@gaoxiaoyunwei2017
2019-08-27T02:06:41.000000Z
字数 7403
阅读 1487
技术运营标准揭秘
白凡
编辑:白凡
作者:徐奇琛
大家下午好非常荣幸又来到了DevOps国际峰会,大梁刚刚和大家讲述了标准的揭秘的上半部分,接下来由我给大家介绍下半部分,其实和我的以往分享有些区别,今天是标准的话题,也是为了除了标准可能相对乏味一点,为了调整大家的兴趣点也会穿插运维时代的变迁以及如何思考这个标准,而不是完全把标准解释一遍,最后大家也知道标准还是要最终的落地和运用,我也会结合自己团队的一些案例和大家讲述出河比较务实的运用这些标准。
简单自我介绍一下,我是一个二娃的奶爸我来自于京东,也是作为技术服务团队的负责人在相应的社区还是比较活跃的,就是经常和专家联盟写一些书做一些相应技术规划框架,曾经管理一些领域,差不多运维算上实习,差不多管了15年了,管一些效率团队,平台化团队,以及管了大半年的业务平台团队,所以也都是更多的换位思考,这里特地说一下15,不是说作为15年特别长,也是为了后面做相应的铺垫,曾经负责过一些项目,包括腾讯投资的一些项目,大家可以了解一下。

简单来说就是分三个章节讲,首先是我眼运维时代的演进和渐变,还有就是相应的解读和思考,最后就是结合案例和简单的总结。

1. 我眼中运维的演进历程
原来是想和大家战时相对比较灰暗的,因为只有15年前我自己很清楚踏出学校,到一家外企做运维,当时很少说运维这个角色,更多成为是NA,SA,DBA,我们必须学各种盗版软件和工具,晚上频繁发布,凌晨看个电影还要背一个笔记本,发展相对比较窄,福利很差,包括当时大家比较聚焦的是一些360的建设,所以本来想有一个互动,还是更多想和大家聊一下这个事,刚才主持人提醒我,大梁占的时间比较多,互动环节取消了。

这里讲一下,运维很快在15年内高速发展的时代,还是传统时代的莅临,更多的时代比较讲究流程化,大量的系统都是ACID系统,很快2007年左右也是进入了互联网时代,马上用运维这个角色得到了长足的发展,这个时代特点是比较关注质量用户,我们追求最终的应用,技术运营也是很快沉淀下来,并且发扬光大,很快过了两年又是一个平台化时代,因为也应该记得有一段时间运维开发非常火,那个时候更多是会比较聚焦于运维的效率提升,差不多2010年左右跨入了云机损时代,去IOE,那个时候更多是开源,价值升级,云时代的一些定义。
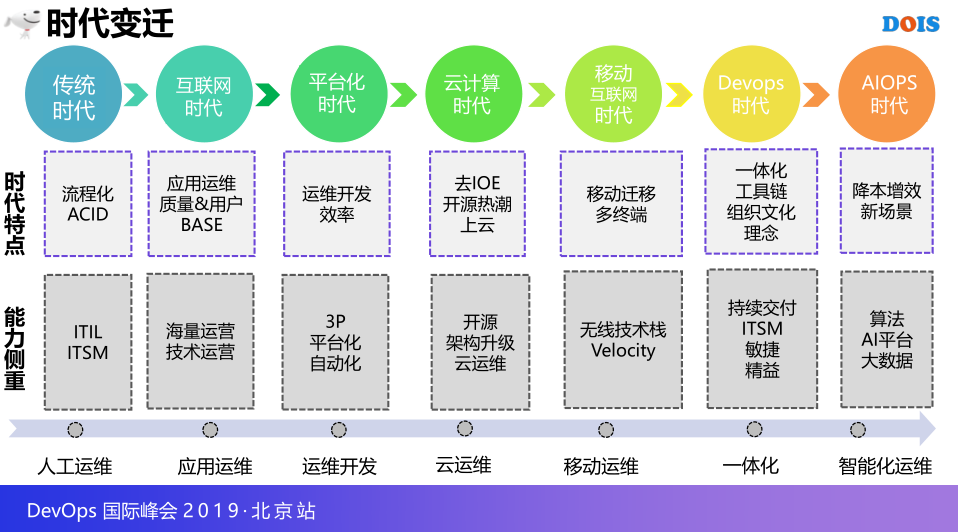
2014年到了移动互联网时代,快速的互联网开始了移动迁移的过程,终端的接口,也是相应的特点,马上也是一种无限纠正的适配,还是DevOps时代和AIOPS时代,以及制成AIOPS时代的运营能力的框架,ITSM,敏捷,精益,更多需要一些算法,还有一些降本增效,包括一些平台化的建设,下面是运维发展的过程,如果真的说一个运维的发展的话,如果这些点可以采到的话,公司应该差不多翻5倍。
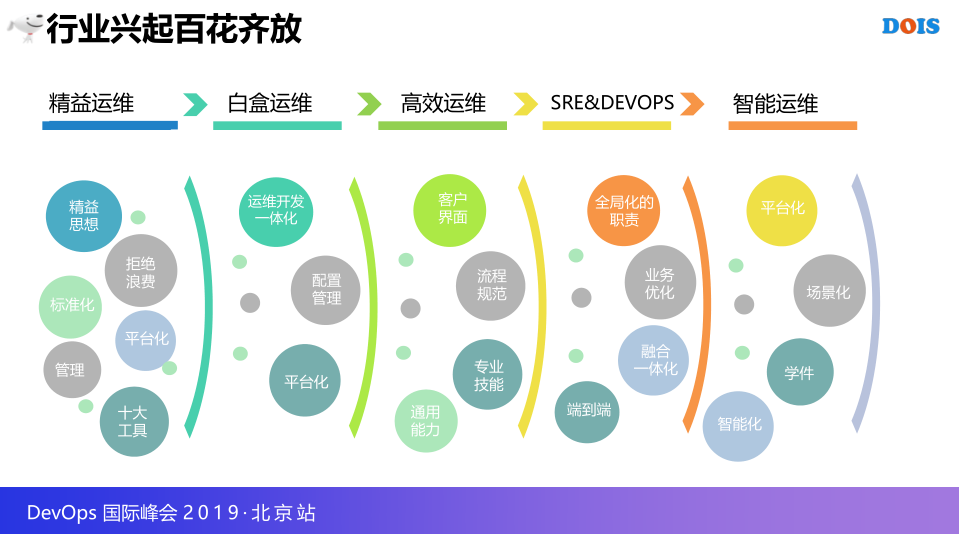
本来这一页向致敬一下大师,特别清楚,差不多在2016-2015年期间,精益运维,又一届的网红,老王,白盒运维,高效运维,包括SRE&DEVOPS,是行业的典型,所以精益运维是相应拒绝浪费,相应的管理工具,更多的还是一些平台化的管理,高效运维是和大家构建了用户界面,专业技能发展更快,通用能力的建设,再到SRE&DevOps,就是端到端的智能,当时提出智能化的理念相当少,也是看到了未来的下一站可能就是智能应用。
2. 标准撰写的思考和解读
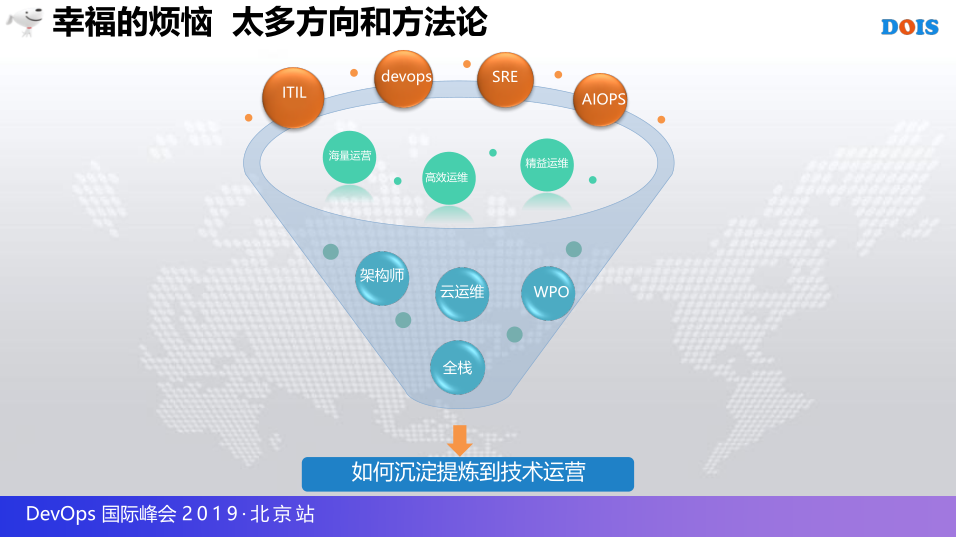
说了这么多的方向,方法论,其实可能迎来一些比较系统的繁杂,就是怎么样提炼这些方法论和关键的横向,因为其实我们说的是技术运营这一块的发展,其实更多希望从一些运维体系和运维论值得沉淀的一些技术运营层面的调度,所以带着这个问题来到第二章,撰写标准的思考,大梁也是花了很多片子说标准的故事和过程,相关的就不再展开和赘述。

简单说一下我的思考,一个就是行业其实发展非常快,我们如何作为运维团队的规划者,或者作为运维团队的管理者,如何把握好和新团队的团体核心发展方向,我发现其实虽然很多方向是一致的,但是理论也是有很多,但是没有更进一步的细化和量化如何做到真正的引导,再到技术运营板块特别没有一些统一类型,把BAP层面也没有统一的运营,所以如何建立一些共识,所以大家也是带着这个问题,2016年的时候,觉得这些还是可以促成这些事,所以也是用了司马迁的一句话“集百家之长,成一家之言”这就纂写了我们核心的诉求。

这个照片还是有好多的网红,都认识的话,你也是有沉淀的,老王,根据大梁,萧老师,更多相应负责人。
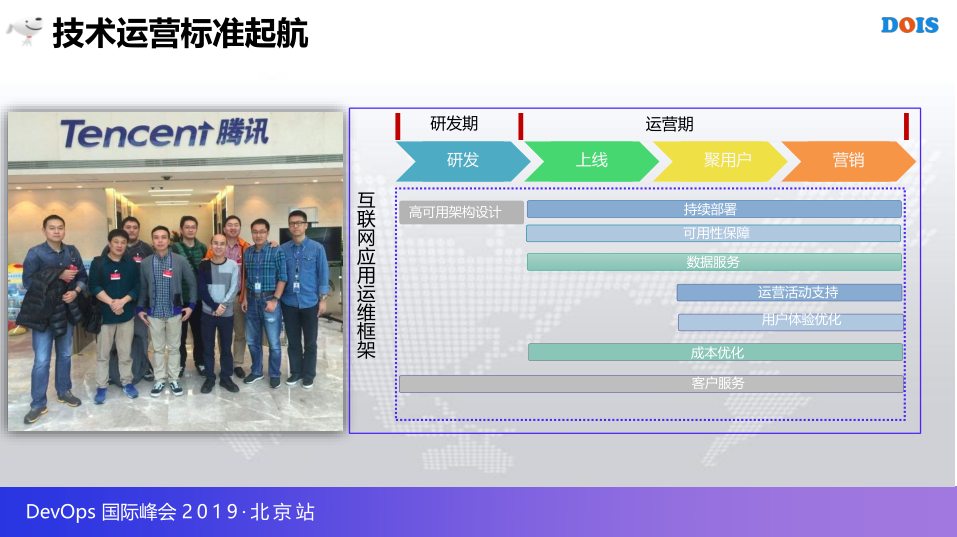
我们作2016年的双十二,齐聚腾讯,共同纂写当时叫做互联网应用运维框架起点是这样的,我们其实在三年前差不多考虑这件事的时候,觉得规划还是思考还是比较清楚的,整体的一些生命周期的覆盖,各个领域的细分,包括运维通用能力的涵盖,其实大家可以里面持续部署的问题,部署还可以翻出这个资料的话应该在这个上面有,老王还是很用心写的好东西,差不多六分之一内容都是老王在实际的部署,当时来看还是非常的不错,但是也是去年大家其实聊了一下,从现在的DevOps时代来看的话,有很多不成熟,或者需要去修改已经过时的点,所以也是进入了下一阶段的构思,也是一个新老观点的碰撞。
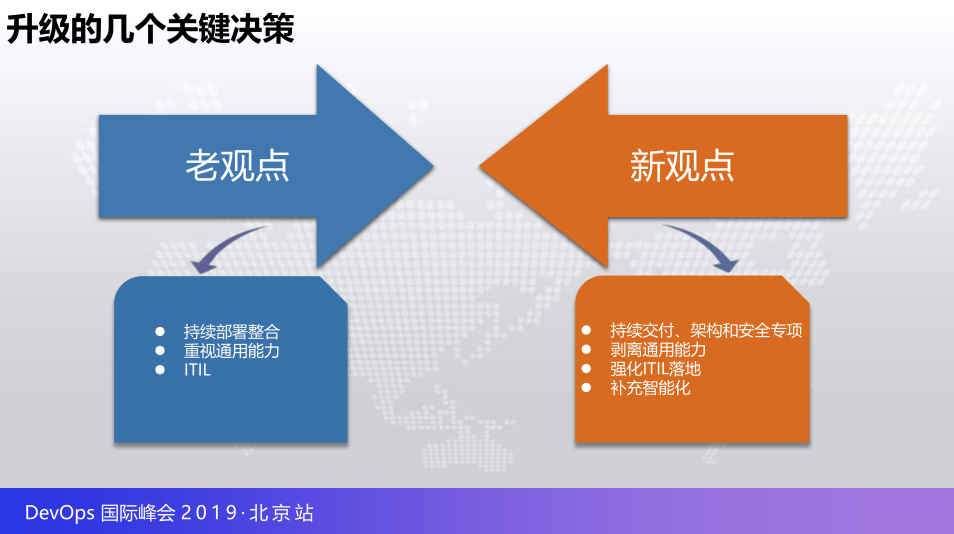
我们的原来实际部署做了一个整合,整个运营框架,现在来看的话整体的交付体系足够的大,还是应该在去年已经体系化实施第一个标准也提到我们的架构和安全也是足够的大,也是需要成立更加独立的专项,更从原来老观点比较重视的通用的建设,从现在来看的话,互联网时代也好,大家都是非常精确的换位思考能力都有,所以我们也是剥离了通用能力的一些要求,补充大量智能化的场景。
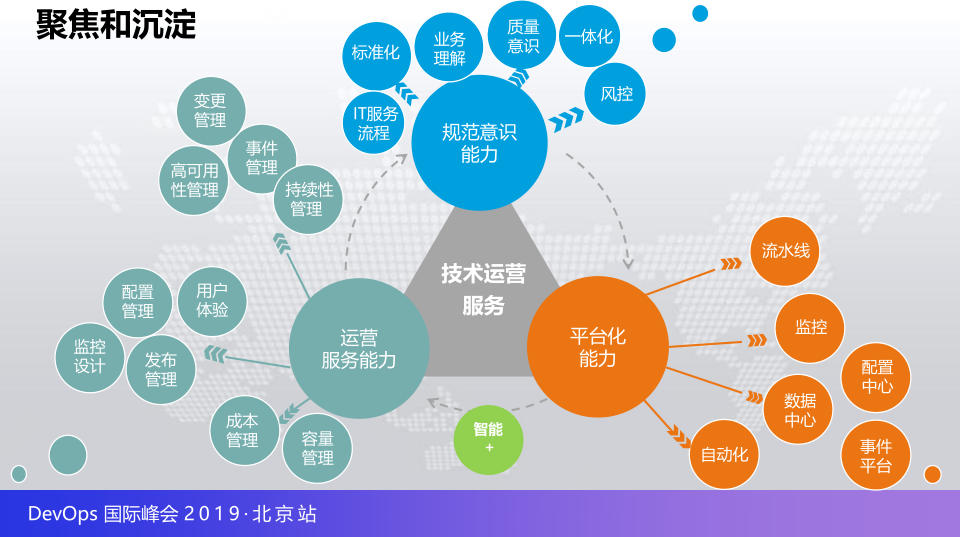
所以我们重新以技术运营目标梳理了技术的框架,这里围绕的是运营的服务能力以及规范意识能力包括平台化能力,包括成本管理,容量管理也是用户发布监控,再朝上的话,变更应用事件,这里基本涵盖了我们需要规范的点,业务的理解,质量的意识,一体化,平台化就是流水线,自动化,并且在不断的衍生过程中,我们的运营能力和平台化能力之间其实有更好的一些互补,在叠加出来更多的一些场频做智能化,也是有一个智能+的定义。
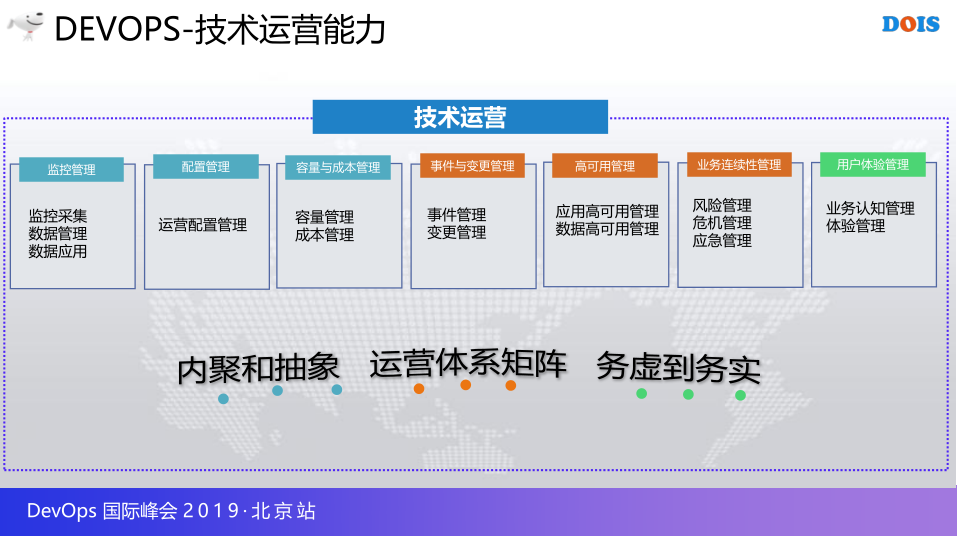
所以接下来是我们定义的新的框架和板块,其实大家应该介绍的监控管理,配置管理,容量与成本管理,一会儿和大家介绍的三块,业务连续性管理以及还有腾讯的监控也会给大家介绍用户体验管理,所以我们的思路还是从内聚和抽象入手,也要建立一种运营的体系的举证,因为除了这个框架之外还有大量的材料我们也有很多的评估方法,很多的内容都会提供出来,也会负责的细化。
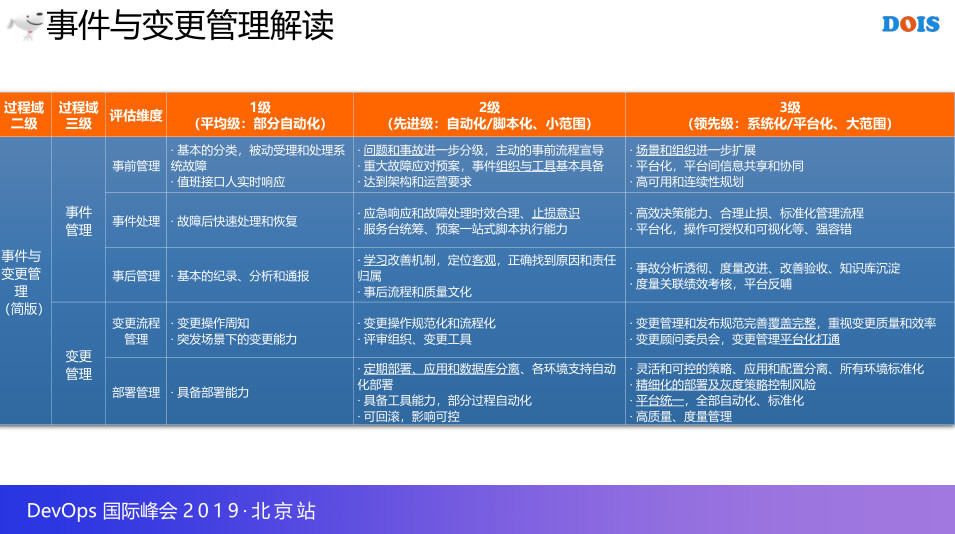
简单花一点时间和大家做一些解读,因为原来写的标准化内容还是特别的大,所以这是有一个简版,首先是事件和变更,其实两块都是在一些板块,所以把他做了相应的合并,我们是以一种生命周期的覆盖,事前,事中,事后定义,这里面也有很多的朋友在过程中问我什么是事件,其实有很多的定义,有的只是相对比较粗的理解为事故,所以说的事件广义的事件,包括事故,包括运维服务请求的事件,这个是一个统称,这里是相应的被动处理系统的故障,需要实时的响应,第二个不断的参与细化,有相应的一些事前的训导,不能所有的事情在事中的时候做,事前有大量的要做,你的组织工具,事前的工具,这些工具不单单是一个事件平台的工具,更多也会去说你的监控也要看,也要打造架构和运营的一些基本要求,靠三级的话场景和增值需要进一步的扩展,场景说明涵盖一些安全类,用户反馈类的,都有,组织也会有,不断的扩展,平台化就不用说了坚持建立更多的共享和协同。
事件处理简单就不念了,简单看一下,简单说一些要点,这里在第二级的时候还是强调一种处理的实效,也需要有一些止损的意识,大家回想一下我们有时候支持了好多业务的研发有几点系统化,做了第一件事情没有任何的处理,你的业务损失可能越来越大,这个质量意识也会不断的选段,包括统一的分发,接受分配,这些能力也要在脚本和工具里面也是有相应的要求,到三级需要更高的止损能力,你整体的架构是不应该是所有的案子都会需要人为处理,从事后的话应该有更多的学习的指出,需要有一种比较客观的运用能力,绝大多数出的一些事后的定位应该是比较客观的,你相应的一些事后的质量的要建立起来。
到三级是我们要求具备复杂事故的一些定位能力,有时候大家定位一些问题的时候会有准则,次则,都会建立相应的机制,所以我们三级也会有这些方式,所以你的知识库和联手都会在三级要求,我希望是和绩效建立相应的关系。
我们再说一下变更,变更相应的基本流程,做到相应的周知,周知以后需要相应的评估和材料至少是二级团队一些能力评估组织,虽然这里强调一个组成但是还是比较简单化的组织,相应的工具,整体三级要求一个更加完整的覆盖,比如开发周期里面覆盖,我印象当中特别深就是变更并不是一个生产和发布的问题,我遇到最大的问题改变我们在打捞工具,代理非常致命的东西,这个是没有谈变更管理的范畴,遭就一个非常大的故障,这个是全生命周期的覆盖,我们也会去提倡相应关注变更质量和变更效率的数据,也提到的变更委员会还是需要提过专项委员会做这个事,平台化就不说了,部署能力大家也说过了,为什么在交付这个会应用,在技术运营标准里面也会应用,背景就不说了,二级开始也要做到应用和数据库的分离,具备工具化的能力,部分自动化可以回滚。
三级我们希望可以做到应用和配置的问题,足够的管理方面的标准化,你随时可以抓住,建立团队的机制非常可控的前提下随时可以发布,平体层面的统一,精细化的部署策略,精细化能力是不一样的,他会基于设备,各式各样都应该去看,这个层面也是需要打造很高的质量,变更事件就解读完了,还是比较快的带大家了解一下。
所以大家可以看起来,下一个我和大家聊的是高可用的解读,高可用大家可以想到什么,高可用这个不是我写的,也是京东金融的同事写的,他的考量点,高可用的逻辑非常简单,应用的高可用和数据的高可用,应用的高可用是到这么难区分的,比如应用的弹性能力,柔性能力以及相应的运营维护管理,他的多种算法匹配一个更合理的分配才是一级能力,你的流量是可切换的,二级更多是一种治理和应用级的一些高可用的建设,整体的应用节点可以快速的横向,可以支持分批发布,三级简单来看就是叫做可以根据监控做到自动化,并且是多应用的,可以横向扩展,柔性这个词也是很好理解,技术的健壮性,可以理解过载保护。三级就是一句话,就是硬件故障不易产生业务终端,看上去好像很简单,但是真的想一下不容易做到,在运行和维护层面更多是一些信息层面的需求,可能还是有一种配置管理实施的管理。

我们看一下数据,数据其实简单说一下,这个更多还是不一定是研发过程中需要进行 管理,现在这个层面也可以很好的支持,我们缓存这一块的话,二级需要做到持久化的实施分布,三级可以做到这么多的切换,这个很多公司可以做到分布式的,平行的一些扩展,数据库可用系统,可能更多的就是从二级分离,一致性,桐城的多机房备份,数据库的变更也不需要影响相应的运营,所以这是高可用的简单的解读。
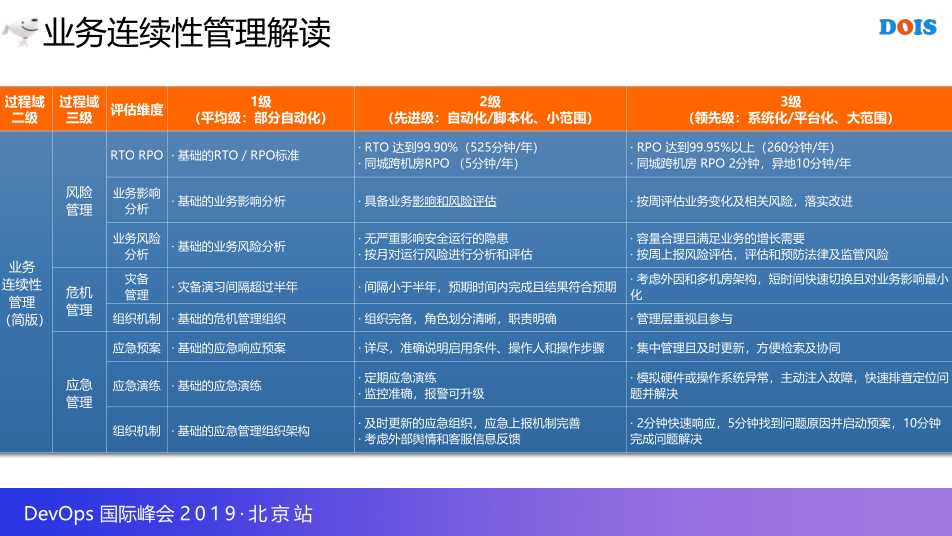
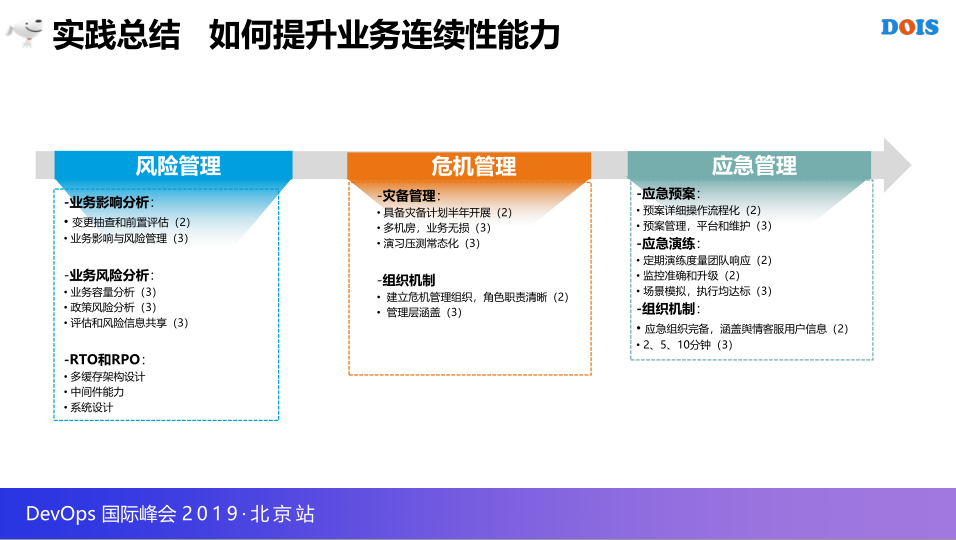
业务连续性管理,首先是风险危机的区分,RTO和RPO相应的标准,RTO可能在五分钟,三级的话可能更高一些,业务影响分析和业务风险分析更多还是有一些评估,时间关系就不展开了,说一下组织,这里提到了危机管理组织和应急管理组织,所以其实都需要从没有组织建立组织,有相应的专岗做这些事,应急管理和应急演练就比较简单了,做多少事,包括一些相应的风险,这里后面就结合案例来说就不展开了。
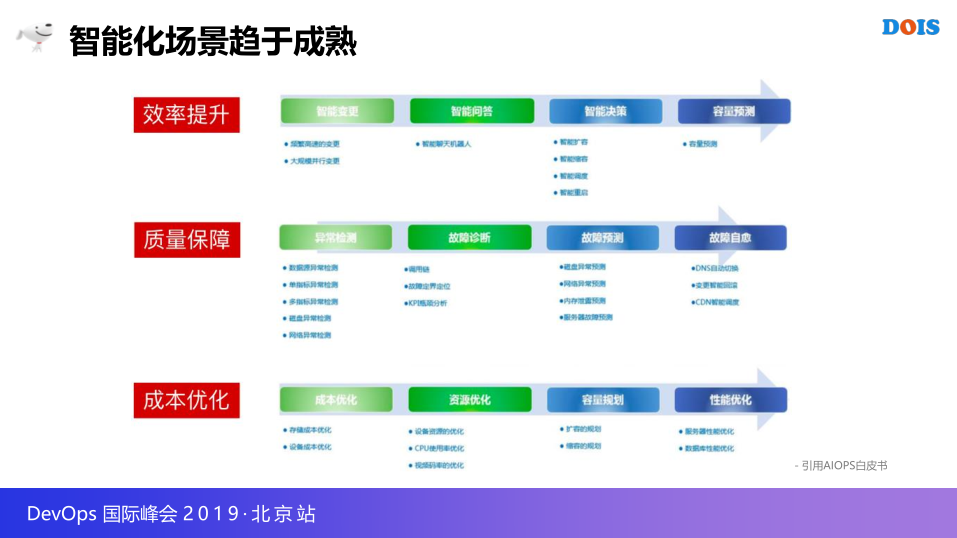
说完了三级内容,大家也会提到智能,这里无论是事件管理其他的管理,相应的高可用都有相应的元素注入,这里引用了一项白皮书,这里已经基本上去说清楚了,我们现在可以做的一些事,所以这里从效率质量和成本方面,都有相关的,大家看到相应的智能变革,变更方面的方式,智能化容量的预测,但是在容量和成本方面有相应的关系,都是在事件里面各个阶段都可以引入的,下面的成本资源智能优化,我们团队也在研究很多的方向,希望可以主动的分析决策出来应用,应该做哪些事,不是一个架构师还有研发架构师做大量的工具做这个事,也是希望有大量的工具做到相应的效果。
3. 案例实践与总结
我也结合相应一些团队过程中的一些过程经验和大家描述一下这些能力的应用,其实不是特别详,我是按照我真正解决问题的步骤回过来靠相应的标准。
3.1 案例实践一 团队事件与变更管理体系搭建
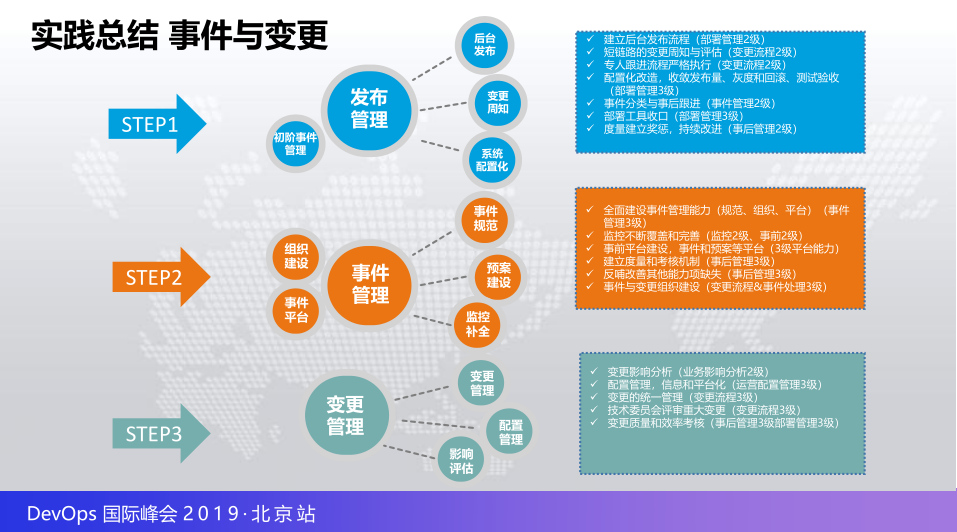
这里三个能力围绕都是我们团队几年前刚刚建立包括刚刚去测重经经营无心段的研发团队的治理一些经验,所以我们现在说一下事件和变更确实非常从零到一的一件事当时面临团队特点也看到了,电子商务的链条相当多,我在腾讯也是服务的很久,腾讯比较幸福的事是链条特别短,电商的业务流程需要经过你的前台团队,中台团队,后台团队,都有大量的京东云的团队,所以你业务请求上下游特别多所以这是一个非常不当的一件事,上万人的研发团队海量的需求,你配套能力也是同样缺失最后就是导致事故是频发的,错误是重复的,团队冲突越来越大,所以我的思考还是从万能的ITOM入手,什么问题ITOM都可以解决,但是ITOM有很多实践,所以从ITOM里面提取出来,第二个事件和变更的发布建立相应的治理,治理相应的规范,再到第三步,这些事要做实,标准化,这里特别标红完整能力的建设,一个时期的解决不是你的一项能力的提到三级解决三级,所以理论和现实是有差距的,我们遇到的问题太多了,步骤就是说先抓到而放小。
就是第一步干的什么事,全面整顿,发布管理,因为大家经常说,发布是变更的一种,可以这么理解,再变更当中,70-80%的故障都是发布带来的,如果发布这件事搞定的话,你可能70%的问题就已经没有了,所以差不多分界线三个阶段,我们先从后台发布入手,差不多有一个团队,SQA7个人整顿所有1500号研发,用最二级的能力,最被动的方法把所有过程推到里面,非常初级,但是非常有效,系统配置化不是配置管理的配置化,等会儿解释一下这个数据,建立初级的一些事件管理,大家看一下右边这一块,第一步可能建立后台发布流程实施,部署管理二级,短电路的变更和评估,短电路什么意思,我自己的团队的变更管理做到位,再做上下游团队的变更管理,就是变更管理二级专门做严格的流程化执行也是二级,收敛就是三级,事件分类,事件管理的二级,工具相应的收口,包括刚才说的配置化的管理,其实大家可以理解,配置化是这么理解的,十个需求都要去做,配置化就是零,来了十个需且只要做一个需求配置化就是90%,原团队接近百分之十几,现在基本上整个团队做上线的质量的事情的时候,都是这么做。

第二步做事件管理,前面的基础没有那么多事件以后建立实验规范,平台组织也建设起来了,大家可以简单看一下全面建设事件管理能力,同时也用到一些监控,这里就不再读了,进入第三步差不多6个版本,基本上从管理层非常重视我们所有的事件其实每周一起合作,所以大家写到事件组织一些能力大家说到的三级需要一些管理层的参加,这点还是非常重要的,变更这里简单说一下,前两步做好变更相当容易,所以这里相应的一些变更的影响管理,相应的基础委员会的建设,统一化的建设,这就是第三个去做的,所以事件和变更差不多就分三步完成了这个工作。
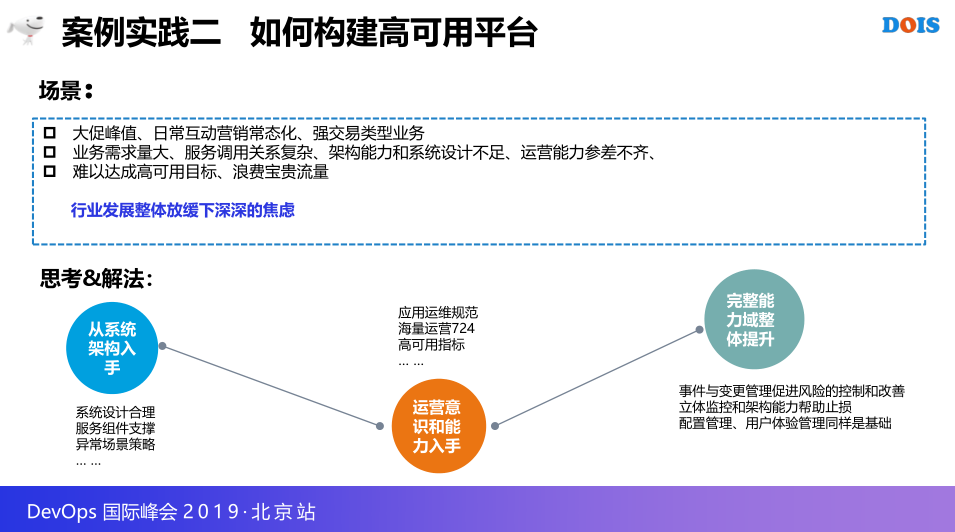
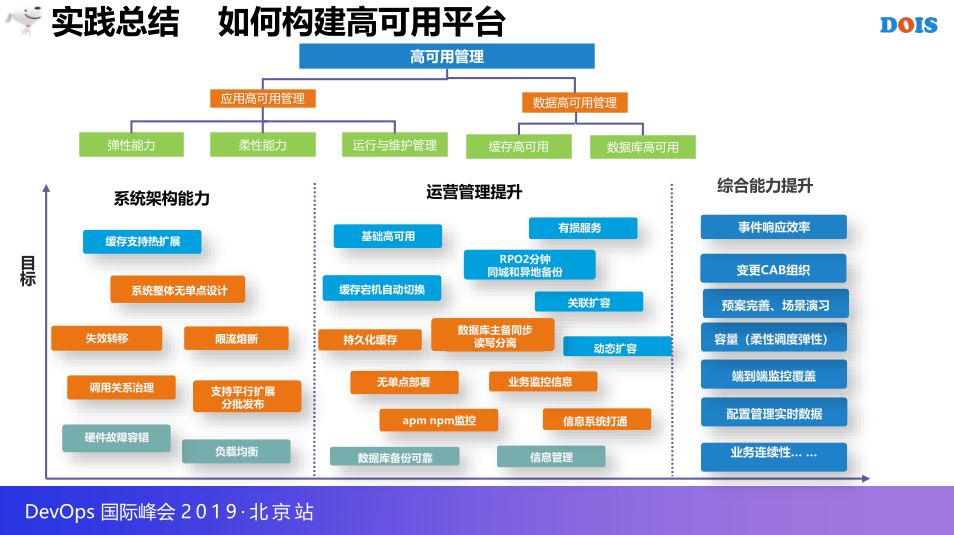
3.2 案例实践二 如何构建高可用平台
整体的风险流程管控好之后,来思考一下,如何来建设一个高可用的占比,如何建设高性能网站,以及用这个标题,高可用平台怎么建设,刚刚说过我们是一个电商大促团队,需求量也不用说了,架构设计都是不足的,有一个非常深的印象,以前双十一,618更多担心的是流量太多,今年开始我就感觉到是流量太少,不能浪费,在流量有限可以红利的情况下,整个行业都是非常低迷的,这个时候没有好的业务保障能力的话,会挂的很惨,所以也是有很深的焦虑感,所以我的思考问题还是要从架构设计入手,对于研发这边相应的原则使我有相应的服务组建的支撑,策略的研究,再到设计才有一个可以运营的过程,我们整地的运营规范,运用的规则,是一个手段,4个意识,再到度量指标的建设,第三点其实还是一种运营建设完整的,架构是一种监控能力的建设。
再往下列举了每一个过程优先做的策略,其实最下面的颜色就是去做的也是最基础的一级,我们团队是从一级开始做起的,京东也是属于一个快速发展的平台,基本上很多能力是不足的,这种就是系统架构能力和运营管理能力就不再展开了,我重点说一下综合能力的提升,因为综合能力提升就是一种协调能力的打造就是我们整个建设过程当中也是关注效率变更的建设和容量,端到端的建设,业务实施数据的打造。
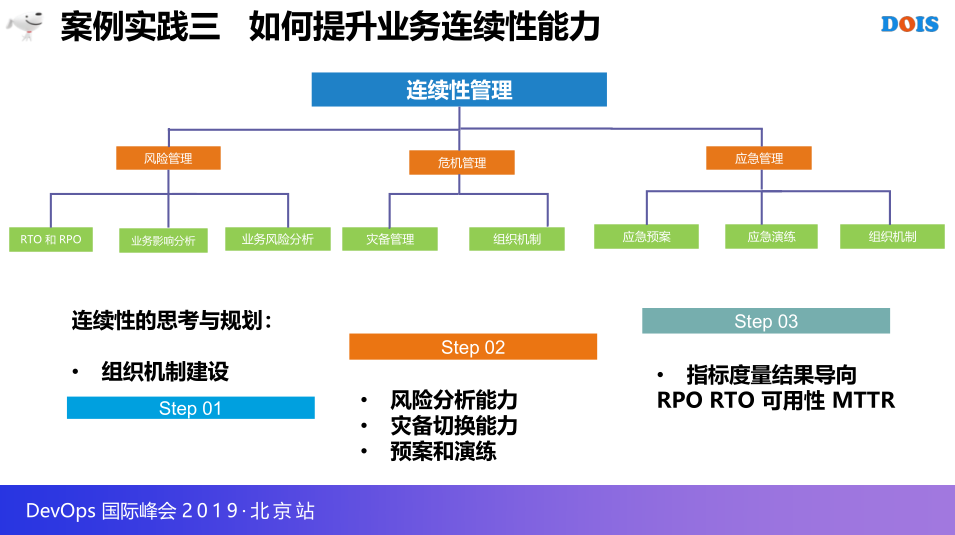
3.3 案例实践三 如何提升业务连续性能力
如何提升业务连续性管理,关键还是说一下思考,要关注分析首先有人想这些事,把人专职专岗建设起来,第二个才是分析风险,分析相应的切换能力之类的,这是分析和过程的一些建设,第三步才会结合行业比较优秀的指标,一些数据衡量不断接近这个指标,每件事情花了很长时间,这是我四年左右的治理,治理的过程,所以时间确实很长。
这里也是同样的,不同阶段,不同能力的引入,从风险管理,危机管理以及应急管理来看,因为时间关系。
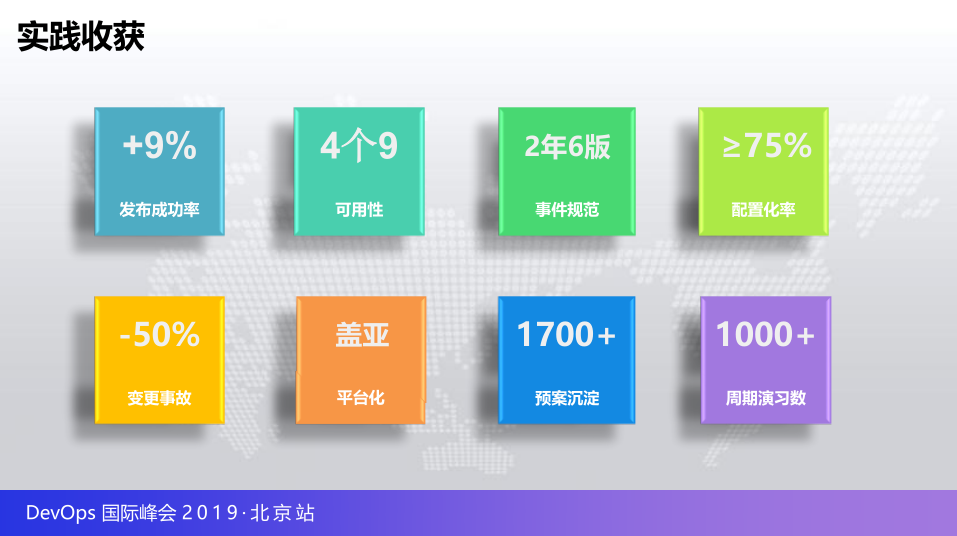
一些收口,没有什么敏感的,第一个原来发布成功率是90%左右,现在是99.6%,我们是作为一个和业务非常密集的,第二个4个9,互联网其实做到4个9还是不容易的,事件规范,两年迭代的6个版本,配置化率说过了,现在真正需求的话,可能只有25个需求可以进入研发阶段,基本上就是配置平台可以做的,完全没有任何发布,减了75%的需求,变更事故的话应该是上周看一下数据差不多两年时间下降了50%,平台化如果了解我之前一些TOP内容的话,其实特别介绍过整个技术运营的平台化的体系,我提到了盖亚就是整体从质量管理的平台,从运维管理的平台,从多用化管理的平台打破管理平台的举证,预案是1700+的预案,周期演习大概是1000多次.
对我分析的三个过程做一个简短的总结,事件管理就是全流程的建设,也需要一种估量改进,也可以从研发架构入手,连续性是风险的分析,三者还是有一些共同点,都是面向于做大量的建设,以及大量的平台化能力建设。

也是简短做一个总结,梳理一些相应的标准,为了给大家很好的方向,还是希望给大家前行,提供一些帮助,整个过程当中,也是希望多提意见,让我们大家多成就自身的业务,追求更高的卓越,面向高层的运维时代的迭代,我们完善自己能力的同时也是进一步去迎接我们下一步的阶段的迭代,以上就是我今天的分享,谢谢大家。

