@gaoxiaoyunwei2017
2018-01-15T03:54:47.000000Z
字数 3362
阅读 1239
从大象到猎豹自动化运维和性能优化实践
白凡

讲师 | 姜鑫韡
编辑 | 白凡
今天我分享的题目是从大象到猎豹,自动化运维和性能优化实践。对于运维来说运维要转型为自动化运维,在故障的排障上面提升我们自己处理故障的能级。

演讲的内容一共分为五张:
- 是大象到猎豹,为什么这样做和痛点
- 第一步应该做什么,运维生态的建立
- 实践分享
- 应用性能分析
- 拥抱新技术

1. 痛点
我们其实背负了很多历史包袱,真的是像大象一样,但是跑不起来,原因是因为历史核心系统架构有可能还是五到十年之前,在扩容方面比较吃力。如果要去扩容一个系统的话,有可能我要进行横向APP的扩容,但是APP扩容之后迟早有一个瓶颈,就是数据库的连结。对于比较老的应用来说整体架构很难进行拆表。
在这样的情况下,我们现在推动了我们这边微服务的系统上线以及老系统的应用整改。老架构核心系统,以及现在将近营运维400多个系统每周的发布和变更,再加上业务冲刺保障,这些东西都是我们整个系统生命周期当中,整个运维和IT陪伴最长的过程。所以我们这个痛点就是我们为什么要去做自动化运维转型的一件事情。

从传统运维到自动化运维,我们现在需要三点:
- 消除后台化的操作,操作全都必须变成前台化,由前台化的业务提供给运维人员操作使用,从基础的重启到日志清理,以及一些服务器连接数,然后是一些日志的抓取,全部都由前台是完成。
- 快速部署。 2015年开始关注Docker,2015年底和2016年初的时候春晚微信系统直接上行了Docker技术。
- 指标可视化这一点是非常重要的,因为在推行自动化运维的过程当中发现了很大的一点:我们做的很多事情都不知道。不知道的原因是什么?因为没有一个具体可视化的看板。我们后来在今年又列了一个项目,做的是两件事情:

2. 运维生态建立
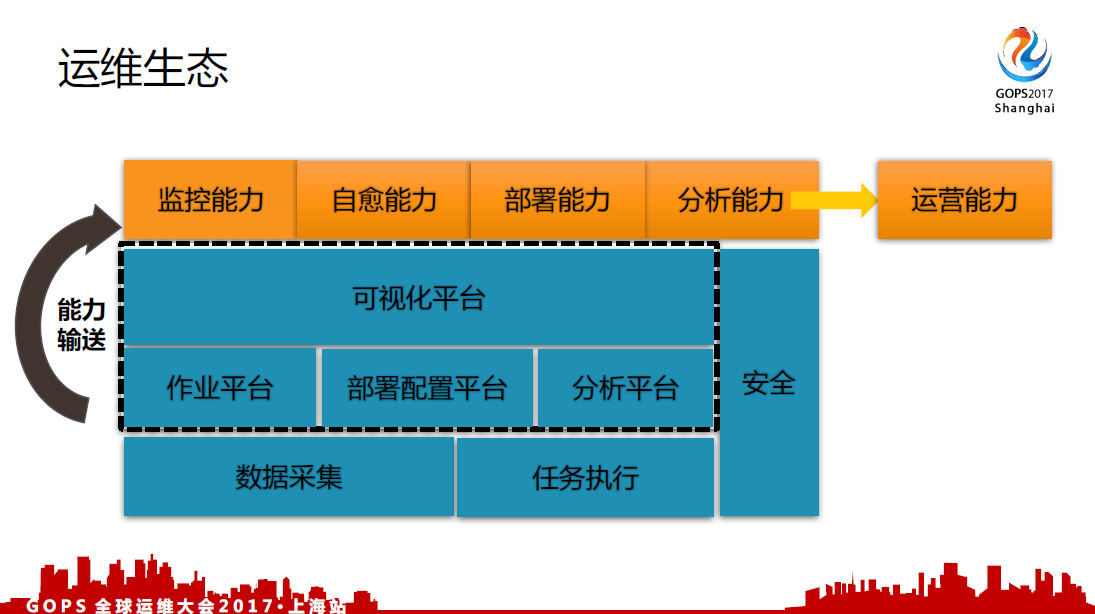
- 给IT人员提供技术看板
业务人员有相应的业务看板,提供关于业务的成交量、入单数等等一些指标。
在做这件事情之前领导已经做了一个规划,到后来越想这件事情是持续往下做的基础。为什么要这样做?在做这件事情的前提是会发现如果你要去做运维的监控,如果你要去做运维任务的执行,但是你会发现在企业里边数据源非常多,对IT来说讲的是数据源,有可能采集端以及监控的软件提供出来的服务。
这些数据是否真的都有用,其实一直是打问号的。所以我们在做自动化运维的过程当中,首先做的是CMDB,使用了我们自己研发的东西抓取服务器上的IP,包括实例的端口,服务器上面的信息。以数据采集作为基础,在这个基础之上通过搭建作业平台,作业平台指的就是自动运维化平台和部署配置平台,就是docker2.0系统。再往上就是可视化的平台,来提供对外的服务。
运维必须讲安全,保护生产的稳定运行才是运维最基础的一个底线。以数据采集作为能力输出,对外提供了监控能力服务,部署能力以及分析能力,进而将一些数据整合,后续提供一些运营能力。但是现在运营能力目前还是比较薄弱的,还没有完全做好。这一张讲的是人的一些语言转化为计算机的操作指令,通过调用我们目前已经打的基础平台完成后端资源的调控,以及数据自动分析,完成既定运维SOP。
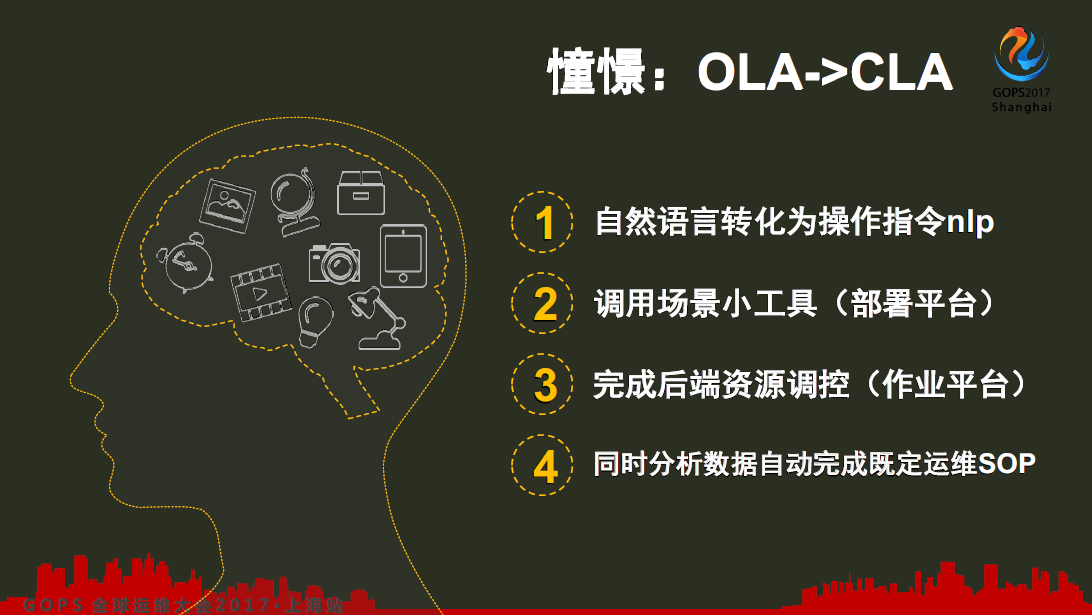
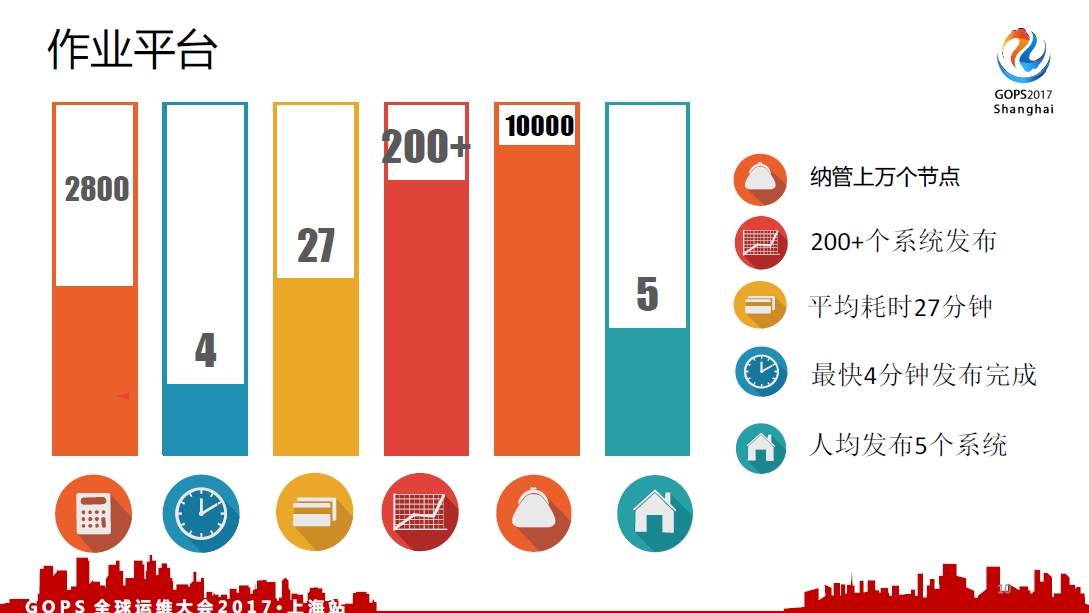
大家可以看一下关于OLA以及CLA相关的文章,还是比较有意义的,因为这些东西实际上是最需要达成的目标。我们的作业平台纳管了上万个节点,平台上提供特定脚本的执行,可供自定义。这个平台在发布日大概有几十到上百个系统,最多的时候有200个系统同时在一个晚上发布了。我们的平均耗时大概是27分钟,最快的一个系统有可能只需要几分钟完成一个发布,人均发布5个系统,这就是现在自动运维化平台提供的对外能力。
部署平台为什么要说是标准化的部署平台?是因为我们通过docker纳入了配置管理,我们统一了现在主机上的配置,为的是很多之前故障发生的时候就发现主机上面的配置被人家改了,跟别的机器不一样。现在这些配置统一部署平台管理。

3. 实践分享
在前段时间保险推广的过程当中,我们在主机分发下来之后,整个平台在5分钟之内对外容积数扩容了10倍,用户首次打开的页面速度提高了大概15倍。我们在自动化运维以及部署平台之外我们还比较关注应用性能的分析。这里体现的是前端资源的压缩,在这个系统上面缩小了大概1/5,为了用户在首次打开页面,没有缓存的情况下第一次加载的时候缩小为原来的1/5。

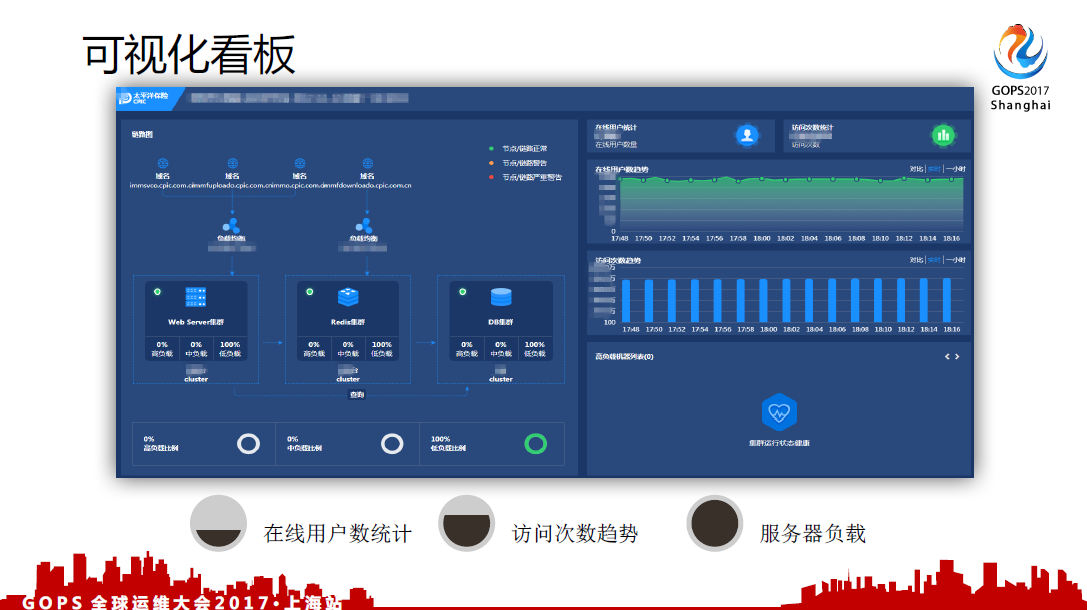
可视化看板
可视化看板数据源比较多,要从技术平台,再加上APM分析的平台抽取一些数据,来展现在我的平台上。这张看板是偏业务方面的看板,数据是从后端的数据源里边取过来,展现给业务源看。关于业务比较关心的在线业务数统计,访问次数统计以及服务器负载的情况都可以在看板上面展现。

4. 应用性能分析
应用性能分析现在规整为四个阶段:
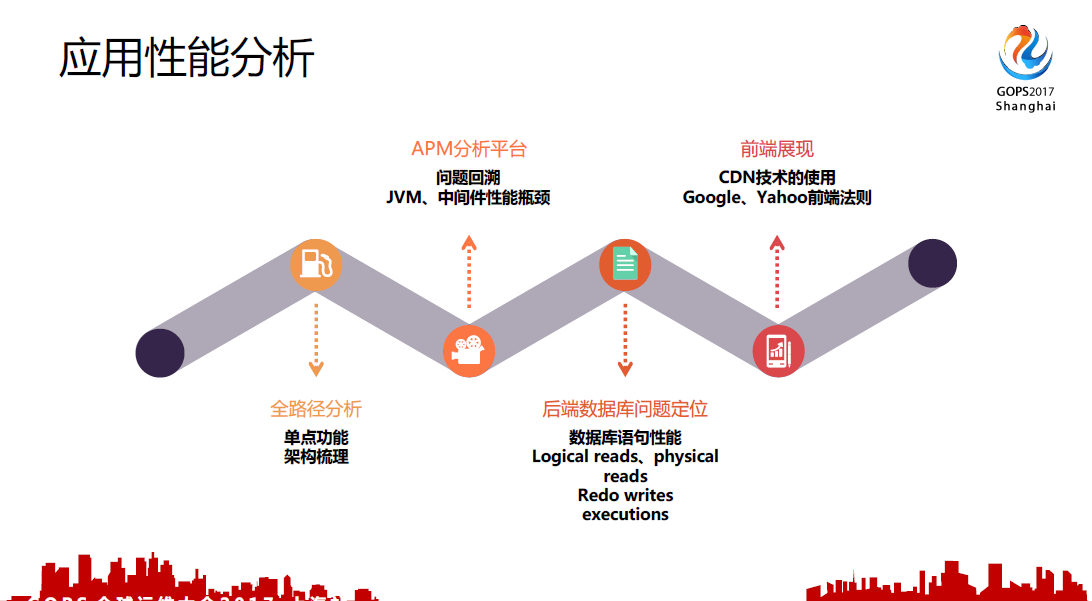
- 首先,全路径分析,主要是了解这个系统的架构和拓扑,为了梳理架构当中存在的单点功能以及网络策略相关的策略
- 第二,通过后端的APP的监控,目前我们是通过APM进行程序的监控,主要是进行问题的回溯以及故障的定位
- 第三,后端数据库性能的分析,我们对数据库,还有CPU性能展现进行分析
- 第四,前端法则
为什么会把前端展现放在最后一端?我们在分析一个故障的过程当中我们首先会看前面三段的问题,最后一段实际上是辅助应用,使得性能更加迅速,前端更加轻,下载更加快。最后一端是整个问题回溯好了之后对前端进行总结,下一个版本继续发上去,对前端做一些混淆,安全的防范以及图片的压缩。
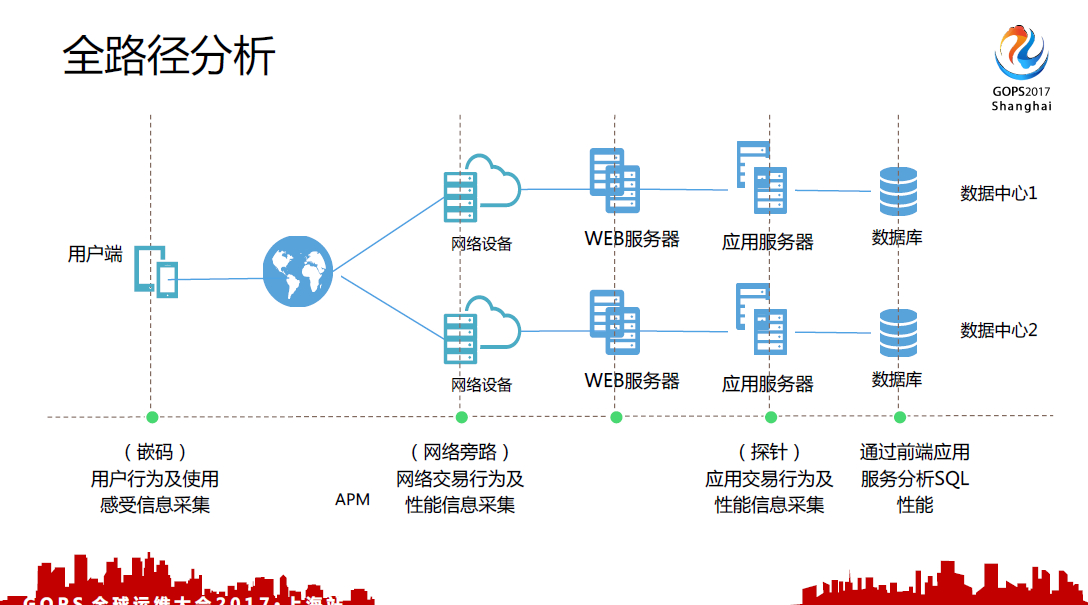
4.1 全路径分析
在应用性能分析过程当中,为什么要引入这些软件?以前我们发现处理故障的过程当中我们会要求各个团队,大家一起集中办公,但是大家看到的数据都不是同一份,中间有可能看到中间件层面的参数,网络是看到网络层面的参数,数据库是看到数据库层面的参数。大家都联系不起来,处理故障的时间非常长,很难定位,大家都有各自的说法。所以我们现在就是引入这样的APM和QM这个软件做这个事情。
数据中心的应用,排查问题大家都觉得比较复杂,对整个数据中心网络电路其实不了解。在没有使用APM和QM的情况下我们很难发觉用户端的感受,很多人报过来的故障我们这边根本没有感觉到,但是那个时候故障已经形成了。我们在这边需要进行全路径的分析。
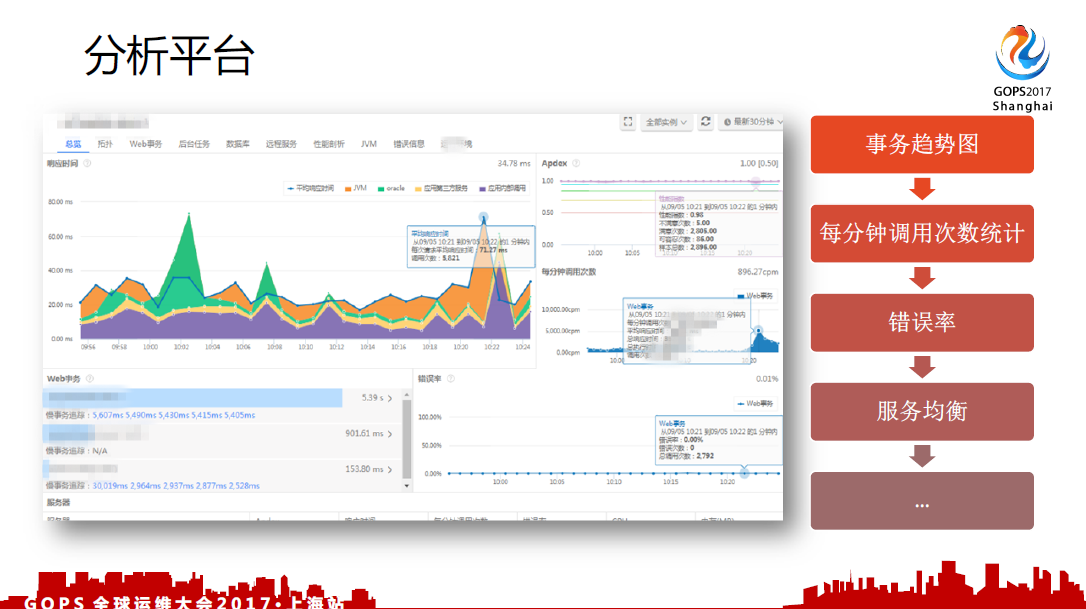
4.2 apm平台
我们的APM平台,可以实时查看用户请求的量以及应用内部的调用都有自己展现的方式,很明显的进行区分。我们通过这些事物的趋势图,每分钟调用的次数判断这个时候的业务量是否有增长,以及事物的处理效率是否是异常的。
在使用APM类软件的时候很多问题可以一步定位,但是仍有很多问题是定位不了的。其实很多关于业界的分析在学术上面分析,但是实际上没有一个算法真正能够定位最终问题的原因,因为我们在故障处理问题中发现崩溃,我们要求可以定位到具体的代码段,代码行出了问题,但是现在只能看一个趋势,具体哪个点造成这个趋势,目前还很难进行定位。所以APM只是回溯问题,以及帮助运维,开发和共同解决问题的工具。

4.3 数据库性能分析平台
这是我们数据库端的分析软件,它可以进行数据库的全表扫描,以及性能展现。我们通过这个就可以抓取应用当中的低效SQL,最后提交相关的研发,进行一些优化。

4.4 前端优化方案
最后要讲一下前端优化方案。现在减少http请求次数,有些还是使用HTP1.0,一个资源加载完了之后再进行下载,现在2.0是几个资源一起加载。这是性能上很大的提升。我们还在运维过程中发现很多系统,这也是有历史原因的,很多系统喜欢做301或者301跳转,但是是很耗性能的,对服务器的性能是有一定影响的,对开发来说有可能就是某一个不需要的,不愿意利马修复,或者之前出了问题之后这次配了301或者之后后面就没有再管这件事情,会对前端的性能造成很大的影响。
页面延迟加载和提前加载可以放在一起说,主要是现在网页展现方式,GOOGLE和雅虎前端的法则来进行前端的优化。
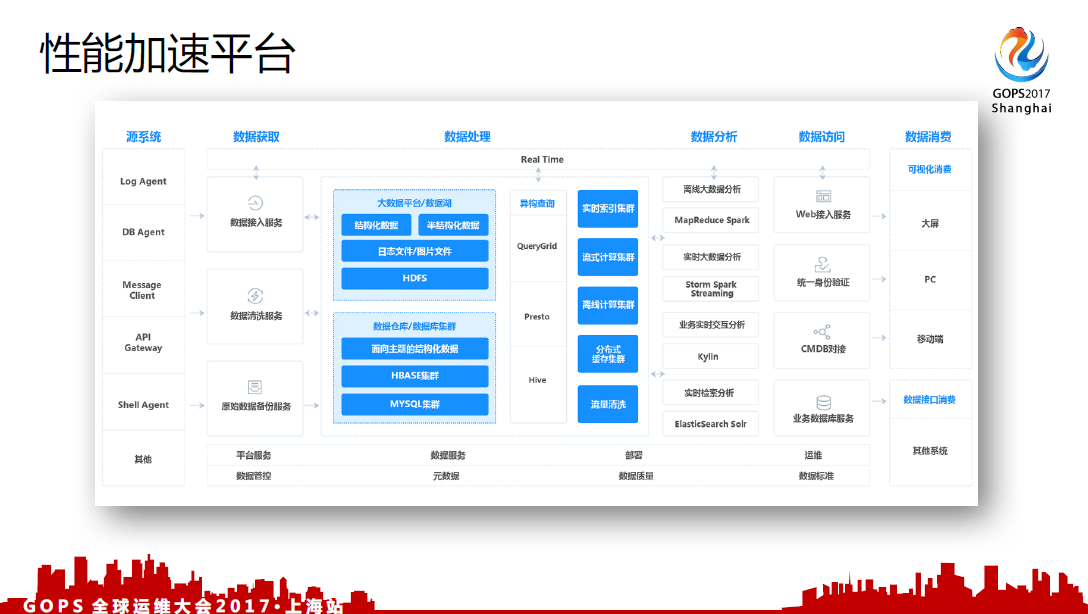
4.5 性能的加速平台
这也是我们这边着力做的平台,定位整个程序,从前端到后端整个性能的分析报告,类似于对整个系统进行一个健康检查,来判断这个系统现在有多少容量上的瓶颈点。关于性能加速这一块目前在代码开发阶段,现在有一些自己的成效,但是目前还不是很完善。

5. 新技术展望
最后关于新技术的研究。我们这边还有很多问题处理以及简单故障的解决,现在也通过相关的AI Ops算法和图片的识别,这些已经可以达到一定成效去解决工单以及运维人员手上的告警处理。

