@gaoxiaoyunwei2017
2017-12-18T06:04:56.000000Z
字数 4980
阅读 1378
百亿访问量的监控平台如何炼成
彭小阳

作者简介:李春旭,2016年加入WiFi万能钥匙,现任WiFi万能钥匙高级架构师,十年互联网研发经验,喜欢折腾技术,曾供职于快钱、阿里巴巴、平安健康等公司,专注于以下领域:分布式监控平台、调用链跟踪平台、统一日志平台、应用性能管理、稳定性保障体系建设等。
前言:
大家下午好,很开心能够跟大家分享WiFi万能钥匙在监控领域做的一些事情,希望今天的分享能够给大家带来收获与价值。今天分享的主题《百万访问量的监控平台如何炼成》,罗马(Roma)项目名称的来历比较有意义:1、罗马不是一天成炼的(线上监控目标相关指标需要逐步完善);2、条条大路通罗马(罗马通过多种数据采集方式收集各监控目标的数据);3、据神话记载特洛伊之战后部分特洛伊人的后代铸造了古代罗马帝国(一个故事的延续、一个新项目的诞生)。今天我将通过三大部分进行讲解:背景介绍(我们公司当初面临的一些问题与挑战)、架构设计(结合公司现状谈一谈我们的监控平台是如何实现)、最佳实践(通过项目演示谈一谈我们的监控平台实践情况)。
一、 背景介绍
随着WiFi万能钥匙日活跃用户大规模的增长,钥匙团队正进行着一场无硝烟的战争:越来越多的应用服务面临着流量激增、架构扩展、性能瓶颈等问题,为了应对并支撑业务的高速发展,我们迈入了SOA、Microservice、API Gateway等组件化及服务化的时代。伴随着各系统微服务化的演进,服务数量、机器规模不断增长,线上环境也变得日益复杂,工程师们每天都会面临着这些苦恼:
线上应用出现故障问题时无法第一时间感知;
面对线上应用产生的海量日志,排查故障问题时一筹莫展;
应用系统内部及系统间的调用链路产生故障问题时难以定位;
......
线上应用的性能问题和异常错误已经成为困扰开发人员和运维人员最大的挑战,而排查这类问题往往需要几个小时甚至几天的时间,严重影响了效率和业务发展。
本次分享将介绍万能钥匙是如何构建一站式、一体化的监控平台,从而实现提升故障发现率、缩短故障处理周期、减少用户投诉率等目标。
1、产品介绍
始于盛大创新院的WiFi万能钥匙在整个过去四年中,我们就是在致力于做一件事情“连接”,我们要帮助这些用户更快更好更安全的连上网。
WiFi万能钥匙从原来的帮助用户连接上网,发展到现在,在帮助连接的同时我们希望做连接后所有的服务。我们向用户推荐更精准的内容,我们让用户享受在他附近的生活中的各类便捷服务,同时让用户在上面消费更多的内容。
2、产品数据

截至到2016年底,我们总用户量已突破9亿、月活跃达5.2亿,用户分布在全球223个国家和地区,在全球可连接热点4亿,日均连接次数超过40亿次。
3、用户体验
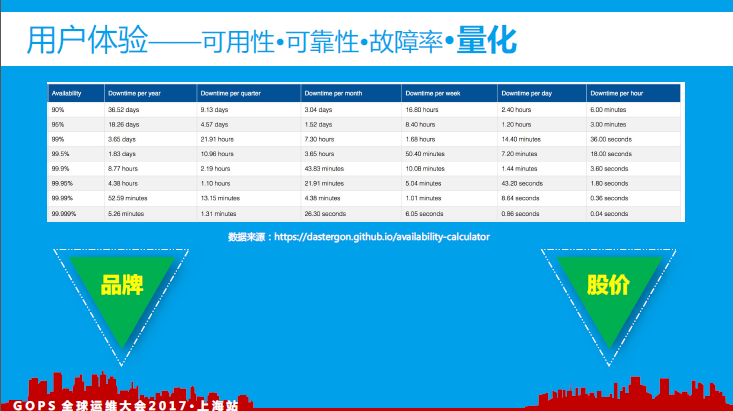
我们可以通过一组数据(可用性指标)来思考每一次故障的背后对用户带来了哪些伤害?给公司的品牌价值、股价等带来哪些不利影响?
4、监控现状
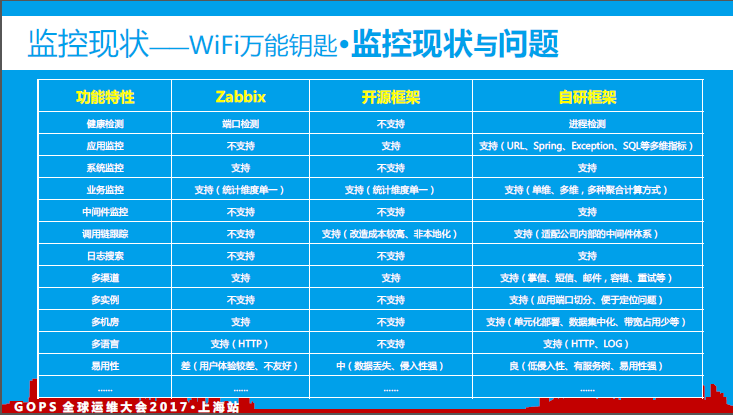
早期为了快速支撑业务发展,我们主要使用了开源的监控方案保障线上系统的稳定性:某开源监控框架、Zabbix,随着各产品线业务的快速发展,开源的解决方案已经不能满足我们的业务需求,我们迫切需要构建一套满足我们现状的全链路监控体系:
多维度监控(系统监控、业务监控、应用监控、日志搜索、调用链跟踪等)
多实例支撑(满足线上应用在单台物理机上部署多个应用实例场景需求等)
多语言支撑(满足各团队多开发语言场景的监控支撑,Go、C++、PHP等)
多机房支撑(满足国内外多个机房内应用的监控支撑,机房间数据同步等)
多渠道报警(满足多渠道报警支撑、内部系统对接,邮件、掌信、短信等)
调用链跟踪(满足应用内、应用间调用链跟踪需求,内部中间件升级改造等)
统一日志搜索(实现线上应用日志、Nginx日志等集中化日志搜索与管控等)
……
5、监控目标

如图所示,从“应用”角度我们把监控体系划分为:应用外、应用内、应用间。
应用外:主要是从应用所处的运行时环境进行监控(硬件、网络、操作系统等)
应用内:主要从用户请求至应用内部的不同方面(JVM、URL、Method、SQL等)
应用间:主要是从分布式调用链跟踪的视角进行监控(依赖分析、容量规划等)
6、参考案例
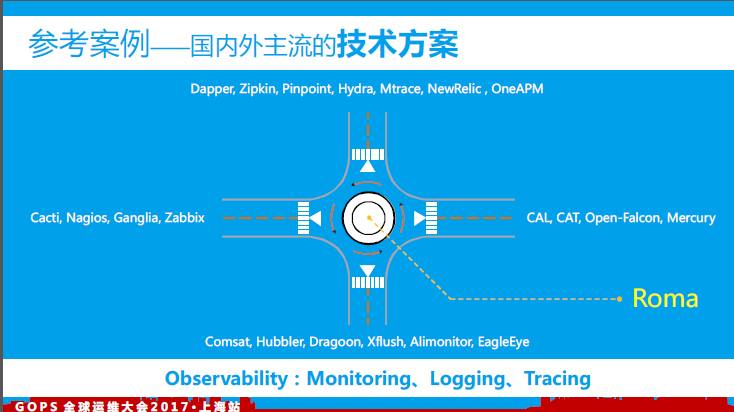
一个完美的监控体系会涵盖IT领域内方方面面的监控目标,从目前国内外各互联网公司的监控发展来看,很多公司把不同的监控目标划分了不同的研发团队进行处理,但这样的会带来一些问题:人力资源浪费、系统重复建设、数据资产不统一、全链路监控实施困难。罗马(Roma)监控体系如图中所示,希望能够汲取各方优秀的架构设计理念,融合不同的监控维度实现监控体系的“一体化”、“全链路”等。
二、 架构设计

面对每天40多亿次的WiFi连接请求,每次请求都会经历内部数十个微服务系统,每个微服务的监控维度又都会涉及应用外、应用内、应用间等多个监控指标,目前罗马监控体系每天需要处理近千亿次指标数据、近百TB日志数据。面对海量的监控数据罗马(Roma)如何应对处理?接下来将从系统架构设计的角度逐一进行剖析。
1、架构原理
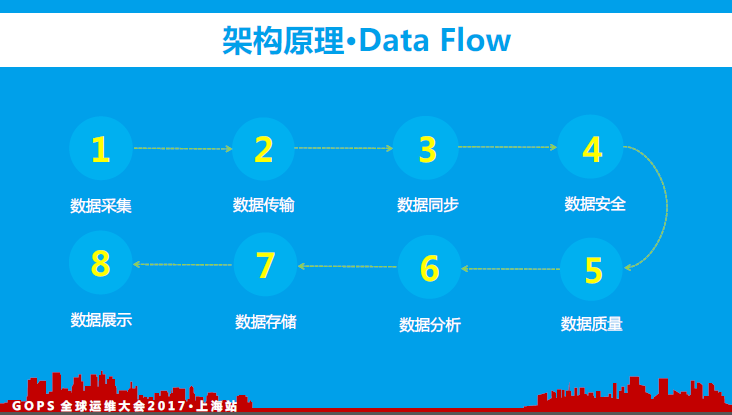
一个完美的监控平台至少需要具备数据平台的所有功能特性。
2、 架构原则
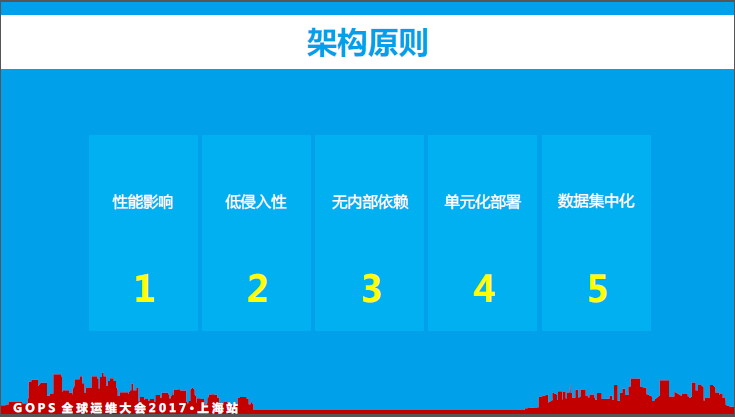
一个监控系统对于接入使用方应用而言,需要满足如下图中所示的五点:
性能影响:对业务系统的性能影响最小化(CPU、Load、Memory、IO等)
低侵入性:方便业务系统接入使用(无需编码或极少编码即可实现系统接入)
无内部依赖:不依赖公司内部核心系统(避免被依赖系统故障导致相互依赖)
单元化部署:监控系统需要支撑单元化部署(支持多机房单元化部署)
数据集中化:监控数据集中化处理、分析、存储等(便于数据统计等)
3、业务架构

上图是业务架构图,从最下侧不同的指标数据来源,到最上面包括图表展示、配置管理等,最左侧主要是做一些离线分析、实时分析等,最右侧处理一些统计报表、周报等。
4、应用架构
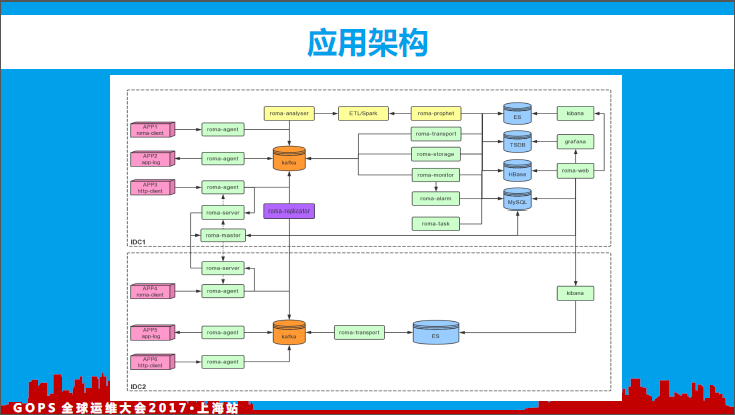
罗马架构中各个组件的功能职责、用途说明如下:
「表格」
5、技术架构

罗马整体架构中数据流处理的不同阶段主要使用到的技术栈如上图所示。
6、配置下发
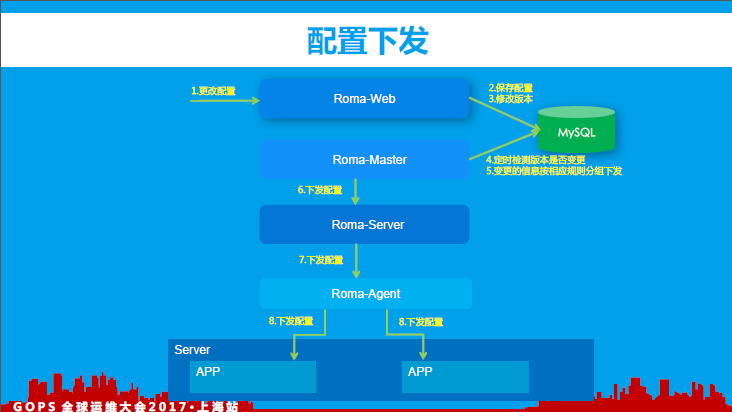
罗马中client->agent->server->master四者之间通过TCP协议建立连接(短连接、长连接),当用户在前端web层进行配置变更时会触发配置下发的动作(如:日志管理中新增应用日志目录、调度脚本执行策略发生变更等)。在整个架构设计过程中需要支撑跨机房间的配置下发,由于机房间网络的不稳定,整个配置下发的过程需要支持推和拉两种模式(用于处理配置下发过程中的各种错误场景)
7、数据采集
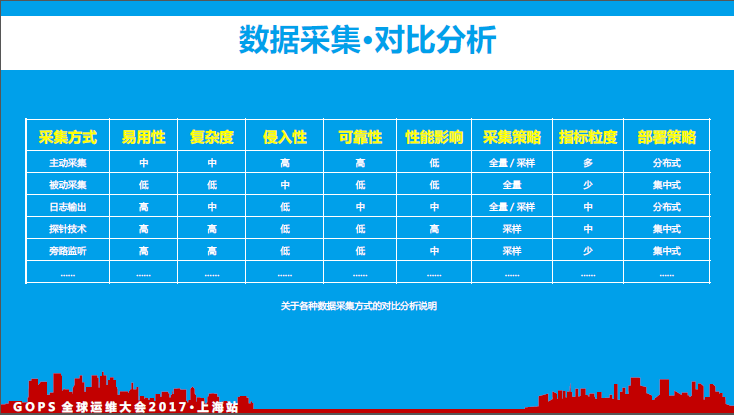
我们可以通过对各种不同的数据采集方式进行对比分析,除了以上图中所示的对比分析的维度,还可以从人力投入成本(人数、时间等)进行分析,只有适合自己公司现状的数据采集方式才是最适合的方案。
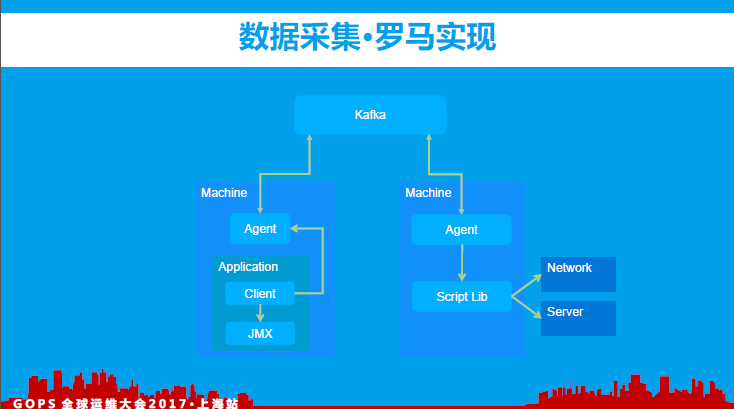
我们的应用内监控主要是通过client客户端与所在机器上的agent建立TCP长连接的方式进行数据采集,agent同时也需要具备支持脚本调度的方式获取系统(网络或其它组件)的性能指标数据。
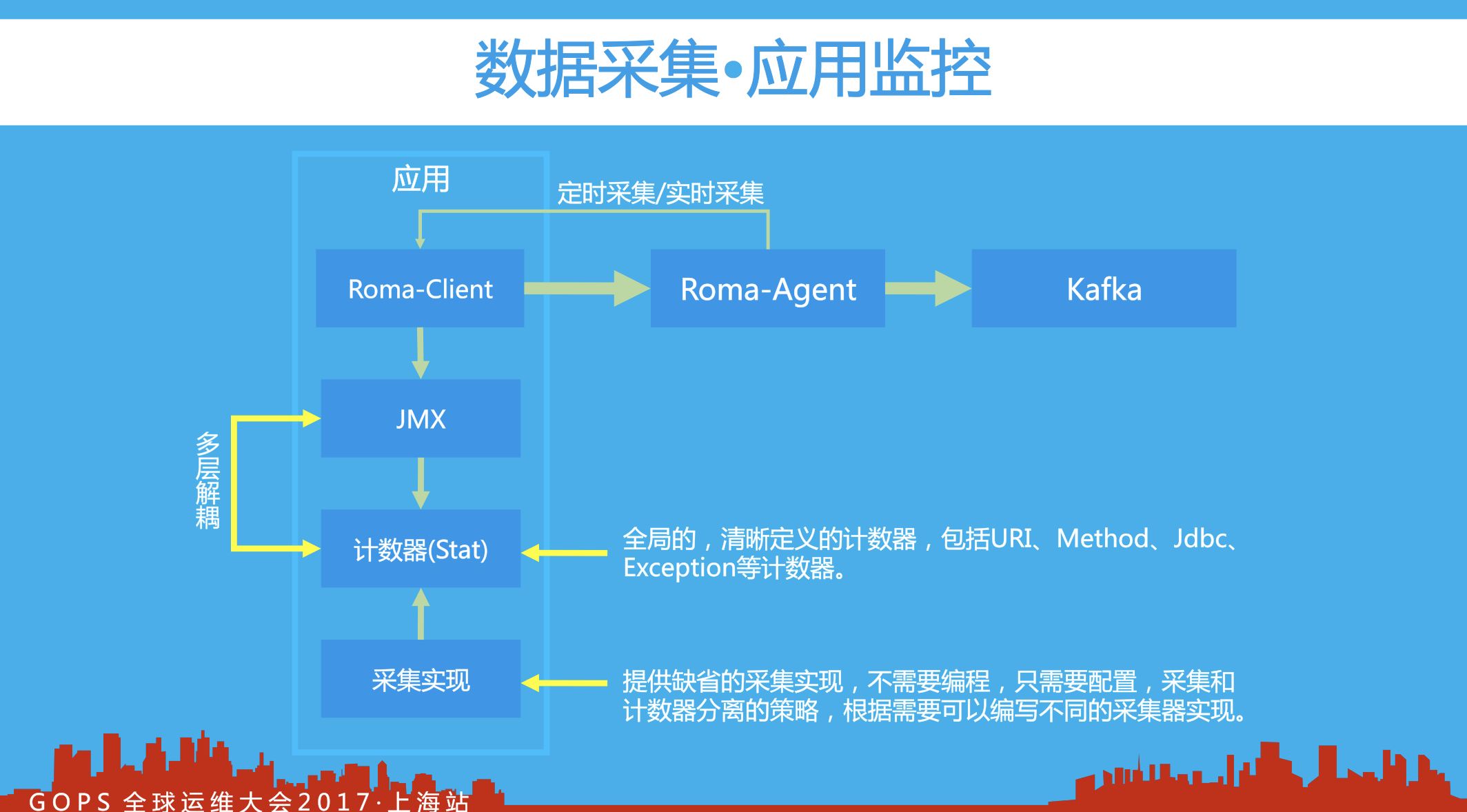
面对海量的监控指标数据,罗马监控通过在各层中预聚合的方式进行汇总计算,
比如在客户端中相同URL请求的指标数据在一分钟内汇总计算后统计结果为一条记录(分钟内相同请求进行累加计算,通过占用极少内存、减少数据传输量),对于一个接入并使用罗马的系统,完全可以根据其实例数、指标维度、采集频率等进行监控数据规模的统计计算。通过各层分级预聚合,减少了海量数据在网络中的数据传输,减少了数据存储成本,节省了网络带宽资源和磁盘存储空间等。
应用内监控的实现原理(如上图所示):主要是通过客户端采集,在应用内部的各个层面进行拦截统计: URL、Method、Exception、SQL等不同维度的指标数据。
8、数据传输
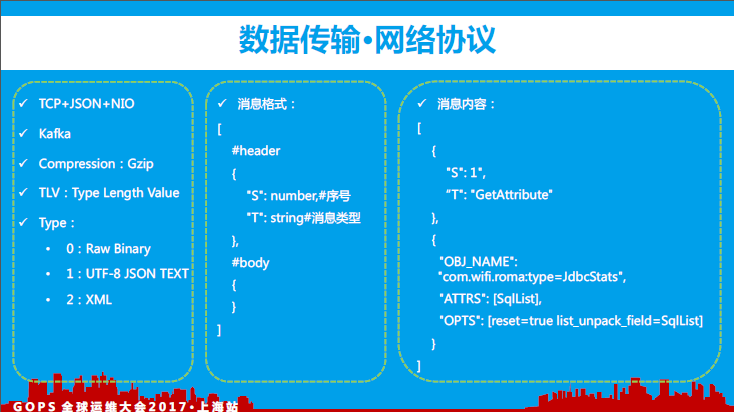
数据传输层主要使用TLV协议,支持二进制、JSON、XML等多种类型。
9、数据同步
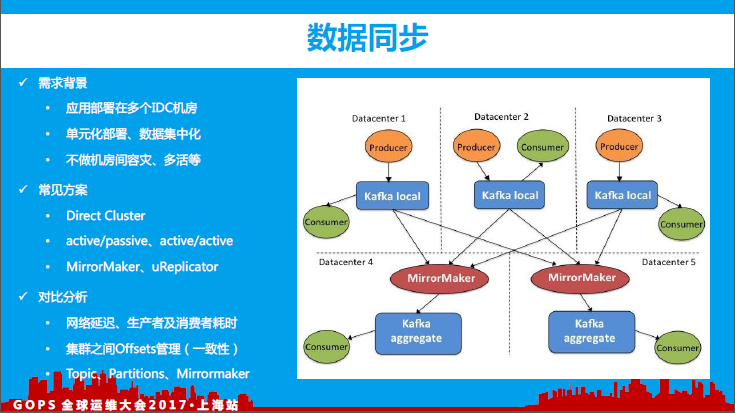
由于我们公司产品用户形态分布于国内外223个国家,海外运营商众多,公网覆盖质量参差不齐,再加上运营商互联策略的不同,付出的代价将是高时延、高丢包的网络质量,钥匙产品走向海外过程中,我们会对整体网络质量情况有正确的评估跟预期,比如对于海外机房内的应用进行监控则需要对监控指标数据建立分级处理,对于实时、准实时、离线等不同需求的指标数据采集时进行归类划分(控制不同需求、不同数据规模等指标数据进行采样策略的调整)
罗马监控平台支持多机房内应用监控的场景,为了避免罗马各组件在各个机房内重复部署,同时便于监控指标数据的统一存储、统一分析等,各个机房内的监控指标数据最终会同步至主机房内,最终在主机房内进行数据分析、数据存储等。
为了实现多机房间数据同步,我们主要是利用kafka跨数据中心部署的高可用方案,在对比分析了MirrorMaker、uReplicator后,我们决定基于uReplicator进行二次开发,主要是因为当MirrorMaker节点发生故障时,数据复制延迟较大,对于动态添加topic则需要重启进程、黑白名单管理完全静态等。虽然uReplicator针对MirrorMaker进行了大量优化,但在我们的大量测试之后仍遇到众多问题,我们需要具备动态管理MirrorMaker进程的能力,同时我们也不希望每次都重启MirrorMaker进程。
10、数据分析

在整个数据流处理过程中,我们面临着很多实际的困难与挑战,比如对于数据过期处理的策略、数据追踪策略等都需要有对应的处理方案。
11、数据存储
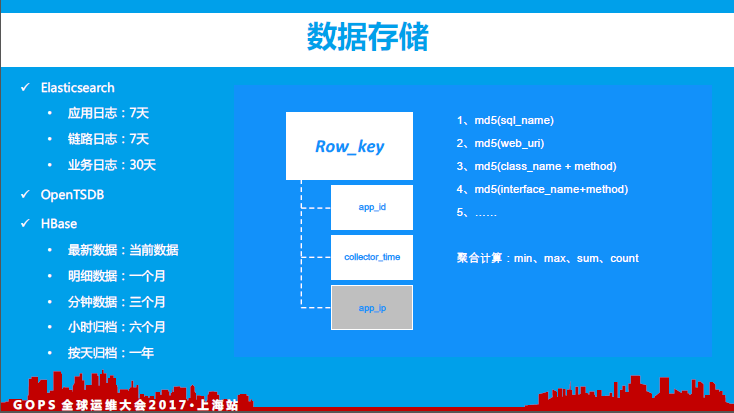
为了应对不同监控指标数据的存储需求,我们主要使用了HBase、OpenTSDB、Elasticsearch等数据存储框架。
数据存储层我们踩过了很多的坑,总结下来主要有以下几点:
集群划分:依据各产品线应用的数据规模,合理划分线上存储资源,比如我们的ES集群是按照产品线、核心系统、数据大小等进行规划切分;
性能优化:Linux系统层优化、TCP优化、存储参数优化等;
数据操作:数据批量入库(避免单条记录保存),例如针对HBase数据存储可以通过在客户端进行数据缓存、批量提交、避免客户端同RegionServer频繁建立连接(减少RPC请求次数等)
12、报警处理
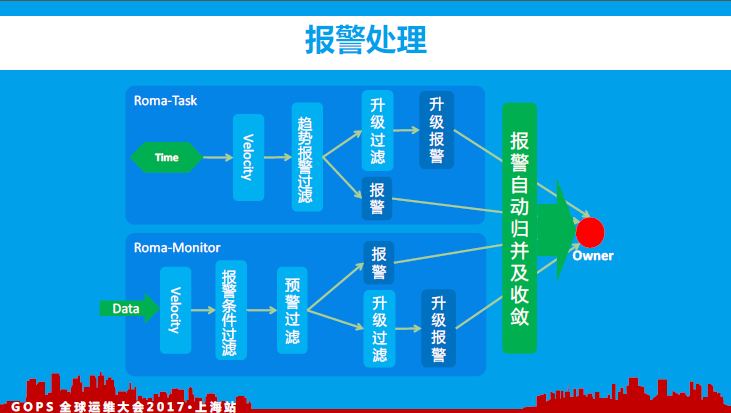
目前我们的报警处理流程主要分为实时报警、离线报警(准实时)、数据驱动、任务驱动(避免没有指标上报时数据阴跌等),对于所有的报警处理最终都会进行归并与收敛动作(后续会逐步建设我们的智能化监控系统,完善报警处理流程)
三、最佳实践

1、 调用链跟踪
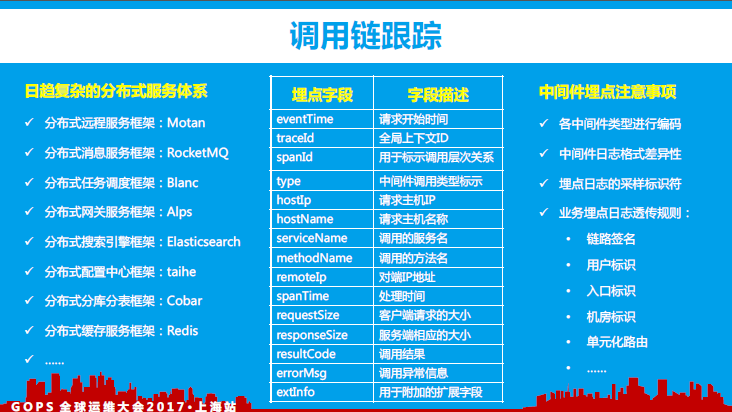
如上图所示,我们公司目前中间件领域的相关项目建设、调用链埋点信息及注意事项。

我们的调用链跟踪系统主要参考了Google Dapper论文、阿里巴巴EagleEye。如上图所示,在调用链跟踪埋点实现过程中,我们在处理上下文生成、异步调用等方面的解决方案。

如上图所示,我们在写日志处理、数据存储、数据分析等方面遇到的问题与应对方案。
2、功能演示
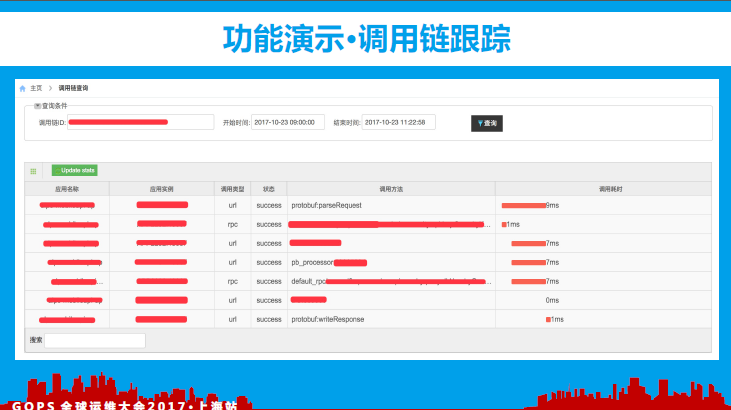
如上图所示,我们的调用链跟踪查询页面(可以根据TraceId查询整个调用链树)
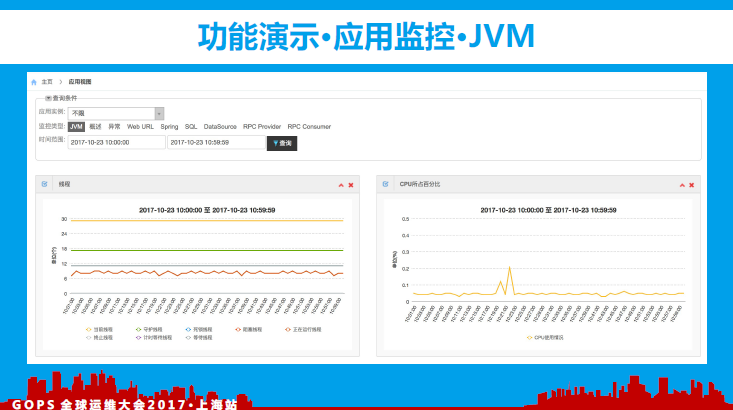
如上图所示,这是我们的应用监控(JVM相关指标图表展示效果)
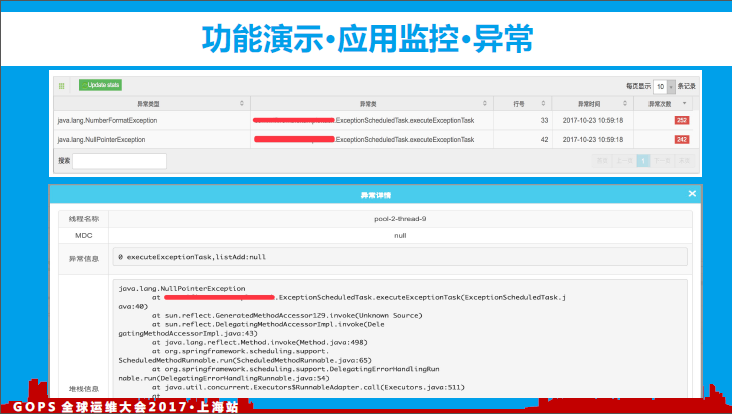
如上图所示,我们可以方便的跟踪线上某应用产生的各种异常堆栈信息。
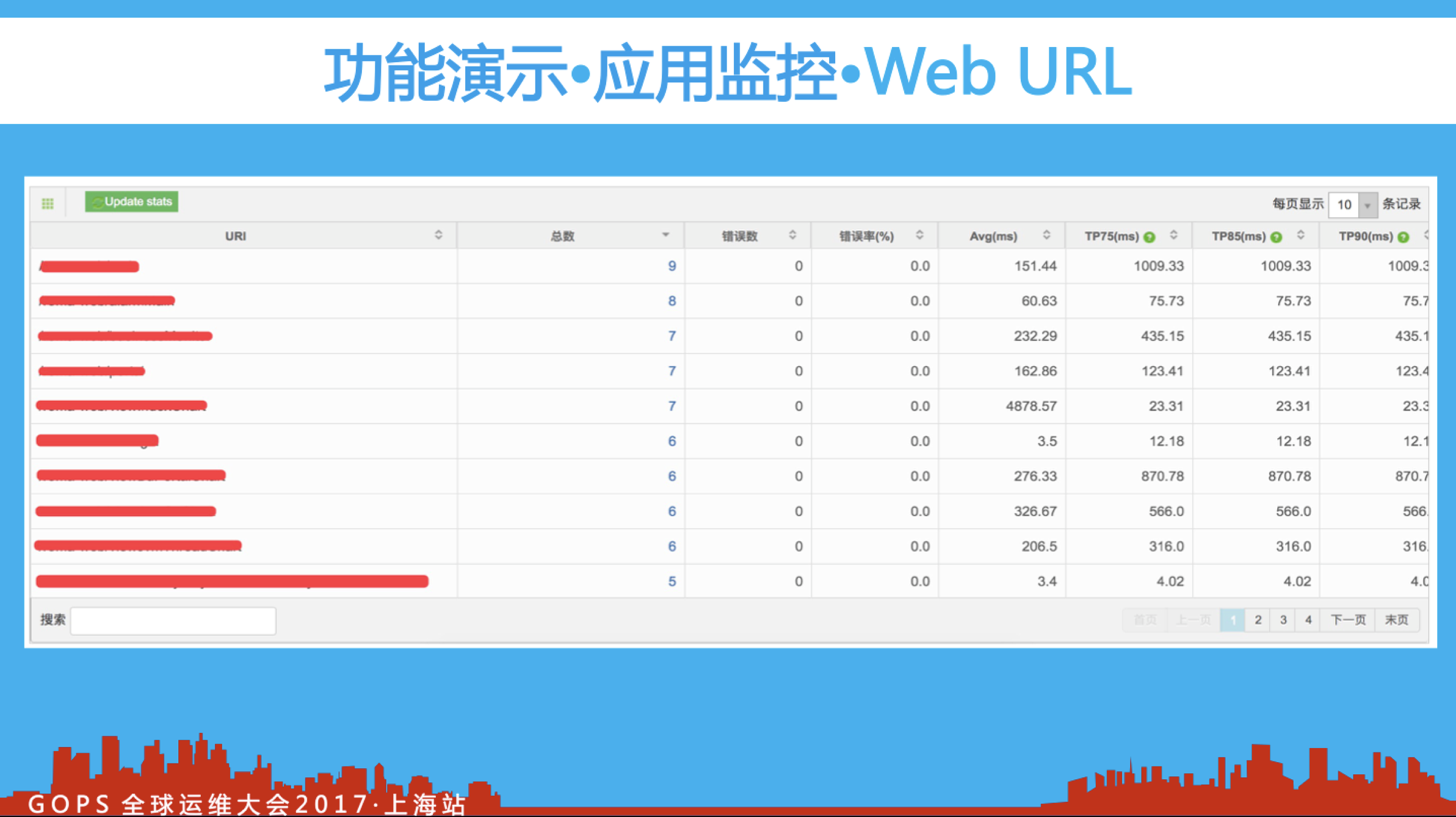
如上图所示,我们可以方便的跟踪线上URI请求的相关指标数据,点击访问总次数可以查看当前查询时段内的图表详情(如下图所示)

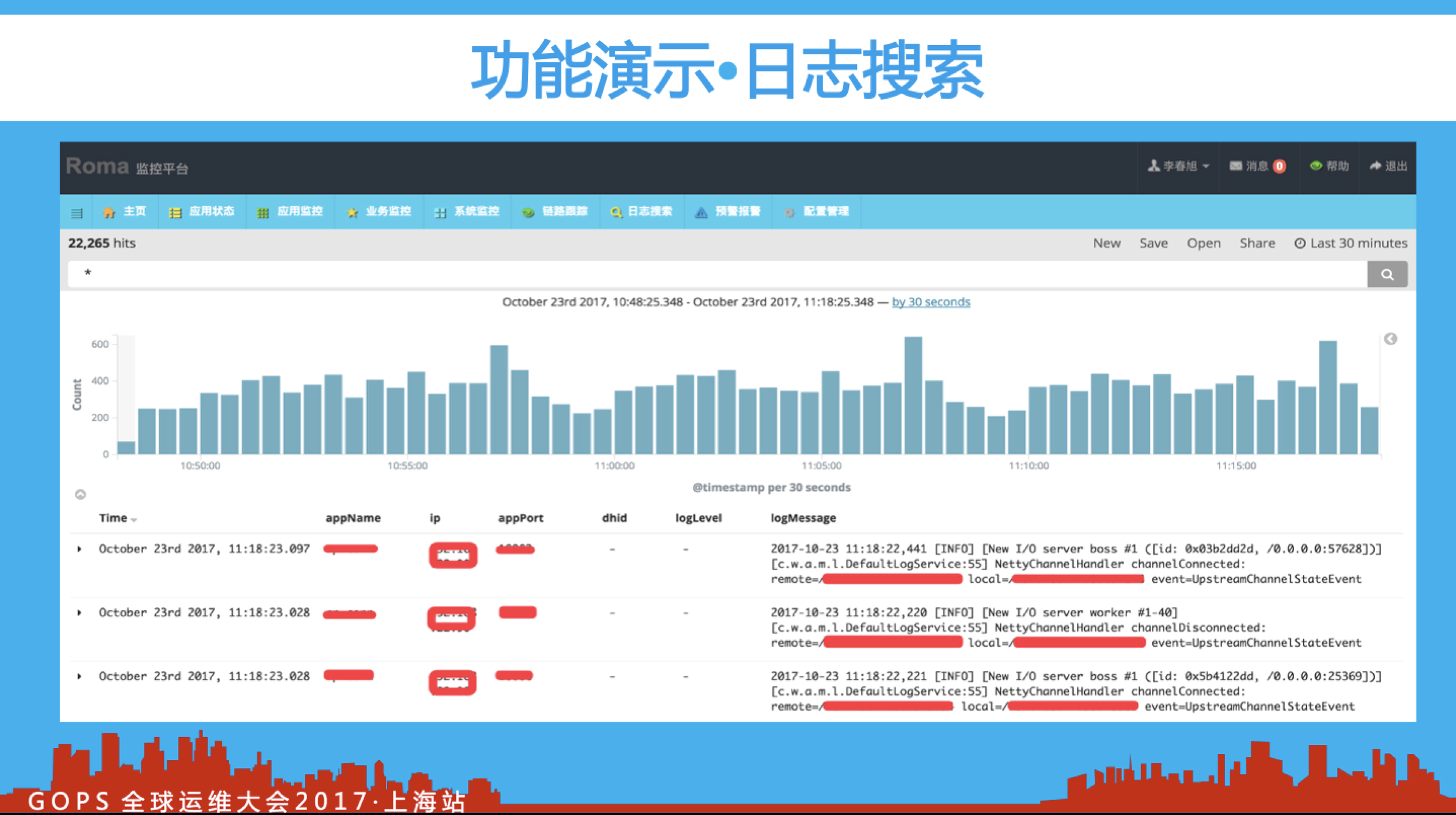
为了支撑好研发人员线上排查故障,我们开发了统一日志搜索平台,便于研发人员在海量日志中定位问题。
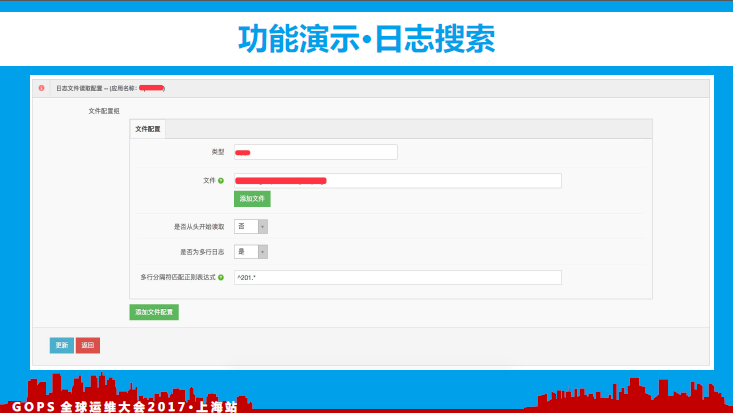
如下图所示:我们可以新增日志配置信息(应用日志路径、日志解析表达式等),该类信息会通过配置下发的功能下发至该应用所在的agent机器(agent会依据该配置信息进行日志相关的读取与处理)
四、未来展望
随着IT新兴技术的迅猛发展,罗马监控体系未来的演进之路:
系统间融合:同公司内部系统进行深度融合(项目管理平台、项目发布平台、性能测试平台、问题跟踪平台等)
容器化监控:容器使得微服务的运维变得高效和轻量,随着公司内部容器化技术的落地推广实施,我们也将需要支撑容器化监控方面的需求。
智能化监控:提高报警及时性、准确性等避免报警风暴(AIOps)
总结
罗马(Roma)是一个能够对应用进行深度监控的全链路监控平台,主要涵盖了应用外、应用内、应用间等不同维度的监控目标,例如应用监控、业务监控、系统监控、中间件监控、统一日志搜索、调用链跟踪等。能够帮助开发者进行快速故障诊断、性能瓶颈定位、架构梳理、依赖分析、容量评估等工作。

