@gaoxiaoyunwei2017
2018-05-08T06:05:20.000000Z
字数 3853
阅读 1468
乐信在消费金融领域的数据库运维实践
彭小阳
[TOC]
作者:刘剑利,乐信运维副总监。
前言:首先标题可能取得有点长,标题当时也是看了历届标题得出的标题,就是XX再XX下面的事件,都是套路。
今天的分享主要分四点:一个是什么是消费金融,这里简单介绍一下,让大家有个简单的认识,然后第二部分前面两位老师着重介绍了,我这里花一部分时间介绍一下我们这边是怎么样的架构事件。我们数据库这边做了一个DevOps的实践,最后做一下展望。
1、 什么是消费金融?

消费金融其实很简单,举一个简单的例子,就是分期购物,可能这边土豪比较多,没有做过分期购物的话我可以简单解释,比如一个苹果X,我们这边的业务场景的话是简化过后的,大体是做下单,分控、资金匹配、生成帐单、还款,当然这是简单的场景。

这里面从字面去理解的话,就是一个消费,就是有一些电商在里面,还有资金在里面。

这里看对我们数据库的要求,因为我们主要在线上做的高并发。第一点大体就过了。
2、 数据库的架构实践

然后我们重点看一下架构的实践,架构的实践说实在话,包括前面两位老师说的,在不断地背锅中我们成长起来了。
我们公司可以大体介绍一下,就是可能数据库的实践时间是两年多,所以套用最近比较火的开局一把刀,一开始都是给你两盘数据库,但是业务是不断快速发展,我们怎样做到背锅踩坑的时候完善我们的架构。
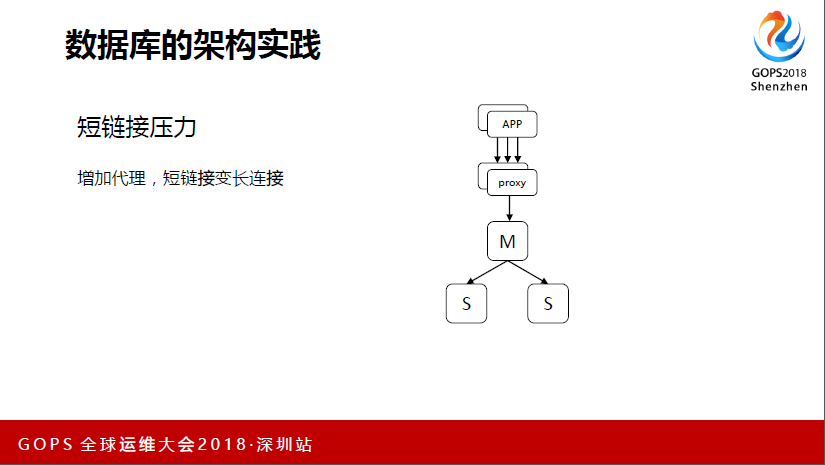
我个人观点就是没有一套最终一致的架构,可能每个人根据自己的业务形态、业务场景、发展阶段都会不一样。包括前面看两位老师也有大同小异的地方,我们第一个遇到的问题就是短链接压力,这里面的问题就是,一开始没有问题,问题来自哪里,就是我们搞大数,就是并发来的,最后被搞死了。
短链接不知道大家有没有遇到过,会导致CPU直接被耗光,可能请求还没有进入到Mysql里面,机器就死了,挂了我们的压力也很大。然后要快速解决问题的话,当时想这个方案,现在开源的很多是有链接池管理的,我们用的对链接池的管理不是很好。
我们这里用了一个方案,就是加了一个Proxy,它是360的,还有一些读写分离、刷脸的功能,不过这里我不介绍,因为我们只用了它的短链接和长链接的功能。
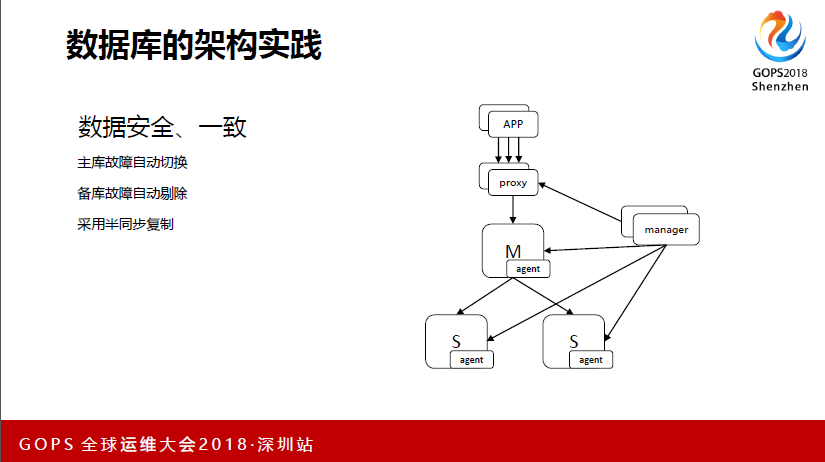
这是数据库的安全和一致性,其实这里跟大家也差不多,一个就是主库故障能做到自动切换,备库故障也能剔除,然后采取半同步复制的方式。我们高可用主要做切换的逻辑,还有当时本机故障切换的逻辑,然后我们所有的切换其实最终都在Proxy去做的,组机挂了,我只要判断故障之后,我就把proxy改到左边去。
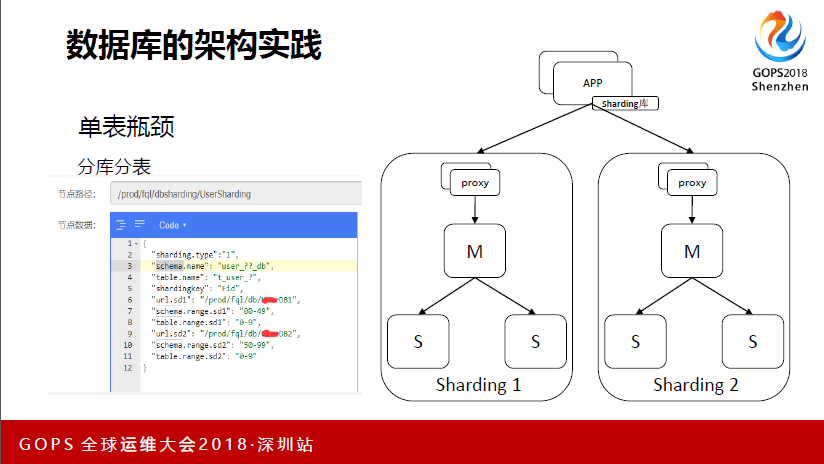
然后这也是大家会遇到的问题,单表瓶颈问题,各家实现单表瓶颈的问题也不一样。我们这边做了分库分表的方案,看左边我们的分库分表,在左边那里语法跟Mysql差不多,但我们这里是没有做成中间件的方式,只是做成一个Sharding库,所有东西去引用它。
这里举个例子,Sharding我们目前只有三种,第一个是把一个逻辑表分成一千张表,这里大体介绍一下,就是库名,因为这里做得比较简单,可能会有一些使用的规则限制。下面可以看到Sharding uil会到哪里去,库下面是表,下面是一样的,这里其实可以做到的是1000张表可以放到1000个时点里面去,但目前还没有达到那样的数据量,整体的迁移其实对研发来说不是完全透明。
这是分布式的事务,投入产出比太低了,刚才老师说到的多活,我们当时考虑的也差不多。
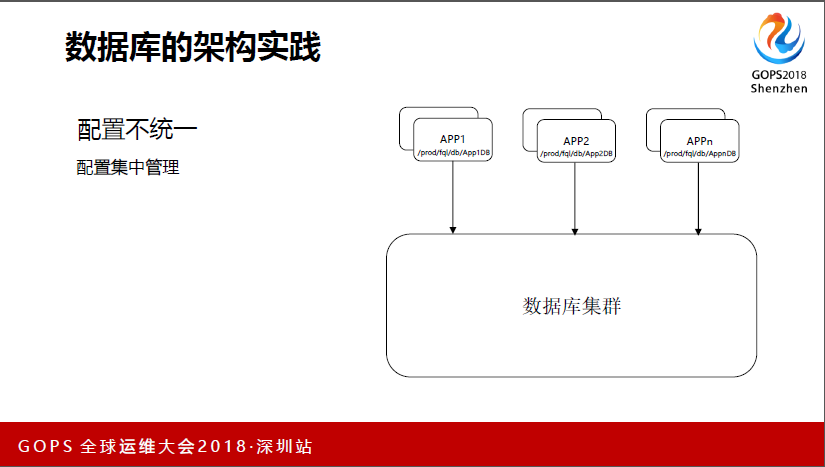
配置不统一的问题,这里可以讲历史背景,有一些开发,一开始研发不是在一起的,各业务自己搞,数据库也是一个团队在维护。这里面临什么问题?有些团队是在代码里,还有一些是稍微标准一点,用了一些配置软件统一管理,还有一些用的就是配置的集中管理。集中管理可能最终包括我们用的这个,因为这个从我们架构上来说,因为我们最开始从PSP,当时在我们那也踩过坑。
因为它要集中配置,做到自动监听,我们配置修改之后,自动监测到。这样有个好处就是,我只要数据库那边做任何的改动,其实对研发来说是透明的,不至于像之前,DBA这边要做改动的话,研发这边怨声载道。
对外来说,其实我的数据库是个大的集群,然后每个应用之间,我给它一个Ki,它只要管它的Ki是什么,后端怎么部署的它不用管。
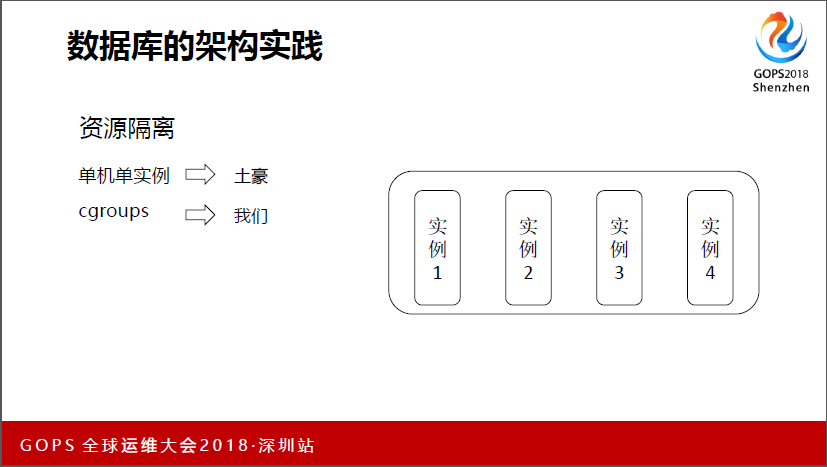
刚才第一个刘老师分享的时候,我听到一个同学有个问题,我这个给你提供一下参考,就是我们这边实例也很多,机器不是那么多,这就遇到一个问题,怎么去做。我们有什么方案呢?一个是单机单实例,现在大家单机单实例的有多少?举一下手,估计是土豪公司。
我们是用了cgroups,我个人的看法就是,补充一点,节省成本对运维是创造价值的东西,就可以做到120分。这里我们会根据业务的重要性,还有根据一些平时每个实际跑的情况,会做一些隔离,比如单机可能会有24个或者48个实例,看实际情况。
对我们来说很容易就用了,但这里在用的过程中有个终端业务,就是重启数据库才能加入到里面去,它可以做CPU内存,IO网络的隔离。

下面我会介绍一下高性能缓存,我们用的redis。最终发展起来总会遇到水平扩展的问题,水平扩展其实可以有一些方案,我们都是结合自己的特点,我们看一下从一个扩展到两个方案,会先做好一个新的集群,然后有个Redis-port的工具,我们当时拿来用发现不可用,所以做了一些改造,就是把数据同步过来做切换。我们这个可以做到任意扩展,可以伸可以缩,这里只是做从两个到三个实例的大体介绍。
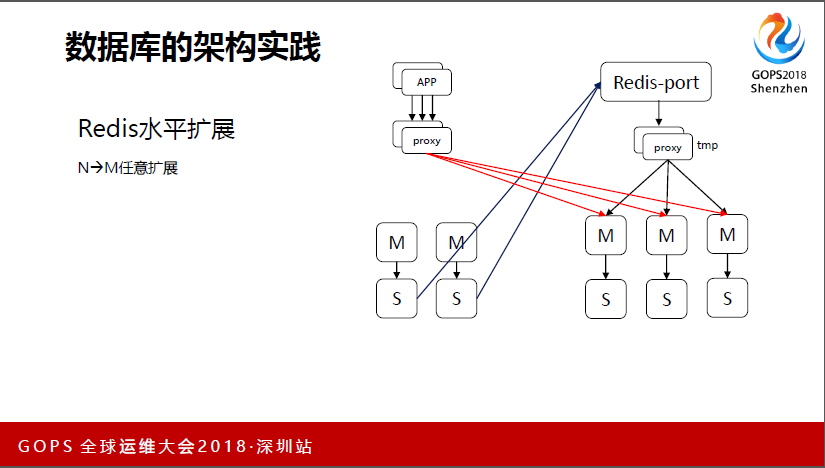
我们现在线上最大的分片就是10个分片,跟刚才那个老师的有点吻合。这里讲一个缓存更新的问题,我们业务缓存的时候,多少都会有一些问题,就是怎么去保证缓存中的数据跟数据库中的数据是一致的,一致性和及时性,有些缓存更新没有那么及时,导致一些问题。
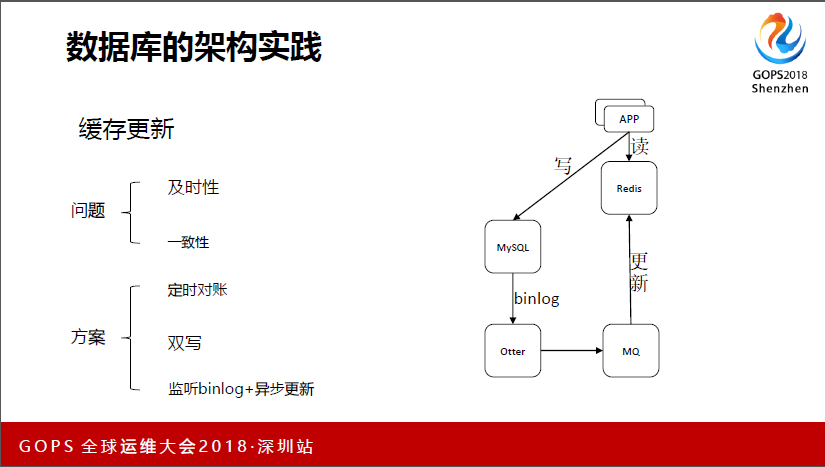
我们这里是分两种场景来做的,一个是读多写少的情况,我们读多写少看一下这个,就是我们不会去写Redis为,我们只会写Mysql。这里感觉流程很长,其实程序做起来也就是十几毫秒的事情。这里其实可以做到一个保证,就是redis数据跟Mysql数据一致,就不需要再做一步对帐。
下面一个就是读多写多的场景,这里写到MQ里面去,然后再去更新Mysql,这样也能够保证redis跟Mysql最终的一致性。
3、数据库的DevOps实践

DevOps这里我简单从思路上看能否为大家做一个抛砖引玉。我想问一下,我们现在会场内的都是运维还是开发?都有。
先看一下DevOps的主流定义,就是利用一些主流平台来提升研发、运营、质量三个角色的整体效率。以前的沟通能力主要靠人,其实这里面更多的是撕逼。
这是我自己说的,不是主流的定义,就是从一开始研发或者质量会吐槽你。我们的沟通能力最终还是停留在人的瓶颈上,我们最终要做好这个事情,DBA还是要面临转型。
当然是不是很难呢?只是开头难,因为我最开始做这个转型的时候也是,总感觉无从下手,这里我讲一下过程中的转型之路,然后看对大家有没有一些启发。就是先找到自己的第一个需求,这肯定是要做的,其实你现在可能很多痛点,比如跟开发之间的沟通问题,或者内部的效率问题。

我当时是一个线上DML和DDL的变更,因为我们当时业务发展挺快的,各种变更。我们当时2015年的时候团队有三个人,只能自己谋出路。然后第一个需求确认了之后怎么开始我们的第一个需求,我们借助开源的力量,我看一下整体的架构下来,基本上开源跟自源只是8比2的关系,这里要看的话就是让顺丰科技找一些人也可以。
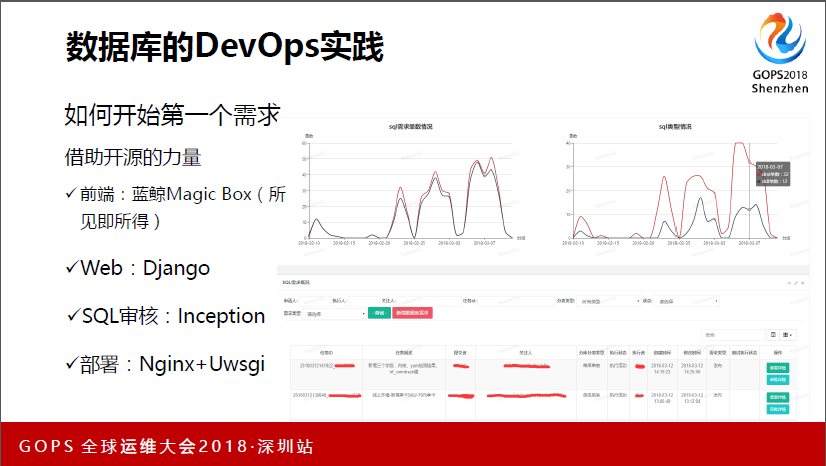
我们更多的是借助开源人员,利用一些轮子,不用重复造轮子,我们用已有的轮子自己去组装。然后前端,这里也是帮别打一下广告,一开始我们做前端,不管对运维还是DBL都是比较痛的点,但是最终发现做的页面交互,还有整体的设立都不太好,那还不如用所见即所得的东西,在对我们来说是最痛的点上可以很好的解决。还有Web,当然还有一些其它的点可以选。
然后SQL审核,因为DDL和DML必然离不开SQL的审核,我们这边应该有同学听过去哪开源的Inception,我们自己的一些规范要求,我们是在上面做了一些封装,但没有去动它。然后就是怎么把这个东西部署下去。
看一下我们DBL和DDL做出来的界面,这里面是一天的需求,把它加起来估计50多个吧,对我们来说,做了这个就一个小的功能,就可以减少一个人力出来。然后下面去做一些监控之类的,只不过逻辑不一样,我这里不做过多介绍。
4、展望

然后来看一下展望,这应该是去年流行起来的叫NewSQL的东西,这个NewSQL是当时比较官方的定义,它是对各种新的可货栈高性能数据库的简称。这类数据库不仅具有NoSQL对海量数据的存储管理能力,还保持了传统数据库支持ACID和SQL等特性。这类数据库国内有两个。
再看一下AI,现在好象不谈AI都不好意思说自己是互联网了。我们看一下,从2016年3月,阿尔法狗以来,整个业界掀起了一场AI热,我们看一下跟我们数据库相关的。2017年6月份,谷歌出了一个OtterTune,它自动去学习、自动去调优的工具。

我们的感受就是完了,再不搞AI,感觉下一步浪潮里要被淘汰了。其实我们这里好像运维的社群也发布了一个叫AIOps的白皮书,我看了,跟我们现在的整体思路差不多,不管目前处于什么场景下都可以尝试去做AI,或者DevOps的阶段比较成熟了也可以去做。AI是大势所趋,我觉得大家应该要积极去拥抱。
我们这边做了数据库容量预测,比如我一套实例,每天上报,会预测什么时候会扩容等等,已经做了,做得没那么深,还有就是异常检测,具体的方法我这里就不展开,大体就是利用大数据,然后用机器学习去做。
我今天的分享就这么多!
