@gaoxiaoyunwei2017
2019-01-29T09:09:58.000000Z
字数 4962
阅读 2799
轻量级CMDB在自动化运维中的实践
白凡
分享:赵班长-DevOps学院创始人
编辑:白凡
讲师介绍:我叫赵舜东,号称赵班长,北漂十年,我个人也是GOPS全球运维大会金牌讲师中国SaltStack用户组发起人。

0. 背景
应该是人生中第一次在大会上分享CMDB,CMDB大家应该都知道是一个特别古老的话题,我们在传统里面CMDB来源于配置管理数据库,这几年随着DevOps自动化运维的发展,CMDB又传信回到了大家的视野里,为什么这样说?因为之前我到了很多公司去看,他们有CMDB,但是很多年前都已经不用了,我说你们现在如果管理你们的资产?他们说用Excel。
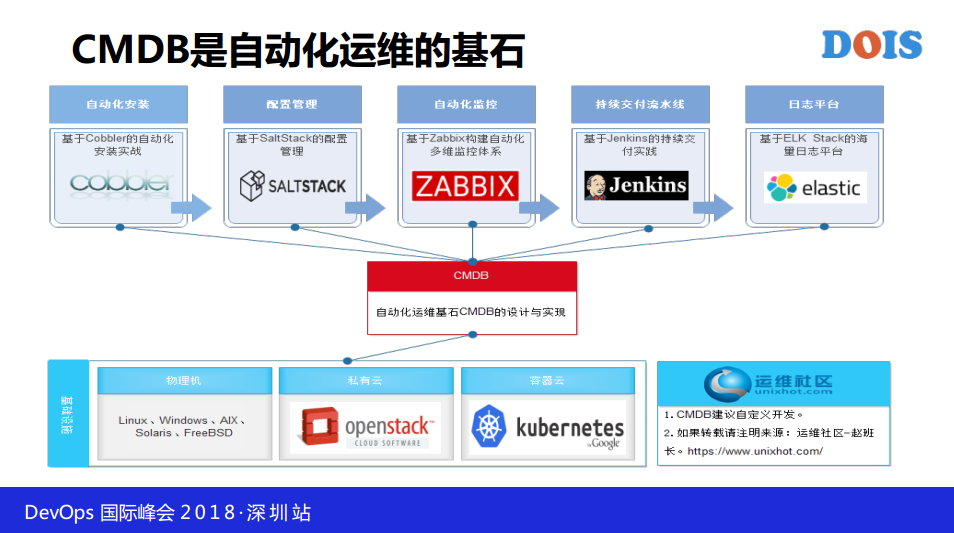
我们说CMDB是自动化的基石,我们做自动化运维情况下我们需要有一个核心的数据库来把我们所有东西全部存放到这里,其实我们知道有很多产品,就是CMDB有很多产品,但是在我们实际应用场景下,CMDB在很多的企业做的并不好,这是为什么呢?我们今天给大家来分析一下,我不说企业版CMDB,我只能说开源,因为企业版CMDB确实有很多,但是做的好的我觉得不多,当然这是客气的说法,不客气的说法是没有。
蓝鲸在今年做了开源的把他们配置平台开源了,蓝鲸的CMDB。一些传统的开源CMDB可能是iTop是一个传统的ITSM的软件,里面有传统的管理功能,我以前在使用,很大的缺点是什么呢?它如果想自定义模型非常麻烦,它是通过修改再到代码的同步,总之很麻烦。还有很多公司就是Django自研,太简单了有的时候针对小规模几十台机器肯定够用,但是对稍微大一点规模会有一些不够用。


1. 传统CMDB的痛点?
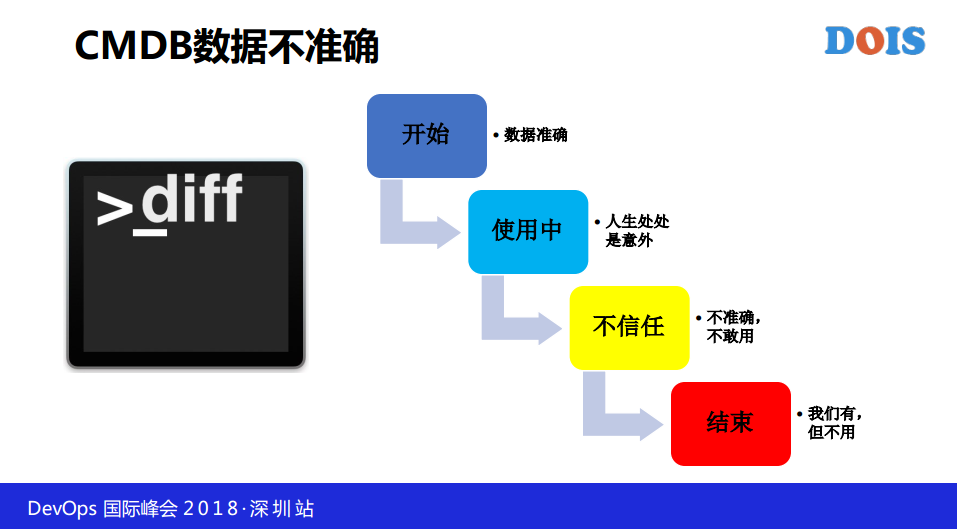
我们看一下传统的CMDB面临哪些问题?第一个很大的问题数据不准确,这是几乎超过90%大家都是这样的。最开始的时候做数据录入,数据很准确,在使用中我们说人生中处处是意外,经常走一些紧急流程没有基于CMDB做变更,CMDB的数据就不准确了,只要有一次,你就不敢用了,最终CMDB就结束了,你们有,但是不用,我见过很多银行、金融公司花了很多钱买了一个不实用的产品放在那里,而且很贵。
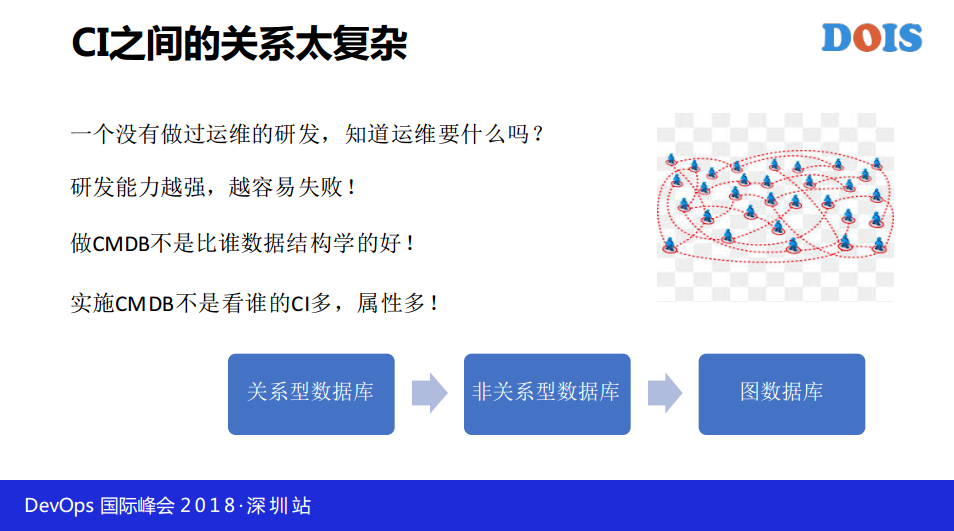
还有一个什么问题呢?CI配置项的关系太复杂,我们在研究CMDB最大的问题就是配置项之间的关系,我们有很多的资产,有物理机、虚拟机等,他们之间是什么样的关系,刚才下面有一个听众问熊老师问的一个问题特别好,说能不能给研发提需求做运维平台。看我第一句话,一个没有做运维的研发知道运维要什么吗?这句话能得罪很多人,你们要看产品经理是做什么出身的,属于是做研发出身的,你要考虑一下这个产品是不是好用。
研发能力用强越容易失败,我接触过很多做CMDB的,做CMDB不是比谁的数据结构学的好,我之前和一个研发能力很行的名牌大学毕业的人,我们一起研究各个配置项的关系,一个虚拟机在物理机里面,里面都有管理员,可能里面的管理员不是一个人,可能都在不同的部门,同一个物理机可能有在不同产品使用,不同的虚拟机被不同应用所使用,所以说你们看到这样的关系,所以很多做CMDB的第一种是关系型数据库,然后马上就发现缺点了,不好使。
然后就非关系型数据库,很多关系通过代码实现。研发能力越强看需求,看到这样的实现方式第一想到的是图数据库,最终做出来CMDB关系展示就是这样子,你们公司买到的产品展示出来是不是这样,至少国际知名的都是这样的,因为这是研发做的,可能是我水平确实不够,做了10年运维确实不懂,至少不能一下子看懂。我刚招一个初级运营工程师,体能奢望他把这个东西研究明白吗,不能。我个人觉得接地气,我能让刚入门的工程师会用,能让他研究明白,这就是接地气。
还有一个痛点,做CMDB不是看谁的配置项多属性多,我见过很多做CMDB,第一服务器CPU内存,他脑子里是特别复杂的资产的结构,首先没有错,但是不知道大家有没有听过这样一句话,不管产品还是数据,往往有70%的功能你是不用的,你只会用到30 %的功能,你的数据也是这样的,你录入100%的数据,你常用的不会超过30%。很多失败就是它太完美了,尤其是我们的技术,我个人算是完美主义者,我有时候比较挑,我觉得这个没有把它管理起来是一个问题,我后面发现其实很多资产我们可以一点一点去完善,把我们常用的做录入就可以了。
2. 轻量级CMDB设计与实现
如何设计一个轻量级的CMDB,我觉得做CMDB,比如说就两个人,我们现在两个人要在公司做CMDB,我认为有三步,我先不说用什么东西无所谓,第一步资产建模,对简单我们要设计一个表结构,虚拟机里面有很多字段,虚拟机名、CPU磁盘等,所运行的物理机是哪台。一个虚拟机肯定运行在某一个物理机上,你做一个Excel表格把关系列出来,用这个表格做资产管理的话,你要一点一点填表格,当然我们有系统的话,我们很多都支持表格导入,先建模到处表格的模板做录入,如果有系统的话,支持资产自动采集,最后数据消费,无非就是搜索、查询、展示。
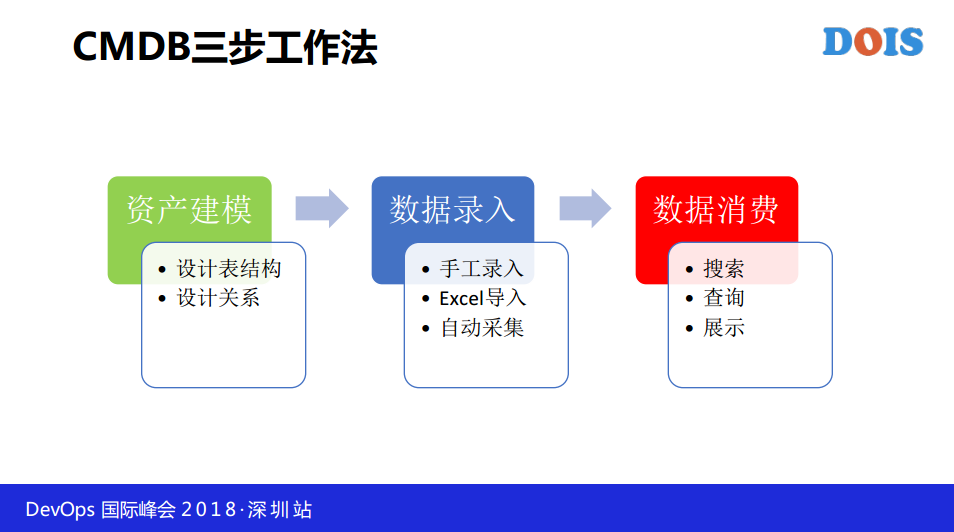
我们分别说一下,我们做整个CMDB最难的是什么?资产和资产管理。我个人将资产分为两级,可以说分为两层,下面是资源层,资源层为资源提供者,上面是应用层及应用层为资源消费者,最早的话,还还想过按照IaaS、PaaS、SaaS方式,但是后来我想用这样的就可以了。资源层有机柜,应用层产品应用集群域名运行的服务等等,为什么这么划分呢?
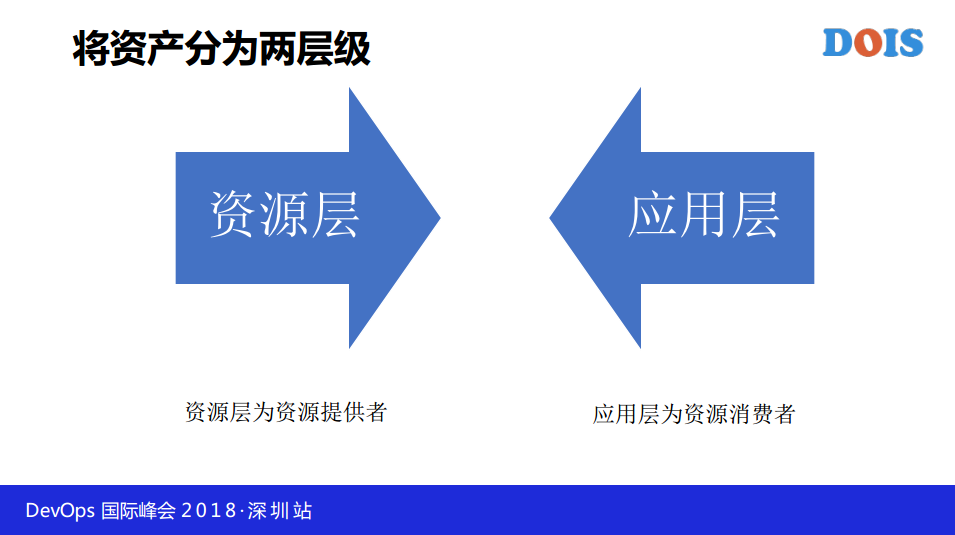
按照这种设计模式,我做一个树的建模,当时我和一个北大的同事,他跟我聊图建模,我跟他聊树型建模。大家可以看到这是一个树,从上面到下面很容易理解,这是用MongoDB组的建模,会把自己上层结构存上来,你不需要关心搜索的问题。

基于存储结构,我就把资产分为两个树,一个是资源树,一个是应用树,资源树怎么设计呢?这只是设计的一个模型,当然你可以按照你的想法设计,上面是数据中心(放机柜)机柜上面放物理机、其他设备,他们两个是父子关系,物理机肯定要放在机柜上,机柜肯定要放在数据中心上,物理机里面可以有虚拟机,也可以没有。在资源层就到操作系统这点,类似于云计算的IaaS,只到操作系统。我来设计应用这个树,产品线,一个产品线下面有多个应用,一个应用下面有多个服务的集群,现在都说微服务(用户服务、定单服务、管理后台)包括若干个应用服务和数据库。这种关联是不是父子关系?这是父子关系,这是父子关系。
这两个树明显是独立的,如果我想知道这个应用跑在哪个机房,大家说这两个树怎么能把它关联起来?只有一种方案,我们在两个树中找关系一定要找唯一性,就不可争辩的,一个应用程序是不是一定要应用在一个操作系统上?是不是?是。我通过这样把两个树木做关联,我现在是不是可以实现随便在CMDB输入一个IP地址,我能把两个架构图全帮你绘出来。
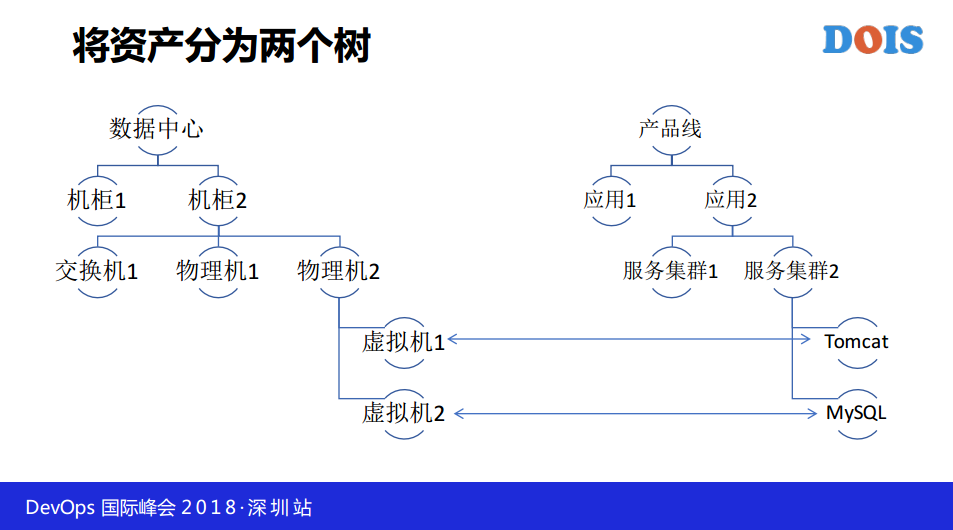
这是不是运维最最需要的?既然要做系统,我们怎么设计,首先我们要替代Excel,要加字段怎么加?在模型里面加一个字段,如果想让运维更应用,首先我们都知道做表结构设计的时候,你要怎么做,有不同的类型,有这么多类型,单行文本、多行文本、整数、小数、日期、下拉菜单、单选、多选、从属关系、连接关系、属性分组。比如说这是一个腾讯云主机,名称、CPU核数、内容,相当于可以在WEB上面自定义你的表结构。
要做这样的产品要可以做一个标准的Restful API,我们要提供一个标准的。
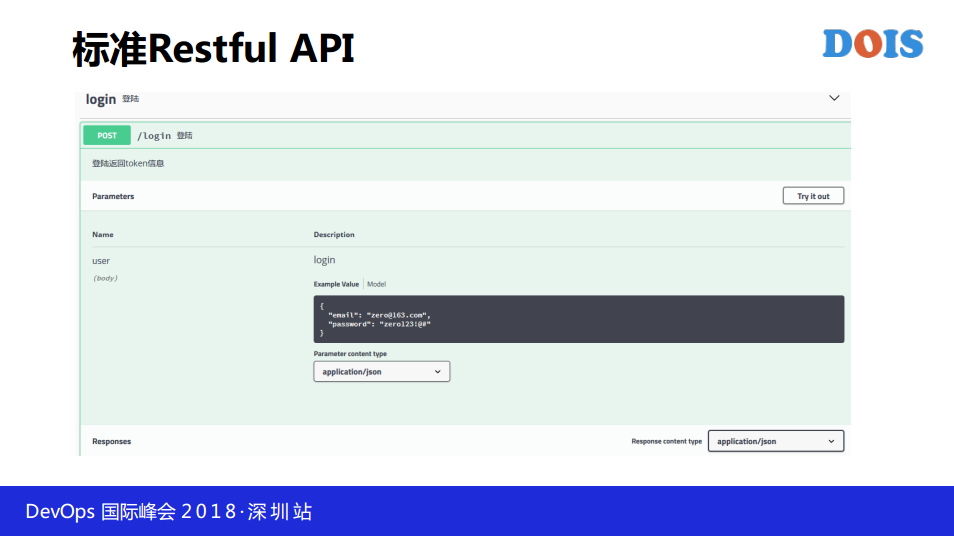
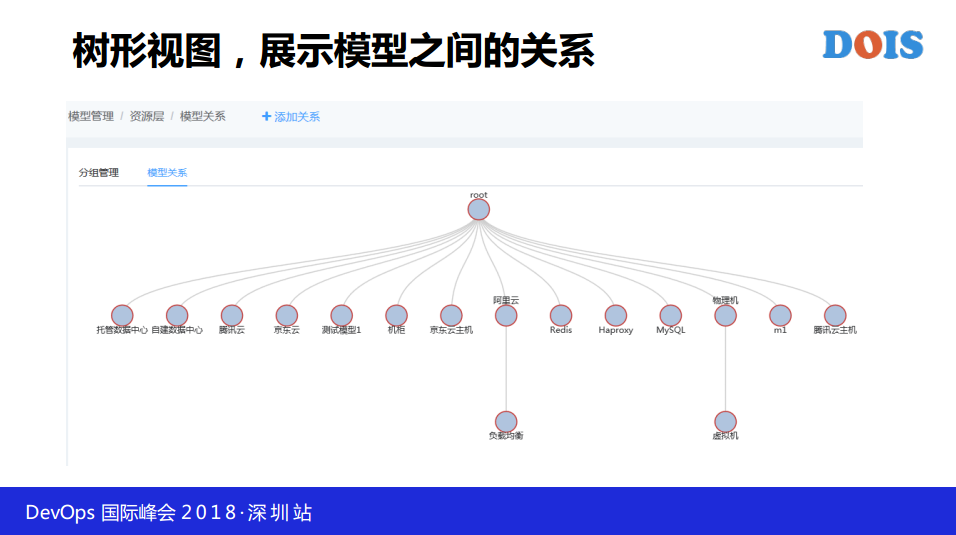
我们还要做什么呢?我们还要做这种模型关系的展示,我们在设计模型的时候虽然说是树,但是得展示出来,我们有一个关系的展示。
我说DOIS CMDB都应该有一个搜索框,CMDB没有搜索框就是失败的,在座的不是做运维的请举手(举手)我们做运维要经常搜索,我们以前使用Excel管理资产的时候,搜索框一搜就查到了,是运维最最想要的一个东西,比如说老板问你,我们有一个域名什么时候过期,打开搜索框搜索,然后就定位这个域名对应的资产,看一下这个资产什么过期,这是不是一个刚需?但没有。

3. OpenCMDB开源项目
虽然说做的不好,我和几个小伙伴还是做了一个全开源的轻量级CMDB的项目,我们这个项目的定位是全开源轻量级CMDB,我们的目标让中国所有运维工程师不再使用Excel管理运维资产,这符合中小企业。我做PO,我们有3个研发人员,两个前端,两个后端。数据可视化用百度的这个,很容易写出来,后端利用Flask+Flask为 Restful+Mongodb实现。

4. 基于CMDB的自动化运维实践
我搞了一个模型,赵班长用荣誉担保,永远不做企业版,未来收费只收服务费。简单看一下这个版本刚发布出来比较基础,我说的功能都有,第一步我这有模型管理,模型支持分组,可以自己分组,你要编辑一个模型,那就是属性管理,可以拖拽,现在支持这么多,比如说CPU,拉一个CPU整数,属性名称:CPU,属性编码:cpu-mum,单位:个,最小值、最大值填一下,然后设定,然后拽内存整数。
我说了每一个资产都应该有一个父亲,就是我们树结构的理念,所以说腾讯云主机有从属关系,实现两种关系,从属关系和链接关系,一般CMDB得有10几种,那些商业的CMDB我都研究过,所有的产品我都看过,部署过,用过,所以我知道关系很多,我故意是做的少的,对我来说已经够用了。在模型关系中,现在做的比较LOW,这个颜色可以点的,说明下面还有其他的数据,然后你在资源层就可以做数据的录入了,当然可以通过API自动填充。
为什么我说这是初级版呢?我们后面要内置很多模型,我们会把阿里云、腾讯云、京东云模型都内置一下。云服务商为空,你在选模型的时候你要选模型对应父亲模型的实例,比如说我有一个云服务商,腾讯云,我这里面做一个录入,让它关联起来,这个我没有添加,我先不添加了,让大家看一看,添加完了就可以搜索,所有的API用Swagger做的。
要走的路还很长,也希望大家私下联系我,有兴趣的话可以我们一块作,搜索框、试图展示还没有做。
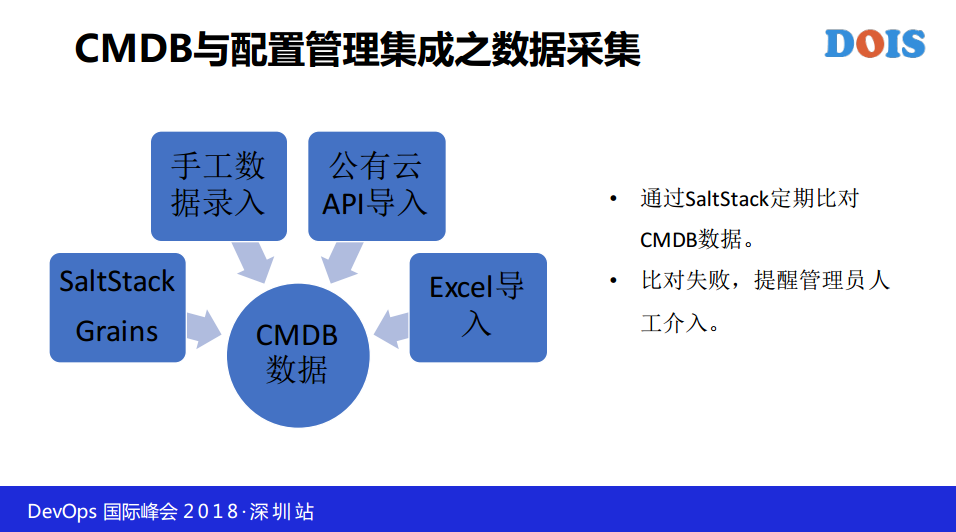
我们来看一下我们下一步的目标除了这个就是和各个运维系统做集成,现在我们已经写了一些代码,但不成熟,没有放进去,包括SaltStack。CMDB有配置管理的集成,相信大家都有配置工具。
CMDB的数据可以通过SaltStack的Grains获取,调取CMDB数据,把数据直接填充进来,SaltStack Grains支持自定义,还支持手工录入,公有云API导入、Excel导入。我们通过SaltStack定期比对CMDB数据,比对失败,提醒管理人员介入。要保证数据准确,得有比对机制,定期比对,每30分钟,每个小时都可以比对,不要每天一次。我们最早没有CMDB的时候,我们是Excel,我们对早做自动化,我们是用Excel管的。
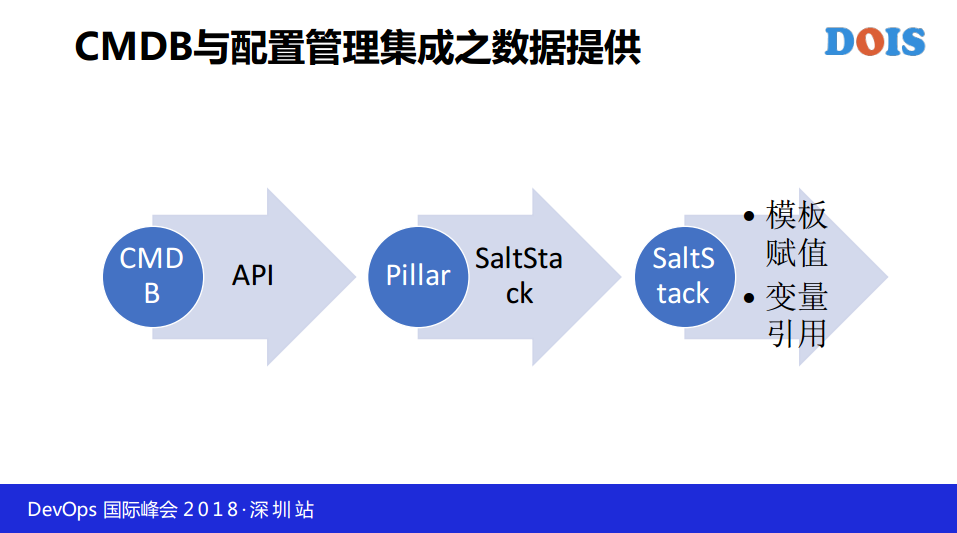
如何能和配置管理系统更好的集成呢?我这里边只做了SaltStack,如果不了解这个的话,大家可以记下来,它有两个数据系统,一个是Pillar,可以用它复制,它支持外部Pillar,只要把CMDB的数据简单包一下客观做成一个Pillar导入外部,我们可以把数据打通。如果是别的配置管理工具的话也可以通过这种方式实现。
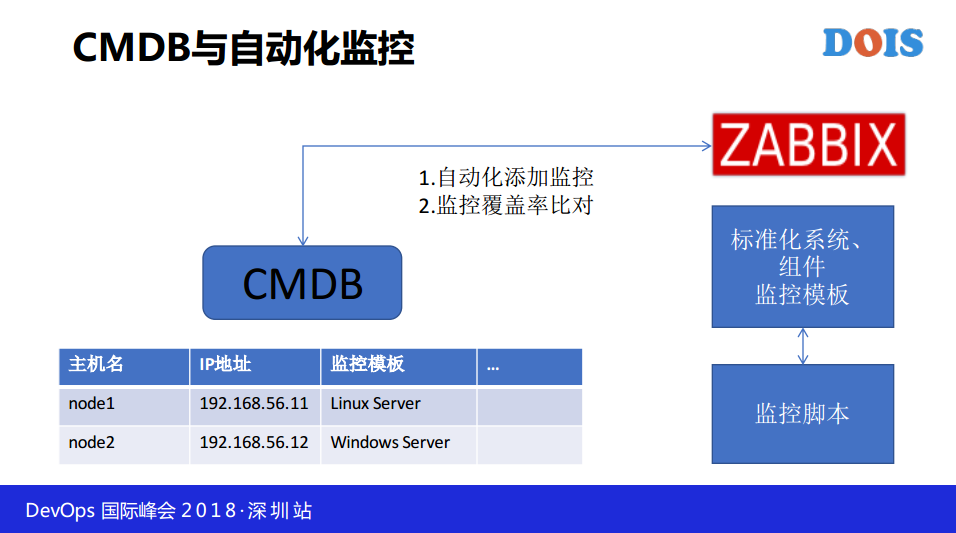
监控更简单了,监控其实真的特别简单,现在脚本已经写好了,只不过没有对外。通过CMDB的API做自动化的监控,比如说自动发现或者网络发现的功能,这两个都不要用,你突然间多了几台机器,你都不知道从哪来的,我们说运维有时候要可控,只要你CMDB没有的,我就可以保证CMDB没有,就很简单,然后直接做比对。提前你要想做一整套的,说复杂一点,你首先要有标准化系统和组建的监控模板,我们会把标准化的监控模板做好,里面包含了一些图形等等,每个监控模板对应一个监控脚本,我们部署监控是怎么部署的呢?现在在CMDB录入IP地址,首先后台进程看到监控模板的时候会怎么办呢?每个监控模板都对应一个监控脚本,我会用SaltStack把被监控的模板放在监控脚本上,然后搞定。如果没有通过CMDB做联动,你无法保证你的监控率是100%。
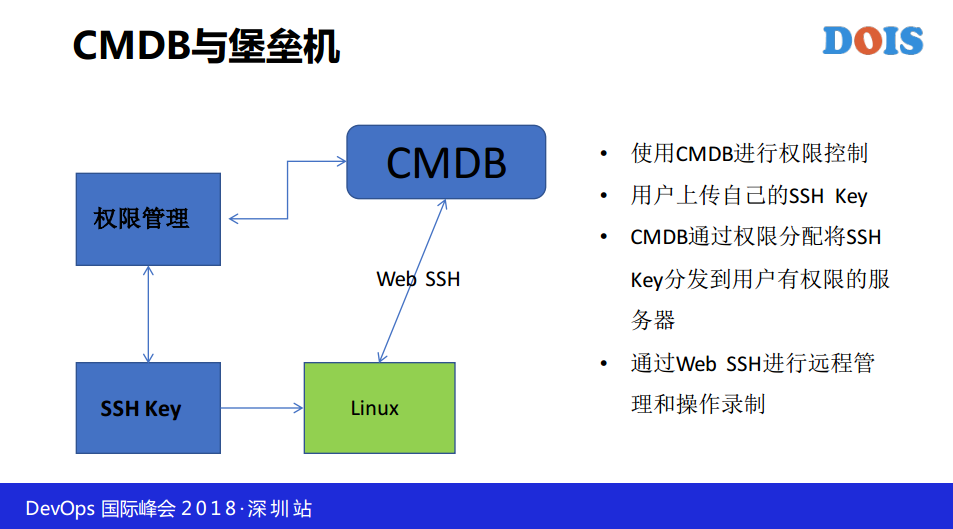
CMDB和堡垒机怎么做?我觉得堡垒机很简单,都是开源的,你不用存储WEB SSH,包括录频都有开源的。我用CMDB进入权限控制,在CMDB有哪些资产的权限,你就只能看到哪些资产,体在CMDB有哪些资产权限,我会让你在用户中心上传SSH Key,我就把这个公钥发到你有权限的机器上,就是SaltStack,然后通过WEB SSH使用公钥,然后就可以对其进行管理了。