@gaoxiaoyunwei2017
2021-06-04T08:56:39.000000Z
字数 5540
阅读 2847
Elasticsearch 数据迁移与容灾实践
公众号
说明:本文根据高斌龙老师在 GOPS 全球运维大会 2021 · 深圳站的分享整理而成。
作者简介
高斌龙(bellen),腾讯云大数据开发工程师,目前专注于 ElasticSearch 云产品研发工作
大家好,我是来自腾讯的高斌龙,今天跟大家分享的主题是“ElasticSearch数据迁移与容灾实践”。
今天分享内容的来源是过去几年我们在服务腾讯云客户使用 ES 过程中碰到的数据同步、数据迁移以及客户有一些容灾方面的需求,我们同样也给出了解决办法,所以今天的分享内容分为三个部分,先首先介绍一下 ES。
ES 是开源的基于 Lucene 打造的分布式搜索引擎,根据 DB-engines 数据库排名常年稳定在七八位,应用场景典型的有搜索、日志,在 APM、LK 领域也有 ES 身影。
一、异构数据与 ES 同步
第一部分异构数据与ES同步,指不同数据源与 ES 之间数据导入导出。不同的数据源,像关系型数据库 MySQL、PostgreSQL,或者文档数据库 MongoDB,消息队列 Kafka、RabbitMQ 和 ES 间的同步,还有 Hadoop 生态系统与 ES 的数据相互的导入导出。
也有客户想把 ES 本身的数据归档到对象存储、腾讯云 COS、阿里云OSS,或亚马逊的 S3 的对象存储中,从而降低 ES 本身的存储成本。因为对象存储可以称为廉价存储,存储成本比较低。
异构数据同步有个非常典型的场景就是电商搜索场景,电商数据本身是要存储在关系型数据库像比较重要的 MySQL 或 Oracle 中 ,这些数据是作为主库的,为了加快商品条目的搜索,就需要用到 ES,需要把 MySQL 中的数据实时同步到 ES 中,利用 ES 的搜索能力进行商品搜索。
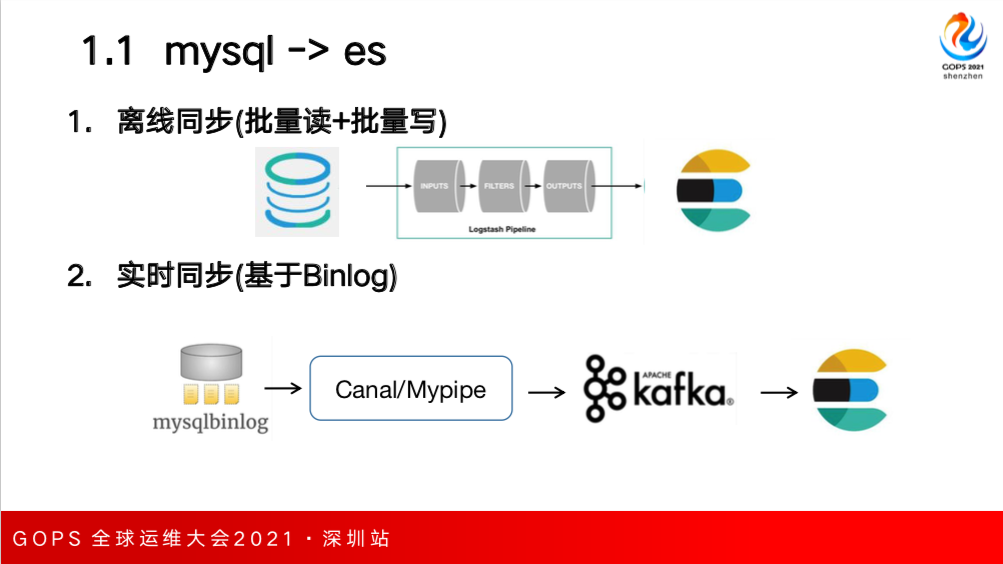
MySQL 数据要导入到 ES 根据同步的方式可以分为两种。第一种是离线同步,是指源库 MySQL 的数据暂停写入,就是说数据不再新增,可以称为一次性或全量通路,这个时候就可以采用 Logstash 组件,在 input 端通过 JDBC
Driver 去连接 MySQL 数据库批量地把数据读出来,在 output 端利用 API 进行批量写入,但是特点是一次性的,只能进行全量导入。
在某些场景下,如果源库里的数据没有删除或者数据量本身比较小的情况下我们也可以做简单增量,即源库数据没有删除,数据量比较小只有新增或更新,这个时候比如可以根据数据库里的 uptime 字段可以批量定时拉取最近一段时间内的新增数据,把新增数据也导入到 ES 中,但是问题是同步的实时性不是特别好,速率比较低。
如果要真正做到实时同步就要基于 MySQL 的 Binlog,当然也有一些开源组件如 canal/Mypipe 组件运 用一些组件实时获取到日志进行解析,也可以直接吐出到 ES 中,也可以加一层消息队列对于解析到 Binlog 中的操作数据做持久化,可以保证实时同步数据的可靠性,数据在 Kafka 中最常见采用 Logstash 进行消费写入到 ES。

与MySQL类似,如果 MongoDB 文档数据库写入到ES,也可以采用 Logstash 一次性全量把 MongoDB 中的数据写入到 ES。
如果要进行实时同步的话,就要采用 MongoDB 的 OPlog,开源的 Monstache 进行实时同步 MongoDB 数据,Monstache 也可以支持全量同步,如果源库中的数据跑了很长一段时间后数据积累了很多,这个时候 Monstache 先进行一次全量再进行增量再把数据写入到 ES 中去。
第三种常见的是在ELK日志系统中,通常我们采集日志不是直接把日志采集就直接放到其中,而是要做持久化,将日志经过 Logstash 等采集到之后,先拖到消息队列Kafka中去,再采用 Logstash 消费 Kafka 中的数据写入ES。
除了用Logstash消费Kafka数据,腾讯云上还有SCF无服务器云函数,也可以实现对 Kafka 数据的消费和写入。这个云函数是跑在容器里的,可以订阅到 Kafka 中的某一个 topic,当这个 topic 产生数据之后之后才可以触发 SCF 云函数的执行,所以它的成本是非常低的,因为是 Serverless,根本不会用到服务器资源,可能跑了几百万次费用才几块钱,成本是非常低的。
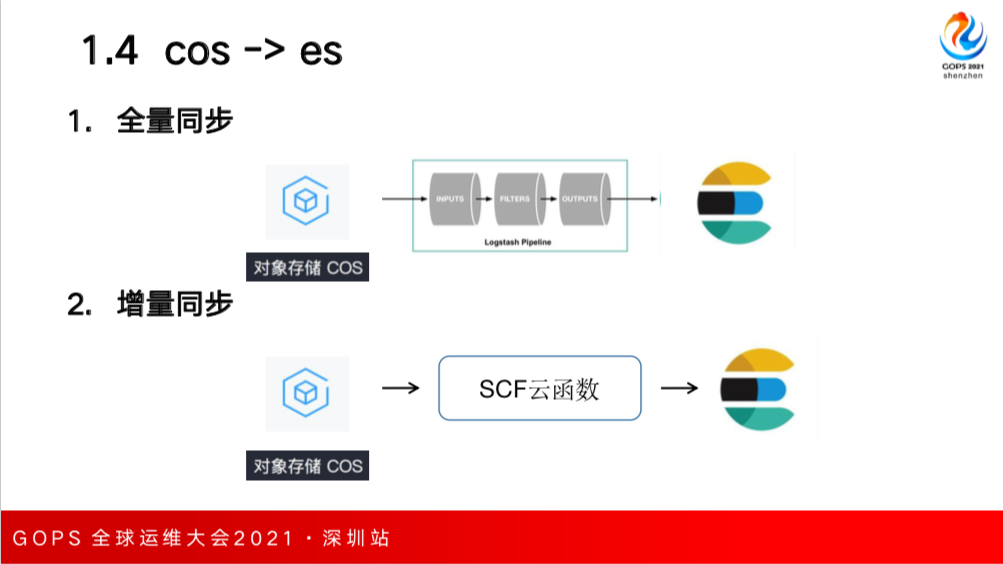
第四种是对象存储,有一些客户需求把对象存储中的数据同步到 ES 中,对象存储本身有8K,里面可以存放各种内容,包括普通文件和音视频文件等,如果要进行全量同步的话,可以采用 Logstash;如果增量同步,目前腾讯云上也是采用SCF云函数,可以订阅到多向存储里某一个bucket,如果这个bucket上传文件的话,就可以触发到云函数的执行,云函数内部逻辑会把文件读出来做一些解析然后再写入到ES中。
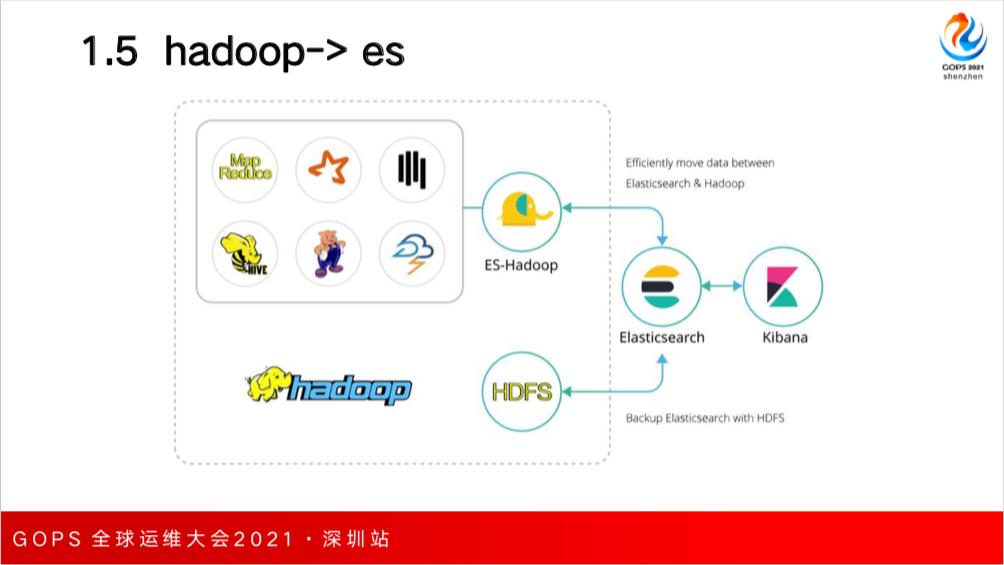
第五种是 Hadoop 生态系统和 ES 数据的导入导出,这种场景 ES 官方提供了 ES-Hadoop 组件,可以实现Hadoop各种生态内的组件和ES的交互,可以在其中建一个Web表,指向的是ES本身的索引,就可以使用其查询其中的数据,也可以通过这个组件到把数据导出到HDFS中。
还有一种场景是ES本身的数据磁盘上的索引文件可以通过快照的方式 可以归档中 HDFS 中,因为一些老的数据做归档存储在ES中的索引文件都可以被删掉了,真正需要用时再恢复到ES中,从而可以降低ES本身的存储成本。
二、ES 集群间数据迁移
介绍完ES和异构数据的数据同步后,解析来介绍一下ES本身不同集群之间的数据迁移,这部分内容主要是为了满足客户跨机房数据同步或跨云数据同步的需求。

根据迁移方式的不同分为离线迁移和在线迁移。离线迁移是迁移过程中旧的集群可以停服或者暂停写入,因为增量数据不好进行同步。如果客户可以接受离线迁移的话需要把原集群暂停写入,迁移完成后业务切换新的集群进行读写。
如果客户不接受就得进行在线迁移,迁移过程中旧的集群不能停服不能暂停写入,这部分增量的数据也需要进行迁移。

离线迁移工具非常多,Elasticsearch-dump,是用 Node.js写的, 特点是简单易用,适合数据量比较小的场景,10GB 以下的数据量建议使用该工具,因为它本身的稳定性不是特别好。
第二种是 Logstash,比较适合于对数据进行过滤或预处理的场景,或者源集群与目的集群版本跨度较大的场景,像刚才赵班长(舜东)提的集群是1.4 的版本,这个时候就可以经过 Logstash 从 1.4 的版本迁移到高版本,比如 5.x,6.x的版本。
第三种是 Reindex,是 ES 本身提供的 API,通过直接调用ES的API方式进行迁移。不仅可以做同集群之间不同索引的迁移,也可以做跨集群之间的数据迁移。但是有一个限制,目的端的集群需要能够访问源端集群的节点。Logstash、Reindex 适合于 100GB 以下的数据量。
2.1 离线迁移
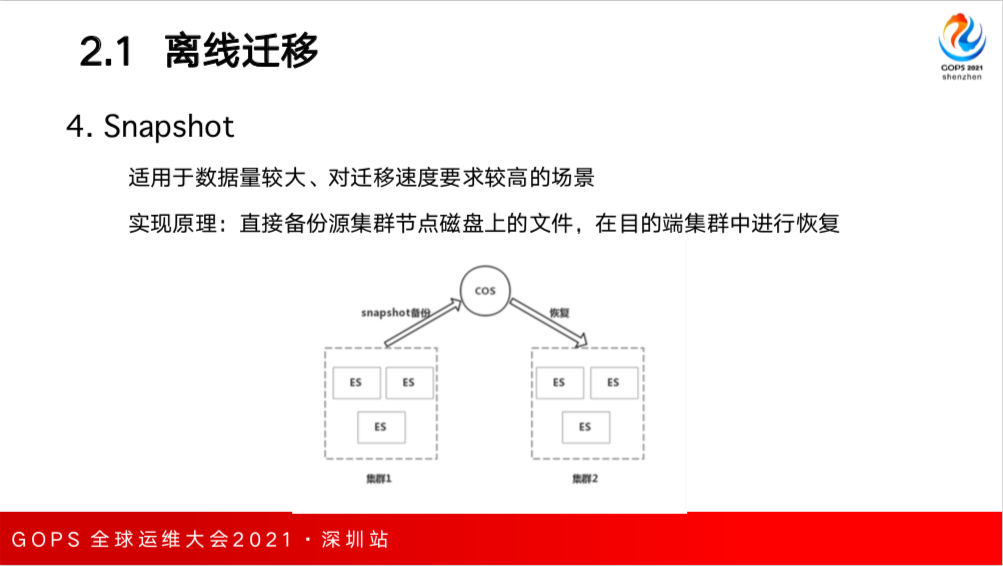
如果数据量比较大,到了几十或几百TB用前面的方式就比较慢了,通过批量读+批量写的方式效率是非常低的,这时候就可以采用 Snapshot,是ES本身提供的一个API,可以直接把源集群节点磁盘上的所有文件进行备份,可以备份到 COS 或者 HDFS 中去。然后在目的端集群进行恢复,恢复的过程比较快,所以适合数据量比较大对迁移速度要求比较高的场景。

2.2 在线迁移
接下来介绍在线迁移。根据用户写入场景可以分为两种,第一种是用户的写入只有数据追加或更新没有删除,在数据量比较小的情况下就可以使用 Logstash 先进行全量再进行增量迁移,全量是指一次性把某一个索引从源集群导入到目的端集群,然后再通过 Logstash 的配置文件里增加一个定时任务,目的是比如每隔一分钟拉取过去一分钟内源集群内新增的数据。拿到新增数据再把这部分增量数据写入到目的端 ES 中,它迁移速率比较低,只适合数据量比较小的场景。如果有删除操作的话,Logstash 根本就达不到删除操作,就需要用其他方案。
第一种方案是 snapshot + 双写。snapshot 是对 ES 底层文件进行备份,所以可以通过snapshot把一些存量的、老的索引进行一次性迁移,它的迁移速度还是比较快的;增量的索引可以采用双写,同时向两个索引进行写入,保证双写的数据在两个集群里都是一致的。
第二种是业务端进行双写。如果业务端数据都存储在消息队列 kafka 中的话,这时可以起两组 Logstash 同时消费 Kafka 中的数据,然后写入两个 ES 中,这样也可以保证数据的一致性。
第三种是采用 ES 原生的 CCR 跨集群复制功能,开启集群间的数据同步。优点是数据一致性可以得到很好保证。
第四种是腾讯云提出的采用节点双网卡的方案,可以使源集群和目的集群融合,使得这两个集群成为一个集群。再采用 ES 的 的 s-cloud 功能把老的集群中数据搬迁到新集群中,之后再把老节点下掉,就完成了一次迁移。
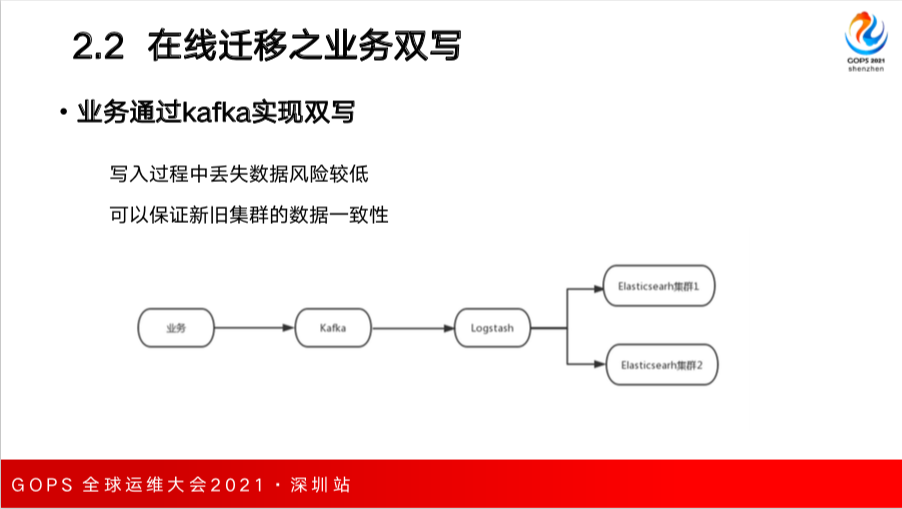
迁移用的双写的话,一般业务数据可以存储在消息队列 Kafka 中,起一组 Logstash 并行消费来写入到两个 ES 中,优点是写入过程中丢失数数据的风险比较低,可以保证新旧数据的一致性。
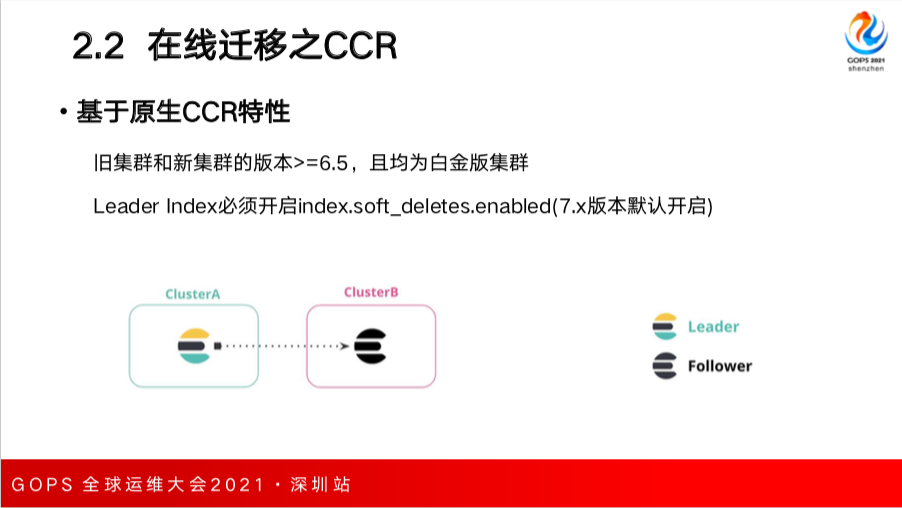
如果采用 CCR 的话有一定限制,因为 CCR 是在高版本集群中才会支持,要求新集群和旧集群的版本在6.5以上,并且都包含高级特性。
比如 ClusterA 作为一个 Leader,ClusterB 是一个 Follower,ClusterA里的一些index是Leader index,B中的索引是Follower Index,Follower Index 会定期向 Leader Index 主动拉最近一段时间内数据的更新,然后在自己这一端做重放,实际上类似于MySQL的binlog。
但是Leader index必须开启soft deletes配置。如果6.x以上的版本是默认不开启的,如果已经创建索引的不能采用CCR,7.x 以上的版本默认这个特性是开启的,所以可以直接采用CCR。
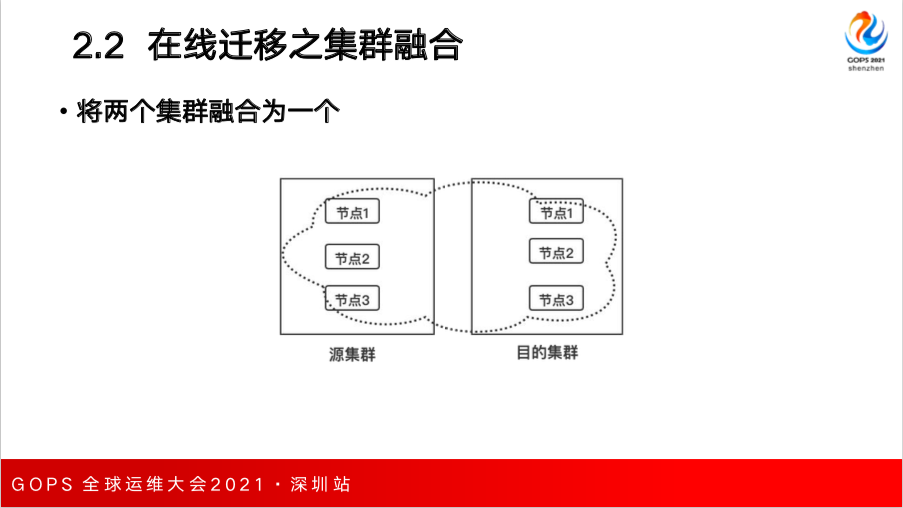
腾讯云提供的方案是把原集群和目的端集群进行融合,每一个节点可以互相通信,融合成一个后就可以调用 ES API,把源集群节点剔除掉,触发分片的自动搬迁,把分片中的数据从源集群节点主动迁移到目的端集群,迁移之后源集群节点就可以下线掉。
3、ES 容灾实践--跨机房、跨地域高可用
介绍完数据同步和数据迁移后再介绍一下ES容灾实践,这部分内容和前两部分是息息相关的,这部分内容主要是为了满足用户在跨机房、跨地域、高可用的需求。
3.1 同城容灾
根据容灾需求的不同可以分为同城容灾和异地容灾,同城容灾主要是采用跨地方部署的方式,异地容灾主要是采用主备集群。

同城容灾如果采用主备集群的话,常见的解决方式是在两个机房中部署一主一备两个集群,再解决数据同步的问题。数据同步一种方式是采用同步双写来保证数据一致性;还有就是异步复制,如果不采用 CCR 的话,没有办法严格保证数据的一致性。

如果不采用主备集群方式,采用跨机房部署集群也可以,相比跨地域的网络延迟低很多,我们的解决方案是在两个机房中部署一个集群,使得同一个索引主分片副分片分布在两个机房中(可用区指机房),某一个可用区挂掉后另外一个可用区仍然保留完整的数据,数据仍然可靠。
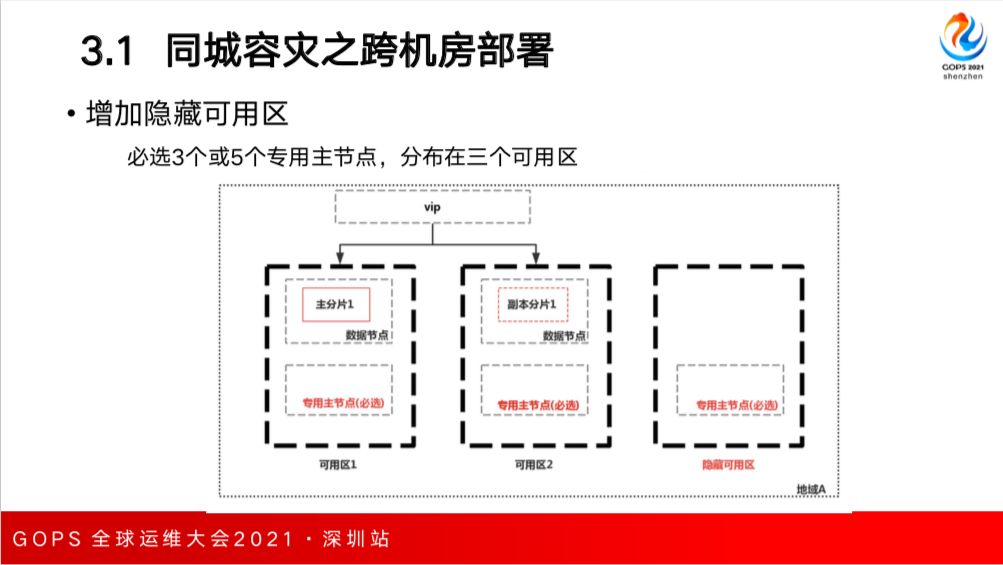
跨机房部署同一个集群,如果没有使用专用主节点的情况下,往往就会在两个机房里部署同样数量的数据节点,这个数据节点同样也作为 master 节点存在,这样就会存在一个问题:当两个机房/可用区之间的网络出现异常时,每个机房的节点都隔离的,会触发脑裂问题,每个机房都会重新选出一个 master 节点各自为政。就出现了脑裂,没有办法保证两边数据的一致,带来的损害非常明显。
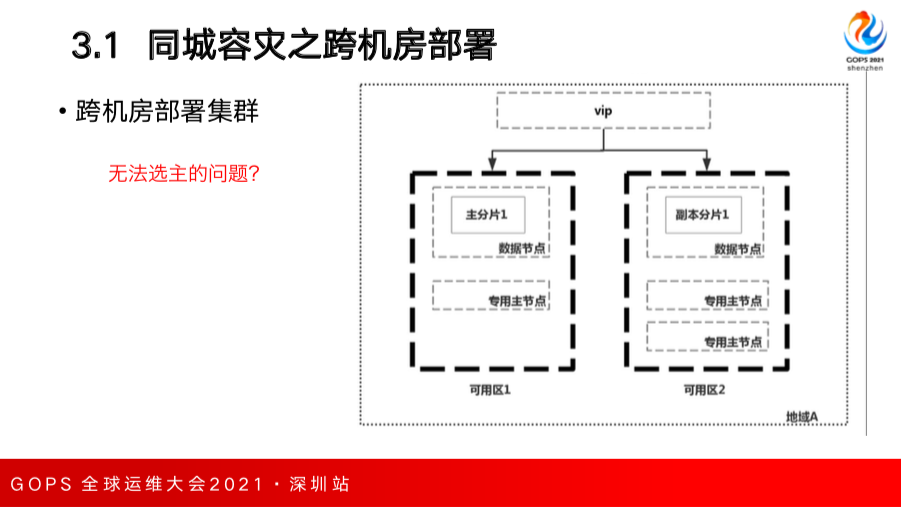
为了解决这个问题,我们可以采用部署专用主节点的方式,部署奇数个专用主节点分布在两个机房中。但是会出现一个问题,比如图中部署了三个专用主节点,机房1有一个,机房2有两个。当机房1挂掉了,机房2有两个专用主节点,这时候可以满足大多数的条件,可以选出专用主节点。但是如果机房2挂掉只剩一个专用主节点,就不满足大多数的条件,这时候机房之间无法选主。
针对脑裂与无法选主的问题,腾讯云的解决方案是增加隐藏可用区。用户购买双可用区部署集群后,我们会在后台默认增加一个隐藏可用区,强制必选3或5个专用主节点,这3或5个主节点分布在三个可用区,任何一个可用区挂掉后,剩下的专用主节点还是可以正常选主,避免了集群脑裂和无法选主问题的产生。
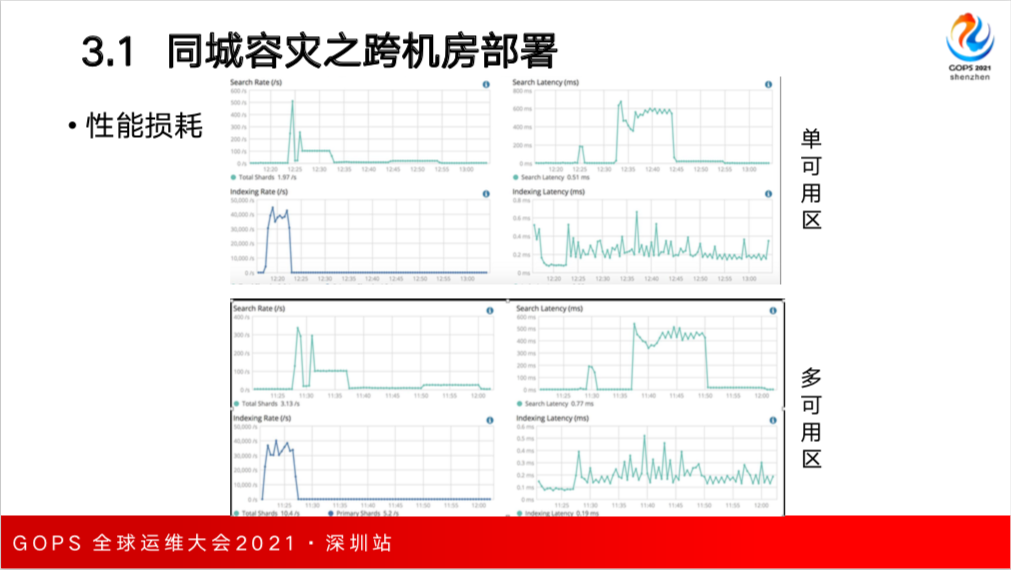
云上网络基础设施的完善,延迟可以做到很低。我们采用了标准的数据技进行了测试,单可用区和多可用区间集群的性能差异别不是特别大。
3.2 异地容灾
关于异地容灾,一般会采用主备集群方式,比如上海是主机群,采用了多可用区部署架构,北京有个单可用区部署的集群,北京的集群作为 Follower 集群主动向上海主集群拉数据进行数据同步,这样就实现了两地多中心的架构。
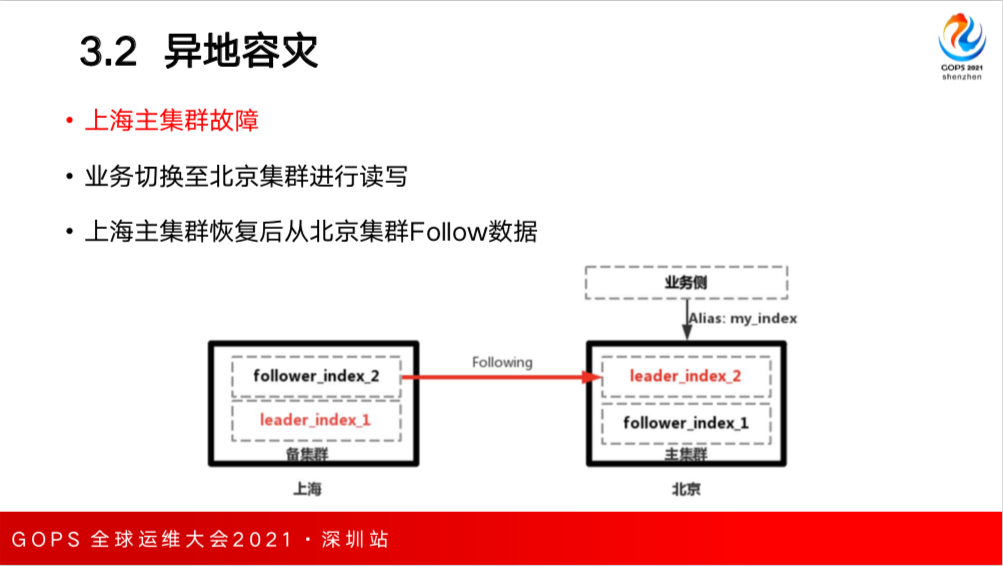
北京的备集群向上海主集群主动拉数据,在发生故障或切换时还会存在问题。这里介绍一个案例,由上海的主集群正常提供服务,北京的备集群向主集群同步数据,正常情况没有问题。上海集群是 Leader Index,北京备集群有个 Follower Index。
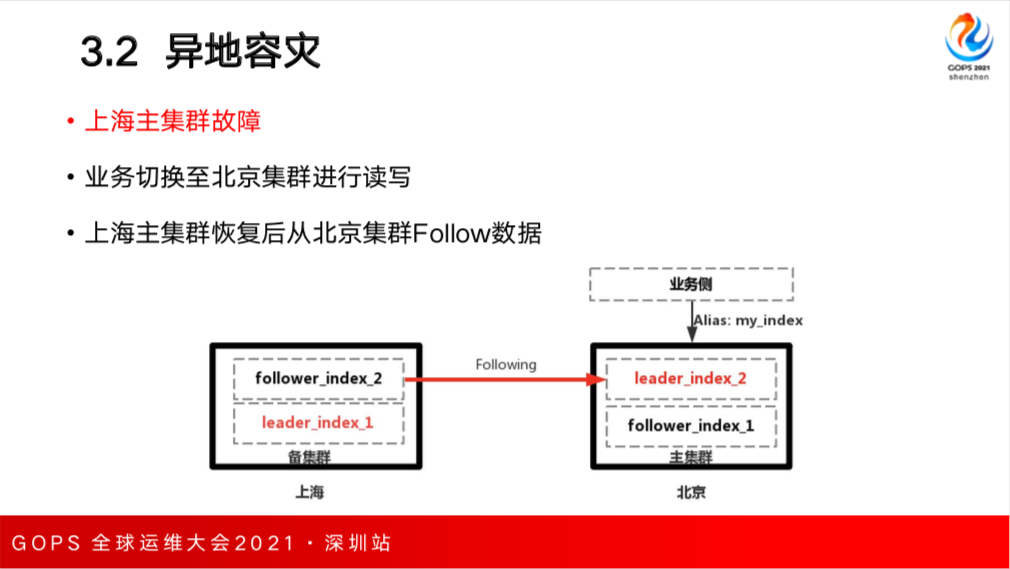
问题在于 CCR 这个特性,Follower Index 是只读的,不能进行写入。如果要进行写入必须要做一些不可恢复不可逆转的操作,Follower Index 需要先关闭,暂停 Following 然后再打开,Follower Index 变成了可写入的索引,但是之后不能继续作为 follower向上海主集群进行同步数据,如果上海的主集群故障,需要切换到备集群进行读写,切换到一个正常的索引进行写入,如果上海主恢复之后就可以从北京的 Leader_Index_2 里 follow 数据。
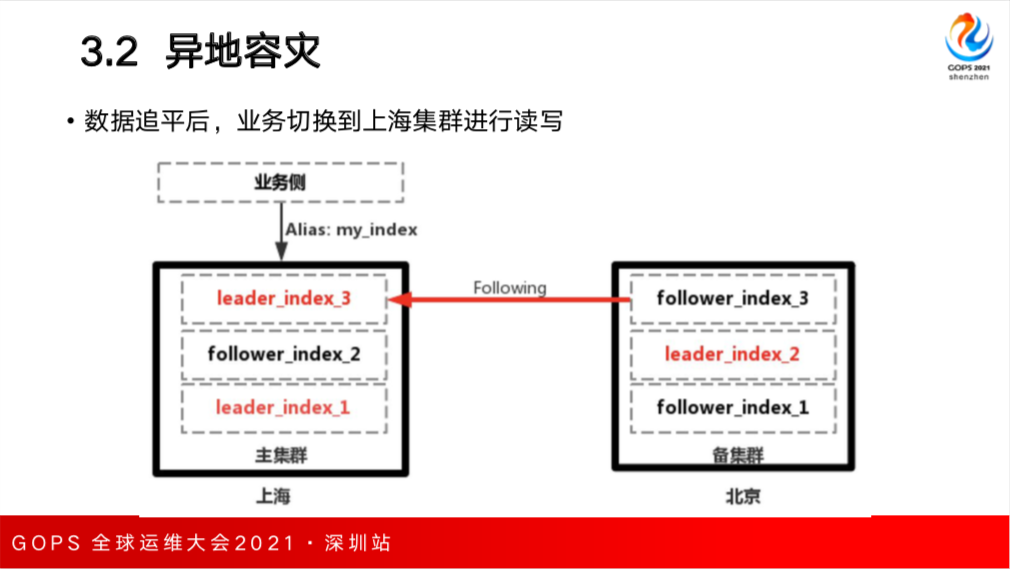
这个时候如果数据追平了,并且上海的集群从北京的集群同步数据已经完成之后,业务往往是采用就近读写的方案需要切换到上海的集群进行读写,这个时候上海的集群仍然作为主集群,重新创建一个新的leader index3,再进行重新同步数据。
