,我们用了很多模型,模型的预测和选择要自动化,怎么做到?我们有一个模型自动选择的规则库,我们把不同识别特征进行了总结,第一个就是皮尔逊线性相关系数大于0.85选择线性回归模型。第二就是稳态或差分稳态选择ARIMA模型。第三就是置信区间预测选择PROPHET。第四未明时序特征预测选择深度学习。
这是我们底层的规则库,我们应用的过程中,对一个具体的监控项来说,可能是固定的,它没有变化,我们说是非常的稳定,我们在这个基础上把监控项预测模型建立了监控值预测模型库,比如说CPU、内存、磁盘空间用线性。响应时间成功率用什么,MQ用什么,TPS用什么,这个好处是什么?你一告诉我是监控什么就可以选择模型了,不要我们人去判断了,可以根据历史的数据选择模型,这个是我们规模化最好的一个取得的成绩。

最后一个关键点就是自适应的告警模型,给大家展示一下我们研究的成果。我们对异常的分布做了研究,异常分布是有规律,第一个异常值是正态分布,这个是偏态分布,我们可以变成正态。
第二就是自愈时间程幂率分布,出现了异常大部分是自己恢复了,而且是很快恢复了,真正持续时间很长的异常是很少,它的自愈时间长短是第二个分布。
第三就是风险概率厚尾分布,对我们维护人员来说,一个异常持续的时间越长,已经不消,肯定有问题,这些是我们要关注的异常。

这个是我们基于异常分布做的自适应的告警模型。
告警模型怎么做?说出来大家都知道,就是异常值和持续时间的积分,就是一个概率。第二个就是异常容忍度,我们这个系统对异常有容忍,有的系统容忍度高,有的容忍度低,我们划成了一个0到100的刻度,0和100是极端了,0是什么都没有事,100就是有一点都不可以忍受。
越接近100就是说明这个异常以前从来没有出现过,比如说它达到这个区间是以前没有出现过的这种现象,那么肯定有高风险,这个是异常容忍。我们一般来说,越重要的系统容忍度的值越高,或者说它越不能容忍异常。通过这个我们就实现了阈值的告警,或者是自适应的告警,你上线以后告诉我是什么等级,容忍度多少,就知道需要不需要告警。

这个是我们无阈值智能监控系统的系统架构图,这个箭头是数据的流向,是从生产系统或者是第三方工具通过实时数据抽取引擎采集过来,放在大数据的平台上,进行一些处理,这些处理包括拆成时序,分钟级、小时级,天级来抽取,进行一些达标。比如说告诉它今天是变更日,它可以不去预警了,另一方面就是不做异常的数据清理了,快速的可以培养新的运行特征。
再往这一块就是时序的预测模型库,我们也是归纳了一些参数。比如说时序参数,清洗的规则,预测的区间,监控参数等等,每一个构成了时序模型,可配置的方式也是保存起来,下一次数据来了以后告诉它是什么模型就直接调,直接跑。
上面这一块就是虚拟的私有云平台,通过规模化并行的模型训练我们做的。
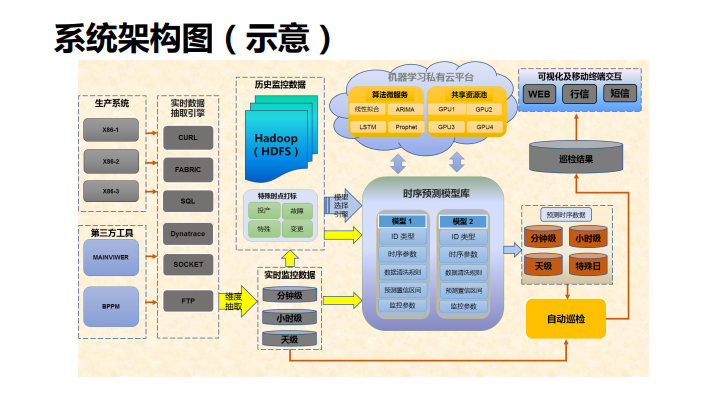
接下来就是一些预测了,自动巡检和预测,有一个巡检的结果,这个通过可视化的方式来主动的推送,实现自适应主动的告警。
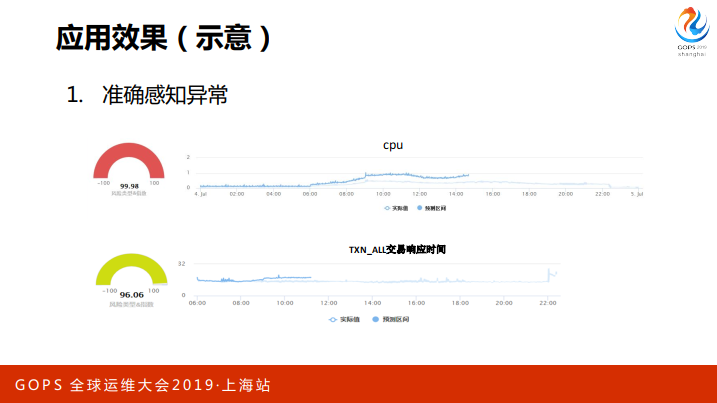
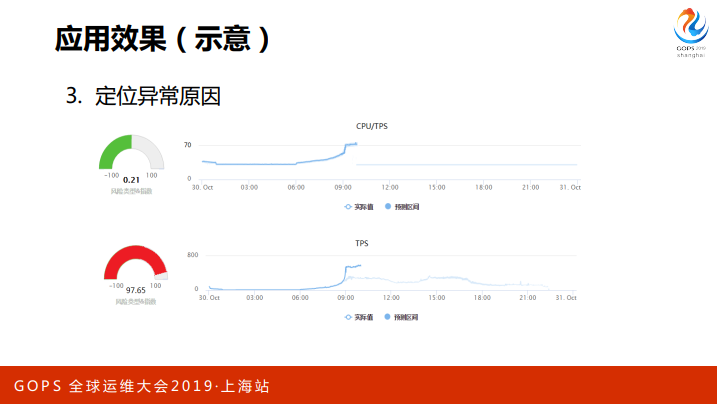
这个是一个应用的效果图,这个是CPU的,明显是偏了,其实很低,只有百分之1到2%,这个在传统的框架下是忽略掉,其实这个已经有异常了,而且异常值很高。下面就是响应时间,响应时间也有偏移,偏移的程度不是很高,就没有达到非常红的预警,也值得我们关注。这个是准确感知异常,出了一场了,会感知到。
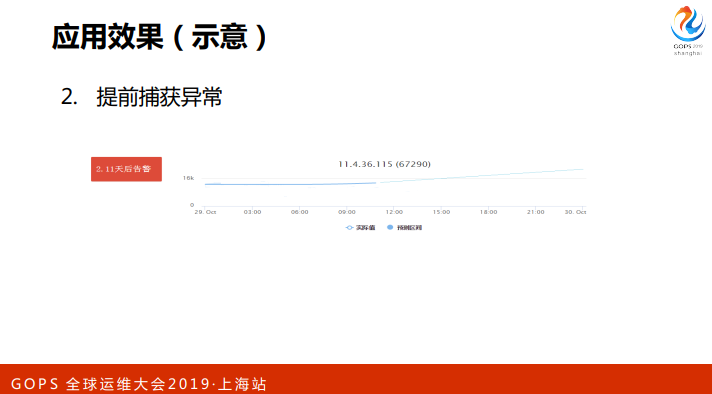
第二块效果就是提前捕获异常,什么概念?这个适合于做线性回归的异常,只要有异常就可以感知到。这个是一个文件系统,平时很缓慢的增长,某一个点急剧上升,而且预测明天告警,达到了传统的固定预警的方式,我们就用两天的时间查问题是非常的充裕。
这个是关联监控的定位异常的原因,上面就是监控项之间的线性强相关性的关联。这个监控图上可以看到这个是根据TPS来的,TPS高的话CPU高这个是正常的,如果是单纯的看CPU会很高,如果用异常检测就会告警了,实际上这个是比较安全的事情,CPU和TPS是相关性保持的很好,离拐点很远,不要有什么措施,关注就可以了。
下面就是CPU高不是TPS高引起的,这个为什么交易量会陡增?这个是因为外围的系统引起的。
4. 推广成效及展望
再接下来说一下推广的成效,我要说的就是我们对一个新上的系统有一个原则,就是推广应用,要先试点,再逐步推广,特别是我们大规模应用来说一定要先试点。
第二就是先并存再逐步替代,这个也是一个原则,是更加慎重的原则,不能轻易的替代原来的传统的方式。现在很多流程、机制都是基于传统的方式做出来的,我们现在行在试点和并存这个阶段。
目前推广就是以X86分布式系统为主,我们是从核心银行系统试点,我们第一个主机下移的就是核心系统,差了一多半了。也推广到渠道和外围多个系统,这个环境还不错。

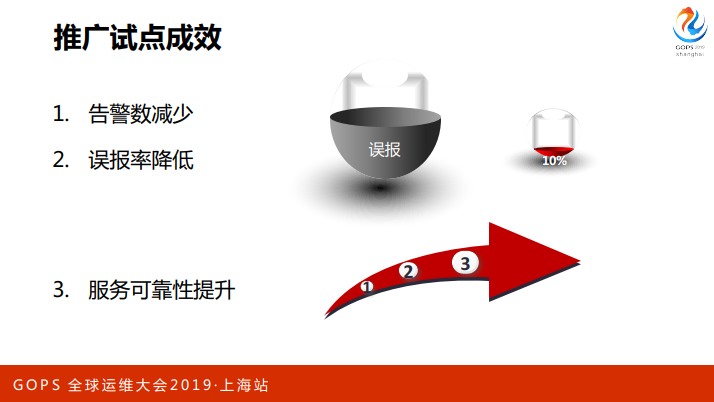
我们主要感受是什么?可以提前的化解风险,我们有这个案例,可以让安全事故消除在萌芽阶段,这个是比较有成效。告警的总数会减少,误报会少,对我们值班同事意义很好。
最终体现在系统上,对外服务连续性很好,没有什么中断性。刚刚上线有一些应急的情况,比如说CPU或者是交易到达什么情况要加入什么资源,现在有什么异常可以提前做这些事情,这个是我们推广的成效。
之后我们会在转型的意义上去推广,我们还要进一步的开展应用的场景,开展未来风险预测,我们觉得未来的风险和现在的风险有一定的关联。这个预测是数据积累到一定的程度可以预测,可以做监督的学习。
还有就是推广服务范围,这个可以考虑,为双十一提供趋势预测,双十一的时候峰值达到多少,我们可以提前知道,那么就可以做资源的调整或者是一些生产能力的储备。

