@gaoxiaoyunwei2017
2019-06-25T02:32:05.000000Z
字数 6306
阅读 1468
B站高可用实践之路
北哥
讲师简介
毛剑
- 架构师

本文内容偏像细节化,完成高可用的RPC框架、服务治理的熔断和限流,我们是怎么做到的。整体大纲会分为五部分:
- 一是B站内部的负载均衡是如何实现;
- 二是应对突发流量和异常情况的时候,我们如何来进行限流;
- 三是个别服务或者是集群遇到内存比较高、CPU比较高的时候,我们如何进行负载系统保护;
- 四是降级实验;
- 五是超时配置等是如何实现的。
1. Load Balancing
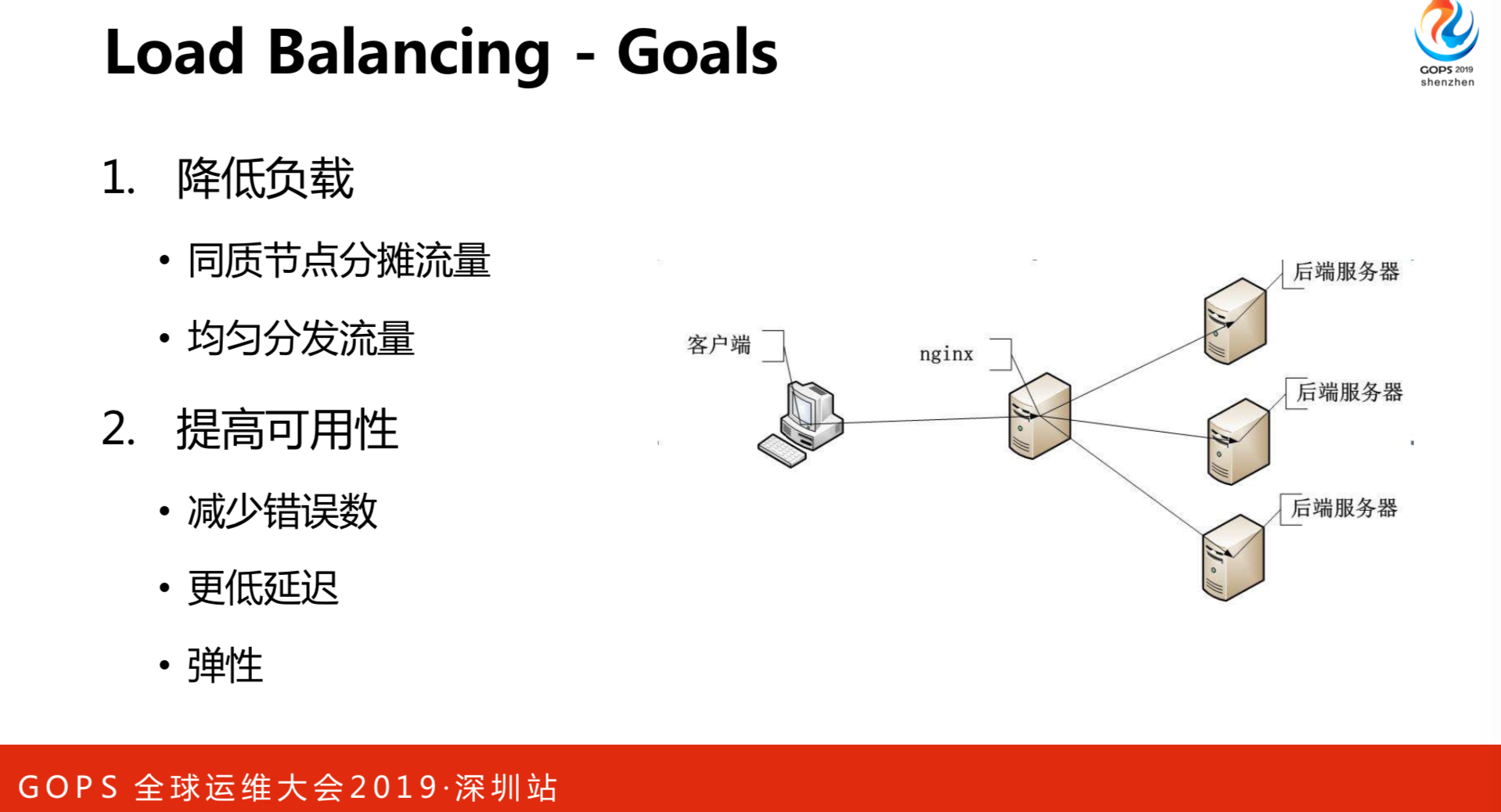
我们经常会接触到负载均衡,负载均衡的目标是两个点:
1.降低负载。一台机器肯定搞不定,就加很多台机器。目标很简单,就是降低负载。指的是同质节点分摊流量。做AI的同事会用异构的方式,可能AB两个进程在代码有差异,但是是同样的接口。目的是均匀分发流量。
2.提高可用性。首先是减少错误数,还有更低延迟和弹性。同一个客户端处理同一个请求和处理十个的时候是有差异的,这是负载均衡的目标。

在实际实现过程当中,经常会遇到什么问题呢?我们看右边这个图,如果负载均衡做得比较差,会导致每一个实例之间CUP的差异是非常大的,有一些可能非常低,有一些非常高。出现这种情况,在部署应用越来越多会导致任务编排、KYS和编排系统每一个物理之间的差异非常大,也就是我们没有合理的利用资源。比较好的形状是每个节点的CPU和负载是比较接近的,这是比较好的情况。为什么会出现图中的两种情况呢?
- 请求处理的成本是不同的。一个信息进来之后,如果只是请求一个用户信息和请求一千个用户信息,它消耗的资源是有差异的,比如要序列化,成本是有一些不同的,消耗CPU内存是有差异的。
- 物理机环境的差异。比如上架的机器,有一些CPU很好,有一些老的机器是CPU差一些。还有一个是坏邻居,指什么呢?有一次我诊断信息就像是左边这个图,当时就发现了KYS把信息调取到更多是这台机器,导致它切换更多。在同样的KYS的情况下,它需要消耗更多的CPU,才能保证我们的接口。这种情况也是比较常见的,很难说编排系统能实时地识别到一个物理机之间的CPU任务变化,我们调度是静态的,高峰可能比较好,低峰的时间可能差异比较大。
- 性能因素,我们有一些语言是在CG端,经常会做一些动态加载数据处理,它就会拉到很多数据,就导致GC时间更长,CPU比其他占用更高。还有一些是JVM进程刚刚启动的时候,需要做预热,这种新起的节点会对负载均衡产生一些新的影响。
在各种差异的情况下,要保证可用性,这种可用性就是定一些指标,比如延迟、错误率。我们要在更小规模的可用性的考量,就要有更优雅的负载均衡的算法。
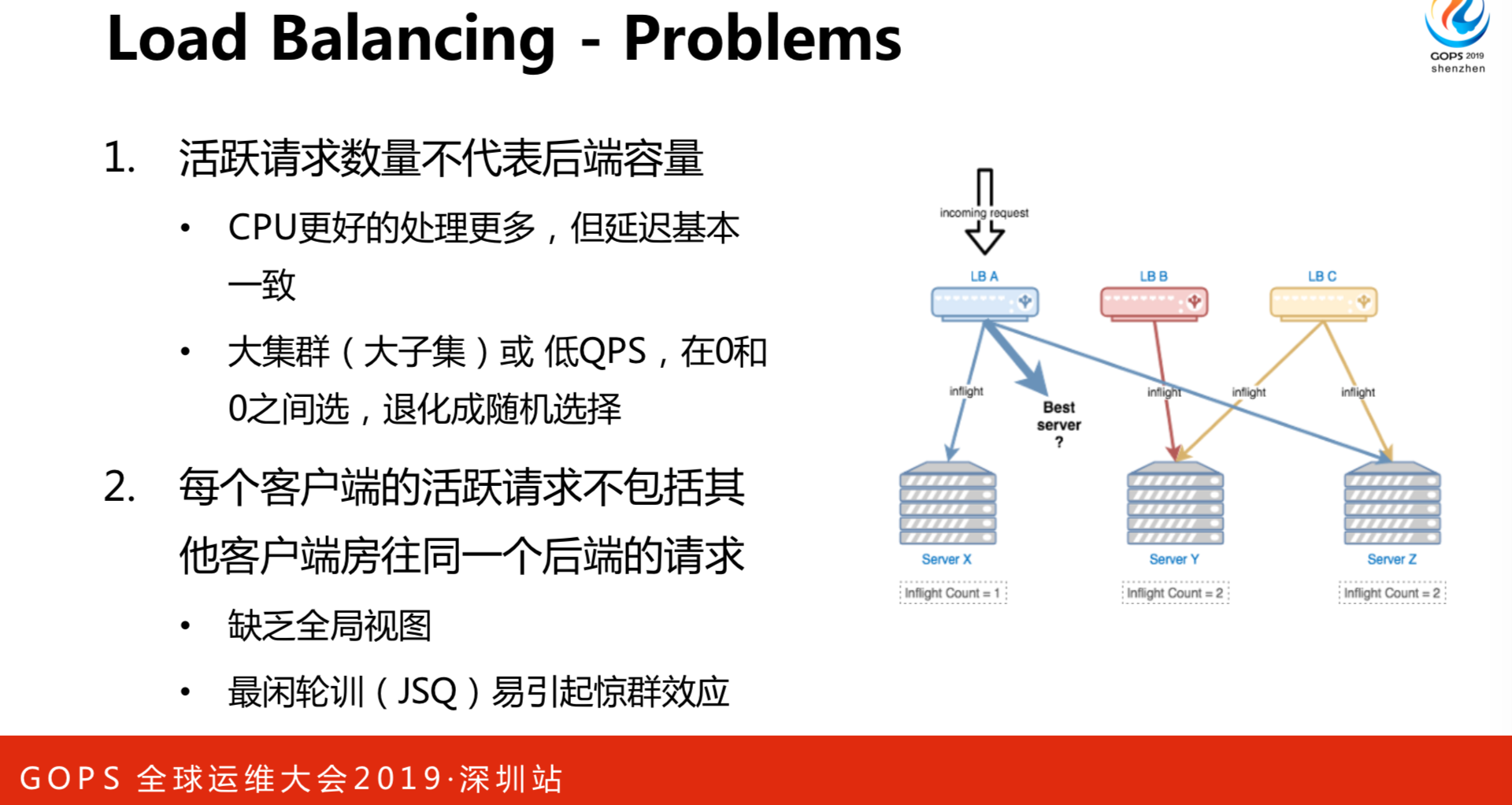
先说一下负载均衡的问题。看右边这张图,有三个负载均衡:LBA、LBB、LBC,对于LBA来说,它当前有三个并发请求,一个是发往X,一个是发往Z,对于第三个选择的最佳服务器是谁呢?如果是JSQ的算法,它一定会选择Y。对于B来说,它可能是X和Z都可以。对于C来说,可能就选择X。但是,实际上当前对于后端来说,正在处理的请求是不一样的,刚刚说的LBA最佳是Y,但是,并发请求数为2,其实不是最佳值。从服务角度来看,最佳角度是X。出现这种情况,负载均衡都缺乏一些失衡,导致调度会偏差。活跃的请求数量不能代表后端的数量,因为有些CPU更好,会处理更多,但是延迟是基本一致的。我们有一些集群可能有成百上千的节点,这种超大集群的QPS不是特别高的时候,如果产生坏邻居,它的物理节点、CPU比较高,产生延迟就会更高。从客户端的角度来看,你缺乏全局试图,看不到其他客户发往其他客户端的请求。这种调度方式容易引起“鲸群效应”,导致它的请求数比其他的多很多的。
对于上述问题怎么解决呢?
choice-of-2算法我们找了很多资料,参考谷歌的方法,最终的实践是用了P2C的算法,叫Choice-of-2,是随机选两个决定,之后再对这两个决定打分。P2C的实现是非常简单的,CPU成本也比较低,请求分布更好。它是伪随机的,假设有10个节点,每个节点的选择的概率是均等的,但是,通过一定的手段,比如打分机制来形成更好的节点。基于client统计指标调度客户端包括健康度,在客户端做负载均衡,如果健康度不够,是不是要对它进行降选。Health连接或特定错误的比率问题,因此选择了Moving Average。CPU、坏邻居等因素引起的请求延迟。还有当前运行的请求数量。这是从客户端维度衡量的三个指标。基于server统计指标调度Server的指标是什么呢?综合测试下来,我们最终选择CPU,就是服务端的CPU,也是使用滑动均值。这个CPU有问题的话,怎么知道对方CPU的信息呢?有两种方式同步回来的:- 对于低QPS的RPC,经常发生一些信息,通过这样的信息能得到具体的情况;
- 每一次发送RPC请求到Server,Server把它的值给带回来。
我的业务是高频的请求,CPU收取信息很快的。PRC算法是选两个节点,用Server打分机制计算选出最优的节点。
4. 针对新启动的节点启用探针 新启动的节点,可能要JVT预热。如果负载均衡和RPC的服务发现把流量介入就容易超时,有两种做法:一种是在进程启动的时候先做代码的覆盖,然后再向服务注册和上层调度系统来借流量。另一种更优雅一些,可以在负载均衡算法里面,对新启动的节点进行惩罚,新启动的节点权重是比较低的,随着时间的推移,慢慢权重恢复到正常水平。早期放一两个请求进去,尽可能的覆盖问题,随着时间推移渐渐增多,这样就不容易超时了,这个叫Penalty。
5. 对统计值进行实践衰减 有一些节点因为某种原因导致延迟非常大,错误率非常高,这样就进入黑名单了。进入黑名单之后,由于数据是老的,没有机会重新调度和刷新峰值,就导致它永远进入黑名单。这种情况下,就要对Server打分进行一些统计上的衰减,让它逐渐恢复到正常的水平,这样黑名单问题就解决了。怎么做的呢?也是使用时间维度来进行衰减。这里有一个公式VT=V(T-1)Xβ+AT(1-β),β为若干次幂的倒数即Math.EXP((-Span)/600MS),这就解决了永远进入黑名单的机制了。
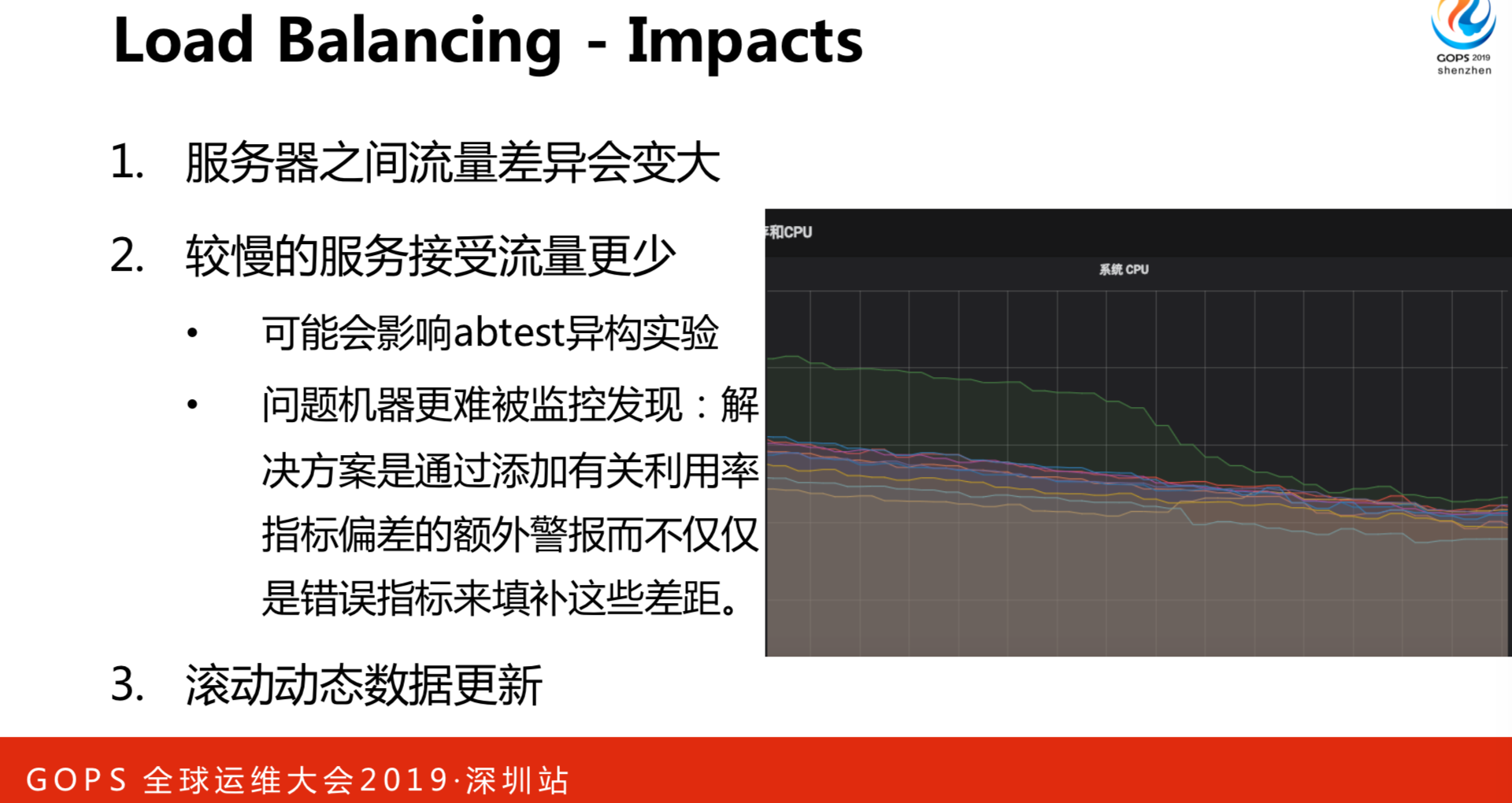
在做了上述事情之后,取得的效果非常明显如上图所示,立马从差异很大的情况下变成了每个节点之间的负载是根据综合调度得到的结果,相对而言是比较均匀的。但是,也会带来一些负面的影响:
- 服务器之间的流量差异会变大。有可能这个节点是十个请求,另外一个可能只有两个请求。
- 较慢的服务接受流量更少。会影响到异构实验,早期做AI的同事不想录同质实验,因为它需要录框架,这是有差异的。流量小对有问题的节点要被报警出来更难了。接受流量更小,CPU恢复到同样的情况下,报警系统不一定能挖掘到这种信息。要利用指标的偏差,比如某一个节点跟大盘的节点有多少,把这些节点挖出来。
- 滚动动态数据更新。我们比较推荐的做法是,假设有十个节点,这十个节点就错峰同一时间执行,比如随机取一个时间范围,尽量的错开。如果我们有一些批储量的任务,一下子取一两千或者是更多用户信息的时候,尽量是合理处理。还有其它做法,比如两套集群,A处理正常的,B处理批处理任务。负载均衡的重点是一个集群之间节点选择的实现,还有更高级的做法,如跨数据中心的数据均衡。
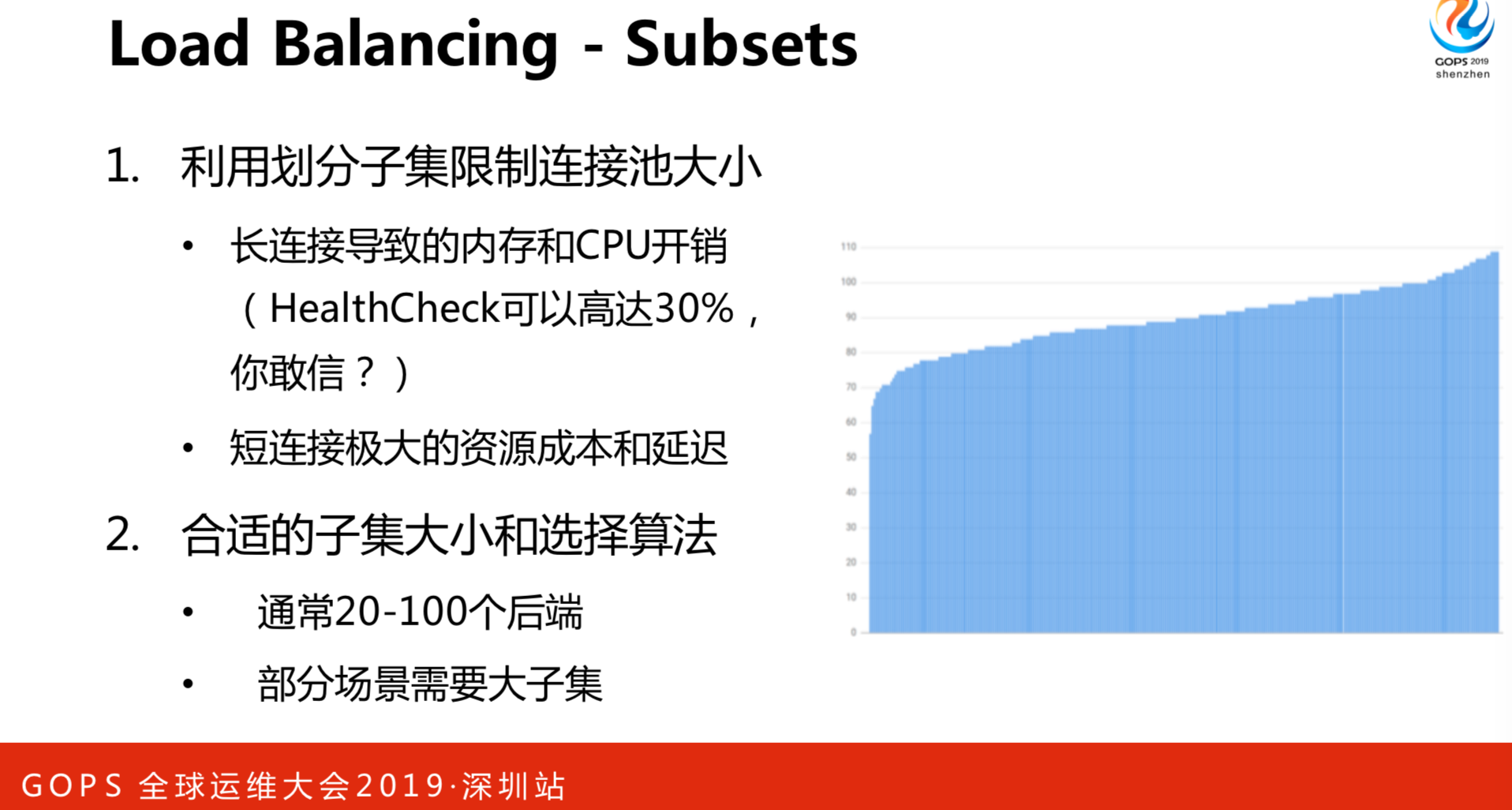
每一个人要跟一百个服务器连接,连接数是100×100 1万个连接,这是一个消费者的情况下。有一些公共几百个服务,数量就非常大了。我们觉得连接数不是特别大,内存开销比较小,但是,真正致命的是Health Check。我们发现大部分CPU开销是HC。怎么解决呢?这就考虑到我们要做子集算法。怎么做的呢?如果我们的客户端数量比后端数量少很多,这种情况下是推荐小子集。如果某个业务经常导致大量的资源不均衡,比如一下请求一千个、一百个或者一个,这种差异大的情况下我们推荐大子集,这可以削掉很大请求带来的负面影响。

我们最终是参考了谷歌的算法,它的核心思路是什么呢?就是不同的客户端使用不同的方案。首先用客户端ID,它会得到一个轮数,不同的轮数用洗牌的算法拿到列表,相当于洗牌打散。有一些会得到相同的轮,又会使用不同子集的ID,比如我的子集是100,我只取20个,另一个人取后20个,这样就不能均衡了。有几个核心的关键,就是尽可能的均分,每个人可以计算种子,洗牌全部打散了。还有客户端重启和下线,所有连接必须重新均匀,包括服务端也是一样。
多集群是同一个应用有多套cluster,如集群A有10个节点,集群B有10个节点,为什么这么做呢?为了避免如果只有一个集群,假如出现了故障,所有的业务就都故障了。我们的做法是两套集群,A集群、B集群是两套储存,使用不同的缓存资源。多Cluster的情况下,是在各个集群之间抽取的节点。早期我们犯了一个错,账号有3套系统,A给业务A使用,B给业务B使用。B站直播和游戏用户,用户之间的重合度未必非常高,有可能集群A用户导到集群B的时候,由于重合度不高导致了负面影响。后面我们就换了个思路,既然一个应用,我们就当成逻辑上的一套集群,但是在物理上是多套缓存,尽量多选择子集节点,这样可以消除掉刚刚手动选择集群带来的负面影响。

负载均衡的Lamed Ducking,就是跛脚鸭,指的是节点启动的时候,没有准备或者是不健康的状态,比如要开始做预热或者是下线的时候,节点需要清洗流量或者是通知连接我的人,我要下线了。我们做的是任务编排系统发送Sigterm,某一个APP拦截到一个信号之后,会向服务发现Cancel心跳。后端进入跛脚鸭状态之后,就知道即将下线,要通知当前已经连接到我的客户端,先要把我从连接池中踢掉。这样两步做下来,新连接服务发现找不到它,老连接主动的告诉它要从连接室剔除,就保证没有连接起来。还剩下当前正在运行的情况,就是Inflight,大致的原理都是类似的,它能监控当前的活跃连接、活跃请求,直到活跃请求降为零,平滑退出。
2. Rate Limiting

- QPS陷阱。不同的请求可能需要数量迥异的资源来处理。有一个人拉全量列表,有一个人点进去一个列表,他们之间的资源开销非常大。99%的公司都是QPS做静态限流,QPS不能代表资源CPU和内存的开销,我们当前也是使用CPU分配。
- 给每个用户设置限制。全局过载发生的时候,80%的情况下都是有一个人BUG引起的,一个人突发的流量把整个集群打死。这个情况下只要把他一个人干掉,其他人都不受影响。要控的就是这一个人我们叫“致死请求”,只要剔除他之后就能解决。我的容量是5000,所有消费者加起来是等于6000,很少有所有配额跑满的情况。
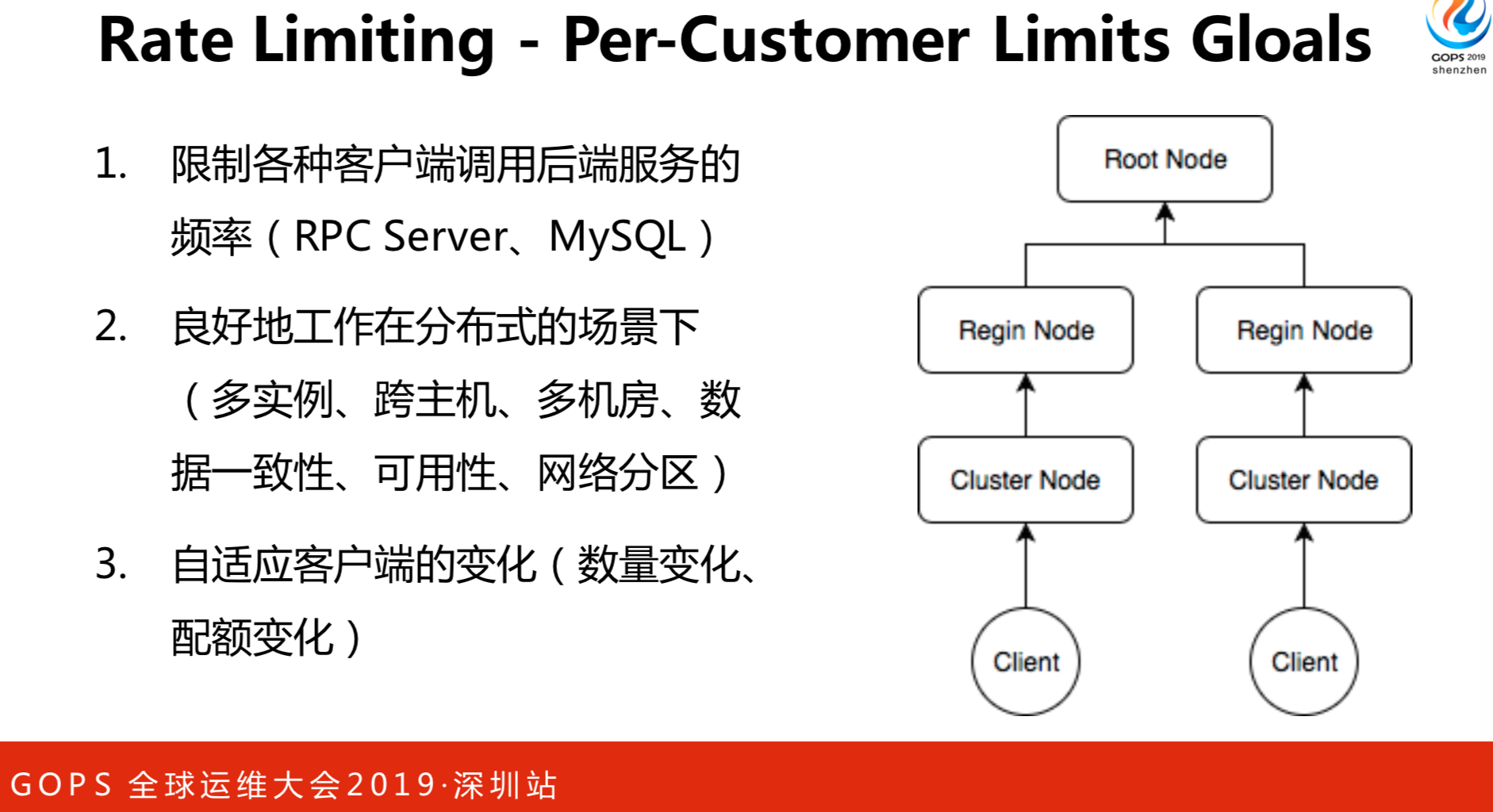
我们参考了分布式限流的服务,分布式限流怎么做?一个技术、一个超时窗口,大于什么数值了就发送信息。现在是拉指标,一次性多拉一点,让每个节点分配是比较困难的,等一下会讲里面的算法。另外是不希望限流系统要人工介入配置,比如A业务用限流系统要用集群A,B业务要用集群B,希望全用一套系统。所有的服务都是在Root node里面。Regin node是地区节点,华南和华北都有机房,可以按照Regin node来全球局域做限流。我的客户端拉配额的时候,只要横向扩展这个节点就行了,这就可以解决伸缩的问题,我们只限SPC Server。假设发了一千,但是要拒绝900,这个拒绝成本很高就会成为问题,我们没有参考“看门人”的做法,只是参考了框架,它的核心思路是客户端连接断掉,就是网络请求不发送了,我们不希望这样,因为这会导致所有的RPC污染。我们怎么实现的呢?下文再阐述。

如何均衡配额呢?首先要知道多少个客户端,对限流服务来说有3个节点,配额是120,先求均值120÷3=40。A需要10就给10,多出来的30就用“均分配额”,至少保底给均值,再给差额的比例,这样就比较公平了。

回到上面遗留的问题,如果拒绝成本非常高的时候就要做一些工作。我们知道有熔断,熔断跟客户端的截流是一个思路,在客户端利用熔断的机制发送流量拒绝。熔断器的半开半闭的框架,它的打开状态是怎么判断的呢?就是错误率超过50%或者60%,QPS大于一定的数字比如100或者150就熔断拒绝请求。再开一个时间窗口,这个时间窗口内放一个请求进去,如果这个请求成功就进入到熔断关闭的状态,继续失败了就重新启用。

我们参考了谷歌SRE的做法,用这个概率算要丢弃多少量。通过公式失败请求越来越多的时候,意味着失败率是百分之百。如果有成功也有失败,这个公式得出来的概率是浮动的,丢弃是控制在一定比例的情况下,可以更好更多的截流。可能在熔断期间导致本来能处理几十个请求的,一刀切了后一个都处理不了。
效果如果所示,蓝色表示发出的请求,绿色表示通过的请求,可以看到这两者呈现线性关系的,基本的趋势是一致的,个人觉得这个是比较好的。如果换到原来的做法看到的是一波上来一波下去就不太好了。
限流在Server端利用配额,给每个人配额来配置某一个人导致的问题。同时,当拒绝请求的时候,我们采用客户端截流机制的做法来相互的配合,以此达到限流。极端情况下,连200个都处理不了的时候也会设到放一两个请求慢慢的让它恢复。
3. Load Shedding
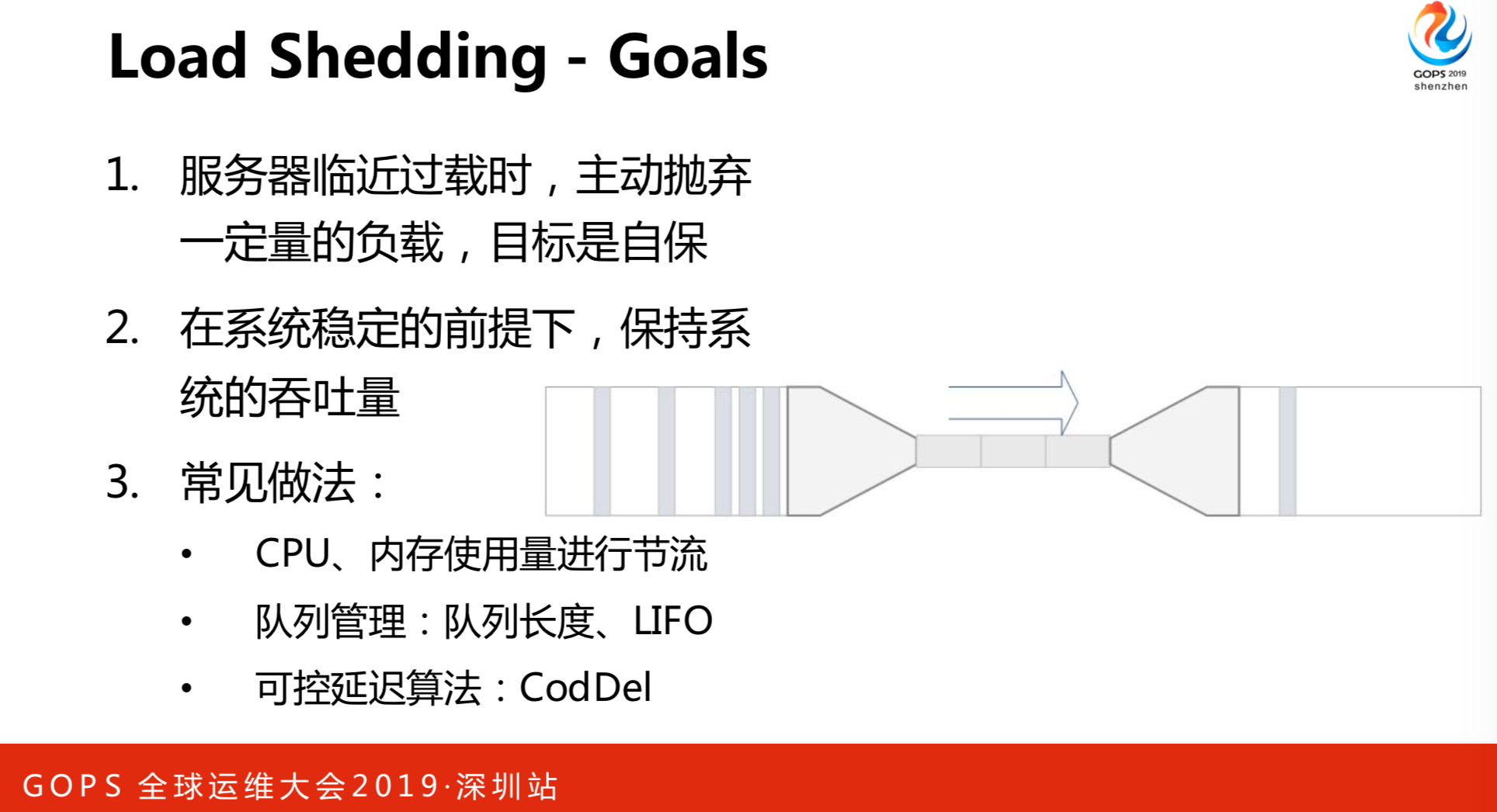
应用自保护:
- 当服务器临近过载时,主动抛弃一定量的负载,目标是自保。常见的做法是:
- CPU使用截流,CPU超过多少就截流。
- 队列管理。
- 可控延迟算法,大家可以百度搜一下蛮有意思的。
这是常见的做法,核心思路都逃不过一个基本的理念,最大的CPU×最小延迟表示应用的吞吐。



我们使用的有点像TCP的BBR,BBR怎么做呢?是交叉窗口探测当前最大带宽和延迟,最终来决定TCP的窗口是多少。我们也是类似的,但是,有一些不同,使用的是由一个Goroutin采CPU,由CPU作为启发值。比如CPU大于80%,就要考虑最大进程是多少。当CPU大于800,当前请求比它大的时候就要抛弃流量,意味着当前并发请求超过了我的承受能力就要丢掉。注意,使用CPU作为启发值,再用过去5秒的窗口统计最大通过和平均延迟,得到这个均值是多少后,再来决定要不要抛弃。CPU会一直抖来抖去,700流量不满足,立马会放一大堆流量进来。另外,我们还加了冷却时间,之后再重新判断这个条件。最终实现的效果是,当高负载CPU的时候,如果不用冷却时间抖动非常厉害,用了之后,相对是比较平稳的。
4. Graceful Degradation

降级一定是有损的。有损的服务代码平常肯定是不怎么运行的,一定要做降级演练,不要等出问题的时候降级,这样也会出问题。做演练的目的是看看到底会出了什么样的问题。常见的做法是比较简单,不仅服务端能做,客户端也能做降级。比如首页打不开的,上一次打开是不是可以缓存副本,两个端要交叉配合。
5. Latency and Deadlines

一定要配置延迟,各个环节最好都配制延迟。高配制服务导致Client浪费资源等待相应。超时是一种FailFast,会导致很多请求堵住进不来。我的建议是如果有基础库一定要做默认值,我见过很多做得不好的库,默认值等于0或者是负数,稍不小心手抖了一下或单词拼错了很久不生效就会出事故。我们会做一些保护,把基础库保存,即便配错了也有默认值。
超时传递,例如A发送RPC到B,10秒超时。B使用了8秒处理请求,再发送请求C。B配置了20秒超时发送给C,但B只有2秒的超时时间。C从队列中取出请求花了5秒。
基础库入口设置了1秒超时,所有下游组件全部要继承这个配置,随着时间推移,配额一定是在减少的。
双峰的分布,合理的配置超时拒绝超长的请求。
轻重隔离,运行时间特别久的请求最好是隔离一套集群。如果时间运行比较久,堵住了我的请求,耗短时的请求也进不来了。
