@gaoxiaoyunwei2017
2018-05-11T08:22:48.000000Z
字数 5789
阅读 1424
海量社交业务多活及调度实战
luna
作者:李剑锋
作者介绍:李剑锋,目前是腾讯QQ的业务运维负责人,负责QQ的业务八年时间,参加了QQ业务多地多活的设计。
前言
天津大爆炸大家知道,我们借助这个来讲一下运维角度的技术问题。
1. QQ多地部署概况
首先,我们来看一下为什么要做异地部署。我们做异地部署其实是有代价的,我们在架构和代码上面都会做比较多的改动,涉及到很多兼容性,会把架构和代码变得非常复杂。
我们为什么做这个事情?可以看一下这张图(见PPT),这张图红红火火,但是一点也不喜庆,这天津港的事情,8月12号天津港发生爆炸,我们刚好有一个IDC就在爆炸点三四公里的地方。如果对深圳熟悉的话,蛇口有一个油库,如果蛇口的油库爆炸,我们的IDC就在海岸城,所以当时都有振动。我们就把7500万QQ用户从天津迁移到上海和深圳,把隐患消除了。

我们的服务是7×24小时服务的,我们要对消息系统进行变更,所以要做操作,所以我们必须有一定的措施,先把用户迁走、调度走,然后再做变更,减少这里面的风险。大中国的网络质量是非常难受的,不但是跨运营商的网络难受,不同地区的也很难受,所以我们要把接入点分布到全国各地去。基于这一点,我们2011年启动了这个部署。
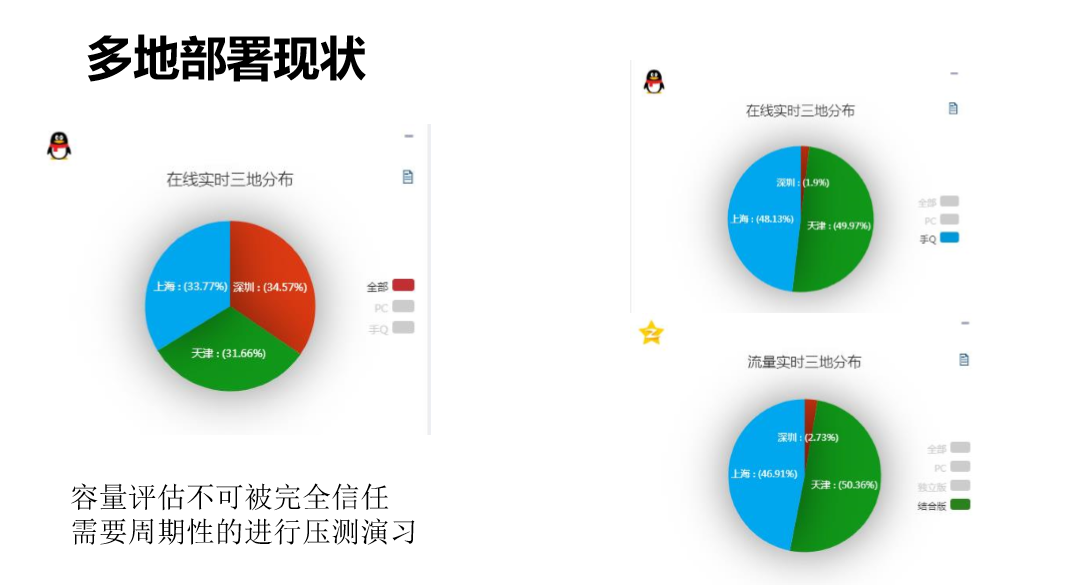
我们QQ的用户会分布在上海、深圳、天津三地,这不是人为的1/3这样分的,而是我们实际根据全国用户的质量检测平均分下来,自动调优,确实这三个地区会覆盖到全中国的所有地区。正常情况下是每个地方1/3,我们任何两地都可以支撑全量的QQ用户。
我们深圳现在集成了7000万用户,怎么把它变成1.4亿的用户,这就要定期的演习。变更是会发生的,每一次变更都可能对模块容量导致影响,为了变更的容量是OK的,基本上我们会对所有地区轮流压测,每个地区压测到1/2的能力。
这是我们演示的图,上面是QQ的在线,可以看到在线的基本上清空了,下面是Qzone。虽然我提到的是QQ,但是腾讯里面海量的服务基本上都是这三地分布的,包括Qzone、广点通、相册等等业务,所以我们调度演习的时候会做联动的演习,QQ调了,相应的其他业务也会一起调动,是做全部的演习。
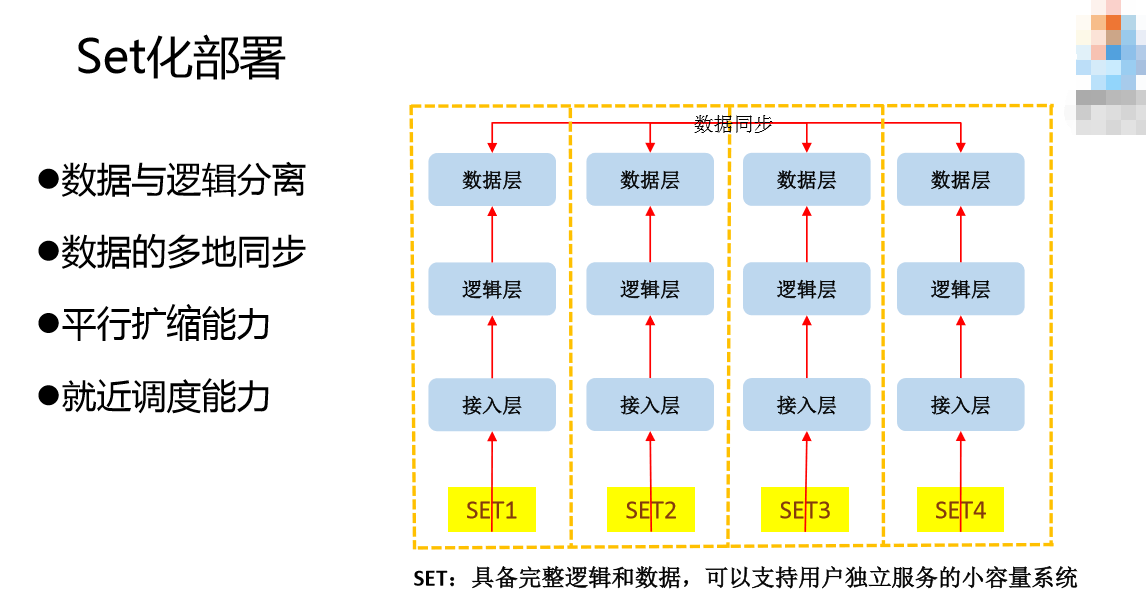
Set化部署与无状态服务调度
Set化部署,具备完整逻辑和数据,可以支持用户独立服务的小容量系统。我们要做Set化,就是把一个大的系统砍成一个个小的系统。我们要做Set化系统,就是系统具备Set化能力。我们要具备什么能力?我们要把逻辑和数据区分开,因为逻辑和数据在实现上的难度是不一样。对数据来说,难的是多地同步。以前对Set化有两个方面的定义,一个是把数据也切分到各个Set里面去,每个Set的数据其实是不完整的,根据用户的数据所在地再引导用户调度到哪一个Set上去。我们的数据是一个完整的数据,可以支撑全量用户,任何一个用户过来都是可以用的,所以数据的同步就是一个很大的问题,数据的多地同步的能力是必须大的要保证的点。逻辑和数据为什么要分开?基于一点,数据要做异地分布,数据的异地部署跟逻辑层的难度不一样,要把它分开,有针对性的解决数据同步的问题。还要具备平行扩缩的能力,扩的能力不用说了,为什么要具备缩的能力?原来我们在深圳,天津要有一套系统部署起来,深圳和天津的资源能力是不对等的,深圳68G的体系,天津给128G的内存,给一个小的内存,我怎么利用起来,就要有缩的能力。还要有就近调度的能力。
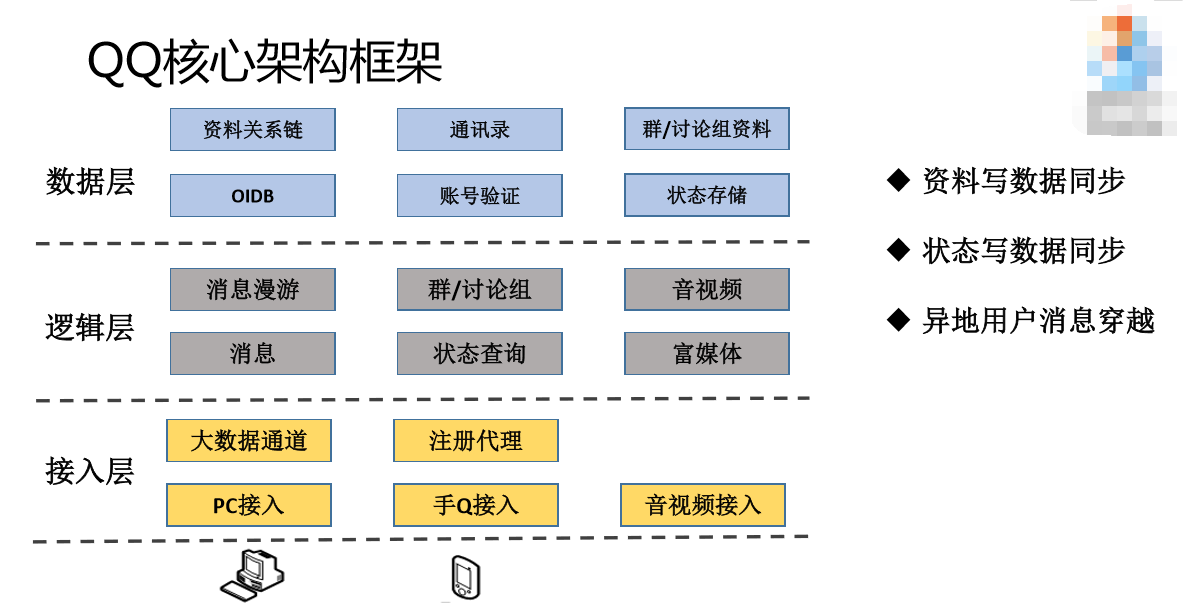
因为我讲的是QQ的东西,所以对QQ的业务做一下解释。QQ这里分三层:数据层、逻辑层、接入层。基层的接入层会负责跟用户建联,负责消息的中转;第二层是逻辑层,我们有一个群,把群的成员转化成一条一条的消息。这个群的成员放在最上层,每一个群的成员的相册等所有资料都在最顶层,这就是数据层。基本上就是这三层架构。
在这个图的基础上要达到Set化,根据用户的实际情况接入,根据用户的网络质量或者我们人为制定的策略,调动到不同地区,他的逻辑访问和数据获取应该在同一个Set里面完成。以群扩散为例,登录之后,群扩散取群成员应该在同一个Set里面去,下发也在一个Set里面下发,整个都在一个Set里面完成,只有资料变更或者改匿称的时候才会同步到其他地方去,其他的都会在一个Set里面跳转。
解释一下逻辑层的调度,讲两点,一个是统一路由对业务的侵入是比较少的,QQ原来没有统一路由,后面才逐步有统一路由,QQ后台是庞大的;第二个特点是我们根据来源访问,有梯度的调到被调的服务器。这个梯度是首先在一个单元里面选择,我会优先给你这个机器,如果这里没有机器就往上一层,看这个IDC有没有,如果IDC没有就往上看整个程序有没有,整个程序都没有,才会再往上选择,这是梯度的。

3. 数据层多地部署与调度
讲一下QQ的核心数据,分两大块,一个是资料关系链数据,二是状态数据。资料关系链数据包括你的头像、好友等等数据,它是可视化的数据,对可靠性保证要求比较高,我们修改这些匿称和备注是比较少的,所以读多写少,正因为读多写少,所以同步流量是比较小的。状态数据方面,每个业务都有落地数据,但是状态数据可能是QQ比较特有的,这个状态要保证每个用户的实地在线,你是安卓登录、iPad登录还是其他登录。每一次数据都会切换,涉及到写数据,所以有一个特点是不但读量多,写量也非常多,Set之间的同步流量也是非常大的。之前有人说到一个原则是数据跟逻辑分离,但是这也不是绝对的,对于我们的业务来说有一个特殊性,每一次在用户发消息的时候都需要查询用户在线状态的数据,这么大量消息的发送每次都要查询数据,这里的网络消耗是大的,对于我们IT业务的核心能力是要做特殊处理的,所以我们把数据下到服务器上面,发送消息的时候本地同步量更加大。资料关系链的特点,同步流量小,状态数据的同步量非常大,根据这两个数据同步量的情况,我们数据存储的情况也是不一样的。

这是有一个模型(见PPT),
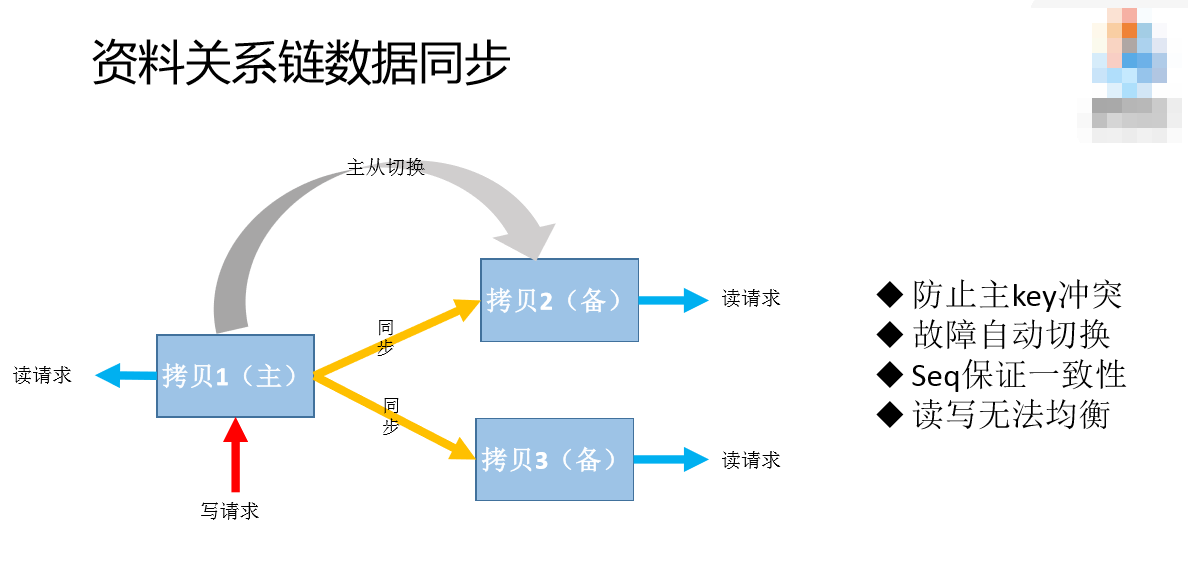
这有三个拷贝,其中一个是主拷贝,两个是备的拷贝。防止主key的问题,一个数据在不同应用上可能会同时发生key的修改,这是无法避免的。我们一个去写,多个去读,谁拿到这个就去修改数据,这会加大复杂性,运维也更加复杂。这套单写多读的方式也有一个不好的地方,一个是负载不均衡,因为出了写之外还要承担读,负担肯定会偏高;二是故障,存在单点的问题,这种情况下可能拷贝到单点,如果拷贝的机器死掉了怎么办?我们收集了一套自动的主备切换,如果主拷贝机器出现问题,会把备用的机器换为主拷贝。
当一个数据从写链进来之后,会有限写入本地的存储,有一个Binlog存储,然后去读,跟被拷贝的进行对比,如果不一致就会进行修改。这跟其他行业的“强一致性”不太一样,我们这个没有做到强一致性,目的是加快写的效率,因为中间加了一层类似消息队列的东西,就是Binlog把读和写隔离了。这里有一个不好的地方,两地数据的状态可能有微小的差距,同步期间可能不一致,这对我们应用来说是可以接受的,比如说修改了一个匿称,并不需要零点几秒就登录、让别人看到我的状态,所以是可以接受的。另外,我们本地存储是用了内存的,机器一旦死机这个数据就没有了,为了加快数据的恢复,我们会定期把数据存储到本地,机器起来之后,会重新把这个数据放到内存里,然后在binlog里面存放数据。
我们看一下这个binlog(见PPT),
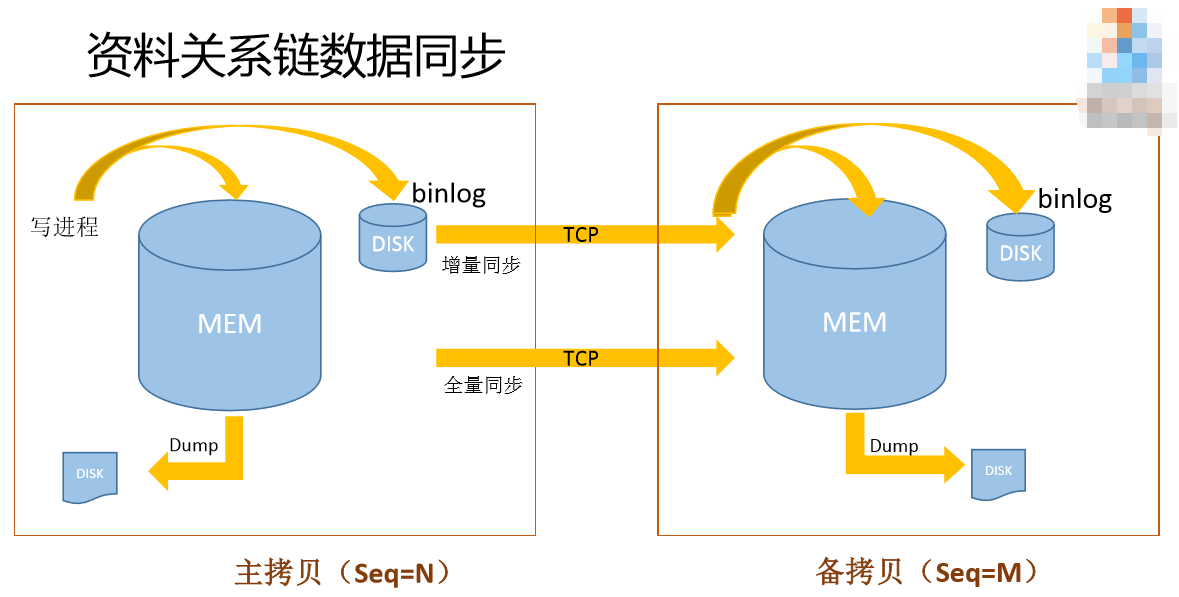
其实这里是磁盘存储的,这里我们变成内存的存储。这样做的目的是什么?因为我们读写的要求是非常高的,如果用原来那一套,读写能力完全达不到我们的要求,我们把所有数据都放到内存,加快这里读写的性能。我们通用的服务器大概是128G上面达到每秒3万左右,这个系统上面写已经不是瓶颈了,瓶颈在于网络流量和内存的大小。我们这个机器是万兆的流量,我们的读写已经没有瓶颈了。
从这张图上可以看,这套状态的数据是比较多的,我们同步的时候可以做到让它恢复的时候慢一点,当然磁盘还是会有一定的系统消耗,为了最大程度的提高读写能力,我们把所有的磁盘全部用起来。
通用的服务器是128G内存,对QQ数据来说没有办法存下来,那怎么办?前面提到多个拷贝的部署,就是为了解决我们请求量的问题。对于容量上的问题怎么解决?就做数据的切分,把存量QQ用户的数据切成很多小份,放在多台服务器上面去。怎么切呢?
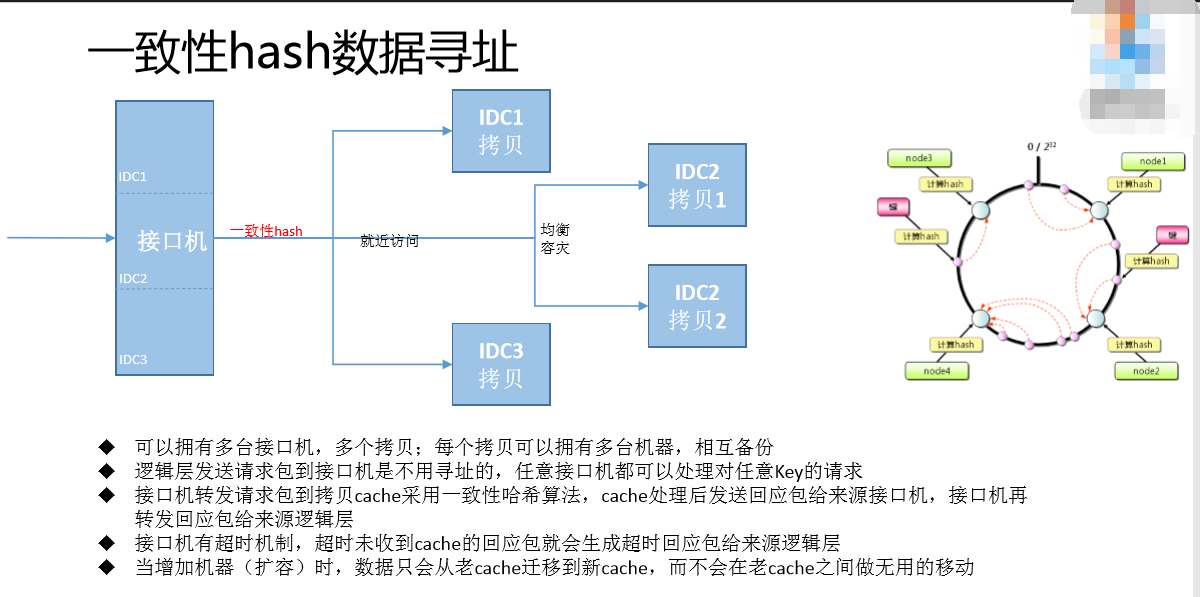
通用的做法有两种,也就是现在比较流行的做法,一种是用一致性hash的方法,每个节点对应起来。大家在网上可以搜一下,一致性hash我不做过多介绍。一致性hash的算法是可以通用的,实现上也是比较通用的,如果纯粹用一致性hash,在数据库里面就会把数据全打乱,扩容就有这个问题,数据的迁移非常多,老数据也会在节点之前做迁移,这是不好实现的,实际也会在中间屏蔽迁移的问题,但是它有一个缺点,算法复杂一点,反正我的大脑是不行的,我看到这个key是分析不出来在哪一个结点上面,所以对故障分析不利,没有办法从某一个故障里面看出某一个节点有问题。
第二个方法是号段的切分。号段的切分有利有弊,有利的是可以看到某一个号段在哪一个结点上,但是我们需要额外开发一套系统去维护起来,包括我讲到的扩缩容,系统也专门针对号段做这个系统。实际上我们两套方法都有用,状态方面用了号段切分的方法。

一致性hash的数据寻址,我们不对外部的调用方产生影响,调用方调用每台服务器都一样,从无状态变成有状态。我们找到相对应的符合要求的hash服务器,每一个拷贝都会找,找到以后会做第二步,会做接近的访问,就是前面类似于逻辑层的访问,会就近选择,比如同一个IDC、同一个地区。因为同一个地区可能有多个拷贝,再从多个拷贝里面选择一台服务器。
这是一致性hash的图(见PPT),到处都可以找到这张图,这是比较原始的一致性hash的原理图。我们实际做的时候,扩容的时候、实现的时候加了另外一个环,这个环就是虚拟节点,用来屏蔽掉真正机器的节点和hash之间直接关联,中间多加一层映射层,我们控制的时候数据会在里面不断的挪动。基本上我控制一台机器,会把所有的hash全部打乱掉。大家可以在网上找来具体学习一下。
号段的切分寻址方案。一个是全量QQ号码,我们有一个办法,直接在这个号段上面切,这一段切成某一个段、下一段切成某一个段,这种方法在增加新的号段的时候,就必须给新的号段增加存储,就造成一个冷热不均的问题,前面的号码天天登录QQ体验,这里都是老用户,非常热,新的用户就非常冷了,就会有冷热不均的问题。我们的方法是把这三个号段取出来,转变成UNIT号码,再用UNIT号码切分,假设切分成这平均的四个号段,我们分别把这个号段定义成SHARD1、SHARD2、SHARD3、SHARD4,然后就可以有服务器集群用户。为了覆盖大量用户,我同时部署多个拷贝。
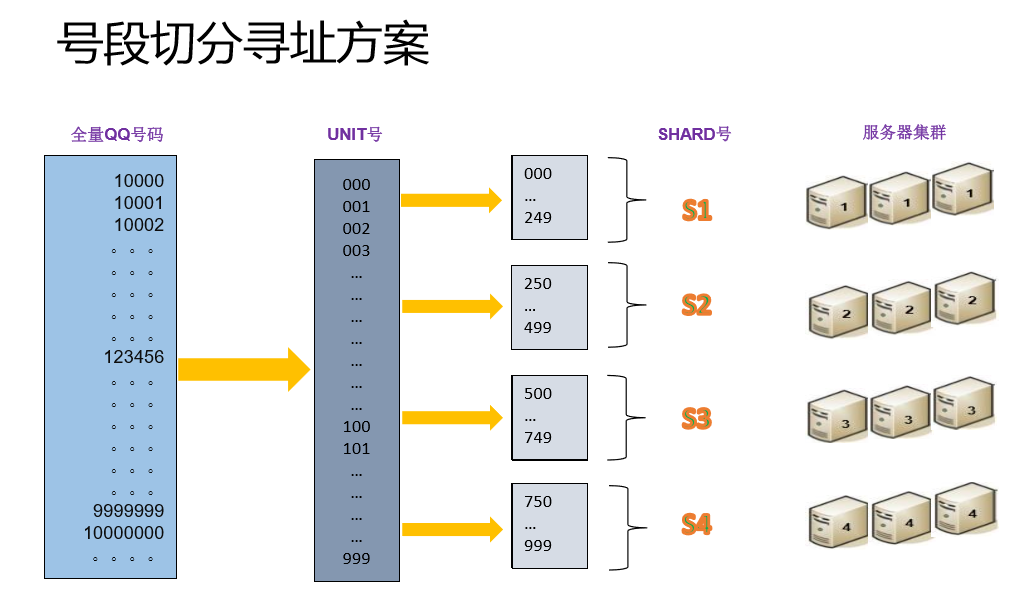
我们要建设很多支撑系统,其中一点是热扩容,这是要专门定义和开发的。来看一下我们是怎么做的。
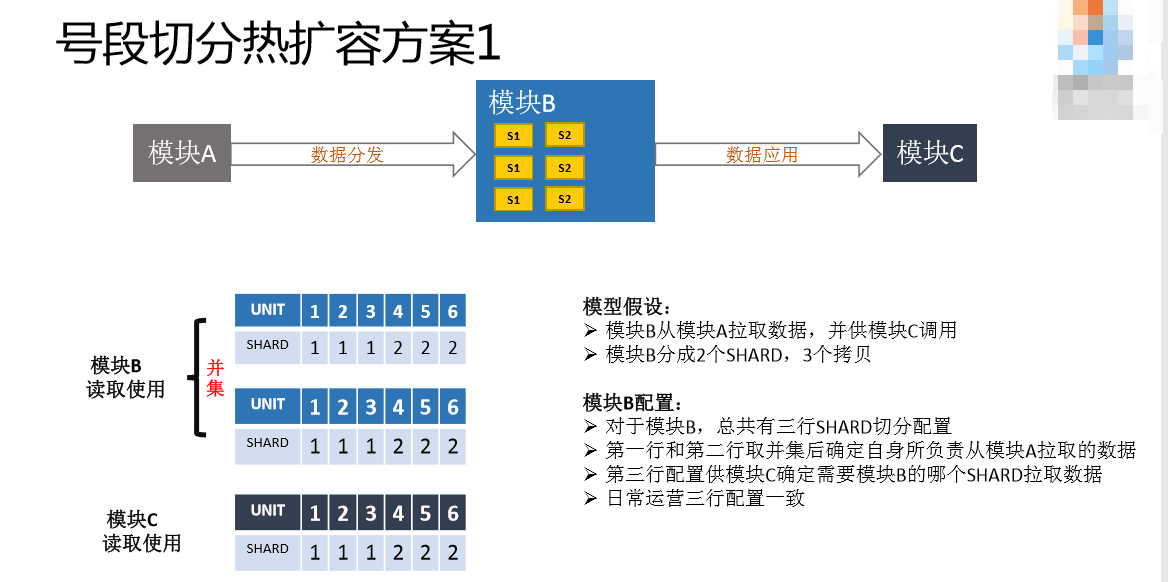
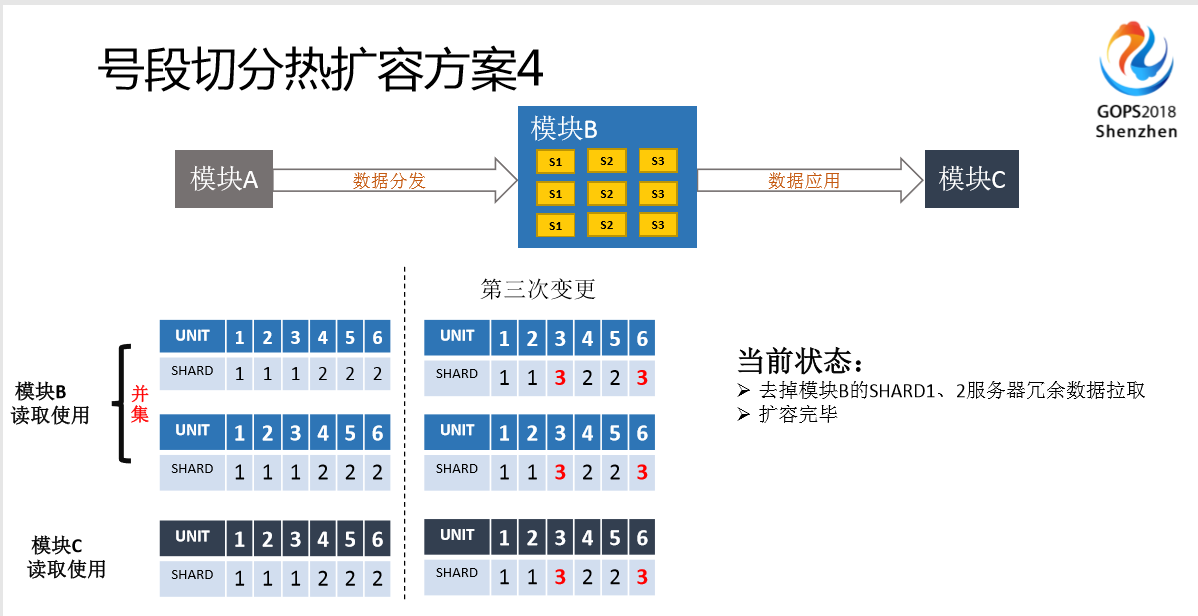
这是一个模型(见PPT),分模块A、模块B、模块C。模块A负责把数据拿过来,提供给模块C这个应用去调用。中间的模块B的配置是怎么做的?前面说到号段的方式,这里是一个配置,我们这里只有三行配置,第一行和第二行配置是给模块B自身用。这是正常情况下,三行数据都是一样的,取出来之后,可以看到这两个取并集,SHARD1负责一二三,SHADR2负责四五六。第三行是给调用去用的,模块C选择调用模块B哪个数据的时候通过这个并集选择,比如这个号段属于UNIT1,那就去UNIT1里面取数据。
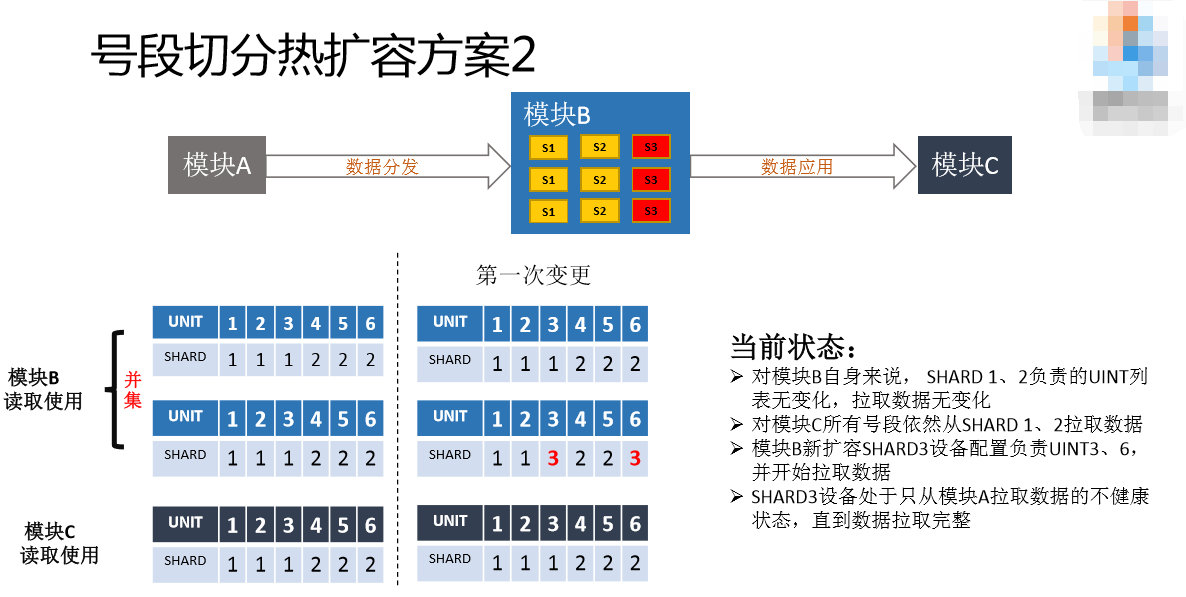
如果不够用了,我通过三台服务器去存储数据,那怎么办?首先做第一次变更,把第二行改掉,增加了SHARD3,用了UNIT6。SHARD1是并集的,所以SHARD1取到的数据,UNIT还是123这三个,SHARD2是456,SHARD3也是456,SHARD3和SHARD2一致,访问数据也还是原来的访问数据,不同的是SHARD3的数据会有提供服务的数据。这其实是数据同步的状态,SHARD3目前不可以提供服务,目前是属于数据同步状态,这时候要等它同步完。
假设同步完了,SHARD3的数据可用了,这时候把第三行改掉,让新扩容的数据、新扩容的服务器提供给模块C,就可以用了。第一行为什么不改呢?第一行是为了防备的,因为可能会回滚。有第一行的数据保证,所以SHARD1和SHARD2的服务器其实还是可以支持全量用户的,一旦发生了意外情况,模块C访问的时候发现UNIT服务有问题,就可以说SHARD3的服务有问题,这时候就回滚,直接把第三方配置再改回来就好了,可以检查一下SHARD3服务器有什么问题。
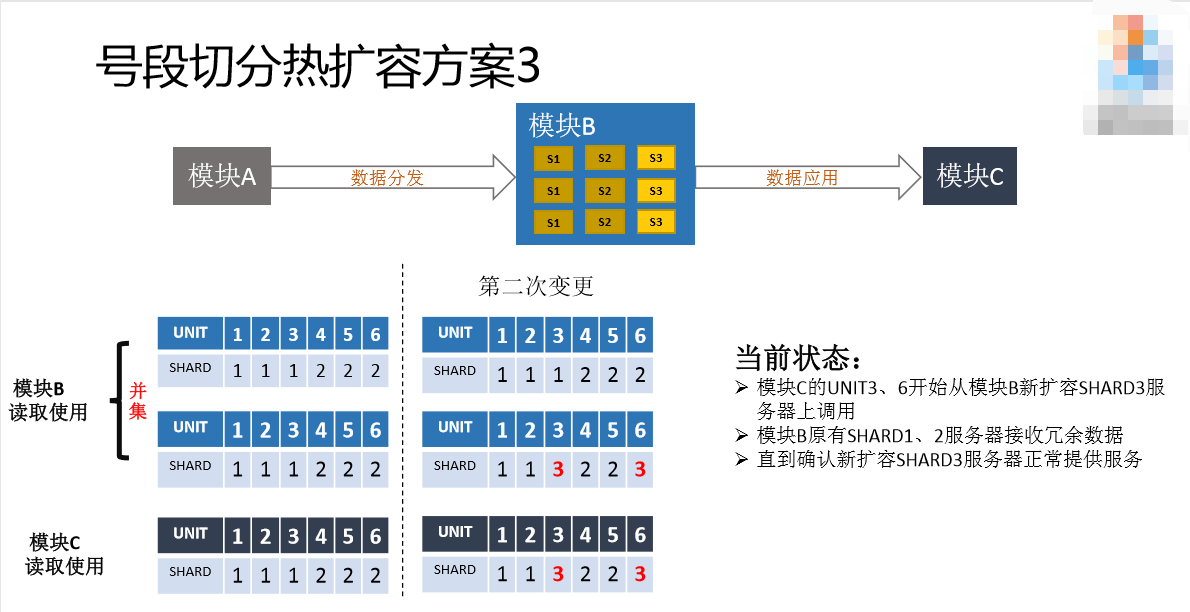
如果没有问题,最后一步才把第一行改掉,这就完成整个扩容的国家。
4. 调度实战。
按照前面的规划,我们已经把Set给Set化好了,也部署好了,怎么把用户调度过去呢?先介绍一下调度的基本原理,PC版QQ我们有一个“重定向”的定义,客户端请求这个服务器的时候,有一个协议,你不要用这个了,这个满了,你要拿一个新的IP,他拿新的IP来登录。手机端的QQ会根据列表里面的IP一个一个登录,优先第一、第二。无论是哪一种方式,我们都可以人为的干预他登录的目的地。

正常情况下,我们根据Set信息统一调度,会根据服务的最优化来分配到你应该登录到哪里去。网络故障了或者哪个地方发生爆炸了,我们可以人为干预,比如说不让用户登录Set1了,我们把Set1的用户和IP在这里面去掉,让调度系统下发的时候不会下发到Set1的机器,这个在线就直接标注到别的地方去了。
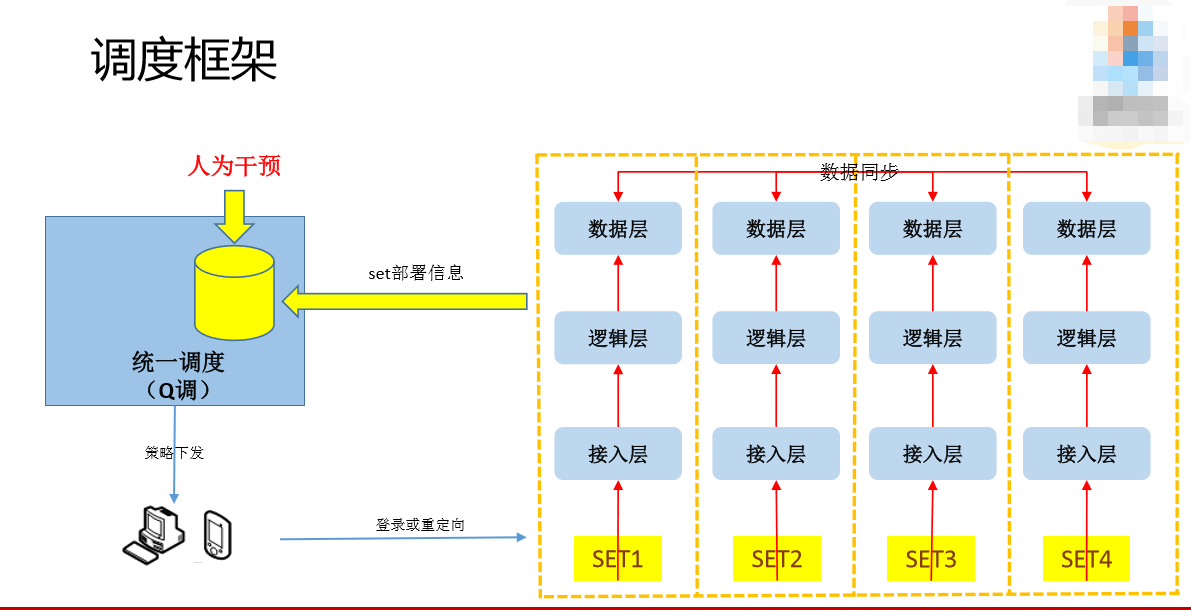
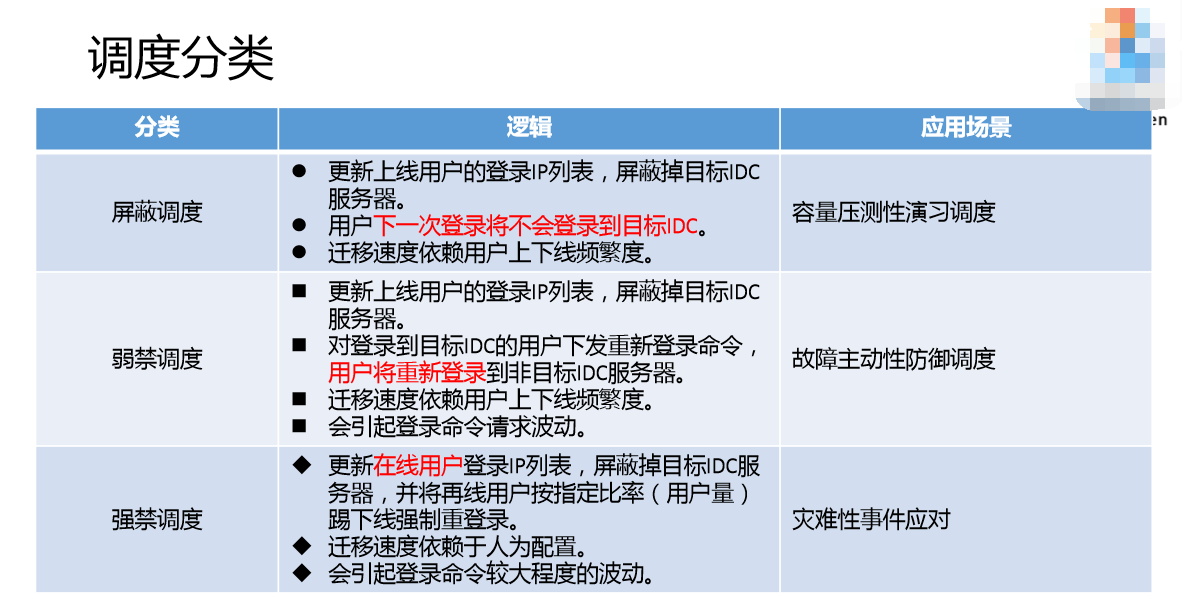
我们根据不同的场景做了三种调度的分类。
- 第一个叫屏蔽调度,用户上线的时候登录了这个IP,实际上已经过滤掉我们的IDC之后的列表,下次登录的时候IP列表就改了,下次登录就不会登到这个新的机器了。
- 第二个叫弱禁调度,用户登录上来更改本地的,这时候不会登录,用新的IP列表重新登录,本次登录是立马生效的。
- 第三叫强禁调度,已经登录的用户,我给你踢下线强制重登录。这种屏蔽的比较慢,等下次才会生效;弱禁调度本次就生效;强禁调度比较快,强制重登录,当然对用户来说是无感知的。
屏蔽调度,我们会压测,因为不知道模块容量够不够,所以会慢慢压它。遇到故障,主动性防御的时候,比如说天津港爆炸了,这时候没有致命的打击,但是风险非常高,所以我们用弱禁调度的方式。如果灾难性事件,比如爆炸真的影响机房了,都死机了,所有用户就要掉线重登录了。