@gaoxiaoyunwei2017
2020-05-09T06:56:21.000000Z
字数 7906
阅读 1503
基于云原生的DevOps能力编排平台实践
彭小阳
作者简介:曾海剑,广东移动DEVOPS总架构师。

本次分享主要是三个部分,第一部分就是动机,为什么需要引入云原生,第二个部分就是我们的云原生的一个实践架构是什么样的,最后是编排能力是什么。
一、 动机
第一个问题,为什么我们需要引入云原生。其实大家都知道运营商有很多的系统建设、系统开发,都是使用IT外包的形式来做,那使用IT外包本身是引入很多的问题。
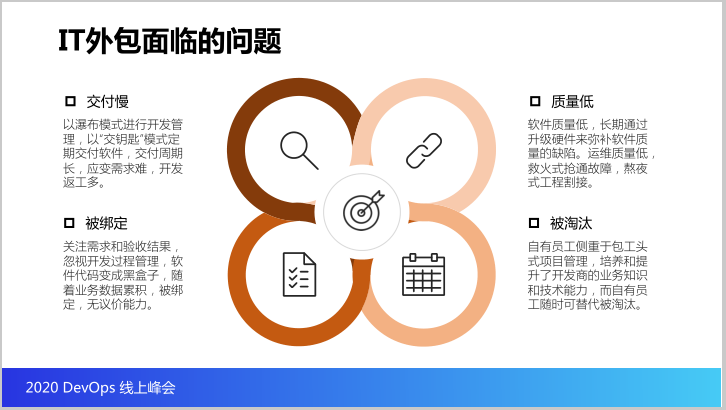
在这里分享几个核心问题。第一是交互慢,开发商是以瀑布模式进行开发管理,他们是以交钥匙的形式交给用方,交付时间长,应变需求难,经常会出现开发返工。
第二个问题质量低,体现在两个部分,第一是软件的质量低,因为很多的项目是通过一个升级硬件来弥补我们在软件设计上的一些缺陷,第二部分相对于运维质量低,基本上抢通故障就是救火式,工程割接就是熬夜式。
第三部分是被绑定被绑架,因为很多是关注需求和结果,也就是关注一个软件开发生命周期里面的头尾,而忽视了开发过程的管理,因此开发商移交过来的代码其实对我们来说是黑盒子,即使验收的时候会给我们这个代码,我们也没法验证这个代码是否能运行,而且随着他们的系统使用的过程累计很多数据,我们第二期第三期你只能绑定的继续用这个开发商。
第四个问题其实就是针对自身员工的被淘汰,自有员工很多情况下侧重当包工头,管项目,所以在这个过程我们是培养和提升开发商,包括业务知识和支持能力,但是自有的人员很尴尬,随时可以被替代,随时可以被淘汰。
前面两个问题交互慢、质量低是影响现状,但是后面两个问题很严重,后面两个问题被绑定影响的是企业的发展,被淘汰应该的是员工的发展。
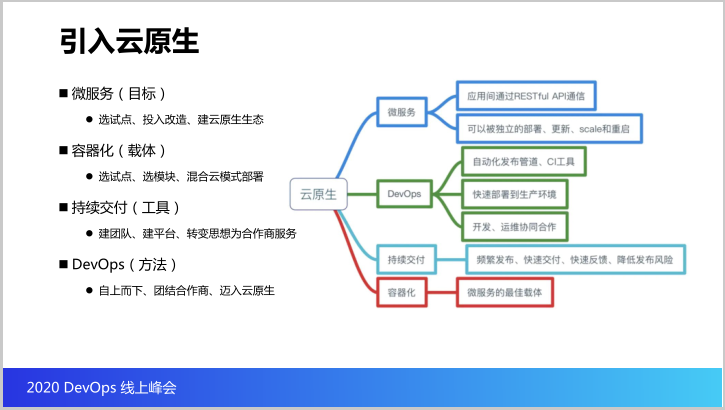
那引入的云原生到底是什么?我们怎么理解这个云原生?以及在引入这个云原生的过程中我们是怎么做的?我们看看右边的这副图,这副图其实是国内的一些社区对云原生的一个理解,所以我就在这里也当是分享一下。那么它分为四个关键词。
咱们云原生的一个目标,因为为了让咱们的系统更加容易适应变化,更加容易变化,更加容易升级,所以我们需要把传统的这种单体的架构改造成微服务的架构。
但是这个目标本身是引入了两个大的问题,几个大问题:第一系统复杂度变高,部署的难度提高了,最关键是对团队的能力要求也是增高了,所以其实在这个实践过程中,其实我们不是一下子就全面去铺开所有的系统一起做微服务改造,而是我们先选合适的有技术能力的开发商,把他们作为试点,先让某些开发商的某些系统做改造,先建立起一个云原生的生态圈。
第二个关键词就是容器化。其实刚才说到微服务部署复杂度非常高,如果继续使用这个虚拟化或者是那种物理机去部署,是否是一个最佳的载体?我看未必。那么企业从云原生的角度就提出了,其实容器化就是微服务的最合适载体,因为它非常轻量,而且迁移非常快,包括可以兼容各种的环境。
所以就是说在实践的过程中我们也是先选一些试点,例如说某个项目,但是我们选某个项目的时候我们也不会要求说这个项目的所有的模块都要以容器化的方式部署,那我们会要求选其中的合适容器化的部分先上容器化,那我们就实现了这样的情况,一个项目里边有部分模块是放在容器云里面,有部分模块还部署在传统架构里面。
第三个关键词就是持续交付。既然讲到要上容器化,上微服务,还用传统手工的上线的方式可行吗?很显然不可行,所以我们其实是需要建立一个持续交付的工具链。那么就是说在广东移动实践的过程中,我们2018年就开始做这一块,而且当时没有一些DevOps成熟的产品。
所以这一块我们其实也是自己去摸索做的,而且因为开源社区也有很多开源的组件给我们适用,因此我们通过建团队、建平台把持续交付的工具链建起来,并且最核心的我们是转变了思路,我们甲方的人员的思路转变为为乙方做服务。
云原生最后一个关键词就是方法。其实DevOps实践的方法,因为云原生所提供前面都是技术的范畴,DevOps严格意义上来说不单单是一个技术的范畴,还是一个管理的范畴,很有幸咱们的领导是一个自上而下的把DevOps这个方法推下去,并且团结了所有的合作商,让他们一起通过持续交付纳入云原生。
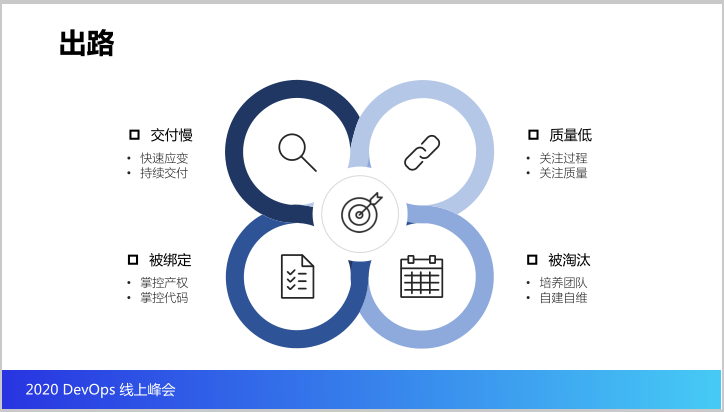
接下来看看云原生给我们解决了很多问题。
第一解决了交付慢的问题,有了持续交付我们的应变能力非常快。
第二质量低的问题解决了,因为代码质量、镜像安全、自动化的测试都可以通过持续交付,可以去收集上来,所以我们可以更加关注这个过程,更加关注质量。
第三个被绑定,我们是自建团队,所以我们掌握了这部分开发商提交的代码的产权,已经掌控了代码,保证代码在我们的CI/CD流水线里面跑得通,即使这家开发商也做,我们也有能力可以选择其他的开发商接管它的代码,不会被绑定,被绑架。
最后一个被淘汰,由于我们的DevOps能力编排平台是自己培养团队自建的,所以解决了自己人只是作为包工头的痛点。
二、实践
下面就是分享DevOps编排能力平台的实践。其实我觉得可能先看看DevOps能力编排平台给我们带来什么价值会更加直观一点。
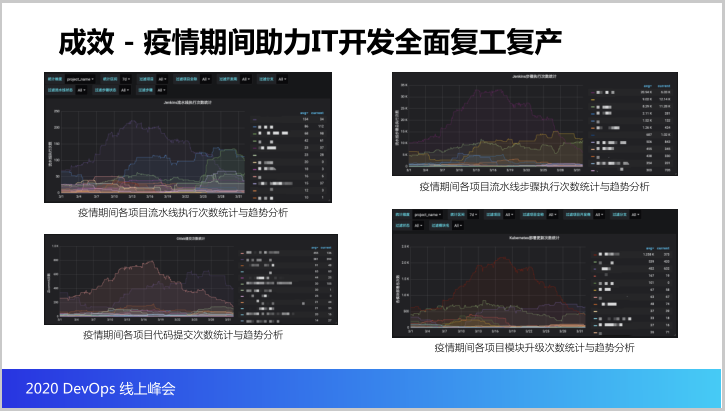
这里边四张图就是DevOps能力编排平台度量的一个指标,这里边这些指标怎么看呢?这是以一个项目的维度,以统计周期是刚好三月份完整一个月进行统计。
看四个指标,第一个指标就是疫情期间各个项目的流水线执行次数的统计,看一周下来我们有一个项目执行了两百次的流水线,接着我们的流水线的步骤,一个流水线里边可能涉及到很多的执行步骤,我们看一周单个项目可以去到三万多个执行步骤,那证明咱们的DevOps能力编排平台性能可以抗得住这么大流量的执行步骤过程。
最后看看这一部分,包括疫情期间每周代码提交的次数,找一个开发商,一周可以提交八百多次代码的以及单周某个项目的模块要部署到环境里面总共是设计到两千多个模块,一周一个项目升级两千多个模块。从数据里面可以看出来DevOps能力编排平台基本成为开发合作伙伴很重要的研发中台,去支撑他们疫情期间全面的复工复产,这个价值是非常重要的。
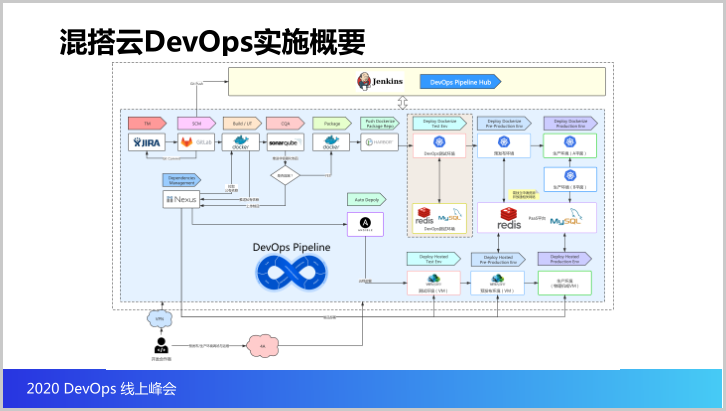
那接下来我们看看我们架构上的一些实践。首先先来看我们的DevOps能力编排平台控制的节点其实就相当于Jenkins,Jenkins就是控制咱们整个DevOps CI/CD的流程,整个流程就是贯穿了包括需求管理、源代码的管理。
当源代码有代码提交就会触发CI/CD流水线,CI/CD流水线大概的流程是先从源代码管理里面拉取代码,再用依赖管理从依赖里面拉相关的依赖进行构建,构建完成之后做代码质量扫描,接着把构建出来的制品打包成容器镜像,或者打包成task制品,然后上传到harbor里边。
我们其实为什么说能力编排平台支持异构云,异构云一部分能力可以让它发布到Knative环境,另外可以通过流水线把升级的制品发布到虚拟机、物理机的环境,所以这是支持异构云的实施。

接下来看看架构的实践,架构分成几层,操作系统层,上面这层是存储云,再上一层容器云Docker,再以上就是组件云和应用云,包括DevOps CI/CD所有流水线里面的组件全部都是放在容器里面,K8S里面,以及所有的企业应用包括DevOps的管理控制台,也是放在K8S的容器里面。
所以架构是分层的,并且这个层是高可用的,容器云高可用,随便一个节点,两个节点都没有问题,不会影响服务对外提供。而且我们使用的是K8S容器云,所以故障迁移非常快。
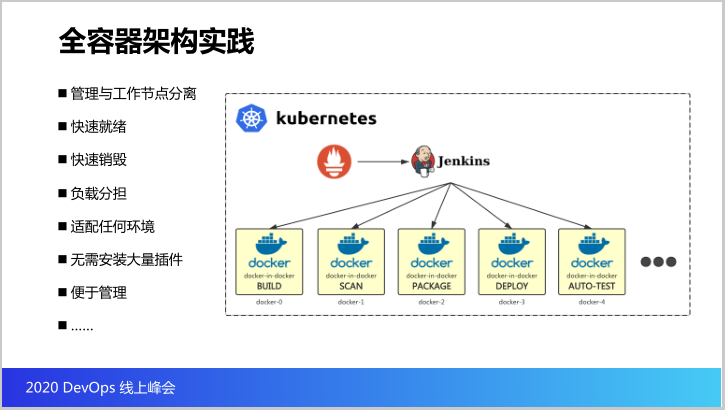
接下来我们看看全容器架构的实现,因为刚才我们已经提到我们这个DevOps的所有所有的组件全都在K8S里边,全容器,那么我们来看看怎么做调度和执行。
这里边有很特殊的组件,火炬,普罗米修斯。普罗米修斯就是用来收集容器云里面所运行的所有的Port所占用的各种资源和指标,那咱们这个Pipeline是怎么做调度的?
我们的Pipeline是Jenkins,我们是这样实现的,所有的调度任务是由Jenkins调度,但是具体的任务执行不在Jenkins里面,而是Jenkins当收到任务需要执行,会先问普罗米修斯,哪些空闲的容器可以帮我执行构建的任务。
那普罗米修斯就会告诉你Docker云刚好有空闲,那么Jenkins就会把提交的任务提交给Docker零,Docker零就会启动构建的容器,当构建的容器做完构建直口这个容器就自动销毁,然后继续往下走。
所以我们可以看得到Jenkins里面所有的具体执行的任务全部不在Jenkins的管理节点上执行,而是全部在K8S的Docker里面执行,包括各种构建任务、扫描任务、发布、自动化任务。
那这样的架构设计有什么优点?第一是管理节点和工作节点是分离的,这就意味着因为很多的高负载的工作是任务的节点,如果这些任务的节点在管理节点上执行,很容易把管理节点拖垮,所以我们要把调度和工作的节点分离。
第二可以快速就绪,因为我们是基于Docker零,所以运行的环境可以快速就绪,而且运行结束可以快速销毁,并且由普罗米修斯监测整个运行环境,可以让低容器运行高负载任务,而且它因为是基于容器,所以适配任何的环境,咱们的Jenkins无须安装大量的插件去支持这些构建环境、运行环境,非常便于管理,而且扩展性非常之好。

那么接下来我们来看看刚才提到既然是平台叫做DevOps能力编排平台,那它的编排能力是什么?总结了三大能力:流程编排、资源编排、服务编排。
第一个流程编排每个项目可能有很多模块,这些模块在流水线里边怎么去跑?以及这些项目的CI/CD流程里面涉及到哪些环节,哪些环节又可以跳过?这些控制可以通过流程编排去编排,其实就是编排我们的流水线长什么样。
第二个资源编排,资源编排其实就是咱们的应用怎么运行在云原生环境,可以通过编排的能力去实现。
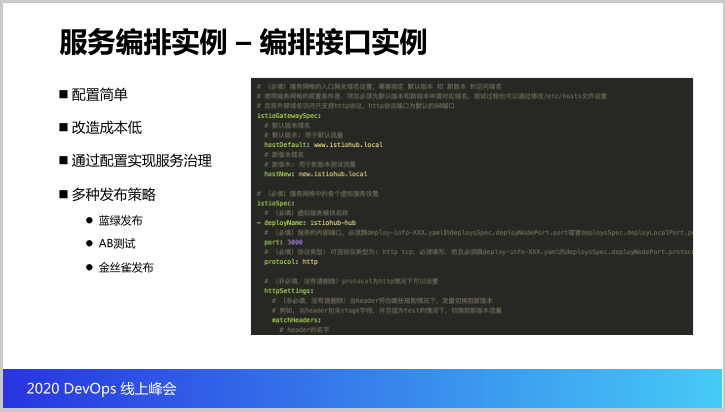
第三个就是服务编排,说白了就是应用如何对外提供服务,而且内部的服务又是怎么做治理的,以及它的应用我们能不能支持更多的发布策略呢?例如一些蓝绿发布,金丝雀发布,能不能通过这个服务编排做支持?这个就是我们提供的全编排的能力的实践。
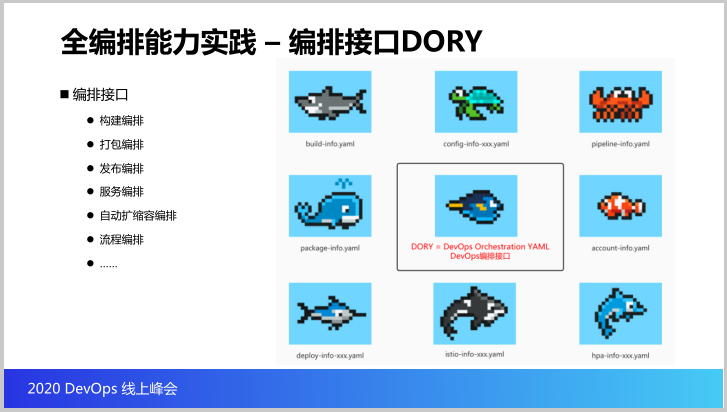
既然谈到编排,如何做编排?我们做一些叫做DORY的编排接口,DORY是一个YAML的接口,就是流程、资源和服务是怎么在云原生环境里面运行的,这些编排接口包括构建编排,模块怎么做构建,代码怎么做构建的,以及打包出来的构建出来的制品怎么打包成容器镜像,以及怎么发布到云原生环境。
服务编排怎么样,当这些应用资源受到限制,流量上来,需要做一个规则也可以做编排,甚至包括刚才说的流程可以做编排,这个就是咱们的编排接口DORY。
那再思考一个问题,为什么要设计这个编排?其实最主要的目的就是两个字:简化。
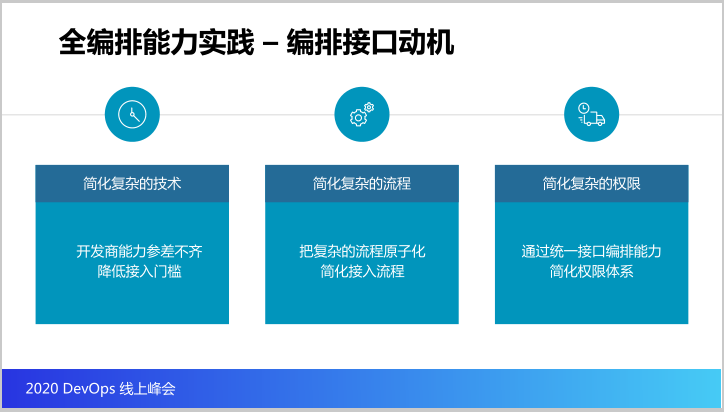
第一我们要简化复杂的技术,因为我们都知道,开发商的能力都参差不齐,你要把开发商能讲清楚云原生是怎么回事,云原生里边的所有的技术细节这个太难了,所以为了降低接入的门槛,所以我们要通过编排接口,把很多复杂的技术屏蔽掉,通过这个编排接口。
第二简化复杂的流程,我们要把这些流程里边的步骤变成一个一个的原子,开发商可以很灵活可以挑选哪些原子,哪些步骤是他想要的去实现他的CI/CD的过程。
最后是简化复杂的权限。思考一个问题,因为现在的CI/CD的流水线,其实所有的开发商都是共用一个Jenkins,如果我们要把Jenkins的Pipeline配置权限交给开发商,那会出现什么问题?可能会出现开发商A可以看到开发商B构建过程的信息,这样不合适。
再思考一个问题,因为所有的开发商的应用部署在同一个K8S环境里面,如果让开发商能够直接在他们的名字空间里面部署这个应用,那意味着A开发商可能可以调用B开发商的共享存储里面的数据,这样很显然也是不合适的。
所以就是通过编排接口统一了接口之后简化了权限的体系,这样开发商就不会再接触到这么复杂的Jenkins Pipeline的配置,K8S的配置,不会接触到,目标非常简单,就是为了简化所有的事,让接口变得更简单,让门槛降到最低。
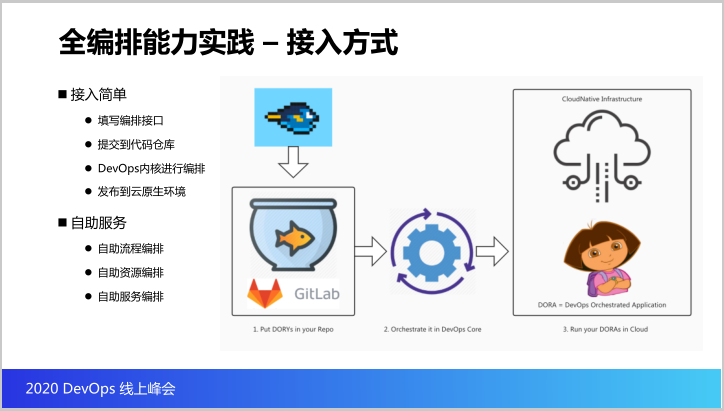
既然讲到编排,怎么做接入?怎么简单法?开发商要做的非常简单,第一他们把写好这个编排接口,把编排接口提交到代码仓库,我们就会触发流水线。那么DevOps编排的内核就会利用这些编排接口进行编排,并且把他们的应用发布到云原生的环境。
那么具备了这么简单的接入能力之后,开发商有很多自助服务能力,包括流程、资源和服务都可以通过这样的编排接口实时做调整,无须DevOps运维小组再做太多的维护和支持的工作。
三、编排
接下来我们讨论一下编排,什么是编排。第一个就是咱们的流程编排,现在看一个流程的实例,有点长,因为咱们的流水线的确是覆盖了DevOps以及CI/CD的方方面面,我们来看一下这个流程。
首先是流水线会从Gitlab拉取代码,形成编排和文件,接着就是我们可以做构建,而且可以看到每个项目有模块,而且每个模块之间本身有依赖,可以对构建的过程分阶段,做完这个构建之后我们就会做代码扫描,把制品进行容器镜像打包,并且把容器镜像进行镜像扫描。
同时如果有一些模块是属于要发布到传统架构里面的,我们会打包成踏包,然后做数据库的样例,之后发布到K8S,更新服务网格,检查K8S部署的情况,最后做API测试和数据库的回滚,测试数据,输出数据报告。
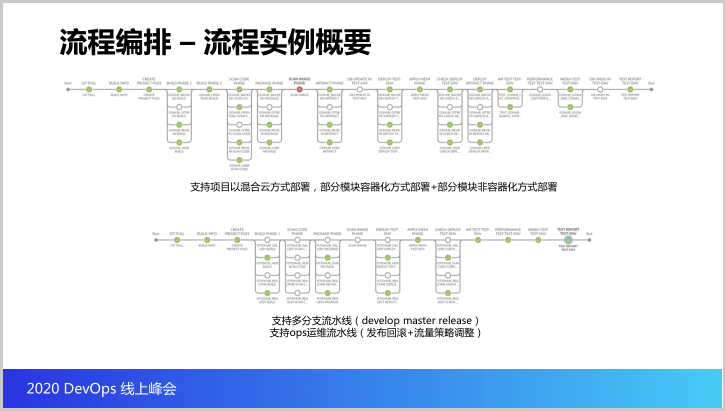
整个过程是比较完整的流水线,我们可以看看,首先可以支持到项目很灵活的进行定制模块,灵活定义各个环节里面的细节,并且可以设置各个环节的开关,而且我们刚才也提到,其实我们是支持项目里边某些模块部署到容器里面,某些模块是部署到非容器的物理机、虚拟机里边。
并且就是说咱们的流程其实不单单每个项目给它开放一条流水线,我们会开放多条流水线去对应不同的分支,因为每个分支可能会发布到目标的环境不一样,而且我们支持一些运维的流水线,包括一些发布的回滚,流量策略的调整等等。

刚才看到我们流水线真的非常非常复杂,那其实我们流水线里边最核心的只有三个环节,就是构建、打包和发布,基本上贯通这三个环节,就表明我们的Pipeline已经通了,是可以实现从源代码到发布最基础的过程了。
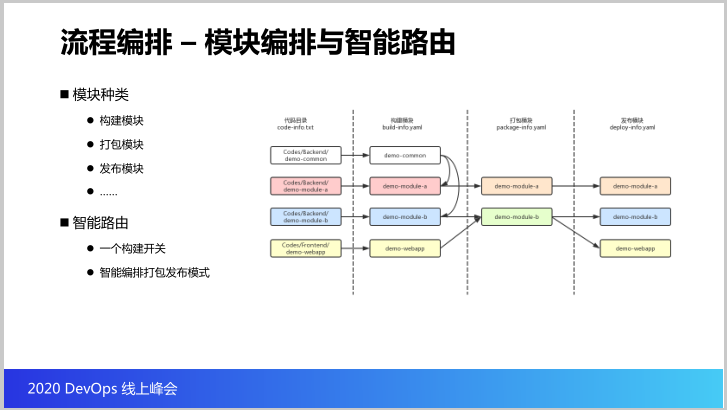
先看看流程编排这一块,这里分四块,第一可以想象源代码的目录,我们可以把每个模块的代码放在单独的目录里边,然后接着每个目录里边我们就会再针对这个目录进行构建,就会形成构建的模块。
我们可以看到构建的模块里面也有依赖关系,就像模块A和模块B可能都需要Common这个模块作为依赖,当我们构建这个模块之后的制品怎么打包成容器镜像?像模块A的制品可以打包成一个模块,然后我们也可以支持这个模块B和模块APP这两个模块可以打包成一个镜像,这是打包的模块,最后打包的镜像最重要运行在云原生环境里边。
那么就是说在云原生的环境里面这个镜像会发布成一个depontment(音),我们可以通过构建的开关就可以决定后面哪些模块可以打包,哪些做发布,这是非常智能的路由开关,只要设置好就可以决定后面所有的路径。
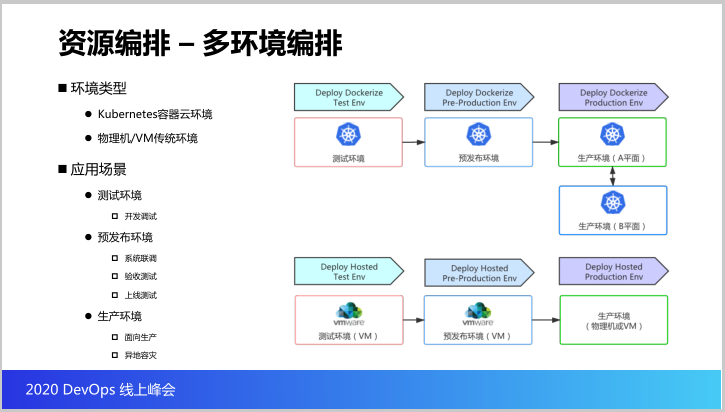
回到异构云的环境,资源编排是支持两类环境,是K8S容器云环境和物理机、虚拟机传统环境。应用场景有三类,测试环境用来给开发人员做开发调试的,预发布环境用来给测试人员做系统联调、验收测试,上线测试,最后生产环境是面向生产。现在K8S容器云是做了AD平面。
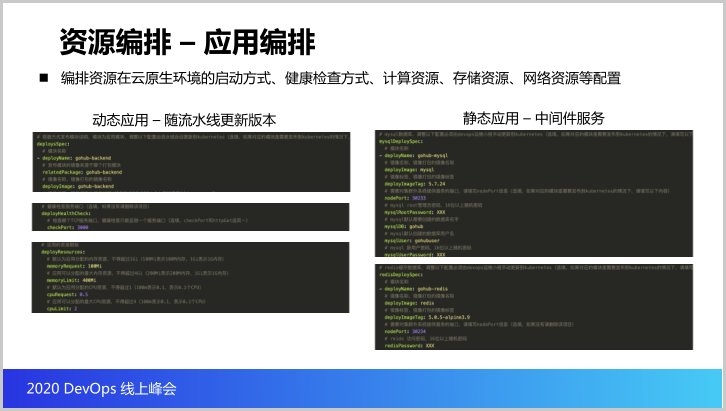
接下来就是咱们的应用编排就是应用是怎么通过编排能力部署到K8S环境里面。其实这个目标就是说我们通过应用编排,把应用在云原生环境里面的启动方式、健康检查方式、计算资源、存储资源、网络资源等配置可以通过编排编排到K8S里面。
我们可以思考项目有两类,第一类就是动态的应用,其实说白了就是开发商开发的代码,开发的代码通过CI/CD流水线随着CI/CD流水线更新版本到K8S容器云里边,第二类应用就是静态应用,就是像中间件。这两类应用其实其实都可以通过编排接口编排到K8S容器云里边去。
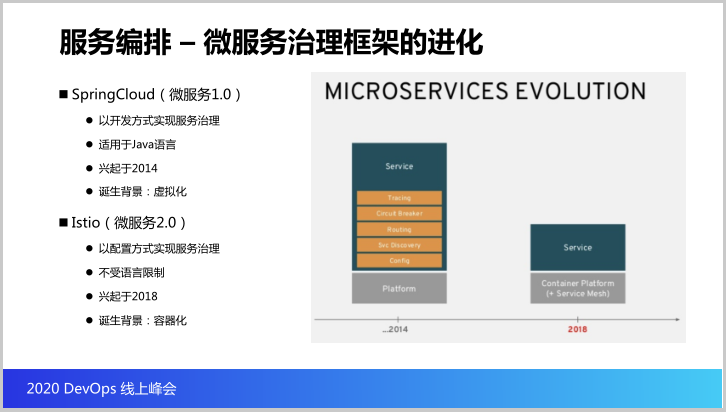
下来探讨一下关于微服务治理框架的进化。先来看看所谓的微服务1.0,这里边有很多开发框架为代表,例如spring Cloub是以开发的方式实现服务治理,如果要使用Spring Cloud需要投入大量的人力对微服务做改造,并且整合Spring Cloud的这些组件,并且适用的是Jira的语言,对团队的开发挺高的。
团队的开发人员必须非常熟悉Spring Cloud的技术框架,它的兴起是2014年,诞生的背景是虚拟化,因为虚拟化的情况是我们需要通过很多的框架来实现各种服务发现和负载均衡,那么这个就是微服务1.0的现状。
那么到了云原生之后,就开始思考微服务2.0是什么,这里就是服务网格,像Istio,它有什么特点?它以配置的方式来实现服务治理,而且它不受语言的限制,它是兴起于2018年,诞生的背景是容器化也就是云原生。
我们思考一个问题K8S本身就已经支持了服务发现和负载均衡,那么就是刚才提到的服务网格的这些优点应该说Spring Cloud所有的缺点刚好就是服务网格的优点,所以我们在云原生的年代,Spring Cloud还是是不是一个最佳选择?可能这个大家可以思考一下。
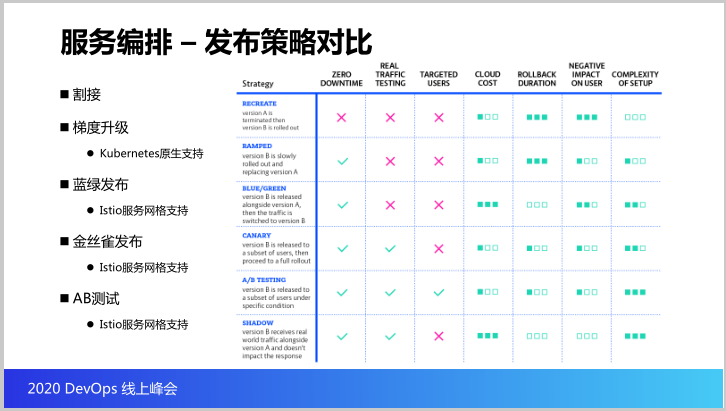
接下来看看一个服务发布策略对比,这个图就是各类发布策略,割接,我们最传统听得最多的是这个,这个是意思,就是下线旧版本再上线新版本,传统的这个物理机、虚拟机的升级方式基本上使用这种。
第二个Ramped,梯度升级,就是我先上线新版本,等新版本准备好了我再下线旧版本。
第三个蓝绿发布,新旧版本同时存在,旧版本用于生产流量,新版本是给测试流量,由测试人员测,测完可以再把生产流量指向新版本,完成蓝绿切换。
接下来是金丝雀发布,就是新旧版本同时存在,但是我会随时选择部分的用户体验新版本,我可以逐步调大测试使用的流量,AB测试和金丝雀发布最大的区别就是可以定向到某些特定特征的用户才使用到新版本。
那么这个表格就是从我们的服务有没有中断,能不能指向目标用户做测试,以及付出云的代价,和回滚的延迟,以及消极的影响甚至是实现的难易度做的一个比较,这个表格大家可以作为一个参考。
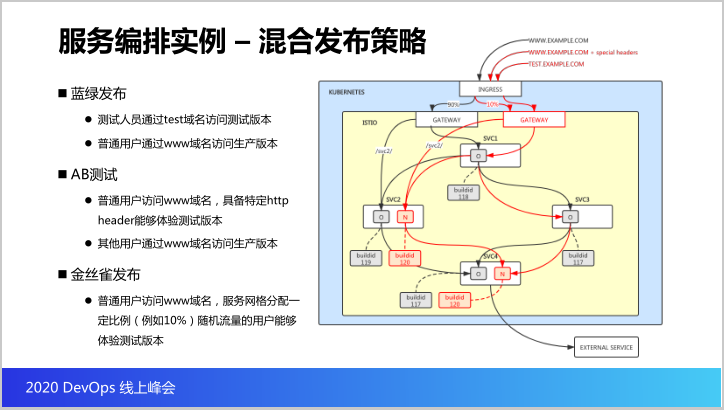
再下来就是我们使用这个Istio怎么实现混合的发布策略,这是一个样例,也是我们现在所实现的。这里面有四个服务,其中服务二和服务三会调用服务一,而服务四会调用服务三和服务二,是一个菱形的状态。并且这次升级服务二和服务四,红色就是表示新版本的流量,我们来看看怎么实现混合的发布策略。
第一个我们支持蓝绿发布测试人员可以通过Task域名访问到的就是测试版本,而普通用户访问www域名访问的就是生产版本,就是黑的这些线。接着我们支持AB测试,普通的用户访问www域名当它的HTTP头具备某些特征的时候我们就让他体验到新的版本。
而其他的用户www域名进来他体验的还是生产的旧版本,而金丝雀发布我们可以控制同样是访问www域名,有一部分的用户可以体验到新的这个版本,这个就是支持的混合发布策略,也就是Istio实现的智能路由。
这是编排接口的实例,可以看到配置非常简单,开发商不需要投入太大的改造的成本,而且我们的服务治理是通过配置来实现的。最下面的这些就是服务编排的实例,可以看看左右,同样都是浏览器,如果访问www的域名,访问的是生产的版本,可以看到这里边的数字对应的是旧的BOID,假如访问新的域名,访问的就是新的ID,就是测试版本。
假如同样是访问www的域名,如果使用这个浏览器访问到生产版本,如果我使用Common的浏览器,因为带了这个(3:03:22英),访问的就是这个新的版本。同样我们金丝雀的发布同样访问的都是www的域名,有部分的用户访问的是旧版本,小部分的用户能够体验到新版本。
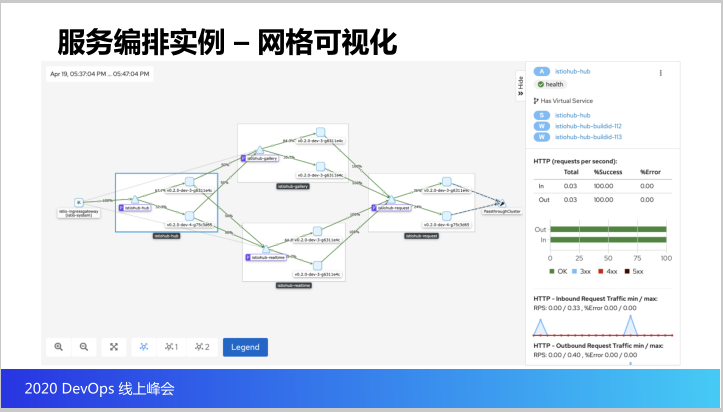
最后这个就是Istio服务网格所实现的服务可视化,可以在里边看到每一个模块有两个不同的版本,以及每个版本走了多少的流量,以及它的流量的监测的情况。
